
مرحبا يا هبر! نواصل نشر مراجعات المقالات العلمية من أعضاء مجتمع Open Data Science من القناة #article_essense. إذا كنت ترغب في الحصول عليها قبل أي شخص آخر - انضم إلى المجتمع !
مقالات لهذا اليوم:
- المعادلات التفاضلية العادية العصبية (جامعة تورنتو ، 2018)
- التعلم شبه الخاضع للرقابة مع النماذج العميقة التوليدية: التجميع والتصنيف باستخدام بطاقات Ultra-Sparse (جامعة أكسفورد ، معهد آلان تورينج ، لندن ، 2019)
- الكشف عن التحيز الحسابي وتخفيف حدته من خلال بنية كامنة مستفادة (معهد ماساتشوستس للتكنولوجيا ، جامعة هارفارد ، 2019)
- التعلم التعزيز العميق من التفضيلات البشرية (OpenAI ، DeepMind ، 2017)
- استكشاف الشبكات العصبية السلكية العشوائية للتعرف على الصور (Facebook AI Research، 2019)
- Photofeeler-D3: شبكة عصبية مع نمذجة الناخبين لتقييم الصور التي يرجع تاريخها (Photofeeler Inc. ، 2019)
- MixMatch: منهج كلي للتعلم شبه الخاضع للإشراف (Google Reasearch ، 2019)
- قسّم واحتل مساحة التضمين للتعلم المتري (جامعة هايدلبرغ ، 2019)
روابط للمجموعات السابقة من السلسلة: 1. المعادلات التفاضلية العادية العصبية
المؤلفون: ريكي تي كيو تشن ، يوليا روبانوفا ، جيسي بيتينكور ، ديفيد دوفينود (جامعة تورنتو ، 2018)
→ المادة الأصلية
مؤلف الاستعراض: جورج Ignatov (في الركود a2dy2n7okhtp)
NIPS Best Paper Award

لاحظ مؤلفو المقال أن الشبكات المشابهة لـ ResNet تشبه إلى حد كبير طريقة أويلر لحل المعادلات التفاضلية. إذا كان الأمر كذلك ، فلماذا لا تصل الفكرة على الفور إلى الحد الأقصى: تخيل شبكة عصبية في شكل معادلة تفاضلية واحصل على
- شبكة ذات عدد تعسفي من الطبقات ، والتي يمكن تغييرها في أي وقت أثناء التدريب والاستدلال. المزيد من الطبقات -> تحويلات أكثر دقة وسلاسة (والعكس صحيح).
- عدد أقل بكثير من المعلمات ، وبالتالي ، انخفاض تكاليف الذاكرة.
NODE من خلال القياس:
- - هذا هو كيف يبدو تعريف الإخراج من الطبقة n في شبكة تشبه resnet ، W - المعلمات.
- - قد يبدو ذلك مثل شبكة تشبه NODE ، شريطة أن تكون n كمية منفصلة.
- . - طريقة أويلر.
- - تا دا! ODE تعمل بالطاقة الشبكة العصبية.
نقوم بحلها باستخدام أي ODEsolver الصندوق الأسود ، ورمي التدرجات باستخدام طريقة الحساسية المجاورة (Pontryagin et al. ، 1962). نظرًا لاختلافه التام ، يمكن دمج NODE مع الشبكات العصبية التقليدية. نشر المؤلفون الكود على pytorch.
يناقش المقال 3 تطبيقات:
- مقارنة مع بنية تشبه ResNet (على MNIST). لا يعمل NODE بشكل أسوأ تقريبًا ، مع استخدام معلمات أقل بثلاث مرات.
- تجاوز التدفقات المعيارية من خلال NODE - التدفقات المعيارية المستمرة (مجموعة البيانات الاصطناعية). يقلل الطراز الجديد من تكاليف الحوسبة من O (n_hidden_units ^ 3) إلى خطي.
- نمذجة الأحداث المؤقتة مع الملاحظات غير النظامية (مجموعة البيانات الاصطناعية). تم إنشاء مجموعة من المسارات الحلزونية التي رشت منها نقاط العينة العشوائية: الملح: ضجيج غاوسي من أجل المعقولية. لقد اختبر RNN و NODE المعتاد ، والثاني أثبت مرة أخرى أنه أفضل.
في مطبوعات صغيرة:
- يتسبب تدريب Minibatch في نوع من النفقات العامة الحسابية ، لكن المؤلفين يجادلون بأن هذا الأمر غير مرئي تقريبًا في الممارسة العملية.
- تظهر معلمتان جديدتان: عمق الشبكة وتحمل الأخطاء عند حل ODE.
- من أجل أن يظل حل ODE فريدًا ، يجب أن يكون للشبكة أوزان محدودة وأن تستخدم خطي Lipshitz ، مثل tanh أو relu.
رابط إلى نظرة عامة أكثر تفصيلا على habr.
2. التعلم شبه الخاضع للإشراف مع النماذج العميقة العميقة: التجميع والتصنيف باستخدام علامات فائقة الانتشار
كاتب المقال: ماثيو ويلتس ، ستيفن روبرتس وكريستوفر هولمز
(جامعة أكسفورد ، معهد آلان تورينج ، لندن ، 2019)
→ المادة الأصلية
مؤلف المراجعة: Alex Chiron (في sliron shiron8bit)
ينظر المؤلفون في حالة شبه خاضعة للإشراف لمشكلة التصنيف ، عندما لم يتم تسمية أي جزء من الفئات الموجودة في الترميز بسبب تحيز الاختيار على الإطلاق ، ولم يتم تسمية الكثير منهم وفقًا لفئات البيانات المعروفة. هذا يخلق مشاكل إضافية ، لأن معظم النماذج تعمل عادة إما في وضع شبه خاضع للإشراف / تحت التصنيف (تصنيف) أو في وضع غير خاضع للرقابة (تجميع) ، وفي هذه الحالة نحتاج إلى النظر في كلا الخيارين. علاوة على ذلك ، يمكن أن يؤدي استخدام خوارزميات شبه خاضعة للإشراف إلى حقيقة أنه سيتم تخصيص بيانات غير مخصصة وفقًا لبعض المقاييس القريبة من الفئات غير الصحيحة. مثال افتراضي على هذه البيانات هو مجموعة من عمليات مسح الورم. أخذنا جزءًا من البيانات وقمنا بتمييز جميع أنواع الأورام الموجودة في هذا الجزء ، لكن اتضح أن أنواعًا أخرى من الأورام كانت موجودة في البيانات المتبقية ، ولم ينعكس تمامًا تباين الأنواع المعروفة في الترميز.
استُوحى المؤلفون من النماذج التوليفية العميقة (أبسط مثال على هذا النموذج مع عمق طبقة واحدة من المتغيرات المخفية هو تشفير تلقائي تنويري ، ويعرف أيضًا باسم VAE): في الأعمال السابقة ، نجحت هذه النماذج في التكيُّف مع كل من الحالة شبه الخاضعة للإشراف (M2 ، ADGM) والتجميع ( VaDE ، GM-VAE).
لماذا لا تحل مشكلتين في نفس الوقت (التعلم شبه الخاضع للفصول التي نادرا ما يتم ترميزها وغير خاضع للرقابة في الفصول غير المستغلة) ، مع الحفاظ على فضاء المتغيرات الكامنة المستفادة المشتركة والجمع بين الأفكار من النماذج المذكورة أعلاه؟ هذه هي الفكرة التي تقوم عليها نماذج GM-DGM / AGM-DGM المقترحة في المقالة.
النظر في نموذج M2 في حالة شبه إشراف. يُطلق عليه ذلك ، لأنه ضمن M1 ، قام المنشئ بتضمين تدريب متسلسل لـ VAE وبعض المصنف (svm) للتمثيلات الكامنة الناتجة عن z ، لكن M2 تم الحصول عليه بالفعل من VAE عن طريق إضافة المتغيرات المخفية إلى طبقة المتغيرات الخفية ، المسؤولة عن الفصل المرصود في بعض الأحيان.
.
حيث .
هنا q عبارة عن مشفر ، p عبارة عن وحدة فك تشفير ، جزء - المصنف المدربين مباشرة.
بالنسبة للحالة غير المراقبة / شبه غير المراقبة ، لا تعمل M2 - يحدث الانهيار الخلفي ، وينهار جزء التصنيف q_phi (y | x) إلى توزيع مسبق p (y). أظهر مؤلف GM-VAE في مقالته أيضًا عدم فعالية M2 في الممارسة العملية ، وأشار إلى أنه في كثير من الأحيان عند تطبيق M2 ، فإن الطبقة الأولى من وحدة فك الترميز h1 تشبه إلى حد كبير مزيج من الغاوسيين.
استنادًا إلى هذه الملاحظة ، يستخدم GM-VAE طبقة صريحة من المتغيرات المخفية لتجميع خليط غاوسي للتكتل ، والذي يتكرر أيضًا من قِبل واضعي هذه المقالة ، وبالتالي فإن نموذج GM-DGM ، الذي يسمح بالتشغيل الناجح في الوضع شبه الخاضع للإشراف ، يعد تعديلاً تستخدم VAE مزيجًا من Gaussians في طبقة مخفية ، اعتمادًا على متغير من الفئة y ، مع الوظيفة المذكورة أعلاه لفترتين لحساب وتوسيع ELBO.
أجرى مؤلفو المقال تجربة على نسخة شبه خاضعة للإشراف من Fashion-MNIST: لقد أزالوا ملصقات الفئات الخمسة الأولى ، وتركت الطبقات الخمسة المتبقية 5٪ من الملصقات ، بينما تلقوا دقة إجمالية قدرها 77.2٪ مقابل 53٪ لـ M2. تم أيضًا عرض إمكانية استخدام نموذج التجميع (وهذا ليس مفاجئًا ، لأنه GM-VAE تقريبًا).
3. كشف وتخفيف التحيز الخوارزمي من خلال بنية كامنة مستفادة
المؤلفون: ألكسندر أميني ، آفا سوليماني ، ويلكو شوارتينج ، سانجيتا ن. بهاتيا ، دانييلا روس (معهد ماساتشوستس للتكنولوجيا ، جامعة هارفارد ، 2019)
→ المادة الأصلية
مؤلف المراجعة: Alex Chiron (في sliron shiron8bit)
في الآونة الأخيرة ، في كثير من الأحيان في وسائل الإعلام ، يمكنك العثور على أخبار تمس موضوع التحيز في البيانات ، خاصة فيما يتعلق بالخوارزميات المتعلقة بالأفراد - مع نمو قابليتها للتطبيق ، وخطر التأثير السلبي القوي على تلك الفئات ومجموعات الأشخاص غير الكافية (أو المفرطة) قدمت في مجموعة البيانات. واحدة من أحدث الأمثلة هي دراسة أظهرت دقة أقل في الكشف عن المشاة بلون البشرة الداكن (في سياق الكشف عن الكائنات في مجموعات البيانات القياسية BDD100K و MSCOCO ، الرابط ). الطرق الأساسية للقضاء على التحيزات:
- موازنة الفصل باستخدام إعادة التشكيل (يتطلب فهمًا أوليًا لبنية البيانات المخفية).
- توليد بيانات غير متحيزة (على سبيل المثال ، استخدام GAN لتوليد أفراد بمجموعة واسعة من درجات البشرة ).
- التجميع وإعادة التشكيل اللاحقة.
- لا يزال بإمكانك الانتظار حتى يتم إحضار مجموعة بيانات IBM Diversity in Faces إلى الأكاديميين.
يقدم مؤلفو المقال تعديلاً على VAE وأخذ العينات ، مع مراعاة توزيع المتغير الكامن z ، والذي يمكن أن يقلل من تأثير التحيز في البيانات في مرحلة التدريب.
لذا ، فإن الأفكار الرئيسية وراء DB-VAE هي:
- ضع في اعتبارك مشكلة التصنيف التي لدينا فيها مجموعة بيانات التدريب {(x، y)}، x هي ميزات m-dimensional، y هي علامات d-dimensional، ومهمتنا هي تقريب التعيين X-> Y.
- لنأخذ VAE ، ولكن بالإضافة إلى متجه المتغيرات الخفية z من البعد 2k (نتذكر ، 2 هنا لأننا نتعامل مع الوسائل والتباينات) ، سنتعلم أيضًا تشفير البعد d ، المسؤول عن التسميات المذكورة أعلاه. في هذه الحالة ، يقبل مفكك التشفير فقط المتجه z كمدخل. وبالتالي ، نحصل على ما يشبه التعلم شبه الخاضع للإشراف ، حيث يتم تعلم جزء من النموذج لإعادة بناء المدخلات ، والجزء الآخر هو حل مشكلة معينة (التصنيف).
- نحن نتحكم في تدريب النموذج بسبب الخسارة المدمجة ، حيث نجمع بين معيار خسارة VAE (إعادة بناء + اختلاف KL) وفقدان مشكلة مساعدة (على سبيل المثال ، الانتروبيا لمشكلة التصنيف الثنائي).
- يتم إيلاء اهتمام خاص لحقيقة أنك تحتاج إلى التحكم في التدريب على البيانات التي لا تريد تصحيحها (أي ، لا تقم بإرجاعها من وحدة فك الترميز).
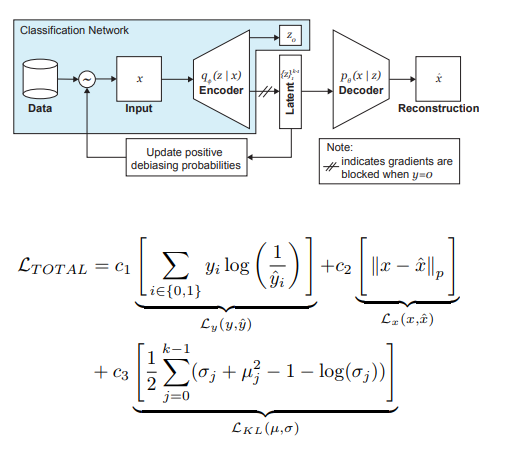
لعبت الدور الأكثر أهمية في القضاء على ألم السود عن طريق أخذ العينات التكيفية في مرحلة التدريب. نريد اختيار عينات نادرة (من وجهة نظر بعض العوامل المخفية ، غير المحددة بوضوح) ، لذلك ننتقل إلى الرسوم البيانية لكل بُعد من أبعاد مساحة المتغيرات المخفية z ، التي يمكن أن يقارب منتجها توزيع Q (z | X) للبيانات على كامل مساحة Z. عند تشكيل مجموعة جديدة ، سنأخذ في الاعتبار "معكوس" لتوزيع Q (z | X) W (z (x) | X) ، والذي يحدد احتمال اختيار مثال في الدفعة (alpha هو مقياس تشعبي يحدد درجة debiasing) ، وتحديث Q (z | س) في كل عصر. كما ترون ، الحذف ليس محددًا مسبقًا ، بل يعتمد على المتغيرات الكامنة المستفادة.
كتجربة ، حل المؤلفون مشكلة التصنيف الثنائي (العثور على الوجه في الصورة). للتدريب ، جمعنا مجموعة البيانات ، التي تتألف من 200 ألف شخص مع CelebA و 200 ألف من غير Imagenet ، بتغيير حجم الصور إلى 64 × 64. كما ذكرنا سابقًا ، أثناء التدريب ، تم حظر backpropagation من وحدة فك ترميز الصور بدون الوجوه (y = 0). بعد التدريب ، تم التحقق من صحتها في "دليل البرلمانات الرائدة" (PPB) (1270 صورة لأشخاص من برلمانات جنوب إفريقيا ورواندا والسنغال والسويد وفنلندا وأيسلندا): بالنسبة إلى جميع alpha> 0 ، زادت دقة الكشف في فئات الذكور الداكنة والإناث الداكنة والإناث الفاتحة مقارنةً بـ الخيار دون الانحراف.
4. التعزيز العميق التعلم من تفضيلات الإنسان
المؤلفون: بول كريستيان ، جان ليك ، توم بي براون ، ميلجان مارتيتش ، شين ليج ، داريو أمودي (OpenAI ، DeepMind ، 2017)
→ المادة الأصلية
مؤلف الاستعراض: ديمتري نيكولين (في الركود dniku)
تتناول هذه المقالة كيفية تنفيذ الفكرة القديمة في سياق تعلم التعزيز العميق (RL). الفكرة: دعنا نطلب من شخص ما تقييم سلوك الوكيل ، وبناءً على ذلك سنتعلم وظيفة المكافأة. المشكلة هي أن RL العميق هو شره جدا ، والوقت البشري باهظ الثمن. توفر المقالة مجموعة من الاختراقات التي تسمح لك بتقليل ساعات العمل إلى قيم معقولة.
وظيفة المكافأة هي وظيفة على أزواج (الملاحظة ، العمل). يتم تعيينه عن طريق حساب متوسط التنبؤ لمجموعة من الشبكات العصبية. تعتقد خوارزميات RL المستخدمة (في المقالة A2C لـ Atari و TRPO لـ Mujoco) أن هذا المتوسط هو مكافأة حقيقية ، ويتم تدريبهم عليها. وبالتالي ، يركز المقال على مسألة تدريب هذه المجموعة.
يتم تدريب الفرقة على التقييمات البشرية. كل تصنيف منظم على النحو التالي. يظهر الشخص مقطعين فيديو من وكيل 1-2 ثانية طويلة. يمكنه تقييم مثل هذا الزوج بأربع طرق: اليسار أفضل / اليمين أفضل / مشابه جدًا / لا يضاهى. إذا قال شخص ما "لا يضاهى" ، فسيتم إلقاء مثل هذا التقييم بعيدًا. بخلاف ذلك ، يتم تذكر الثلاثية (σ¹ و σ² و μ) ، حيث σⁱ هو مسار العامل في الفيديو المقابل (مثل قائمة الأزواج (obs ، act)) ، و μ هو الزوج (1 ، 0) ، (0 ، 1) ) أو (½، ½). علاوة على ذلك ، يعتقد أن التنبؤ بمكافأة المسار يساوي مجموع التنبؤات لكل زوج (obs ، act). أخيرًا ، نقوم ببساطة بتحسين softmax_cross_entropy_with_logits.
يُعتقد أن الشخص الذي لديه احتمال بنسبة 10٪ يختار إجابة عشوائية ، ويتم أخذ ذلك في الاعتبار عند إنشاء نموذج تدريبي. القسم 2.2.3 من المقال يعطي بعض الحيل ويكتب كل الصيغ.
يتم اختيار أزواج من مقاطع العرض التوضيحي لشخص ما على النحو التالي: يتم أخذ عينات كبيرة من المقاطع ، ويتم النظر في تشتت المجموعة عليها ، ويتم عرض أزواج عشوائية من المقاطع ذات التشتت العالي للأشخاص. يقول المؤلفون أنني أرغب في الاختيار وفقًا لقيمة المعلومات ، لكن هذا عمل مستقبلي.
يجرى المؤلفون اختبارات على أتاري وموجوكو ، مع تصنيفات بشرية حقيقية (المقاولون المستأجرون) والتركيبية (يتم إنشاء التصنيفات وفقًا لوظيفة المكافأة الحقيقية) ، وفي نفس الوقت تتم مقارنتها مع RL المعتاد. مع عدد متساوٍ تقريبًا من التصنيفات ، تعمل الاختبارات الاصطناعية والحقيقية على نحو مماثل. علاوة على ذلك ، من المستغرب أن RL المنتظم (الذي يرى وظيفة المكافأة الحقيقية) لا يعمل بالضرورة بشكل أفضل.
أخيرًا ، بالإضافة إلى محاولة تدريب الوكيل على الحصول على الكثير من المكافآت بالمعنى المعتاد ، تقدم المقالة أيضًا أمثلة على مهمتين أخريين: يقوم Hopper in Mujoco بعمل ارتجاعي ، والآلة في Atari Enduro لا تتفوق على السيارات الأخرى ، لكنها تسير بالتوازي معها. اتضح لحل كل المشاكل.
في الختام: يصف المثال محاولة إعادة إنتاج هذه المقالة. كانت المحاولة ناجحة ، لكنها استغرقت 8 أشهر من العمل في وقت الفراغ و 220 ساعة من الوقت الخالص ، نصفها ذهب لتصحيح أبسط إصدار.
5. استكشاف الشبكات العصبية السلكية عشوائيا للتعرف على الصور
المؤلفون: سينينج شيه ، ألكساندر كيريلوف ، روس جيرشيك ، كايمينغ هي (Facebook AI Research، 2019)
→ المادة الأصلية
مؤلف المراجعة: إيجور بانفيلوف (في فترة الركود tutk1ja)
مقدمة:
يثير العمل مسألة إنشاء هندسة الشبكات العصبية. حاليًا ، تُعرف العديد من الحيل المعمارية (LSTM ، و Inception ، و ResNet ، و DenseNet) ، والتي يمكنها تحسين جودة العديد من المهام ، ولكنها تُقدم أيضًا معمارية قوية معينة قبل النموذج. بدلاً من الحلول المذكورة ، تمضي Google قدما في بحثها عن الهندسة المعمارية العصبية (NAS) ، حيث يتم البحث عن الهندسة المعمارية لمهمة محددة من خلال وحدات محددة مسبقا عبر RL - NASNet ، AmoebaNet.
يجادل المؤلفون بأن كلا الطريقتين حيث يتم تحديد التصميم من قبل الإنسان و NAS تقدم صارمة للغاية قبل الهندسة المعمارية. في محاولة لتقليصها ، يحاولون استخدام النهج التوليفي المعلمي للشبكة العصبية ، حيث يتم تنفيذ توصيل الأسلاك (العناصر) بشكل عشوائي. اتضح أنه تم استكشاف أساليب الأسلاك العشوائية منذ الأربعينيات من قبل علماء مثل أ. تورينج ، م. مينسكي ، ف. روزنبلات. وكحجة أخرى ، يتذكر المؤلفون أنه في الدراسات العلمية العصبية تبين أن بنية الوصلات العصبية في الكائنات الحية من نوع واحد مختلفة (حتى مستوى معين من التفاصيل ، بالطبع). هذا صحيح بالنسبة لكل من الديدان والرضع البشري ، بشكل عام ، تبدو فكرة الجيل الإجرائي للشبكات العصبية مثيرة للاهتمام وواعدة ، وهو ما يدور حوله العمل.
الأسلوب:
دعنا نحاول تنظيم عملية إنشاء إجرائية لهندسة الشبكات العصبية من خلال نهج الرسم البياني. الخطوات الأولية كالتالي:
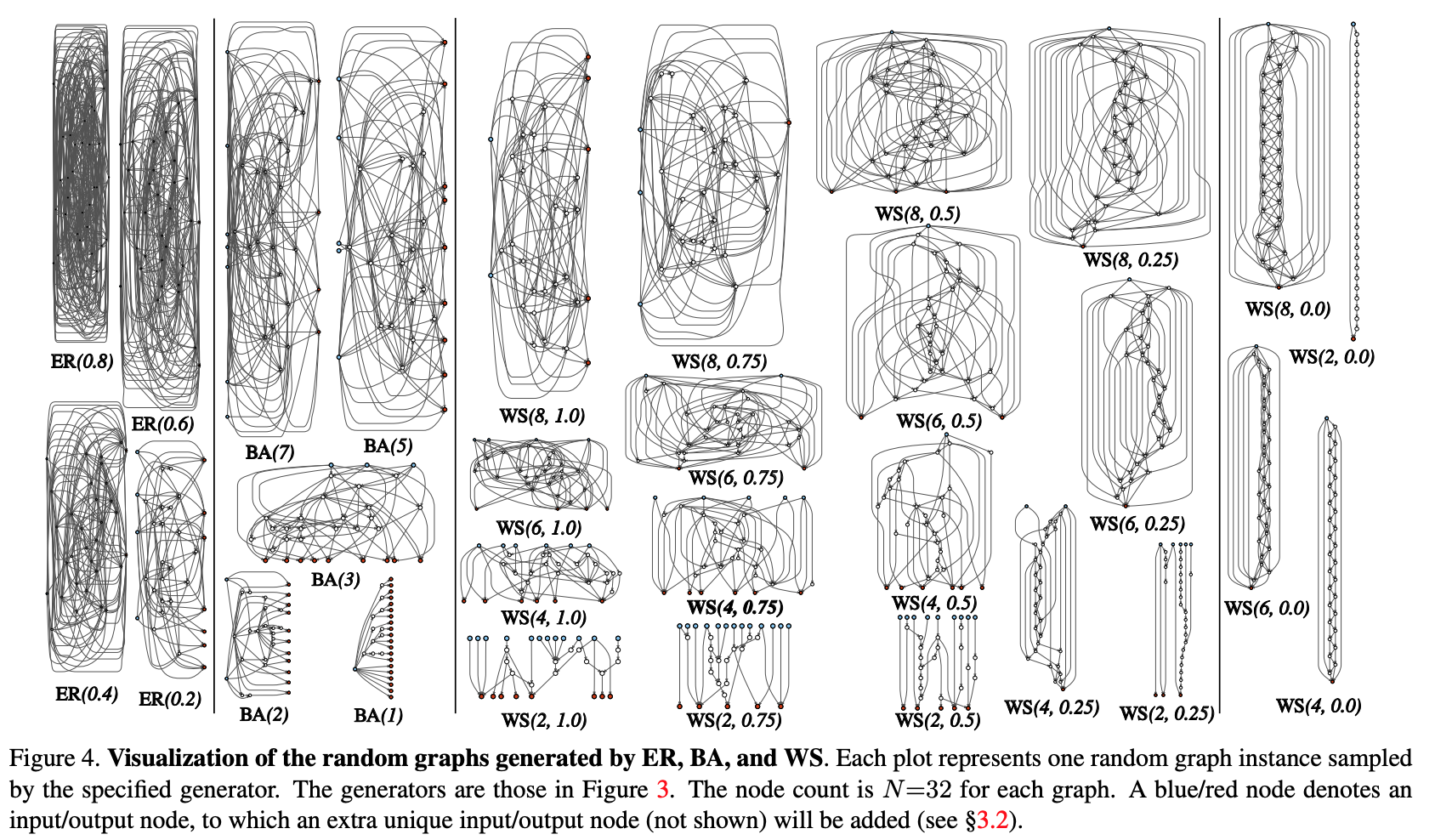
- يتم إنشاء الرسم البياني العشوائي من عائلة ذات معلمات. يتم استخدام الأساليب الكلاسيكية: Erdos-Renyi (ER) و Barabasi-Albert (BA) و Watts-Strogatz (WS).
- يتم تحويل الرسم البياني إلى شبكة عصبية:
- من المفترض أن تكون جميع حواف الرسم البياني عبارة عن حاملات موجّهة لتنسنات البيانات ؛
- بالنسبة لكل قمة من الرسم البياني ، يتم تحديد نوع العملية التي تقوم بها: (I) التجميع من خلال الجمع مع الأوزان المدربة ، (II) التحول - ReLU + convolution + BN ، (III) التوزيع - نقل الموتر على طول كل حافة الإخراج ؛
- وفقًا لنتائج الفقرة الفرعية السابقة ، يمكن أن يكون هناك العديد من رؤوس المدخلات والمخرجات ، لكنني أريد أن أحصل على نقطة دخول واحدة في الرسم البياني ونقطة إخراج واحدة. يتم إنشاء هذه العقد بشكل منفصل. يقوم المدخل ببساطة بنشر نسخة من الموتر على جميع رؤوس المدخلات من الرسم البياني ، والناتج واحد يأخذ في الاعتبار المتوسط غير المرجح لجميع رؤوس المخرجات ، ونتيجة للخطوتين 1 و 2 ، في الواقع ، لا يتم إنشاء شبكة كاملة ، ولكن واحدة فقط من الوحدات النمطية (مثل conv_1 ، ... الشائعة) الترميز التلافيفي). من أجل الحصول على الشبكة العصبية بالكامل:
- يتم إنشاء عدة وحدات ومتصلة في سلسلة. لتقليل عدد معلمات الشبكة ، يتم إجراء التحويلات في جميع رؤوس الإدخال للوحدات النمطية بخط 2x2. يزداد عدد القنوات التي تمر بمرحلة انتقالية إلى الوحدة التالية بمعدل مرتين. لإجراء تجارب على مهمة محددة:
- عند إخراج الشبكة ، يتم إضافة رئيس للتصنيف.
النتائج:
تم إجراء اختبار للأسلوب على مشكلة التصنيف على ImageNet. اتضح أن جودة الشبكة العصبية التي تم إنشاؤها تتوافق مع بنيات SotA ، حيث خسرت بعض الشيء إلى DeepBrain AmoebaNet من Google: (مع عدد مماثل من المعلمات).
فحصنا ما قد يحدث إذا أزلنا قمة / حافة عشوائية من الرسم البياني الناتج. قياس الجودة المتري اعتمادًا على العدد المجاور لحواف الإخراج / رؤوس المدخلات ، على التوالي. بشكل عام ، الجودة آخذة في الانخفاض ، ولكنها ليست حرجة.
فحص المؤلفون أيضًا ما إذا كان تعلم النقل يعمل مع هذه البنية. في مهمة الكشف عن COCO ، تم استبدال العمود الفقري Faster R-CNN مع FPN بشبكة تم إنشاؤها وتدريبها مسبقًا. أظهرت النتائج أن جودة النموذج ليست أسوأ من جودة ResNeXt-50 / -101. ولكن حتى حقيقة أن نقل التعلم يبدأ ، فهو أمر ممتع للغاية.
6. Photofeeler-D3: شبكة عصبية مع نمذجة الناخبين لتقييم الصور التي يرجع تاريخها
مؤلفو المقال: أغستيا كالرا وبن بيترسون (Photofeeler Inc. ، 2019)
→ المادة الأصلية
مؤلف المراجعة: Alex Chiron (في sliron shiron8bit)
يقترح المؤلفون Photofeeler-D3: بنية شبكة لتقييم الصور من مواقع المواعدة في 3 اتجاهات / سمات - كيف يبدو الشخص ذكيًا وجدير بالثقة وجذابًا (أهمل تأثير الهالة!). نشأت هذه المهمة بناءً على استطلاع أجرته الجارديان ، والذي ينص على أن 90٪ من الأشخاص يقررون في تاريخ مستقبلي فقط على أساس تقييم صور القمر الصناعي المحتمل
لذلك ، تتكون الشبكة من الكتل التالية:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
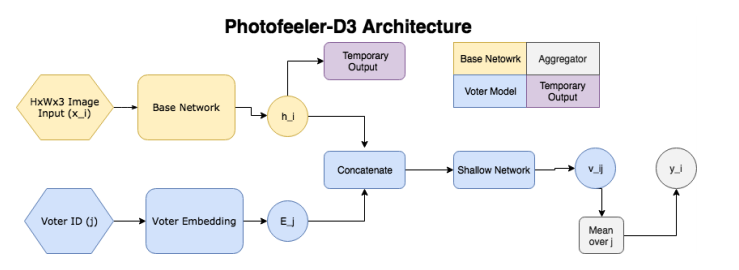
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
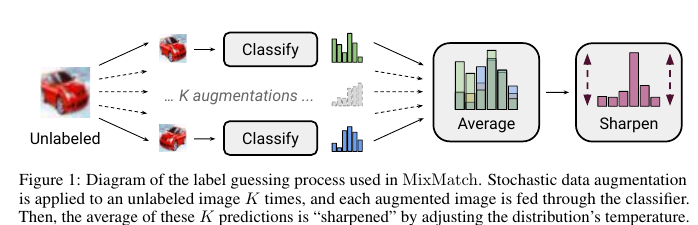
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
ج. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
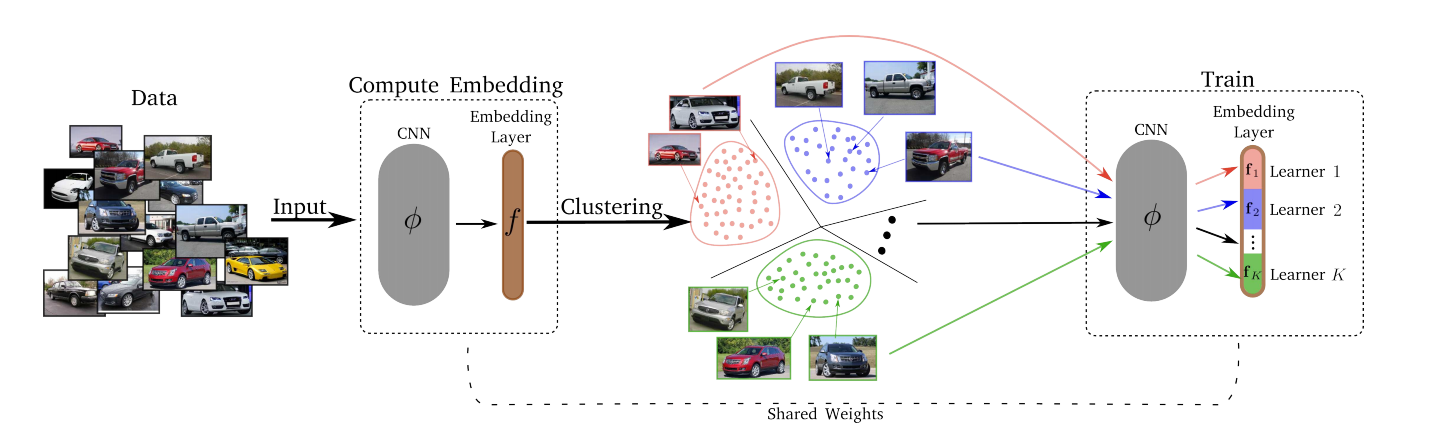
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - قهر.
بعد مرحلة Divide ، يتم تعيين كل مجموعة من مجموعات K إلى واحدة من K Lerners. يتدرب ليرنرز بدوره ، أي في كل لحظة معينة قمنا باختيار مجموعة يتم التدريب عليها ، يتم أخذ عينة صغيرة منها ، ويقلل ليرنر المقابل من خسارته عن طريق تحديث معالمه. يتم تحديث مساحة حفلات الزفاف مع مرور الوقت ، بحيث يتم كل عصر T ، التجميع (الفجوة) من جديد. - Merjim - نحن نسلسل كل ليرنرز (شرائح طبقة التضمين). ثم نقوم بتدريب طبقة التضمين على مجموعة البيانات بأكملها لتكوين صداقات مع Lerners.
النتائج التجريبية: فاز الجميع في عدة مجموعات بيانات.
يمكن أن تكون الخسارة أي شيء - خسارة ثلاثية أو خسارة هامش أو وكيل NCA ، إلخ.
تبين أن العدد الأمثل لـ K Lerners هو 8 (كان البعد الخاص بكامل مساحة التضمين 128) ، بحيث قام كل Lerner بحل مهمته الفرعية في مساحة 16-الأبعاد.
لم يؤثر التغيير في T من 1 إلى 10 بشكل كبير على أي شيء ، لذلك تم استخدام T = 2.