نقدم ورقة غش شاملة حيث نقول بكلمات بسيطة ما "يصنع" الذكاء الاصطناعي وكيف يعمل كل شيء.
ما الفرق بين الذكاء الاصطناعي والتعلم الآلي وعلوم البيانات؟
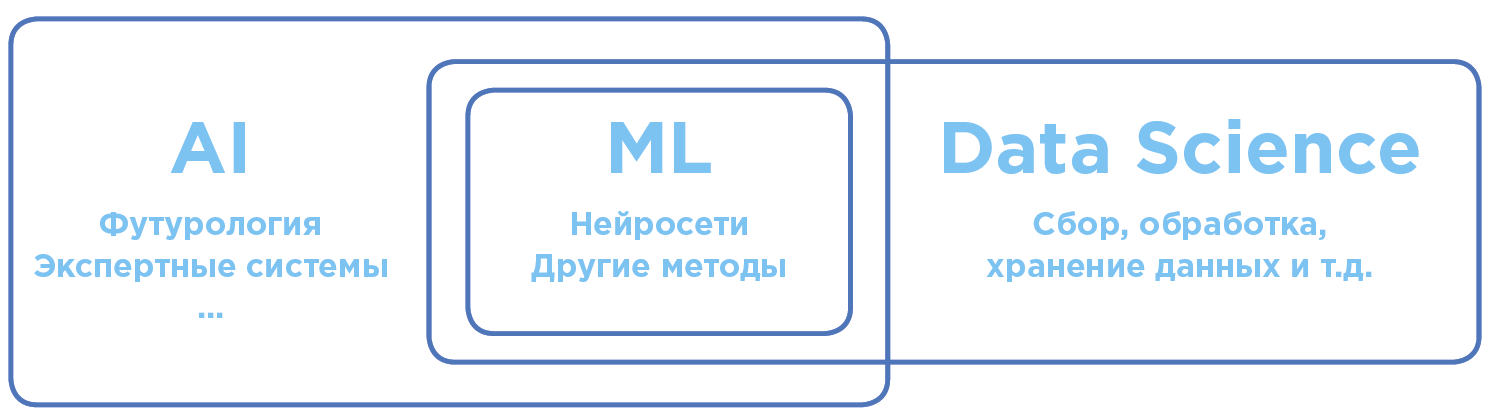 تمايز المفاهيم في مجال الذكاء الاصطناعي وتحليل البيانات.
تمايز المفاهيم في مجال الذكاء الاصطناعي وتحليل البيانات.الذكاء الاصطناعي - الذكاء الاصطناعي
بالمعنى العالمي الشامل ، الذكاء الاصطناعى هو مصطلح واسع بقدر الإمكان. ويشمل كلا من النظريات العلمية والممارسات التكنولوجية المحددة لإنشاء برامج قريبة من الذكاء البشري.
تعلم الآلة - ML (تعلم الآلة)
القسم AI ، يطبق بنشاط في الممارسة. اليوم ، عندما يتعلق الأمر باستخدام الذكاء الاصطناعي في العمل أو التصنيع ، فإننا نعني في الغالب بالتعلم الآلي.
تعمل خوارزميات ML ، كقاعدة عامة ، على مبدأ نموذج رياضي للتعلم يقوم بإجراء تحليل على أساس كمية كبيرة من البيانات ، في حين يتم استخلاص النتائج دون اتباع قواعد محددة بشكل صارم.
أكثر أنواع المهام شيوعًا في التعلم الآلي هي التعلم مع المعلم. لحل هذا النوع من المشكلات ، يتم استخدام التدريب على مجموعة من البيانات المعروفة للإجابة عليها مسبقًا (انظر أدناه).
علوم البيانات - DS (علوم البيانات)
علم وممارسة تحليل كميات كبيرة من البيانات باستخدام جميع أنواع الأساليب الرياضية ، بما في ذلك التعلم الآلي ، وكذلك حل المهام ذات الصلة المتعلقة بجمع صفيف البيانات وتخزينها ومعالجتها.
علماء البيانات هم خبراء البيانات ، على وجه الخصوص ، الذين يحللون باستخدام التعلم الآلي.

كيف يعمل التعلم الآلي؟
النظر في عمل ML على مثال مهمة التهديف المصرفي. البنك لديه بيانات عن العملاء الحاليين. إنه يعرف ما إذا كان شخص ما قد تأخر سداد القروض. تتمثل المهمة في تحديد ما إذا كان عميل محتمل جديد سيقوم بالدفع في الوقت المحدد. لكل عميل ، يمتلك البنك مجموعة من السمات / الخصائص المعينة: الجنس والعمر والدخل الشهري والمهنة ومكان الإقامة والتعليم ، وما إلى ذلك. من بين الخصائص ، قد تكون المعلمات ضعيفة التنظيم ، مثل البيانات من الشبكات الاجتماعية أو تاريخ الشراء. بالإضافة إلى ذلك ، يمكن إثراء البيانات بمعلومات من مصادر خارجية: أسعار الصرف ، وبيانات من مكاتب الائتمان ، إلخ.
يرى الجهاز أي عميل على أنه مزيج من الميزات:
. حيث على سبيل المثال
- العمر
- الدخل ، و
- عدد صور عمليات الشراء باهظة الثمن شهريًا (في الممارسة العملية ، كجزء من مهمة مماثلة ، يعمل Data Scientist مع أكثر من مائة ميزة). كل عميل لديه متغير واحد آخر -
مع اثنين من النتائج المحتملة: 1 (هناك مدفوعات متأخرة) أو 0 (لا توجد مدفوعات متأخرة).
مجمل البيانات
و
- هناك مجموعة البيانات. باستخدام هذه البيانات ، يقوم عالم البيانات بإنشاء نموذج
، واختيار وتعديل خوارزمية التعلم الآلي.
في هذه الحالة ، يبدو نموذج التحليل كما يلي:
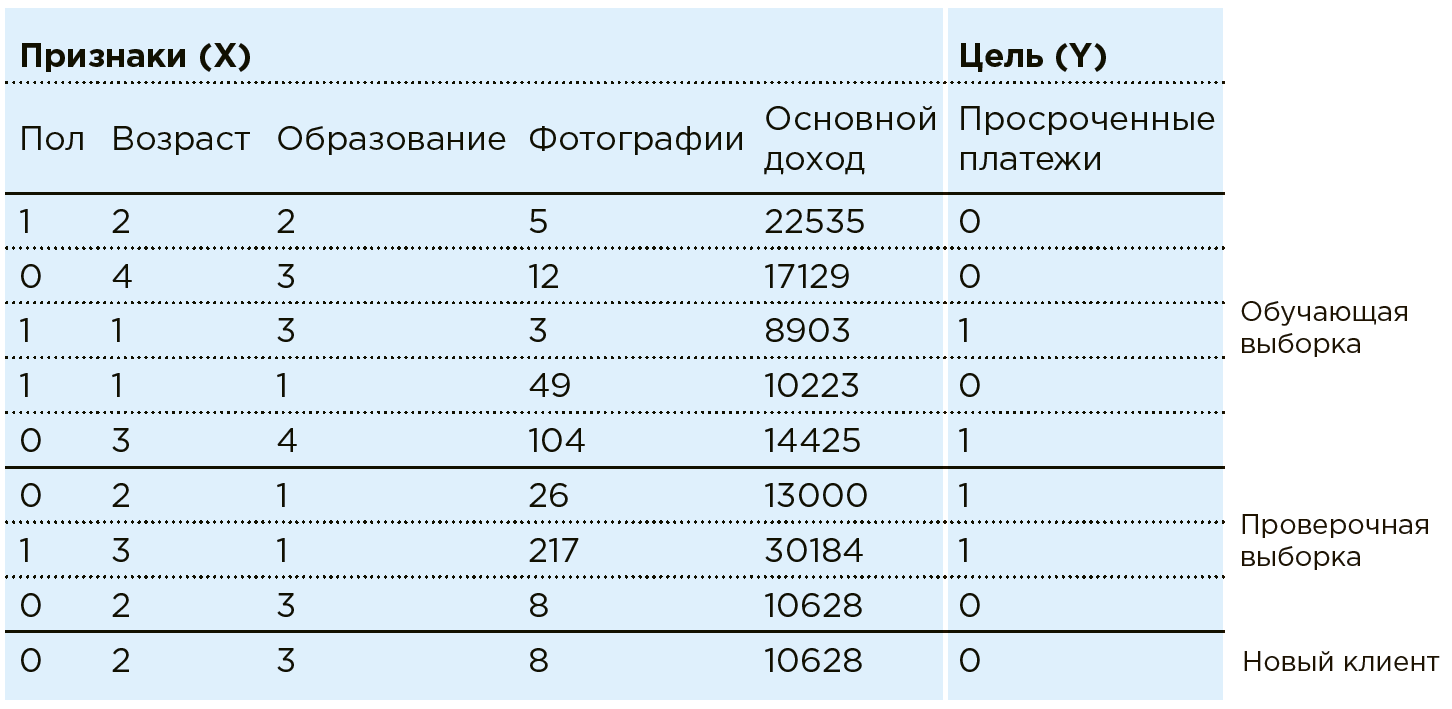
تتضمن خوارزميات التعلم الآلي تقريبًا تدريجيًا لاستجابات النموذج
للإجابات الحقيقية (المعروفة مسبقًا في مجموعة بيانات التدريب). هذا هو التدريب مع المعلم في عينة معينة.
في الممارسة العملية ، يتعلم الجهاز في معظم الأحيان فقط على جزء من المصفوفة (80٪) ، باستخدام الباقي (20٪) للتحقق من صحة الخوارزمية المحددة. على سبيل المثال ، يمكن تدريب النظام على صفيف يتم منه استبعاد بيانات زوج من المناطق ، والتي يتم التحقق من دقة النموذج بعدها.
الآن ، عندما يأتي عميل جديد إلى البنك ، وفقًا لذلك
البنك لم يعرف بعد ، وسيقوم النظام بتحديد موثوقية الدافع بناءً على البيانات المعروفة عنه
.
ومع ذلك ، فإن التدريس مع المعلم ليس الفئة الوحيدة من المشكلات التي يمكن أن يحلها ML.
هناك مجموعة أخرى من المهام هي التجميع ، والذي يكون قادرًا على فصل الكائنات وفقًا لسماتها ، على سبيل المثال ، لتحديد فئات العملاء المختلفة لهم لتقديم عروض فردية.
أيضًا ، بمساعدة خوارزميات ML ، يتم حل مهام مثل نمذجة اتصالات أخصائي الدعم أو إنشاء أعمال فنية لا يمكن تمييزها عن إبداعات بشرية (على سبيل المثال ، صور شبكات الشبكات العصبية)
فئة جديدة وشعبية من المهام هي التدريب على التعزيز ، والذي يتم في بيئة محدودة تقوم بتقييم تصرفات الوكلاء (على سبيل المثال ، باستخدام هذه الخوارزمية ، تم إنشاء AlphaGo وهزم الشخص في Go).

الشبكة العصبية
واحدة من طرق التعلم الآلي. خوارزمية مستوحاة من بنية الدماغ البشري ، والتي تقوم على الخلايا العصبية والروابط بينهما. في عملية التعلم ، يتم ضبط الاتصالات بين الخلايا العصبية بطريقة تقلل من أخطاء الشبكة بالكامل.
من سمات الشبكات العصبية وجود بنيات مناسبة لأي تنسيق بيانات تقريبًا: الشبكات العصبية التلافيفية لتحليل الصور ، والشبكات العصبية المتكررة لتحليل النصوص والتسلسلات ، والتشفير التلقائي لضغط البيانات ، والشبكات العصبية التوليدية لإنشاء كائنات جديدة ، إلخ.
في الوقت نفسه ، فإن جميع الشبكات العصبية تقريبًا لها قيود كبيرة - لتدريبها ، هناك حاجة إلى كمية كبيرة من البيانات (أوامر بحجم أكبر من عدد الاتصالات بين الخلايا العصبية في هذه الشبكة). نظرًا لحقيقة أن حجم البيانات الجاهزة للتحليل قد نما مؤخرًا بشكل ملحوظ ، فإن النطاق يتزايد أيضًا. بمساعدة الشبكات العصبية اليوم ، على سبيل المثال ، يتم حل مهام التعرف على الصور ، مثل تحديد عمر وجنس شخص ما من مقطع فيديو ، أو الحصول على خوذة على العامل.
تفسير النتيجة
قسم علم البيانات ، والذي يسمح لفهم أسباب اختيار حل واحد أو آخر بواسطة نموذج ML
هناك مجالان رئيسيان للبحث:
- دراسة النموذج كمربع أسود. عند تحليل الأمثلة التي تم تحميلها فيه ، تقارن الخوارزمية ميزات هذه الأمثلة واستنتاجات الخوارزمية ، مما يجعل الاستنتاجات حول أولوية أي منها. في حالة الشبكات العصبية ، عادة ما يستخدم الصندوق الأسود.
- دراسة خصائص النموذج نفسه. دراسة الخصائص التي يستخدمها النموذج لتحديد درجة أهميتها. يتم تطبيقها في الغالب على الخوارزميات استنادًا إلى طريقة شجرة القرار.
على سبيل المثال ، عند التنبؤ بعيوب في الإنتاج ، علامات الكائنات
- هذه هي بيانات إعدادات الآلات والتركيب الكيميائي للمواد الخام ومؤشرات أجهزة الاستشعار والفيديو من الناقل وما إلى ذلك.
- هذه هي الإجابات على السؤال عما إذا كان سيكون هناك زواج أم لا.
بطبيعة الحال ، لا يهتم الإنتاج بتنبؤ الزواج نفسه فحسب ، بل يهتم أيضًا بتفسير النتيجة ، أي أسباب الزواج لإلغائها لاحقًا. قد يكون هذا غيابًا طويلًا لصيانة الماكينة ، أو جودة المواد الخام ، أو مجرد قراءات غير طبيعية لبعض أجهزة الاستشعار التي ينبغي على الفني الاهتمام بها.
لذلك ، في إطار المشروع للتنبؤ بالزواج في الإنتاج ، لا ينبغي إنشاء نموذج ML ، ولكن يجب أيضًا القيام بعمل لتفسيره ، أي تحديد العوامل التي تؤثر على الزواج.

متى يكون التعلم الآلي فعالاً؟
عندما يكون هناك مجموعة كبيرة من البيانات الإحصائية ، ولكن من المستحيل أو الشاق للغاية العثور على التبعيات باستخدام الأساليب الرياضية الخبيرة أو الكلاسيكية. لذلك ، إذا كان هناك أكثر من ألف معلمة عند الإدخال (من بينها كل من الأرقام والنصوص ، بالإضافة إلى الفيديو والصوت والصور) ، فمن المستحيل العثور على اعتماد النتيجة عليها بدون آلة.
على سبيل المثال ، بالإضافة إلى المواد نفسها التي تدخل في التفاعل ، يتأثر التفاعل الكيميائي بالعديد من البارامترات: درجة الحرارة والرطوبة ومواد الحاوية التي تحدث فيها ، إلخ. من الصعب على الكيميائي أن يأخذ في الاعتبار كل هذه العلامات من أجل حساب زمن التفاعل بدقة. على الأرجح ، سوف يأخذ في الاعتبار العديد من المعايير الرئيسية وسيستند إلى خبرته. في الوقت نفسه ، استنادًا إلى بيانات ردود الفعل السابقة ، سيكون التعلم الآلي قادرًا على مراعاة جميع العلامات وإعطاء تنبؤات أكثر دقة.
كيف ترتبط البيانات الضخمة والتعلم الآلي؟
من أجل بناء نماذج تعلم الآلة ، في حالات مختلفة ، هناك حاجة إلى البيانات العددية والنصية والصور والفيديو والصوت وغيرها من البيانات. من أجل تخزين وتحليل هذه المعلومات ، هناك مجال كامل من التكنولوجيا - البيانات الكبيرة. من أجل تخزين البيانات وتحليلها على النحو الأمثل ، يقومون بإنشاء "Data Lake" - تخزين خاص موزع لكميات كبيرة من المعلومات ذات البنية السيئة استنادًا إلى تقنيات البيانات الكبيرة.
رقمي مزدوج كجواز سفر إلكتروني
المضاعفة الرقمية هي نسخة افتراضية لكائن أو عملية أو مؤسسة مادية حقيقية ، والتي تتيح لك محاكاة سلوك الكائن / العملية المدروسة. على سبيل المثال ، يمكنك أن ترى نتائج التغييرات في التركيب الكيميائي في المصنع بشكل مبدئي بعد التغييرات في إعدادات خطوط الإنتاج ، والتغيرات في المبيعات بعد حملة إعلانية ذات خصائص معينة ، وما إلى ذلك. في هذه الحالة ، يتم وضع التوقعات من خلال مضاعفة رقمية استنادًا إلى البيانات المتراكمة ، ويتم تصميم السيناريوهات والمواقف المستقبلية بما في ذلك أساليب التعلم الآلي.
ما هو مطلوب لتعلم آلة الجودة؟
بيانات العالم! هم الذين ينشئون خوارزمية التنبؤ: فهم يدرسون البيانات المتاحة ويطرحون الفرضيات ويصنعون النماذج بناءً على مجموعة البيانات. يجب أن يكون لديهم ثلاث مجموعات رئيسية من المهارات: معرفة القراءة والكتابة وتكنولوجيا المعلومات ، والمعرفة الرياضية والإحصائية ، والخبرة الفنية في مجال معين.
التعلم الآلي يقف على ثلاثة أعمدة
استرجاع البياناتيمكن استخدام البيانات من الأنظمة ذات الصلة: جدول العمل ، خطة المبيعات. يمكن أيضًا إثراء البيانات من خلال مصادر خارجية: أسعار الصرف ، والطقس ، وتقويم العطلات ، وما إلى ذلك. من الضروري تطوير منهجية للعمل مع كل نوع من أنواع البيانات والتفكير من خلال خط أنابيب لتحويله إلى تنسيق نموذج التعلم الآلي (مجموعة من الأرقام).
بناء علاماتيتم تنفيذها مع خبراء من المجال المطلوب. يساعد هذا في حساب البيانات المناسبة جيدًا لأغراض التنبؤ: الإحصاءات والتغييرات في عدد المبيعات خلال الشهر الماضي للتنبؤ بالسوق.
نموذج التعلم الآلييتم اختيار طريقة حل هذه المشكلة التجارية من قبل عالم البيانات بشكل مستقل على أساس خبرته وقدرات النماذج المختلفة. لكل مهمة محددة ، تحتاج إلى اختيار خوارزمية منفصلة. تعتمد سرعة ودقة نتيجة معالجة البيانات المصدر بشكل مباشر على الطريقة المحددة.
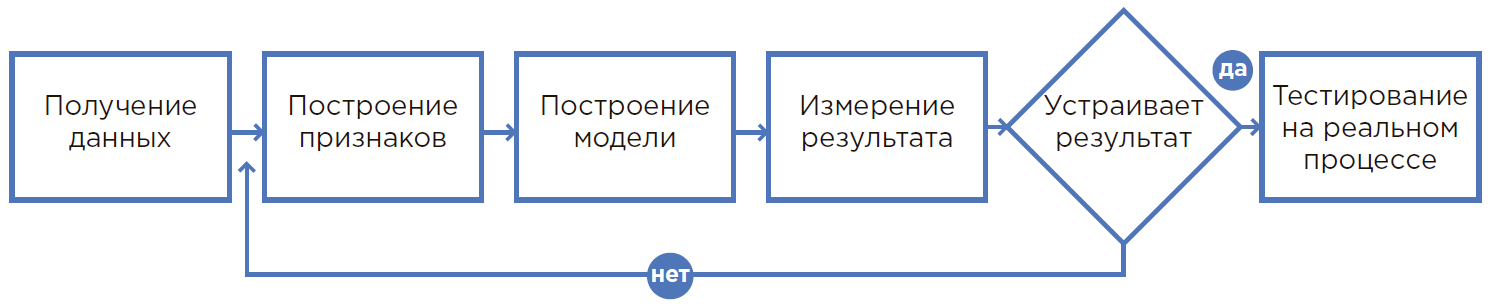 عملية إنشاء نموذج ML.
عملية إنشاء نموذج ML.من الفرضية إلى النتيجة
1. كل شيء يبدأ بفرضية
يتم فرض فرضية عند تحليل عملية المشكلة أو تجربة الموظفين أو مع نظرة جديدة على الإنتاج. عادةً ما تؤثر الفرضية على عملية يكون فيها الشخص غير قادر جسديًا على مراعاة العديد من العوامل ويستخدم التقريب أو الافتراضات أو ببساطة يفعل كما فعل دائمًا.
في هذه العملية ، يتيح لك استخدام التعلم الآلي استخدام مزيد من المعلومات بشكل ملحوظ عند اتخاذ القرارات ، وبالتالي ، فمن الممكن تحقيق نتائج أفضل بكثير. بالإضافة إلى ذلك ، فإن أتمتة العمليات باستخدام ML والحد من الاعتماد على شخص معين يقلل إلى حد كبير من عامل الإنسان (المرض ، تركيز منخفض ، وما إلى ذلك).
2. تقييم الفرضية
بناءً على الفرضية المصممة ، يتم اختيار البيانات اللازمة لتطوير نموذج التعلم الآلي. يتم إجراء بحث عن البيانات ذات الصلة وتحديد مدى ملاءمتها لتضمين النموذج في العمليات الحالية وتحديد من سيكون مستخدموه وبسبب تحقيق التأثير. إذا لزم الأمر ، يتم إجراء أية تغييرات تنظيمية وأي تغييرات أخرى.
3. حساب التأثير الاقتصادي والعائد على الاستثمار (ROI)
يتم إجراء تقييم للأثر الاقتصادي للحل الذي تم تنفيذه من قبل المتخصصين بالتعاون مع الإدارات ذات الصلة: الكفاءة ، والتمويل ، وما إلى ذلك. في هذه المرحلة ، تحتاج إلى فهم ما هو بالضبط المقياس (عدد العملاء الذين تم تحديدهم بشكل صحيح / الزيادة في إنتاج / توفير المواد الاستهلاكية ، وما إلى ذلك) و التعبير بوضوح عن الهدف المقاس.
4. الصياغة الرياضية للمشكلة
بعد فهم نتيجة العمل ، من الضروري تحويلها إلى المستوى الرياضي - لتحديد مقاييس القياس والقيود التي لا يمكن انتهاكها. مراحل البيانات البيانات
يقوم العالم بالتزامن مع عميل تجاري.
5. جمع البيانات وتحليلها
من الضروري جمع البيانات في مكان واحد ، وتحليلها ، والنظر في الإحصاءات المختلفة ، وفهم بنية هذه البيانات وعلاقاتها الخفية لتشكيل علامات.
6. إنشاء نموذج أولي
إنه في الواقع اختبار للفرضية. هذه فرصة لإنشاء نموذج على البيانات الحالية والتحقق في البداية من نتائج عملها. عادة ، يتم إنشاء نموذج أولي على البيانات الموجودة دون تطوير التكامل والعمل مع دفق في الوقت الحقيقي.
النماذج الأولية هي طريقة سريعة وغير مكلفة للتحقق من حل المشكلة. هذا مفيد للغاية عندما يكون من المستحيل أن نفهم مقدمًا ما إذا كان من الممكن تحقيق التأثير الاقتصادي المنشود. بالإضافة إلى ذلك ، تتيح لك عملية إنشاء نموذج أولي تقييم نطاق وتفاصيل المشروع بشكل أفضل لتنفيذ الحل ، وإعداد تبرير اقتصادي لمثل هذا التنفيذ.
DevOps و DataOps
أثناء التشغيل ، قد يظهر نوع جديد من البيانات (على سبيل المثال ، سيظهر مستشعر آخر على الجهاز أو سيظهر نوع جديد من البضائع في المستودع) ثم يحتاج النموذج إلى تدريب. DevOps و DataOps هي منهجيات تساعد في إعداد التعاون والعمليات الشاملة بين فرق علوم البيانات ، ومهندسي إعداد البيانات ، وخدمات تطوير تكنولوجيا المعلومات وتشغيلها ، وتساعد في جعل هذه الإضافات جزءًا من العملية الحالية بسرعة ، دون أخطاء ودون حل في كل مرة فريدة من نوعها مشاكل.
7. خلق حل
في تلك اللحظة ، عندما تُظهر نتائج عمل النموذج الأولي تحقيقًا واثقًا للمؤشرات ، يتم إنشاء حل كامل يكون فيه نموذج التعلم الآلي مجرد مكون من العمليات المدروسة. بعد ذلك ، تكامل وتركيب المعدات اللازمة وتدريب الموظفين وتغيير عمليات صنع القرار ، إلخ.
8. التجريبية والصناعية العملية
أثناء التشغيل التجريبي ، يعمل النظام في وضع المشورة ، بينما لا يزال المتخصص يكرر الإجراءات المعتادة ، في كل مرة يقدم ملاحظات حول التحسينات اللازمة للنظام ويزيد من دقة التنبؤات.
الجزء الأخير هو التشغيل الصناعي ، عندما تتحول العمليات المنشأة إلى الصيانة الأوتوماتيكية بالكامل.
يمكنك تنزيل ورقة الغش من
الرابط .
غدًا في منتدى أنظمة الذكاء الاصطناعي
RAIF 2019 من الساعة 9:30 إلى الساعة 10:45 ، ستكون هناك حلقة نقاش: "الذكاء الاصطناعي للأشخاص:
نفهمهم بكلمات بسيطة".
في هذا القسم ، في تنسيق النقاش ، سوف يشرح المتحدثون التقنيات المعقدة بكلمات بسيطة عن أمثلة الحياة. وناقش أيضًا المواضيع التالية:
- ما الفرق بين الذكاء الاصطناعي والتعلم الآلي وعلوم البيانات؟
- كيف يعمل التعلم الآلي؟
- كيف تعمل الشبكات العصبية؟
- ما هو مطلوب لتعلم آلة الجودة؟
- ما هو العلامات ، وسم البيانات؟
- ما هو المضاعفة الرقمية وكيفية التعامل مع النسخ الافتراضية للكائنات المادية الحقيقية؟
- ما هو جوهر الفرضية؟ كيف نحصل من الطريقة التي تم تعيينها إلى تقييم وتفسير النتيجة؟
حضر المناقشة:
نيكولاي مارين ، مدير التكنولوجيا في شركة آي بي إم في روسيا ورابطة الدول المستقلة
أليكسي ناتكين ، مؤسس ، Open Data Science x Data Souls
أليكسي Hakhunov ، CTO ، Dbrain
يفغيني كولسنيكوف ، مدير مركز التعلم الآلي ، جت انفورمز
بافيل دورونين ، الرئيس التنفيذي لمنظمة العفو الدولية اليوم
ستكون المناقشة متاحة على
قناة Jet Infosystems على YouTube في أواخر أكتوبر.