مرحبا بالجميع! اسمي Lyudmila ، أنا منخرط في اختبار الحمل ، أريد أن أشارك كيف أجرينا أتمتة التحليل المقارن لملف تعريف الانحدار لنظام اختبار الحمل من قاعدة بيانات Oracle DBMS مع أحد عملائنا.
ليس الغرض من هذه المقالة اكتشاف نهج "جديد" لمقارنة أداء قاعدة البيانات ، ولكن لوصف تجربتنا ومحاولة أتمتة مقارنة النتائج التي تم الحصول عليها و
تقليل عدد المكالمات إلى DBA Oracle.
عند إجراء اختبار تحميل أي قاعدة بيانات ، نحن مهتمون في المقام الأول بما يلي:
- هل حدث شيء ما بعد تثبيت مجموعة جديدة؟
- ديناميات قاعدة البيانات أثناء الاختبار.
مقارنة تقارير AWR وحدها ليست كافية لتحقيق أهدافك.
التخزين المركزي لمقالب AWR هو أيضا ممارسة جيدة. تحتفظ مقالب AWR بجميع المشاهدات التاريخية (dba_hist).
تم بالفعل تطبيق هذه الممارسة من قبل عملائنا.
بعد الجلسة التالية لاختبار الحمل ، قارنا النتائج:
- تفريغ اختبار الحالي مع تفريغ الصناعي.
- تفريغ الاختبار الحالي مع تفريغ الاختبار السابق.
لماذا هذا مطلوب؟
الأهداف مختلفة:
- في بعض الأحيان ، يختلف ملء القاعدة نفسها في بيئة اختبار عن البيئة التشغيلية ، مما يعني أنه ستكون هناك اختلافات تتداخل مع التحليل ("التدخل" للإجابة على السؤال الرئيسي ، "هل تم كسر شيء؟"). اريد التعرف على هذه الاختلافات
- تساعد مقارنة الاختبار الحالي مع عمل القاعدة الصناعية على فهم مدى صحة اختبارات الإجهاد الحالية (في مكان نحمله أكثر من اللازم ، لكننا نسينا شيئًا على الإطلاق) ؛
- تساعد مقارنة الاختبار الحالي مع الاختبار السابق على فهم ما إذا كان سلوك النظام الحالي أمرًا طبيعيًا. هل تغير أي شيء في سلوك النظام مقارنة مع الاختبار السابق.
لتحقيق كل هذه الأهداف ، فإننا في كثير من الأحيان حل مشكلة مقارنة مقالب مختلفة بين بعضها البعض. عادة ما تكون التواريخ ضيقة جدًا عندما كان من المفترض أن يتم تقديمها بالأمس! الوقت للتحقق بشكل كامل من كل اختبار الانحدار يفتقر إلى حد كبير. وإذا قمت بإجراء اختبار الموثوقية ليوم واحد ، فيمكنك قضاء الكثير من الوقت في تحليل النتيجة ...
بالطبع ، يمكنك مشاهدة كل شيء عبر الإنترنت في Enterprise Manager (أو مع طلبات الحصول على آراء gv $) أثناء الاختبار: لا تذهب إلى التدخين ، وتناول الطعام والنوم ...

ربما لديك أيضا أداة مخصصة خاصة بك ، مصنوعة لنفسك؟ يمكنك مشاركة في التعليقات. وسوف نشارك ما نستخدمه لمهامنا.
تقارير AWR لديها الكثير من المعلومات المفيدة:

هناك معلومات مفيدة هنا ، على سبيل المثال: مقدار تنفيذ الاستعلام ، sql_id ، الوحدة النمطية والنص المختص. على الرغم من وجود النص ، يتم اقتطاعه ويمكن الحصول على النسخة الكاملة من الفقرة Complete List of SQL Text.
بالنسبة إلى السلبيات: في تقرير AWR ، ليس من الواضح متى حدثت هذه الطلبات ، وفي أي وقت كان هناك أكثر ، وفي أي أقل ... بعد كل شيء ، لتحليل نتائج الاختبار ، وفهم ما حدث وفي أي لحظة تقريبًا مهمة: بالتساوي للجميع اختبار أو ذروة / زيادة كما لو كان في جدول. سنرى أيضًا قمة محدودة هنا. يمكن عرض ذلك بسهولة أكبر عن طريق الاستعلام عن الجداول التاريخية.
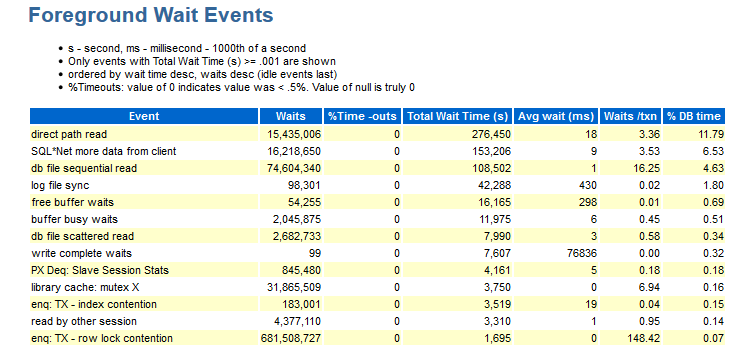
هنا يمكنك رؤية الأحداث التي وقعت أثناء الاختبار. يتم ترتيب البيانات في هذا القسم حسب وقت DB.
بالنسبة لي ، المعلومات التالية مفقودة في هذا القسم:
- Wait_class (نعم ، تتذكر بخبرة نوع التوقعات التي ينتمي إليها هذا الحدث).
- توزيعات حسب الوحدات (إذا رأيت ، على سبيل المثال ، في انتظار enq: TX - تنازع في قفل الصف: هناك حاجة إلى المعلومات ، وبموجب هذه الوحدة حدث هذا).
هناك وظائف لا توجد فيها أرقام تحمل جزءًا دلاليًا ، أي أنك بحاجة إلى تجميع الوحدات النمطية نفسها والحصول على إجابة للمجموعة ، على سبيل المثال: module_A_1 و module_A_2 و module_A_3 و module_B_1 و module_B_1 و module_B_2 و module_ B_3. وهذا هو ، كان هناك اثنين من وحدات الدلالية ، ولكن لديهم أسماء مختلفة.
- الكائن الذي نشير إليه (CURRENT_OBJ # - إذا حدث ، على سبيل المثال ، enq: TX - index contention ، فسيكون من الجيد معرفة الفهرس الذي يجب إلقاء اللوم عليه).
- Sql_id - الذي طلب نص هذا الطلب حاول تنفيذ.
- معلومات حول توزيع الكميات لكل لقطة (كما هو موضح أعلاه ...).
لمقارنة الاختبارين ، يمكنك استخدام مقارنة تقارير AWR:
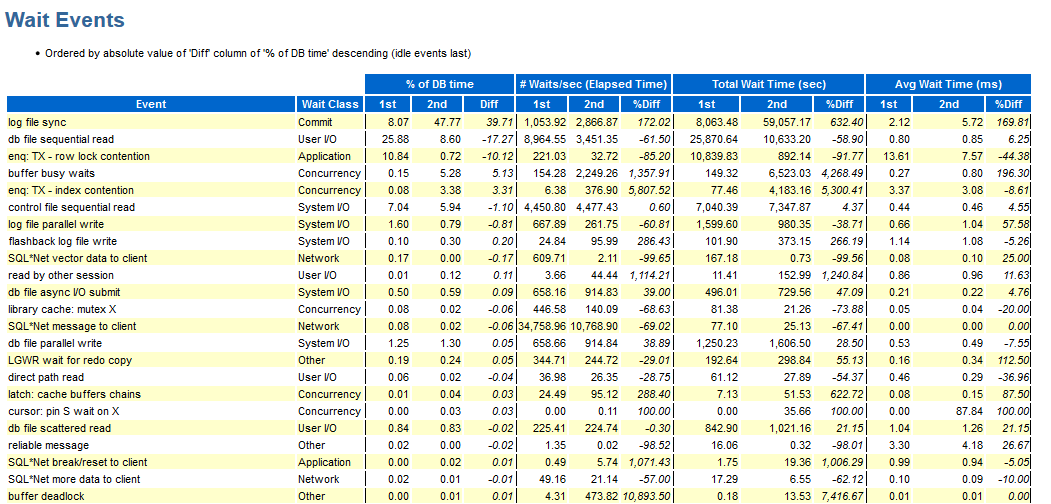
الصيحة ، هنا لدينا wait_class معروضة ؛ وإلا فإن السلبيات هي نفسها كما هو موضح أعلاه.
في بعض الأحيان لا يوجد Enterprise Manager في المشروعات ، ويمكنك على سبيل المثال استخدام Enterprise Manager Express أو ASH Viewer. في Enterprise Manager ، يستخدم العديد من الأشخاص "Top Activity" للبيانات التاريخية ، لكن بالنسبة لي ، من السهل النظر إلى العديد من الأشياء مع الاستعلامات. يجب مقارنة كل ما سبق مع اختبارات أخرى / عبء العمل. كان لدينا بالفعل مقارنة مخصصة من حيث وقت التشغيل ، ولكن لم يكن لدينا مقارنة مخصصة ، وقمنا بالتحقق يدويًا من خلال الاستعلامات على الجداول التاريخية.
بعد كل اختبار انحدار ، كان من الضروري مقارنة النتائج في الجداول التاريخية مع الاستعلامات إلى قاعدة البيانات ، وعرض تقارير AWR ، وتوطين التوقع الإشكالي (على أي وحدة نمطية تحدث ، في أي وقت ، ما هو الشيء الذي تم تعليقه عليه) ، بحيث يمكن إنشاء خطأ لفريق التطوير المناسب.
وصلت قاعدة بيانات العميل إلى 190 تيرابايت ، ويتم معالجة عدد كبير من الطلبات في النظام: عدد الوحدات الموازية هو 16237.
ثم كان لدي فكرة عن كيفية تبسيط عملية مقارنة مقالب AWR. مع هذه الفكرة ، ذهبت إلى
فريد . معا ، أنشأنا بوابة مريحة.
في البداية ، بدا بيان المشكلة مني كما يلي:

بعد ذلك ، ومع ذلك ، فقد قررت أن أبدأ بشكل منهجي في ما يتعلق بالاستعلامات إلى الجداول التاريخية التي أستخدمها غالبًا ... بدأ فريد في ربط ذلك بالبوابة وبعد ذلك بدأ ...
بادئ ذي بدء ، كنت مهتمًا بمقارنة الأحداث ، نظرًا لوجود مقارنة بين سرعة تنفيذ الاستعلام بشكل أو بآخر. الخطوة التالية كنت بحاجة إلى معلومات مفصلة حول كل حدث: على سبيل المثال ، إذا كان الحدث هو خلاف حول الفهرس ، فأنت بحاجة إلى فهم الفهرس الذي نعلقه بالفعل.
ثم كنت مهتمًا بالوقت الذي كانت فيه لحظات هذه الأحداث أكثر من غيره ، حيث كان هناك العديد من المهام (الوظائف) التي تم تحديدها أثناء التنفيذ وكان من الضروري أن نفهم في أي وقت كان كل شيء يتفكك في طبقات.
بشكل عام ، إليك ما أردت الحصول عليه:
- مقارنة كمية للأحداث بين الاختبارات المختلفة (بدون القرفصاء إضافية) ؛
- جميع المعلومات ذات الصلة التي أحتاج إلى تحليلها: sql_id ، نص الاستعلام ، التوزيع أثناء الاختبار ، والذي يعترض على الجلسات المشار إليها ، الوحدة النمطية ؛
- مرشحات مريحة لنفسك لمعرفة ما تغير.
- واجهة المستخدم الرسومية ، كل شيء غني بالألوان لدرجة أنه مرئي على الفور (يمكنك فحص الأطراف المهتمة من جانب التطوير)
- تجميع الوحدات النمطية: كما هو موضح سابقًا ، 16237 وحدة ، ولكن ، من وجهة نظر الوظائف التي يتم تنفيذها ، عدة مرات أقل.
لقد صممنا أنا و فريد بوابة لاستخدامنا لمقارنة مقالب AWR لاختبار الحمل ، والتي سأناقشها بمزيد من التفصيل أدناه.
عن البوابة
لذلك ، يتم إنشاء مقالب AWR في النظام ، والتي يتم سكبها في قاعدة البيانات ومقارنتها على البوابة.
استخدمنا المكدس التالي:
- أوراكل DB - لتخزين مقالب AWR
- بيثون 2+
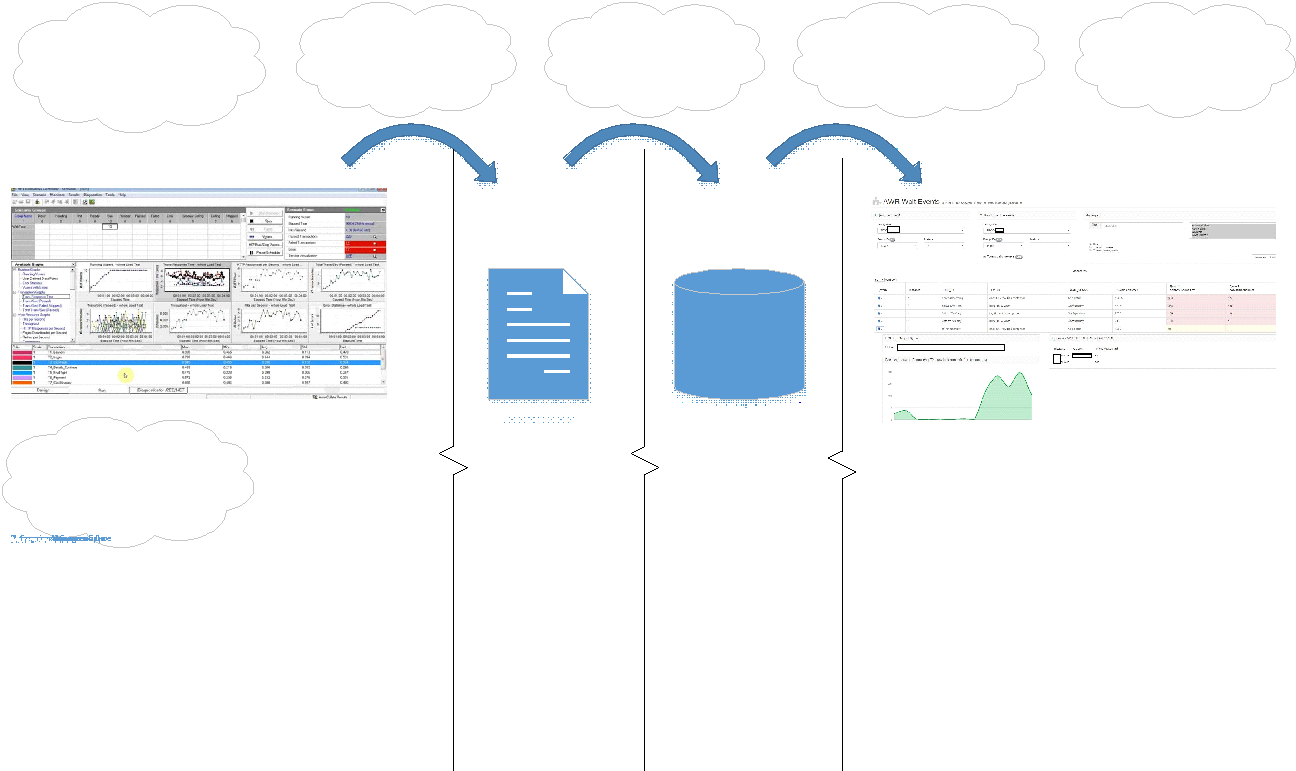
تبدو واجهة المدخل كما يلي:

على المدخل ، يمكنك اختيار أنواع مقالب المقارنة أو اختبار الاختبار أو اختبار prom.
كل تفريغ له معرف فريد خاص به - DBID.
يمكنك أيضًا التصفية حسب المعلمات التالية:
- مثيل (مثيل) - كان لدينا قاعدة بيانات كتلة.
- طلب (Sql_id) ؛
- نوع الانتظار (Wait_Class) ؛
- الحدث (الحدث).
في الجزء العلوي الأيسر ، يمكنك تحديد dumps ، وعلى اليمين يمكنك تعيين المرشحات اللازمة لتحديد الوحدة المطلوبة على الفور - وهذا يتيح لك تحديد المشاكل في الوظيفة التي تم تغييرها / تحسينها بحيث لا توجد مشاكل في التدهور في الإصدار السابق.
الجدول في الوسط هو نتيجة لمقارنة مقالب النفايات. تُظهر عناوين الأعمدة على الفور البيانات التي يتم إخراجها. يُظهر العمودين الأيمن الاختلافات بين المقالبتين:
- الأحداث المظللة باللون الأحمر أكثر من المقارنة مع تفريغ مقارن للقطعة ؛
- أحداث صفراء جديدة
- الأخضر - الأحداث التي كانت بالفعل في التفريغ الأصلي.
من الواضح على الفور مدى حسن اختبارنا. إذا حدث الحدث في كثير من الأحيان ، فعلى الأرجح:
- طاقتها النظام ؛
- أو تم تغيير شروط تنفيذ وظائف الخلفية وبدأ الحدث يلعب أكثر من مرة. مرة واحدة بهذه الطريقة ، تم العثور على خطأ في الكود: حدث باستمرار ، وليس على فرع الشرط المطلوب.
إذا كان لدينا حدث جديد - أصفر - فهذا يشير إلى نوع من التغيير في النظام ، ونحن بحاجة إلى تحليل عواقبه. يمكنك هنا مشاهدة توزيع الأحداث حسب اللقطات وعرض معلومات مفصلة حول الانتظار.
ما إن كانت هناك حالة: تم اكتشاف حدث جديد ، والذي كان نادرًا جدًا ولم يتم تضمينه في الأحداث الكبرى ، ولكن بسببه كانت هناك تباطؤات في الوظائف ، والتي كانت فيها اتفاقيات مستوى الخدمة حرجة. تحليل الاستعلامات العليا فقط في تقرير AWR لا يمكن أن يكشف عن هذا.
لكل طلب ، يمكنك الحصول على معلومات أكثر تفصيلاً:
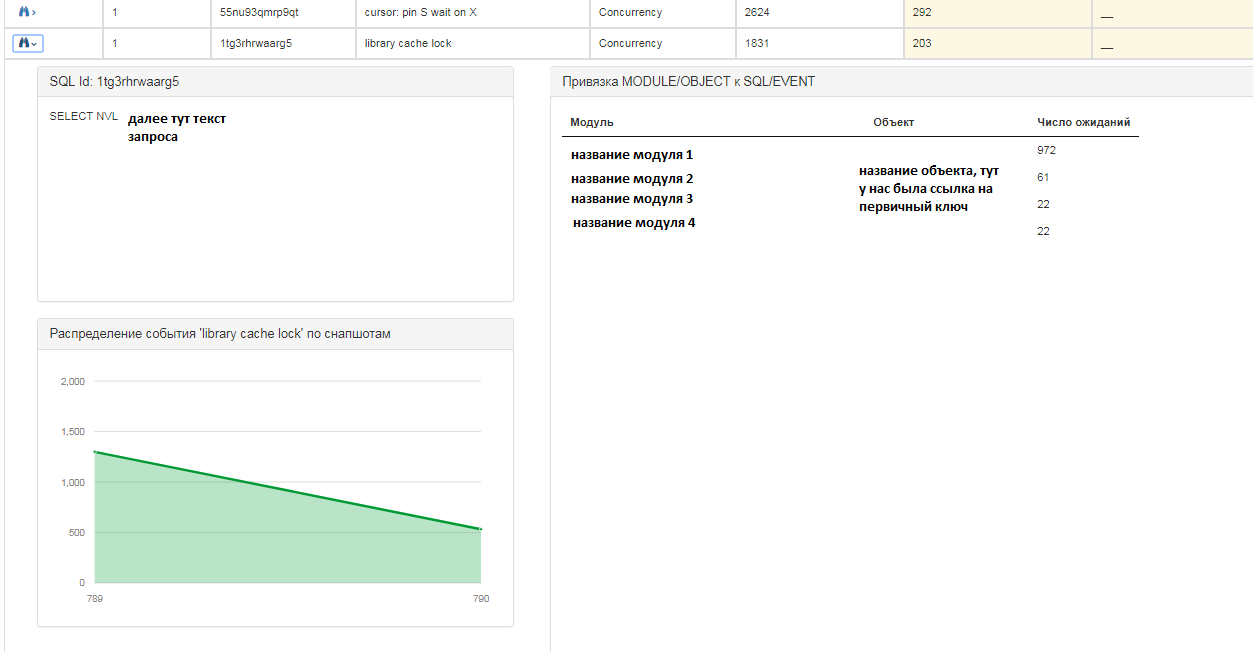
لكل إدخال ، يمكنك أيضًا رؤية المعلومات التالية:
- نص sql الاستعلام؛
- توزيع الأحداث على لقطة في نسبة كمية ، أي في أي وقت كانت هناك أحداث أكثر / أقل ؛
- التي وحدات والأشياء "معلقة" الانتظار.
تشارك طرق عرض نظام أوراكل في مقارنة النتائج:
DBA_HIST_ACTIVE_SESS_HISTORY ، DBA_HIST_SEG_STAT ، DBA_HIST_SNAPSHOT ، DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED - جدول الخدمة الخاص به (تم تنفيذه بالفعل من قبل العميل) ، ويحتوي على معلومات حول مقالب التحميل المحملة.
بعض الاستعلامات:
توزيع الأحداث على الصور:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
التجميع حسب الوحدة النمطية (يتم دمج الوحدات النمطية التي تمثل مجموعة منطقية واحدة فيها) ، ويتم حظر الكائن:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
ماذا حصلت في النهاية؟
أتاحت لنا البوابة توفير وقت مقارنة مقالب AWR. استغرقت المقارنة اليدوية 4-6 ساعات ، ونحن الآن نقضي 2-3 ساعات. لدينا دائمًا الفرصة المتاحة لمقارنة نتائج الاختبارات المختلفة بسرعة فيما بينها ومع تفريغ صناعي ، وكذلك تعيين المرشحات التي نحتاجها الآن. وهذا يعني أنه يمكننا بسهولة مقارنة البيانات التاريخية بيننا ، وليس فقط مشاهدة النتيجة الحالية عبر الإنترنت.
في السابق ، بعد كل انحدار ، كان من الضروري مقارنة النتائج في الجداول التاريخية مع الاستعلامات إلى قاعدة البيانات ، وعرض تقارير AWR ، وتوطين التوقع الإشكالي (على أي وحدة نمطية تحدث ، وما هي أوقات حدوثها ، وما يعترض عليها) ، بحيث يمكن أن تؤدي في النهاية إلى حدوث خلل في فريق التطوير الصحيح. والآن فقط حدد مقالب للمقارنة ، قم بتعيين المرشحات - وستكون نتائج المقارنة جاهزة فورًا. يمكنك أيضًا إرسال رابط للمطورين إلى البوابة يشير إلى معرف قاعدة بيانات التفريغ (DBID) لتفريغ الاختبار ، وسيتم ترشيحهم بأنفسهم بواسطة الوحدة النمطية الخاصة بهم.
استغرق إنشاء المدخل أسبوعين فقط ، لأن جزءًا منه كان جاهزًا بالفعل: تحميل مقالب في قاعدة البيانات. بالطبع ، لا يلزم مثل هذا الحل المدخل لأي مشروع له قاعدة Oracle. إنه مفيد للمنتجات التي تنقسم إلى وحدات متعددة بأسماء مختلفة. بالنسبة للأنظمة البسيطة أو للأنظمة التي لم تعلق عليها أهمية لملء الوحدة ، ستكون البوابة زائدة عن الحاجة.
نظرًا لأن المدخل يحلل الصور التي يتم التقاطها مرة واحدة في فترة معينة ، فإن البوابة لا تعفي تمامًا من المراقبة عبر الإنترنت لقاعدة البيانات ، حيث قد لا تتمكن بعض الأحداث من الوصول إلى الصورة.
هذه أداة مناسبة لتحليل البيانات التاريخية من نتائج الاختبار ، ولكنها قد تكون مفيدة في مواقف أخرى عندما يتم إنشاء الكثير من الصور وتحتاج إلى فحص كميات كبيرة من البيانات. بفضل مزيج من المرشحات والرسوم البيانية ، يمكنك أن ترى على الفور رشقات من الأحداث في تقارير AWR العادية (لا يجب الخلط بينها وبين مقالب) ستكون مخفية في المعلومات المجمعة. يكفي تحديد مقالب للمقارنة ، وضبط المرشحات - وتكون نتائج المقارنة جاهزة فورًا ، أو يمكنك إرسال رابط للمطورين على موقع البوابة يشير إلى DBID لتفريغ الاختبار ، سيتم تصفيتهم بواسطة الوحدة النمطية الخاصة بهم.
إذا قررت تطوير مدخل مشابه لمشروعك ، فحدد مجموعة المرشحات المناسبة لك. إذا قمت بالتصفية وفقًا لظروف مختلفة في كل مرة ، فسيكون من الأسهل بكثير إنشاء فلتر مناسب لذلك.
لا يزال من الممكن الانتهاء من الحل الناتج ، على سبيل المثال:
- مقارنة مدة الطلب ؛
- مقارنة خطط الاستعلام ؛
- مقارنة الطلبات مع نفس الخطة ، ولكن بنص مختلف ؛
- التفريغ في تقارير الاختبار (التنفيذ كمستند Word / Exel).
أو ، بشكل عام ، أخبر المدخل بالاتصال بقاعدة البيانات المختبرة بحيث يقوم بإنشاء صور مماثلة عبر الإنترنت باستخدام طرق عرض في الذاكرة وليس فقط بيانات تاريخية. وحفظها في قاعدة البيانات الخاصة بك.
لقد تم استخدام البوابة لأكثر من عام. فريد ، شكرا جزيلا لك!
كتب بواسطة لودميلا ماتسكوس ،
جت انفورمز