
يعد التسامح مع الخطأ والتوافر الكبير من الموضوعات الكبيرة ، لذا سيكرس RabbitMQ و Kafka مقالات منفصلة. هذه المقالة تدور حول RabbitMQ ، والمقال التالي يدور حول Kafka ، مقارنة بـ RabbitMQ. المقال طويل ، لذا اجعل نفسك مريحًا.
النظر في استراتيجيات التسامح مع الخطأ ، والاتساق ، وتوافر عالية (HA) ، وكذلك المفاضلات التي يتعين على كل استراتيجية لجعل. يمكن تشغيل RabbitMQ على مجموعة من العقد - ثم يتم تصنيفها كنظام موزع. عندما يتعلق الأمر بالأنظمة الموزعة ، فإننا نتحدث غالبًا عن الاتساق وإمكانية الوصول.
تصف هذه المفاهيم كيف يتصرف النظام في حالة حدوث فشل. فشل في اتصال الشبكة أو فشل الخادم أو فشل القرص الثابت أو عدم توفر الخادم المؤقت بسبب تجميع البيانات المهملة أو فقد الحزمة أو تباطؤ اتصال الشبكة. كل هذا يمكن أن يؤدي إلى فقدان البيانات أو تعارضات. اتضح أنه يكاد يكون من المستحيل رفع نظام متسق تمامًا (بدون فقدان البيانات ، دون تباينات في البيانات) ، ويمكن الوصول إليه (سيقبل عمليات القراءة والكتابة) لجميع أنواع الفشل.
سنرى أن الاتساق وإمكانية الوصول في نهايات مختلفة من الطيف ، وستحتاج إلى اختيار الطريقة الأمثل. والخبر السار هو أنه مع RabbitMQ مثل هذا الخيار ممكن. لديك نوع من ضغط "الطالب الذي يذاكر كثيرا" لتحويل التوازن نحو مزيد من التماسك أو إمكانية الوصول أكبر.
سنولي اهتمامًا خاصًا للتكوينات التي تؤدي إلى فقد البيانات بسبب السجلات المؤكدة. هناك سلسلة من المسؤولية بين الناشرين والوسطاء والمستهلكين. بعد إرسال الرسالة إلى الوسيط ، من وظيفته ألا تفقد الرسالة. عندما يؤكد الوسيط للناشر استلام الرسالة ، لا نتوقع فقدها. لكننا سنرى أن هذا يمكن أن يحدث بالفعل اعتمادًا على تهيئة الوسيط والناشر.
بدائل استقرار عقدة واحدة
قوائم الانتظار الدائمة / التوجيه
هناك نوعان من قوائم الانتظار في RabbitMQ: دائم / غير دائم. يتم تخزين جميع قوائم الانتظار في قاعدة بيانات Mnesia. يتم إعادة تعريف قوائم الانتظار الدائمة عند بدء تشغيل العقدة وبالتالي تنجو من إعادة التشغيل أو تعطل النظام أو تعطل الخادم (طالما يتم حفظ البيانات). هذا يعني أنه بينما تعلن عن التوجيه (التبادل) وقائمة الانتظار المرنة ، ستعود البنية الأساسية للصفوف / التوجيه عبر الإنترنت.
يتم حذف قوائم الانتظار المتغيرة والتوجيه عند إعادة تشغيل المضيف.
الرسائل المستمرة
لمجرد أن قائمة الانتظار طويلة لا تعني أن جميع رسائلها ستستمر في إعادة تشغيل العقدة. سيتم استعادة الرسائل التي حددها الناشر على أنها ثابتة فقط. تخلق الرسائل المستمرة عبئًا إضافيًا على الوسيط ، ولكن إذا كانت خسارة الرسائل غير مقبولة ، فلا توجد طريقة أخرى.
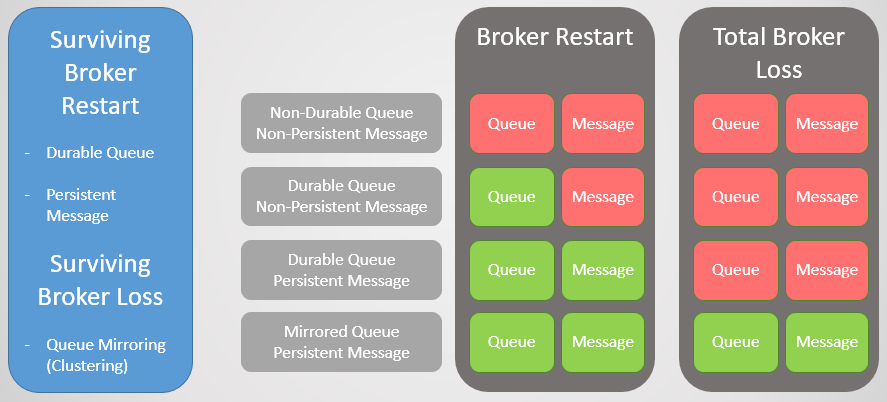 التين. 1. مصفوفة الاستقرار
التين. 1. مصفوفة الاستقرارقائمة انتظار النسخ المتطابق
للبقاء على قيد الحياة من فقدان وسيط ، نحن بحاجة إلى التكرار. يمكننا دمج العديد من عقد RabbitMQ في نظام مجموعة ، ثم إضافة تكرار إضافي عن طريق نسخ قوائم الانتظار بين عدة عقد. وبالتالي ، إذا سقطت عقدة واحدة ، فإننا لا نفقد البيانات ونظل متاحين.
قائمة انتظار النسخ المتطابق:
- قائمة انتظار رئيسية واحدة (رئيسية) ، والتي تتلقى جميع أوامر الكتابة والقراءة
- واحد أو أكثر من المرايا التي تتلقى جميع الرسائل والبيانات الوصفية من قائمة الانتظار الرئيسية. هذه المرايا غير موجودة للتحجيم ، ولكن فقط للتكرار.
 التين. 2. عكس قائمة الانتظار
التين. 2. عكس قائمة الانتظاريتم تعيين النسخ المتطابق بواسطة السياسة المناسبة. في ذلك ، يمكنك اختيار معدل النسخ المتماثل وحتى العقد التي يجب وضع قائمة الانتظار. الأمثلة على ذلك:
ha-mode: all
ha-mode: exactly, ha-params: 2 (واحد رئيسي ومرآة واحدة)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
تأكيد للناشر
لتحقيق تسجيل متسلسل ، يجب تأكيد Publisher تأكيد. بدونها ، هناك فرصة لفقدان الرسائل. يتم إرسال تأكيد للناشر بعد كتابة الرسالة إلى القرص. RabbitMQ يكتب رسائل إلى القرص ليس عند الاستلام ، ولكن على أساس دوري ، في منطقة عدة مئات من ميلي ثانية. عند نسخ قائمة الانتظار ، يتم إرسال التأكيد فقط بعد أن تكون جميع النسخ المتطابقة أيضًا قد كتبت نسختها من الرسالة إلى القرص. هذا يعني أن استخدام الإقرارات يضيف إلى التأخير ، ولكن إذا كان أمان البيانات مهمًا ، فسيكون ذلك ضروريًا.
قائمة انتظار تجاوز الفشل
عندما يغلق الوسيط أو يتعطل ، فإن جميع قوائم الانتظار الرئيسية (الماجستير) على هذه العقدة تقع معها. تقوم الكتلة بعد ذلك بتحديد أقدم نسخة متطابقة لكل سيد وترويجها كسيد جديد.
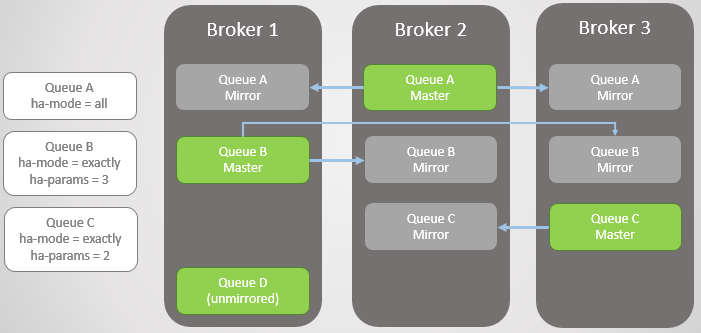 التين. 3. عدة طوابير معكوسة وسياساتها
التين. 3. عدة طوابير معكوسة وسياساتهاوسيط 3 قطرات. لاحظ أنه يتم ترقية نسخة متطابقة Queue C على Broker 2 إلى رئيسي. لاحظ أيضًا أنه تم إنشاء نسخة متطابقة جديدة لقائمة الانتظار C على الوسيط 1. يحاول RabbitMQ دائمًا الحفاظ على معدل النسخ المتماثل المحدد في سياساتك.
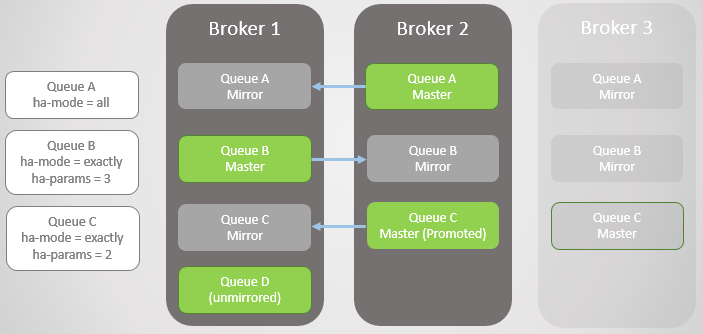 التين. 4. الوسيط 3 يسقط ، مما تسبب في فشل قائمة الانتظار C
التين. 4. الوسيط 3 يسقط ، مما تسبب في فشل قائمة الانتظار Cالوسيط التالي 1 يسقط! لدينا وسيط واحد فقط اليسار. ترتفع مرآة قائمة الانتظار B للسيد.
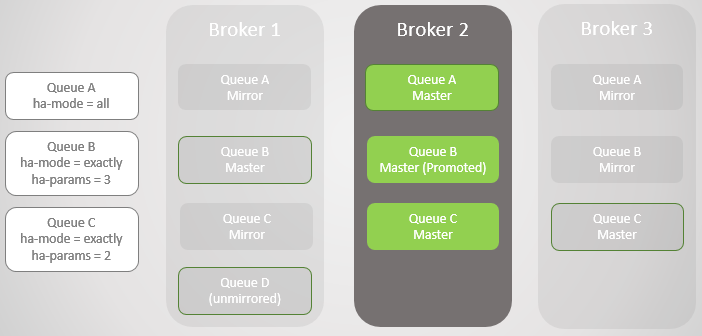 التين. 5
التين. 5لقد عدنا Broker 1. بغض النظر عن مدى نجاح البيانات في التغلب على خسارة واسترداد الوسيط ، يتم تجاهل جميع رسائل قائمة الانتظار المتطابقة عند إعادة التشغيل. من المهم ملاحظة ذلك ، حيث ستكون هناك عواقب. سننظر قريباً في هذه العواقب. وبالتالي ، أصبح Broker 1 الآن مرة أخرى عضوًا في المجموعة ، وتحاول المجموعة الامتثال للسياسات وبالتالي تنشئ مرايا على Broker 1.
في هذه الحالة ، كان فقدان الوسيط 1 كاملاً ، وكذلك البيانات ، وبالتالي فقد قائمة الانتظار غير المتطابقة بالكامل.
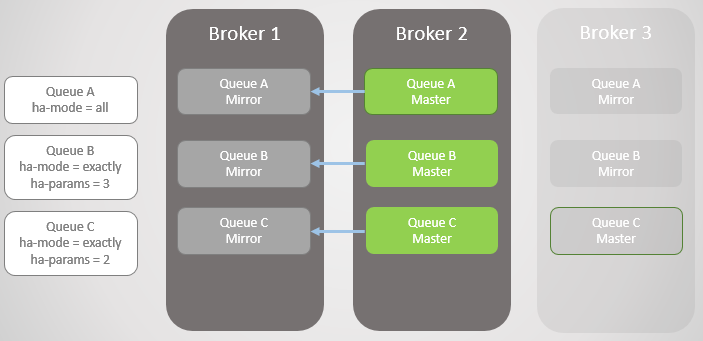 التين. 6. عاد الوسيط 1 إلى الخدمة
التين. 6. عاد الوسيط 1 إلى الخدمةعاد السمسار 3 عبر الإنترنت ، لذا تم إنشاء خطوط A و B على المرايا لتناسب سياسات HA الخاصة بهم. ولكن الآن كل الخطوط الرئيسية موجودة على عقدة واحدة! هذه ليست مثالية ؛ التوزيع الموحد بين العقد هو أفضل. لسوء الحظ ، لا توجد خيارات خاصة لإعادة التوازن للسادة. سنعود إلى هذه المشكلة لاحقًا ، حيث نحتاج إلى التفكير في مزامنة قائمة الانتظار أولاً.
 التين. 7. عاد الوسيط 3 إلى الخدمة. جميع قوائم الانتظار الرئيسية على عقدة واحدة!
التين. 7. عاد الوسيط 3 إلى الخدمة. جميع قوائم الانتظار الرئيسية على عقدة واحدة!وبالتالي ، يجب أن يكون لديك الآن فكرة عن كيفية توفير المرايا للتكرار والتسامح مع الخطأ. هذا يضمن توافر في حالة فشل عقدة واحدة ويحمي من فقدان البيانات. لكننا لم ننته بعد ، لأنه في الواقع كل شيء أكثر تعقيدًا.
تزامن
عند إنشاء نسخة متطابقة جديدة ، سيتم دائمًا نسخ جميع الرسائل الجديدة إلى هذه المرآة وأي رسائل أخرى. بالنسبة للبيانات الموجودة في قائمة الانتظار الرئيسية ، يمكننا نسخها في نسخة متطابقة جديدة ، والتي تصبح نسخة كاملة من النسخة الرئيسية. لا يمكننا أيضًا تكرار الرسائل الحالية والسماح لقائمة الانتظار الرئيسية والمرآة الجديدة بالالتقاء في الوقت المناسب عندما تصل الرسائل الجديدة إلى الذيل وتترك الرسائل الحالية رأس قائمة الانتظار الرئيسية.
تتم هذه المزامنة تلقائيًا أو يدويًا ويتم التحكم فيها باستخدام سياسة قائمة الانتظار. النظر في مثال.
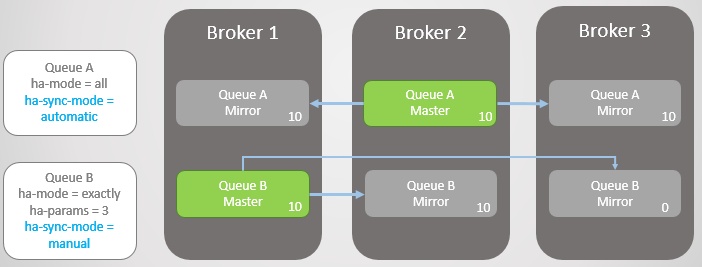
لدينا اثنين من خطوط معكوسة. قائمة الانتظار A تتم مزامنتها تلقائيًا ، و Queue B يدويًا. يحتوي كلا الخطين على عشر رسائل لكل منهما.
 التين. 8. اثنين من قوائم الانتظار مع أوضاع التزامن المختلفة
التين. 8. اثنين من قوائم الانتظار مع أوضاع التزامن المختلفةالآن نحن نفقد الوسيط 3.
 التين. 9. انخفض السمسار 3
التين. 9. انخفض السمسار 3عاد السمسار 3 إلى الخدمة. تقوم الكتلة بإنشاء نسخة متطابقة لكل قائمة انتظار على العقدة الجديدة ومزامنة قائمة الانتظار الجديدة تلقائيًا مع الرئيسي. ومع ذلك ، فإن مرآة Turn B الجديدة تظل فارغة. وبالتالي ، لدينا تكرار كامل لقائمة الانتظار A ومرآة واحدة فقط للرسائل الموجودة في قائمة الانتظار B.
 التين. 10. النسخة المتطابقة الجديدة من قائمة الانتظار A تتلقى جميع الرسائل الموجودة ، لكن النسخة المتطابقة الجديدة من قائمة الانتظار B لا تستقبلها
التين. 10. النسخة المتطابقة الجديدة من قائمة الانتظار A تتلقى جميع الرسائل الموجودة ، لكن النسخة المتطابقة الجديدة من قائمة الانتظار B لا تستقبلهاكلا الخطين يتلقى عشرة رسائل أخرى. ثم يقع Broker 2 ، وتعود قائمة الانتظار A إلى أقدم نسخة متطابقة ، والتي تقع على Broker 1. في حالة حدوث عطل ، لا يوجد فقدان للبيانات. توجد 20 رسالة في قائمة الانتظار B في المعالج وعشرة رسائل فقط في النسخة المتطابقة ، لأن قائمة الانتظار هذه لم تنسخ الرسائل العشرة الأصلية أبدًا.
 التين. 11. يتم إرجاع الخط A إلى الوسيط 1 دون فقد الرسائل
التين. 11. يتم إرجاع الخط A إلى الوسيط 1 دون فقد الرسائلكلا الخطين يتلقى عشرة رسائل أخرى. تعطل الوسيط 1. الآن تنتقل قائمة الانتظار A إلى النسخة المتطابقة دون أي مشاكل دون فقد الرسائل. ومع ذلك ، قائمة الانتظار B لديه مشاكل. في هذه المرحلة ، يمكننا تحسين إمكانية الوصول أو التناسق.
إذا كنا نرغب في تحسين إمكانية الوصول ، فيجب أن تكون سياسة
ha-promotion-on-الفشل معدة
دائمًا . هذه هي القيمة الافتراضية ، لذلك يمكنك ببساطة حذف السياسة على الإطلاق. في هذه الحالة ، في الواقع ، نحن نسمح بالفشل في النسخ المتطابقة غير المتزامنة. سيؤدي ذلك إلى فقد الرسالة ، لكن قائمة الانتظار تظل قابلة للقراءة والكتابة.
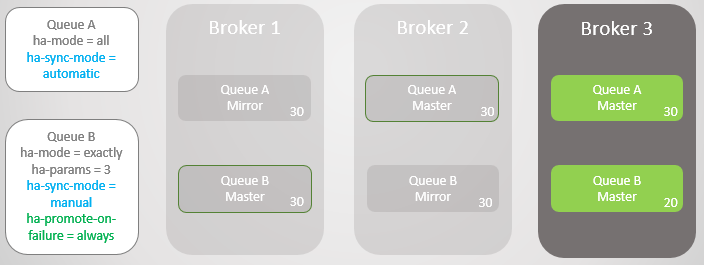 التين. 12. يتم إرجاع الخط A إلى الوسيط 3 دون فقد الرسائل. يعود السطر B إلى الوسيط 3 مع فقدان عشر رسائل
التين. 12. يتم إرجاع الخط A إلى الوسيط 3 دون فقد الرسائل. يعود السطر B إلى الوسيط 3 مع فقدان عشر رسائليمكننا أيضًا ضبط
ha-promote-on-failure على
when-synced . في هذه الحالة ، بدلاً من التراجع إلى النسخة المتطابقة ، سوف تنتظر قائمة الانتظار حتى يعود وسيط 1 مع بياناته إلى وضع الاتصال. بعد عودته ، تظهر قائمة الانتظار الرئيسية مرة أخرى على الوسيط 1 دون فقدان البيانات. تم التضحية بإمكانية الوصول من أجل أمان البيانات. لكن هذا وضع محفوف بالمخاطر ، وقد يؤدي حتى إلى فقد البيانات بشكل كامل ، والذي سنأخذه في الاعتبار في المستقبل القريب.
 التين. 13. لا يزال الخط B غير متوفر بعد خسارة الوسيط 1
التين. 13. لا يزال الخط B غير متوفر بعد خسارة الوسيط 1يمكنك طرح سؤال: "ربما من الأفضل عدم استخدام المزامنة التلقائية مطلقًا؟". الجواب هو أن المزامنة هي عملية حظر. أثناء المزامنة ، لا يمكن لقائمة الانتظار الرئيسية إجراء أي عمليات قراءة أو كتابة!
النظر في مثال. الآن لدينا خطوط طويلة جدا. كيف يمكن أن تنمو إلى هذا الحجم؟ لعدة أسباب:
- لا تستخدم قوائم الانتظار بنشاط.
- هذه خطوط عالية السرعة ، والمستهلكون الآن بطيئون
- هذه هي طوابير عالية السرعة ، وقد حدث فشل والمستهلكين اللحاق بالركب
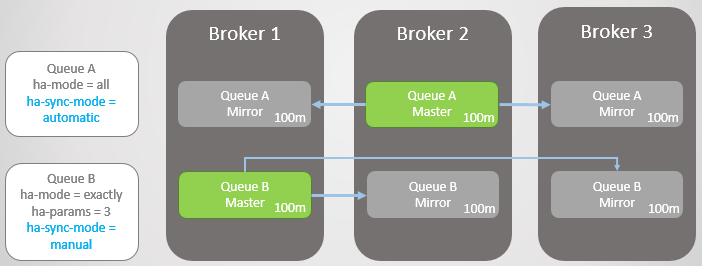 التين. 14. طابور كبير مع أوضاع التزامن المختلفة
التين. 14. طابور كبير مع أوضاع التزامن المختلفةالآن تعطل الوسيط 3.
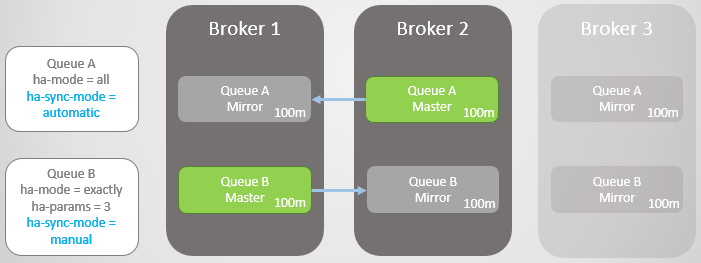 التين. 15. يقع السمسار 3 ، ويترك سيدًا ومرآة في كل قائمة انتظار
التين. 15. يقع السمسار 3 ، ويترك سيدًا ومرآة في كل قائمة انتظاريعود وسيط 3 ، ويتم إنشاء مرايا جديدة. قائمة الانتظار الرئيسية A تبدأ في نسخ الرسائل الموجودة إلى نسخة متطابقة جديدة ، وخلال هذا الوقت ، قائمة الانتظار A غير متوفرة. يتطلب النسخ المتماثل للبيانات ساعتين ، مما يؤدي إلى توقف ساعتين عن قائمة الانتظار هذه!
ومع ذلك ، يبقى الخط B متاحًا طوال الفترة بأكملها. لقد ضحت ببعض التكرار من أجل الوصول.
 التين. 16. قائمة الانتظار غير متوفرة أثناء المزامنة
التين. 16. قائمة الانتظار غير متوفرة أثناء المزامنةبعد ساعتين ، تصبح قائمة الانتظار A متاحة أيضًا وقد تبدأ مرة أخرى في قبول عمليات القراءة والكتابة.
تحديث
هذا السلوك حظر أثناء المزامنة يجعل من الصعب ترقية الكتل مع قوائم انتظار كبيرة جداً. في مرحلة ما ، يجب إعادة تشغيل العقدة مع المعالج ، مما يعني إما التبديل إلى النسخة المتطابقة أو إيقاف تشغيل قائمة الانتظار أثناء تحديث الخادم. إذا اخترنا عملية انتقال ، فسوف نفقد الرسائل إذا لم تتم مزامنة المرايا. بشكل افتراضي ، أثناء فصل الوسيط ، لا يتم تنفيذ الانتقال إلى نسخة متطابقة غير متزامنة. هذا يعني أنه بمجرد عودة الوسيط ، لا نفقد أي رسائل ، فالضرر الوحيد كان مجرد قائمة انتظار بسيطة. يخضع الوسطاء المعطلون لسياسة
ha-promote-on-shutdown . يمكنك تعيين إحدى القيمتين:
always = تمكين التبديل إلى المرايا غير المتزامنة
when-synced = قم بالتبديل إلى النسخة المتطابقة فقط ، وإلا تصبح قائمة الانتظار غير قابلة للوصول للقراءة والكتابة. تعود قائمة الانتظار بمجرد عودة الوسيط
بطريقة أو بأخرى ، مع قوائم الانتظار الكبيرة ، عليك أن تختار بين فقدان البيانات وعدم إمكانية الوصول إليها.
عندما توفر يحسن أمن البيانات
قبل اتخاذ قرار ، يجب أن تؤخذ في الاعتبار تعقيد واحد. في حين أن المزامنة التلقائية أفضل للتكرار ، كيف تؤثر على أمان البيانات؟ بالطبع ، بفضل التكرار الأفضل ، من غير المرجح أن يفقد RabbitMQ الرسائل الموجودة ، ولكن ماذا عن الرسائل الجديدة من الناشرين؟
هنا تحتاج إلى مراعاة ما يلي:
- هل يمكن للناشر فقط إرجاع الخطأ ، وسوف تقوم الخدمة أو المستخدم الأعلى بإعادة المحاولة لاحقًا؟
- هل يمكن للناشر حفظ رسالة محليًا أو في قاعدة بيانات لإعادة المحاولة لاحقًا؟
إذا كان الناشر قادرًا فقط على إسقاط الرسالة ، فإن تحسين إمكانية الوصول يزيد أيضًا من أمان البيانات.
وبالتالي ، يجب السعي لتحقيق التوازن ، والقرار يعتمد على الموقف المحدد.
مشاكل ha-promotion-on-failure = عند المزامنة
فكرة
ha-promotion-on-failure =
عندما تتم
مزامنتها هي أننا نمنع التبديل إلى نسخة متطابقة غير متزامنة وبالتالي تجنب فقد البيانات. قائمة الانتظار لا يمكن الوصول إليها للقراءة أو الكتابة. بدلاً من ذلك ، نحاول إرجاع وسيط متراجع ببيانات غير تالفة بحيث يستأنف العمل كسيد بدون فقدان البيانات.
لكن (وهذا كبير لكن) إذا فقد الوسيط بياناته ، عندئذٍ لدينا مشكلة كبيرة: قائمة الانتظار ضائعة! ذهب كل البيانات! حتى لو كان لديك مرايا تلحق بالركب الأساسي ، فهذه المرايا يتم تجاهلها أيضًا.
لإعادة إضافة عقدة بنفس الاسم ، نطلب من المجموعة أن تنسى العقدة المفقودة (باستخدام
الأمر rabbitmqctl forget_cluster_node ) وأن تبدأ وسيطًا جديدًا يحمل نفس اسم المضيف. طالما يتذكر نظام المجموعة العقدة المفقودة ، فإنه يتذكر قائمة الانتظار القديمة والمرايا غير المتزامنة. عندما يُطلب من المجموعة أن تنسى عقدة مفقودة ، يتم أيضًا نسيان قائمة الانتظار هذه. أنت الآن بحاجة إلى إعادة الإعلان عنها. فقدنا جميع البيانات ، على الرغم من أن لدينا مرايا مع مجموعة بيانات جزئية. سيكون من الأفضل التبديل إلى نسخة متطابقة غير متزامنة!
لذلك ، فإن المزامنة اليدوية (وفشل المزامنة) بالاقتران مع
ha-promote-on-failure=when-synced ، في رأيي ، تعتبر مخاطرة كبيرة. تشير المستندات إلى أن هذا الخيار موجود من أجل أمان البيانات ، لكنه سكين ذو حدين.
إعادة التوازن للاساتذة
كما وعدنا ، نعود إلى مشكلة تراكم جميع الأساتذة على عقد واحدة أو أكثر. يمكن أن يحدث هذا حتى نتيجة لاستكمال تحديثات نظام المجموعة. في مجموعة مكونة من ثلاثة عقد ، تتراكم جميع قوائم الانتظار الرئيسية على عقد أو اثنتين.
يمكن أن يكون إعادة التوازن للسادة مشكلة لسببين:
- لا توجد أدوات جيدة لإعادة التوازن
- قائمة انتظار المزامنة
من أجل إعادة التوازن ، يوجد
ملحق إضافي لجهة خارجية غير معتمد رسميًا. فيما يتعلق بالمكونات الإضافية لجهة خارجية ،
يقول دليل RabbitMQ: "يوفر المكوّن الإضافي بعض أدوات التكوين وإعداد التقارير الإضافية ، لكنه غير مدعوم ولا يتم اختباره من قبل فريق RabbitMQ. استخدم على مسؤوليتك الخاصة. "
هناك حيلة أخرى لنقل قائمة الانتظار الرئيسية من خلال سياسات HA. يذكر الدليل
النصي لهذا الغرض. يعمل على النحو التالي:
- يحذف جميع النسخ المتطابقة باستخدام سياسة مؤقتة ذات أولوية أعلى من سياسة HA الحالية.
- يغير سياسة HA المؤقتة لاستخدام وضع العقد مع العقدة التي يجب نقل قائمة الانتظار الرئيسية إليها.
- مزامنة قائمة الانتظار للهجرة القسرية.
- بعد اكتمال الترحيل ، يحذف السياسة المؤقتة. تدخل السياسة الأولية لـ HA حيز التنفيذ ويتم إنشاء العدد المطلوب من المرايا.
العيب هو أن هذا النهج قد لا يعمل إذا كان لديك قوائم انتظار كبيرة أو متطلبات التكرار الصارمة.
الآن دعونا نرى كيف تعمل مجموعات RabbitMQ مع أقسام الشبكة.
انقطاع الاتصال
يتم توصيل عقد النظام الموزع بواسطة ارتباطات الشبكة ، ويمكن ، وسيتم قطع اتصال ارتباطات الشبكة. يعتمد تكرار الانقطاع على البنية التحتية المحلية أو موثوقية السحابة المحددة. في أي حال ، يجب أن تكون الأنظمة الموزعة قادرة على التعامل معها. مرة أخرى ، لدينا خيار بين إمكانية الوصول والاتساق ، والخبر السار هو أن RabbitMQ يوفر كلاهما (ليس فقط في نفس الوقت).
مع RabbitMQ ، لدينا خياران رئيسيان:
- السماح بالفصل المنطقي (انقسام الدماغ). يوفر هذا إمكانية الوصول ، ولكن يمكن أن يسبب فقدان البيانات.
- عدم السماح بالفصل المنطقي. قد يؤدي إلى فقدان مدى التوفر على المدى القصير اعتمادًا على كيفية اتصال العملاء الكتلة. يمكن أن يؤدي أيضًا إلى عدم إمكانية الوصول الكامل في مجموعة من العقدتين.
ولكن ما هو الفصل المنطقي؟ هذا هو عندما يتم تقسيم كتلة في اثنين بسبب فقدان اتصالات الشبكة. على كل جانب ، ترتفع المرايا إلى درجة الماجستير ، لذلك في النهاية ، هناك العديد من الأسياد في كل منعطف.
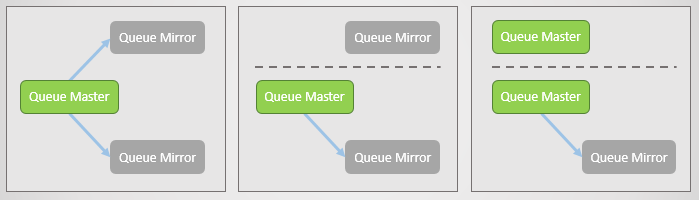 التين. 17. الخط الرئيسي واثنين من المرايا ، كل على عقدة منفصلة. ثم يحدث فشل في الشبكة ويفصل نسخة متطابقة واحدة. ترى العقدة المنفصلة أن الاثنين الأخريين قد سقطا ، وتقدم المرايا الخاصة به للسيد. الآن لدينا سطرين رئيسيين ، وكلاهما يسمح بالكتابة والقراءة.
التين. 17. الخط الرئيسي واثنين من المرايا ، كل على عقدة منفصلة. ثم يحدث فشل في الشبكة ويفصل نسخة متطابقة واحدة. ترى العقدة المنفصلة أن الاثنين الأخريين قد سقطا ، وتقدم المرايا الخاصة به للسيد. الآن لدينا سطرين رئيسيين ، وكلاهما يسمح بالكتابة والقراءة.إذا قام الناشرون بإرسال بيانات إلى كلا الماجستير ، فسنحصل على نسختين متباعدتين من قائمة الانتظار.
توفر أوضاع RabbitMQ المختلفة إمكانية الوصول أو التناسق.
تجاهل الوضع (الافتراضي)
يوفر هذا الوضع إمكانية الوصول. بعد فقدان الاتصال ، يحدث فصل منطقي. بعد إعادة الاتصال ، يجب على المسؤول تحديد القسم المفضل. سيتم إعادة تشغيل الجانب الخاسر ، وسيتم فقد جميع البيانات المتراكمة من هذا الجانب.
 التين. 18. ثلاثة ناشرين مرتبطون بثلاثة وسطاء. داخليًا ، تقوم المجموعة بإعادة توجيه جميع الطلبات إلى قائمة الانتظار الرئيسية على الوسيط 2.
التين. 18. ثلاثة ناشرين مرتبطون بثلاثة وسطاء. داخليًا ، تقوم المجموعة بإعادة توجيه جميع الطلبات إلى قائمة الانتظار الرئيسية على الوسيط 2.الآن نحن نخسر الوسيط 3. إنه يرى أن السماسرة الآخرين قد سقطوا ، وينقل مرآته إلى السيد. هذا هو الفصل المنطقي.
 التين. 19. الانفصال المنطقي (انقسام الدماغ). تسجل السجلات في سطرين رئيسيين ، وتتباعد نسختان.
التين. 19. الانفصال المنطقي (انقسام الدماغ). تسجل السجلات في سطرين رئيسيين ، وتتباعد نسختان.تتم استعادة الاتصال ، ولكن يبقى الفصل المنطقي. يجب على المسؤول تحديد الجانب الخاسر يدويًا. في الحالة التالية ، يقوم المسؤول بإعادة تشغيل Broker 3. يتم فقد جميع الرسائل التي لم يتمكن من نقلها.
 التين. 20. المسؤول يعطل الوسيط 3.
التين. 20. المسؤول يعطل الوسيط 3. التين. 21. يبدأ المسؤول Broker 3 وينضم إلى المجموعة ويفقد كل الرسائل التي بقيت هناك.
التين. 21. يبدأ المسؤول Broker 3 وينضم إلى المجموعة ويفقد كل الرسائل التي بقيت هناك.أثناء فقد الاتصال وبعد استعادته ، كانت المجموعة وقائمة الانتظار هذه متاحة للقراءة والكتابة.
وضع Autoheal
يعمل بشكل مشابه لوضع التجاهل ، باستثناء أن الكتلة نفسها تحدد تلقائيًا الجانب الخاسر بعد تقسيم الاتصال واستعادته. يعود الجانب الخاسر إلى الكتلة فارغًا ، ويفقد قائمة الانتظار جميع الرسائل التي تم إرسالها فقط إلى هذا الجانب.
وقفة وضع الأقلية
إذا كنا لا نريد السماح بالفصل المنطقي ، فإن خيارنا الوحيد هو رفض القراءة والكتابة على الجانب الأصغر بعد قسم المجموعة. عندما يرى وسيط أنه على الجانب الأقل ، فإنه يتوقف مؤقتًا ، أي ، يغلق جميع الاتصالات الحالية ويرفض أي اتصالات جديدة. مرة واحدة في الثانية ، فإنه يتحقق لإعادة الاتصال. بمجرد استعادة الاتصال ، يستأنف العمل وينضم إلى الكتلة.
 التين. 22. يرتبط ثلاثة ناشرين بثلاثة وسطاء. داخليًا ، تقوم المجموعة بإعادة توجيه جميع الطلبات إلى قائمة الانتظار الرئيسية على الوسيط 2.
التين. 22. يرتبط ثلاثة ناشرين بثلاثة وسطاء. داخليًا ، تقوم المجموعة بإعادة توجيه جميع الطلبات إلى قائمة الانتظار الرئيسية على الوسيط 2.بعد ذلك يتم فصل الوسطاء 1 و 2 عن الوسيط 3. بدلاً من ترقية نسختهم إلى رئيسية ، يتوقف الوسيط 3 مؤقتًا ويصبح يتعذر الوصول إليه.
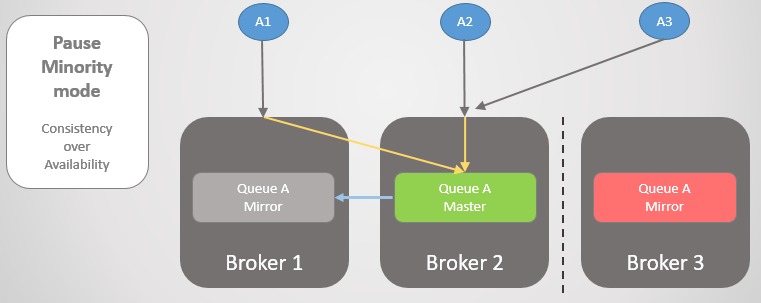 التين. 23. يقوم الوسيط 3 بإيقاف تشغيل جميع العملاء مؤقتًا ، ويرفض طلبات الاتصال.
التين. 23. يقوم الوسيط 3 بإيقاف تشغيل جميع العملاء مؤقتًا ، ويرفض طلبات الاتصال.بمجرد استعادة الاتصال ، فإنه يعود إلى الكتلة.
دعونا نلقي نظرة على مثال آخر ، حيث يكون الخط الرئيسي في Broker 3.
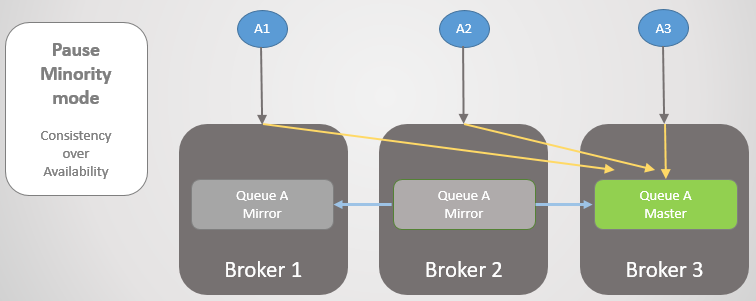 التين. 24. الخط الرئيسي في الوسيط 3.
التين. 24. الخط الرئيسي في الوسيط 3.ثم يحدث نفس فقدان الاتصال. الوسيط 3 يتوقف مؤقتًا لأنه على الجانب الأصغر. على الجانب الآخر ، ترى العقد أن الوسيط 3 قد سقط ، بحيث ترتفع النسخة القديمة من الوسيطين 1 و 2 للسيد.
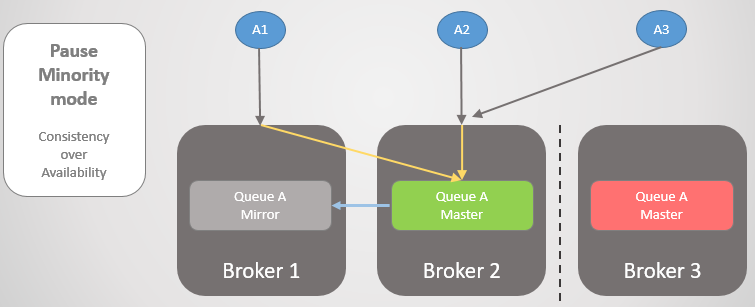 التين. 25. الانتقال إلى الوسيط 2 إذا كان الوسيط 3 غير متوفر.
التين. 25. الانتقال إلى الوسيط 2 إذا كان الوسيط 3 غير متوفر.عند استعادة الاتصال ، سينضم Broker 3 إلى المجموعة.
 التين. 26. عادت الكتلة إلى التشغيل الطبيعي.
التين. 26. عادت الكتلة إلى التشغيل الطبيعي.من المهم أن نفهم أننا نحصل على تناسق ، ولكن يمكننا أيضًا الحصول على إمكانية الوصول
إذا نجحنا في نقل العملاء إلى معظم القسم. بالنسبة لمعظم المواقف ، سأختار شخصيًا وضع Pause Minority ، لكنه يعتمد حقًا على الحالة الخاصة.
لضمان توفرها ، من المهم التأكد من أن العملاء يتصلون بنجاح بالموقع. النظر في خياراتنا.
اتصال العملاء
لدينا العديد من الخيارات حول كيفية إرسال العملاء إلى الجزء الرئيسي من الكتلة أو إلى عقد العمل (بعد فشل عقدة واحدة) بعد فقدان الاتصال. أولاً ، دعنا نتذكر أن قائمة انتظار معينة يتم استضافتها على مضيف معين ، ولكن يتم نسخ التوجيه والسياسات على جميع المضيفين. يمكن للعملاء الاتصال بأي عقدة ، وسيوجههم التوجيه الداخلي عند الضرورة. ولكن عندما يتم تعليق العقدة ، فإنها ترفض الاتصال ، لذلك يجب على العملاء الاتصال بعقدة أخرى. إذا سقطت عقدة ، فإنه لا يستطيع فعل الكثير على الإطلاق.
خياراتنا:
- يتم الوصول إلى الكتلة باستخدام موازن التحميل ، والذي يقوم ببساطة بالتدوير عبر العقد ويقوم العملاء بمحاولات متكررة للاتصال حتى يتم الانتهاء بنجاح. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
النتائج
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446