مرحبا يا هبر!
كجزء من استكشاف موضوع C # 8 ، نقترح مناقشة المقالة التالية حول القواعد الجديدة لتطبيق الواجهات.
 عند النظر عن كثب في كيفية تنظيم
عند النظر عن كثب في كيفية تنظيم الواجهات
في C # 8 ، يتعين عليك مراعاة أنه عند تنفيذ الواجهات ، يمكنك كسر الحطب افتراضيًا.
يمكن أن تؤدي الافتراضات المتعلقة بالتطبيق الافتراضي إلى تلف التعليمات البرمجية واستثناءات وقت التشغيل وضعف الأداء.إحدى الميزات المعلنة بفاعلية لواجهات C # 8 هي أنه يمكنك إضافة أعضاء إلى واجهة دون كسر برامج التنفيذ الحالية. لكن الإهمال في هذه الحالة محفوف بالمشاكل الكبيرة. خذ بعين الاعتبار الكود الذي تم به افتراضات خاطئة - هذا سيجعل من الواضح مدى أهمية تجنب مثل هذه المشاكل.
تم نشر جميع التعليمات البرمجية لهذه المقالة على GitHub: jeremybytes / interfaces-in-csharp-8 ، وتحديداً في مشروع DangerousAssumptions .
ملاحظة: تتناول هذه المقالة ميزات C # 8 ، المطبقة حاليًا فقط في .NET Core 3.0. في الأمثلة التي استخدمتها ، Visual Studio 16.3.0 و .NET Core 3.0.100 .
افتراضات حول تفاصيل التنفيذالسبب الرئيسي في توضيح هذه المشكلة هو كما يلي: لقد وجدت مقالًا على الإنترنت حيث يقدم المؤلف رمزًا مع افتراضات ضعيفة جدًا حول التنفيذ (لن أشير إلى المقالة لأنني لا أريد أن يتم نشر المؤلف مع التعليقات ؛ سأتصل به شخصيًا) .
تتحدث المقالة عن مدى جودة التطبيق الافتراضي ، لأنه يسمح لنا بتكميل الواجهات حتى بعد وجود رمز بالفعل للمنفذين. ومع ذلك ، يتم وضع عدد من الافتراضات السيئة في هذا الرمز (الرمز موجود في
BadInterface للمجلد في مشروعي GitHub)
هنا هي الواجهة الأصلية:
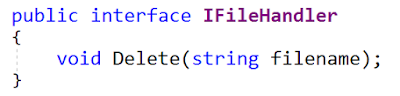
يوضح باقي المقالة تطبيق واجهة MyFile (بالنسبة لي ، في ملف
MyFile.cs ):
توضح المقالة بعد ذلك كيف يمكنك إضافة طريقة
Rename التسمية مع التطبيق الافتراضي ، ولن يتم فصل فئة
MyFile الحالية.
هذه هي الواجهة المحدّثة (من ملف
IFileHandler.cs ):

MyFile لا يزال يعمل ، لذلك كل شيء على ما يرام. إلى هذا الحد؟ ليس حقا
الافتراضات السيئةتتمثل المشكلة الرئيسية في طريقة إعادة التسمية في ما يرتبط به افتراض ضخم: تستخدم التطبيقات ملفًا فعليًا موجودًا في نظام الملفات.
النظر في التطبيق الذي أنشأته للاستخدام في نظام الملفات الموجود في RAM. (ملاحظة: هذا هو الرمز الخاص بي. ليس من مقال أنتقده. ستجد التنفيذ الكامل في ملف
MemoryStringFileHandler.cs .)

تطبق هذه الفئة نظام ملفات رسمي يستخدم قاموسًا موجودًا في ذاكرة الوصول العشوائي ، والذي يحتوي على ملفات نصية. لا يوجد شيء هنا من شأنه أن يؤثر على نظام الملفات الفعلي ؛ لا توجد عموما إشارات إلى
System.IO .
المنفذ الخاطئبعد تحديث الواجهة ، هذه الفئة تالفة.
إذا قام رمز العميل باستدعاء طريقة إعادة التسمية ، فسيؤدي ذلك إلى إنشاء خطأ في وقت التشغيل (أو ما هو أسوأ من ذلك ، إعادة تسمية الملف المخزن في نظام الملفات).
حتى إذا كان تطبيقنا سيعمل مع الملفات الفعلية ، فيمكنه الوصول إلى الملفات الموجودة في التخزين السحابي ، ولا يمكن الوصول إلى هذه الملفات من خلال System.IO.File.
هناك أيضًا مشكلة محتملة عندما يتعلق الأمر باختبار الوحدة. إذا لم يتم تحديث الكائن المحاكاة أو المزيفة ، وتم تحديث الرمز المختبر ، فسيحاول الوصول إلى نظام الملفات عند إجراء اختبارات الوحدة.
نظرًا لأن الافتراض الخاطئ يتعلق بالواجهة ، فإن الجهات المنفذة لهذه الواجهة تالفة.
مخاوف غير معقولة؟لا جدوى من التفكير في مثل هذه المخاوف. عندما أتحدث عن التجاوزات في الكود ، يجيبونني: "حسنًا ، لا يعرف الشخص كيفية البرمجة." لا أستطيع أن أتعارض مع هذا.
عادة ما أفعل هذا: أنا أنتظر وننظر في كيفية عمل ذلك. على سبيل المثال ، كنت خائفًا من احتمال إساءة استخدام "استخدام ثابت". حتى الآن ، لم يكن هذا مقتنعا.
يجب أن يؤخذ في الاعتبار أن مثل هذه الأفكار موجودة في الهواء ، لذلك في وسعنا أن نساعد الآخرين على اتخاذ مسار أكثر ملاءمة ، والذي لن يكون مؤلمًا للغاية لمتابعة.
مشاكل الأداءبدأت أفكر في المشكلات الأخرى التي يمكن أن تنتظرنا إذا وضعنا افتراضات غير صحيحة حول مطبقي الواجهة.
في المثال السابق ، يتم استدعاء الكود الموجود خارج الواجهة نفسها (في هذه الحالة ، خارج System.IO). ربما توافق على أن مثل هذه الأعمال جرس خطير. ولكن ، إذا استخدمنا الأشياء التي تعد بالفعل جزءًا من الواجهة ، فكل شيء يجب أن يكون جيدًا ، أليس كذلك؟
ليس دائما
كمثال صريح ، قمت بإنشاء واجهة IReader.
واجهة المصدر وتنفيذهفيما يلي واجهة IReader الأصلية (من ملف
IReader.cs - رغم أن هناك الآن تحديثات بالفعل في هذا الملف):

هذه واجهة أسلوب عامة تتيح لك الحصول على مجموعة من العناصر للقراءة فقط.
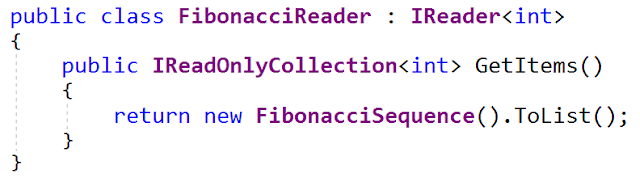
ينشئ أحد تطبيقات هذه الواجهة سلسلة من أرقام فيبوناتشي (نعم ، لدي مصلحة غير صحية في توليد تسلسلات فيبوناتشي). هذه هي واجهة
FibonacciReader (من ملف
FibonacciReader.cs - يتم تحديثها أيضًا على github):
فئة
FibonacciSequence هي تطبيق لـ
IEnumerable <int> (من ملف FibonacciSequence.cs). يستخدم عددًا صحيحًا 32 بت كنوع بيانات ، لذلك يحدث تجاوز السرعة بسرعة كبيرة.

إذا كنت مهتمًا بهذا التطبيق ،
فقم بإلقاء نظرة على
TDDing في تسلسل Fibonacci في المقالة
C # .
مشروع DangerousAssumptions هو تطبيق وحدة تحكم يعرض نتائج FibonacciReader (من ملف
Program.cs ):

وهنا الاستنتاج:
 واجهة محدثة
واجهة محدثةحتى الآن لدينا رمز العمل. ولكن ، عاجلاً أم آجلاً ، قد نحتاج إلى الحصول على عنصر منفصل عن IReader ، وليس المجموعة بأكملها دفعة واحدة. نظرًا لأننا نستخدم نوعًا عامًا مع الواجهة ، ومع ذلك ، فليس لدينا خاصية "المعرف الطبيعي" في الكائن ، وسنقوم بتوسيع العنصر الموجود في فهرس محدد.
فيما يلي واجهة المستخدم التي
GetItemAt أسلوب
GetItemAt (من الإصدار النهائي من ملف
IReader.cs ):

GetItemAt هنا يفترض تطبيق افتراضي. للوهلة الأولى - ليست سيئة للغاية. يستخدم عضو واجهة موجود (
GetItems ) ، لذلك ، لا توجد افتراضات "خارجية" هنا. مع النتائج ، يستخدم طريقة LINQ. أنا معجب كبير بـ LINQ ، وهذا الرمز ، في رأيي ، مبني بشكل معقول.
اختلافات الأداءنظرًا لأن التطبيق الافتراضي يستدعي
GetItems ، فإنه يتطلب إعادة المجموعة بالكامل قبل تحديد عنصر معين.
في حالة
FibonacciReader هذا يعني أنه سيتم إنشاء جميع القيم. في نموذج محدّث ، سيحتوي ملف
Program.cs على الكود التالي:

لذلك نحن نسمي
GetItemAt . هنا الاستنتاج:

إذا وضعنا نقطة تفتيش داخل ملف FibonacciSequence.cs ، فسنرى أن التسلسل بأكمله يتم إنشاؤه لهذا الغرض.
بعد بدء تشغيل البرنامج ،
GetItems عند نقطة التحكم هذه مرتين: أولاً عند استدعاء
GetItems ، ثم عند استدعاء
GetItemAt .
افتراض ضار بالأداءأخطر مشكلة في هذه الطريقة هي أنها تتطلب استرداد المجموعة الكاملة للعناصر. إذا كان هذا
IReader سيأخذه من قاعدة البيانات ، فيجب سحب الكثير من العناصر منه ، وبعد ذلك سيتم اختيار واحد منهم فقط. سيكون أفضل بكثير إذا تمت معالجة هذا الاختيار النهائي في قاعدة بيانات.
بالعمل مع
FibonacciReader ، نحسب كل عنصر جديد. وبالتالي ، يجب حساب القائمة بالكامل بالكامل للحصول على عنصر واحد فقط نحتاجه. حساب تسلسل فيبوناتشي هو عملية لا تحمّل المعالج أكثر من اللازم ، لكن ماذا لو تعاملنا مع شيء أكثر تعقيدًا ، على سبيل المثال ، سنحسب الأعداد الأولية؟
قد تقول: "حسنًا ، لدينا طريقة
GetItems تُرجع كل شيء. إذا كان يعمل لفترة طويلة ، فمن المحتمل ألا يكون هنا. وهذا بيان صريح.
ومع ذلك ، رمز الاتصال لا يعرف شيئا عن هذا. إذا اتصلت بـ
GetItems ،
GetItems أنه (ربما) يجب أن تمر معلوماتي عبر الشبكة وستكون هذه العملية مكثفة في التاريخ. إذا طلبت عنصرًا واحدًا ، فلماذا أتوقع مثل هذه التكاليف؟
تحسين الأداء المحددفي حالة
FibonacciReader يمكننا إضافة تطبيقنا لتحسين الأداء بشكل ملحوظ (في الإصدار النهائي من ملف
FibonacciReader.cs ):

يتجاوز الأسلوب
GetItemAt التطبيق الافتراضي المتوفر في الواجهة.
أنا هنا استخدم نفس طريقة LINQ
ElementAt كما في التطبيق الافتراضي. ومع ذلك ، لا أستخدم هذه الطريقة مع المجموعة للقراءة فقط التي يُرجعها GetItems ، لكن مع FibonacciSequence ، وهو
IEnumerable .
نظرًا لأن
FibonacciSequence هو
IEnumerable ، فإن الدعوة إلى
ElementAt ستنتهي بمجرد وصول البرنامج إلى العنصر الذي
ElementAt . لذلك ، لن نقوم بإنشاء المجموعة بأكملها ، ولكن فقط العناصر الموجودة حتى الموضع المحدد في الفهرس.
لتجربة ذلك ، اترك نقطة التحكم التي قمنا بها أعلاه في التطبيق وقم بتشغيل التطبيق مرة أخرى. هذه المرة
GetItems عند نقطة توقف مرة واحدة فقط (عند استدعاء
GetItems ). عند استدعاء
GetItemAt لن يحدث هذا.
مثال مفتعلة قليلاهذا المثال بعيد المنال قليلاً ، لأنه ، كقاعدة عامة ، ليس عليك تحديد عناصر من مجموعة البيانات حسب الفهرس. ومع ذلك ، يمكنك أن تتخيل شيئًا مماثلاً يمكن أن يحدث إذا كنا نعمل مع خاصية الهوية الطبيعية.
إذا قمنا بسحب العناصر حسب المعرف ، وليس عن طريق الفهرس ، فربما واجهنا مشاكل الأداء نفسها في التطبيق الافتراضي. يتطلب التنفيذ الافتراضي إرجاع جميع العناصر ، وبعد ذلك يتم اختيار عنصر واحد منها فقط. إذا سمحت لقاعدة البيانات أو "قارئ" آخر بسحب عنصر معين بمعرفه ، فستكون هذه العملية أكثر فاعلية.
فكر في افتراضاتكالافتراضات لا غنى عنها. إذا حاولنا مراعاة الكود في أي حالات استخدام محتملة لمكتباتنا ، فلن تكتمل أي مهمة على الإطلاق. لكنك لا تزال بحاجة إلى التفكير بعناية في الافتراضات الموجودة في الكود.
هذا لا يعني أن تطبيق
GetElementAt سيئ بالضرورة. نعم ، هناك مشكلات محتملة في الأداء. ومع ذلك ، إذا كانت مجموعات البيانات صغيرة ، أو كانت العناصر المحسوبة "رخيصة" ، فقد يكون التنفيذ الافتراضي حلاً معقولاً.
مع ذلك ، لا أرحب بالتغييرات في الواجهة بعد أن تحتوي بالفعل على منفذين. لكنني أفهم أن هناك أيضًا سيناريوهات يفضل فيها الخيارات البديلة. البرمجة هي الحل للمشكلات ، وعند حل المشكلات ، من الضروري أن نزن إيجابيات وسلبيات كل أداة وطرق نستخدمها.
قد يؤدي التطبيق الافتراضي إلى الإضرار بمنفذي الواجهة (وربما الكود الذي سيستدعي هذه التطبيقات). لذلك ، يجب أن تكون حذراً بشكل خاص حول الافتراضات المتعلقة بالتطبيقات الافتراضية.
حظا سعيدا في عملك!