كيفية اختبار الأفكار والهندسة المعمارية والخوارزميات دون كتابة التعليمات البرمجية؟ كيفية صياغة والتحقق من ممتلكاتهم؟ ما هي لعبة الداما والباحثين عن النماذج؟ ماذا تفعل عندما تكون قدرات الاختبارات غير كافية؟
مرحبا. اسمي Vasil Dyadov ، والآن أعمل كمبرمج في Yandex.Mail ، وقبل ذلك عملت في شركة Intel ، وقد سبق لي أن وضعت رمز RTL (مستوى نقل التسجيل) على Verilog / VHDL لـ ASIC / FPGA. لقد كنت مغرمًا منذ فترة طويلة بموضوع موثوقية البرامج والأجهزة والرياضيات والأدوات والأساليب المستخدمة لتطوير البرامج والمنطق بخصائص مضمونة ومحددة مسبقًا.
هذه هي المقالة الثانية في سلسلة (المقالة الأولى هنا ) ، المصممة لجذب انتباه المطورين والمديرين إلى النهج الهندسي لتطوير البرمجيات. في الآونة الأخيرة ، تم تجاهله بشكل غير مستحق ، على الرغم من التغييرات الثورية في نهجه وأدوات الدعم.
بدا المقال الأول لبعض القراء مجردة للغاية. يود الكثيرون أن يروا مثالًا على استخدام نهج هندسي ومواصفات رسمية في ظروف قريبة من الواقع.
في هذه المقالة ، سننظر في مثال على التطبيق الحقيقي لـ TLA + لحل مشكلة عملية.
أنا دائمًا منفتح لمناقشة القضايا المتعلقة بتطوير البرمجيات ، وسأكون سعيدًا للدردشة مع القراء (إحداثيات الاتصال في ملفي الشخصي).
ما هو TLA +؟
بادئ ذي بدء ، أود أن أقول بضع كلمات حول TLA + و TLC.
TLA + (المنطق الزمني للإجراءات + البيانات) هو شكلية تستند إلى نوع من المنطق الزمني. صممه ليزلي لامبورت.
في إطار هذه الشكليات ، يمكن للمرء أن يصف فضاء متغيرات سلوك النظام وخصائص هذه السلوكيات.
للبساطة ، يمكننا أن نفترض أن سلوك النظام يمثله سلسلة من حالاته (مثل الخرزات اللانهائية ، الكرات على السلسلة) ، وتعرف صيغة TLA + فئة من السلاسل التي تصف جميع المتغيرات المحتملة لسلوك النظام (عدد كبير من الخرزات).
TLA + مناسب تمامًا لوصف أجهزة الحالة المحددة غير المحددة (التفاعل على سبيل المثال ، تفاعل الخدمات في النظام) ، على الرغم من أن تعبيرها يكفي لوصف العديد من الأشياء الأخرى (والتي يمكن التعبير عنها في منطق الدرجة الأولى).
و TLC هو مدقق طراز صريح: برنامج ، وفقًا لوصف نظام TLA + معين وصيغ خاصية ، يتكرر على حالات النظام ويحدد ما إذا كان النظام يفي بالخصائص المحددة.
بشكل عام ، يتم إنشاء العمل باستخدام TLA + / TLC بهذه الطريقة: نحن نصف النظام في TLA + ، ونضفي الطابع الرسمي على الخصائص المثيرة للاهتمام في TLA + ، وقم بتشغيل TLC للتحقق.
نظرًا لأنه ليس من السهل وصف نظام أكثر أو أقل تعقيدًا بشكل مباشر في TLA + ، تم اختراع لغة ذات مستوى أعلى - PlusCal ، والتي تترجم إلى TLA +. يوجد PlusCal بطريقتين: مع بناء جملة Pascal و C-like. في المقال الذي استخدمته بناء جملة تشبه Pascal ، يبدو لي أنه من الأفضل قراءة. PlusCal فيما يتعلق TLA + هو نفسه تقريبا C فيما يتعلق المجمّع.
هنا لن نتعمق في النظرية. يتم توفير أدب الغمر في TLA + / PlusCal / TLC في نهاية المقالة.
تتمثل مهمتي الرئيسية في إظهار تطبيق TLA + / TLC في مثال حقيقي بسيط ومفهوم للحياة.
في بعض التعليقات على المقال السابق ، تم تأنيب أنني لم أرسم الأسس النظرية للأدوات ، ولكن الغرض من هذه السلسلة من المقالات هو إظهار التطبيق العملي لأدوات النهج الهندسي في تطوير البرمجيات.
أعتقد أن الانغماس العميق في النظرية لا يهم أي شخص ، ولكن إذا كنت مهتمًا ، فيمكنك دائمًا الذهاب إلى رئيس الوزراء للحصول على روابط وتفسيرات ، وبقدر ما لدي معرفة كافية (بعد كل شيء ، أنا لست عالمًا نظريًا في الرياضيات ، ولكني مهندس برمجيات) ، سأحاول الإجابة .
بيان المشكلة
أولاً ، سأتحدث قليلاً عن المهمة التي تم استخدام TLA + لها.
تتعلق المهمة بمعالجة تدفق الأحداث. وهي لإنشاء قائمة انتظار لتخزين الأحداث وإرسال إعلامات حول هذه الأحداث.
يتم تنظيم مستودع البيانات فعليًا على أساس PostgreSQL DBMS.
الشيء الرئيسي الذي تحتاج إلى معرفته:
- هناك مصادر للأحداث. لأغراضنا ، يمكننا أن نقصر أنفسنا على حقيقة أن كل حدث يتميز بالوقت الذي يتم فيه التخطيط للمعالجة. تكتب هذه المصادر الأحداث إلى قاعدة البيانات. عادةً لا يرتبط وقت الكتابة بقاعدة البيانات ووقت المعالجة المخططة بأي شكل من الأشكال.
- هناك عمليات تنسيقية تقرأ الأحداث من قاعدة البيانات وترسل إخطارات الأحداث القادمة إلى مكونات النظام التي يجب أن تستجيب لهذه الإشعارات.
- الشرط الأساسي: يجب ألا نفقد الأحداث. يمكن تكرار إعلام الحدث في الحالات القصوى ، أي أنه يجب أن يكون هناك ضمان مرة واحدة على الأقل . في الأنظمة الموزعة ، من الصعب للغاية تنفيذ ضمان مرة واحدة فقط (قد يكون ذلك مستحيلًا ، لكن يجب إثباته) دون وجود آليات إجماع ، وهي (على الأقل كل ما أعرفه) لها تأثير قوي جدًا على النظام من حيث التأخير والإنتاجية.
الآن بعض التفاصيل:
- هناك العديد من عمليات المصدر ؛ يمكن أن تولد الملايين (في أسوأ الحالات) من الأحداث التي تقع في فترة زمنية ضيقة.
- يمكن إنشاء الأحداث للمستقبل وللوقت الماضي (على سبيل المثال ، إذا تباطأت عملية المصدر وسجلت حدثًا للحظة التي مرت بالفعل).
- تكون أولوية معالجة الحدث في الوقت المناسب ، أي يجب علينا أولاً معالجة الأحداث المبكرة.
- لكل حدث ، تولد العملية المصدر رقمًا عشوائيًا للعامل ، بحيث يتم توزيع الأحداث بين المنسقين.
- هناك العديد من عمليات التنسيق (المقاييس وفقًا للاحتياجات بناءً على تحميل النظام).
- كل عملية منسق تقوم بمعالجة الأحداث الخاصة بمجموعتها worker_id ، بمعنى ، وبسبب worker_id ، نتجنب التنافس بين المنسقين والحاجة إلى الأقفال.
كما يتضح من الوصف ، يمكننا النظر في عملية تنسيق واحدة فقط وعدم مراعاة عامل_ عامل في مهمتنا.
وهذا هو ، للبساطة ، نفترض أن:
- هناك العديد من عمليات المصدر.
- عملية التنسيق واحدة.
سوف أصف تطور فكرة حل هذه المشكلة على مراحل ، بحيث يكون من الفهم كيف تطورت الفكرة من تطبيق بسيط إلى تطبيق محسن.
قرار الجبهة
سنقوم بإنشاء لوحة للأحداث حيث سنقوم بتخزين الأحداث في شكل طابع زمني (نحن لسنا مهتمين بمعلمات أخرى في هذه المهمة). دعونا بناء فهرس في حقل الطابع الزمني .
يبدو أن الحل الطبيعي تماما.
هناك مشكلة في قابلية التوسع: كلما زاد عدد الأحداث ، كلما كانت عمليات قاعدة البيانات أبطأ.
يمكن أن تأتي الأحداث للوقت الماضي ، لذلك سيتعين على المنسق مراجعة الجدول الزمني بأكمله باستمرار.
يمكن حل المشكلة على نطاق واسع عن طريق تقسيم قاعدة البيانات إلى شظايا بمرور الوقت ، إلخ. لكن هذه طريقة كثيفة الاستخدام للموارد.
نتيجة لذلك ، سوف يتباطأ عمل المنسقين ، حيث سيتعين عليك قراءة ودمج البيانات من عدة قواعد بيانات.
من الصعب تطبيق التخزين المؤقت للحدث في المنسق حتى لا تنتقل إلى القواعد لمعالجة كل حدث.
المزيد من قواعد البيانات - المزيد من مشاكل التسامح مع الخطأ.
و هكذا.
لن نتناول بالتفصيل هذا الحل الأمامي بالتفصيل ، لأنه تافه وغير مهتم.
التحسين الأول
دعونا نرى كيفية تحسين الحل الأمامي.
لتحسين الوصول إلى قاعدة البيانات ، يمكنك تعقيد الفهرس قليلاً ، وإضافة معرف زيادة رتابة إلى الأحداث التي سيتم إنشاؤها عند ارتكاب معاملة في قاعدة البيانات. أي أن الحدث يتميز الآن بالزوج {time، id} ، حيث يكون الوقت هو الوقت الذي تم فيه جدولة الحدث ، والمعرف هو عداد متزايد بشكل رتيب. يوجد ضمان لتفرد المعرف لكل حدث ، ولكن لا يوجد ضمان بأن قيم المعرف تذهب بدون ثقوب (أي ، يمكن أن يكون هناك مثل هذا التسلسل: 1 ، 2 ، 7 ، 15 ).
يبدو أنه يمكننا الآن تخزين معرّف حدث القراءة الأخير في عملية المنسق ، وعند جلب الأحداث ، حدد أحداث ذات معرّفات أكبر من آخر حدث معالج.
ولكن هنا تظهر المشكلة على الفور: يمكن لعمليات المصدر تسجيل حدث مع طابع زمني بعيد في المستقبل. عندها سيتعين علينا أن نأخذ في الاعتبار دائمًا مجموعة الأحداث ذات المعرفات الصغيرة في عملية التنسيق ، والتي لم يحن موعدها بعد.
يمكنك ملاحظة أن الأحداث المتعلقة بالوقت الحالي مقسمة إلى فئتين:
- الأحداث مع الطابع الزمني في الماضي ، ولكن مع معرف كبير. لقد تمت كتابتها إلى قاعدة البيانات مؤخرًا ، بعد أن قمنا بمعالجة ذلك الفاصل الزمني. هذه أحداث ذات أولوية عالية ، ويجب معالجتها أولاً حتى لا يتأخر الإخطار - الذي تأخر بالفعل.
- الأحداث المسجلة ذات مرة مع طوابع زمنية قريبة من اللحظة الحالية. سيكون لهذه الأحداث قيمة معرف منخفضة.
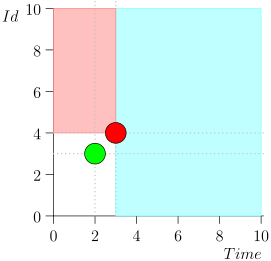
وفقًا لذلك ، تتميز الحالة الحالية لعملية المنسق بالزوج {state.time، state.id}.
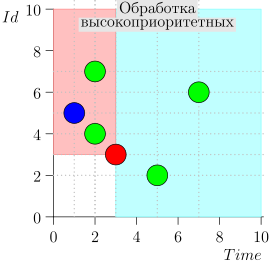
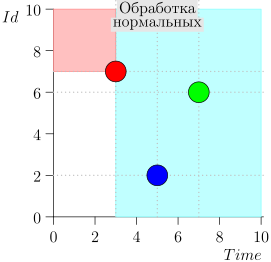
اتضح أن الأحداث ذات الأولوية العليا هي على اليسار وفوق هذه النقطة (المنطقة الوردية) ، والأحداث العادية هي إلى اليمين (الأزرق الفاتح):
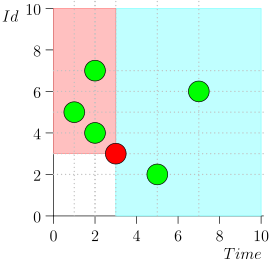
مخطط التدفق
خوارزمية عمل المنسق هي كما يلي:
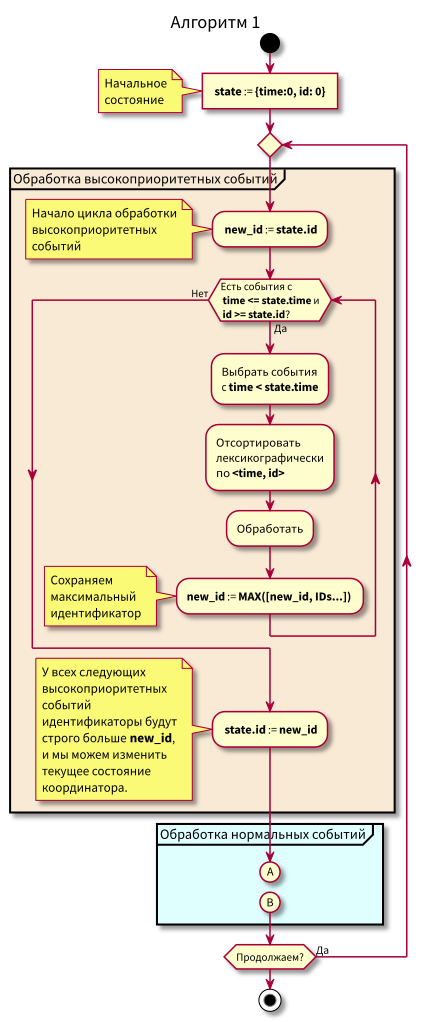
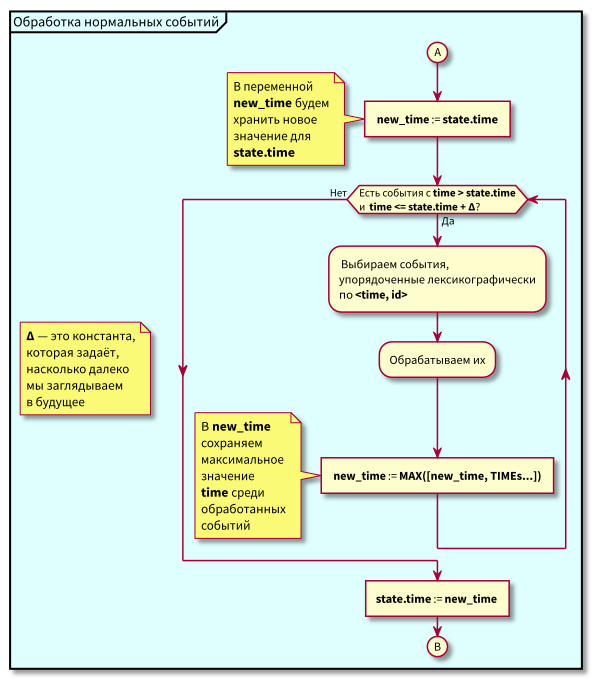
عند دراسة الخوارزمية ، قد تثار الأسئلة:
- ماذا لو بدأت معالجة الأحداث العادية وفي تلك اللحظة وصلت أحداث جديدة في الماضي (في المنطقة الوردية) ، ألا تضيع؟ الإجابة: ستتم معالجتها في الدورة التالية لمعالجة الأحداث ذات الأولوية العالية. لا يمكن أن يضيعوا ، لأن معرفهم مضمون ليكون أعلى من معرف الحالة.
- ماذا لو حدث بعد معالجة جميع الأحداث العادية - في وقت التبديل إلى معالجة الأحداث ذات الأولوية العالية - أحداث جديدة مع طوابع زمنية من الفاصل الزمني [state.time، state.time + Delta] ، هل نفقدها؟ الإجابة: سوف يسقطون في المنطقة الوردية ، حيث سيكون لديهم وقت <state.time و id > state.id: لقد وصلوا مؤخرًا ، ويتزايد معرف الهوية رتابة.
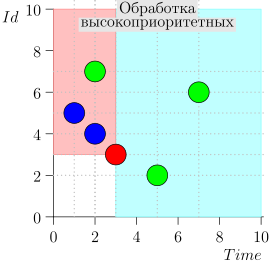
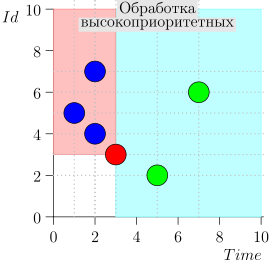
مثال عملية الخوارزمية
دعونا نلقي نظرة على بضع خطوات من الخوارزمية:
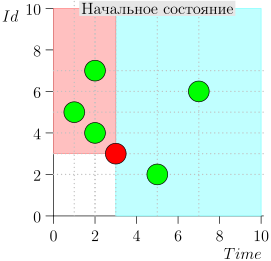
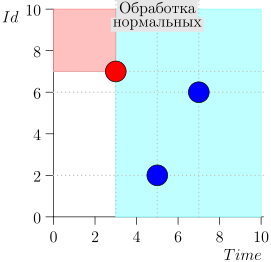
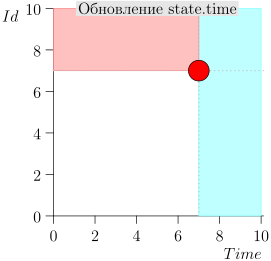
نموذج
سوف نتأكد من أن الخوارزمية لا تفوت الأحداث وسيتم إرسال جميع الإخطارات: سنقوم بإنشاء نموذج بسيط والتحقق منه.
بالنسبة للطراز ، نستخدم TLA + ، وبشكل أكثر دقة PlusCal ، والذي يترجم إلى TLA +.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
كما ترى ، الوصف صغير نسبيًا ، على الرغم من القسم الضخم من التعريفات (تعريف) ، والذي يمكن أخذه في وحدة نمطية منفصلة ، ثم إعادة استخدامه.
في التعليقات حاولت توضيح ما يحدث في النموذج. امل هذا
تمكنت وليس هناك حاجة لرسم النموذج بمزيد من التفاصيل.
أود فقط توضيح نقطة واحدة فيما يتعلق بمدى ذرية التحولات بين الحالات وميزات النمذجة.
يتم النمذجة عن طريق تنفيذ الخطوات الذرية للعمليات. في عملية انتقال واحدة ، يتم تنفيذ خطوة ذرية واحدة من العملية التي يمكن القيام بهذه الخطوة. اختيار الخطوة والعملية غير حاسم: أثناء النمذجة ، يتم فرز جميع السلاسل الممكنة من الخطوات الذرية لجميع العمليات.
قد ينشأ السؤال: ماذا عن نمذجة التوازي الحقيقي ، عندما ننفذ في وقت واحد عدة خطوات ذرية في عمليات مختلفة؟
لطالما تم إجابة هذا السؤال على Leslie Lamport في كتاب "تحديد الأنظمة" والأعمال الأخرى.
لن أقتبس من الإجابة بشكل كامل ، باختصار ، فإن الجوهر هو هذا: إذا لم يكن هناك نطاق زمني محدد حيث يرتبط كل حدث بلحظة معينة ، فلا يوجد فرق في نمذجة الأحداث المتوازية كأحداث متتالية غير حتمية ، لأنه يمكننا دائمًا افتراض أن حدثًا ما وقع قبل آخر قيمة لانهائية.
ولكن المهم حقًا هو التخصيص المختص للخطوات الذرية. إذا كان هناك الكثير منهم ، فسيحدث انفجار اندماجي لمساحة الدولة. إذا اتخذت خطوات أقل من اللازم ، أو حددتها بشكل غير صحيح - أي احتمال فقد حالة / انتقال غير صالح (أي ، سنفتقد الأخطاء في النموذج).
لتقسيم العمليات بشكل صحيح إلى خطوات ذرية ، يجب أن يكون لديك فكرة جيدة عن كيفية عمل النظام من حيث اعتماد العمليات على البيانات وعلى آليات المزامنة.
وكقاعدة عامة ، لا يؤدي تقسيم العمليات إلى خطوات ذرية إلى حدوث مشكلات كبيرة. وإذا حدث ذلك ، فهو يشير إلى عدم فهم المشكلة ، وليس عن مشاكل تجميع النموذج وكتابة مواصفات TLA +. هذه هي ميزة أخرى مفيدة للغاية من المواصفات الرسمية: فهي تتطلب دراسة وتحليل دقيق.
مشكلة كقاعدة عامة ، إذا كانت المهمة ذات معنى وفهمها جيدًا ، فلا توجد مشكلات في إضفاء طابع رسمي عليها.
تحقق النموذج
لنمذجة سأستخدم أداة TLA. يمكنك بالطبع تشغيل كل شيء من سطر الأوامر ، لكن IDE لا يزال أكثر ملاءمة ، خاصة لبدء التعلم عن النمذجة باستخدام TLA +.
تم وصف إنشاء المشروع بشكل جيد في الأدلة والمقالات والكتب ، والروابط التي أشرت إليها في نهاية المقال ، لذلك لن أكرر نفسي. الشيء الوحيد الذي سألفت انتباهك إليه هو إعدادات المحاكاة.
TLC هو مدقق نموذج مع التحقق من حالة واضحة. من الواضح أن مساحة الدولة يجب أن تكون محدودة بحدود معقولة. من ناحية ، يجب أن تكون كبيرة بما يكفي لتكون قادرًا على التحقق من الخصائص التي تهمنا ، ومن ناحية أخرى ، فهي صغيرة بما يكفي لإتمام المحاكاة في فترة زمنية معقولة باستخدام موارد مقبولة.
هذه نقطة حساسة للغاية ، وهنا تحتاج إلى فهم خصائص النظام والطراز. لكنه يأتي بسرعة مع الخبرة. بالنسبة للمبتدئين ، يمكنك ببساطة تعيين الحدود القصوى الممكنة التي لا تزال مقبولة من حيث وقت المحاكاة والموارد المستهلكة.
هناك أيضًا طريقة للتحقق من مساحة الولاية بأكملها ، ولكن هناك سلاسل انتقائية على عمق معين. كما أنه في بعض الأحيان ممكن وضروري للاستخدام.
نعود إلى إعدادات المحاكاة.
أولاً ، نحدد القيود المفروضة على مساحة حالة النظام. يتم تعيين القيود في قسم إعدادات محاكاة الخيارات المتقدمة / حالة القيد .
أشرت إلى تعبير TLA +: Cardinality(Events) <= 5 /\ Event_Id <= 5 ،
حيث Event_Id هو الحد الأعلى لقيمة معرف الحدث ، Cardinality(Events) هو حجم مجموعة سجلات الأحداث (يقتصر النموذج الأساسي
البيانات من خلال خمسة سجلات في لوحة).
في المحاكاة ، سوف ينظر TLC فقط في الحالات التي تكون فيها هذه الصيغة صحيحة.
لا يزال بإمكانك السماح بانتقالات الحالة الصحيحة ( خيارات متقدمة / قيد الإجراء ) ،
لكننا لسنا بحاجة إليها.
بعد ذلك ، نشير إلى صيغة TLA + التي تصف نظامنا: Model Overview / Temporal Formula = Spec ، حيث Spec هو اسم صيغة TLA + autogenerated بواسطة PlusCal (في رمز النموذج أعلاه لا: لتوفير مساحة ، لم أذكر نتيجة ترجمة PlusCal إلى TLA +) .
الإعداد التالي يستحق الاهتمام هو الاختيار الجمود.
(علامة اختيار في نظرة عامة على النموذج / حالة توقف تام ). عند تمكين هذه العلامة ، سوف يتحقق TLC من النموذج لحالات "التعليق" ، أي تلك التي لا توجد بها انتقالات صادرة. إذا كان هناك مثل هذه الحالات في مساحة الولاية ، فهذا يعني وجود خطأ واضح في النموذج. أو في TLC ، الذي ، مثله مثل أي برنامج آخر غير تافه ، ليس محصنًا من الأخطاء :) في ممارستي (ليست كبيرة) ، لم أواجه بعد حالة توقف تام.
وأخيرًا ، من أجل بدء كل هذا الاختبار ، صيغة الأمان في نظرة عامة على النموذج / Invariants = ALL_EVENTS_PROCESSED(state) .
سوف يتحقق TLC من صحة الصيغة في كل ولاية ، وإذا أصبحت خاطئة ،
سيعرض رسالة خطأ ويظهر تسلسل الحالات التي أدت إلى الخطأ.
بعد بدء تشغيل TLC ، وبعد العمل لمدة 8 دقائق ، أبلغت "بلا أخطاء". هذا يعني أن النموذج تم اختباره ويلبي الخصائص المحددة.
يعرض TLC أيضًا الكثير من الإحصاءات المثيرة للاهتمام. على سبيل المثال ، بالنسبة لهذا النموذج ، تم الحصول على 7247 724 حالة فريدة ؛ في المجموع ، نظر TLC إلى 27 109 02 ولاية ، يبلغ قطر مساحة الولاية 47 (وهذا هو الحد الأقصى لطول سلسلة الحالة قبل التكرار ،
الحد الأقصى لطول الدورة من الحالات غير المتكررة في الحالة والرسم البياني الانتقالي).
إذا قسمنا 27 مليون ولاية إلى 8 دقائق ، فسنحصل على حوالي 56 ألف ولاية في الثانية ، والتي قد لا تبدو سريعة جدًا. لكن ضع في اعتبارك أنني قمت بتشغيل المحاكاة على جهاز كمبيوتر محمول يعمل في وضع توفير الطاقة (لقد أجبرت التردد الأساسي على 800 ميجاهرتز ، لأنني كنت أقود السيارة في تلك اللحظة في القطار) ، ولم أقوم بتحسين نموذج سرعة المحاكاة على الإطلاق.
هناك العديد من الطرق لتسريع عملية المحاكاة: من نقل جزء من رمز طراز TLA + إلى Java والاتصال بـ TLC أثناء التنقل (من المفيد تسريع جميع أنواع وظائف المساعد) إلى تشغيل TLC في السحب وعلى التجمعات (تم تصميم دعم السحابة من Amazon و Azure مباشرة في TLC نفسه).
التحسين الثاني
في الخوارزمية السابقة ، كل شيء على ما يرام ، باستثناء بعض المشاكل:
- إلى أن نعالج جميع الأحداث من المنطقة الزرقاء في الفاصل الزمني
[state.time, state.time + Delta] ، لا يمكننا الانتقال إلى الأحداث ذات الأولوية العالية. أي أن الأحداث المتأخرة ستتأخر أكثر. وعادة ما يكون التأخير غير متوقع. وبسبب هذا ، يمكن أن يتخلف state.time عن الوقت الحالي ، وهذا هو سبب المشكلة التالية. - قد تكون الأحداث التي تصل إلى منطقة الأحداث العادية متأخرة ( id > state.id). إنها بالفعل أولوية عالية ويجب اعتبارها أحداثًا من المنطقة الوردية ، وما زلنا نعتبرها طبيعية ونعاملها على أنها طبيعية.
- من الصعب تنظيم التخزين المؤقت للحدث وتجديد ذاكرة التخزين المؤقت (القراءة من قاعدة البيانات).
إذا كانت النقطتان الأوليتان واضحتين ، فربما تثير النقطة الثالثة معظم الأسئلة. دعونا نتناولها بمزيد من التفاصيل.
افترض أننا نريد أولاً قراءة عدد ثابت من الأحداث في الذاكرة ثم معالجتها.
بعد المعالجة ، نريد وضع علامة على الأحداث في قاعدة البيانات باستخدام استعلامات الكتل كما تمت معالجتها ، لأنه إذا كنت لا تعمل مع الكتل ، ولكن مع الأحداث الفردية ، فلن يكون هناك مكسب كبير من التخزين المؤقت.
لنفترض أننا قمنا بمعالجة جزء من الكتل ونرغب في استكمال ذاكرة التخزين المؤقت. ثم ، إذا وصلت الأحداث ذات الأولوية العليا المتأخرة أثناء المعالجة ، يمكننا معالجتها مبكرًا.
أي أنه من المرغوب فيه للغاية أن تكون قادرًا على قراءة الأحداث في كتل صغيرة من أجل معالجة الأحداث المتأخرة في أسرع وقت ممكن ، ولكن لتحديث سمة المعالجة في قاعدة البيانات مع كتل كبيرة مرة واحدة - لتحقيق الكفاءة.
ماذا تفعل في هذه الحالة؟
حاول العمل مع قاعدة البيانات في كتل صغيرة ذات مساحة زرقاء و وردية ونقل نقطة الولاية بخطوات صغيرة.
وبالتالي ، تم تقديم ذاكرة التخزين المؤقت وقراءتها من أجزاء قاعدة بيانات البيانات ، بعد كل قراءة ، تم تغيير نقطة الحالة حتى لا تتم إعادة قراءة الأحداث التي تم قراءتها بالفعل.
الآن أصبحت الخوارزمية أكثر تعقيدًا قليلاً ، وبدأنا نقرأ في أجزاء محدودة.
مخطط التدفق
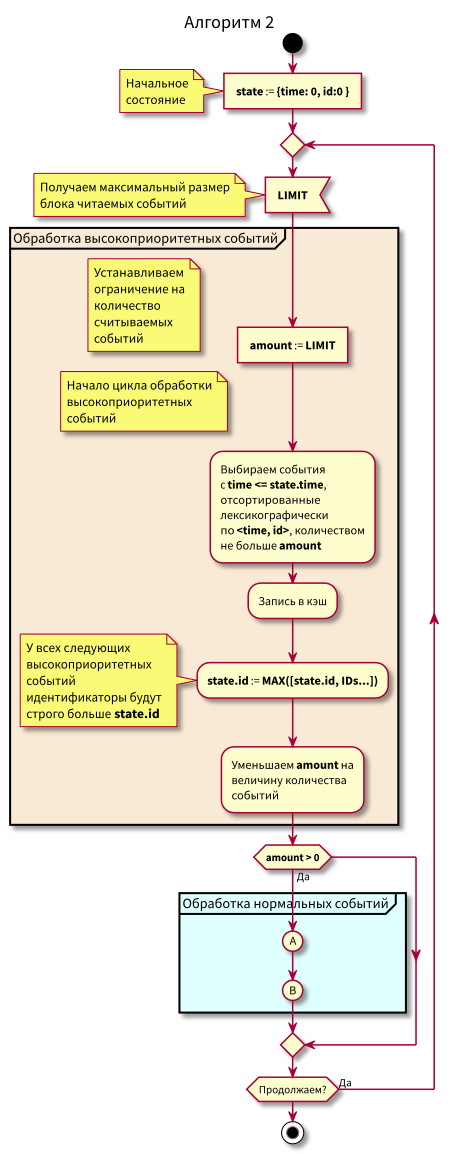
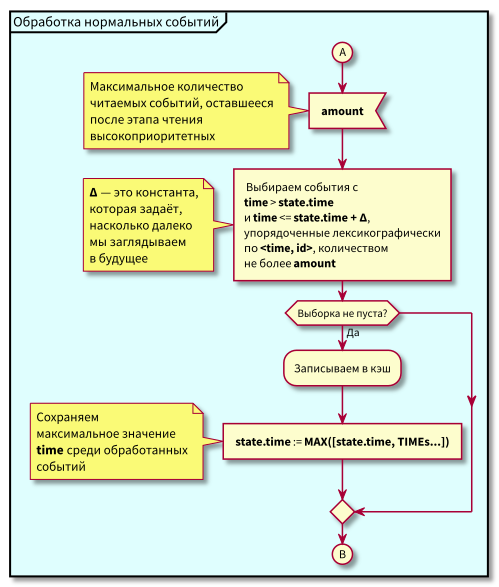
في هذه الخوارزمية ، يمكن ملاحظة أنه نظرًا للتقييد المفروض على كتل الأحداث القابلة للقراءة ، فإن الحد الأقصى للتأخير في الانتقال من المعالجة ذات الأولوية المنخفضة إلى المعالجة ذات الأولوية العالية سيكون مساوياً لوقت المعالجة الأقصى للكتلة.
هذا هو ، الآن يمكننا قراءة الأحداث في ذاكرة التخزين المؤقت في كتل صغيرة ، والتحكم في الحد الأقصى للتأخير في الانتقال إلى معالجة الأحداث ذات الأولوية العالية من خلال التحكم في الحد الأقصى لحجم الكتلة للقراءة.
مثال عملية الخوارزمية
دعونا نلقي نظرة على الخوارزمية في العمل ، في خطوات. للراحة ، خذ LIMIT = 2 .
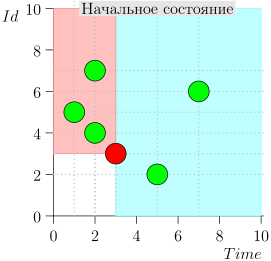
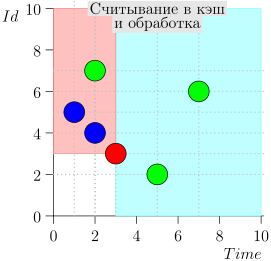
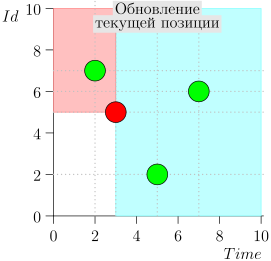
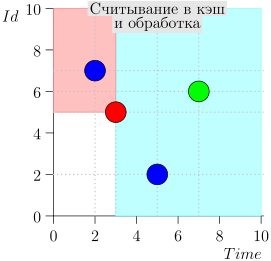
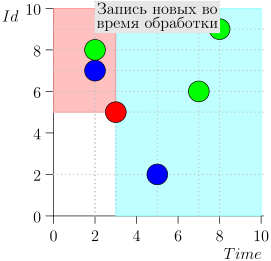
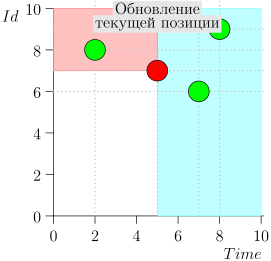
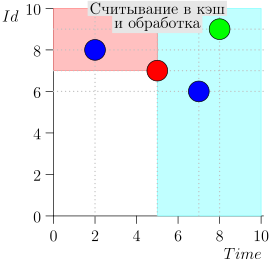
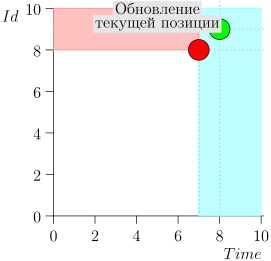
اتضح يتم حل المشكلة؟ لكن لا. (من الواضح أنه إذا تم حل المشكلة بالكامل في هذه المرحلة ، إذن
هذا المقال لم يكن :))
الخطأ؟
في هذا النموذج ، عملت الخوارزمية لفترة طويلة إلى حد ما. كل الاختبارات سار على ما يرام. لم تكن هناك مشاكل في الإنتاج سواء.
لكن مطور الخوارزمية وتنفيذه (زميلي بيتر ريزنيكوف) ذو خبرة كبيرة ، وشعر بشكل حدسي بأن هناك شيئًا ما خطأ هنا. لذلك ، تم إجراء المدقق بجوار الرمز الرئيسي ، والذي تم التحقق منه مرة واحدة على جهاز توقيت لمعرفة ما إذا كانت هناك أية أحداث ضائعة ، و
إن وجدت ، لقد عالجتها.
في هذا النموذج ، عمل النظام بنجاح. صحيح ، لم يحتفظ أحد بإحصائيات حول عدد الأحداث التي اختارها المدقق. لذلك ، للأسف ، لا نعرف عدد حالات الفشل المرتبطة بمعالجة الأحداث في وقت غير مناسب.
قمت بتنفيذ قائمة انتظار مماثلة من الكائنات المحددة زمنيا. مناقشة تطبيق الخوارزميات وتحسينها مع بيتر ريزنيكوف ، تحدثنا عن هذه الخوارزمية للعمل مع الأحداث. لقد شككوا في أن الخوارزمية صحيحة. قررنا تقديم نموذج صغير لتأكيد أو تبديد الشكوك. نتيجة لذلك ، وجدنا خطأ.
نموذج
قبل تفكيك التتبع مع وجود خطأ ، سأقدم الكود المصدري للنموذج الذي تم اكتشاف الخطأ عليه.
الاختلافات في النموذج السابق صغيرة جدًا ، ولا يوجد سوى حد لحجم كتل القراءة: يتم إضافة عامل التشغيل "الحد" ، وبالتالي يتم تغيير عوامل اختيار الحدث.
لتوفير مساحة ، تركت التعليقات فقط على الأجزاء التي تم تغييرها من النموذج.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
قد يلاحظ القارئ اليقظ أنه بالإضافة إلى إدخال الحد ، تم تغيير التصنيفات في event_processor أيضًا. الهدف هو أفضل قليلاً لمحاكاة الكود الحقيقي الذي يتم تنفيذه في معاملة واحدة ، أي اختيار الأحداث التي يمكن تنفيذها على أساس تلقائي.
حسنًا ، وإذا وجدنا خطأً في نموذج ذي عمليات ذرية أكبر ، فإن هذا يضمن عملياً حدوث نفس الخطأ في نفس النموذج ، ولكن مع خطوات ذرية أصغر (عبارة قوية جدًا ، لكنني أعتقد أنه حدسي ؛ يجب أن تكون جيدة إذا لم تثبت ، ثم التحقق من مجموعة واسعة من النماذج).
تحقق النموذج
نبدأ المحاكاة بنفس المعلمات كما في النموذج الأول.
وقد حصلنا على انتهاك للخاصية ALL_EVENTS_PROCESSED في الخطوة 19 من المحاكاة عند البحث في العرض.
بالنسبة للبيانات الأولية المحددة (هذه مساحة صغيرة جدًا للحالة) ، يشير الخطأ في الخطوة التاسعة عشرة إلى أن الخطأ نادر جدًا ويصعب اكتشافه ، لأنه قبل ذلك تم فحص جميع سلاسل الحالة بطول أقل من 19.
لذلك ، من الصعب اللحاق بهذا الخطأ في الاختبارات. فقط إذا كنت تعرف المكان الذي تبحث فيه ، وحدد على وجه التحديد الاختبارات والأكواخ المؤقتة.
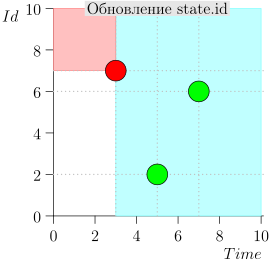
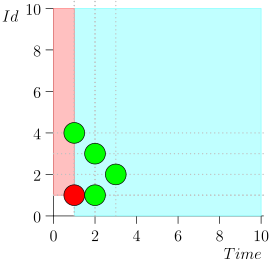
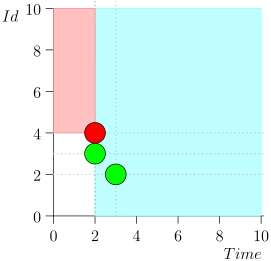
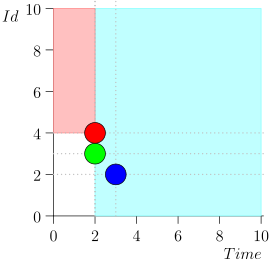
لن أحقق المسار بالكامل من أجل توفير المساحة والوقت. إليك مقطع من عدة ولايات مع وجود خطأ:

التحليل والتصحيح
ماذا حدث؟
كما ترون ، فإن الخطأ تجلى في حقيقة أننا أخطأنا الحدث {2 ، 3} بسبب حقيقة أن الحد انتهى في الحدث {2 ، 1} ، وبعد ذلك قمنا بتغيير حالة المنسق. يمكن أن يحدث هذا فقط إذا كانت هناك عدة أحداث في لحظة واحدة.
هذا هو السبب في أن الخطأ كان بعيد المنال في الاختبارات. من أجل مظهره ، من الضروري أن تتزامن الأشياء النادرة جدًا:
- ضرب العديد من الأحداث نفس النقطة في الوقت المناسب.
- انتهى الحد الأقصى لاختيار الأحداث قبل لحظة قراءة كل هذه الأحداث.
يمكن تصحيح الخطأ نسبيًا بسهولة إذا تم توسيع حالة المنسق قليلاً: أضف وقت ومعرف آخر حدث قراءة من منطقة الحدث العادية بأقصى معرف إذا كان وقت هذا الحدث يتوافق مع قيمة الحالة التالية.
إذا لم يكن هناك أي حدث من هذا القبيل ، فسنقوم بتعيين الحالة الإضافية (دولة_إضافية) إلى حالة غير صالحة (UNDEF_EVT) ولا نأخذها في الاعتبار عند العمل.
ستعتبر تلك الأحداث من المنطقة الطبيعية التي لم تتم معالجتها في الخطوة السابقة للمنسق أولوية عالية وسنقوم بالتالي بتصحيح اختيار الأولوية العالية والأمان المتوقع.
قد يكون من الممكن إدخال منطقة أخرى وسيطة بين الأولوية العليا والطبيعية ، وتغيير الخوارزمية. أولاً ، ستقوم بمعالجة تلك ذات الأولوية العالية ، ثم المتوسطة منها ، ثم الانتقال إلى الحالات العادية مع التغيير اللاحق للحالة.
لكن مثل هذه التغييرات ستؤدي إلى زيادة حجم إعادة البناء مع فوائد غير واضحة (ستكون الخوارزمية أكثر وضوحًا قليلاً ، والمزايا الأخرى غير مرئية على الفور).
لذلك ، قررنا ضبط الحالة الحالية واختيار الأحداث من قاعدة البيانات قليلاً فقط.
النموذج المعدل
هنا هو نموذج تصحيحها.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
كما ترى ، فإن التغييرات صغيرة جدًا:
- تمت إضافة بيانات إضافية إلى حالة extra_state.
- تم تغيير اختيار الأحداث ذات الأولوية العليا.
- UpdateExtraState extra_state.
- safety - .
, . , (, , , ).
, , TLA+/TLC . :)
استنتاج
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
قائمة المراجع
الكتب
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .