مرحبا يا هبر. في هذه المقالة ، سنتعامل مع معادلة Navier-Stokes لسائل غير قابل للضغط ، ونحلها رقميًا ، ونجري محاكاة جميلة تعمل عن طريق الحوسبة المتوازية على CUDA. الهدف الرئيسي هو إظهار كيف يمكنك تطبيق الرياضيات التي تقوم عليها المعادلة في الممارسة العملية عند حل مشكلة نمذجة السوائل والغازات.

تحذيرتحتوي المقالة على الكثير من الرياضيات ، لذلك يمكن للراغبين في الجانب الفني من المشكلة الانتقال مباشرةً إلى قسم التنفيذ في الخوارزمية. ومع ذلك ، ما زلت أوصي بأن تقرأ المقالة بأكملها وتحاول فهم مبدأ الحل. إذا كانت لديك أية أسئلة بنهاية القراءة ، فسيسعدني أن أجيب عليها في التعليقات على المنشور.
ملاحظة: إذا كنت تقرأ حبر من جهاز محمول ، ولم تشاهد الصيغ ، فاستخدم النسخة الكاملة للموقعمعادلة Navier-Stokes لسائل غير قابل للضغط
جزئية bf vecu أكثرمن جزئيةt=−( bf vecu cdot nabla) bf vecu−1 over rho nabla bfp+ nu nabla2 bf vecu+ bf vecF
أعتقد أن الجميع قد سمعوا مرة واحدة على الأقل عن هذه المعادلة ، بعضها ، وربما حلها بشكل تحليلي في حالاتها الخاصة ، لكن بشكل عام ، تظل هذه المشكلة دون حل حتى الآن. بالطبع ، نحن لا نضع هدفًا لحل مشكلة الألفية في هذه المقالة ، ومع ذلك لا يزال بإمكاننا تطبيق الطريقة التكرارية عليها. ولكن بالنسبة للمبتدئين ، دعونا ننظر إلى التدوين في هذه الصيغة.
تقليديًا ، يمكن تقسيم معادلة Navier-Stokes إلى خمسة أجزاء:
- جزئية bf vecu over جزئيةt - يدل على معدل التغير في سرعة المائع عند نقطة (سننظر في كل جسيم في محاكاة لدينا).
- −( bf vecu cdot nabla) bf vecu - حركة السوائل في الفضاء.
- −1 over rho nabla bfp هو الضغط الذي يمارس على الجسيمات (هنا rho - معامل كثافة السوائل).
- nu nabla2 bf vecu - لزوجة الوسيط (كلما زاد حجمها ، كلما كان السائل يقاوم القوة المطبقة من جانبه) ، nu - معامل اللزوجة).
- bf vecF - القوى الخارجية التي نطبقها على السائل (في حالتنا ، ستلعب القوة دورًا محددًا للغاية - ستعكس الإجراءات التي يقوم بها المستخدم.
أيضًا ، نظرًا إلى أننا سننظر في حالة سائل غير متجانس وغير قابل للضغط ، لدينا معادلة أخرى:
nabla cdot bf vecu=0 . الطاقة في البيئة ثابتة ، لا تذهب إلى أي مكان ، لا تأتي من أي مكان.
سيكون من الخطأ حرمان جميع القراء الذين لم يكونوا على دراية
بتحليل المتجهات ، وبالتالي ، في نفس الوقت ، واستعرض باختصار جميع المشغلين الموجودين في المعادلة (ومع ذلك ، فإنني أوصي بشدة بتذكير ما هو المشتق والتفاضلي والمتجه ، لأنهم يرتكزون على كل ذلك ما سوف تناقش أدناه).
نبدأ بمشغل nabla ، الذي يمثل ناقلًا (في حالتنا ، سيكون مكونًا من عنصرين ، نظرًا لأننا سنقوم بنمذجة السائل في الفضاء ثنائي الأبعاد):
nabla= تبدأpmatrix جزئية فوق جزئيةx، جزئية فوق جزئيةy endpmatrix
عامل nabla هو
عامل تفاضلي متجه ويمكن تطبيقه على كل من دالة العددية وعلى متجه واحد. في حالة العددية ، نحصل على التدرج اللوني للوظيفة (متجه مشتقاته الجزئية) ، وفي حالة المتجه ، مجموع المشتقات الجزئية على طول المحاور. الميزة الرئيسية لهذا المشغل هي أنه من خلاله يمكنك التعبير عن العمليات الرئيسية لتحليل المتجهات -
grad (
gradient ) ،
div (
divergence ) ،
rot (
rototor ) و
nabla2 (
مشغل لابلاس ). تجدر الإشارة على الفور إلى أن التعبير
( bf vecu cdot nabla) bf vecu لا يرقى إلى ( nabla cdot bf vecu) bf vecu - عامل nabla لا يملك تبديلية.
كما سنرى لاحقًا ، يتم تبسيط هذه التعبيرات بشكل ملحوظ عند الانتقال إلى مساحة منفصلة سننفذ فيها جميع الحسابات ، لذلك لا تنزعج إذا لم تكن واضحًا في الوقت الحالي بشأن ما يجب القيام به مع كل هذا. بعد تقسيم المهمة إلى عدة أجزاء ، سنحل كل منها على التوالي ونعرض كل ذلك في شكل تطبيق متتابع لعدة وظائف على بيئتنا.
الحل العددي لمعادلة Navier-Stokes
لتمثيل سائلنا في البرنامج ، نحتاج إلى الحصول على تمثيل رياضي لحالة كل جسيم سائل في وقت تعسفي. الطريقة الأكثر ملاءمة لذلك هي إنشاء حقل متجه من الجزيئات يخزن حالته في شكل مستوي إحداثي:

في كل خلية من صفيفنا ثنائي الأبعاد ، سنخزن سرعة الجسيمات في وقت واحد
t: bf vecu=u( bf vecx،t)، bf vecx= تبدأpmatrixx،y endpmatrix ، والمسافة بين الجزيئات هي التي يرمز لها
دلتا× و
دلتاذ على التوالي. في الكود ، سيكون كافياً بالنسبة لنا تغيير قيمة السرعة لكل تكرار ، وحل مجموعة من المعادلات المتعددة.
الآن نعبر عن التدرج والانحراف ومشغل لابلاس مع مراعاة شبكة الإحداثيات لدينا (
i،j - المؤشرات في الصفيف ،
bf vecu(x)، vecu(y) - أخذ المكونات المقابلة من المتجه):
يمكننا تبسيط الصيغ المنفصلة لمشغلي المتجهات إذا افترضنا ذلك
deltax= deltay=1 . لن يؤثر هذا الافتراض بشكل كبير على دقة الخوارزمية ، ومع ذلك ، فهو يقلل من عدد العمليات لكل تكرار ، ويجعل التعبيرات بشكل عام أكثر متعة للعين.
حركة الجسيمات
هذه العبارات لا تعمل إلا إذا تمكنا من العثور على أقرب الجسيمات بالنسبة للجسيم قيد الدراسة في الوقت الحالي. من أجل إلغاء جميع التكاليف المحتملة المرتبطة بالعثور عليها ، فإننا لن نتتبع حركتها ، ولكن من
أين تأتي الجزيئات في بداية التكرار من خلال إسقاط مسار الحركة للخلف في الوقت المناسب (وبعبارة أخرى ، قم بطرح متجه السرعة مرات تغيير الوقت من الموقف الحالي). باستخدام هذه التقنية لكل عنصر من عناصر المصفوفة ، سنكون متأكدين من أن أي جسيم سيكون له "جيران":
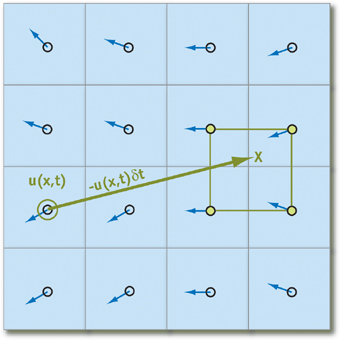
وضع ذلك
فدولا - عنصر صفيف يخزن حالة الجسيمات ، نحصل على الصيغة التالية لحساب حالتها بمرور الوقت
دلتار (نعتقد أن جميع المعلمات اللازمة في شكل التسارع والضغط قد تم حسابها بالفعل):
q( vec bfx،t+ deltat)=q( bf vecx− bf vecu deltat،t)
نلاحظ على الفور أنه صغير بما فيه الكفاية
دلتار ولا يمكننا أبدًا تجاوز حدود الخلية ، لذلك من المهم جدًا اختيار الزخم المناسب الذي سيعطيه المستخدم للجزيئات.
من أجل تجنب فقدان الدقة في حالة حدوث إسقاط في حدود الخلية أو في حالة إحداثيات غير عدد صحيح ، سنقوم بإجراء استيفاء خطي مزدوج لحالات الجسيمات الأقرب الأربعة ونأخذها كقيمة حقيقية في هذه النقطة. من حيث المبدأ ، لن تقلل مثل هذه الطريقة من الناحية العملية من دقة المحاكاة ، وفي نفس الوقت يكون التنفيذ بسيطًا للغاية ، لذلك سنستخدمها.
لزوجة
كل سائل له لزوجة معينة ، والقدرة على منع تأثير القوى الخارجية على أجزائه (العسل والماء سيكونان مثالاً جيدًا ، وفي بعض الحالات تختلف معاملات اللزوجة حسب الحجم). تؤثر اللزوجة بشكل مباشر على التسارع الذي يكتسبه السائل ، ويمكن التعبير عنه بالصيغة أدناه ، إذا كنا نختصر المصطلحات الأخرى لفترة قصيرة:
جزئية vec bfu over جزئيةt= nu nabla2 bf vecu
. في هذه الحالة ، تأخذ المعادلة التكرارية للسرعة بالشكل التالي:
u( bf vecx،t+ deltat)=u( bf vecx،t)+ nu deltat nabla2 bf vecu
سوف نقوم بتحويل هذه المساواة قليلاً ، ونصل بها إلى الشكل
bfA vecx= vecb (النموذج القياسي لنظام المعادلات الخطية):
( bfI− nu deltat nabla2)u( bf vecx،t+ deltat)=u( bf vecx،t)
حيث
bfI هي مصفوفة الهوية. نحن بحاجة إلى مثل هذه التحولات من أجل تطبيق
طريقة جاكوبي فيما بعد لحل عدة أنظمة مماثلة للمعادلات. سنناقشها لاحقًا.
قوى خارجية
أبسط خطوة في الخوارزمية هي تطبيق القوى الخارجية على الوسيط. بالنسبة للمستخدم ، سينعكس هذا في شكل نقرات على الشاشة باستخدام الماوس أو حركته. يمكن وصف القوة الخارجية بالمعادلة التالية ، والتي نطبقها على كل عنصر من عناصر المصفوفة (
vec bfG - متجه الزخم
xp،yp - موقف الماوس
x،y - إحداثيات الخلية الحالية ،
ص - نصف قطر العمل ، معلمة القياس):
vec bfF= vec bfG deltat bfexp left(−(x−xp)2+(y−yp)2 overr اليمين)
يمكن حساب متجه النبض بسهولة كالفرق بين الموضع السابق للماوس والموضع الحالي (إذا كان هناك واحد) ، وهنا لا يزال بإمكانك أن تكون مبدعًا. في هذا الجزء من الخوارزمية يمكننا تقديم إضافة الألوان إلى سائل ، وإضاءة ، وما إلى ذلك. يمكن أن تشمل القوى الخارجية أيضًا الجاذبية ودرجة الحرارة ، وعلى الرغم من أنه ليس من الصعب تنفيذ مثل هذه المعلمات ، إلا أننا لن نعتبرها في هذه المقالة.
الضغط
الضغط في معادلة Navier-Stokes هو القوة التي تمنع الجزيئات من ملء كل المساحة المتاحة لها بعد تطبيق أي قوة خارجية عليها. على الفور ، حسابها صعب للغاية ، ولكن يمكن تبسيط مشكلتنا إلى حد كبير من خلال تطبيق
نظرية تحلل Helmholtz .
ونحن ندعو
bf vecW مجال مكافحة ناقلات التي تم الحصول عليها بعد حساب النزوح والقوى الخارجية واللزوجة. سيكون هناك تباعد غير صفري ، مما يتناقض مع حالة عدم انضغاط السائل (
nabla cdot bf vecu=0 ) ، ولإصلاح ذلك ، من الضروري حساب الضغط. وفقًا لنظرية تحلل هلمهولتز ،
bf vecW يمكن تمثيله كمجموع مجالين:
bf vecW= vecu+ nablap
حيث
bfu - هذا هو مجال مكافحة ناقلات الذي نبحث عنه مع اختلاف التباعد. لن يتم تقديم أي دليل على هذه المساواة في هذه المقالة ، ولكن في النهاية يمكنك العثور على رابط مع شرح مفصل. يمكننا تطبيق عامل nabla على كلا جانبي التعبير للحصول على الصيغة التالية لحساب مجال ضغط العدد:
nabla cdot bf vecW= nabla cdot( vecu+ nablap)= nabla cdot vecu+ nabla2p= nabla2p
التعبير المكتوب أعلاه هو
معادلة بواسون للضغط. يمكننا أيضًا حلها عن طريق طريقة Jacobi المذكورة آنفًا ، وبالتالي نجد آخر متغير غير معروف في معادلة Navier-Stokes. من حيث المبدأ ، يمكن حل أنظمة المعادلات الخطية بعدة طرق مختلفة ومعقدة ، لكننا سنظل نتناول أبسطها ، حتى لا نثقل كاهل هذه المقالة.
الشروط الحدودية و الأولية
تتطلب أي معادلة تفاضلية تم تصميمها على نطاق محدود شروطًا أولية أو حدودية محددة بشكل صحيح ، وإلا فمن المحتمل جدًا أن نحصل على نتيجة غير صحيحة جسديًا. يتم تحديد شروط الحدود للتحكم في سلوك المائع بالقرب من حواف شبكة الإحداثيات ، وتحدد الشروط الأولية المعلمات التي لدى الجسيمات في وقت بدء البرنامج.
ستكون الشروط الأولية بسيطة للغاية - في البداية يكون السائل ثابتًا (سرعة الجسيمات صفر) ، والضغط أيضًا صفر. سيتم تعيين شروط الحدود للسرعة والضغط بواسطة الصيغ المعطاة:
bf vecu0،j+ bf vecu1،j over2 deltay=0، bf vecui،0+ bf vecui،1 over2 deltax=0
bfp0،j− bfp1،j over deltax=0، bfpi،0− bfpi،1 over deltaذ=0دولا
وبالتالي ، فإن سرعة الجسيمات عند الحواف ستكون عكس السرعة في الحواف (وبالتالي فإنها سوف تتصدى من الحافة) ، ويكون الضغط مساويًا للقيمة المجاورة للحدود مباشرةً. يجب تطبيق هذه العمليات على جميع العناصر المرتبطة للصفيف (على سبيل المثال ، هناك حجم شبكة
N مرةM ، ثم نطبق الخوارزمية للخلايا المميزة باللون الأزرق في الشكل):

صبغ
مع ما لدينا الآن ، يمكنك بالفعل التوصل إلى الكثير من الأشياء المثيرة للاهتمام. على سبيل المثال ، لتحقيق انتشار الصبغة في السائل. للقيام بذلك ، نحتاج فقط إلى الحفاظ على حقل عددي آخر ، والذي سيكون مسؤولاً عن مقدار الطلاء في كل نقطة من المحاكاة. الصيغة لتحديث الصبغة تشبه إلى حد كبير السرعة ، ويتم التعبير عنها على النحو التالي:
جزئيةd over جزئيةt=−( vec bfu cdot nabla)d+ gamma nabla2d+S
في الصيغة
S مسؤول عن تجديد المنطقة بصبغة (ربما حسب المكان الذي ينقر فيه المستخدم) ،
د مباشرة هي كمية الصبغة في هذه النقطة ، و
gamma - معامل الانتشار. حلها ليس بالأمر الصعب ، حيث أن جميع الأعمال الأساسية المتعلقة باشتقاق الصيغ قد تم تنفيذها بالفعل ، وهي كافية لإجراء بعض البدائل. يمكن تنفيذ الرسام في الكود بلون في تنسيق RGB ، وفي هذه الحالة يتم تقليل المهمة إلى عمليات مع العديد من القيم الحقيقية.
الدردورية
لا تعد معادلة الدوامة جزءًا مباشرًا من معادلة Navier-Stokes ، ولكنها تعد معلمة مهمة لمحاكاة معقولة لحركة الصبغة في السائل. نظرًا لحقيقة أننا ننتج خوارزمية في حقل منفصل ، وكذلك بسبب الخسائر في دقة قيم الفاصلة العائمة ، يتم فقد هذا التأثير ، وبالتالي نحتاج إلى استعادته عن طريق تطبيق قوة إضافية على كل نقطة في الفضاء. تم تحديد متجه هذه القوة كـ
bf vecT ويتم تحديده بواسطة الصيغ التالية:
bf omega= nabla times vecu
vec eta= nabla| omega|
bf vec psi= vec eta over| vec eta|
bf vecT= epsilon( vec psi times omega) deltax
أوميغا هناك نتيجة لتطبيق
الدوار على ناقل السرعة (يرد تعريفه في بداية المقال) ،
vec eta - التدرج في مجال العددية للقيم المطلقة
أوميغا .
vec psi يمثل ناقل طبيعي
vec eta و
epsilon هو ثابت يتحكم في حجم الدوامات في سائلنا.
طريقة جاكوبي لحل أنظمة المعادلات الخطية
عند تحليل معادلات Navier-Stokes ، توصلنا إلى نظامين من المعادلات - أحدهما يتعلق باللزوجة والآخر للضغط. يمكن حلها بواسطة خوارزمية تكرارية ، يمكن وصفها بواسطة الصيغة التكرارية التالية:
x(k+1)i،j=x(k)i−1،j+x(k)i+1،j+x(k)i،j−1+x(k)i،j+1+ alphabi،j over beta
بالنسبة لنا
x - عناصر مجموعة تمثل حقل العددية أو المتجهات.
ك - رقم التكرار ، يمكننا ضبطه من أجل زيادة دقة الحساب أو العكس بالعكس لتقليله وزيادة الإنتاجية.
لحساب اللزوجة نستبدل:
x=b= bf vecu .
alpha=1 over nu deltat .
beta=4+ alpha ، هنا المعلمة
beta - مجموع الأوزان. وبالتالي ، نحتاج إلى تخزين حقلي سرعة متجهين على الأقل من أجل قراءة قيم أحد الحقول بشكل مستقل وكتابتها في حقل آخر. في المتوسط ، لحساب مجال السرعة باستخدام طريقة Jacobi ، من الضروري إجراء 20 إلى 50 تكرارًا ، وهذا كثير جدًا إذا أجرينا حسابات على وحدة المعالجة المركزية.
لمعادلة الضغط ، نقوم بالتبديل التالي:
x=p .
b= nabla bf cdot vecW .
a l p h a = - 1 .
b e t a = 4 . نتيجة لذلك ، نحصل على القيمة
p i ، j d e l t a t عند هذه النقطة. ولكن نظرًا لأنه يستخدم فقط لحساب التدرج المخصوم من حقل السرعة ، يمكن حذف التحويلات الإضافية. بالنسبة لحقل الضغط ، من الأفضل إجراء 40-80 تكرارًا ، لأنه مع وجود أعداد أقل يصبح التناقض ملحوظًا.
تنفيذ الخوارزمية
سننفذ الخوارزمية في C ++ ، نحتاج أيضًا إلى
Cuda Toolkit (يمكنك قراءة كيفية تثبيته على موقع Nvidia) ، وكذلك
SFML . نحتاج إلى CUDA لموازنة الخوارزمية ، وسيتم استخدام SFML فقط لإنشاء نافذة وعرض صورة على الشاشة (من حيث المبدأ ، يمكن كتابة هذا في OpenGL ، ولكن الفرق في الأداء سيكون ضئيلًا ، لكن الكود سيزداد بمقدار 200 سطر آخر).
مجموعة أدوات Cuda
أولاً ، سنتحدث قليلاً عن كيفية استخدام Cuda Toolkit لموازنة المهام.
يتم توفير
دليل أكثر تفصيلا من قبل نفيديا نفسها ، لذلك نحن هنا نقتصر فقط على الأكثر ضرورة. من المفترض أيضًا أنك تمكنت من تثبيت برنامج التحويل البرمجي ، وكنت قادراً على إنشاء مشروع اختبار دون أخطاء.
لإنشاء وظيفة يتم تشغيلها على وحدة معالجة الرسومات ، يجب أولاً أن تعلن عن عدد النواة التي نرغب في استخدامها ، وعدد كتل النواة التي نحتاج إلى تخصيصها. لهذا ، توفر لنا مجموعة Cuda Toolkit بنية خاصة -
dim3 ، من خلال إعداد كل قيم x و y و z الافتراضية على 1. عن طريق تحديدها كوسيطة عند استدعاء الوظيفة ، يمكننا التحكم في عدد النواة المخصصة. نظرًا لأننا نعمل مع صفيف ثنائي الأبعاد ، نحتاج إلى تعيين حقلين فقط في المُنشئ:
x و
y :
dim3 threadsPerBlock(x_threads, y_threads); dim3 numBlocks(size_x / x_threads, y_size / y_threads);
حيث
size_x و
size_y هما حجم المصفوفة قيد المعالجة. استدعاء الدالة والتوقيع كالتالي (تتم معالجة الأقواس ثلاثية الزاوية بواسطة برنامج التحويل البرمجي Cuda):
void __global__ deviceFunction();
في الوظيفة نفسها ، يمكنك استعادة مؤشرات صفيف ثنائي الأبعاد من خلال رقم الكتلة ورقم النواة في هذه الكتلة باستخدام الصيغة التالية:
int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y;
تجدر الإشارة إلى أن الوظيفة المنفذة على بطاقة الفيديو يجب أن يتم وضع علامة عليها بعلامة
__global__ ، وأن تُرجع أيضًا
لاغية ، لذلك غالبًا ما تتم كتابة نتائج العمليات الحسابية على المصفوفة التي تم تمريرها كوسيطة وتم تخصيصها مسبقًا في ذاكرة بطاقة الفيديو.
وظائف
CudaMalloc و
CudaFree هي المسؤولة عن تحرير وتخصيص الذاكرة على بطاقة الفيديو. يمكننا العمل على مؤشرات إلى منطقة الذاكرة التي يعودون إليها ، لكن لا يمكننا الوصول إلى البيانات من الكود الرئيسي. أسهل طريقة لإرجاع نتائج الحساب هي استخدام
cudaMemcpy ، على غرار
memcpy القياسي ، لكن مع إمكانية نسخ البيانات من بطاقة الفيديو إلى الذاكرة الرئيسية والعكس.
SFML ونافذة تقديم
مسلحين بكل هذه المعرفة ، يمكننا أخيرًا الانتقال إلى كتابة التعليمات البرمجية مباشرةً. للبدء ، دعنا ننشئ ملف
main.cpp ونضع كل الشفرة الإضافية لعرض النافذة هناك:
MAIN.CPP #include <SFML/Graphics.hpp> #include <chrono> #include <cstdlib> #include <cmath> //SFML REQUIRED TO LAUNCH THIS CODE #define SCALE 2 #define WINDOW_WIDTH 1280 #define WINDOW_HEIGHT 720 #define FIELD_WIDTH WINDOW_WIDTH / SCALE #define FIELD_HEIGHT WINDOW_HEIGHT / SCALE static struct Config { float velocityDiffusion; float pressure; float vorticity; float colorDiffusion; float densityDiffusion; float forceScale; float bloomIntense; int radius; bool bloomEnabled; } config; void setConfig(float vDiffusion = 0.8f, float pressure = 1.5f, float vorticity = 50.0f, float cDiffuion = 0.8f, float dDiffuion = 1.2f, float force = 1000.0f, float bloomIntense = 25000.0f, int radius = 100, bool bloom = true); void computeField(uint8_t* result, float dt, int x1pos = -1, int y1pos = -1, int x2pos = -1, int y2pos = -1, bool isPressed = false); void cudaInit(size_t xSize, size_t ySize); void cudaExit(); int main() { cudaInit(FIELD_WIDTH, FIELD_HEIGHT); srand(time(NULL)); sf::RenderWindow window(sf::VideoMode(WINDOW_WIDTH, WINDOW_HEIGHT), ""); auto start = std::chrono::system_clock::now(); auto end = std::chrono::system_clock::now(); sf::Texture texture; sf::Sprite sprite; std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4); texture.create(FIELD_WIDTH, FIELD_HEIGHT); sf::Vector2i mpos1 = { -1, -1 }, mpos2 = { -1, -1 }; bool isPressed = false; bool isPaused = false; while (window.isOpen()) { end = std::chrono::system_clock::now(); std::chrono::duration<float> diff = end - start; window.setTitle("Fluid simulator " + std::to_string(int(1.0f / diff.count())) + " fps"); start = end; window.clear(sf::Color::White); sf::Event event; while (window.pollEvent(event)) { if (event.type == sf::Event::Closed) window.close(); if (event.type == sf::Event::MouseButtonPressed) { if (event.mouseButton.button == sf::Mouse::Button::Left) { mpos1 = { event.mouseButton.x, event.mouseButton.y }; mpos1 /= SCALE; isPressed = true; } else { isPaused = !isPaused; } } if (event.type == sf::Event::MouseButtonReleased) { isPressed = false; } if (event.type == sf::Event::MouseMoved) { std::swap(mpos1, mpos2); mpos2 = { event.mouseMove.x, event.mouseMove.y }; mpos2 /= SCALE; } } float dt = 0.02f; if (!isPaused) computeField(pixelBuffer.data(), dt, mpos1.x, mpos1.y, mpos2.x, mpos2.y, isPressed); texture.update(pixelBuffer.data()); sprite.setTexture(texture); sprite.setScale({ SCALE, SCALE }); window.draw(sprite); window.display(); } cudaExit(); return 0; }
خط في بداية الوظيفة
الرئيسية std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4);
ينشئ صورة RGBA كصفيف أحادي البعد بطول ثابت. سنقوم
بتمريرها مع معلمات أخرى (موضع الماوس ، الفرق بين الإطارات) إلى وظيفة
computeField . يتم الإعلان عن الأخير ، وكذلك العديد من الوظائف الأخرى ، في
kernel.cu واستدعاء الكود الذي تم تنفيذه على وحدة معالجة الرسومات. يمكنك العثور على وثائق على أي من الوظائف على موقع SFML ، ولا يوجد شيء مثير للاهتمام في كود الملف ، لذلك لن نتوقف عند هذا الحد لفترة طويلة.
GPU الحوسبة
لبدء كتابة التعليمات البرمجية تحت gpu ، قم أولاً بإنشاء ملف kernel.cu وحدد العديد من الفئات المساعدة فيه:
Color3f و Vec2 و Config و SystemConfig :
kernel.cu (هياكل البيانات) struct Vec2 { float x = 0.0, y = 0.0; __device__ Vec2 operator-(Vec2 other) { Vec2 res; res.x = this->x - other.x; res.y = this->y - other.y; return res; } __device__ Vec2 operator+(Vec2 other) { Vec2 res; res.x = this->x + other.x; res.y = this->y + other.y; return res; } __device__ Vec2 operator*(float d) { Vec2 res; res.x = this->x * d; res.y = this->y * d; return res; } }; struct Color3f { float R = 0.0f; float G = 0.0f; float B = 0.0f; __host__ __device__ Color3f operator+ (Color3f other) { Color3f res; res.R = this->R + other.R; res.G = this->G + other.G; res.B = this->B + other.B; return res; } __host__ __device__ Color3f operator* (float d) { Color3f res; res.R = this->R * d; res.G = this->G * d; res.B = this->B * d; return res; } }; struct Particle { Vec2 u;
السمة
__host__ أمام اسم الأسلوب تعني أنه يمكن تنفيذ التعليمات البرمجية على وحدة المعالجة المركزية ،
__device__ ، على العكس من ذلك ، يلزم المترجم بجمع الكود تحت GPU. تعلن الكود عن بدائل للعمل مع المتجهات المكونة ، اللون ، التكوينات مع المعلمات التي يمكن تغييرها في وقت التشغيل ، وكذلك العديد من المؤشرات الثابتة للصفائف ، والتي سوف نستخدمها كمخازن للحسابات.
يتم تعريف
cudaInit و
cudaExit أيضًا
بشكل تافه للغاية:
kernel.cu (الحرف الأول) void cudaInit(size_t x, size_t y) { setConfig(); colorArray[0] = { 1.0f, 0.0f, 0.0f }; colorArray[1] = { 0.0f, 1.0f, 0.0f }; colorArray[2] = { 1.0f, 0.0f, 1.0f }; colorArray[3] = { 1.0f, 1.0f, 0.0f }; colorArray[4] = { 0.0f, 1.0f, 1.0f }; colorArray[5] = { 1.0f, 0.0f, 1.0f }; colorArray[6] = { 1.0f, 0.5f, 0.3f }; int idx = rand() % colorArraySize; currentColor = colorArray[idx]; xSize = x, ySize = y; cudaSetDevice(0); cudaMalloc(&colorField, xSize * ySize * 4 * sizeof(uint8_t)); cudaMalloc(&oldField, xSize * ySize * sizeof(Particle)); cudaMalloc(&newField, xSize * ySize * sizeof(Particle)); cudaMalloc(&pressureOld, xSize * ySize * sizeof(float)); cudaMalloc(&pressureNew, xSize * ySize * sizeof(float)); cudaMalloc(&vorticityField, xSize * ySize * sizeof(float)); } void cudaExit() { cudaFree(colorField); cudaFree(oldField); cudaFree(newField); cudaFree(pressureOld); cudaFree(pressureNew); cudaFree(vorticityField); }
في وظيفة التهيئة ، نخصص ذاكرة للصفيفات ثنائية الأبعاد ، ونحدد مجموعة من الألوان التي سنستخدمها لطلاء السائل ، وكذلك تعيين القيم الافتراضية في التكوين. في
cudaExit ، نقوم فقط بتحرير جميع المخازن المؤقتة. من المفارقات التي تبدو ، لتخزين المصفوفات ثنائية الأبعاد ، من الأفضل استخدام المصفوفات أحادية البعد ، والتي سيتم الوصول إليها بالتعبير التالي:
array[y * size_x + x];
نبدأ في تنفيذ الخوارزمية المباشرة مع وظيفة إزاحة الجسيمات. يتم نقل الحقول
oldField و
newField (الحقل الذي
تأتي منه البيانات ومن أين تتم كتابتها إلى) ، وحجم المصفوفة ، وكذلك دلتا الوقت ومعامل الكثافة (المستخدمة لتسريع
إذابة الصبغة في السائل وجعل الوسيط غير حساس للغاية لل
advect ، إلى
advect إجراءات المستخدم).
يتم تنفيذ وظيفة
الاستيفاء الثنائية الخطية بطريقة كلاسيكية عن طريق حساب القيم الوسيطة:
تقرر تقسيم وظيفة نشر اللزوجة إلى عدة أجزاء: يُسمى
computeDiffusion من الكود الرئيسي ، الذي يطلق على
diffuse and
computeColor عددًا محددًا مسبقًا من المرات ، ثم
يستبدل الصفيف من حيث نأخذ البيانات والآخر حيث
نكتبها . هذه هي أسهل طريقة لتنفيذ معالجة البيانات الموازية ، لكننا ننفق ضعف الذاكرة.
كلتا الدالتين تسبب اختلافات في طريقة جاكوبي.
يتحقق نص jacobiColor و
jacobiVelocity على الفور من أن العناصر الحالية ليست على الحدود - في هذه الحالة ، يجب أن
نضبطها وفقًا للصيغ الموضحة في قسم
الشروط والحدود الأولية .
يتم استخدام القوة الخارجية من خلال وظيفة واحدة -
applyForce ، والتي تأخذ كحجة موقف الماوس ولون الصبغة ، وكذلك دائرة نصف قطرها العمل. مع ذلك ، يمكننا إعطاء السرعة للجزيئات ، وكذلك طلاء لهم. يتيح لك الأس الشقيق جعل المنطقة غير حادة جدًا ، وفي نفس الوقت واضح تمامًا في نصف القطر المحدد.
إن حساب الدوامة هو بالفعل عملية أكثر تعقيدًا ، وبالتالي
ننفذها في
حساب vorticity وطبق Vorticity ، نلاحظ أيضًا أنه من الضروري بالنسبة لهما تحديد اثنين من مشغلي الموجات مثل
curl (الدوار) و
absGradient (تدرج قيم الحقل المطلقة). لتحديد تأثيرات دوامة إضافية ، فإننا نضرب
ذ مكون من ناقلات التدرج على
- 1 د و ل ا ، ثم قم بتطبيعه عن طريق القسمة على الطول (دون أن ننسى التحقق من أن الموجه غير صفري):
ستكون الخطوة التالية في الخوارزمية هي حساب مجال الضغط القياسي وإسقاطه على حقل السرعة. للقيام بذلك ، نحتاج إلى تنفيذ 4 وظائف هي:
التباعد ، والذي سينظر في سرعة التباعد ،
jacobiPressure ، الذي ينفذ طريقة Jacobi للضغط ، و
computePressure باستخدام
computePressureImpl ، والذي
يكرر حسابات الحقل:
يناسب الإسقاط وظيفتين صغيرتين -
المشروع والتدرج الذي
يستدعي الضغط. يمكن قول ذلك في المرحلة الأخيرة من خوارزمية المحاكاة لدينا:
بعد الإسقاط ، يمكننا المضي قدمًا بأمان في تقديم الصورة إلى المخزن المؤقت والتأثيرات اللاحقة المختلفة. تقوم وظيفة
الطلاء بنسخ الألوان من حقل الجسيمات إلى صفيف RGBA. تم أيضًا تطبيق وظيفة
ApplyBloom ، والتي تبرز السائل عند وضع المؤشر عليه والضغط على زر الماوس. من التجربة ، تجعل هذه التقنية الصورة أكثر متعة وإثارة للاهتمام لعيون المستخدم ، ولكنها ليست ضرورية على الإطلاق.
في مرحلة ما بعد المعالجة ، يمكنك أيضًا تسليط الضوء على الأماكن التي يكون فيها السائل أعلى سرعة ، وتغيير اللون اعتمادًا على ناقل الحركة ، وإضافة تأثيرات مختلفة ، وما إلى ذلك ، ولكن في حالتنا سنقتصر على نوع من الحد الأدنى ، لأنه حتى الصور رائعة للغاية (خاصة في الديناميات) :
وفي النهاية ، لا يزال لدينا وظيفة رئيسية واحدة نسميها من
main.cpp -
computeField . إنه يربط جميع أجزاء الخوارزمية معًا ويدعو الكود الموجود على بطاقة الفيديو ، كما ينسخ البيانات من وحدة المعالجة المركزية إلى وحدة المعالجة المركزية. كما أنه يحتوي على حساب الزخم المتجه واختيار لون الصبغة ، والذي
نمرره لتطبيق :
kernel.cu (الوظيفة الرئيسية) استنتاج
في هذه المقالة ، قمنا بتحليل خوارزمية رقمية لحل معادلة Navier-Stokes وكتبنا برنامج محاكاة صغير لسائل غير قابل للضغط. ربما لم نفهم جميع التعقيدات ، لكنني آمل أن تكون المادة مثيرة للاهتمام ومفيدة بالنسبة لك ، وكانت بمثابة مقدمة جيدة على الأقل في مجال نمذجة السوائل.
بصفتي مؤلف هذا المقال ، سأقدر بإخلاص أي تعليقات وإضافات ، وسأحاول الإجابة على جميع أسئلتك تحت هذا المنشور.
مواد إضافية
يمكنك العثور على كل شفرة المصدر في هذه المقالة في
مستودع جيثب الخاص بي. أي اقتراحات للتحسين هي موضع ترحيب.
المواد الأصلية التي كانت بمثابة أساس لهذه المقالة ، يمكنك أن تقرأ على الموقع الرسمي لنفيديا. كما يقدم أمثلة على تنفيذ أجزاء من الخوارزمية بلغة التظليل:
developer.download.nvidia.com/books/HTML/gpugems/gpugems_ch38.htmlيمكن العثور على دليل على نظرية تحلل Helmholtz وكمية هائلة من المواد الإضافية حول ميكانيكا الموائع في هذا الكتاب (الإنجليزية ، انظر القسم 1.2):
Chorin ، AJ ، و JE Marsden. 1993. مقدمة رياضية لميكانيكا الموائع. 3rd ed. الوثاب.قناة يوتيوب واحدة يتحدث الإنجليزية ، مما يجعل محتوى عالي الجودة يتعلق بالرياضيات ، وحل المعادلات التفاضلية على وجه الخصوص (الإنجليزية). مقاطع الفيديو المرئية للغاية التي تساعد على فهم جوهر العديد من الأشياء في الرياضيات والفيزياء:3Blue1Brown -المعادلات التفاضلية في YouTube (3Blue1Brown)وأشكر أيضًا WhiteBlackGoose على المساعدة في إعداد المواد للمقال.
وفي النهاية ، هناك مكافأة صغيرة - بعض لقطات الشاشة الجميلة التي تم التقاطها في البرنامج: الدفق المباشر (الإعدادات الافتراضية)
الدفق المباشر (الإعدادات الافتراضية) الدوامة (دائرة نصف قطرها كبيرة في applicForce)
الدوامة (دائرة نصف قطرها كبيرة في applicForce) Wave (دوامة عالية + نشر)أيضًا ، بناءً على الطلب الشائع ، أضفت فيديوًا باستخدام المحاكاة:
Wave (دوامة عالية + نشر)أيضًا ، بناءً على الطلب الشائع ، أضفت فيديوًا باستخدام المحاكاة: