نحن بصدد إعداد الإصدار الرئيسي التالي من Tokio ، وهي بيئة تشغيل غير متزامنة لصدأ. في 13 أكتوبر ، تم إصدار
طلب تجمع مع جدولة مهمة تمت إعادة كتابته بالكامل لدمجه في فرع. ستكون النتيجة تحسينات هائلة في الأداء وتقليل زمن الوصول. سجلت بعض الاختبارات تسارع عشرة أضعاف! كالعادة ، الاختبارات الاصطناعية لا تعكس الفوائد الفعلية في الواقع. لذلك ، فحصنا أيضًا كيف أثرت التغييرات في المجدول على المهام الحقيقية ، مثل
Hyper و
Tonic (spoiler: النتيجة رائعة).
أثناء الاستعداد للعمل على مخطط جديد ، قضيت وقتًا في البحث عن الموارد المواضيعية. بصرف النظر عن التطبيقات الفعلية ، لم يتم العثور على شيء خاص. لقد وجدت أيضًا أن شفرة المصدر للتطبيقات الحالية يصعب التنقل فيها. لإصلاح هذا الأمر ، حاولنا كتابة sheduler Tokio بطريقة نظيفة قدر الإمكان. آمل أن تساعد هذه المقالة المفصلة عن تنفيذ المجدول أولئك الذين هم في نفس الموقف ويبحثون عن معلومات حول هذا الموضوع دون جدوى.
تبدأ المقالة بمراجعة عالية المستوى للتصميم ، بما في ذلك سياسات التقاط الوظائف. ثم اطلع على تفاصيل التحسينات المحددة في برنامج جدولة Tokio الجديد.
تحسينات تعتبر:
كما ترون ، الموضوع الرئيسي هو "التخفيض". بعد كل شيء ، أسرع رمز هو افتقارها!
سنتحدث أيضًا عن
اختبار الجدولة الجديدة . من الصعب جدًا كتابة الرمز الصحيح الموازي بدون أقفال. من الأفضل العمل ببطء ، ولكن بشكل صحيح ، بدلاً من العمل بسرعة ، ولكن مع الأخطاء ، خاصةً إذا كانت الأخطاء تتعلق بأمان الذاكرة. ومع ذلك ، يجب أن يعمل الخيار الأفضل بسرعة وبدون أخطاء ، لذلك فقد كتبنا أداة اختبار التزامن.
قبل الغوص في الموضوع ، أود أن أشكر:
- Withoutboats وغيرهم ممن عملوا على وظيفة المزامنة
async / await في Rust. لقد قمت بعمل رائع. هذه هي ميزة القاتل.
- @ cramertj وغيرهم ممن طوروا
std::task . هذا تحسن كبير عما كان عليه من قبل. وكود كبير.
- Buoyant ، خالق Linkerd ، والأهم من ذلك ، صاحب العمل. شكرا لك على السماح لي بقضاء الكثير من الوقت في هذه الوظيفة. إذا كان أي شخص مهتمًا بشبكة الخدمة ، فقم بإلقاء نظرة على Linkerd. قريبا سوف تشمل جميع الفوائد التي نوقشت في هذه المقالة.
- الذهاب لهذا التنفيذ مخطط جيد.
خذ كوب من القهوة والجلوس. هذا سيكون مقال طويل.
كيف يعمل المخططون؟
مهمة sheduler هي خطة العمل. يتم تقسيم التطبيق إلى وحدات العمل ، والتي سوف نسميها
المهام . تعتبر المهمة قابلة للتشغيل عندما يمكنها التقدم في تنفيذها ، ولكنها لم تعد مكتملة أو في وضع الخمول ، عندما يتم تأمينها على مورد خارجي. المهام مستقلة بمعنى أنه يمكن تنفيذ أي عدد من المهام في وقت واحد. المجدول مسؤول عن تشغيل المهام في حالة التشغيل حتى يعودوا إلى وضع الاستعداد. يتضمن تنفيذ المهمة تعيين وقت المعالج للمهمة - مورد عمومي.
تتناول هذه المقالة جدولة مساحة المستخدم ، أي العمل على مؤشرات ترابط نظام التشغيل (والتي بدورها يتم التحكم فيها بواسطة sheduler مستوى kernel). تقوم أداة جدولة Tokio بتنفيذ عقود Rust المستقبلية ، والتي يمكن اعتبارها "خيوط خضراء غير متزامنة". هذا هو نمط
التدفق المختلط M: N حيث تتم مضاعفة العديد من مهام واجهة المستخدم على عدة مؤشرات ترابط لنظام التشغيل.
هناك العديد من الطرق المختلفة لمحاكاة sheduler ، لكل منها إيجابيات وسلبيات. على المستوى الأساسي ، يمكن تصميم برنامج الجدولة كقائمة
انتظار ومعالج يفصلها. المعالج هو جزء من التعليمات البرمجية التي يتم تشغيلها في سلسلة رسائل. في الرمز الزائف ، يقوم بما يلي:
while let Some(task) = self.queue.pop() { task.run(); }
عندما تصبح المهمة ممكنة ، يتم إدراجها في قائمة انتظار التنفيذ.
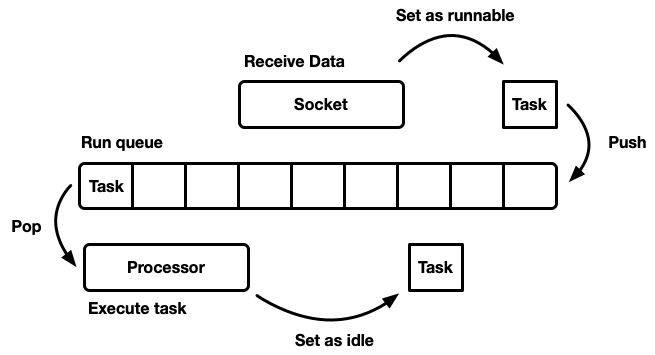
على الرغم من أنه يمكنك تصميم نظام تتواجد فيه الموارد والمهام والمعالج على نفس الخيط ، إلا أن Tokio يفضل استخدام مؤشرات ترابط متعددة. نحن نعيش في عالم حيث يحتوي الكمبيوتر على العديد من المعالجات. تطوير جدولة مفردة الخيوط سيؤدي إلى عدم كفاية تحميل الحديد. نريد استخدام جميع وحدات المعالجة المركزية. هناك عدة طرق للقيام بذلك:
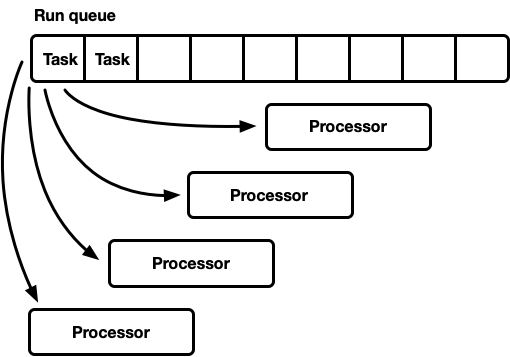
- قائمة انتظار تنفيذ عالمية واحدة ، العديد من المعالجات.
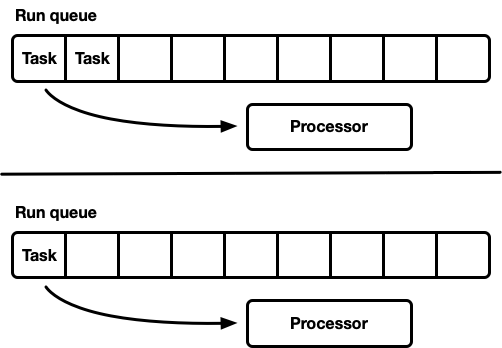
- العديد من المعالجات ، ولكل منها قائمة انتظار التشغيل الخاصة بها.
منعطف واحد ، العديد من المعالجات
يحتوي هذا النموذج على قائمة انتظار تنفيذ عالمية واحدة. عندما تصبح المهام كاملة ، يتم وضعها في ذيل قائمة الانتظار. هناك العديد من المعالجات ، كل في موضوع منفصل. يأخذ كل معالج مهمة من رأس قائمة الانتظار أو يحظر سلسلة العمليات إذا لم تكن هناك مهام متاحة.
يجب دعم خط التنفيذ من قبل العديد من المصنعين والمستهلكين. عادةً ما يتم استخدام قائمة
تدخلية تتضمن فيها بنية كل مهمة مؤشرًا للمهمة التالية في قائمة الانتظار (بدلاً من لف المهام في قائمة مرتبطة). وبالتالي ، يمكن تجنب تخصيص الذاكرة لعمليات الدفع والبوب. يمكنك استخدام
عملية الدفع بدون قفل ، ولكن لتنسيق المستهلكين ، يكون كائن المزامنة مطلوبًا للعملية المنبثقة (من الممكن تقنيًا تنفيذ قائمة انتظار متعددة المستخدمين دون قفل).
ومع ذلك ، في الممارسة العملية ، النفقات العامة للحماية المناسبة ضد الأقفال أكثر من مجرد استخدام كائن مزامنة.
غالبًا ما يتم استخدام هذا الأسلوب في تجمع مؤشرات ترابط للأغراض العامة ، لأنه يحتوي على عدة مزايا:
- يتم تخطيط المهام إلى حد ما.
- تنفيذ بسيط نسبيا. يتم ربط قائمة انتظار قياسية أو أكثر مع دورة المعالج الموضحة أعلاه.
مذكرة موجزة عن التخطيط العادل (العادل). وهذا يعني أن المهام يتم تنفيذها بصدق: من جاء في وقت سابق هو الذي ترك في وقت سابق. يحاول المخططون للأغراض العامة أن يكونوا منصفين ، لكن هناك استثناءات ، مثل التوازي عبر الربط بين مفترق طرق ، حيث تعد سرعة حساب النتيجة ، بدلاً من تحقيق العدالة لكل مهمة فرعية فردية ، عاملاً هامًا.
هذا النموذج لديه الجانب السلبي. تنطبق جميع المعالجات على المهام من رأس قائمة الانتظار. لخيوط للأغراض العامة ، وهذا عادة لا يمثل مشكلة. يتجاوز الوقت اللازم لإكمال المهمة الوقت اللازم لاستردادها من قائمة الانتظار. عندما يتم تنفيذ المهام على مدار فترة زمنية طويلة ، يتم تقليل المنافسة في قائمة الانتظار. ومع ذلك ، من المتوقع أن تكتمل مهام Rust غير المتزامنة بسرعة كبيرة. في هذه الحالة ، تزيد التكاليف العامة للقتال في قائمة الانتظار بشكل كبير.
التزامن والتعاطف الميكانيكي
لتحقيق أقصى قدر من الأداء ، يجب علينا الاستفادة القصوى من ميزات الأجهزة. استخدم المصطلح "تعاطف ميكانيكي" للبرنامج لأول مرة بواسطة
Martin Thompson (لم تعد مدوّنته محدّثة ، لكنها مازالت مفيدة للغاية).
مناقشة تفصيلية لتنفيذ التوازي في المعدات الحديثة هو خارج نطاق هذه المقالة. بشكل عام ، يزيد الحديد من الإنتاجية ليس بسبب التسارع ، ولكن بسبب إدخال عدد أكبر من مراكز وحدة المعالجة المركزية (حتى جهاز الكمبيوتر المحمول به ستة!) يمكن لكل نواة إجراء كميات كبيرة من الحساب في فترات زمنية صغيرة للغاية. تستغرق إجراءات مثل الوصول إلى ذاكرة التخزين المؤقت والذاكرة وقتًا
أطول بكثير مقارنة بوقت التنفيذ على وحدة المعالجة المركزية. لذلك ، لتسريع التطبيقات ، تحتاج إلى زيادة عدد تعليمات وحدة المعالجة المركزية لكل وصول إلى الذاكرة. على الرغم من أن المترجم يساعد كثيرًا ، لا يزال يتعين علينا التفكير في أشياء مثل أنماط المحاذاة والوصول إلى الذاكرة.
تعمل مؤشرات الترابط المنفصلة بشكل منفصل تمامًا مثل سلسلة العمليات المنفردة ،
حتى تقوم عدة مؤشرات ترابط في نفس الوقت بتعديل نفس خط ذاكرة التخزين المؤقت (الطفرات المتزامنة) أو مطلوب
تناسق ثابت . في هذه الحالة ،
يتم تنشيط
بروتوكول تماسك ذاكرة التخزين المؤقت لوحدة المعالجة المركزية . ويضمن أهمية ذاكرة التخزين المؤقت لكل وحدة المعالجة المركزية.
الاستنتاج واضح: قدر الإمكان ، تجنب التزامن بين الخيوط ، لأنه بطيء.
العديد من المعالجات ، ولكل منها قائمة انتظار التنفيذ الخاصة بها
نموذج آخر هو عدة برامج جدولة مفردة. يتلقى كل معالج قائمة انتظار التنفيذ الخاصة به ، ويتم إصلاح المهام على معالج محدد. هذا يتجنب تماما مشكلة التزامن. نظرًا لأن نموذج مهمة Rust يتطلب القدرة على انتظار مهمة من أي مؤشر ترابط ، يجب أن تظل هناك طريقة آمنة لسلسلة العمليات لإدخال المهام في المجدول. تدعم إما قائمة انتظار التنفيذ لكل معالج عملية الدفع الآمن لمؤشر الترابط (MPSC) ، أو يحتوي كل معالج على طابور انتظار تنفيذ: غير آمن ومتزامن.
هذه الاستراتيجية تستخدم
Seastar . نظرًا لأننا نتجنب التزامن تمامًا تقريبًا ، توفر هذه الاستراتيجية سرعة جيدة جدًا. لكنها لا تحل كل المشاكل. إذا لم يكن عبء العمل متجانسًا تمامًا ، تكون بعض المعالجات تحت الحمل ، بينما يكون البعض الآخر خاملاً ، مما يؤدي إلى عدم الاستخدام الأمثل للموارد. يحدث هذا بسبب إصلاح المهام على معالج معين. عندما يتم التخطيط لمجموعة من المهام في حزمة على معالج واحد ، فإنها تفي بمفردها بأقصى حمل ، حتى لو كانت الخمول أخرى.
معظم أعباء العمل "الحقيقية" ليست متجانسة. لذلك ، عادة ما يتجنب المخططون للأغراض العامة هذا النموذج.
التقاط وظيفة جدولة
يستند المجدول مع جدولة سرقة العمل إلى نموذج المجدول المحدد ، ويحل مشكلة التحميل غير الكامل لموارد الأجهزة. يدعم كل معالج قائمة انتظار التنفيذ الخاصة به. يتم وضع المهام التي يتم تنفيذها في قائمة انتظار التنفيذ للمعالج الحالي ، ويعمل عليها. ولكن عندما يكون المعالج خاملاً ، فإنه يتحقق من صفوف المعالج الشقيق ويحاول الحصول على شيء من هناك. ينتقل المعالج إلى وضع السكون فقط بعد عدم تمكنه من العثور على عمل من قوائم انتظار التنفيذ من نظير إلى نظير.

على مستوى النموذج ، هذا هو نهج "أفضل ما في العالمين". تحت الحمل ، تعمل المعالجات بشكل مستقل ، وتتجنب المزامنة العلوية. في الحالات التي يتم فيها توزيع الحمل بين المعالجات بشكل غير متساو ، يمكن لجدولة إعادة توزيعه. هذا هو السبب في استخدام هذه
المجدولات في
Go و
Erlang و
Java ولغات أخرى.
العيب هو أن هذا النهج هو أكثر تعقيدا بكثير. يجب أن تدعم خوارزمية قائمة الانتظار التقاط الوظيفة ، وللتنفيذ السلس ، يلزم إجراء
بعض المزامنة بين المعالجات. إذا لم يتم تطبيقه بشكل صحيح ، فيمكن أن تكون النفقات الإضافية لالتقاط الصور أكبر من الربح.
ضع في اعتبارك هذا الموقف: يقوم المعالج A حاليًا بتنفيذ مهمة ، ولديه قائمة انتظار تنفيذ فارغة. المعالج B خاملاً ؛ يحاول التقاط بعض المهام ، لكنه يفشل ، لذلك يذهب إلى وضع السكون. ثم يتم إنشاء 20 مهمة من مهمة المعالج A. من الناحية المثالية ، يجب على المعالج B الاستيقاظ والاستيلاء على بعضها. لهذا ، من الضروري تطبيق بعض الاستدلال في برنامج الجدولة ، حيث تشير المعالجات إلى معالجات نظير النوم حول ظهور مهام جديدة في قائمة الانتظار الخاصة بهم. بالطبع ، هذا يتطلب تزامن إضافي ، لذلك يتم تقليل هذه العمليات إلى الحد الأدنى.
باختصار:
- كلما كان التزامن أقل ، كان ذلك أفضل.
- التقاط الوظيفة هو الخوارزمية المثلى لمخططي الأغراض العامة.
- يعمل كل معالج بشكل مستقل عن الآخرين ، ولكن يلزم إجراء بعض المزامنة لالتقاط العمل.
Tokio 0.1 المجدول
تم إصدار أول جدولة عمل لـ Tokio في مارس 2018. كانت هذه المحاولة الأولى ، بناءً على بعض الافتراضات التي تبين أنها خاطئة.
أولاً ، اقترح برنامج جدولة Tokio 0.1 إغلاق مؤشرات ترابط المعالج إذا كانت خاملة لفترة زمنية معينة. تم إنشاء المجدول في الأصل كنظام "للأغراض العامة" لتجمع خيط الصدأ. في ذلك الوقت ، كان وقت تشغيل Tokio لا يزال في مرحلة مبكرة من التطوير. ثم افترض النموذج أنه سيتم تنفيذ مهام الإدخال / الإخراج على نفس مؤشر الترابط مثل محدد الإدخال / الإخراج (epoll ، kqueue ، iocp ...). يمكن توجيه المزيد من المهام الحسابية إلى تجمع مؤشرات الترابط. في هذا السياق ، يتم افتراض تكوين مرن لعدد مؤشرات الترابط النشطة ، لذلك من المنطقي تعطيل مؤشرات الترابط الخاملة. ومع ذلك ، في برنامج الجدولة الذي يحتوي على التقاط الوظيفة ، تحول النموذج إلى أداء
جميع المهام غير المتزامنة ، وفي هذه الحالة ، من المنطقي دائمًا الاحتفاظ بعدد صغير من مؤشرات الترابط في الحالة النشطة.
ثانياً ، تم تنفيذ خط
العارضة ذات الاتجاهين
هناك . يعتمد هذا التطبيق على
خط Chase-Lev ثنائي الاتجاه ، وهو غير مناسب للتخطيط لمهام غير متزامنة مستقلة للأسباب الموضحة أدناه.
ثالثا ، تبين أن التنفيذ معقد للغاية. هذا يرجع جزئيًا إلى حقيقة أن هذا كان أول برنامج جدولة للمهمة. بالإضافة إلى ذلك ، كنت صبورًا جدًا عند استخدام الذرات في الفروع ، حيث كان من الممكن أن يكون المزيف جيدًا. درس مهم هو أنه في كثير من الأحيان يكون المزاح الذي يعمل بشكل أفضل.
وأخيراً ، كان هناك العديد من العيوب الطفيفة في التنفيذ الأولي. في السنوات الأولى ، تطورت تفاصيل تطبيق نموذج Rust غير المتزامن بشكل كبير ، لكن المكتبات أبقت API مستقرًا طوال الوقت. هذا أدى إلى تراكم بعض الديون الفنية.
والآن تقترب Tokio من الإصدار الأول الأول - ويمكننا سداد كل هذا الدين ، بالإضافة إلى التعلم من الخبرة المكتسبة على مدار سنوات التطوير. هذا وقت مثير!
الجيل القادم Tokio جدولة
حان الوقت الآن لإلقاء نظرة فاحصة على ما تغير في برنامج الجدولة الجديد.
نظام مهمة جديد
أولاً ، من المهم تسليط الضوء على ما
لا يمثل جزءًا من Tokio ، ولكنه ضروري من حيث تحسين الكفاءة: هذا
نظام جديد من المهام في
std ، تم تطويره أصلاً بواسطة
Taylor Kramer . يوفر هذا النظام الخطافات التي يجب أن يقوم المجدول بتنفيذها لتنفيذ مهام Rust غير متزامنة ، وقد تم تصميم النظام وتنفيذه بشكل رائع حقًا. انها أخف وزنا وأكثر مرونة من التكرار السابق.
تشير بنية
Waker من المصادر إلى وجود مهمة
ممكنة يجب وضعها في قائمة انتظار المجدول. في نظام المهام الجديد ، هذا هيكل ذو مؤشرين ، في حين كان قبل ذلك أكبر بكثير. يعد تقليل الحجم مهمًا لتقليل الحمل
Waker لنسخ قيمة
Waker في أماكن مختلفة ،
Waker مساحة أقل في الهياكل ، مما يتيح لك ضغط البيانات الأكثر أهمية في سطر ذاكرة التخزين المؤقت. قام التصميم
vtable بعدد من التحسينات ، والتي سنناقشها لاحقًا.
اختيار أفضل خوارزمية قائمة الانتظار
قائمة انتظار التنفيذ في وسط المجدول. لذلك ، هذا هو المكون الأكثر أهمية لإصلاح. استخدم برنامج جدولة Tokio الأصلي
قائمة انتظار ذات اتجاه
متقاطع : تطبيق أحادي المصدر (منتج) والعديد من المستهلكين. يتم وضع المهمة في نهاية واحدة ، ويتم استرداد القيم من الطرف الآخر. في معظم الأوقات ، يقوم مؤشر الترابط "بدفع" القيم من نهاية قائمة الانتظار ، ولكن في بعض الأحيان تقطع مؤشرات الترابط الأخرى العمل ، وتؤدي العملية نفسها. يتم دعم قائمة الانتظار في اتجاهين من خلال مجموعة ومجموعة من الفهارس التي تتبع الرأس والذيل. عند امتلاء قائمة الانتظار ، يؤدي إدخالها إلى زيادة في مساحة التخزين. يتم تخصيص صفيف جديد أكبر ، ويتم نقل القيم إلى وحدة التخزين الجديدة.
يتم تحقيق القدرة على النمو من خلال التعقيد والنفقات العامة. يجب أن تأخذ عمليات Push / pop هذا النمو في الاعتبار. بالإضافة إلى ذلك ، فإن تحرير المجموعة الأصلية محفوف بالمصاعب الإضافية. في لغة مجموعة البيانات المهملة (GC) ، ستنتقل المصفوفة القديمة عن نطاقها وفي النهاية ستقوم المجموعة بمسحها. ومع ذلك ، السفن الصدأ دون GC. هذا يعني أننا أنفسنا مسؤولون عن تحرير الصفيف ، لكن يمكن أن تحاول الخيوط الوصول إلى الذاكرة في نفس الوقت. لحل هذه المشكلة ، يستخدم crossbeam استراتيجية استصلاح تستند إلى عصر. على الرغم من أنها لا تتطلب الكثير من الموارد ، إلا أنها تضيف النفقات العامة غير التافهة إلى المسار الرئيسي (المسار السريع). يجب أن تقوم كل عملية الآن بتنفيذ عمليات RMW (قراءة-تعديل-كتابة) ذرية عند مدخل وخروج الأقسام الحرجة للإشارة إلى مؤشرات ترابط أخرى أن الذاكرة قيد الاستخدام ولا يمكن محوها.
بسبب النفقات العامة لنمو قائمة انتظار التنفيذ ، فمن المنطقي أن نفكر: هل دعم هذا النمو ضروري حقًا؟ هذا السؤال دفعني في النهاية إلى إعادة كتابة المخطط. تتمثل الإستراتيجية الجديدة في الحصول على حجم قائمة انتظار ثابت لكل عملية. عندما تكون قائمة الانتظار ممتلئة ، بدلاً من زيادة قائمة الانتظار المحلية ، تنتقل المهمة إلى قائمة الانتظار العالمية مع العديد من المستهلكين والعديد من المنتجين. ستقوم المعالجات بالتحقق من قائمة الانتظار العالمية هذه بشكل دوري ، ولكن بتردد أقل بكثير من التردد المحلي.
كجزء من إحدى التجارب الأولى ،
استبدلنا crossbeam بـ
mpmc . لم يؤد ذلك إلى تحسن كبير بسبب مقدار التزامن للضغط والضغط. المفتاح لالتقاط العمل هو عدم وجود منافسة في قوائم الانتظار قيد التحميل تقريبًا ، لأن كل معالج لا يصل إلا إلى قائمة الانتظار الخاصة به.
في هذه المرحلة ، قررت دراسة مصادر Go بعناية - ووجدت أنها تستخدم حجم قائمة انتظار ثابت مع جهة تصنيع واحدة والعديد من المستهلكين ، مع الحد الأدنى من التزامن ، وهو أمر مثير للإعجاب للغاية. لتكييف الخوارزمية مع جدولة Tokio ، قمت ببعض التغييرات. من الجدير بالذكر أن تطبيق Go يستخدم عمليات ذرية متسلسلة (كما أفهمها). يقلل إصدار Tokio أيضًا من عدد من عمليات النسخ في فروع الأكواد النادرة.
تطبيق قائمة الانتظار هو مخزن مؤقت دائري يخزن القيم في صفيف. يتم تعقب رأس وقائمة الانتظار من خلال العمليات الذرية مع قيم عدد صحيح.
struct Queue {
يتم تنفيذ قائمة انتظار بواسطة مؤشر ترابط واحد:
loop { let head = self.head.load(Acquire);
لاحظ أنه في وظيفة
push هذه ، يتم تحميل العمليات الذرية الوحيدة مع
Acquire الطلب وحفظها مع ترتيب
Release . لا توجد عمليات RMW (
compare_and_swap ،
fetch_and ...) أو ترتيب تسلسلي ، كما كان من قبل. هذا أمر مهم لأنه على x86 رقائق جميع التنزيلات / يحفظ بالفعل "الذرية". وبالتالي ، على مستوى وحدة المعالجة المركزية ،
لن تتم مزامنة هذه الوظيفة . ستمنع العمليات الذرية بعض التحسينات في المترجم ، لكن هذا كله. على الأرجح ، يمكن إجراء عملية
load الأولى بأمان مع طلب
Relaxed ، لكن الاستبدال لا يحمل أي تكاليف ملحوظة.
عند امتلاء قائمة الانتظار ، يتم
push_overflow .
تنقل هذه الوظيفة نصف المهام من قائمة انتظار محلية إلى قائمة انتظار عمومية. قائمة الانتظار العالمية هي قائمة تدخلية محمية بواسطة كائن مزامنة. عند الانتقال إلى قائمة الانتظار العمومية ، يتم ربط المهام أولاً معًا ، ثم يتم إنشاء كائن مزامنة ، ويتم إدراج جميع المهام عن طريق تحديث المؤشر إلى ذيل قائمة الانتظار العمومية. هذا يحفظ حجم صغير قسم بالغ الأهمية.إذا كنت على دراية بتفاصيل ترتيب الذاكرة الذرية ، فقد تلاحظ "مشكلة" محتملة في الوظيفة الموضحة أعلاه push. عملية loadالترتيب الذري Acquireضعيفة إلى حد ما. يمكن أن يعرض قيمًا قديمة ، أي أن عملية الالتقاط المتوازية قد تزيد القيمة بالفعل self.head، ولكن في ذاكرة التخزين المؤقت للتيارpushستبقى القيمة القديمة ، لذلك لن تلاحظ عملية الالتقاط. هذه ليست مشكلة في صحة الخوارزمية. بالطريقة الرئيسية (السريعة) ، pushنهتم فقط بما إذا كانت قائمة الانتظار المحلية ممتلئة أم لا. نظرًا لأن الخيط الحالي فقط يمكنه دفع قائمة الانتظار ، فإن العملية القديمة loadستجعل قائمة الانتظار تبدو كاملة أكثر مما هي عليه بالفعل. قد تحدد بشكل غير صحيح أن قائمة الانتظار ممتلئة وسبب push_overflow، ولكن هذه الوظيفة تتضمن عملية ذرية أقوى. إذا push_overflowحدد أن قائمة الانتظار ليست ممتلئة فعليًا ، فتُرجع w / Err، pushوتبدأ العملية من جديد. هذا سبب آخرpush_overflowينقل نصف قائمة انتظار التنفيذ إلى قائمة الانتظار العالمية. بعد هذه الحركة ، تحدث هذه الإيجابيات الخاطئة بشكل أقل تواترا.يتم تطبيق محلي pop(من المعالج الذي تنتمي إليه قائمة الانتظار) ببساطة: loop { let head = self.head.load(Acquire);
في هذه الوظيفة، القميص واحد loadواحد compare_and_swapمع Release. النفقات العامة الرئيسية تأتي من compare_and_swap. تشبهالوظيفة ، ولكن يجب نقل الحمولة الذرية من . بالإضافة إلى ذلك ، بالمثل ، تحاول العملية التظاهر بأنها نصف قائمة الانتظار بدلاً من مهمة واحدة. هذا له تأثير جيد على الأداء ، والذي سنناقشه لاحقًا.stealpopself.tailpush_overflowstealالجزء الأخير المفقود هو تحليل قائمة الانتظار العالمية ، التي تتلقى المهام التي تجاوزت قوائم الانتظار المحلية ، وكذلك لنقل المهام إلى المجدول من مؤشرات الترابط غير المعالج. إذا كان المعالج قيد التحميل ، فهناك مهام في قائمة الانتظار المحلية ، سيحاول المعالج سحب المهام من قائمة الانتظار العالمية بعد حوالي 60 مهمة في قائمة الانتظار المحلية. يتحقق أيضًا من قائمة الانتظار العمومية عندما يكون في حالة "البحث" الموضحة أدناه.تبسيط قوالب الرسائل
تتكون تطبيقات Tokio عادةً من العديد من المهام المستقلة الصغيرة. يتفاعلون مع بعضهم البعض من خلال الرسائل. يشبه هذا القالب اللغات الأخرى مثل Go و Erlang. بالنظر إلى مدى شيوع القالب ، فمن المنطقي للمخطط تحسينه.افترض أنه تم إعطاء المهام A و B. المهمة الآن هي تنفيذ وإرسال رسالة إلى المهمة B عبر قناة الإرسال. القناة هي مورد تم تأمين المهمة B عليه حاليًا ، وبالتالي فإن إجراء إرسال رسالة سيتسبب في انتقال المهمة B إلى حالة قابلة للتنفيذ - وسيتم وضعها في قائمة انتظار التنفيذ للمعالج الحالي. بعد ذلك سوف يستنتج المعالج المهمة التالية من قائمة انتظار التنفيذ ، وينفذها ، ويكرر هذه الدورة حتى تصل إلى المهمة ب.المشكلة هي أنه قد يكون هناك تأخير كبير بين إرسال رسالة وإكمال المهمة ب. بالإضافة إلى ذلك ، يتم تخزين البيانات الساخنة ، مثل الرسالة ، في ذاكرة التخزين المؤقت لوحدة المعالجة المركزية ، ولكن بحلول الوقت الذي يتم فيه إنجاز المهمة ، من المحتمل أن يتم مسح ذاكرات التخزين المؤقت المقابلة.لحل هذه المشكلة ، يقوم برنامج جدولة Tokio الجديد بتنفيذ التحسين (كما في جدولة Go و Kotlin). عندما تنتقل المهمة إلى حالة قابلة للتنفيذ ، لا يتم وضعها في نهاية قائمة الانتظار ، ولكن يتم تخزينها في فتحة "المهمة التالية" الخاصة. يتحقق المعالج دائمًا من هذه الفتحة قبل التحقق من قائمة الانتظار. إذا كانت هناك مهمة قديمة بالفعل عند الإدراج في الفتحة ، فسيتم حذفها من الفتحة وتتحرك إلى نهاية قائمة الانتظار. وبالتالي ، سيتم الانتهاء من مهمة إرسال رسالة مع أي تأخير تقريبا.
القبض على خنق
في جدولة التقاط الوظيفة ، إذا كانت قائمة انتظار تنفيذ المعالج فارغة ، يحاول المعالج التقاط المهام من وحدات المعالجة المركزية النظيرة. أولاً ، يتم تحديد وحدة المعالجة المركزية النظيرة العشوائية ، إذا لم يتم العثور على مهام لها ، فسيتم البحث عن الوحدة التالية ، وهكذا ، حتى يتم العثور على المهام.في الممارسة العملية ، غالبًا ما تنتهي عدة معالجات من معالجة قائمة انتظار التنفيذ في نفس الوقت تقريبًا. يحدث هذا عندما تصل حزمة العمل (على سبيل المثال ، متىepollشملهم الاستطلاع من أجل استعداد المقبس). تستيقظ المعالجات ، وتلقي المهام ، وبدء تشغيلها وإكمالها. يؤدي هذا إلى حقيقة أن جميع المعالجات تحاول في وقت واحد التقاط مهام الآخرين ، أي أن العديد من مؤشرات الترابط تحاول الوصول إلى قوائم الانتظار نفسها. هناك صراع. يساعد الاختيار العشوائي لنقطة البداية في تقليل المنافسة ، لكن الوضع لا يزال غير جيد للغاية.لحل هذه المشكلة، يحد جدولة جديدة عدد المعالجات المتوازية التي تؤدي عمليات الالتقاط. نسمي حالة المعالج الذي يحاول فيه التقاط مهام الآخرين "البحث عن وظيفة" أو "البحث" عن الاختصار (المزيد عن ذلك لاحقًا). يتم إجراء هذا التحسين باستخدام القيمة الذريةint، مما يزيد المعالج قبل بدء البحث وينخفض عند الخروج من حالة البحث. يمكن أن يكون أكبر عدد ممكن في حالة البحث هو نصف إجمالي عدد المعالجات. وهذا هو ، تم تعيين الحد التقريبي ، وهذا أمر طبيعي. نحن لسنا بحاجة إلى حد صارم لعدد وحدات المعالجة المركزية (CPU) في البحث ، فقط اختناق. نحن نضحي بالدقة من أجل كفاءة الخوارزمية.بعد الدخول في حالة البحث ، يحاول المعالج التقاط العمل من وحدات المعالجة المركزية النظيرة والتحقق من قائمة الانتظار العالمية.تقليل التزامن بين المواضيع
جزء مهم آخر من برنامج الجدولة هو إعلام وحدات المعالجة المركزية النظيرة بمهام جديدة. إذا كان "الأخ" نائماً ، يستيقظ ويلتقط المهام. تلعب الإخطارات دورًا مهمًا آخر. تذكر أن خوارزمية قائمة الانتظار تستخدم ترتيبًا ذريًا ضعيفًا ( Acquire/ Release). بسبب التخصيص الذري للذاكرة ، ليس هناك ما يضمن أن معالج النظير سيرى المهام في قائمة الانتظار بدون تزامن إضافي. لذلك ، الإخطارات هي المسؤولة عن ذلك أيضا. لهذا السبب ، تصبح الإخطارات باهظة الثمن. الهدف هو تقليل عددهم حتى لا يستخدم موارد وحدة المعالجة المركزية ، أي أن المعالج له مهام ولا يستطيع الأخ أن يسرقها. عدد كبير من الإخطارات يؤدي إلى مشكلة القطيع الرعد .اتخذ مخطط Tokio الأصلي مقاربة ساذجة للإشعارات. كلما وضعت مهمة جديدة في قائمة انتظار التنفيذ ، تلقى المعالج إشعارًا. كلما تم إخطار وحدة المعالجة المركزية ورأيت المهمة بعد الاستيقاظ ، أبلغت وحدة المعالجة المركزية آخر. أدى هذا المنطق بسرعة كبيرة إلى استيقاظ جميع المعالجات والبحث عن عمل (مما تسبب في حدوث تعارض). في أغلب الأحيان ، لم يجد معظم المعالجات عملاً وناموا مجددًا.قام المجدول الجديد بتحسين هذا النمط بشكل كبير ، على غرار برنامج جدولة الذهاب. يتم إرسال الإشعارات كما كان من قبل ، ولكن فقط في حالة عدم وجود وحدة المعالجة المركزية في حالة البحث (انظر القسم السابق). عندما يتلقى المعالج إشعارًا ، فإنه يدخل حالة البحث على الفور. عندما يعثر المعالج في حالة البحث على مهام جديدة ، فإنه يترك حالة البحث أولاً ثم يخطر المعالج الآخر.يحد هذا المنطق من السرعة التي تستيقظ بها المعالجات. إذا تم التخطيط لحزمة مهمة كاملة على الفور (على سبيل المثال ، متىepollتم استطلاع الرأي لمعرفة مدى استعداد المقبس) ، ثم ستؤدي المهمة الأولى إلى إخطار المعالج. هو الآن في حالة بحث. لن تقوم المهام المجدولة المتبقية في الحزمة بإخطار المعالج ، نظرًا لوجود وحدة المعالجة المركزية واحدة على الأقل في حالة البحث. سيقوم هذا المعالج الذي تم إخطاره بالتقاط نصف المهام في المجموعة ، ويقوم بدوره بإخطار المعالج الآخر. يستيقظ معالج ثالث ، ويجد مهام أحد المعالجات الأولى والثانية ويلتقط نصفها. وهذا يؤدي إلى زيادة سلسة في عدد وحدات المعالجة المركزية (CPU) العاملة ، بالإضافة إلى موازنة التحميل السريعة.تقليل تخصيص الذاكرة
يتطلب برنامج جدولة Tokio الجديد تخصيص ذاكرة واحدة فقط لكل مهمة تم إنتاجها ، بينما تتطلب المهمة القديمة اثنين. في السابق ، بدا هيكل المهمة بشيء من هذا القبيل: struct Task {
Taskكما سيتم تسليط الضوء على الهيكل Box. لفترة طويلة جدًا ، أردت إصلاح هذا المفصل (حاولت لأول مرة عام 2014). لقد تغير شيئان منذ مخطط Tokio القديم. أولا ، استقر std::alloc. ثانياً ، تحول نظام المهام في المستقبل إلى استراتيجية vtable صريحة . كان هذان الشيئان هما المفقودان ، أخيرًا ، للتخلص من التخصيص غير الفعال للذاكرة المزدوجة لكل مهمة.الآن Taskيتم تقديم الهيكل في النموذج التالي: struct Task<T> { header: Header, future: T, trailer: Trailer, }
للمهام ضرورية و Headerو Trailer، ولكنها تنقسم بين البيانات "الساخنة" (الرأس) و "البرد" (الذيل)، م. E. تقريبا بين البيانات الوصول إليها بشكل متكرر، وتلك التي نادرا ما تستخدم. يتم وضع البيانات "الساخنة" على رأس الهيكل وتخزينها بأقل قدر ممكن. عندما يقوم المعالج بإلغاء تحديد مؤشر المهمة ، يقوم على الفور بتحميل خط ذاكرة التخزين المؤقت (من 64 إلى 128 بايت). نريد أن تكون هذه البيانات وثيقة الصلة قدر الإمكان.انخفاض عدد الروابط الذرية
التحسين الأخير الذي نناقشه في هذه المقالة هو تقليل عدد الروابط الذرية. هناك العديد من الإشارات إلى بنية المهمة ، بما في ذلك من المجدول ومن كل مستيقظ. الاستراتيجية العامة لإدارة هذه الذاكرة هي حساب الارتباط الذري . تتطلب هذه الاستراتيجية إجراء عملية ذرية في كل مرة يتم فيها استنساخ الرابط وفي كل مرة يتم فيها حذف الارتباط. عندما يخرج الرابط الأخير عن نطاقه ، يتم تحرير الذاكرة.في برنامج جدولة Tokio القديم ، احتوى كل من المجدول وكل المهتمين على رابط إلى واصف المهمة ، تقريبًا: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
عندما تستيقظ المهمة ، يتم استنساخ الرابط (تحدث زيادة ذرية). ثم يتم وضع الرابط في قائمة انتظار التنفيذ. عندما يتلقى المعالج المهمة ويكمل تنفيذها ، يتجاهل الارتباط ، مما يؤدي إلى الخفض الذري. هذه العمليات الذرية (الزيادة والنقصان) تضيف ما يصل.تم تحديد هذه المشكلة مسبقًا بواسطة مطوري نظام المهمة std::future. لاحظوا أنه عند الاتصال ، لم تعد هناك حاجة Waker::wakeإلى الرابط الأصلي waker. يتيح لك ذلك إعادة استخدام عداد الارتباط الذري عند نقل مهمة إلى قائمة انتظار التنفيذ. يشتمل نظام المهمة std::futureالآن على مكالمات API اثنين "للاستيقاظ":مثل هذا البناء API يجعلنا استخدامه عند الاتصال wake، وتجنب الزيادة الذرية. يصبح التنفيذ مثل هذا: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
يؤدي ذلك إلى تجنب الحمل الإضافي للتعدادات الإضافية للارتباط فقط إذا كان بإمكانك تحمل مسؤولية الاستيقاظ. في تجربتي ، بدلاً من ذلك ، يُنصح دائمًا بالاستيقاظ دائمًا &self. الصحوة selfتمنع إعادة استخدام المستيقظ (مفيد في الحالات التي يرسل فيها المورد الكثير من القيم ، مثل القنوات والمآخذ ...). أيضًا في حالة أنه selfمن الصعب تطبيق الاستيقاظ الآمن للخيط (سنترك التفاصيل لمقال آخر).يحل المخطط الجديد مشكلة "الاستيقاظ self" من خلال تجنب الزيادة الذرية wake_by_ref، مما يجعلها فعالة مثلwake(self). للقيام بذلك ، يحتفظ المجدول بقائمة بجميع المهام النشطة حاليًا (لم تكتمل بعد). تمثل القائمة عداد المرجع اللازم لإرسال المهمة إلى قائمة انتظار التنفيذ.يكمن تعقيد هذا التحسين في حقيقة أن المجدول لن يزيل المهام من قائمته حتى يتلقى ضمانًا بأن المهمة ستوضع في قائمة انتظار التنفيذ مرة أخرى. تفاصيل تنفيذ هذا المخطط خارج نطاق هذه المقالة ، لكنني أوصي بشدة أن تنظر إلى المصدر.تزامن غامق (غير آمن) مع Loom
من الصعب جدًا كتابة الرمز الصحيح الموازي بدون أقفال. من الأفضل العمل ببطء ، ولكن بشكل صحيح ، بدلاً من العمل بسرعة ، ولكن مع الأخطاء ، خاصةً إذا كانت الأخطاء تتعلق بأمان الذاكرة. أفضل خيار ، ومع ذلك ، يجب أن تعمل بسرعة ودون أخطاء. جعلت المجدول الجديد بعض التحسينات العدوانية إلى حد ما وأنه يتجنب معظم أنواع stdمن أجل التخصص. بشكل عام ، هناك الكثير من التعليمات البرمجية غير الآمنة فيه unsafe.هناك عدة طرق لاختبار الرمز الموازي. أحدها هو أن يقوم المستخدمون باختبار الأخطاء وتصحيحها بدلاً منك (خيار جذاب ، هذا أمر مؤكد). آخر هو كتابة اختبارات الوحدة التي تعمل في حلقة ويمكن أن تلحق خطأ. ربما حتى استخدام TSAN. بالطبع ، إذا وجد خطأً ، فلا يمكن استنساخه بسهولة دون إعادة تشغيل دورة الاختبار. أيضا ، كم من الوقت تستغرق هذه الدورة؟ عشر ثوان؟ عشر دقائق؟ عشرة ايام؟ في السابق ، كان عليك اختبار الرمز الموازي في Rust.وجدنا هذا الوضع غير مقبول. عندما نصدر الشفرة ، نريد أن نشعر بالثقة (قدر الإمكان) ، خاصة في حالة الكود الموازي بدون أقفال. يحتاج مستخدمي Tokio إلى الموثوقية.لذلك ، قمنا بتطوير Loom : أداة لاختبار التقليب للرمز الموازي. تتم كتابة الاختبارات كالمعتاد ، ولكنloomسيتم تشغيلها عدة مرات ، وإعادة ترتيب جميع الخيارات الممكنة للتنفيذ والسلوك التي قد يواجهها الاختبار في بيئة التدفق. كما يتحقق أيضًا من الوصول الصحيح للذاكرة ، وتحرير الذاكرة ، وما إلى ذلك.وكمثال على ذلك ، إليك اختبار تلوح في الأفق لجدولة جديدة: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
يبدو الأمر طبيعيًا جدًا ، لكن هناك جزءًا من الكود في كتلة ما loom::modelيعمل عدة آلاف من المرات (ربما الملايين) ، في كل مرة مع تغيير بسيط في السلوك. كل شوط يغير الترتيب الدقيق للخيوط. بالإضافة إلى ذلك ، لكل عملية ذرية ، يحاول المنوال كل السلوكيات المختلفة المسموح بها في طراز الذاكرة C ++ 11. تذكر أن العبء الذري Acquireكان ضعيفًا إلى حد ما ويمكن أن يُرجع قيمًا قديمة. loomسيحاول الاختبار جميع القيم الممكنة التي يمكن تحميلها.loomأصبحت أداة لا تقدر بثمن في تطوير مخطط جديد. لقد اكتشف أكثر من عشرة أخطاء نجحت في اجتياز جميع اختبارات الوحدة والاختبار اليدوي واختبار الحمل.قد يشك القارئ المميز في أن المنوال يتحقق من "كل التباديل الممكنة" ، وسيكون على صواب. التباديل الساذج سيؤدي إلى انفجار اندماجي. أي اختبار غير تافهة لن ينتهي أبدا. تمت دراسة هذه المشكلة لسنوات عديدة ، وتم تطوير عدد من الخوارزميات لمنع حدوث انفجار اندماجي. تلوح في الأفق الأساسية خوارزمية على أساس الحد ديناميكية مع ترتيب جزئي (حيوي تخفيض جزئي النظام). هذه الخوارزمية تزيل التباديل التي تؤدي إلى نفس النتيجة. لكن لا يزال بإمكان مساحة الدولة أن تنمو إلى هذا الحجم بحيث لن تتم معالجتها في فترة زمنية معقولة (عدة دقائق). يسمح لك Loom بتقييده أكثر باستخدام الحد الديناميكي من خلال طلب جزئي.بشكل عام، وذلك بفضل اختبارات مكثفة باستخدام المنوال أنا الآن الكثير أكثر ثقة في صحة المجدول.النتائج
لذلك ، نظرنا في ماهية المجدولين وكيف حقق برنامج جدولة Tokio الجديد زيادة هائلة في الأداء ... ولكن أي نوع من النمو؟ بالنظر إلى أن المجدول الجديد قد تم تطويره فقط ، في العالم الحقيقي لم يتم اختباره بالكامل. هنا ما نعرفه.أولاً ، جدولة جديدة أسرع بكثير في المعايير الجزئية:مخطط قديم
test chained_spawn ... bench: 2،019،796 ns / iter (+/- 302،168)
اختبار ping_pong ... bench: 1،279،948 ns / iter (+/- 154،365)
اختبار تفرخ ... مقعد: 10،283،608 نانومتر / iter (+/- 1،284،275)
اختبار العائد ... مقعد: 21،450،748 ns / iter (+/- 1،201،337)
مخطط جديد
test chained_spawn ... bench: 168،854 ns / iter (+/- 8،339)
اختبار ping_pong ... bench: 562،659 ns / iter (+/- 34،410)
اختبار تفرخ ... مقعد: 7،320،737 ns / iter (+/- 264،620)
اختبار العائد ... مقاعد البدلاء: 14،638،563 ns / iter (+/- 1،573،678)
يتضمن هذا المعيار ما يلي:chained_spawn تفرخ مهام جديدة بشكل متكرر ، أي إنشاء مهمة تنشئ مهمة أخرى ، والتي تنشئ مهمة أيضًا ، إلخ.
ping_pongيختار قناة oneshotويولد مهمة ترسل رسالة على تلك القناة. المهمة الأصلية تنتظر رسالة. هذا هو الاختبار الأقرب إلى "العالم الحقيقي".
spawn_many يتحقق من تنفيذ المهام في المجدول ، أي يولد المهام من خارج سياقها.
yield_many يتحقق من مهمة الصحوة المستقلة.
الفرق في المعايير مثير للإعجاب للغاية. ولكن كيف سينعكس هذا في "العالم الحقيقي"؟ من الصعب القول بالتأكيد ، لكنني حاولت تشغيل معايير Hyper .هنا هو أبسط خادم Hyper ، الذي يتم قياس أدائه باستخدام wrk -t1 -c50 -d10:مخطط قديم
تشغيل اختبار 10s @ http://127.0.0.1 {000
1 المواضيع و 50 اتصالات
إحصائيات الموضوع متوسط Stdev Max +/- Stdev
زمن الوصول 371.53us 99.05us 1.97ms 60.53٪
Req / Sec 114.61k 8.45k 133.85k 67.00٪
1139307 طلبات في 10.00s ، قراءة 95.61 ميغابايت
الطلبات / ثانية: 113923.19
نقل / ثانية: 9.56MB مخطط جديد
تشغيل اختبار 10s @ http://127.0.0.1 {000
1 المواضيع و 50 اتصالات
إحصائيات الموضوع متوسط Stdev Max +/- Stdev
الكمون 275.05us 69.81us 1.09ms 73.57٪
Req / Sec 153.17k 10.68k 171.51k 71.00٪
طلبات 1522671 في 10.00s ، قراءة 127.79 ميغابايت
الطلبات / ثانية: 152258.70
نقل / ثانية: 12.78MB نرى زيادة بنسبة 34 ٪ في الطلبات في الثانية فقط بعد تغيير المجدول! في المرة الأولى التي رأيتها فيها ، كنت سعيدًا جدًا ، لأنني كنت أتوقع زيادة بحد أقصى 5-10 ٪. لكنني شعرت بالحزن ، لأن هذه النتيجة أظهرت أيضًا أن برنامج جدولة Tokio القديم ليس جيدًا. ثم تذكرت أن Hyper بالفعل رائد في تصنيفات TechEmpower . من المثير للاهتمام أن نرى كيف سيؤثر المخطط الجديد على التصنيفات.Tonic ، عميل وخادم gRPC ، مع تسريع المجدول الجديد بنسبة 10 ٪ ، وهو أمر مثير للإعجاب للغاية بالنظر إلى أن تونيك لم يتم تحسينه بالكامل بعد.استنتاج
أنا سعيد جدًا بإكمال هذا المشروع أخيرًا بعد عدة أشهر من العمل. هذا هو تحسن كبير في I / O غير متزامن الصدأ. أنا سعيد للغاية بالتحسينات التي تمت. لا يزال هناك مجال كبير للتحسين في كود Tokio ، لذلك لم ننته بعد من تحسين الأداء.آمل أن تكون المادة الموجودة في المقالة مفيدة للزملاء الذين يحاولون كتابة برنامج جدولة المهام.