- ما حجم الكتلة التي أحتاجها؟
- حسنًا ، هذا يعتمد ... (ضحك غاضب)
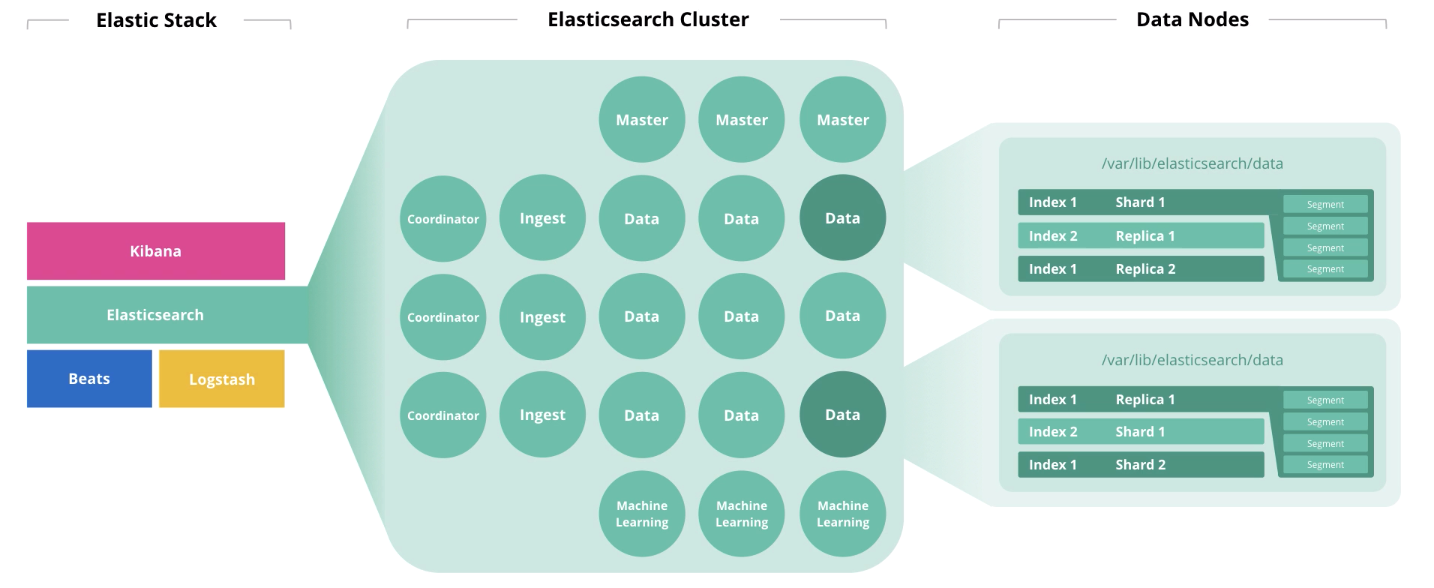
Elasticsearch هو قلب المرنة المكدس ، حيث يحدث كل سحر الوثائق: إصدار وتلقي ومعالجة وتخزين. يعتمد الأداء على العدد الصحيح للعقد وبنية الحل. والسعر ، بالمناسبة ، أيضًا ، إذا كان اشتراكك ذهبيًا أو بلاتينيًا.
الخصائص الرئيسية للجهاز هي القرص (التخزين) ، الذاكرة (الذاكرة) ، المعالجات (حساب) والشبكة (الشبكة). كل عنصر من هذه المكونات مسؤول عن الإجراء الذي يقوم به Elasticsearch على المستندات ، والتي ، على التوالي ، هي التخزين والقراءة والحوسبة والاستقبال / الإرسال. دعنا نتحدث عن المبادئ العامة للتحجيم وكشف "يعتمد". وفي نهاية المقال توجد روابط إلى ندوات عبر الإنترنت ومقالات ذات صلة. دعنا نذهب!
تستند هذه المقالة إلى
ديفيد مور عن الندوات عبر الإنترنت وتخطيط القدرات . لقد استكملنا تعليله بالروابط والتعليقات لجعله أكثر وضوحًا. في نهاية المقال ، مسار المكافآت هو روابط للمواد المرنة لأولئك الذين يرغبون في الانغماس في الموضوع بشكل أفضل. إذا كانت لديك تجربة جيدة مع Elasticsearch ، فيرجى مشاركة التعليقات في كيفية تصميم مجموعة. نحن وجميع الزملاء مهتمون بمعرفة رأيك.
Elasticsearch العمارة والعمليات
في بداية المقال ، تحدثنا عن 4 مكونات تشكل الأجهزة: القرص والذاكرة والمعالجات والشبكة. يؤثر دور العقدة في التخلص من كل من هذه المكونات. يمكن لعقدة واحدة أداء عدة أدوار في وقت واحد ، ولكن مع نمو المجموعة ، يجب توزيع هذه الأدوار عبر عقد مختلفة.
العقد الرئيسية مراقبة صحة الكتلة ككل. في عمل العقدة الرئيسية ، يجب مراعاة النصاب القانوني ، أي يجب أن يكون عددهم غريبًا (ربما 1 ، لكن أفضل 3).
عقد البيانات أداء وظائف التخزين. لزيادة أداء الكتلة ، يجب تقسيم العقد إلى
"حار" و "حار" و "بارد" (مجمّد) . الأول مخصص للوصول عبر الإنترنت ، والثاني للتخزين ، والثالث للأرشيف. وفقًا لذلك ، من المعقول استخدام محركات الأقراص SSD المحلية بالنسبة لـ "الساخنة" ، وبالنسبة لمجموعة HDD "الدافئة" و "الباردة" فهي مناسبة محليًا أو في شبكة منطقة التخزين (SAN).
لتحديد سعة التخزين للعقد للتخزين ، توصي Flex باستخدام المنطق التالي: "ساخن" → 1:30 (30 جيجابايت من مساحة القرص لكل غيغابايت من الذاكرة) ، "دافئ" → 1: 100 ، "بارد" → 1: 500). تحت
كومة JVM ، لا يزيد عن 50٪ من إجمالي الذاكرة ولا يزيد عن 30
جيجابايت لتجنب غارة جامع البيانات المهملة. سيتم استخدام الذاكرة المتبقية كذاكرة التخزين المؤقت لنظام التشغيل.
تتأثر مؤشرات أداء مثيل Elastisearch مثل
تجمعات مؤشرات
الترابط وقوائم مؤشرات
الترابط أكثر من
الاستخدام الأساسي للمعالج. يتم تشكيل الأول على أساس الإجراءات التي تنفذها العقدة: البحث والتحليل والكتابة وغيرها. والثاني هو قائمة انتظار الطلبات المقابلة من أنواع مختلفة. يتم تحديد عدد معالجات Elasticsearch المتاحة للاستخدام تلقائيًا ، ولكن يمكنك تحديد هذه القيمة يدويًا في الإعدادات (قد يكون ذلك مفيدًا عندما يكون لديك مثيلان أو أكثر من مثيلات Elasticsearch تعمل على نفس المضيف). يمكن تعيين الحد الأقصى لعدد تجمعات مؤشرات الترابط وقوائم انتظار سلسلة من كل نوع في الإعدادات. مقياس تجمعات الخيط هو مقياس الأداء الأساسي لـ Elasticsearch.
تأخذ
العقد الأكبر مدخلات من المجمعين (Logstash ، Beats ، وما إلى ذلك) ، وإجراء التحويلات عليها ، والكتابة إلى الفهرس الهدف.
الغرض من
عقد التعلم الآلي هو تحليل البيانات. كما كتبنا في
مقالة حول التعلم الآلي في Elastic Stack ، فإن الآلية مكتوبة بلغة C ++ وتعمل خارج JVM ، حيث يتدفق Elasticsearch نفسه ، لذلك فمن المعقول إجراء مثل هذه التحليلات على عقدة منفصلة.
تقبل
عُقد المنسق طلب بحث وتوجيهه. وجود هذا النوع من العقدة يسرع معالجة استعلامات البحث.
إذا أخذنا بعين الاعتبار الحمل على العقد من حيث قدرات البنية التحتية ، سيكون التوزيع شيئًا مثل هذا:
بعد ذلك ، نقدم 4 أنواع رئيسية من العمليات في Elasticsearch ، كل منها يتطلب نوعًا معينًا من الموارد.
الفهرس - معالجة وحفظ مستند في الفهرس. يوضح الرسم البياني أدناه الموارد المستخدمة في كل مرحلة.
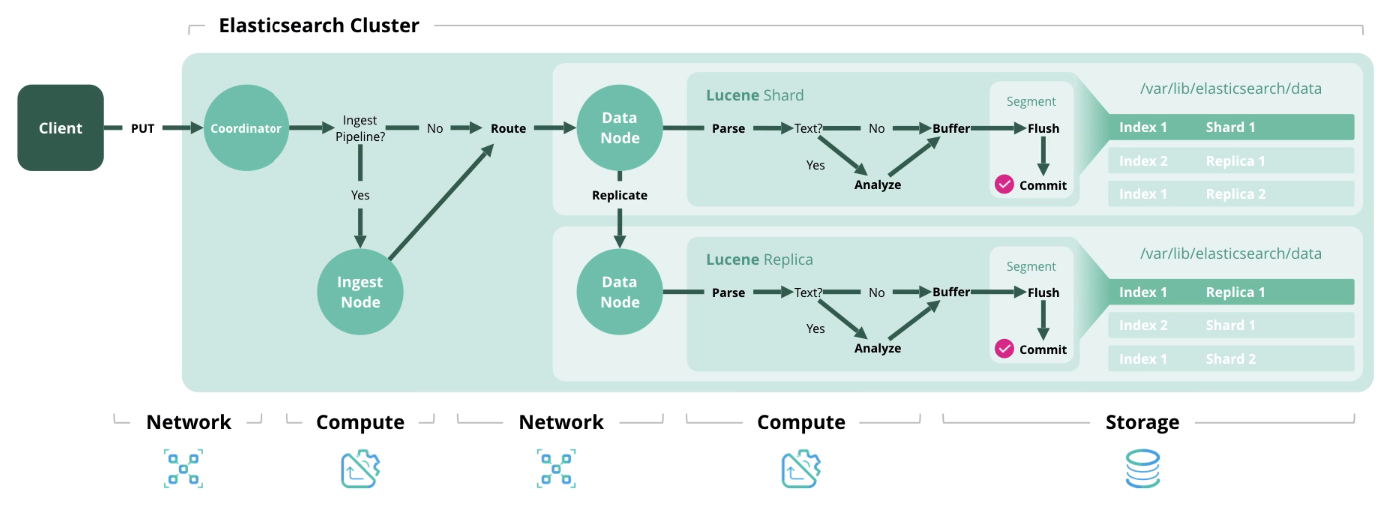 حذف
حذف - حذف مستند من الفهرس.
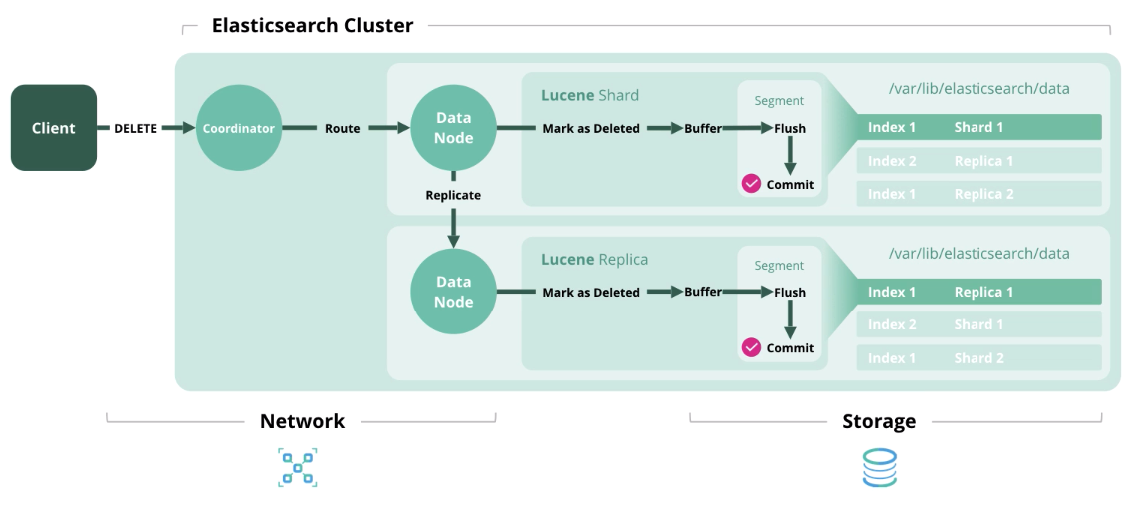 تحديث
تحديث - يعمل مثل الفهرس والحذف ، لأن المستندات في Elasticsearch غير قابلة للتغيير.
البحث - الحصول على مستند واحد أو أكثر أو تجميعها من فهرس أو أكثر.
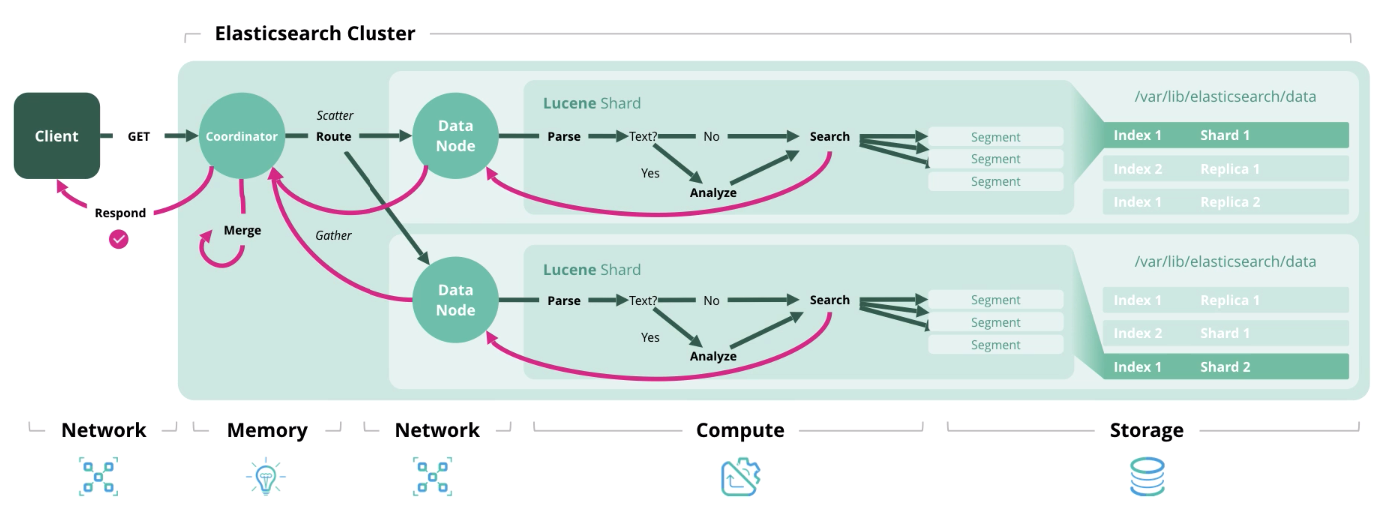
اكتشفنا بنية وأنواع الأحمال ، والآن دعنا ننتقل إلى تشكيل نموذج التحجيم.
تحجيم Elasticsearch والأسئلة قبل تشكيلها
توصي المرونة باستخدام إستراتيجيتين للتحجيم: موجه نحو التخزين والإنتاجية. في الحالة الأولى ، تعتبر موارد القرص والذاكرة ذات أهمية قصوى ، وفي الحالة الثانية ، الذاكرة وطاقة المعالج والشبكة.
التحجيم العمارة Elasticsearch على أساس حجم التخزين
قبل الحسابات ، نحصل على البيانات الأولية. الحاجة:
- كمية البيانات الخام يوميا ؛
- فترة تخزين البيانات بالأيام ؛
- عامل تحويل البيانات (عامل json + عامل الفهرسة + عامل الضغط) ؛
- عدد النسخ المتماثل
- كمية العقد بيانات الذاكرة ؛
- نسبة الذاكرة إلى البيانات (1:30 ، 1: 100 ، إلخ).
لسوء الحظ ، يتم حساب عامل تحويل البيانات بشكل تجريبي فقط ويعتمد على أشياء مختلفة: تنسيق البيانات الأولية ، وعدد الحقول في المستندات ، إلخ. لمعرفة ذلك ، تحتاج إلى تحميل جزء من بيانات الاختبار في الفهرس. حول موضوع هذه الاختبارات ، يوجد
فيديو مثير للاهتمام من المؤتمر ومناقشة في مجتمع المرونة . بشكل عام ، يمكنك ترك الأمر يساوي 1.
بشكل افتراضي ، يقوم Elasticsearch
بضغط البيانات باستخدام خوارزمية LZ4 ، ولكن هناك أيضًا DEFLATE ، والذي يضغط بنسبة 15٪ أكثر. بشكل عام ، يمكن تحقيق ضغط 20-30 ٪ ، ولكن يتم احتساب هذا أيضًا بشكل تجريبي. عند التبديل إلى خوارزمية DEFLATE ، يزداد الحمل على طاقة الحوسبة.
لا يزال هناك توصيات إضافية:
- إيداع 15 ٪ لديك احتياطي على مساحة القرص ؛
- تعهد 5 ٪ لتلبية الاحتياجات الإضافية ؛
- ضع 1 مكافئ لعقدة البيانات لضمان سرعة الترحيل.
الآن دعنا ننتقل إلى الصيغ. لا يوجد شيء معقد هنا ، ونعتقد أنه سيكون من الممتع بالنسبة لك التحقق من مجموعتك للتأكد من امتثالها لهذه التوصيات.
إجمالي كمية البيانات (GB) = البيانات الخام في اليوم * عدد أيام التخزين * عامل تحويل البيانات * (عدد النسخ المتماثلة - 1)
إجمالي تخزين البيانات (GB) = إجمالي البيانات (GB) * (مخزون 1 + 0.15 + 0.05 احتياجات إضافية)
إجمالي عدد العقد = موافق (إجمالي سعة تخزين البيانات (GB) / حجم الذاكرة لكل عقدة / نسبة الذاكرة إلى البيانات + 1 مكافئ لعقدة البيانات)
تحجيم بنية Elasticsearch لتحديد عدد القطع وعقد البيانات حسب حجم التخزين
قبل الحسابات ، نحصل على البيانات الأولية. الحاجة:
- عدد أنماط الفهرس التي ستقوم بإنشائها ؛
- عدد القطع الأساسية والنسخ المتماثلة ؛
- بعد عدد الأيام التي سيتم فيها تنفيذ دوران المؤشر ، على كل حال ؛
- عدد الأيام لتخزين المؤشرات ؛
- مقدار الذاكرة لكل عقدة.
لا يزال هناك توصيات إضافية:
- لا تتجاوز 20 قطعة لكل 1 جيجابايت من JVM على كل عقدة ؛
- لا تتجاوز 40 غيغابايت من مساحة القرص شارد.
الصيغ هي كما يلي:
عدد القطع = عدد أنماط الفهرس * عدد القطع الرئيسية * (عدد القطع المكررة + 1) * عدد أيام التخزين
عدد نقاط البيانات = موافق (عدد القطع / (20 * ذاكرة لكل عقدة))
التحجيم عرض النطاق الترددي Elasticsearch
الحالة الأكثر شيوعًا عند الحاجة إلى النطاق الترددي العالي متكررة وفي استعلامات البحث بأعداد كبيرة.
البيانات الأولية اللازمة للحساب:
- عمليات البحث عن الذروة في الثانية ؛
- متوسط زمن الاستجابة المسموح بالمللي ثانية ؛
- عدد المراكز والخيوط الأساسية لكل معالج على عقد البيانات.
قيمة مؤشرات الترابط القصوى = OK UP (الحد الأقصى لعدد استعلامات البحث في الثانية * متوسط الوقت اللازم للرد على استعلام البحث بالمللي ثانية / 1000 ميلي ثانية)
تجمع مؤشر ترابط وحدة التخزين = OKRUP ((عدد النوى المادية لكل عقدة * عدد سلاسل العمليات لكل نواة * 3/2) +1)
عدد نقاط البيانات = موافق (قيمة مؤشر ترابط الذروة / حجم تجمع مؤشرات الترابط)
ربما لن تكون جميع البيانات الأولية بين يديك عند تصميم الهيكل ، ولكن بعد النظر في
الندوة عبر الإنترنت أو قراءة هذه المقالة ، سيظهر فهم أنه من حيث المبدأ يؤثر على مقدار موارد الأجهزة.
يرجى ملاحظة أنه ليس من الضروري الالتزام بالهندسة المعطاة (على سبيل المثال ، إنشاء عقد تنسيق إحداثية وعقد معالج). يكفي أن تعرف أن مثل هذه البنية المرجعية موجودة ويمكن أن تقدم دفعة أداء لا يمكنك تحقيقها بوسائل أخرى.
في أحد المقالات التالية ، سننشر قائمة كاملة من الأسئلة التي تحتاج إلى إجابة لتحديد حجم الكتلة.
للاتصال بنا ، يمكنك استخدام الرسائل الشخصية على Habré أو
نموذج الملاحظات على الموقع .
مواد إضافيةالويبينار "تحجيم Elasticsearch وتخطيط القدرات"ندوة تخطيط القدراتخطاب في ElasticON مع موضوع "التحجيم الكمي الكتلة"ندوة حول Rally الأداة المساعدة لتحديد مؤشرات أداء الكتلةتحجيم Elasticsearch المادةندوة كومة مرنة