مقدمة
ذات مرة كنت بحاجة إلى تنفيذ كتلة صغيرة من CAM (الذاكرة النقابية). بعد قراءة كيف يقوم Xilinx بهذا على BRAM (كتل الذاكرة الثابتة) أو على SRL16 (سجلات إزاحة 16 بت) ، شعرت بالحزن قليلاً ، لأن تطبيقاتهم استغرقت الكثير من المساحة. قررت أن أحاول القيام بذلك بنفسي. كان الخيار الأول هو تنفيذ الجبهة. إذا نظرنا إلى المستقبل ، فقد وصلني الأمر تقريبًا على الفور ، وكان التكرار المستهدف للتصميم 125 ميغاهيرتز فقط.
هندسة معمارية
لتبدأ ، والنظر في بيان المشكلة. لذلك ، نحن بحاجة إلى CAM صغير مع عرض كلمة من 8-64 بت وعمق 16-1024 كلمة. كنت بحاجة إلى بحث ثنائي في CAM ، ولكن تبين فيما بعد أن جعل TCAM (الذاكرة الترابطية الثلاثية) منه رخيص جدًا من حيث الموارد ويؤثر قليلاً على التوقيت. الحد الأدنى للتردد هو MHz 125 على عائلة Kintex7 . لنبدأ! سيتكون CAM الخاص بنا من هذه الأسطر ، كل منها سيتوافق مع عنوان واحد ويخزن كلمة واحدة:
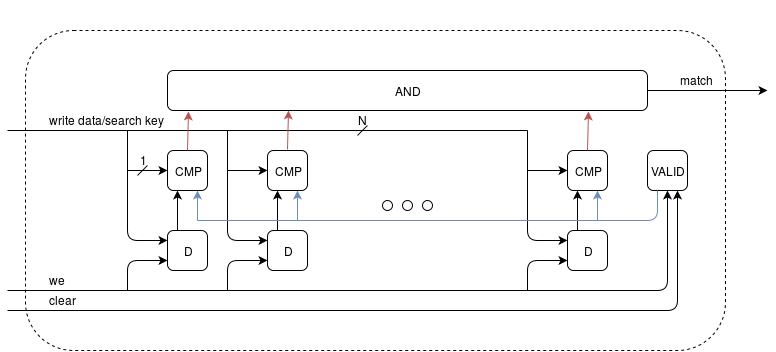
الشكل 1. هيكل سطر واحد من كام
في الشكل 1 ، D عبارة عن مشغل D منتظم لتخزين البيانات ؛ يتوافق عدد هذه المشغلات في السطر مع عرض كلمة بيانات الإدخال في CAM. VALID - D-trigger ، الذي يخزن "1" إذا كانت البيانات الموجودة في السطر ذات صلة. CMP عبارة عن مقارنة تقارن قيمة بت ناقل ناقل البحث المقابل إذا كانت VALID = '1'. كتابة البيانات - ناقل البيانات لكتابة bitwise متصلاً بـ D ( N - عرض كلمة CAM) المقابل ، نحن - كتابة إشارة ، واضح - إعادة تعيين VALID (إبطال سطر البيانات). AND - منطقي AND من مخرجات N من المقارنة ، تتحول علامة التطابق إلى "1" إذا نجح البحث في هذا السطر.
لذلك ، لدينا سطر واحد يمكننا البحث فيه. ادمجهم الآن:
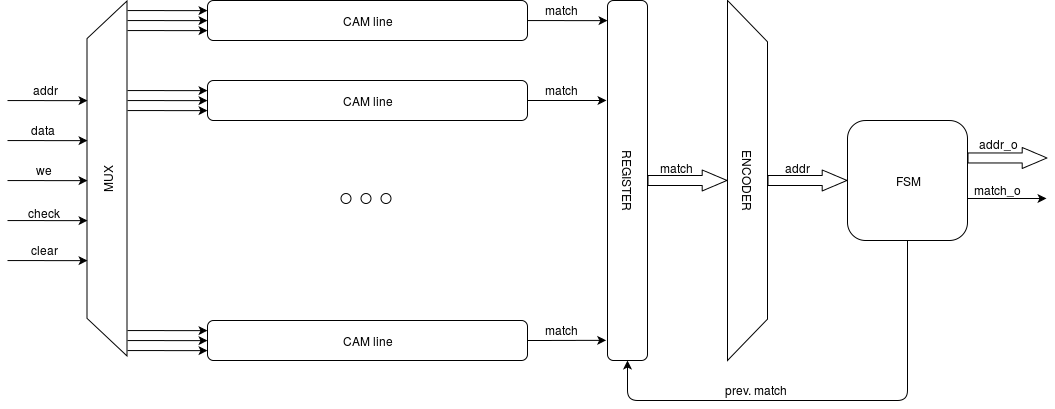
الشكل 2. هيكل CAM
في الشكل 2 ، CAM_line هو خط CAM نفسه من الشكل 1 ، MUX هو مُضاعِف عنوان الإدخال ، MATCH REGISTER هو سجل يخزن قيم علامة التطابق ، ENCODER هو وحدة فك ترميز تقوم بتحويل ناقل المطابقة إلى أدنى عنوان مطابقة موجود. FSM هي آلة مراقبة محدودة للدولة ، وهي سائدة. التطابق يزيل من السجل المطابق البت المطابق للعنوان المرسل بحيث ينتقل ENCODER إلى العنوان الموجود التالي. ستكون واجهة CAM الخاصة بنا كما يلي:
الجدول 1. CAM واجهة
في الشكل 3 أدناه ، يوجد مخطط توقيت لتشغيل هذه الواجهة ، والذي يُظهر أولاً تسجيل ثلاث كلمات في CAM ، ثم بحثًا ناجحًا ومحوها والبحث فيها مرة أخرى:

الشكل 3. الرسم البياني توقيت واجهة ل CAM
لذلك ، لدينا وصف CAM ، دعنا ننتقل إلى التوليف.
تركيب
سنقوم بتوليف في Xilinx ISE لمقارنة النتائج مع تلك التي تم الحصول عليها في XAPP1151 .
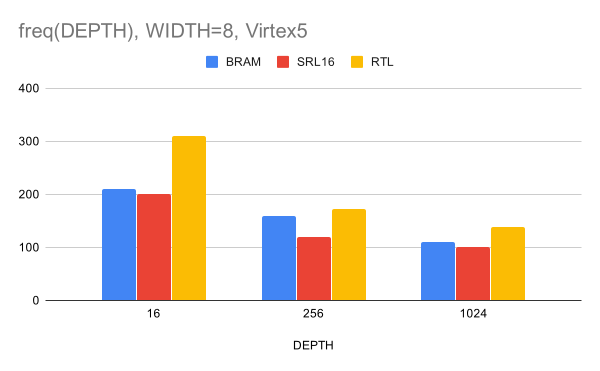
الشكل 4. الاعتماد على التردد بعد XST (المزج كجزء من ISE) على عمق CAM لعرض ناقل البيانات 8 بت
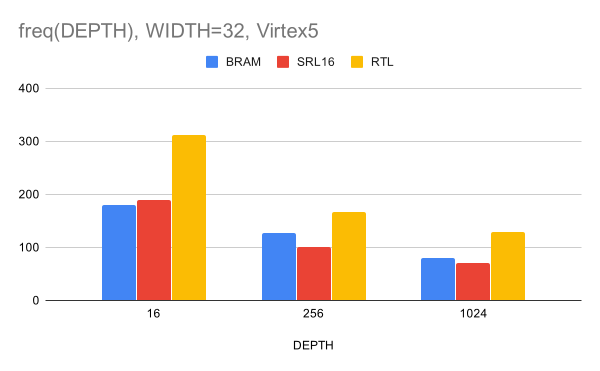
الشكل 5. التردد بعد XST مقابل عمق CAM لعرض ناقل البيانات 32 بت
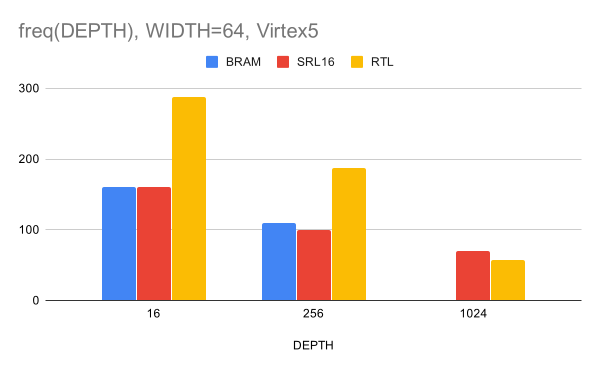
الشكل 6. التردد بعد XST مقابل عمق CAM لعرض ناقل البيانات 64 بت
في الشكل 6 ، لا توجد بيانات عن Virtex5 ، حيث إن CAM من هذا الحجم لا يتلاءم مع BRAM الحالي. نلاحظ أيضًا أنه نتيجة عرض 64 بت وعمق 1024 ، كانت نتيجةنا أسوأ قليلاً من نتيجة التنفيذ على SRL16. الآن دعنا ننتقل إلى Vivado التوليف ل XC7K325T . النتائج هي كما يلي:
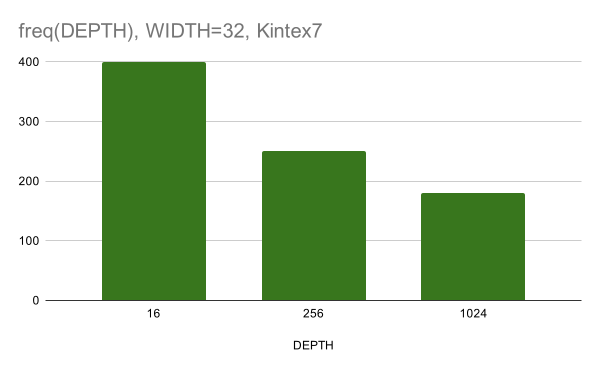
الشكل 7. الاعتماد على التردد بعد PnR (وضع الكتل على الشريحة وإشارة تتبع) على عمق CAM لعرض ناقل بيانات 32 بت
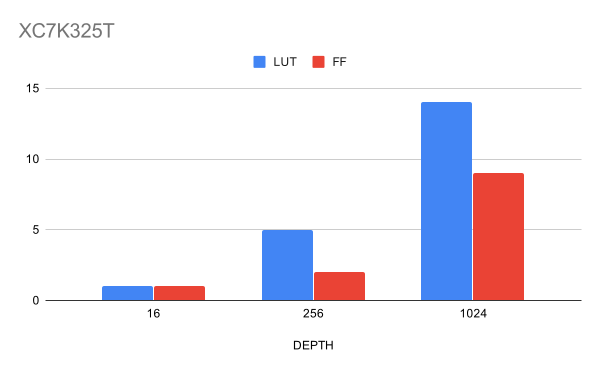
الشكل 8. استخدام الموارد لمختلف أعماق CAM لعرض بيانات تبلغ 32 بت في٪
من المهم ملاحظة أن النتائج على Vivado تم الحصول عليها بعد PnR ، مما يعني أن التصميم لا يواجه أي صعوبات في التتبع.
TCAM
كما ذكر أعلاه ، فإن الحصول على هذا النهج من CAM TCAM لم يكن مشكلة خاصة. يكفي إضافة ناقل تقنيع لبتات البيانات وتوزيعه شيئًا فشيئًا في المقارنات ، بحيث يراعون قيمته عند مقارنة البيانات بالمفتاح. لم يؤدي هذا التغيير إلى انخفاض في التكرار أو زيادة خطيرة في الموارد المستهلكة ، لذلك حصلنا على TCAM مجانًا.
النتائج
لذلك ، كنا قادرين على إكمال المهمة. يسمح التصميم الناتج لعائلة Xilinx FPGA السابعة باستقبال CAM كبير بدرجة كافية بتردد أعلى من 125 MHz الهدف. نتيجة المقارنة مع XAPP1151 لم تكن متوقعة بالنسبة لي ، افترضت أن التنفيذ على BRAM ، على الرغم من أنه مكلف للغاية من حيث الموارد ، سيتفوق على التنفيذ الجبلي بشكل متكرر. ومع ذلك ، لا تحتفل بالنصر مبكرًا ، تصف هذه الوثيقة جوهر Xilinx CAM IP ، والذي يسمح ، على سبيل المثال ، بالحصول على CAM بعمق 32 كيلو خلية وتردد 155 ميجاهرتز ، استنادًا إلى BRAM. يمكن تحقيق هذه النتيجة على الأرجح في المتغير المقترح في المقالة ، إما عن طريق إضافة مراحل خط الأنابيب ، أو عن طريق جمع CAM كبيرة من صغيرة ، لكن لا يمكنني التنبؤ على الفور ما إذا كان سيتم احتواؤها في الشريحة أم لا. سأحاول في المستقبل تطبيق شيء مماثل على برنامج BRAM ، لكن في الوقت الحالي ، شكرًا على اهتمامك.