 يمكنك تنزيل الملف مع الكود والبيانات في المنشور الأصلي على مدونتي
يمكنك تنزيل الملف مع الكود والبيانات في المنشور الأصلي على مدونتيهناك مشروع مثير للاهتمام للغاية - "
Rosetta Code" . هدفهم هو "تقديم حل للمشاكل نفسها في أكبر عدد ممكن من لغات البرمجة المختلفة من أجل إظهار الأماكن والاختلافات المشتركة ومساعدة الشخص الذي لديه المعرفة لحل المشكلة مع طريقة واحدة لتعلم لغة أخرى."
يوفر هذا المورد فرصة فريدة لمقارنة رموز البرنامج بلغات مختلفة ، وهو ما سنفعله في هذه المقالة. إنها مراجعة وتنقيح كامل للمقالة التي كتبها جون ماكلون "
طول الكود المقاس بـ 14 لغة ".
استيراد وتحليل البيانات
لنبدأ بإنشاء تعديل على وظيفة
الاستيراد التي ستخزن البيانات لاستخدامها في المستقبل حتى لا تطلبها لاحقًا من الخادم.
Clear[importOnce]; importOnce[args___]:=importOnce[args]=Import[args]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "importOnce.mx"}]
إنشاء محلل لاستيراد البيانات.
Clear[createPageLinkDataset]; createPageLinkDataset[baseLink_]:=createPageLinkDataset[baseLink]=Cases[Cases[Import[baseLink, "XMLObject"], XMLElement["div", {"class"->"mw-content-ltr", "dir"->"ltr", "lang"->"en"}, data_]:>data, Infinity], XMLElement["li", {}, {XMLElement["a", {___, "href"->link_, ___}, {name_}]}]:><|"name"->name, "link"->"http://rosettacode.org"<>link|>, Infinity]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "createPageLinkDataset.mx"}]
نحن نستورد قائمة بجميع لغات البرمجة التي يدعمها المشروع (يوجد بالفعل أكثر من 750 منها):
$Languages=createPageLinkDataset["http://rosettacode.org/wiki/Category:Programming_Languages"]; Dataset@$Languages

سننشئ وظائف لترجمة الاسم إلى رابط والعكس صحيح ، وسيكون هذا مفيدًا لنا لاحقًا:
langLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Languages, #[["link"]]==link&]["name"]; langNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Languages, #[["name"]]==name&]["link"];
سنقوم بتحميل قائمة المهام التي تم حلها في كل من لغات البرمجة. تم تصميم التحليل بحيث لا تكون كل روابط الصفحات مهمة. سنقوم بتنظيفها في وقت لاحق.
$LangTasksAllPre=Map[<|"name"->#["name"], "link"->#["link"], "tasks"->createPageLinkDataset[#["link"]][[All, "link"]]|>&, $Languages]; Dataset@$LangTasksAllPre

نحسب قائمة بجميع المهام المحتملة التي يمكن حلها في المشروع (هناك ما يزيد قليلاً عن 2600 منهم):
$TasksPre=DeleteDuplicates[Flatten[$LangTasksAllPre[[;;, "tasks"]]]]; Length[$TasksPre]

لنقم بإنشاء وظيفة تلتقط كل أجزاء الكود في صفحة المهمة.
ClearAll[codeExtractor]; codeExtractor[link_String]:=Module[{code, positions, rawData}, code=importOnce[link, "XMLObject"]; positions=Map[{#[[1, 1;;-2]], Partition[#[[;;, -1]], 2, 1]}&, DeleteCases[ Gather[ Position[code, XMLElement["h2", _, title_]], And[Length[#1]==Length[#2], #1[[1;;-2]]==#2[[1;;-2]]]&], x_/; Length[x]==1]]; rawData=Framed/@Flatten[Map[ With[{pos=#[[1]]}, Map[Extract[code, pos][[#[[1]];;#[[2]]-1]]&, #[[2]]]]&, positions], 1]; Association@DeleteCases[Map[langLinkToName[("link"/.#)]->("code"/.#)&, Map[ KeyValueMap[If[#1==="link", #1->#2[[1]], #1->#2]&, Merge[SequenceSplit[Cases[#, Highlighted[x_, ___]:>x, Infinity], {"Output"}][[1]], Identity]]&, rawData/.{XMLElement["h2", _, title_]:>Cases[title, XMLElement["a", {___, "href"->linkInner_/; MemberQ[$Languages[[;;, "link"]], "http://rosettacode.org"<>linkInner], ___}, {___}]:>Highlighted[<|"link"->"http://rosettacode.org"<>linkInner|>], Infinity], XMLElement["div", {}, x_/; Not[FreeQ[x, "Output:"]]]:>Highlighted["Output"], XMLElement["pre", _, code_]:>Highlighted[<|"code"->Check[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]], Echo[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]]]]|>, Background->Red]} ]], _->"code"]];
الآن سنقوم بمعالجة جميع الصفحات:
ClearAll[taskCodes]; taskCodes[link_]:=taskCodes[link]=Check[codeExtractor[link], Echo[link]]; If[FileExistsQ[#], Get[#], taskCodes/@$TasksPre; DumpSave[#, taskCodes]]&@FileNameJoin[{NotebookDirectory[], "taskCodes.mx"}];
مثال على ما تنتج الوظيفة:
Dataset[taskCodes[$TasksPre[[20]]]]
حدد صفحات المهام (تلك التي تحتوي على شفرة واحدة على الأقل):
$taskLangs=DeleteCases[{#, taskCodes[#]}&/@$TasksPre, {_, <||>}];
$langTasks=Map[<|"name"->#[["name"]], "link"->#[["link"]], "tasks"->With[{lang=#[["name"]]}, Select[$taskLangs, MemberQ[Keys[#[[2]]], lang]&][[;;, 1]]]|>&, $Languages]; Dataset[$langTasks]

قائمة المهام والوظائف التي تترجم اسم المهمة إلى رابط ، والعكس بالعكس:
$Tasks=<|"name"->StringReplace[URLDecode[StringReplace[#, "http://rosettacode.org/wiki/"->""]], {"_"->" ", "/"->" -> "}], "link"->#|>&/@$taskLangs[[;;, 1]]; taskLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Tasks, #[["link"]]==link&]["name"]; taskNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Tasks, #[["name"]]==name&]["link"];
إحصائيات بسيطة
بالنسبة لعدد من اللغات ، لا توجد مشكلة واحدة تم حلها:
WordCloud[1/StringLength[#]->#&/@Select[$langTasks, Length[#["tasks"]]==0&][[All, "name"]], ImageSize->{1200, 800}, MaxItems->All, WordOrientation->{

قائمة اللغات التي حلت المشاكل:
$LanguagesWithTasks=Select[$langTasks, Length[#["tasks"]]=!=0&][[All, "name"]]; Length[$LanguagesWithTasks]
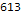
توزيع عدد المشكلات التي تم حلها حسب اللغة:
Histogram[Length/@$langTasks[[;;, "tasks"]], 50, PlotRange->All, BarOrigin->Bottom, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", lg[" "]}], ScalingFunctions->"Log10", PlotLabel->Style[" ", 20]]
توزيع عدد اللغات حسب المهام التي تم حلها:
Histogram[Length/@$taskLangs[[;;, 2]], 50, PlotRange->All, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", " "}], PlotLabel->Style[" ", 20]]

اللغات التي تكون فيها أكثر المشكلات التي تم حلها هي:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.1, BarOrigin -> Left, AspectRatio -> 1, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last], {_, x_/; x<200}]

المهام التي تم حلها في أكبر عدد من لغات البرمجة:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.2, BarOrigin -> Left, AspectRatio -> 1.6, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last], {_, x_/; x<100}]

المهام التي لها حل لمجموعة معينة من لغات البرمجة
وظيفة تعرض المهام التي تم حلها بلغة برمجة واحدة أو أكثر في آن واحد:
commonTasks[lang_String]:=commonTasks[lang]=Sort[SelectFirst[$langTasks, #["name"]==lang&][["tasks"]]]; commonTasks["Mathematica"]:=commonTasks["Mathematica"]=Union[commonTasks["Wolfram Language"], Sort[SelectFirst[$langTasks, #["name"]=="Mathematica"&][["tasks"]]]]; commonTasks[lang_List]:=commonTasks[lang]=Sort[Intersection@@(commonTasks/@lang)];
المهام الشائعة في أول 25 لغة شائعة (يتوافق حجم الخط مع العدد النسبي للغات التي تم حل المشكلة بها):
WordCloud[With[{tasks=taskLinkToName/@commonTasks[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-25;;-1]][[;;, 1]]]}, Transpose@{tasks, tasks/.Rule@@@SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last]}], ImageSize->{1000, 1000}, MaxItems->All, WordOrientation->{

وظيفة لقياس طول الرمز
بعد ذلك ، نحتاج إلى قياس لتقدير طول الرمز. ويعتقد عموما أن هذا هو عدد أسطر التعليمات البرمجية:
SetAttributes[lineCount, Listable] lineCount[str_String]:=StringCount[StringReplace[StringReplace[str, {" "->"", "\t"->""}], "\n"..->"\n"], "\n"]+1;
ولكن نظرًا لأن هذه المعلمة تتأثر بشكل كبير بترميز الرمز (في النهاية ، على سبيل المثال ، في Wolfram Langiuage (
Mathematica ) ، يمكنك كتابة العديد من الأوامر في سطر واحد مرة واحدة) ، فسنستخدم عدد الأحرف التي ليست مسافات كمقياس.
SetAttributes[characterCount, Listable] characterCount[str_String]:=StringLength[StringReplace[str, WhitespaceCharacter->""]];
لا يتم تشغيل مثل هذا المقياس في أيدي
Mathematica مع أسماء الأوامر الوصفية الطويلة (والذي لا شك فيه أنه زائد كبير خارج هذه المدونة) ؛ وبالتالي ، فإننا نطبق أيضًا مقياسًا يستند إلى عد الرموز (الكائنات "الرمزية") ، والتي سنتخذ بها كلمات فردية مفصولة بأي حرف لا الرسالة.
SetAttributes[tokens, Listable] tokens[str_String]:=DeleteCases[StringSplit[str, Complement[Characters@FromCharacterCode[Range[1, 127]], CharacterRange["a", "z"], CharacterRange["A", "Z"], CharacterRange["0", "9"], {"."}]], ""]; tokenCount[str_String]:=Length[tokens[str]];
طول رمز القياس
نحصل على مجموعة بيانات بخصوص كل مهمة:
$taskData=Map[<|"name"->#[[1]], "lineCount"->Map[lineCount, #[[2]]], "characterCount"->Map[characterCount, #[[2]]], "tokens"->Map[Flatten[tokens[#]]&, #[[2]]]|>&, $taskLangs]; Dataset[$taskData]

دالة تقوم بجمع إحصائيات لكل لغة فيما يتعلق بجميع المهام التي تم حلها عليها:
Clear[langData]; langData[name_]:=langData[name]=<|"name"->name, "lineCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]], "characterCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]], "tokens"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]|>&@(With[{task=#}, SelectFirst[$taskData, #[["name"]]==task&]]&/@commonTasks[name]); Map[langData, $LanguagesWithTasks];
دالة تقارن مقارنات المقارنة بين لغتين (أو أكثر) من لغات البرمجة بناءً على جميع المهام الشائعة:
ClearAll[compareLanguagesData, compareLanguages]; compareLanguagesData[langs_List/; Length[langs]>=2]:=compareLanguagesData[langs]=Module[{tasks, data}, tasks=commonTasks[langs]; data=langData/@langs; <|"lineCount"->Transpose[Lookup[#[["lineCount"]], tasks][[;;, 1]]&/@data], "characterCount"->Transpose[Lookup[#[["characterCount"]], tasks][[;;, 1]]&/@data], "tokensCount"->Transpose[Lookup[Map[Length, #[["tokens"]]], tasks]&/@data]|> ]; compareLanguages[langs_List/; Length[langs]>=2, function_]:=Module[{data}, data=compareLanguagesData[langs]; Map[Map[function, #]&, data] ];
التحليل والتصور
الآن يمكننا الحصول على الكثير من التحليلات.
بادئ ذي بدء ، قارنا المؤشرات المطلقة. تقوم الوظيفة أدناه بإنشاء رسم بياني تعرض فيه النقاط القيم المقابلة للغتين. إذا كانت النقطة أسفل الخط المائل (يختلف المقياس على طول المحاور ، غالبًا إذا كان طول الكود يتغير بشكل كبير) ، فإن هذا يعني أن اللغة من أسفل "فاز" ، وإلا فإن اللغة "من أعلى".
compareGraphic[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[Graphics[{Map[{If[#[[1]]<#[[2]], Orange, Darker@Green], Point[#]}&, #2], AbsoluteThickness[2], Gray, InfiniteLine[{{0, 0}, {1, 1}}]}, PlotRangePadding->0, GridLines->Automatic, AspectRatio->1, PlotRange->All, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"])]&, compareLanguages[{lang1, lang2}, Identity]], Background->White]
يمكنك أن ترى بوضوح أن رمز لغة Wolfram دائمًا ما يكون أقصر من رمز C:
compareGraphic[{"Mathematica", "C"}]

أو بيطنون:
compareGraphic[{"Mathematica", "Python"}]

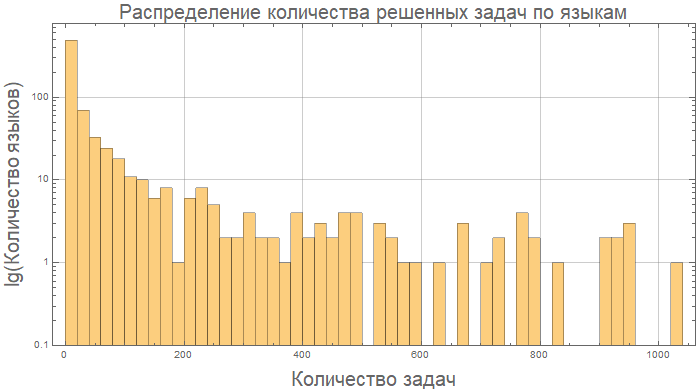
وهنا ، على سبيل المثال ، Kotlin و Java هما "متشابهان" بشكل أساسي من حيث طول الكود:
compareGraphic[{"Kotlin", "Java"}]
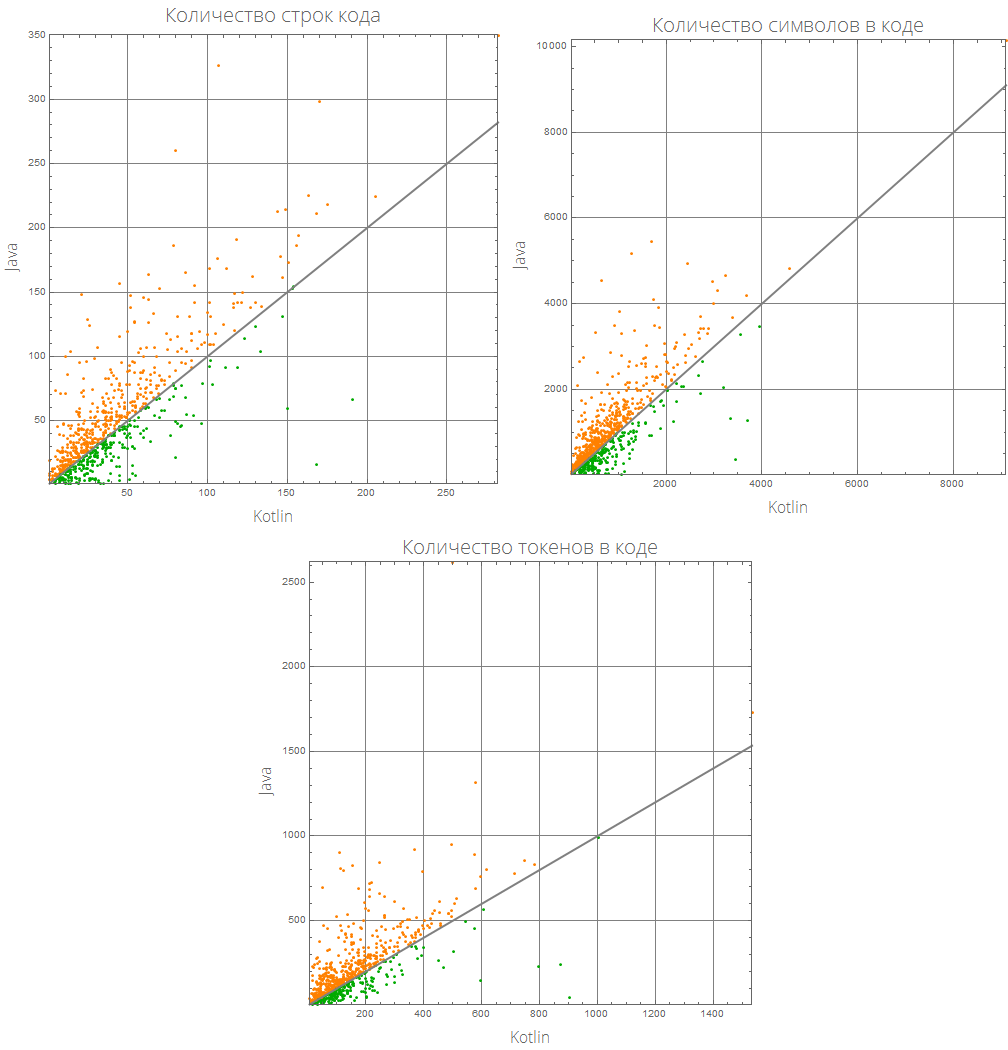
يمكن جعل هذا التمثيل البياني أكثر إفادة:
comparePlot[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[ListLinePlot[Sort@#2, GridLines->Automatic, AspectRatio->1, PlotRange->{Automatic, {0, 2}}, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"]), ColorFunction->(If[#2>1, Orange, Darker@Green]&), ColorFunctionScaling->False, PlotStyle->AbsoluteThickness[3]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]], Background->White]
comparePlot[{"Mathematica", "R"}]
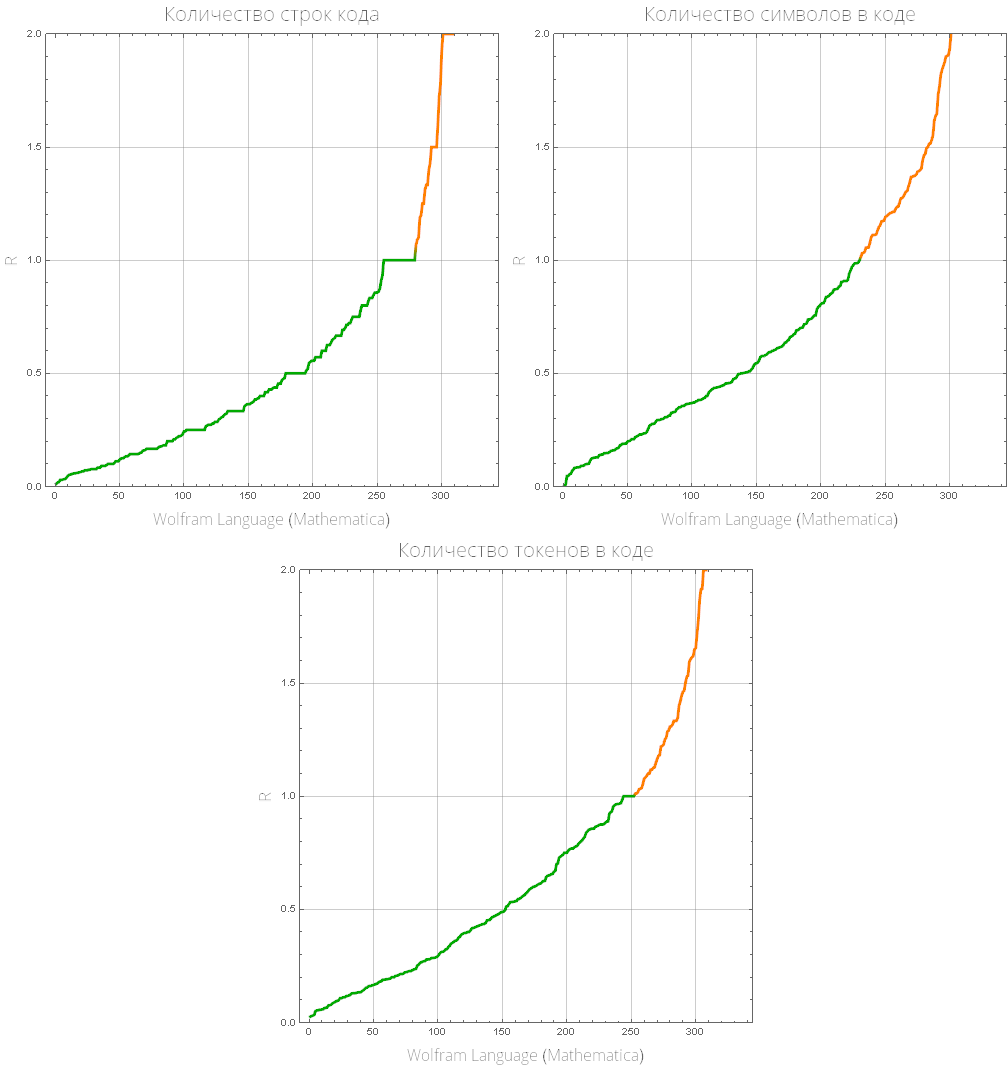
comparePlot[{"BASIC", "ALGOL 68"}]
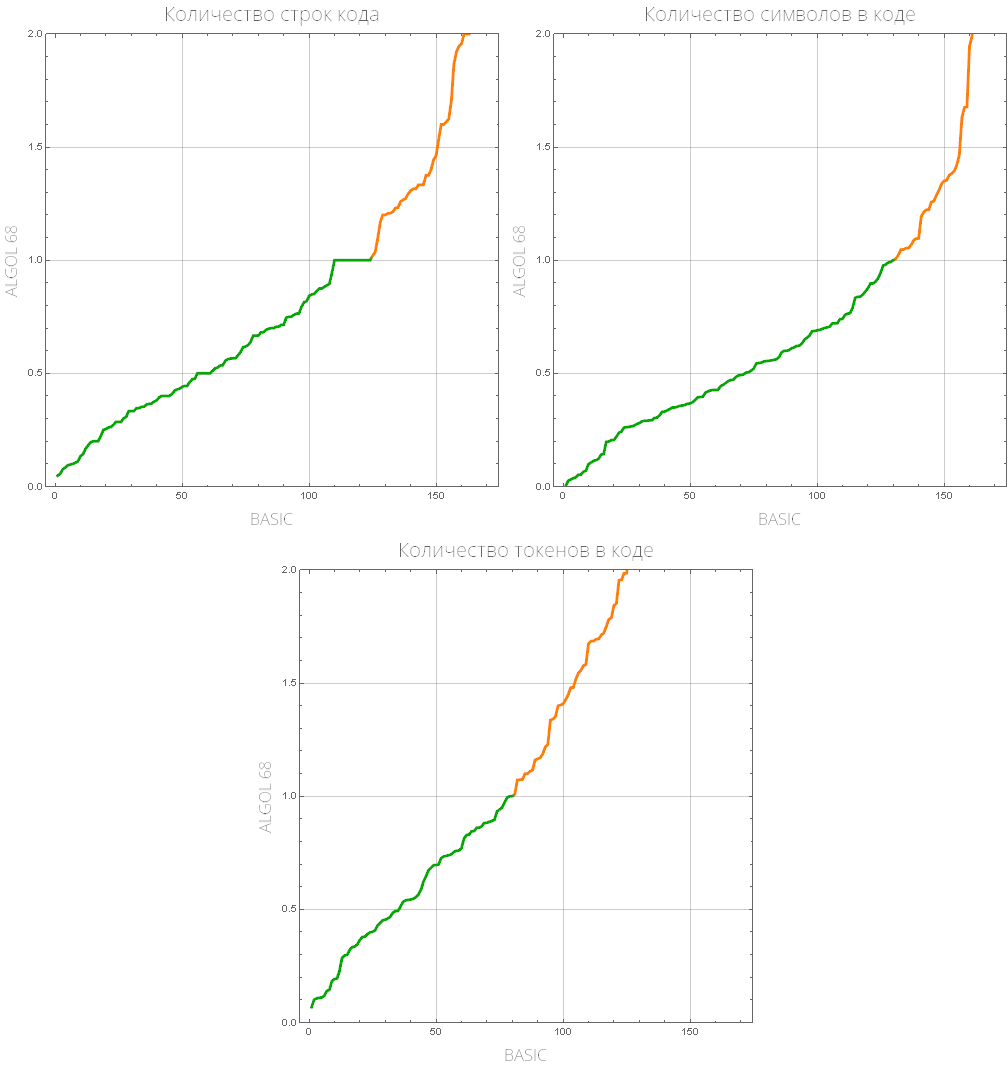
نحدد وظيفة من شأنها أن تعرض قائمة من لغات البرمجة "الشعبية" (تلك التي لديها أكبر عدد من المهام التي تم حلها):
Clear[$popularLanguages]; $popularLanguages[n_/; n>2]:=$popularLanguages[n]=Reverse[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-n;;-1]]]
$popularLanguages[25]

نحن نتصور قائمة أول 350 لغة (هكذا تم إنشاء شاشة التوقف لهذا المنشور في البداية):
WordCloud[$popularLanguages[350], ColorNegate@Binarize@ImageCrop@Import@"D:\\YandexDisk\\WolframMathematicaRuFiles\\388-3885229_rosetta-stone-silhouette-stone-silhouette-png-transparent-png.png", ImageSize->1000, MaxItems->All, WordOrientation->{

دالة تعرض تحليل طول الكود في مقاييس مختلفة للغات الأولى الشائعة:
ClearAll[langMetricsGrid]; langMetricsGrid[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]<OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; orderedMeans=Round[If[OptionValue["SortQ"], Map[Mean, tableData/.""->Nothing][[order]], Map[Mean, tableData/.""->Nothing]], 1/1000]//N; {min, max}=MinMax[Cases[Flatten[tableData], _?NumericQ]]; scale=Function[Evaluate[Rescale[#, {min, max}, {0, 1}]]]; fullTableData=Transpose[{{""}~Join~$pl[[order]]}~Join~{{""}~Join~orderedMeans}~Join~Transpose[{Map[Rotate[#, 90Degree]&, $pl]}~Join~ReplaceAll[tableData, x_?NumericQ:>Item[Round[x, 1/100]//N, Background->Which[x<1, LightGreen, x==1, LightBlue, x>1, LightRed]]][[order]]/.""->Item["", Background->Gray]]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], Grid[fullTableData, Background->White, ItemStyle->Directive[FontSize -> 12, FontFamily->"Open Sans Light"], Dividers->White]], FrameStyle->None, Background->White]];
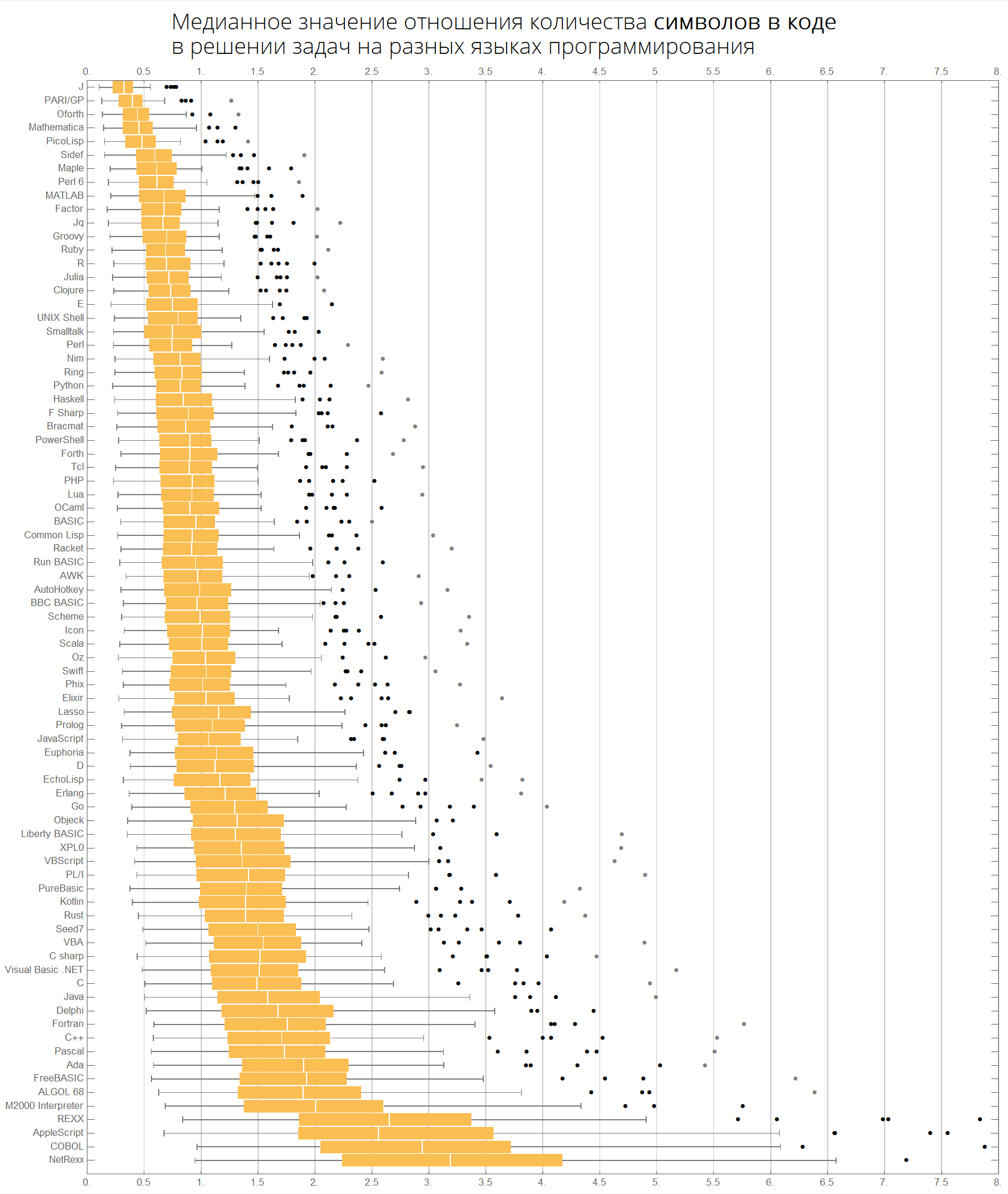
القيمة المتوسطة لنسبة عدد سطور التعليمات البرمجية في حل المشكلات بلغات البرمجة المختلفة:
langMetricsGrid[25, "lineCount", "SortQ"->False]

إذا قمت بفرز الجدول حسب العمود "متوسط" ، فسيكون الأمر أكثر وضوحًا - خيوط Wolfram Language (Mathematica):
langMetricsGrid[25, "lineCount", "SortQ"->True]
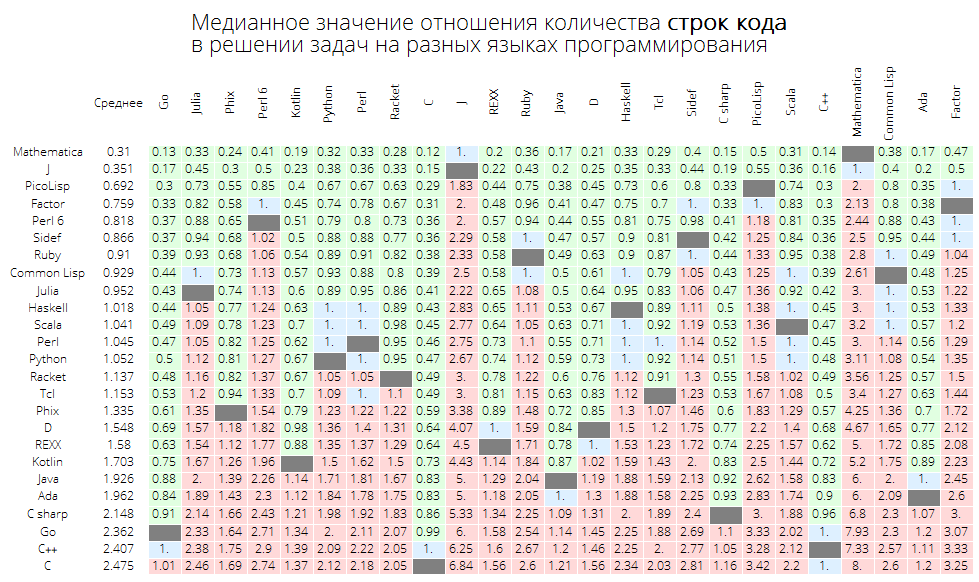
القيمة المتوسطة لنسبة عدد الأحرف في الكود في حل المشكلات بلغات البرمجة المختلفة:
langMetricsGrid[25, "characterCount", "SortQ"->True]

القيمة المتوسطة لنسبة عدد الرموز المميزة في الكود في حل المشكلات بلغات البرمجة المختلفة:
langMetricsGrid[25, "tokensCount", "SortQ"->True]

يمكن بناء نفس الجداول ، على سبيل المثال ، لأول 50 لغة شائعة:
langMetricsGrid[50, "lineCount", "SortQ"->True] langMetricsGrid[50, "characterCount", "SortQ"->True] langMetricsGrid[50, "tokensCount", "SortQ"->True]



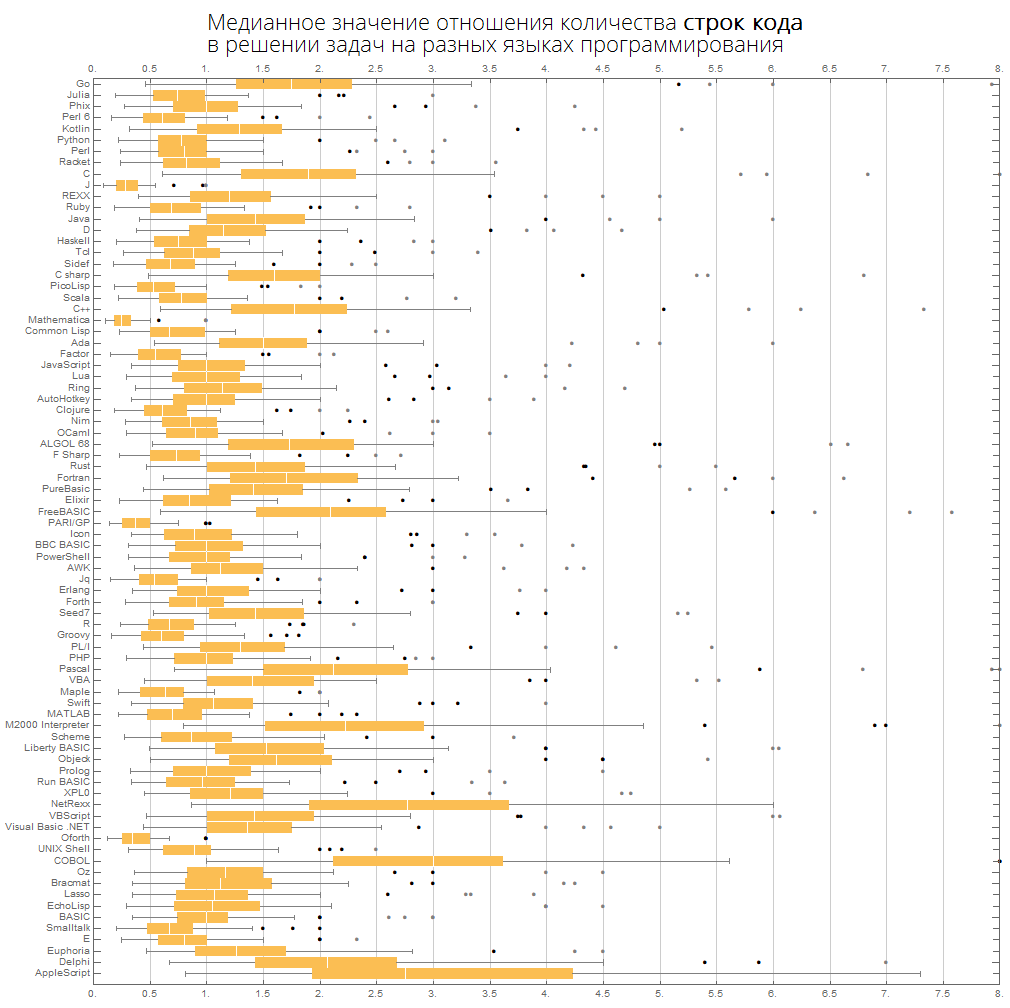
يمكننا أن نتخيل نفس المعلومات بشكل أكثر إحكاما - في شكل مربعات مع شارب (مخطط مربع وشعيرات):
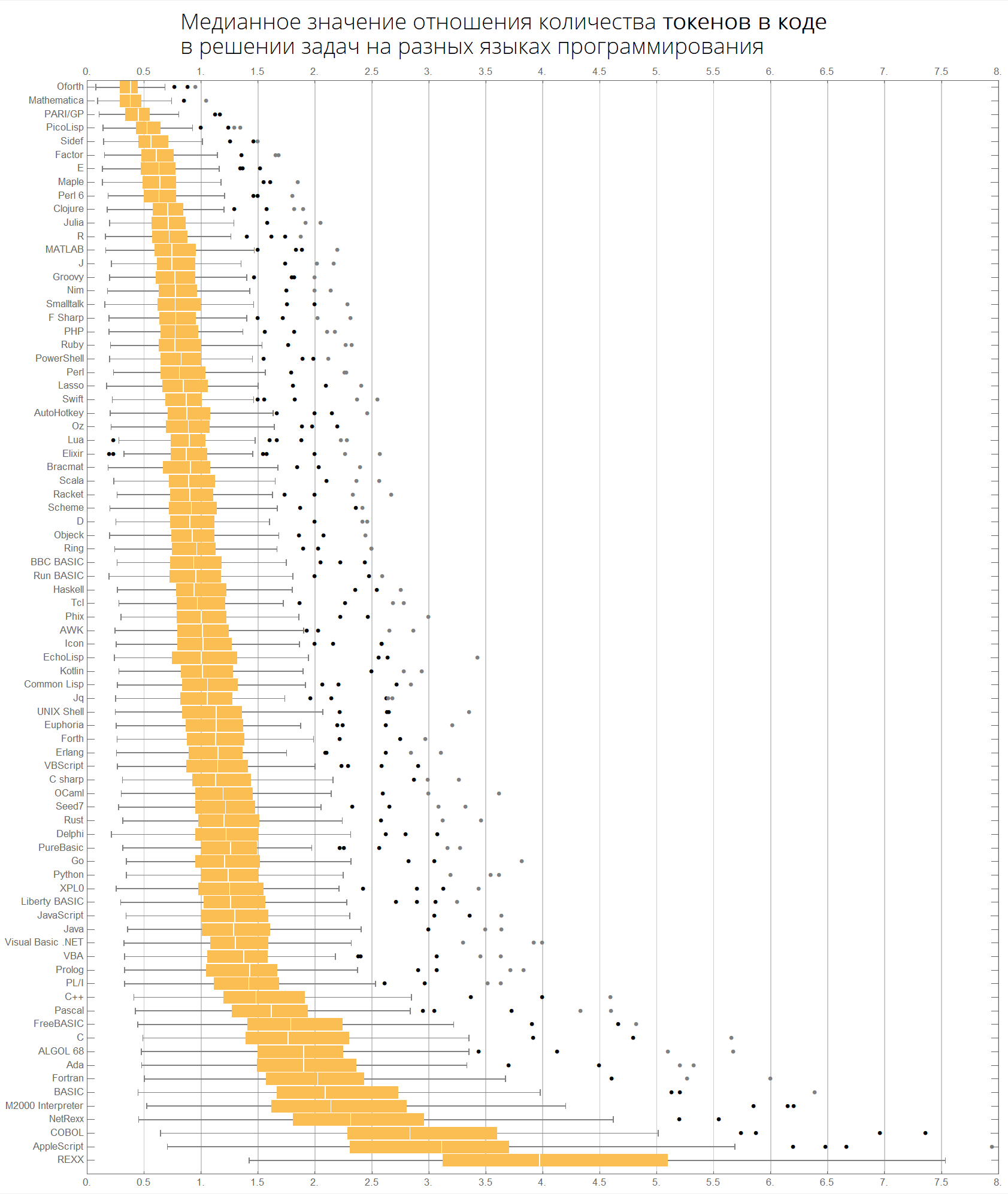
ClearAll[langMetricsBoxWhiskerChart]; langMetricsBoxWhiskerChart[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=Reverse@$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]>OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], BoxWhiskerChart[tableData[[order]], "Outliers", ChartLabels->$pl[[order]], BarOrigin->Left, ImageSize->1000, AspectRatio->1, GridLines->{Range[0, 20, 1/2], None}, FrameTicks->{Range[0, 20, 0.5], Automatic}, PlotRangePadding->0, PlotRange->{{0, 8}, Automatic}, Background->White] ], FrameStyle->None, Background->White]];
يتم فرز اللغات حسب الشعبية (يوضح الرسم البياني نسبة عدد سطور الكود بين اللغات):
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->False]
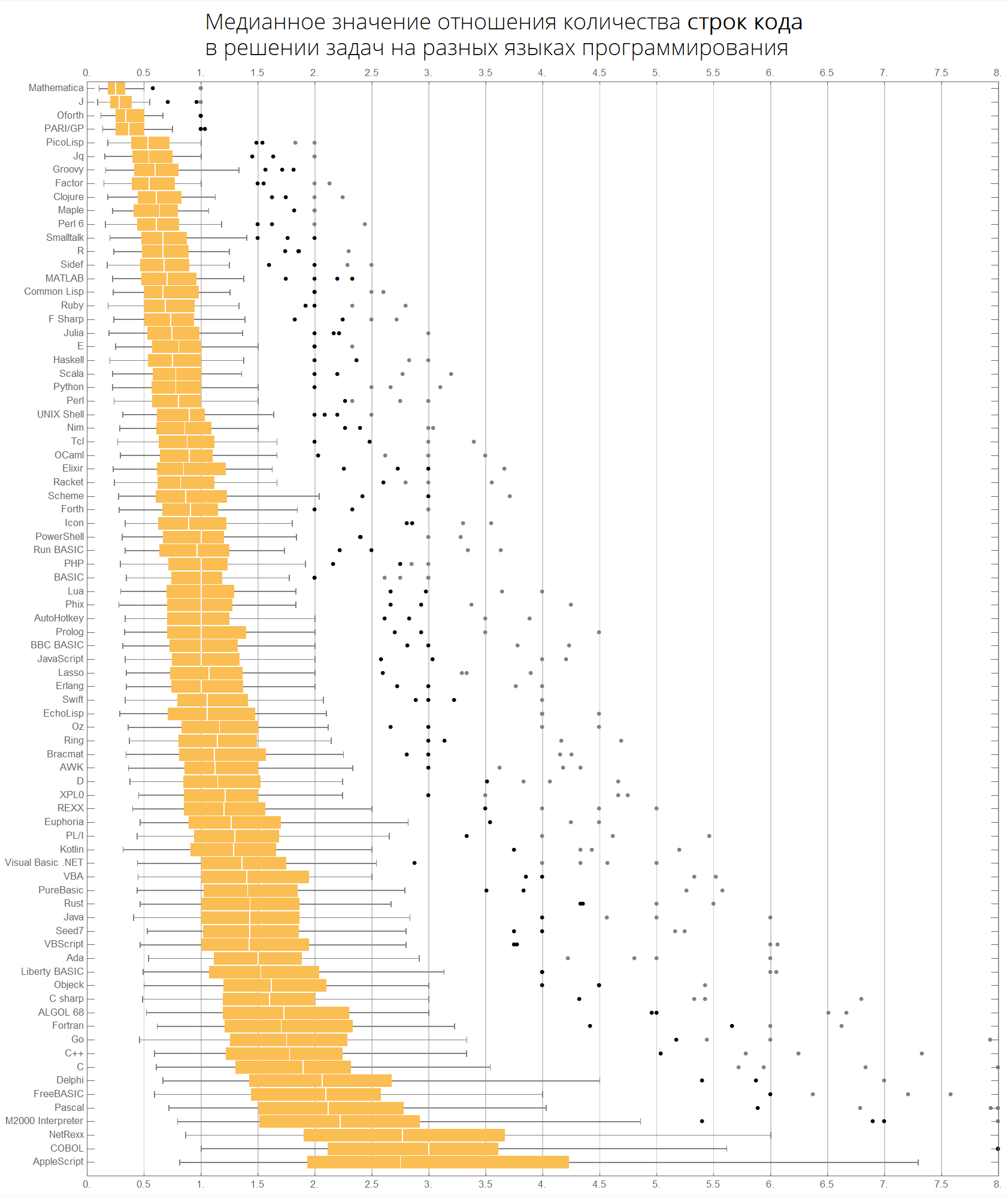
حسب القيمة المتوسطة:
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->True]
أخيرًا ، الرسوم البيانية المتعلقة بعدد الحروف والرموز:
langMetricsBoxWhiskerChart[80, "characterCount", "SortQ"->True] langMetricsBoxWhiskerChart[80, "tokensCount", "SortQ"->True]
لنرى الرموز المميزة الشائعة بلغات مختلفة:
languagePopularTokens[lang_, nMin_:50]:=Framed[Labeled[Style[Row[{" ", Style[lang, Bold]}], FontFamily->"Open Sans Light", 24], WordCloud[Cases[SortBy[Tally[Flatten[Values[langData[lang][["tokens"]]]]], -Last[#]&], {x_/; (StringLength[x]>1&&StringMatchQ[x, RegularExpression["[a-zA-Z0-9.]+"]]&&Not[StringMatchQ[x, RegularExpression["[0-9.]+"]]]), y_/; y>nMin}], ImageSize->{1000, 500}, MaxItems->200, WordOrientation->{
clouds=Grid[{Image[#, ImageSize->All]&@Rasterize[languagePopularTokens[#, 10]]}&/@{"Mathematica", "C", "Python", "Go", "JavaScript"}]

وأخيرًا ، مقارنة مثيرة جدًا للغات استنادًا إلى قرب رموزها.
تعمل وظيفة langSimilarity على النحو التالي: أولاً ، يتم تحديد "الرموز المميزة" (تلك التي تعتبر جميع سلاسل الأحرف اللاتينية بطول لا يقل عن 2 أحرف يمكن أن تحتوي على فترة) ؛ ثم يتم البحث عن الرموز المميزة لزوج من اللغات lang1 و lang2؛ بعد ذلك ، يُعتبر مقياس "التشابه" الخاص بهم ، كمنتج لقياس Jacquard لمجموعتين من الرموز بالكمية المسؤولة عن قرب الرموز بين بعضها البعض (مجموع عناصر النموذج
حيث
هو مجموع المظاهر الرمزية في جميع حلول مشاكل اللغة lang1 و lang2 ، على التوالي).
Clear[langSimilarity]; langSimilarity[{lang1_,lang2_},clearTokens_]:=langSimilarity@@(Sort[{lang1,lang2}]~Join~{clearTokens}); langSimilarity[lang1_,lang2_,clearTokens_:False]:=langSimilarity[lang1,lang2,clearTokens]=Module[{tokens,t1,t2,t1W,t2W,intersection}, tokens[lang_]:=Module[{values,tokensPre,allValues,replacements,n}, values=Values[langData[lang][["tokens"]]]; n=Length[values]; allValues=DeleteDuplicates[Flatten[values]]; tokensPre=If[clearTokens,Cases[allValues,x_/;(StringLength[x]>1&&StringMatchQ[x,RegularExpression["[a-zA-Z0-9._$]+"]]&&Not[StringMatchQ[x,RegularExpression["[0-9.,eE]+"]]])],allValues]; replacements=Dispatch@ Thread[Complement[allValues,tokensPre]->Nothing]; Cases[Tally@Flatten@(values/.replacements),{t_,x_/;x>=n/10}:>{t,x}]]; {t1,t2}=tokens/@{lang1,lang2}; {t1W,t2W}=Dispatch/@{Rule@@@t1,Rule@@@t2}; intersection=Intersection[t1[[;;,1]],t2[[;;,1]]]; Times@@{Total[(#[[1]]+#[[2]])/(1+Abs[#[[1]]-#[[2]]])&/@Transpose@N[{intersection/.t1W,intersection/.t2W}]],Length[intersection]/Length[Union[t1[[;;,1]],t2[[;;,1]]]]}]
ClearAll[langSimilarityGrid]; langSimilarityGrid[n_Integer, OptionsPattern[{"SortQ" -> True, "measureFunction" -> Mean, "clearTokens" -> True}]] := Module[{$nPL, $pl, tableData, notSortedTableData, order, fullTableData, min, max, orderedMeans, median, rescale}, $nPL = n; $pl = $popularLanguages[$nPL][[;; , 1]]; tableData = Quiet@Table[ If[i == j, "", langSimilarity[{$pl[[i]], $pl[[j]]}, OptionValue["clearTokens"]]], {i, 1, $nPL}, {j, 1, $nPL}]; {min, max} = MinMax[Flatten[tableData] /. "" -> Nothing]; median = 10^Median@Log10@Flatten[tableData /. "" -> Nothing]; rescale = Function[Evaluate[Rescale[#, {median, max}, {0, 1}]]]; order = If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1 /. "" -> Nothing] > OptionValue["measureFunction"][#2 /. "" -> Nothing] &], Range[1, $nPL]]; fullTableData = Transpose[{{""}~Join~$pl[[order]]}~Join~ Transpose[{Map[Rotate[#, 90 Degree] &, $pl]}~Join~ ReplaceAll[tableData[[order]], x_?NumericQ :> Item[Style[Round[x, 1], If[x < median, Black, White]], Background -> If[x < median, LightGray, ColorData["Rainbow"][rescale[x]]]]] /. "" -> Item["", Background -> Gray]]]; Framed[ Labeled[Style[ Row[{" ( )", "\n", "(", Style[If[OptionValue["clearTokens"], " ", " "], Bold], ")"}], 22, FontFamily -> "Open Sans Light", TextAlignment -> Center], Grid[fullTableData, Background -> White, ItemStyle -> Directive[FontSize -> 12, FontFamily -> "Open Sans Light"], Dividers -> White]], FrameStyle -> None, Background -> White]];
محدث: بعد تعليق قيِّم ، قرر التجميع إنشاء جدولين: مع الرموز التي تم مسحها وجميع الرموز ، دون أي نوع من التنظيف ، للتأثير على النتيجة بأقل قدر ممكن. النتيجة مختلفة بعض الشيء ، كما ترون بنفسك ، على الرغم من أن بعض التبعيات أصبحت أكثر وضوحًا.
إليك ما نحصل عليه (الجدول غير المصنف):
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> True] langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> False]
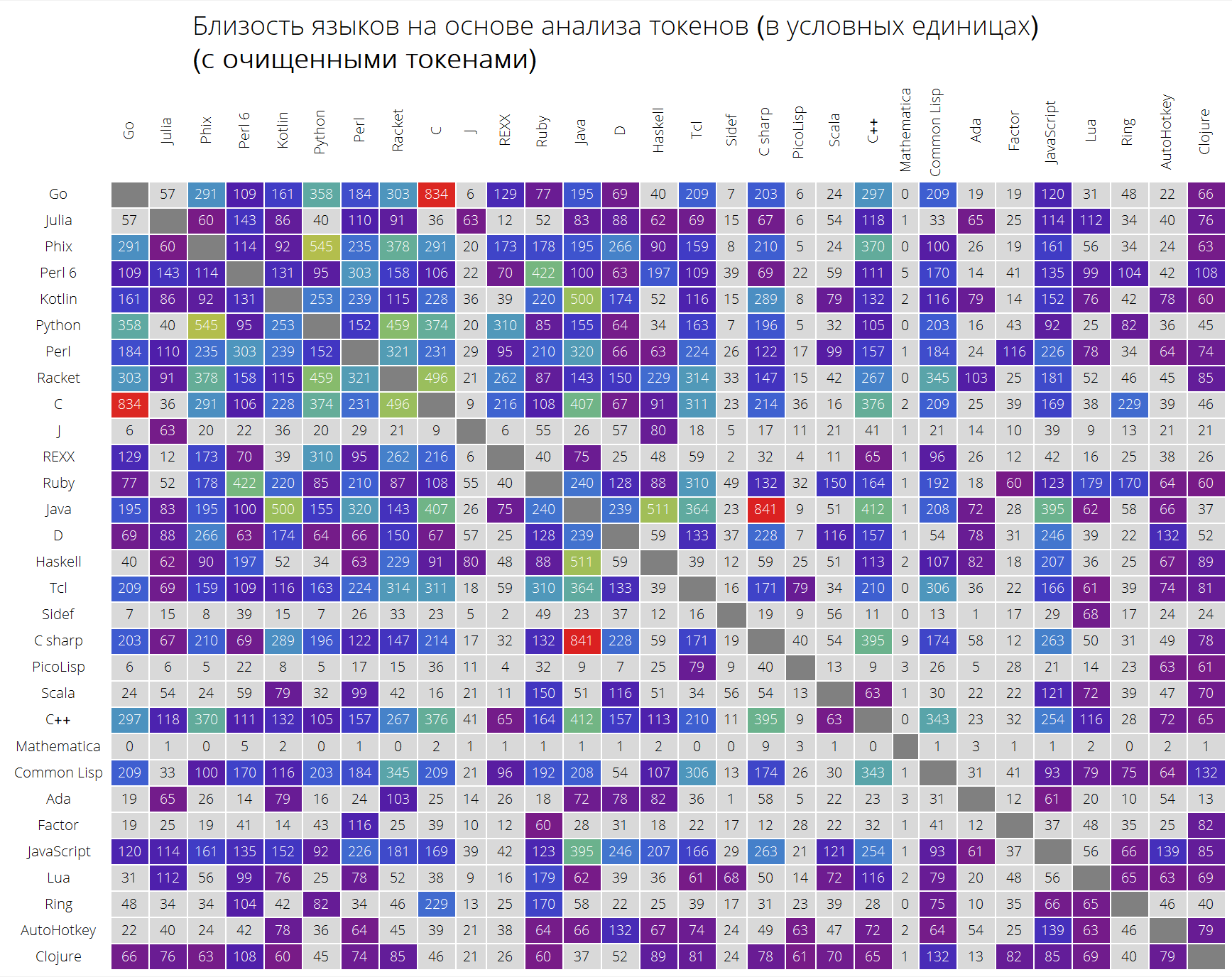

جدول مصنف (من حيث متوسط التشابه مع اللغات الأخرى - كلما زاد الخط ، زاد عدد لغات البرمجة الأخرى التي تبدو عليها هذه اللغة):
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> False]


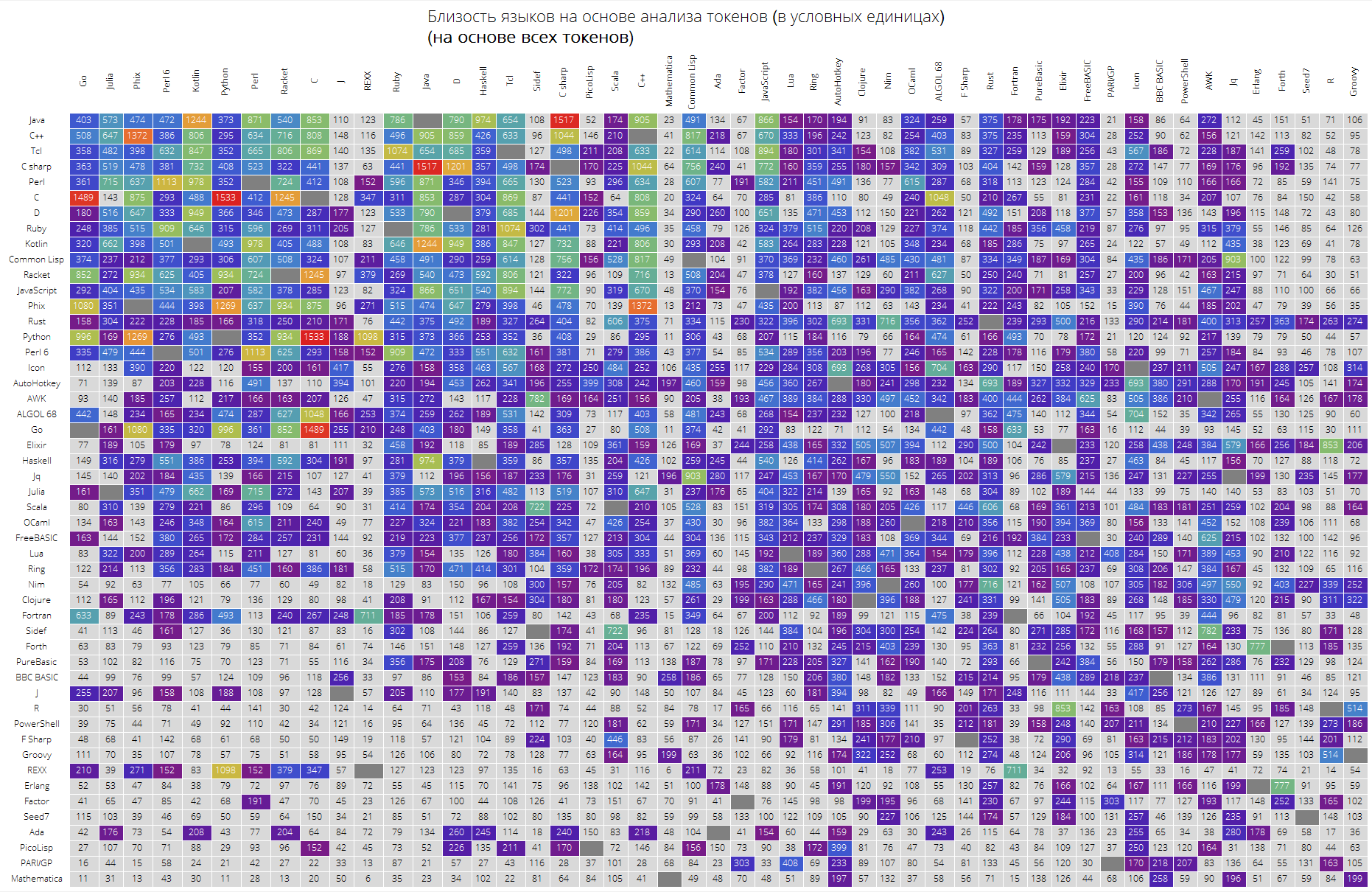
وأخيرا ، طاولة كبيرة لأول 50 لغة في شعبية.
من المتوقع أن تكون اللغات "الرئيسية" مثل Java و C و C ++ و C # في الأعلى. كان Racket (PLTScheme سابقًا) موجودًا ، أحد أهدافه هو إنشاء وتطوير وتنفيذ لغات البرمجة.
ومن المثير للاهتمام ، أن لغة ولفرام تبين أنها لغة مختلفة في الأساس.
إن الروابط بين اللغات مرئية أيضًا ، دعنا نقول أن الرابط بين Java و C # و Go و C و Java و Haskell و Java و Kotlin و Java و Python و Phix و Python و Racket والمزيد مرئي جدًا.
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> False]
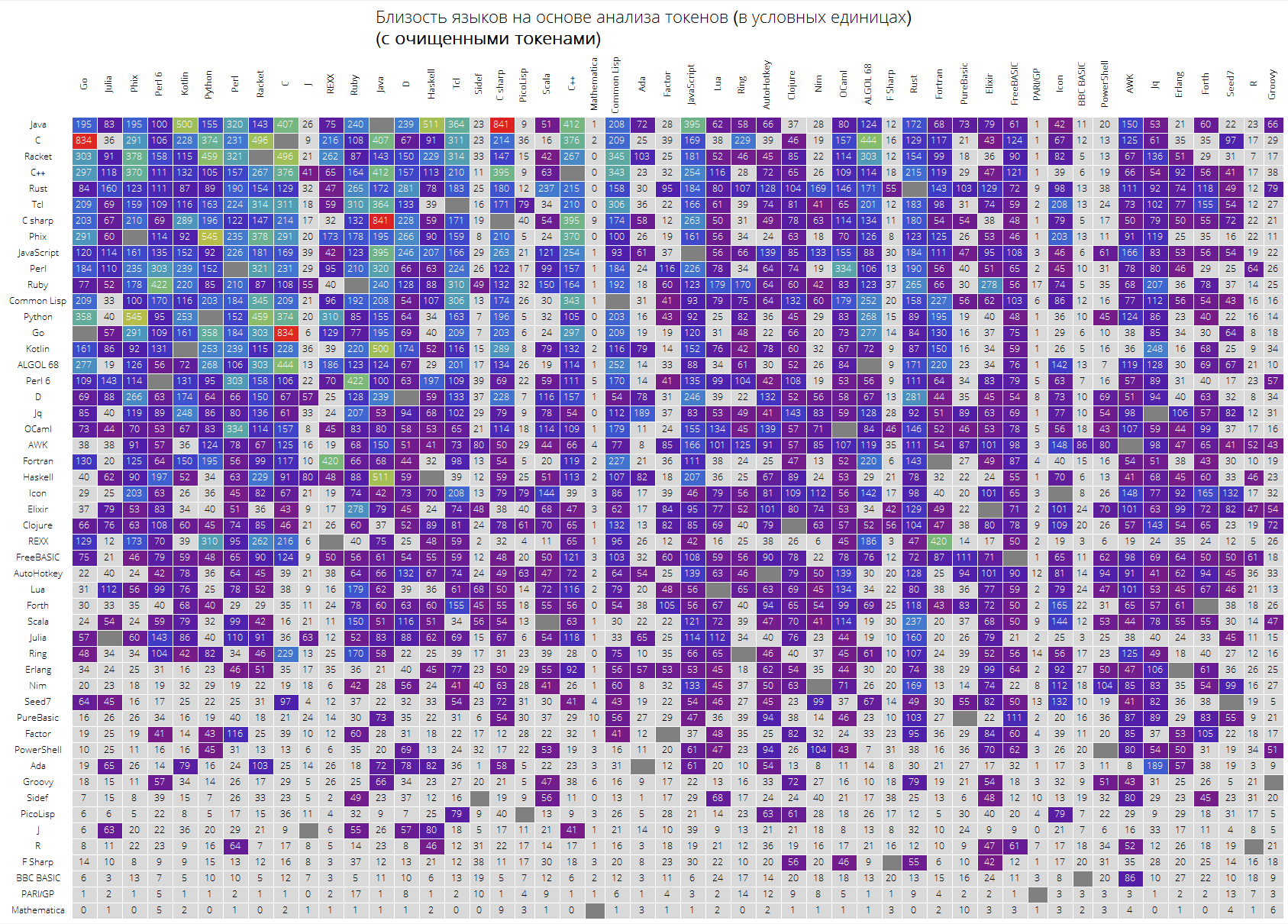
آمل أن تكون هذه الدراسة مثيرة للاهتمام بالنسبة لك وستتمكن من اكتشاف شيء جديد. بالنسبة لي ، بصفتي شخصًا يستخدم لغة ولفرام باستمرار ، كان من الجيد أن نعرف أنها تتحول إلى أكثر اللغات "ضغطًا" ، من ناحية ، من ناحية أخرى ، فإن "الاختلاف" الموضوعي للغات الأخرى يجعل من الصعب إدخالها قليلاً.
تريد أن تتعلم كيفية البرنامج في ولفرام اللغة؟
مشاهدة ندوات أسبوعية.
التسجيل للدورات الجديدة . بالطبع استعداد على الانترنت .