التعلم الآلي الحديث يسمح لك أن تفعل أشياء لا تصدق. تعمل الشبكات العصبية لصالح المجتمع: فهي تجد مجرمين ، وتتعرف على التهديدات ، وتساعد في تشخيص الأمراض وتتخذ قرارات صعبة. يمكن أن تتفوق الخوارزميات على الشخص في الإبداع: فهي ترسم الصور وتكتب الأغاني وتصنع روائع من الصور العادية. وغالبا ما يتم تقديم أولئك الذين يطورون هذه الخوارزميات كعلماء كاريكاتوريين.
ليس كل شيء مخيف جدا! يمكن لأي شخص مطلع إلى حد ما على البرمجة إنشاء شبكة عصبية من النماذج الأساسية. وليس من الضروري تعلم بايثون ، كل شيء يمكن القيام به في JavaScript الأصلي. قال
Aleksey Okhrimenko (
obenjiro ) في
FrontendConf ، إنه من السهل البدء ولماذا
هناك حاجة إلى التعلم الآلي
للبائعين الأماميين ، وقمنا بنقله إلى النص بحيث أصبحت أسماء الهندسة المعمارية والروابط المفيدة في متناول اليد.
المفسد. تنبيه!
هذه القصة:
- ليس لأولئك الذين يعملون بالفعل مع التعلم الآلي. سيكون هناك شيء مثير للاهتمام ، لكن من غير المرجح أن تنتظر الافتتاح في ظل الخفض.
- ليس حول نقل التعلم. لن نتحدث عن كيفية كتابة شبكة عصبية في بيثون ، ثم العمل معها من JavaScript. لا غش - سنكتب شبكات عصبية عميقة على وجه التحديد على JS.
- ليس كل التفاصيل. بشكل عام ، لن تتوافق جميع المفاهيم مع مقال واحد ، لكننا بالطبع سوف نحلل ما هو ضروري.
نبذة عن المتحدث: يعمل أليكسي أوخريمنكو في شركة Avito في قسم Frontend Architecture ، وفي أوقات فراغه يُجري Angular Moscow Meetup ويصدر "Five Minute Angular". خلال حياته المهنية الطويلة ، قام بتطوير نمط التصميم MALEVICH ، وهو محلل قواعد اللغة PEG ، SimplePEG. يشارك مشرف صيانة Alexey CSSComb بانتظام المعرفة حول التقنيات الجديدة في المؤتمرات وفي
قناته برقية JS للتعلم الآلي.
آلة التعلم تحظى بشعبية كبيرة.
يتمتع المساعدون الصوتيون ، Siri ، مساعد Google ، Alice ، بشعبية وغالبًا ما يتم العثور عليهم في حياتنا. لقد تحولت العديد من المنتجات من معالجة البيانات الخوارزمية التقليدية إلى التعلم الآلي. مثال صارخ هو ترجمة جوجل.
تعتمد جميع الابتكارات وأروع الرقائق في الهواتف الذكية على التعلم الآلي.

على سبيل المثال ، يستخدم Google NightSight التعلم الآلي. لم يتم الحصول على الصور الرائعة التي نراها بالعدسات أو المستشعرات أو الثبات ، ولكن بمساعدة التعلم الآلي. أخيراً ، ضربت الآلة الناس في DOTA2 ، مما يعني أن لدينا فرصة ضئيلة لهزيمة الذكاء الاصطناعي. لذلك ، يجب علينا إتقان تعلم الآلة في أسرع وقت ممكن.
لنبدأ بكل بساطة
ما هو روتين البرمجة اليومي لدينا ، كيف نكتب عادة وظائف؟

نحن نأخذ البيانات والخوارزمية التي اخترعناها أو أخذناها من تلك الشعبية الجاهزة ، والجمع ، والقيام ببعض السحر والحصول على وظيفة تعطينا الإجابة الصحيحة في موقف معين.
لقد اعتدنا على هذا الترتيب للأشياء ، ولكن ستكون هناك فرصة كهذه ، دون معرفة الخوارزمية ، ولكن ببساطة الحصول على البيانات والإجابة ، احصل على الخوارزمية منها.

يمكنك أن تقول: "أنا مبرمج ، يمكنني دائمًا كتابة خوارزمية".
حسنًا ، ولكن على سبيل المثال ، ما الخوارزمية المطلوبة هنا؟

لنفترض أن القطة لها آذان حادة وأن آذان الكلب مملتان وصغيرة مثل الصلصال.

دعونا نحاول أن نفهم من هو الذي من الأذنين. ولكن في مرحلة ما ، اكتشفنا أن الكلاب يمكن أن يكون لها آذان حادة.

فرضيتنا ليست جيدة ، نحن بحاجة إلى خصائص أخرى. بمرور الوقت ، سوف نتعلم المزيد والمزيد من التفاصيل ، مما يؤدي إلى تثبيط أنفسنا أكثر وأكثر ، وفي وقت ما نريد إنهاء هذا العمل تمامًا.
أتصور صورة مثالية مثل هذه: مقدماً هناك إجابة (نحن نعرف نوع الصورة التي هي) ، هناك بيانات (نعلم أن قطة مرسومة) ، نريد الحصول على خوارزمية يمكن أن تغذي البيانات والحصول على إجابات في الإخراج.
هناك حل - هذا هو التعلم الآلي ، وهو أحد أجزائه - الشبكات العصبية العميقة.
الشبكات العصبية العميقة
التعلم الآلي هو مساحة ضخمة. إنه يوفر كمية هائلة من الأساليب ، وكل منها جيدة بطريقتها الخاصة.
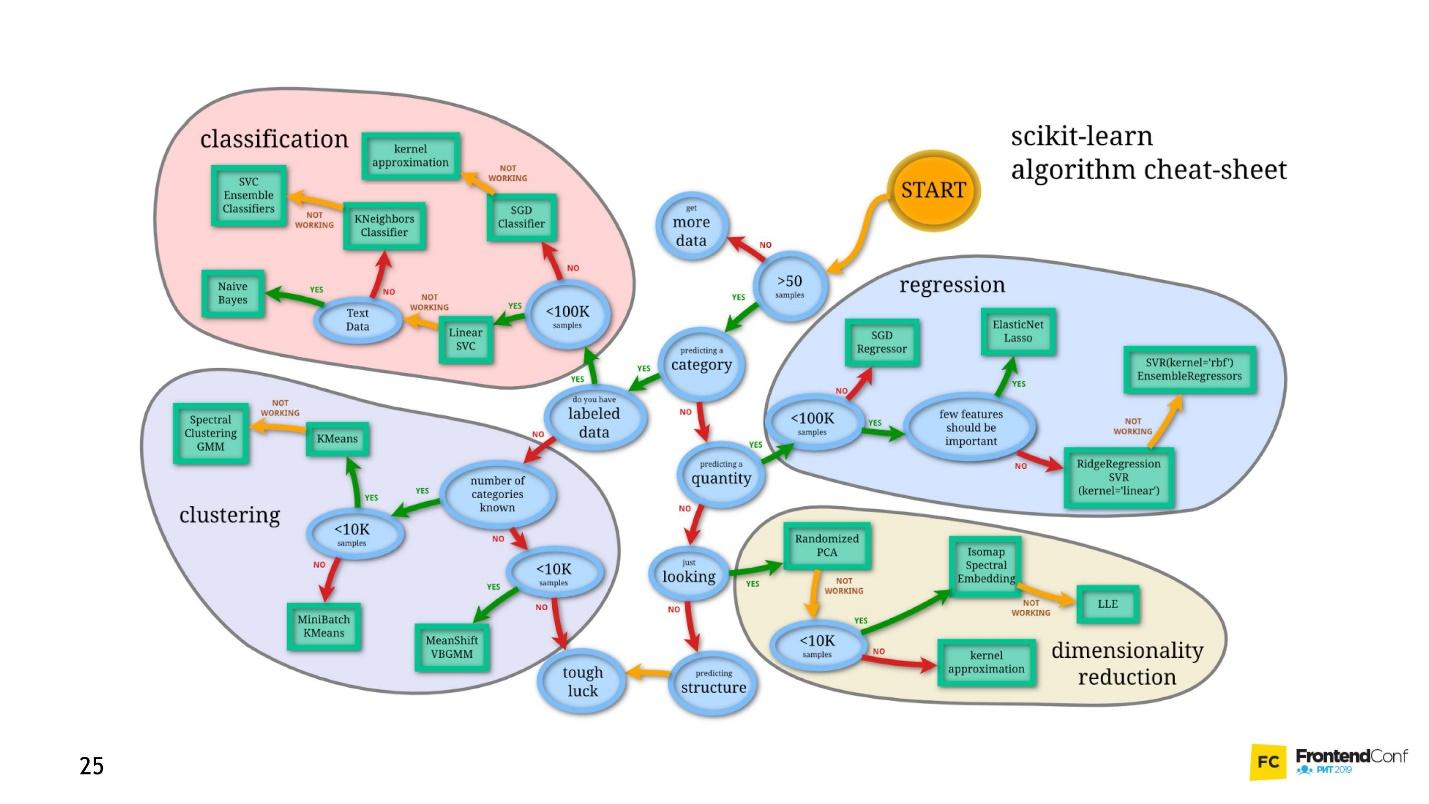
واحد منهم هو الشبكات العصبية العميقة. التعلم العميق له ميزة لا يمكن إنكارها نظرًا لأنه أصبح شائعًا.
لفهم هذه الميزة ، دعونا ننظر إلى مشكلة التصنيف الكلاسيكي باستخدام القطط والكلاب كمثال.
هناك بيانات: صور أو صور. أول شيء يجب فعله هو التضمين (التضمين) ، أي تحويل البيانات بحيث تكون الآلة مريحة في العمل معها. من غير الملائم العمل مع الصور ، فالسيارة تحتاج إلى شيء أكثر بساطة.
أولاً ، قم بمحاذاة الصور وإزالة اللون. بغض النظر عن لون الكلب أو القط ، من المهم تحديد نوع الحيوان. ثم نحول الصور إلى صفائف ، على سبيل المثال ، 0 مظلمة ، 1 ضوء.

باستخدام هذا العرض التقديمي للبيانات ، يمكن أن تعمل الشبكات العصبية بالفعل.
لنقم بإنشاء صفيفين آخرين ودمجهما في "طبقة" معينة. بعد ذلك ، نقوم بضرب كل عنصر من عناصر الطبقة ومصفوفة البيانات مع بعضها البعض باستخدام مضاعفة مصفوفة بسيطة ، ونقوم بتوجيه النتيجة إلى وظيفتين للتنشيط (سنقوم لاحقًا بتحليل ماهية هذه الوظائف). إذا تلقت وظيفة التنشيط عددًا كافٍ من القيم ، فسيتم "تنشيطها" وستنتج النتيجة:
- ستُرجع الدالة الأولى 1 إذا كانت قطة ، و 0 إذا لم تكن قطة.
- سوف ترجع الوظيفة الثانية 1 إذا كان كلبًا ، و 0 إن لم تكن كلبًا.
تسمى هذه الطريقة في تشفير استجابة
One-Hot Encoding .

بالفعل ، العديد من ميزات الشبكات العصبية العميقة ملحوظة:
- للعمل مع الشبكات العصبية ، تحتاج إلى تشفير البيانات عند الإدخال وفك التشفير عند الإخراج.
- يسمح لنا الترميز بالاستخلاص من البيانات.
- من خلال تغيير بيانات الإدخال ، يمكننا إنشاء شبكات عصبية لنطاقات مجال مختلفة. حتى تلك التي لسنا خبراء.
ليس من الضروري معرفة ماهية القطط ، ما هو الكلب. يكفي تحديد الأرقام اللازمة لطبقة إضافية.
الشيء الوحيد الذي لا يزال غير واضح حتى الآن هو سبب تسمية هذه الشبكات "بالعمق".
كل شيء بسيط للغاية: يمكننا إنشاء طبقة أخرى (صفائف ووظائف التنشيط الخاصة بها). ونقل نتيجة طبقة إلى أخرى.
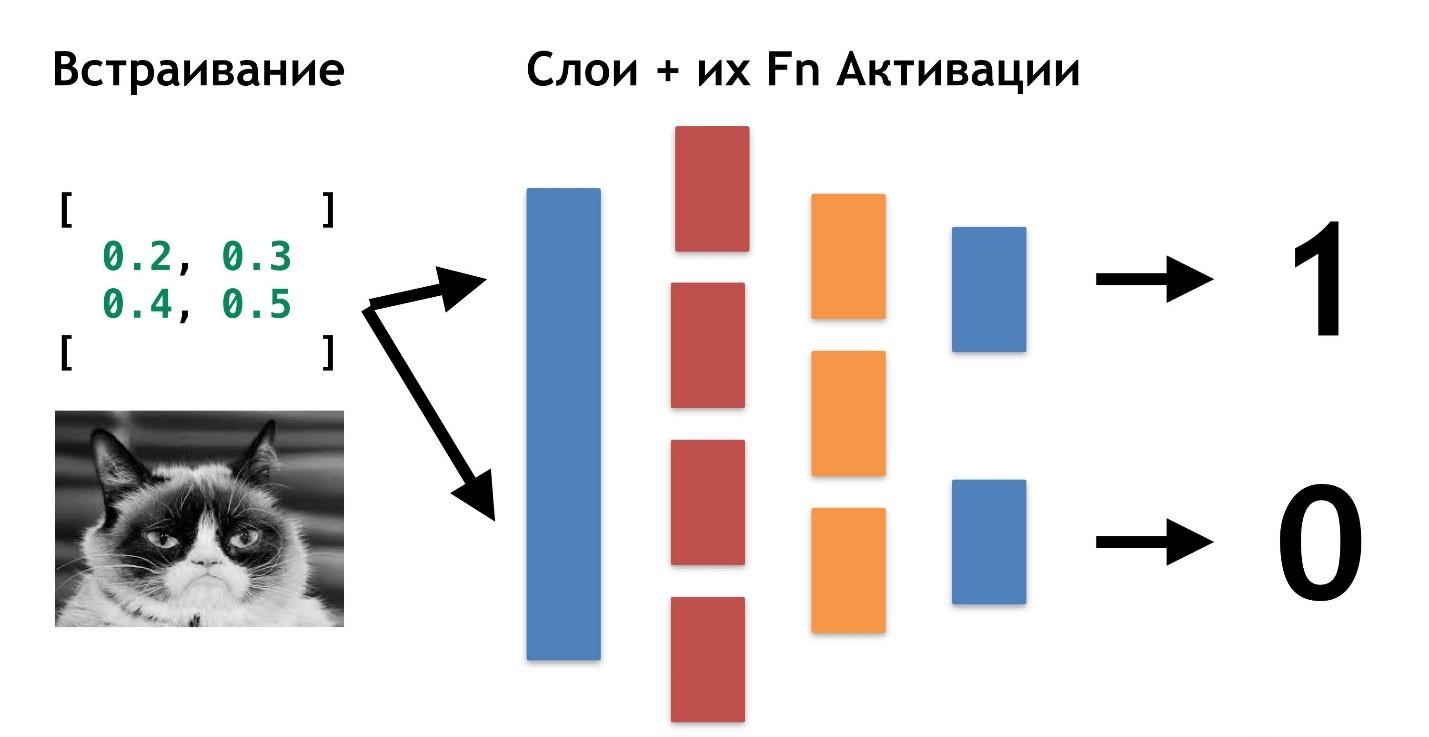
يمكنك وضع بعضها على بعض من هذه الطبقات ووظائفها للتنشيط. الجمع بين العمارة الطبقات ، نحصل على شبكة عصبية عميقة. عمقها هو العديد من الطبقات. ويطلق عليها مجتمعة
"النموذج" .
الآن دعونا نرى كيف يتم اختيار القيم لجميع هذه الطبقات. هناك
تصور رائع يتيح لك فهم كيفية حدوث عملية التعلم.
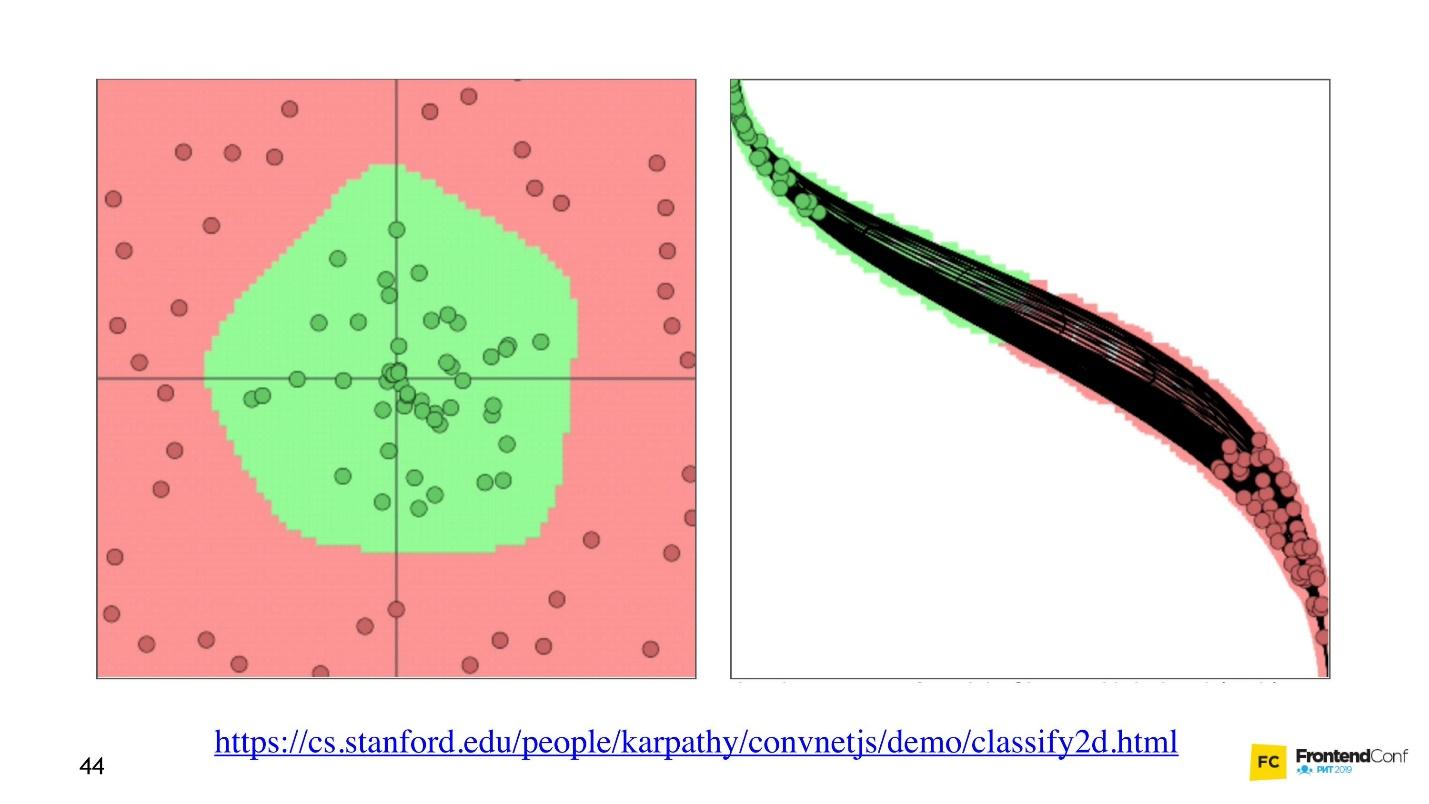
على اليسار توجد بيانات ، وعلى اليمين توجد إحدى الطبقات. يمكن ملاحظة أن تغيير القيم داخل صفائف الطبقة ، يبدو أننا نغير نظام الإحداثيات. وبالتالي التكيف مع البيانات والتعلم. وبالتالي ، فإن التعلم هو عملية اختيار القيم الصحيحة لصفائف الطبقة. تسمى هذه القيم أوزان أو أوزان.
التعلم الآلي صعب
أريد أن أزعجك ، التعلم الآلي صعب. كل ما سبق هو تبسيط كبير. في المستقبل ، ستجد كمية هائلة من الجبر الخطي ، ومعقدة للغاية. للأسف ، لا مفر من هذا.
بالطبع ، هناك دورات ، لكن حتى أسرع تدريب يستمر عدة أشهر وليس رخيصًا. بالإضافة إلى ذلك ، لا يزال يتعين عليك معرفة ذلك بنفسك. نما مجال التعلم الآلي بدرجة كبيرة بحيث أصبح من المستحيل تقريبًا تتبع كل شيء. على سبيل المثال ، فيما يلي مجموعة من النماذج لحل مهمة واحدة فقط (اكتشاف الكائن):

شخصيا ، كنت متحمسا جدا. لم أستطع الاقتراب من الشبكات العصبية وبدء العمل معهم. لكنني وجدت طريقة وأريد مشاركتها معك. انها ليست ثورية ، لا يوجد شيء من هذا القبيل في ذلك ، أنت بالفعل على دراية به.
Blackbox - منهج بسيط
ليس من الضروري أن تفهم تمامًا جميع جوانب التعلم الآلي من أجل معرفة كيفية تطبيق الشبكات العصبية على مهام عملك. سأعرض بعض الأمثلة التي نأمل أن تلهمك.
بالنسبة للكثيرين ، تعتبر السيارة أيضًا صندوقًا أسود. ولكن حتى لو كنت لا تعرف كيف تعمل ، فأنت بحاجة إلى معرفة القواعد. لذلك مع التعلم الآلي - لا تزال بحاجة إلى معرفة بعض القواعد:
- تعلم TensorFlow JS (مكتبة للعمل مع الشبكات العصبية).
- تعلم كيفية اختيار النماذج.
نحن نركز على هذه المهام ونبدأ مع الكود.
التعلم عن طريق إنشاء رمز
تتم كتابة مكتبة TensorFlow لعدد كبير من اللغات: Python و C / C ++ و JavaScript و Go و Java و Swift و C # و Haskell و Julia و R و Scala و Rust و OCaml و Crystal. لكننا بالتأكيد سنختار الأفضل - JavaScript.
يمكن توصيل TensorFlow بصفحتنا عن طريق توصيل برنامج نصي بـ CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
أو استخدم npm:
npm install @tensorflow/tfjs-node - لعملية العقدة (موقع الويب) ؛npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - من أجل وحدة معالجة الرسومات ، ولكن فقط إذا كانت آلة Linux وبطاقة الفيديو تدعم تقنية CUDA. تأكد من التأكد من أن CUDA Compute Capability تتطابق مع مكتبتك حتى لا تتحول إلى أن الأجهزة باهظة الثمن غير مناسبة.npm install @tensorflow/tfjs (Slowest / Browser) - لمتصفح دون استخدام Node.js.
للعمل مع TensorFlow JS ، يكفي استيراد إحدى الوحدات أعلاه. سترى العديد من أمثلة التعليمات البرمجية حيث يتم استيراد كل شيء. لا حاجة للقيام بذلك ، حدد واستورد واحدة فقط.
التنسورات
عندما تكون البيانات الأولية جاهزة ، فإن أول ما عليك فعله هو
استيراد TensorFlow . سوف نستخدم tensorflow / tfjs-node-gpu للحصول على تسارع بسبب قوة بطاقة الفيديو.
هناك مجموعة بيانات ثنائية الأبعاد - سنعمل معها.
الشيء المهم التالي هو
إنشاء موتر . في هذه الحالة ، يتم إنشاء الموتر من الرتبة 2 ، أي في الواقع صفيف ثنائي الأبعاد. ننقل البيانات ونحصل على الموتر 2x2.
لاحظ أن طريقة
print تسمى ، وليس
console.log ، لأن
b (الموتر الذي أنشأناه) ليس كائنًا عاديًا ، أي الموتر. لديه أساليبه وخصائصه.
يمكنك أيضًا إنشاء موتر من صفيف مستوي والحفاظ على شكله في الاعتبار ، دعنا نقول. وهذا هو ، لإعلان شكل - صفيف ثنائي الأبعاد - لنقل ببساطة صفيف مسطح والإشارة مباشرة إلى النموذج. والنتيجة ستكون هي نفسها.
نظرًا لحقيقة أنه يمكن تخزين البيانات والنموذج بشكل منفصل ، فمن الممكن تغيير شكل الموتر. يمكننا استدعاء طريقة
reshape وتغيير الشكل من 2x2 إلى 4x1.
الخطوة المهمة التالية هي
إخراج البيانات ، وإعادتها إلى العالم الحقيقي.
رمز لجميع الخطوات الثلاث.ترجع طريقة
data الوعد. بعد أن يتم حلها ، نحصل على القيمة المباشرة للقيمة الخام ، ولكن نحصل عليها بشكل غير متزامن. إذا أردنا ذلك ، يمكننا الحصول عليه بشكل متزامن ، لكن تذكر أنه يمكنك هنا فقدان الأداء ، لذا استخدم طرقًا غير متزامنة كلما أمكن ذلك.
طريقة
dataSync دائمًا بإرجاع البيانات بتنسيق صفيف ثابت. وإذا أردنا إرجاع البيانات بالتنسيق الذي يتم تخزينها به في الموتر ، نحتاج إلى استدعاء
arraySync .
مشغلي
جميع المشغلين في TensorFlow
غير قابلين
للتغيير بشكل افتراضي ، أي في كل عملية يتم إرجاع موتر جديد دائمًا. أعلاه ، ما عليك سوى أخذ صفيفنا ومربع جميع عناصره.
لماذا هذه الصعوبات لعمليات رياضية بسيطة؟ جميع المشغلين الذين نحتاجهم - المبلغ ، الوسيط ، إلخ - موجودون هناك. هذا ضروري لأنه في الواقع يسمح لك الموتر وهذا النهج بإنشاء رسم بياني للحسابات وإجراء العمليات الحسابية ليس على الفور ، ولكن على WebGL (في المستعرض) أو CUDA (Node.js على الجهاز). أي أن استخدام تسريع الأجهزة في الواقع غير مرئي لنا ، وإذا لزم الأمر ، فعل احتياطي على وحدة المعالجة المركزية. الشيء العظيم هو أننا لسنا بحاجة إلى التفكير في أي شيء حيال ذلك. نحن فقط بحاجة لمعرفة API tfjs.
الآن الشيء الأكثر أهمية هو النموذج.
نموذج
أسهل طريقة لإنشاء نموذج هي متسلسلة ، أي ، نموذج متسلسل ، عندما يتم نقل بيانات من طبقة إلى الطبقة التالية ، ومنه إلى الطبقة التالية. يتم استخدام أبسط الطبقات المستخدمة هنا.
الطبقة نفسها هي مجرد تجريد من tensors والمشغلين. تحدث تقريبًا ، هذه وظائف مساعدة تخفي قدرًا كبيرًا من الرياضيات عنك.
دعنا نحاول فهم كيفية التعامل مع النموذج دون الدخول في تفاصيل التنفيذ.
أولاً ، نشير إلى شكل البيانات التي تقع في الشبكة العصبية -
inputShape هو معلمة مطلوبة. نشير إلى
units - عدد المصفوفات متعددة الأبعاد ووظيفة التنشيط.
إن وظيفة
relu لافتة للنظر حيث تم العثور عليها بالصدفة - لقد جُربت ، وعملت بشكل أفضل ، ولفترة طويلة ، بحثوا عن تفسير رياضي لسبب حدوث ذلك.
بالنسبة للطبقة الأخيرة ، عندما نصنع فئة ، غالبًا ما تستخدم وظيفة softmax - وهي مناسبة تمامًا لعرض إجابة بتنسيق One-Hot Encoding. بعد إنشاء النموذج ، اتصل
model.summary() للتأكد من تجميع النموذج بالطريقة الصحيحة. في المواقف الصعبة بشكل خاص ، يمكنك التعامل مع نموذج باستخدام البرمجة الوظيفية.
إذا كنت بحاجة إلى إنشاء نموذج معقد بشكل خاص ، يمكنك استخدام الطريقة الوظيفية: في كل مرة يكون كل طبقة متغيرًا جديدًا. على سبيل المثال ، نأخذ الطبقة التالية يدويًا ونطبق الطبقة السابقة عليها ، حتى نتمكن من بناء أبنية أكثر تعقيدًا. سأريكم لاحقًا أين يمكن أن يكون هذا مفيدًا.
التفاصيل المهمة التالية هي أننا نقوم بتمرير طبقات المدخلات والمخرجات في النموذج ، أي الطبقات التي تدخل الشبكة العصبية والطبقات التي هي طبقات للإجابة.
بعد ذلك ، خطوة مهمة هي
تجميع النموذج . دعونا نحاول أن نفهم ما هو التجميع من حيث tfjs.
تذكر ، حاولنا إيجاد القيم الصحيحة في شبكتنا العصبية. ليس من الضروري التقاطها. يتم اختيارهم بطريقة معينة ، كما تقول وظيفة المحسن.
رمز لوصف الطبقات المتسلسلة والتجميع.سأوضح ماهية المحسن وما هي وظيفة الخسارة.
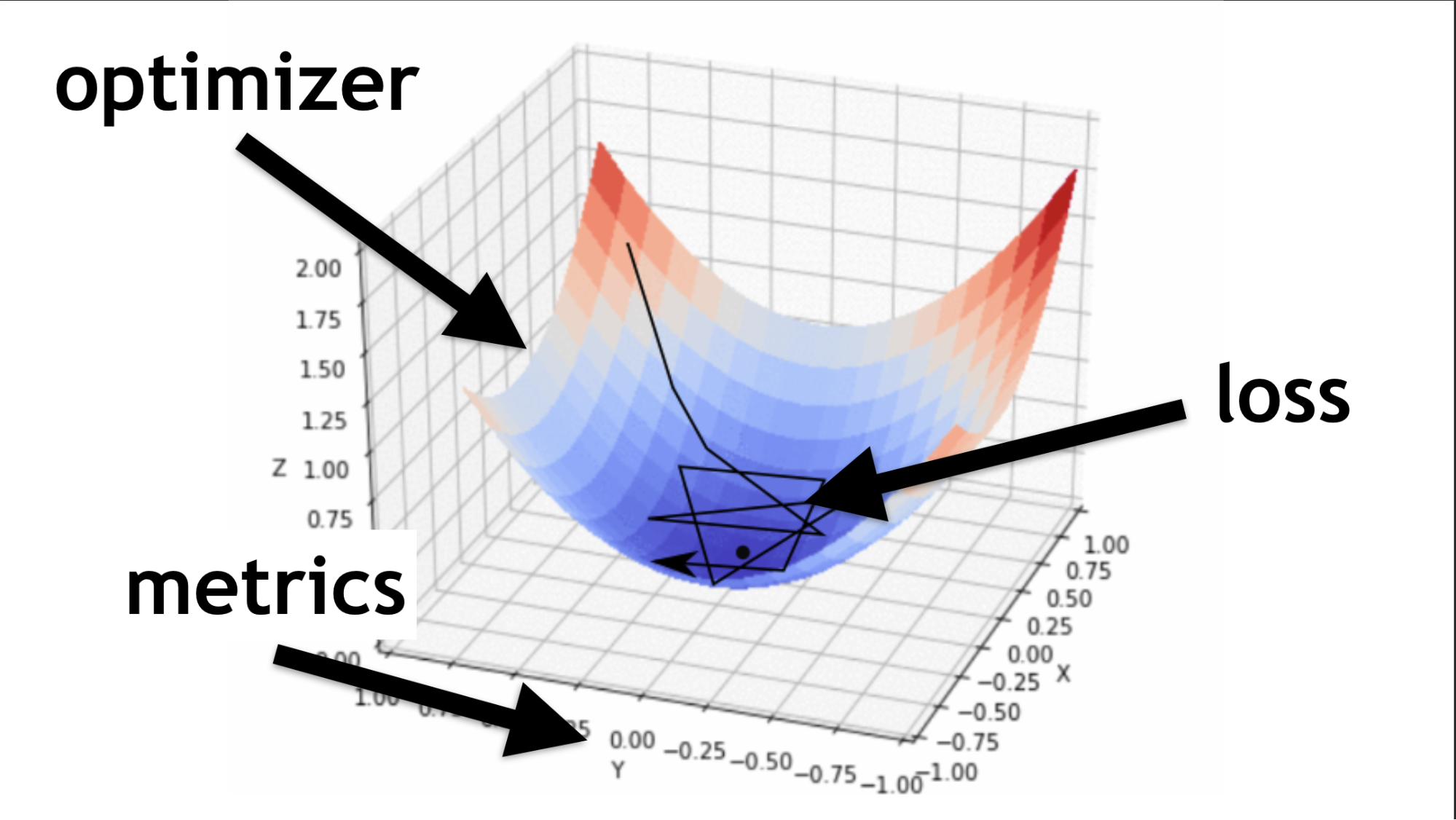
المحسن هو الخريطة بأكملها. يسمح لك ليس فقط بالتجول بشكل عشوائي والبحث عن القيمة ، ولكن للقيام بذلك بحكمة ، وفقًا لخوارزمية معينة.
وظيفة الخسارة هي الطريقة التي نبحث بها عن القيمة المثلى (السهم الأسود الصغير). إنها تساعد على فهم القيم المتدرجة التي يجب استخدامها لتدريب شبكتنا العصبية.
في المستقبل ، عندما تتقن الشبكات العصبية ، ستكتب وظيفة الخسارة بنفسك. يعتمد الكثير من نجاح الشبكة العصبية على مدى جودة هذه الوظيفة المكتوبة جيدًا. لكن هذه قصة أخرى. لنبدأ بسيطة.
مثال التعلم على الشبكة
سنقوم بإنشاء بيانات عشوائية وإجابات عشوائية (علامات). نحن ندعو وحدة
fit ، تمرير البيانات والإجابات والعديد من المعلمات الهامة:
epochs - 5 مرات ، أي ، تقريبًا ، 5 مرات سنقوم بإجراء تدريب كامل ؛batchSize ، الذي يوضح عدد الأوزان التي يمكن تغييرها في وقت واحد لرفعها - عدد العناصر المطلوب معالجتها في نفس الوقت. كلما كانت بطاقة الفيديو أفضل ، زادت الذاكرة ، زاد batchSize .
رمز جميع الخطوات الأخيرة.Model.fit طريقة غير متزامن ، يعود الوعد. ولكن يمكنك استخدام المزامنة / الانتظار وانتظار التنفيذ بهذه الطريقة.
يصل المقبل هو
استخدام . لقد قمنا بتدريب نموذجنا ، ثم نأخذ البيانات التي نريد معالجتها ، ونطلق على طريقة
predict ، ونقول: "توقع ما هو موجود بالفعل؟" ، وبفضل هذا نحصل على النتيجة.
هيكل قياسي
تحتوي كل شبكة عصبية على ثلاثة ملفات رئيسية:
- index.js - ملف يتم تخزين جميع معلمات الشبكة العصبية فيه ؛
- model.js - ملف يتم تخزين النموذج بهيكله مباشرة ؛
- data.js - ملف يتم فيه تجميع البيانات ومعالجتها ودمجها في نظامنا.
لذلك ، تحدثت عن كيفية تعلم TensorFlow.js. الأعمال التجارية الصغيرة ، يبقى
اختيار نموذج .
لسوء الحظ ، هذا ليس صحيحًا تمامًا. في الواقع ، في كل مرة تختار فيها نموذجًا ، يتعين عليك تكرار بعض الخطوات.
- قم بإعداد البيانات الخاصة به ، أي جعل التضمين ، واضبطه على الهيكل.
- قم بتهيئة إعدادات Hyper (سأخبرك لاحقًا بما يعنيه هذا).
- تدريب / تدريب كل شبكة عصبية (قد يكون لكل نموذج فروق دقيقة خاصة به).
- تطبيق نموذج عصبي ، ومرة أخرى ، يمكنك تطبيق بطرق مختلفة.
اختيار نموذج
لنبدأ بالخيارات الأساسية التي ستواجهها كثيرًا.
شعور عميق
هذا مثال شائع على شبكة عصبية عميقة. كل شيء يتم بكل بساطة: هناك مجموعة بيانات متاحة للجمهور - مجموعة بيانات MNIST.
هذه عبارة عن صور تحمل أرقامًا ، وعلى أساسها مناسب لتدريب شبكة عصبية.
وفقًا لهندسة ترميز One-Hot Encoding ، نقوم بتشفير كل طبقة من الطبقات الأخيرة. الأرقام 10 - وفقًا لذلك ، سيكون هناك 10 طبقات أخيرة في النهاية. نحن ببساطة نرسل صورًا بالأبيض والأسود عند المدخل ، كل هذا مشابه جدًا لما تحدثنا عنه في البداية.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
نقوم بتصويب الصورة في صفيف أحادي البعد ، ونحصل على 784 عنصرًا. في طبقة واحدة 512 صفائف. وظيفة التنشيط
'relu' .
الطبقة التالية للصفائف أصغر قليلاً (256) ، طبقة التنشيط هي أيضًا
'relu' . قللنا عدد المصفوفات للبحث عن المزيد من الخصائص العامة. يجب مطالبة الشبكة العصبية بكيفية التعلم ، وإجبارها على اتخاذ قرار عام أكثر جدية ، لأنها هي نفسها لن تفعل ذلك.
في النهاية ، نصنع 10 مصفوفات ونستخدم تنشيط softmax لترميز One-Hot Encoding - هذا النوع من التنشيط يعمل بشكل جيد مع هذا النوع من تشفير الاستجابة.
تسمح لك الشبكات العميقة بالتعرف بشكل صحيح على 80 إلى 90٪ من الصور - أريد المزيد. يتعرف الشخص بنوعية تصل إلى 96٪ تقريبًا. هل يمكن للشبكات العصبية إلقاء القبض على شخص وتجاوزه؟
CNN (الشبكة العصبية التلافيفية)
الشبكات التلافيفية تعمل بجنون. في النهاية ، لديهم نفس البنية كما في الأمثلة السابقة. ولكن في البداية ، يحدث شيء آخر. المصفوفات ، بدلاً من مجرد إعطاء بعض الحلول ، تقلل الصورة. يأخذون جزءًا من الصورة ويقللونها ، ينهار ، إلى رقم واحد. ثم يتم جمعها معا وتقليلها مرة أخرى.
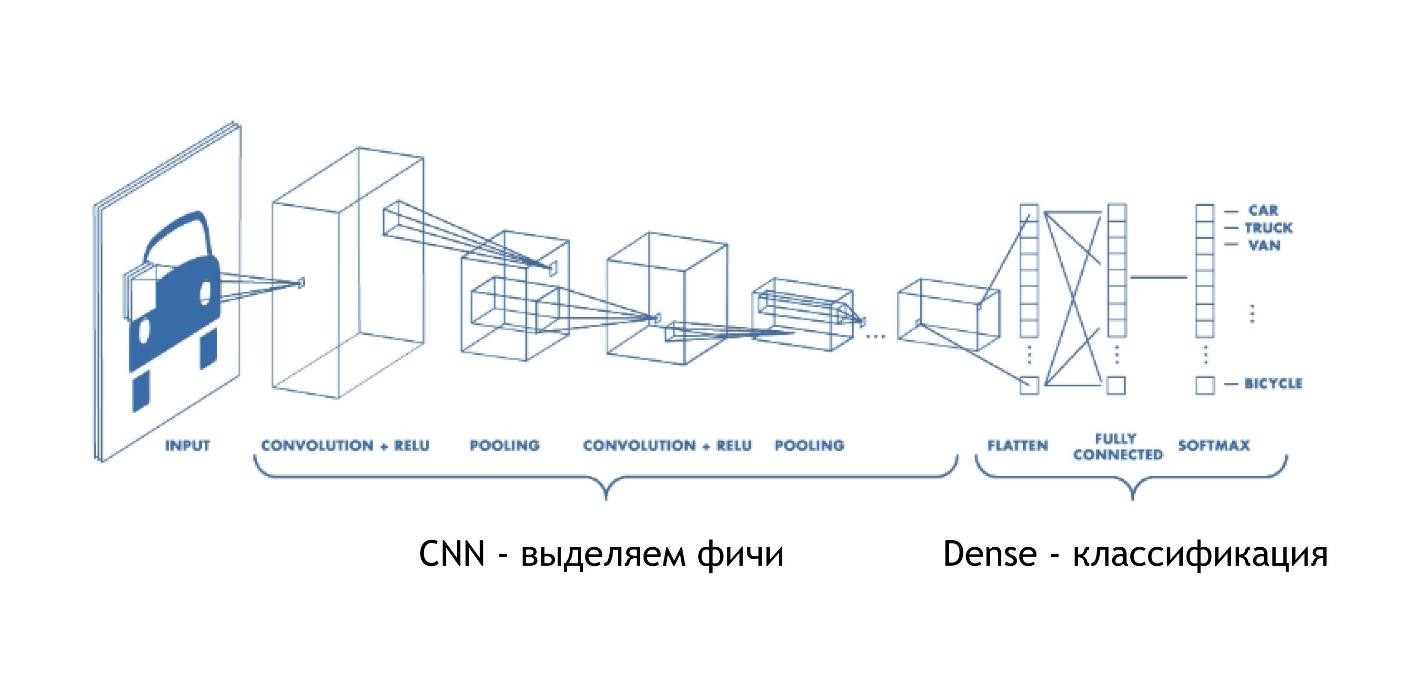
وبالتالي ، يتم تقليل حجم الصورة ، ولكن في نفس الوقت يتم التعرف على أجزاء الصورة بشكل أفضل وأفضل. تعمل شبكات الالتفاف بشكل جيد للغاية للتعرف على الأنماط ، حتى أفضل من البشر.
إن التعرف على الصور أفضل في السيارة من الشخص. كانت هناك دراسة خاصة ، والشخص ، للأسف ، فقد.
تعمل شبكات CNN بكل بساطة:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
نقوم بإدخال مجموعة محددة متعددة الأبعاد: صورة بحجم 28 × 28 بكسل ، بالإضافة إلى بُعد واحد للسطوع ، وفي هذه الحالة تكون الصورة بالأبيض والأسود ، وبالتالي فإن البعد الثالث هو 1.
بعد ذلك ، قمنا بتعيين عدد
filters kernelSize - كم عدد البكسل الذي سيتم
kernelSize . وظيفة التنشيط في كل مكان
relu .
هناك طبقة أخرى
maxPooling2d ، وهي ضرورية لتقليل الحجم بشكل أكثر كفاءة. تضيق الشبكات التلافيفية الحجم تدريجياً ، وغالباً ما لا تكون هناك حاجة لإنشاء شبكات تلافيفية عميقة جدًا.
سأشرح لماذا من المستحيل عمل شبكات تحويل عميقة جدًا بعد ذلك بقليل ، ولكن في الوقت الحالي ، تذكر: في بعض الأحيان يحتاجون إلى تجديد أسرع. هناك طبقة منفصلة maxPooling لهذا الغرض.
في النهاية هناك نفس الطبقة الكثيفة. أي باستخدام الشبكات العصبية التلافيفية ، استخرجنا العديد من العلامات من البيانات ، وبعد ذلك نستخدم النهج القياسي ونصنّف نتائجنا ، بفضل تعترفنا بالصور.
ش صافي
يرتبط هذا النموذج المعماري بشبكات الالتفاف. بفضل مساعدتها ، تم إجراء العديد من الاكتشافات في مجال مكافحة السرطان ، على سبيل المثال ، في التعرف على الخلايا السرطانية والزرق. علاوة على ذلك ، يمكن لهذا النموذج أن يجد خلايا خبيثة ليس أسوأ من أستاذ في هذا المجال.
مثال بسيط: من بين البيانات الصاخبة تحتاج إلى العثور على الخلايا السرطانية (الدوائر).

U-Net جيد جدًا بحيث يمكنه العثور عليها بشكل مثالي تقريبًا. العمارة بسيطة جدا:
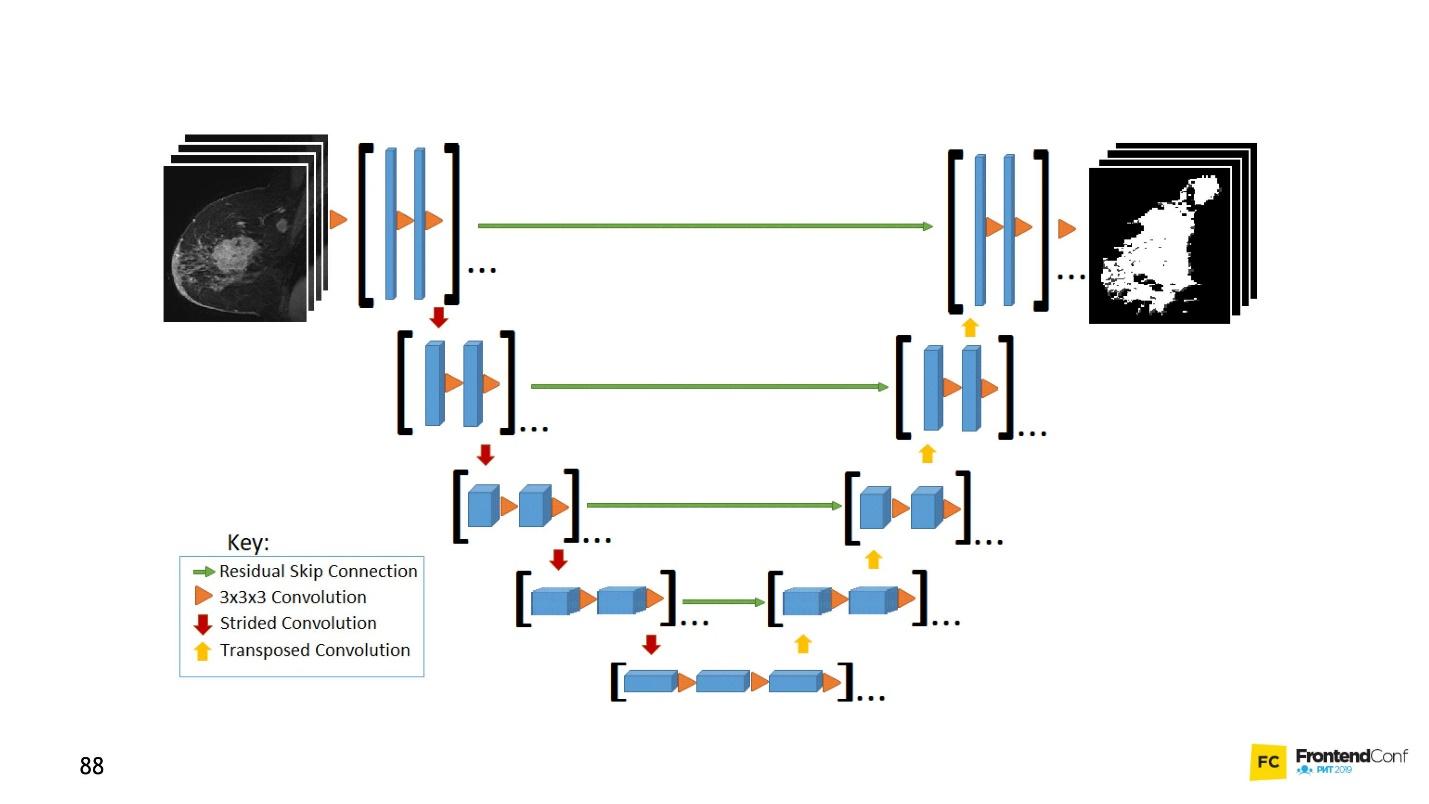
هناك شبكات الالتواء نفسها ، تمامًا كما يوجد MaxPooling ، مما يقلل من الحجم. الفرق الوحيد: يستخدم النموذج أيضًا شبكات
المسح الضوئي -
الشبكة غير الدستورية .
بالإضافة إلى فحص الالتفاف ، يتم دمج كل طبقة من الطبقات عالية المستوى مع بعضها البعض (البدء والخروج) ، بسبب ظهور عدد كبير من العلاقات. تعمل شبكة U-Net بشكل جيد حتى على كميات صغيرة من البيانات.
هذا الرمز هو أسهل للتعلم في المحرر. بشكل عام ، يتم إنشاء عدد كبير من شبكات الالتفاف هنا ، ومن ثم ، لننشرها مرة أخرى ، فإننا نقوم
concatenate ودمج عدة طبقات. هذا مجرد تصور لصورة ، فقط في شكل رمز. كل شيء بسيط للغاية - نسخ هذا النموذج واستنساخه أمر سهل.
LSTM (ذاكرة قصيرة المدى طويلة)
لاحظ أن جميع الأمثلة التي تم النظر فيها لها ميزة واحدة - تنسيق بيانات الإدخال ثابت. المدخلات على الشبكة ، يجب أن تكون البيانات من نفس الحجم وتتطابق مع بعضها البعض. وتركز نماذج LSTM على كيفية التعامل مع هذا.
على سبيل المثال ، هناك خدمة Yandex.Referats ، والتي تولد ملخصات.
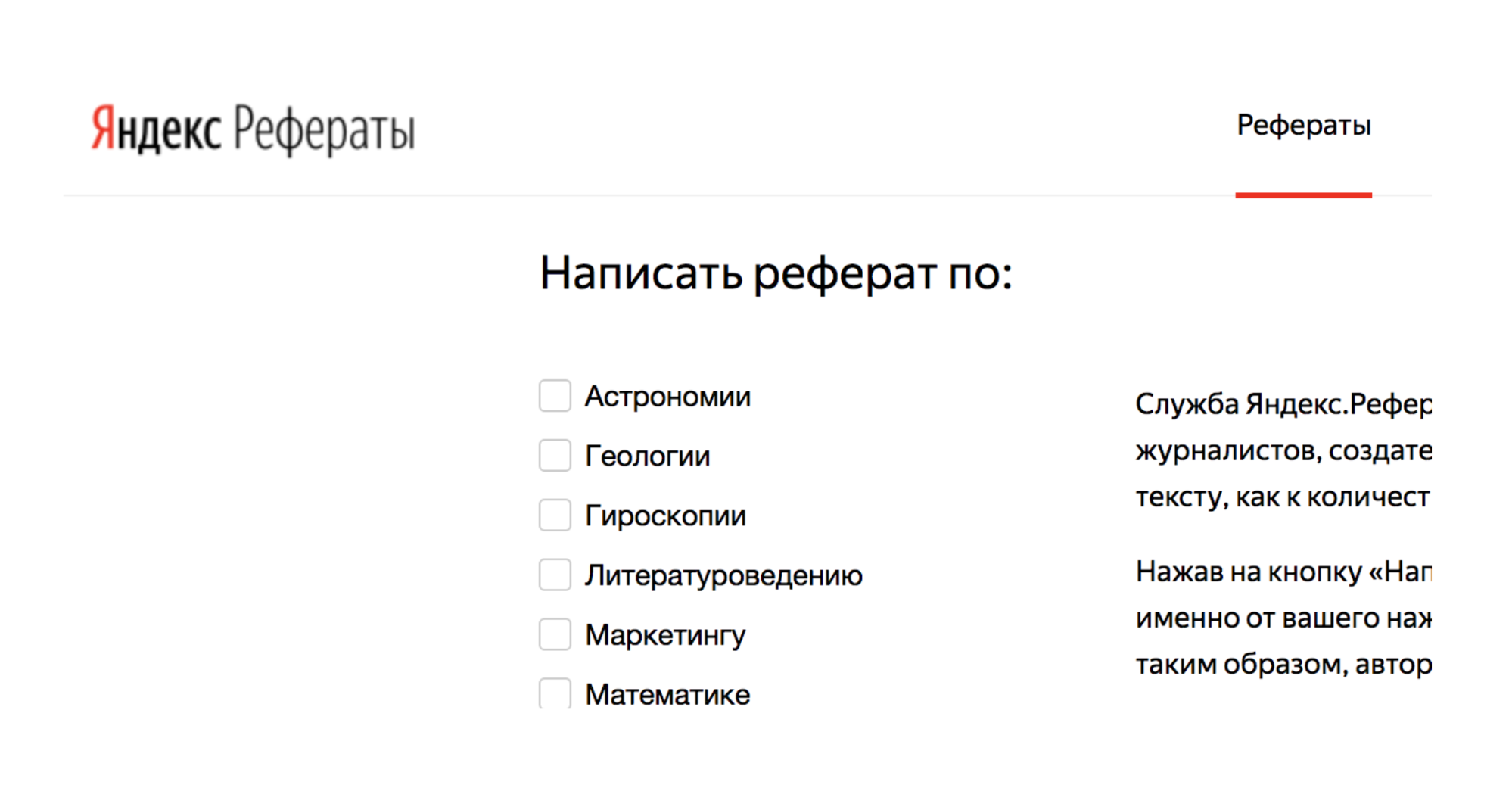
انه يعطي abracadabra كاملة ، ولكن في الوقت نفسه مشابهة تماما للحقيقة:
ملخص في الرياضيات حول موضوع: "ذات الحدين نيوتن كالبديهية"
وفقًا لما سبق ، ينتج تكامل السطح جزءًا لا يتجزأ من الخط المنحني. وظيفة محدب إلى أسفل لا يزال في الطلب.
ويترتب على ذلك بطبيعة الحال أن العادي إلى السطح لا يزال في الطلب. وفقا لما سبق ، يحدد بواسون جزءا لا يتجزأ أساسا من المثلثية بواسون لا يتجزأ.
تعتمد الخدمة على الشبكات العصبية من ساق إلى ساق. الهندسة المعمارية هي أكثر تعقيدا.

يتم ترتيب الطبقات في نظام معقد إلى حد ما. لكن لا تشعر بالقلق - ليس عليك أن تدير كل هذه الأسهم بنفسك. إذا كنت تريد ، يمكنك ، ولكن ليس من الضروري. هناك مساعد من شأنه أن يفعل هذا من أجلك.
الشيء الرئيسي الذي يجب فهمه هو أن كل قطعة من هذه القطع يتم دمجها مع القطعة السابقة. يأخذ البيانات ليس فقط من البيانات الأولية ، ولكن أيضا من الطبقة العصبية السابقة. بمعنى تقريبي ، من الممكن بناء نوع من الذاكرة - لحفظ سلسلة من البيانات وإعادة إنتاجها ، ونتيجة لهذا العمل "التسلسل إلى التسلسل". علاوة على ذلك ، يمكن أن تكون التسلسلات بأحجام مختلفة في كل من المدخلات والمخرجات.
كل شيء يبدو جميلا في الكود:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
هناك مساعد خاص يقول أن لدينا 512 كائنًا (صفائف). بعد ذلك ، قم بإرجاع التسلسل وإدخال النموذج (
inputShape: [10000, 64] ). بعد ذلك نقدم طبقة أخرى ، لكننا لا نرجع التسلسل (
returnSequences: false ) ، لأنه في النهاية نقول إننا بحاجة الآن إلى استخدام وظيفة التنشيط لـ 64 حرفًا مختلفًا (أحرف صغيرة وحروف كبيرة). يتم تنشيط 64 خيارًا باستخدام ترميز One-Hot Encoding.
الأكثر إثارة للاهتمام
الآن ، ربما تتساءل: "هذا جيد بالطبع ، لكن لماذا أحتاجه؟ "مكافحة السرطان جيدة ، لكن لماذا أحتاجها في الخط الأمامي؟"
وتبدأ الرقصات مع الدف: لمعرفة كيفية تطبيق الشبكات العصبية على التخطيط ، على سبيل المثال.
بمساعدة الشبكات العصبية ، يمكن حل المشكلات التي كان من المستحيل حلها سابقًا. البعض الذي لا يمكنك حتى التفكير فيه. كل هذا يتوقف عليك ، خيالك وممارسة القليل.
الآن سأعرض أمثلة مثيرة للاهتمام لاستخدام النماذج التي درسناها.
CNN. فرق الصوت
باستخدام شبكات الالتفاف ، يمكنك التعرف ليس فقط على الصور ، ولكن أيضًا على الأوامر الصوتية ، وبجودة التعرف على 97٪ ، أي على مستوى Google Assistant و Yandex-Alice.
على الشبكة وحدها ، بالطبع ، لا يمكن التعرف على الكلام الكامل والجمل ، ولكن يمكنك إنشاء مساعد صوتي بسيط.
يمكن العثور على مزيد من المعلومات حول Alice في
تقرير Nikita Dubko ، وعن مساعد Google ، وكيفية التعامل مع الصوت فيه ، وحول معايير المتصفح ،
هنا .
الحقيقة هي أن أي كلمة ، أي أمر يمكن أن يتحول إلى الطيفية.
يمكنك تحويل أي معلومات صوتية إلى مثل هذا الطيفية. وبعد ذلك يمكنك تشفير الصوت في الصورة ، وتطبيق CNN على الصورة والتعرف على الأوامر الصوتية البسيطة.
U-نت. لقطة للشاشة
U-Net مفيد ليس فقط لتشخيص السرطان بنجاح ، ولكن أيضًا ، على سبيل المثال ، لاختبار لقطات الشاشة. لمزيد من التفاصيل ، انظر
تقرير ليودميلا مزاخيش ، وسأخبر القاعدة نفسها.
للاختبار باستخدام لقطات الشاشة ، يلزم وجود شاشتين:
- أساسي (مرجع) الذي نقارن به ؛
- لقطة شاشة للاختبار.

لسوء الحظ ، في اختبار لقطة الشاشة ، غالبًا ما يكون هناك الكثير من السقوط (ايجابيات كاذبة). ولكن يمكن تجنب ذلك من خلال تطبيق تقنيات متقدمة لمكافحة السرطان على الواجهة الأمامية.
تذكر ، وضعنا علامة على الصورة في المنطقة التي يوجد بها السرطان وليس. نفس الشيء يمكن القيام به هنا.
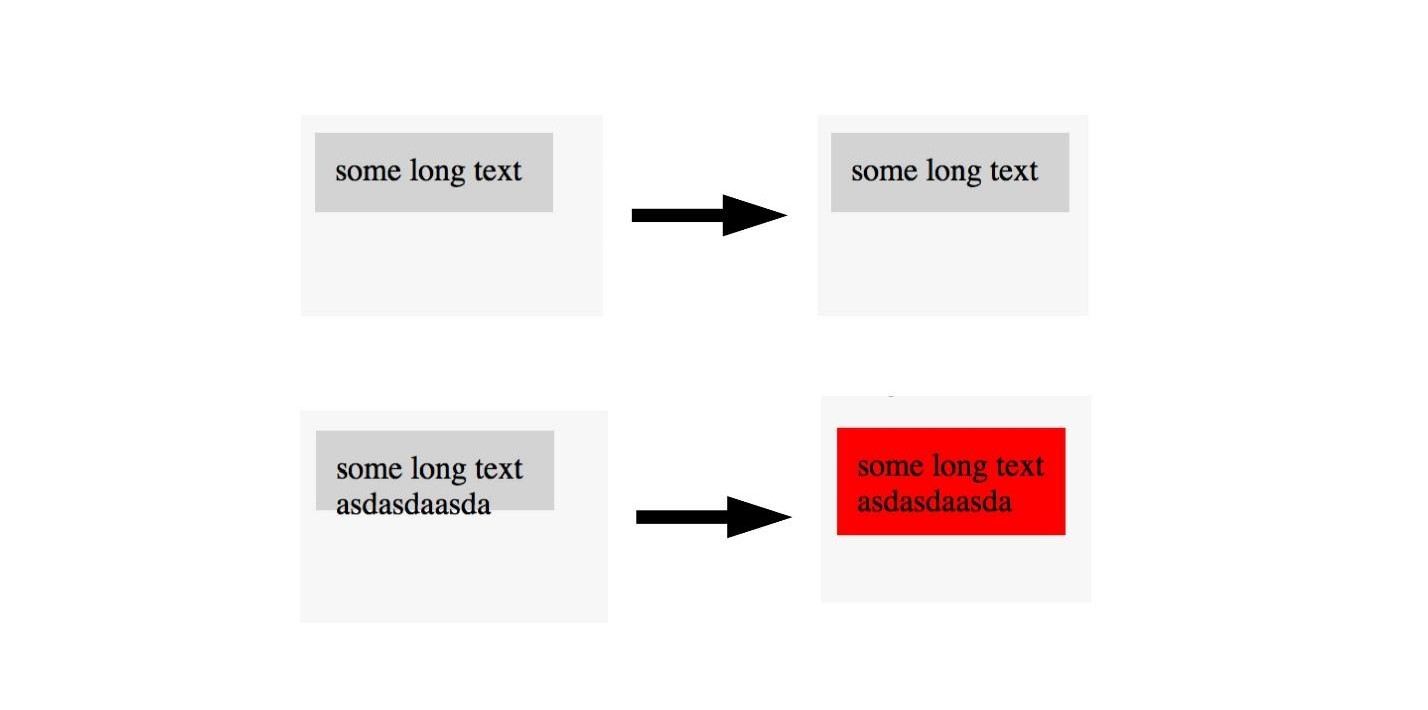
إذا رأينا صورة ذات تصميم جيد ، فلن نضع علامة عليها ، ونضع علامة على صور ذات تخطيط رديء. وبالتالي ، يمكنك اختبار التخطيط مع صورة واحدة. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
بدلا من الاستنتاجات
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .