تقوم
أداة سطر الأوامر
Sloc Cloc and Code (scc) التي كتبت ، والتي تم الانتهاء من
إعدادها ودعمها الآن من قبل أشخاص رائعين ، بحساب سطور من التعليمات البرمجية والتعليقات وتقييم مدى تعقيد الملفات داخل الدليل. هناك حاجة لاختيار جيد هنا. تحسب الأداة العوامل المتفرعة في التعليمات البرمجية. ولكن ما هو التعقيد؟ على سبيل المثال ، العبارة "هذا الملف لديه صعوبة 10" ليست مفيدة للغاية بدون سياق. لحل هذه المشكلة ، ركضت
scc على جميع المصادر على الإنترنت. سيسمح لك هذا أيضًا بالعثور على بعض الحالات القصوى التي لم أضعها في الاعتبار في الأداة نفسها. اختبار القوة الغاشمة قوية.
ولكن إذا كنت سأجري الاختبار على جميع المصادر في العالم ، فسيتطلب ذلك الكثير من موارد الحوسبة ، وهي أيضًا تجربة مثيرة للاهتمام. لذلك ، قررت أن أكتب كل شيء - وظهرت هذه المقالة.
باختصار ، قمت بتنزيل ومعالجة الكثير من المصادر.
شخصيات عارية:
- 9،985،051 مجموع المستودعات
- المستودعات 9،100،083 مع ملف واحد على الأقل
- 884 968 مستودعات فارغة (بدون ملفات)
- 3،500،000،000 ملف في جميع المستودعات
- معالجة 40 736 530 379 778 بايت (40 تيرابايت)
- تم تحديد 1،086.723.618.560 صفًا
- 816،822،273،469 أسطر مع التعرف على الكود
- 124 382 152 510 خطوط فارغة
- 145 519 192 581 سطر التعليقات
- إجمالي التعقيد وفقًا لقواعد scc: 71 884 867 919
- تم العثور على 2 أخطاء جديدة في scc
دعنا نذكر فقط تفصيل واحد. لا يوجد 10 ملايين مشروع ، كما هو مبين في العنوان البارز. فاتني 15000 ، لذلك أنا تقريبه. انا اعتذر عن هذا
استغرق الأمر حوالي خمسة أسابيع لتنزيل كل شيء ، وتصفح scc وحفظ جميع البيانات. ثم أكثر من 49 ساعة بقليل لمعالجة 1 TB JSON واحصل على النتائج أدناه.
لاحظ أيضًا أنه قد أكون مخطئًا في بعض الحسابات. سوف أبلغكم على الفور إذا تم اكتشاف أي خطأ ، وتقديم مجموعة بيانات.
جدول المحتويات
منهجية
منذ إطلاق
searchcode.com ، قمت بالفعل بتجميع مجموعة تضم أكثر من 7000 مشروع على البوابة والزئبق والتخريب وما إلى ذلك. فلماذا لا نعالجها؟ عادةً ما يكون العمل مع git هو الحل الأسهل ، لذلك تجاهلت هذه المرة الزئبق والتخريب وقمت بتصدير قائمة كاملة بمشاريع git. اتضح أنني تتبعت بالفعل 12 مليون مستودع بوابة ، وربما أحتاج إلى تحديث الصفحة الرئيسية لتعكس هذا.
لدي الآن 12 مليون مستودع تخزين لتحميلها ومعالجتها.
عند تشغيل scc ، يمكنك تحديد الإخراج في JSON مع حفظ الملف على القرص:
scc --format json --output myfile.json main.go النتائج كالتالي (لملف واحد):
[ { "Blank": 115, "Bytes": 0, "Code": 423, "Comment": 30, "Complexity": 40, "Count": 1, "Files": [ { "Binary": false, "Blank": 115, "Bytes": 20396, "Callback": null, "Code": 423, "Comment": 30, "Complexity": 40, "Content": null, "Extension": "go", "Filename": "main.go", "Hash": null, "Language": "Go", "Lines": 568, "Location": "main.go", "PossibleLanguages": [ "Go" ], "WeightedComplexity": 0 } ], "Lines": 568, "Name": "Go", "WeightedComplexity": 0 } ]
للحصول على مثال أكبر ، راجع نتائج مشروع
redis :
redis.json . يتم الحصول على جميع النتائج أدناه من هذه النتيجة دون أي بيانات إضافية.
يجب أن يؤخذ في الاعتبار أن scc يصنف عادة اللغات بناءً على الامتداد (ما لم يكن الامتداد شائعًا ، مثل Verilog و Coq). وبالتالي ، إذا قمت بحفظ ملف HTML بامتداد java ، فسيتم اعتباره ملف java. هذا عادة لا يمثل مشكلة ، لماذا تفعل هذا؟ لكن ، بالطبع ، على نطاق واسع ، تصبح المشكلة ملحوظة. لقد اكتشفت ذلك لاحقًا عندما تم إخفاء بعض الملفات كملحق مختلف.
منذ بعض الوقت كتبت
رمزًا لإنشاء علامات github المستندة إلى scc . نظرًا لأن العملية اللازمة لتخزين النتائج مؤقتًا ، فقد غيرتها قليلاً لتخزينها مؤقتًا بتنسيق JSON على AWS S3.
مع رمز التسميات في AWS على lambda ، أخذت قائمة من المشاريع المصدرة ، وكتبت حوالي 15 سطورًا من الثعبان لمسح التنسيق لتطابق lambda ، وقدمت طلبًا إليه. باستخدام معالجة البيثون المتعددة ، قمت بموازاة الطلبات مع 32 عملية حتى استجاب نقطة النهاية بسرعة كافية.
كل شيء يعمل ببراعة. ومع ذلك ، كانت المشكلة ، أولاً ، في التكلفة ، وثانياً ، لدى lambda مهلة لمدة 30 ثانية لـ API Gateway / ALB ، لذلك لا يمكن معالجة مستودعات كبيرة بسرعة كافية. كنت أعلم أن هذا ليس هو الحل الأكثر اقتصادا ، لكنني اعتقدت أن السعر سيكون حوالي 100 دولار ، وهو ما كنت أتعامل معه. بعد معالجة مليون مستودعات ، راجعت - وكانت التكلفة حوالي 60 دولارًا. نظرًا لأنني لم أكن سعيدًا باحتمالية حساب AWS نهائي بقيمة 700 دولار ، فقد قررت إعادة النظر في قراري. ضع في اعتبارك أن هذا كان في الأساس وحدة التخزين ووحدة المعالجة المركزية التي تم استخدامها لجمع كل هذه المعلومات. أي معالجة وتصدير البيانات زيادة كبيرة في السعر.
نظرًا لأنني كنت بالفعل على AWS ، فإن الحل السريع هو تفريغ عناوين URL كرسائل في SQS وسحبها باستخدام مثيلات EC2 أو Fargate للمعالجة. ثم مقياس مثل مجنون. لكن على الرغم من التجربة اليومية مع AWS ، فقد كنت أؤمن دائمًا
بمبادئ برمجة Taco Bell . بالإضافة إلى ذلك ، كان هناك 12 مليون مستودع فقط ، لذلك قررت تنفيذ حل أبسط (أرخص).
لم يكن بدء الحساب محليًا ممكنًا بسبب الإنترنت الرهيب في أستراليا. ومع ذلك ، يعمل searchcode.com الخاص بي باستخدام خوادم مخصصة من Hetzner بعناية. هذه هي ذاكرة الوصول العشوائي i7 رباعية النواة بقوة 32 جيجابايت من ذاكرة الوصول العشوائي ، وغالبا مع 2 تيرابايت من مساحة التخزين (عادة لا تستخدم). لديهم عادة امدادات جيدة من الطاقة الحاسوبية. على سبيل المثال ، يحسب خادم الواجهة الأمامية معظم الوقت الجذر التربيعي للصفر. فلماذا لا تبدأ معالجة هناك؟
هذه ليست حقا تاكو بيل البرمجة منذ أن استخدمت أدوات باش وجنو. لقد كتبت برنامجًا
بسيطًا على Go لتشغيل 32 عملية انتقال تقرأ البيانات من قناة ، وتوليد git و scc subprocesses قبل كتابة الإخراج إلى JSON في S3. لقد كتبت الحل أولاً في Python ، لكن الحاجة إلى تثبيت تبعيات النقاط على الخادم النظيف تبدو فكرة سيئة ، وتعطل النظام بطرق غريبة لم أكن أرغب في تصحيحها.
يؤدي تشغيل كل هذا على الخادم إلى إنتاج المقاييس التالية في htop ، ويفترض العديد من عمليات git / scc قيد التشغيل (لا تظهر scc في لقطة الشاشة هذه) أن كل شيء كان يعمل كما هو متوقع ، وهو ما أكدته النتائج في S3.

عرض وحساب النتائج
لقد قرأت مؤخرًا
هذه المقالات ، لذلك كان لدي فكرة لاستعارة تنسيق هذه المنشورات فيما يتعلق بتقديم المعلومات. ومع ذلك ، أردت أيضًا إضافة
jTuery DataTables إلى جداول كبيرة لفرز النتائج وبحثها / تصفيتها. وبالتالي ، في
المقالة الأصلية ، يمكنك النقر فوق العناوين للفرز واستخدام حقل البحث للتصفية.
أثار حجم البيانات اللازمة للمعالجة سؤالًا آخر. كيفية معالجة 10 مليون ملف JSON ، تشغل مساحة تزيد قليلاً على 1 تيرابايت من مساحة القرص في دلو S3؟
كان الفكر الأول AWS أثينا. ولكن نظرًا لأنه سيكلف حوالي 2.50 دولار
لكل استعلام لمجموعة البيانات هذه ، فقد بدأت بسرعة في البحث عن بديل. ومع ذلك ، إذا قمت بحفظ البيانات هناك ونادراً ما تقوم بمعالجتها ، فقد يكون هذا هو الحل الأرخص.
لقد نشرت سؤالًا في الدردشة الجماعية (لماذا تحل المشكلات وحدها).
كانت إحدى الأفكار تفريغ البيانات في قاعدة بيانات SQL كبيرة. ومع ذلك ، هذا يعني معالجة البيانات في قاعدة البيانات ، ثم تنفيذ الاستعلامات عليها عدة مرات. بالإضافة إلى ذلك ، تعني بنية البيانات جداول متعددة ، مما يعني وجود مفاتيح وفهارس خارجية لتوفير مستوى معين من الأداء. هذا يبدو مضيعة ، لأنه يمكننا فقط معالجة البيانات كما نقرأها من القرص - مرة واحدة. كنت قلقًا أيضًا حول إنشاء قاعدة بيانات كبيرة. مع البيانات فقط ، سيكون حجمها أكثر من 1 تيرابايت قبل إضافة فهارس.
عندما رأيت كيف أنشأت JSON بطريقة بسيطة ، فلماذا لا أقوم بمعالجة النتائج بالطريقة نفسها؟ بالطبع ، هناك مشكلة واحدة. إن سحب 1 تيرابايت من البيانات من S3 سيكلف الكثير. إذا تعطل البرنامج ، فسيكون ذلك مزعجًا. لخفض التكاليف ، أردت سحب جميع الملفات محليًا وحفظها لمزيد من المعالجة. نصيحة جيدة: من الأفضل عدم تخزين
العديد من الملفات الصغيرة في دليل واحد . هذا تمتص لأداء وقت التشغيل ، وأنظمة الملفات لا تحب ذلك.
كانت إجابتي على هذا عبارة عن
برنامج Go بسيط آخر لسحب الملفات من S3 ثم حفظها في ملف tar. ثم يمكنني معالجة هذا الملف مرارا وتكرارا. تقوم العملية نفسها بتشغيل
برنامج Go قبيح للغاية لمعالجة ملف tar بحيث يمكنني إعادة تشغيل الاستعلامات دون الحاجة إلى سحب البيانات من S3 مرارًا وتكرارًا. لم أكن مضطرا مع إجراءات الذهاب هنا لسببين. أولاً ، لم أكن أرغب في تحميل الخادم قدر الإمكان ، لذلك قصرت نفسي على وحدة أساسية واحدة للعمل بجد (وحدة المعالجة المركزية مؤمنة في الغالب على المعالج لقراءة ملف tar). ثانيا ، أردت أن أضمن سلامة موضوع.
عندما تم ذلك ، كانت هناك حاجة لمجموعة من الأسئلة للإجابة. لقد استخدمت العقل الجماعي مرة أخرى وربطت زملائي بينما أتيت بأفكاري الخاصة. تم عرض نتيجة دمج العقول أدناه.
يمكنك العثور على
جميع الشفرة التي اعتدت عليها لمعالجة JSON ، بما في ذلك رمز المعالجة المحلية ،
والنص البرمجي Python القبيح الذي استخدمته لإعداد شيء مفيد لهذه المقالة: يرجى عدم التعليق عليه ، وأنا أعلم أن الرمز قبيح ، وهو مكتوب لمهمة لمرة واحدة ، حيث من غير المحتمل أن أنظر إليها مرة أخرى.
إذا كنت تريد الاطلاع على الكود الذي كتبته للاستخدام العام ،
فراجع مصادر scc .
تكلفة
لقد أنفقت حوالي 60 دولارًا على الحوسبة أثناء محاولتي العمل مع لامدا. لم أكن قد نظرت في تكلفة تخزين S3 بعد ، لكن يجب أن تكون قريبة من 25 دولارًا ، اعتمادًا على حجم البيانات. ومع ذلك ، فإن هذا لا يشمل تكاليف الإرسال ، والتي لم أشاهدها أيضًا. يرجى ملاحظة أنني قمت بتنظيف الجرافة عندما انتهيت من ذلك ، لذلك ليست تكلفة ثابتة.
ولكن بعد فترة ما زلت أتخلى عن AWS. فما هي التكلفة الحقيقية إذا أردت القيام بذلك مرة أخرى؟
جميع البرامج لدينا مجانية ومجانية. لذلك لا يوجد شيء يدعو للقلق.
في حالتي ، ستكون التكلفة صفرية ، حيث أنني استخدمت طاقة الحوسبة "المجانية" المتبقية من searchcode.com. ومع ذلك ، ليس كل شخص لديه مثل هذه الموارد المجانية. لذلك ، لنفترض أن الشخص الآخر يريد تكرار هذا ويجب رفع الخادم.
يمكن القيام بذلك مقابل 73 يورو باستخدام أرخص
خادم مخصص جديد
من Hetzner ، بما في ذلك تكلفة تثبيت خادم جديد. إذا انتظرت وانتقلت إلى
القسم مع المزادات ، فيمكنك العثور على خوادم أرخص بكثير دون رسوم التثبيت. في وقت كتابة هذا التقرير ، وجدت سيارة مثالية لهذا المشروع ، مقابل 25.21 يورو شهريًا دون رسوم التركيب.
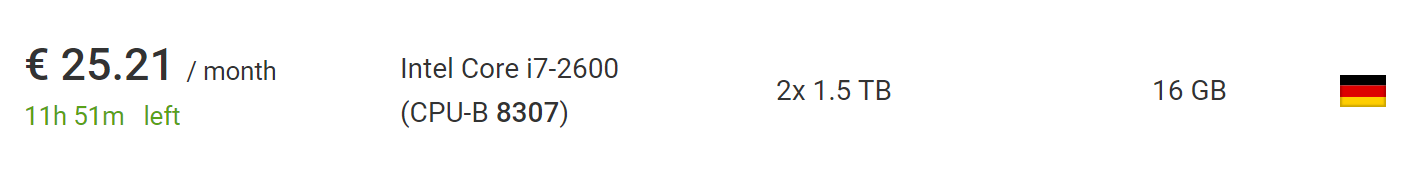
ما هو أفضل ، خارج الاتحاد الأوروبي ، سيتم إزالة ضريبة القيمة المضافة من هذا السعر ، لذلك لا تتردد في أخذ 10 ٪ أخرى.
لذلك ، إذا قمت برفع هذه الخدمة من نقطة الصفر على برنامجي ، فستكلف في نهاية المطاف ما يصل إلى 100 دولار ، ولكن قد تصل إلى 50 دولارًا ، إذا كنت صبورًا أو ناجحًا إلى حد ما. يفترض هذا أنك تستخدم الخادم منذ أقل من شهرين ، وهو ما يكفي للتنزيل والمعالجة. هناك أيضًا ما يكفي من الوقت للحصول على قائمة تضم 10 ملايين مستودع.
إذا كنت قد استخدمت tar zip (وهو في الواقع ليس بهذه الصعوبة) ، فبإمكاني معالجة مستودعات أكثر 10 أضعاف على نفس الجهاز ، وسيظل الملف الناتج صغيرًا بما يكفي لملائمة نفس محرك الأقراص الثابتة. على الرغم من أن العملية قد تستغرق عدة أشهر ، لأن التنزيل سيستغرق وقتًا أطول.
للذهاب إلى ما هو أبعد من 100 مليون مستودع ، ومع ذلك ، هناك حاجة إلى نوع من التقاسم. ومع ذلك ، من الآمن القول أنك ستعيد العملية على نطاقي أو أكبر من ذلك بكثير ، على نفس الجهاز دون بذل الكثير من الجهد أو تغييرات الكود.
مصادر البيانات
إليك عدد المشروعات التي جاءت من كل من المصادر الثلاثة: github ، و bitbucket ، و gitlab. يرجى ملاحظة أن هذا هو قبل استبعاد مستودعات التخزين الفارغة ، وبالتالي ، فإن المبلغ يتجاوز عدد المستودعات التي تمت معالجتها بالفعل وأخذها في الاعتبار في الجداول التالية.
أعتذر لموظفي GitHub / Bitbucket / GitLab إذا قرأت هذا. إذا تسبب النص البرمجي في أي مشاكل (على الرغم من أنني أشك في ذلك) ، فأنا أتناول مشروبًا من اختيارك عند مقابلتي.
كم عدد الملفات في المستودع؟
دعنا ننتقل إلى القضايا الحقيقية. لنبدأ مع واحد بسيط. كم عدد الملفات في مستودع متوسط؟ معظم المشاريع لديها سوى اثنين من الملفات أو أكثر؟ بعد التكرار خلال المستودعات ، نحصل على الجدول التالي:

هنا ، يُظهر المحور س عدد المجموعات مع عدد الملفات ، ويظهر المحور ص عدد المشاريع مع الكثير من الملفات. حدد المحور الأفقي بألف ملف ، لأن الرسم البياني قريب جدًا من المحور.
يبدو أن معظم المستودعات بها أقل من 200 ملف.
ولكن ماذا عن التصور حتى المئوية 95 ، والتي سوف تظهر الصورة الحقيقية؟ اتضح أنه في الغالبية العظمى (95 ٪) من المشاريع - أقل من 1000 ملف. في حين أن 90 ٪ من المشاريع لديها أقل من 300 ملف و 85 ٪ لديها أقل من 200.

إذا كنت ترغب في إنشاء مخطط بنفسك والقيام به بشكل أفضل مني ، فإليك
رابط للبيانات الأولية في JSON .
ما هو انهيار اللغة؟
على سبيل المثال ، إذا تم تحديد ملف Java ، فسنزيد عدد Java في المشاريع بواحد ، ولا نفعل شيئًا للملف الثاني. هذا يعطي فكرة سريعة عن اللغات الأكثر استخدامًا. مما لا يثير الدهشة ، أن أكثر اللغات شيوعًا تشمل تخفيض السعر و. gitignore و plaintext.
تعد لغة تخفيض السعر هي اللغة الأكثر استخدامًا ؛ حيث يتم مشاهدتها في أكثر من 6 ملايين مشروع ، أي حوالي 2 إلى 3 من الإجمالي. هذا منطقي ، نظرًا لأن جميع المشاريع تقريبًا تتضمن README.md الذي يتم عرضه في HTML لصفحات المستودع.
كم عدد الملفات الموجودة في المستودع حسب اللغة؟
إضافة إلى الجدول السابق ، ولكن بلغ متوسط عدد الملفات لكل لغة في المستودع. بمعنى ، كم عدد ملفات Java الموجودة في المتوسط لجميع المشاريع التي يوجد فيها Java؟
كم عدد سطور التعليمات البرمجية في ملف اللغة النموذجي؟
أفترض أنه لا يزال من المثير للاهتمام معرفة اللغات التي بها أكبر الملفات في المتوسط؟ يؤدي استخدام الوسط الحسابي إلى إنشاء أرقام عالية بشكل غير طبيعي بسبب مشاريع مثل sqlite.c ، والتي يتم تضمينها في العديد من المستودعات ، وتجمع العديد من الملفات في ملف واحد ، لكن لا أحد يعمل على هذا الملف الكبير واحد (آمل!)لذلك ، حسبت متوسط الوسيط. ومع ذلك ، ظلت اللغات ذات القيم العالية السخيفة ، مثل Bosque و JavaScript.لذلك اعتقدت ، لماذا لا تجعل خطوة فارس؟ بناءً على اقتراح داريل (أحد سكان كابلامو وعالم بيانات ممتاز) ، قمت بتغيير واحد صغير وغيرت الوسط الحسابي ، وأسقطت الملفات أكثر من 5000 سطر لإزالة الحالات الشاذة.متوسط تعقيد الملف في كل لغة؟
ما هو متوسط تعقيد الملف لكل لغة؟في الواقع ، لا يمكن ربط تصنيفات التعقيد بشكل مباشر بين اللغات. مقتطف من التمهيدي نفسه scc:درجة التعقيد هي مجرد رقم لا يمكن مطابقته إلا بين الملفات التي تحمل نفس اللغة. لا ينبغي أن تستخدم لمقارنة اللغات مباشرة. السبب هو أنه يتم حسابه من خلال البحث عن مشغلي الفرع والحلقة لكل ملف.
وبالتالي ، لا يمكن مقارنة اللغات مع بعضها البعض هنا ، على الرغم من أنه يمكن القيام بذلك بين لغات متشابهة مثل Java و C ، على سبيل المثال.هذا هو مقياس أكثر قيمة للملفات الفردية في نفس اللغة. وبالتالي ، يمكنك الإجابة على السؤال "هل هذا الملف أعمل بطريقة أسهل أم أصعب من المتوسط؟"يجب أن أذكر أنني سأكون سعيدًا بالاقتراحات لتحسين هذا المقياس في scc . بالنسبة إلى الالتزام ، عادة ما يكفي إضافة بضع كلمات رئيسية فقط إلى ملف languages.json ، لذلك يمكن لأي مبرمج المساعدة.متوسط عدد التعليقات للملفات في كل لغة؟
ما هو متوسط عدد التعليقات في الملفات في كل لغة؟ربما يمكن إعادة صياغة السؤال: مطورو البرامج الذين يكتبون معظم التعليقات ، مما يشير إلى سوء فهم القارئ.ما هي أسماء الملفات الأكثر شيوعا؟
ما هي أسماء الملفات الأكثر شيوعًا في جميع الأكواد البرمجية ، مع تجاهل الإمتداد والحالة؟إذا سألتني في وقت سابق ، سأقول: README ، الرئيسية ، الفهرس ، الترخيص. النتائج تعكس بشكل جيد افتراضاتي. رغم أن هناك الكثير من الأشياء المثيرة للاهتمام. ليس لدي أي فكرة عن سبب احتواء العديد من المشاريع على ملف يسمى 15أو s15.فاجأني الملف الأكثر شيوعًا قليلاً ، لكنني تذكرت أنه تم استخدامه في العديد من مشاريع جافا سكريبت الجديدة. شيء آخر مثير للاهتمام أن نلاحظه: يبدو أن jQuery لا يزال على الحصان ، وتقارير وفاته مبالغ فيها إلى حد كبير ، وهو في المركز الرابع في القائمة.يرجى ملاحظة أنه بسبب قيود الذاكرة ، جعلت هذه العملية أقل دقة قليلاً. بعد كل 100 مشروع ، راجعت الخريطة وحذفت أسماء الملفات التي حدثت أقل من 10 مرات من القائمة. يمكن أن يعودوا إلى الاختبار التالي ، وإذا التقوا أكثر من 10 مرات ، فقد ظلوا في القائمة. ربما يكون لبعض النتائج خطأ ما إذا كان اسمًا شائعًا نادرًا ما يظهر في المجموعة الأولى من المستودعات قبل أن يصبح شائعًا. باختصار ، هذه ليست أرقامًا مطلقة ، لكن يجب أن تكون قريبة بما فيه الكفاية.يمكنني استخدام شجرة البادئة "للضغط" على المساحة والحصول على الأرقام المطلقة ، لكنني لا أريد أن أكتبها ، لذلك قمت بإساءة استخدام الخريطة قليلاً لتوفير ذاكرة كافية والحصول على النتيجة. ومع ذلك ، سيكون من المثير للاهتمام تجربة شجرة البادئة لاحقًا.كم عدد المستودعات التي تفتقد إلى ترخيص؟
هذا مثير جدا للاهتمام. كم عدد المستودعات التي لديها على الأقل بعض ملفات الترخيص الصريحة؟ يرجى ملاحظة أن عدم وجود ملف ترخيص هنا لا يعني أن المشروع لا يحتوي عليه ، لأنه يمكن أن يوجد في ملف README أو يمكن الإشارة إليه من خلال علامات تعليق SPDX في سطور. هذا يعني ببساطة sccأنه لا يمكن العثور على ملف الترخيص الصريح باستخدام معاييره الخاصة. في الوقت الحالي ، تُعتبر هذه الملفات "ترخيصًا" أو "ترخيصًا" أو "نسخًا" أو "نسخًا 3" أو "غير مرخص به" أو "إلغاء ترخيص" أو "ترخيصًا معيّنًا" أو "ترخيصًا متعدد الحقوق" أو "حقوق طبع ونشر".لسوء الحظ ، فإن الغالبية العظمى من المستودعات لا تملك ترخيصًا. أود أن أقول أن هناك العديد من الأسباب التي تجعل أي برنامج يحتاج إلى ترخيص ، لكن شخصًا آخر قال لي ذلك.
كم عدد المشاريع التي تستخدم ملفات .gitignore متعددة؟
قد لا يعرف البعض هذا ، ولكن قد يكون هناك عدة ملفات .gitignore في مشروع git. مع وضع ذلك في الاعتبار ، كم عدد المشاريع التي تستخدم ملفات .gitignore متعددة؟ وفي الوقت نفسه ، كم لا تملك واحدة؟لقد وجدت مشروعًا مثيرًا للاهتمام مع 25،794 ملف .gitignore في المستودع. وكانت النتيجة التالية 2547. ليس لدي أي فكرة عما يجري هناك. نظرت لفترة وجيزة: يبدو أنها تستخدم للتحقق من الأدلة ، لكن لا يمكنني تأكيد ذلك.بالرجوع إلى البيانات ، يوجد هنا رسم بياني لمستودعات التخزين مع ما يصل إلى 20 ملفًا من ملفات جينيجنور ، والتي تغطي 99٪ من جميع المشاريع. كما هو متوقع ، تحتوي معظم المشاريع على ملفات 0 أو 1.gitignore. ويؤكد ذلك انخفاضًا كبيرًا في عدد المشروعات التي تحتوي على ملفات بعشرة أضعاف. ما أدهشني هو عدد المشروعات التي تحتوي على أكثر من ملف .gitignore. الذيل الطويل في هذه الحالة طويل بشكل خاص.كنت فضولية لماذا بعض المشاريع لديها الآلاف من هذه الملفات. واحدة من مثيري الشغب الرئيسيين هي الشوكة https://github.com/PhantomX/slackbuilds : لدى كل منهم حوالي 2547 ملفًا. توجد مستودعات أخرى بها أكثر من ألف ملف .gitignore مدرجة أدناه.
كما هو متوقع ، تحتوي معظم المشاريع على ملفات 0 أو 1.gitignore. ويؤكد ذلك انخفاضًا كبيرًا في عدد المشروعات التي تحتوي على ملفات بعشرة أضعاف. ما أدهشني هو عدد المشروعات التي تحتوي على أكثر من ملف .gitignore. الذيل الطويل في هذه الحالة طويل بشكل خاص.كنت فضولية لماذا بعض المشاريع لديها الآلاف من هذه الملفات. واحدة من مثيري الشغب الرئيسيين هي الشوكة https://github.com/PhantomX/slackbuilds : لدى كل منهم حوالي 2547 ملفًا. توجد مستودعات أخرى بها أكثر من ألف ملف .gitignore مدرجة أدناه.?
هذا القسم ليس علمًا دقيقًا ، ولكنه ينتمي إلى فئة مشكلات معالجة اللغة الطبيعية. لن يكون البحث عن المصطلحات المسيئة أو المسيئة في قائمة ملفات محددة فعالًا أبدًا. إذا قمت بالبحث باستخدام بحث بسيط ، فستجد العديد من الملفات العادية مثل assemble.shوهلم جرا. لذا ، أخذت قائمة من اللعنات ، ثم تحقق مما إذا كانت أي ملفات في كل مشروع تبدأ بأحد هذه القيم متبوعة بنقطة. هذا يعني أن الملف المحدد gangbang.javaسيؤخذ بعين الاعتبار ، لكن assemble.shليس. ومع ذلك ، سوف يفوتك العديد من الخيارات المختلفة ، مثل pu55syg4rgle.javaالأسماء الأخرى غير المتساوية.تحتوي قائمتي بعض الكلمات على leetspeak، مثل b00bs، و b1tchللقبض على بعض القضايا المثيرة للاهتمام. قائمة كاملة هنا.على الرغم من أن هذا ليس دقيقًا تمامًا ، كما ذُكر سابقًا ، إلا أنه من المثير للإعجاب النظر إلى النتيجة. لنبدأ بقائمة اللغات التي بها أكثر اللعنات. ربما ، يجب أن تربط النتيجة بالمبلغ الإجمالي للرمز في كل لغة. إذن ها هم القادة.! مثيرة للاهتمام فكرتي الأولى كانت: "أوه ، هؤلاء المطورين المشاغبين!" لكن على الرغم من العدد الكبير لمثل هذه الملفات ، فإنهم يكتبون الكثير من الشفرة بحيث تضيع نسبة الشتائم في المبلغ الإجمالي. ومع ذلك ، من الواضح أن مطوري Dart لديهم بعض الكلمات في ترسانتهم! إذا كنت تعرف أحد مبرمجي Dart ، فيمكنك مصافحة.أريد أيضًا أن أعرف ما هي اللعنات الأكثر استخدامًا. لنلقِ نظرة على العقل الجماعي القذر المشترك. بعض من أفضل ما وجدته أسماء عادية (إذا قمت بالتحديق) ، لكن معظم الآخرين سيفاجئون الزملاء وبعض التعليقات في طلبات المجموعة.يرجى ملاحظة أن بعض الكلمات المسيئة في القائمة تحتوي على أسماء ملفات مطابقة ، والتي أجدها مروعة جدًا. لحسن الحظ ، فهي ليست شائعة جدًا ولا يتم تضمينها في القائمة أعلاه ، والتي تقتصر على الملفات التي يزيد عددها عن 100. آمل أن تكون هذه الملفات موجودة فقط لاختبار قوائم السماح / الرفض وما شابه ذلك.أكبر الملفات حسب عدد الأسطر في كل لغة
كما هو متوقع ، يشغل النص العادي و SQL و XML و JSON و CSV المراكز العليا: فهي تحتوي عادةً على بيانات التعريف ومقالب قاعدة البيانات وما شابه.المذكرة.
قد لا تعمل بعض الروابط أدناه بسبب بعض المعلومات الإضافية عند إنشاء الملفات. يجب أن يعمل معظمهم ، لكن بالنسبة للبعض ، قد تحتاج إلى تعديل عنوان URL قليلاً.ما هو الملف الأكثر تعقيدًا في كل لغة؟
مرة أخرى ، لا يمكن مقارنة هذه القيم بشكل مباشر مع بعضها البعض ، ولكن من المثير للاهتمام معرفة ما يعتبر الأكثر صعوبة في كل لغة.بعض هذه الملفات وحوش مطلقة. على سبيل المثال ، ضع في اعتبارك ملف C ++ الأكثر تعقيدًا الذي وجدته: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp : إنه 28.3 ميغابايت من برنامج التحويل البرمجي للجحيم (ولحسن الحظ ، يتم إنشاؤه تلقائيًا).المذكرة.
قد لا تعمل بعض الروابط أدناه بسبب بعض المعلومات الإضافية عند إنشاء الملفات. يجب أن يعمل معظمهم ، لكن بالنسبة للبعض ، قد تحتاج إلى تعديل عنوان URL قليلاً.الملف الأكثر تعقيدًا فيما يتعلق بعدد الأسطر؟
يبدو جيدًا من الناحية النظرية ، ولكن في الحقيقة ... شيء مصغر أو بدون فواصل الأسطر يشوه النتائج ، مما يجعلها بلا معنى. لذلك ، أنا لا نشر نتائج العمليات الحسابية. ومع ذلك، أنا خلق تذكرة في sccكان الدعم كشف تصغير الحجم لحذفها من حساب النتائج.ربما يمكنك استخلاص بعض الاستنتاجات بناءً على البيانات المتاحة ، لكنني أريد أن يستفيد جميع المستخدمين من هذه الميزة scc.ما هو الملف الأكثر تعليقًا في كل لغة؟
ليس لدي أي فكرة عن المعلومات القيمة التي يمكنك الحصول عليها من هذا ، ولكن من المثير للاهتمام أن نرى.المذكرة.
قد لا تعمل بعض الروابط أدناه بسبب بعض المعلومات الإضافية عند إنشاء الملفات. يجب أن يعمل معظمهم ، لكن بالنسبة للبعض ، قد تحتاج إلى تعديل عنوان URL قليلاً.«»
«» . , , . , 25 , .
.
, , , markdown, json, yml, css, .gitignore,
scc . , , , «» ( ), . , , , .
ما أدهشني هو طفرة غريبة حول 34-35 لغة. ليس لدي أي تفسير معقول للمكان الذي جاء منه ، وربما هذا يستحق التحقيق المنفصل.
مشاريع مع TypeScript ولكن ليس JavaScript
آه ، العالم الحديث من TypeScript. ولكن بالنسبة لمشاريع TypeScript ، فكم عدد هذه اللغات المحض؟يجب أن أعترف ، أنا مندهش قليلاً من هذا الرقم. على الرغم من أنني أفهم أن مزج JavaScript مع TypeScript أمر شائع إلى حد ما ، إلا أنني أعتقد أنه سيكون هناك المزيد من المشاريع باللغة الجديدة. ولكن من المحتمل أن تؤدي مجموعة أحدث من المستودعات إلى زيادة أعدادها بشكل كبير.هل أي شخص يستخدم CoffeeScript و TypeScript؟
أشعر أن بعض مطوري TypeScript يمرضون من فكرة ذلك. إذا كان هذا يساعدهم ، يمكنني أن أفترض أن معظم هذه المشاريع هي برامج مثل sccأمثلة لجميع اللغات لأغراض الاختبار.ما هو طول المسار النموذجي في كل لغة
نظرًا لأنه يمكنك إما تحميل جميع الملفات التي تحتاجها في دليل واحد أو إنشاء نظام دليل ، ما هو طول المسار المعتاد وعدد الأدلة؟للقيام بذلك ، حساب عدد خطوط مائلة في المسار لكل ملف ومتوسط. لم أكن أعرف ما الذي يمكنني توقعه هنا ، فيما عدا أن Java قد تكون في أعلى القائمة ، نظرًا لوجود مسارات طويلة للملفات.YAML أو YML؟
كان هناك مرة واحدة "مناقشة" في سلاك - باستخدام .yaml أو .yml. قتل كثيرون هناك على الجانبين.قد ينتهي النقاش في النهاية؟ على الرغم من أنني أظن أن البعض ما زالوا يفضلون الموت في نزاع.العلوية أو السفلية أو المختلطة
ما هو السجل المستخدم لأسماء الملفات؟ نظرًا لأنه لا يزال هناك امتداد ، يمكننا أن نتوقع ، بشكل أساسي ، حالة مختلطة.وهذا بالطبع ليس مثيرًا للاهتمام ، لأن عادةً ما تكون امتدادات الملفات صغيرة. ماذا لو تجاهل التمديدات؟ليس ما كنت أتوقع. مرة أخرى ، مختلطة في الغالب ، ولكن كنت أعتقد أن الجزء السفلي سيكون أكثر شعبية.مصانع في جاوة
فكرة أخرى توصل إليها الزملاء عند النظر في بعض رموز جافا القديمة. اعتقدت ، لماذا لا تضيف التحقق من أي كود جافا حيث يظهر Factory أو FactoryFactory أو FactoryFactoryFactory في العنوان. والفكرة هي تقدير عدد هذه المصانع.لذلك ، تبين أن أكثر من 2٪ من كود جافا هو مصنع أو مصنع. لحسن الحظ ، لم يتم العثور على المصنع. ربما تموت هذه النكتة أخيرًا ، على الرغم من أنني متأكد من أن واحدة على الأقل من الخطورة العودية المتعددة المستوى لا تزال تعمل في مكان ما في نوع واحد من Java 5 ، وهي تجني أموالًا كل يوم أكثر مما رأيته في حياتي المهنية بأكملها. .تجاهل الملفات
تم تطوير فكرة ملفات .ignore بواسطة burntsushi و ggreer في مناقشة حول Hacker News . ربما يكون هذا أحد أفضل الأمثلة لأدوات المصدر المفتوح "المنافسة" التي تعمل مع نتائج جيدة ويتم إكمالها في وقت قياسي. لقد أصبح المعيار الفعلي لإضافة رمز ستجاهله الأدوات. sccيفي أيضًا بقاعدة .ignore ، لكنه يعرف أيضًا كيفية حسابها. دعونا نرى مدى انتشار الفكرة.أفكار للمستقبل
أحب القيام ببعض التحليلات للمستقبل. سيكون من الجيد مسح أشياء مثل مفاتيح AWS AKIA وما شابه ذلك. أود أيضًا توسيع تغطية مشاريع Bitbucket و Gitlab مع تحليل لكل منها ، لمعرفة ما إذا كان هناك فرق تطوير من مناطق مختلفة معلقة هناك.إذا كررت المشروع من قبل ، أود أن أتغلب على أوجه القصور التالية وأخذ الأفكار التالية في الاعتبار.- قم بتخزين عناوين URL في مكان ما في البيانات الأولية بشكل صحيح. كان استخدام اسم ملف لتخزينه فكرة سيئة ، حيث يتم فقد المعلومات وقد يكون من الصعب تحديد مصدر الملف وموقعه.
- لا تهتم مع S3. من المنطقي أن أدفع مقابل حركة المرور إذا كنت أستخدمها فقط للتخزين. كان من الأفضل منذ البداية طرح كل شيء في ملف tar.
- , .
- -n , , , .
- scc, , . , CIDE.C C, , HTML. .
- , scc, , , . .
- أرغب في إضافة كشف shebang إلى scc .
- سيكون من الجميل أن نفكر بطريقة ما في عدد النجوم على جيثب وعدد مرات ارتكابها.
- أريد أن أضيف بطريقة ما حساب مؤشر الصيانة. سيكون من الجيد جدًا معرفة أي المشاريع تعتبر الأكثر رواجًا اعتمادًا على حجمها.
لماذا هذا كله؟
حسنًا ، يمكنني أخذ بعض هذه المعلومات واستخدامها في محرك البحث وبرنامج searchcode.com scc. على الأقل بعض نقاط البيانات المفيدة. في البداية ، تم تصميم المشروع بعدة طرق من أجل هذا. بالإضافة إلى ذلك ، من المفيد جدًا مقارنة مشروعك مع الآخرين. كانت أيضًا طريقة ممتعة لقضاء عدة أيام في حل بعض المشكلات المثيرة للاهتمام. وفحص موثوقية جيدة ل scc.بالإضافة إلى ذلك ، أعمل حاليًا على أداة تساعد المطورين أو المديرين الرئيسيين على تحليل الشفرة ، والبحث عن لغات معينة ، والملفات الكبيرة ، والعيوب ، وما إلى ذلك ... مع افتراض أنك بحاجة إلى تحليل عدة مستودعات. تقوم بإدخال نوع من التعليمات البرمجية ، وتوضح الأداة مدى قابليته للصيانة والمهارات اللازمة لصيانته. يكون هذا مفيدًا عند تحديد ما إذا كنت ترغب في شراء نوع ما من قواعد الكود ، أو خدمتها ، أو للحصول على فكرة عن منتجك الخاص الذي يقدمه فريق التطوير. من الناحية النظرية ، ينبغي أن يساعد هذا الفرق على توسيع نطاق الموارد المشتركة. شيء مثل AWS Macie ، لكن بالنسبة للرمز - شيء من هذا القبيل أعمل عليه. أنا شخصياً أحتاج إلى هذا للعمل اليومي ، وأظن أن الآخرين قد يجدون طلباً لهذه الأداة ، على الأقل هذه هي النظرية.ربما يكون الأمر يستحق وضع هنا بعض أشكال التسجيل للمهتمين ...الملفات غير المعالجة / المعالجة
إذا كان هناك من يريد إجراء التحليل الخاص به وإجراء التصحيحات ، فإليك رابط للملفات التي تمت معالجتها (20 ميغابايت). إذا أراد شخص ما نشر ملفات أولية في المجال العام ، فأعلمني بذلك. هذا هو 83 غيغابايت من tar.gz ، والداخل يزيد قليلاً عن 1 تيرابايت. يتكون المحتوى من أكثر من 9 ملايين ملف JSON بأحجام مختلفة.UPD.
اقترح العديد من النفوس الجيدة وضع الملف ، يشار إلى الأماكن أدناه:من خلال استضافة ملف tar.gz ، بفضل CNCF للخادم لـ xet7 من مشروع Wekan .