
مرحبا يا هبر! نواصل نشر مراجعات المقالات العلمية من أعضاء مجتمع Open Data Science من القناة #article_essense. إذا كنت ترغب في الحصول عليها قبل أي شخص آخر - انضم إلى المجتمع !
مقالات لهذا اليوم:
- دوران الطبقة: مؤشر قوي بشكل مدهش للتعميم في الشبكات العميقة؟ (الجامعة الكاثوليكية في لوفان ، بلجيكا ، 2018)
- المعلمة - كفاءة نقل التعلم ل NLP (جوجل البحوث ، جامعة Jagiellonian ، 2019)
- RoBERTa: منهج تدريبي بيرت الأمثل بقوة (جامعة واشنطن ، Facebook AI ، 2019)
- EfficientNet: إعادة التفكير في توسيع نطاق نموذج الشبكات العصبية التلافيفية (Google Research، 2019)
- كيف ينتقل المخ من الإدراك إلى الإدراك الحسي (الولايات المتحدة الأمريكية ، الأرجنتين ، إسبانيا ، 2019)
- طبقات ذاكرة كبيرة مع مفاتيح المنتج (Facebook AI Research، 2019)
- هل نحن حقًا نحرز الكثير من التقدم؟ تحليل مقلق لنهج التوصية العصبية الحديثة (بوليتنيكو دي ميلانو ، جامعة كلاغنفورت ، 2019)
- Omni-Scale Feature Learning for Re-Identification (جامعة سوري ، جامعة كوين ماري ، Samsung AI ، 2019)
- إعادة القياس العصبي تعمل على تحسين التحسين الهيكلي (Google Research، 2019)
روابط للمجموعات السابقة من السلسلة: 1. دوران الطبقة: مؤشر قوي بشكل مدهش من التعميم في الشبكات العميقة؟
المؤلفون: سيمون كاربونيل ، كريستوف دي فليشوير (جامعة الكاثوليك في لوفان ، بلجيكا ، 2018)
→ المادة الأصلية
مؤلف المراجعة: Svyatoslav Skoblov (في error_derivative الركود)

في هذه المقالة ، لفت المؤلفون الانتباه إلى ملاحظة بسيطة إلى حد ما: مسافة جيب التمام بين أوزان الطبقة أثناء التهيئة وبعد التدريب (تسمى عملية زيادة المسافة أثناء التدريب دوران الطبقة). يقول السادة أنه في معظم التجارب ، تكون الشبكات التي وصلت إلى مسافة واحدة في جميع الطبقات متفوقة باستمرار في التكوينات الأخرى. تعرض الورقة أيضًا خوارزمية Layca (مقدار التحكم في مستوى الدوران للوزن من الدوران) ، والذي يسمح باستخدام معدل التعلم الحكيم للطبقة هذا للتحكم في نفس دوران الطبقة. في الواقع ، فهو يختلف عن خوارزمية SGD المعتادة بوجود الإسقاط المتعامد والتطبيع. يمكن الاطلاع على قائمة مفصلة بالخوارزمية إلى جانب مخطط التدريب في المقالة.
الفكرة الرئيسية التي يستنتجها المؤلفون هي: كلما كانت دوران الطبقة أكبر ، كان أداء التعميم أفضل . معظم المقال عبارة عن سجل للتجارب التي تمت فيها دراسة سيناريوهات تدريب مختلفة: MNIST ، CIFAR-10 / CIFAR-100 ، تم استخدام ImageNet الصغير مع أبنية مختلفة ، من شبكة طبقة واحدة إلى عائلة ResNet.
تم تقسيم سلسلة من التجارب إلى عدة مراحل:
- Vanilla SGD اتضح أن سلوك المقاييس يتطابق بشكل عام مع الفرضية (التغيرات الكبيرة في المسافة تقابل أفضل القيم المترية) ، ومع ذلك ، فقد لوحظت مشاكل أيضًا: توقف دوران الطبقة قبل وقت طويل من القيم المطلوبة ؛ كما لوحظ عدم الاستقرار في تغيير المسافة.
- SGD + تدهور الوزن أدى تقليل معيار الوزن إلى تحسين صورة التدريب بشكل كبير: وصلت معظم الطبقات إلى الحد الأقصى للمسافة ، وأداء الاختبار مشابه لـ Layca المقترح. الميزة غير المؤكدة لطريقة المؤلف هي عدم وجود معلمة تشعبية إضافية.
- الاحترار LR اتضح أن الاحماء يساعد SGD على التغلب على مشكلة تدوير الطبقة غير المستقرة ، ومع ذلك ، فإنه ليس له أي تأثير على Layca.
- أساليب التدرج التكيفي بالإضافة إلى الحقيقة المعروفة (أنه باستخدام هذه الطرق يصعب تحقيق مستوى التعميم الذي يمكن أن يوفره تسوس SGD + لتخفيف الوزن) ، اتضح أن تأثيرات تدوير الطبقة مختلفة تمامًا: أول زيادة الدوران في الطبقات الأخيرة ، بينما SGD في الطبقات الأولية . يلمح المؤلفون إلى أن هذا قد يكون معنى الأساليب التكيفية. ويقترحون استخدام Layca بالتزامن معهم (تحسين القدرة على التعميم في الأساليب التكيفية وتسريع التعلم في SGD).
تختتم المقالة بمحاولة لتفسير هذه الظاهرة. للقيام بذلك ، قام المؤلفون بتدريب شبكة ذات طبقة مخفية على نسخة مجردة من MNIST ، وبعد ذلك قاموا بتصور الخلايا العصبية العشوائية ، وتوصلوا إلى استنتاج منطقي تمامًا: درجة أكبر من دوران الطبقة يتوافق مع تأثير أقل للتهيئة ودراسة أفضل للميزات ، مما يساهم في تحسين التعميم.
يتم تحميل رمز الخوارزمية المنفذة (tf / keras) ورمز إعادة إنتاج التجارب.
2. معلمة نقل كفاءة التعلم ل NLP
مؤلفو المقالات: نيل هولسبي ، وأندريه جيورجيو ، وستانيسلو جاسترزيبسكي ، وبرونا مورون ، وكوينتين دي لاروسيله ، وأندريا جيسموندو ، ومون أتاريان ، وسيلفان جيليلي (Google Research ، جامعة جاجيلونيان ، 2019)
→ المادة الأصلية
مؤلف المراجعة: أليكسي كارناتشيف (في سلاك زرزلي)
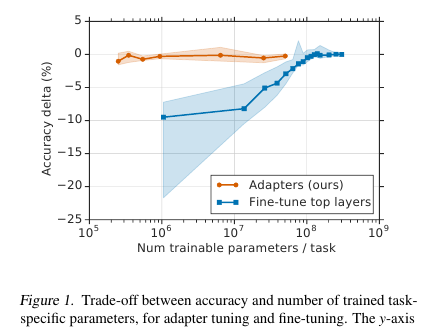
يقدم السادة هنا تقنية بسيطة ولكنها فعالة لضبط نماذج البرمجة اللغوية العصبية (في هذه الحالة ، بيرت). تتمثل الفكرة في تضمين طبقات التعلم (المحولات) مباشرةً في الشبكة. كل طبقة من هذه الطبقات هي عبارة عن شبكة ذات عنق الزجاجة ، والتي تتكيف مع الحالات الكامنة للنموذج الأصلي إلى مهمة محددة من المستوى الأدنى. تبقى أوزان النموذج الأصلي ، بدورها ، مجمدة.
حافز
في ظروف التدريب على البث المباشر (أو التدريب القريب من الإنترنت) ، حيث توجد الكثير من مهام البث المباشر ، لا أريد حقًا تقديم النموذج بالكامل. أولاً ، لفترة طويلة ، وثانيا ، من الصعب ، وثالثًا ، حتى لو كان ضيقًا ، يجب تخزين النموذج بطريقة أو بأخرى: للتخلص من الذاكرة أو الاحتفاظ بها في الذاكرة. ولن نتمكن من إعادة استخدام هذا النموذج للمهمة التالية: في كل مرة يتعين علينا ضبطها بطريقة جديدة. نتيجة لذلك ، يمكننا محاولة تكييف حالات الشبكة المخفية مع المشكلة الحالية. علاوة على ذلك ، لا يزال النموذج الأصلي دون تغيير ، والمحولات نفسها أكثر رحيبًا بكثير من النموذج الرئيسي (~ 4٪ من إجمالي عدد المعلمات)
تطبيق
تم حل المشكلة بطريقة بسيطة بشكل لا يصدق: نضيف محوّلين إلى كل طبقة من النموذج. قبل تطبيع الطبقة في النماذج القائمة على المحولات ، يحدث تخطي الاتصال: تتم إضافة الإدخال المحول (الحالة المخفية الحالية) إلى الإدخال الأصلي.
يوجد قسمان من هذه الأقسام في كل طبقة من المحولات: أحدهما بعد انتباه الرؤوس المتعددة ، والثاني بعد التغذية للأمام. وبالتالي ، يتم تمرير الحالات المخفية لهذه الأقسام بشكل إضافي عبر المهايئ: شبكة ضحلة ذات طبقة مخفية عنق الزجاجة واحدة مع الإخراج بنفس البعد مثل الإدخال. يتم تطبيق اللاخطية على حالة عنق الزجاجة ، وتتم إضافة الإدخال (اتصال تخطي) إلى الإخراج. اتضح أن إجمالي عدد المعلمات المدربة هو: 2md + m + d ، حيث d هو بُعد الحالة المخفية للنموذج الأصلي ، m هو حجم طبقة محول عنق الزجاجة. اتضح أنه بالنسبة لطراز قاعدة BERT (12 طبقة ، 110M معلمات) وبالنسبة لحجم bottlneck'a 128 ، نحصل على 4.3 ٪ من إجمالي عدد المعلمات
النتائج
تم إجراء مقارنة مع ضبط النموذج الكامل. بالنسبة لجميع المهام ، أظهر هذا النهج خسارة طفيفة في المقاييس (في المتوسط أقل من نقطة واحدة) ، مع عدد الأوزان المدربة - 3 ٪ من المجموع. لن أدرج المهام بأنفسهم ، فهناك الكثير منهم ، وهناك لوحة في المقال.
ضبط غرامة
في هذا النموذج ، يتم ضبط جزء المحول فقط (+ مصنف المخرجات نفسه). بالنسبة لمقاييس المهايئ ، يقترحون إجراء تهيئة قرب الهوية. وبالتالي ، لن يغير النموذج غير المدرَّب حالات الشبكة المخفية بأي طريقة ، وهذا سيمكّن بالفعل في عملية تدريب النموذج على تحديد الحالات التي تتكيف مع المهمة وتغييرها دون تغيير.
معدل التعلم يوصي بأخذ أكثر مما هو الحال مع معيار بيرت. شخصيا ، في مهمتي ، 1e-04 lr عملت بشكل جيد. بالإضافة إلى ذلك ، (بالفعل شخصياً ملاحظتي) أثناء عملية الضبط ، ينفجر النموذج دائمًا في التدرجات اللونية ، لذلك عليك أن تتذكر القيام بعملية القطع. محسن - آدم مع الاحماء 10 ٪
قانون
تم إرفاق الكود في مقالتهم. التنفيذ على Tensorflow .
بالنسبة إلى Torch ، قام مؤلف مراجعة محولات pytorch forked بإضافة طبقة محول (في بداية ملف README.md يوجد دليل تشغيل صغير)
3. RoBERTa: منهج بيرت المُحسّن بقوة
مؤلفو المقال: يينهان ليو ، وميل أوت ، ونامان جويال ، وجينغفي دو ، وماندار جوشي ، ودانكي تشن ، وعمير ليفي ، ومايك لويس ، ولوك زيتليمويير ، وفيسيلين ستويانوف (جامعة واشنطن ، Facebook AI ، 2019)
→ المادة الأصلية
مؤلف المراجعة: Artem Rodichev (في slack fuckai)
رفع بشكل كبير جودة نماذج بيرت ، في المقام الأول على المتصدرين GLUE و SOTA في العديد من مهام البرمجة اللغوية العصبية. اقترحوا عددًا من الطرق لتدريب نموذج بيرت على أفضل وجه ممكن دون أي تغيير في بنية النموذج نفسه.
الاختلافات الرئيسية مع بيرت الأصلي:
- زيادة بناء القطار 10 مرات ، من 16 غيغابايت من النص الخام إلى 160 غيغابايت
- صنع اخفاء ديناميكي لكل عينة
- إزالة استخدام الجملة التالية التنبؤ الخسارة
- زيادة حجم الدفعة المصغرة من 256 عينة إلى 8 كيلو
- تحسين ترميز BPE عن طريق ترجمة قاعدة البيانات من Unicode إلى بايت.
تم تدريب أفضل طراز نهائي على 1024 بطاقة Nvidia V100 (128 خادم DGX-1) لمدة 5 أيام.
جوهر النهج:
البيانات. بالإضافة إلى أصداف ويكي و BookCorpus (16 جيجابايت في المجموع) ، التي علمت بيرت الأصلي ، أضافوا ثلاث قذائف أكبر ، كلها باللغة الإنجليزية:
- SS- أخبار 63 مليون الأخبار في 2.5 سنة على 76GB
- OpenWebText هو الإطار الذي تم من خلاله تعليم OpenAI نموذج GPT2. هذه هي المقالات التي تم الزحف إليها والتي تم تقديم الارتباطات إليها في المنشورات على reddit مع ثلاثة تحديثات على الأقل. 38 جيجابايت البيانات
- قصص - 31GB CommonCrawl قصة حالة
اخفاء ديناميكي. في BERT الأصلي ، يتم حجب 15٪ من الرموز في كل عينة ويتم توقع هذه الرموز باستخدام الجزء غير المقنع من التسلسل. يتم إنشاء قناع لكل عينة مرة واحدة أثناء المعالجة المسبقة ولا يتغير. في الوقت نفسه ، يمكن أن تحدث نفس العينة في القطار عدة مرات ، وهذا يتوقف على عدد العصور في الجسم. فكرة التقنيع الديناميكي هي إنشاء قناع جديد للتسلسل في كل مرة ، بدلاً من استخدام قناع ثابت في المعالجة المسبقة.
الهدف التالي الجملة التنبؤ. دعونا مجرد قطع هذا objektiv ومعرفة ما إذا كان ساءت؟ هل أصبح أفضل أو بقي أيضًا - في مهام SQuAD و MNLI و SST و RACE.
زيادة حجم الدفعة الصغيرة. في العديد من الأماكن ، لا سيما في الترجمة الآلية ، تبين أنه كلما كانت الدفعة الصغيرة أكبر ، كانت النتائج النهائية للقطار أفضل. لقد أظهروا أنه إذا قمت بزيادة الميكروباص من 256 عينة ، كما هو الحال في BERT الأصلي ، إلى 2k ، ثم إلى 8k ، فسوف تنخفض الحيرة عند التحقق من الصحة ، وتنمو المقاييس في MNLI و SST-2.
BPE. يستخدم BPE من تطبيق BERT الأصلي أحرف Unicode كأساس لوحدات الكلمات الأساسية. يؤدي هذا إلى حقيقة أنه في الحالات الكبيرة والمتنوعة ، سيتم احتلال جزء كبير من القاموس بواسطة أحرف Unicode فردية. اقترح OpenAI مرة أخرى في GPT2 استخدام أحرف Unicode ، ولكن البايتات كأساس للكلمات الفرعية. إذا استخدمنا قاموس BPE 50 كيلو بايت ، فلن يكون لدينا رموز غير معروفة. مقارنةً بـ BERT الأصلي ، نما حجم النموذج بمقدار 15 مليون معلمة للنموذج الأساسي وبنسبة 20 مليونًا للكبير ، أي 5-10٪ أكثر.
النتائج:
تستخدم BERT-large و XLNet-large كنماذج للمقارنة. RoBERTa هي نفسها في معايير BERT-large ، ونتيجة لذلك ، فقد فازوا بالمركز الأول في مؤشر GLUE. استخدمنا توليف الملفات أحادية المهمة ، على عكس العديد من الطرق الأخرى من قمة GLUE المعيارية التي تقوم بضبط ملفات متعددة المهام. على الفتيات في GLUE ، تتم مقارنة نتائج النموذج الفردي ، حيث حصلن على SOTA في جميع المهام التسعة. في مجموعة الاختبار ، تتم مقارنة مجموعة الطرز ، SOTA لمدة 4 من 9 مهام وسرعة الغراء النهائية. على نسختين من SQuAD على شبكة تطوير SOTA ، في الاختبار المعين على مستوى XLNet. علاوة على ذلك ، على عكس XLNet ، لا يتم اكتشافهم على حزم ضمان الجودة الإضافية قبل حل SQuAD.

مهمة SOTA on RACE التي يتم فيها تقديم جزء من النص ، وسؤال حول هذا النص و 4 خيارات للإجابة حيث تحتاج إلى اختيار الخيار الصحيح. لحل هذه المهمة ، يقومون بتسلسل النص والسؤال والإجابة ، والتشغيل من خلال BERT ، والحصول على تمثيل من الرمز المميز لـ CLF ، والتطبيق على طبقة واحدة متصلة تمامًا والتنبؤ بما إذا كانت الإجابة صحيحة. يتم ذلك 4 مرات - لكل خيار من خيارات الإجابة.
لقد قمنا بنشر الكود والتظاهر المسبق لنموذج RoBERTa في اللفت fairseq . يمكنك استخدامه ، كل شيء يبدو أنيق وبسيط.
4. EfficientNet: إعادة التفكير في توسيع نطاق نموذج الشبكات العصبية التلافيفية
المؤلفون: Mingxing Tan ، Quoc V. Le (Google Research، 2019)
→ المادة الأصلية
مؤلف المراجعة: الكسندر دينيسينكو (في الكساد دينيسينكو الكسندر)

إنهم يدرسون تحجيم (تحجيم) النماذج وموازنة عمق الشبكة وعرضها (عدد القنوات) ، وكذلك دقة الصور في الشبكة. إنها توفر طريقة تحجيم جديدة تقيس بشكل موحد العمق / العرض / الدقة. أظهر فعاليته على MobileNet و ResNet.
يستخدمون أيضًا Neural Architecture Search لإنشاء شبكة جديدة وتوسيع نطاقها ، وبالتالي الحصول على فئة من النماذج الجديدة - EfficientNets. إنها أفضل وأكثر اقتصادا من الشبكات السابقة. على ImageNet ، تحقق EfficientNet-B7 أحدث 84.4٪ من أعلى 1 و 97.1٪ من أعلى 5 دقة ، حيث تقل بنسبة 8.4 مرة وأسرع بمقدار 6.1 مرة عن الاستدلال الحالي من أفضل فئة من فئة ConvNet. ينتقل بشكل جيد إلى مجموعات البيانات الأخرى - فقد حصلوا على SOTA في 5 من 8 مجموعات البيانات الأكثر شعبية.
تحجيم نموذج مركب
يتم القياس عندما يتم تثبيت العمليات التي تتم داخل الشبكة وتغيير العمق (عدد مرات تكرار نفس الوحدات) d والعرض (عدد القنوات في الالتفاف) w والقرار r. في الاستدعاء ، تتم صياغة التحجيم كمشكلة تحسين - نريد الحد الأقصى من الدقة (Net (d ، w ، r)) على الرغم من حقيقة أننا لا نقوم بالزحف خارج الذاكرة و FLOPS.
لقد أجرينا تجارب وتأكدنا من أنها تساعد أيضًا في زيادة الدقة والعمق عند التوسع في العرض. باستخدام FLOPS نفسه ، نحقق نتيجة أفضل بشكل ملحوظ على ImageNet (انظر الصورة أعلاه). بشكل عام ، هذا معقول ، لأنه يبدو أنه مع زيادة دقة صورة الشبكة ، هناك حاجة إلى مزيد من الطبقات في العمق لزيادة حقل الاستلام والمزيد من القنوات من أجل التقاط جميع الأنماط في الصورة بدقة أعلى.
جوهر التحجيم المركب: نأخذ معامل المركب فاي ، الذي يوازن بالتساوي d و w و r مع هذا المعامل: حيث - الثوابت التي تم الحصول عليها من طريقة عرض شبكة صغيرة على الشبكة المصدر. - معامل توصيف مقدار موارد الحوسبة المتاحة.
صافي كفاءة
لإنشاء الشبكة ، استخدمنا بحثًا عن الهندسة العصبية متعددة الأهداف ودقة محسّنة و FLOPS مع المعلمة المسؤولة عن المفاضلة بينهما. أعطى مثل هذا البحث EfficientNet-B0. باختصار - Conv متبوعة بالعديد من MBConv ، في نهاية Conv1x1 ، Pool ، FC.
ثم قم بإجراء القياس بخطوتين:
- للبدء ، نصلح ، هل شبكة البحث عن البحث .
- قم بتوسيع الشبكة باستخدام الصيغ لـ d و w و r. حصلت على EffiientNet-B1. وبالمثل ، زيادة ، الحصول على EfficientNet-B2 ، ... B7.
تحجيم مختلف ResNet و MobileNet ، تلقى في كل مكان تحسينات كبيرة على ImageNet ، أعطى التحجيم المركب زيادة كبيرة بالمقارنة مع التحجيم في بعد واحد فقط. لقد أجرينا أيضًا تجارب مع EfficientNet على ثماني مجموعات بيانات أكثر شعبية ، في كل مكان حصلنا على SOTA أو نتيجة قريبة منه مع عدد أقل بكثير من المعلمات.
التعليمات البرمجية.
5. كيف ينتقل المخ من الإدراك إلى الإدراك الحسي
مؤلفو المقال: فرانشيسكا آريس لوسيني ، جينو ديل فيرارو ، ماريانو سيغمان ، هرنان أ. ماكسي (الولايات المتحدة الأمريكية ، الأرجنتين ، إسبانيا ، 2019)
→ المادة الأصلية
مؤلف المراجعة: Svyatoslav Skoblov (في error_derivative الركود)
هذه المقالة هي عبارة عن استمرار وإعادة النظر في عمل Dehaene، S، Naccache، L، Cohen، L، Le Bihan، D، Mangin، JF، Poline، JB، & Rivie`re، D. آليات دماغية لإخفاء الأقنعة وتهيئتها لتكرار اللاوعي ، في الذي حاول المؤلفون النظر في أوضاع وظائف المخ الواعية وغير الواعية.
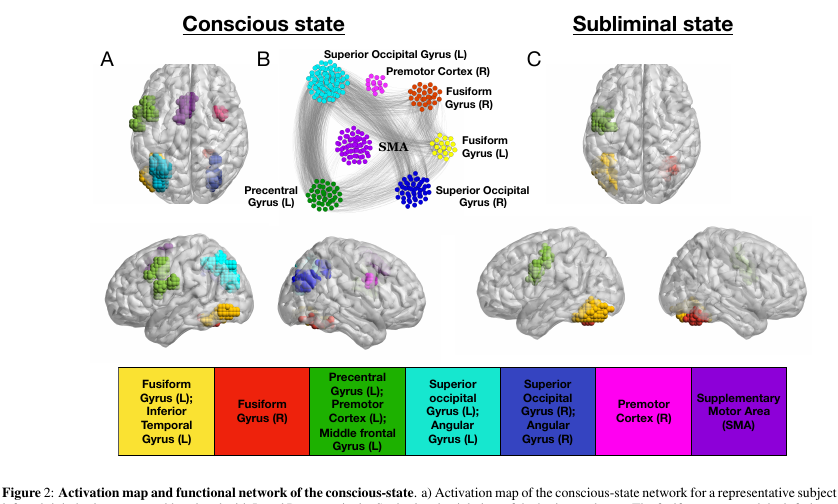
التجربة:
يتم عرض الصور على المتطوعين (كلمات مكونة من 4 أحرف أو شاشة فارغة أو خربشات). يظهر كل منهم لمدة 30 مللي ثانية ، بشكل عام ، يستمر الإجراء بأكمله 5 دقائق.
- في الوضع "الواعي" للتجربة ، تتناوب شاشة فارغة مع الكلمات ، مما يتيح للشخص إدراك النص بوعي.
- في الوضع "اللاشعوري" ، تتناوب الكلمات مع الشخبطة ، التي تتداخل بشكل فعال مع إدراك النص على مستوى واعي.
المعلومات:
خلال هذا العرض التقديمي ، تم فحص أدمغة قرودنا باستخدام الرنين المغناطيسي الوظيفي. في المجموع ، كان لدى الباحثين 15 متطوعًا ، كرر كل منهم التجربة 5 مرات ، أي ما مجموعه 75 مجرى رنين مغناطيسي. تجدر الإشارة إلى أن فحص voxel تبين أنه كبير جدًا (مبسط للغاية: voxel هو مكعب ثلاثي الأبعاد يحتوي على عدد كبير جدًا من الخلايا) - 4x4x4mm.
السحر:
دعنا ندعو العقدة النشط فوكسل من تيارنا. نظرًا لأن المخ عبارة عن قطعة قماش قابلة للفصل ، فإننا نقدم نوعين من الوصلات فيه: خارجي وداخلي (مطابق للترتيب المكاني للعقد). يتم تجميع الاتصالات بطريقة مثيرة للاهتمام: نقوم ببناء مصفوفة الارتباط المتبادل بين العقد وتوصيل العقد مع اتصال إذا كان الارتباط أكبر من بعض المعلمة التكيفية lambda. تؤثر هذه المعلمة على تفريغ شبكتنا.
يتم إجراء تعديل المعلمة باستخدام إجراء "التصفية". إذا قمنا بتأثير lambda الخاص بنا ، فستكون بعض التحولات الحادة بين الأبعاد النهائية للشبكة ملحوظة (على سبيل المثال ، تغيير معلمة صغير بما فيه الكفاية يتوافق مع زيادة كبيرة في الحجم).
لذلك: يتم تنشيط الاتصالات الداخلية بواسطة قيمة lambda-1 ، والتي تتوافق مع قيمة lambda قبل انتقال حاد. الخارجية - قيمة lambda-2 المقابلة لقيمة lambda مباشرة بعد انتقال حاد.
السحر 2:
تصفية k الأساسية. يصف مفهوم k-core اتصال الشبكة ويتم صياغته بكل بساطة: الحد الأقصى للشبكة الفرعية ، التي تحتوي جميع عقدها على جيران k على الأقل. يمكن الحصول على هذه الشبكة الفرعية عن طريق الإزالة التكرارية للعُقد ذات الجيران الأقل من k. نظرًا لأن العقد المتبقية ستفقد الجيران ، تستمر العملية حتى لا يوجد شيء للحذف. ما تبقى هو الشبكة الأساسية.
النتائج:
بتطبيق هذه المدفعية على أدمغتنا ، يمكنك رؤية عدد من الميزات المثيرة للاهتمام للغاية.
- عدد العقد في k-core مع k الصغيرة / الكبيرة جدًا كبير للغاية. ولكن بالنسبة إلى متوسط k ، على العكس ، لا يكفي. في الصورة ، يبدو وكأنه شكل U ، أي أن تكوين الشبكة هذا يعطي أكبر استقرار للنظام (مقاومة كل من الأخطاء المحلية والعالمية).
- وأهم العقد التي تنتمي إلى k-core مع small k يمكن رؤيتها في أي حالة تقريبًا من الشبكة. لكن k-core ذو الحجم الكبير جدًا k هو سمة مميزة فقط لتلك الأجزاء من الدماغ التي تنشط في حالة التلفيف المغزلي اللاإرادي والتلفيف الأيسر المركزي . نفس الأجزاء من القشرة هي الأكثر نشاطا وفي حالة واعية.
للتحقق من النتيجة ، أنشأ المؤلفون مليون شبكة عشوائية تعتمد على شبكات حقيقية ، تقوم بعمل أسلاك كهربائية عشوائية ، مع الحفاظ على الدرجة الأصلية للعقد (مثل درجة قمة الرأس في الرسم البياني). تختلف الشبكات الحقيقية عن الشبكات العشوائية بقيم أكبر بكثير بحد أقصى k. في الوقت نفسه ، ظل الشكل U لعدد العقد في المجموعات ملحوظًا في الشبكات العشوائية ، مما دفع المؤلفين إلى فكرة أن درجة العقد هي المسؤولة عن هذه الظاهرة.
الاستنتاجات:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. أي query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
ReID OSNet ( 2 ) (Market: R1 93.6%, mAP 81.0% OSNet R1 87.0%, mAP 69.5% MobileNetV2) ResNet DenseNet (Market: R1 94.8%, mAP 84.9% OSNet R1 94.8%, mAP 86.0% ResNet).
التحدي الآخر هو تكييف المجال : النماذج المدربة على مجموعة بيانات ذات نوعية رديئة على أخرى. تُظهر OSNet أيضًا نتائج جيدة في هذا الجزء دون استخدام "تكييف المجال غير الخاضع للإشراف" (باستخدام بيانات الاختبار في نموذج غير مخصص حتى لتوزيع البيانات).
تم اختبار البنية أيضًا على ImageNet ، حيث حققت دقة مماثلة مع MobileNetV2 مع عدد أقل من المعلمات ، ولكن مع المزيد من العمليات.
9. reparameterization العصبية يحسن الأمثل الهيكلي
المؤلفون: ستيفان هوير ، وجاشا سوهل-دكستين ، وسام جريدانوس (Google Research ، 2019)
→ المادة الأصلية
مؤلف المراجعة: أليكسي (في أراك سلاك)
في البناء والتكنولوجيات الأخرى ، هناك مهام لتحسين هيكل / طوبولوجيا بعض الحلول. بمعنى تقريبي ، هذه إجابة للكمبيوتر على سؤال مثل ، على سبيل المثال ، كيفية تصميم جسر / بناء / جناح لطائرة / شفرة التوربينات / blablabla ، بحيث يتم الوفاء ببعض القيود والبنية قوية بما فيه الكفاية. هناك مجموعة من أساليب الحل "القياسية" - إنها تعمل ، ولكن كل شيء ليس دائمًا سلسًا هناك.
ماذا فعل هؤلاء الرجال من Google؟ قالوا: دعنا نولد حلاً من خلال شبكة عصبية (الجزء المختزل من UNet) ، ثم باستخدام نموذج مادي قابل للتمييز ، والذي سيحسب سلوك الحل تحت تأثير كل القوى والجاذبية ، نحسب الوظيفة الموضوعية - القوة (بشكل أدق ، معكوس - الامتثال) ) التصاميم. بعد ذلك ، نظرًا لأن كل شيء يمكن تمييزه تلقائيًا ، نحصل على التدرج اللوني للوظيفة الموضوعية ، والتي يتم دفعها عبر الهيكل بأكمله إلى الأوزان وإدخال الشبكة العصبية. نغير الأوزان والدخول ونواصل الدورة حتى نتقارب إلى حل مستقر.
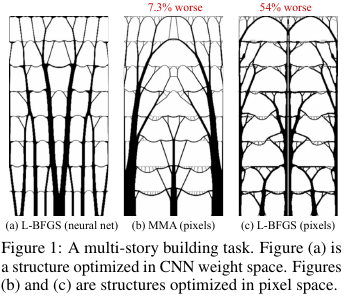
تبين أن النتائج كانت على مشاكل صغيرة (من حيث حجم الحلول الممكنة) مقارنة بالطرق التقليدية لتحسين الطبولوجيا ، وبالنسبة للمشاكل الكبيرة ، فهي أفضل بشكل ملحوظ من المشاكل التقليدية (زيادة الوزن في 99 مقابل 66 من أصل 116 مشكلة). علاوة على ذلك ، فإن الحلول الناتجة غالبًا ما تكون تكنولوجيًا ومثاليًا بشكل ملحوظ عن قرارات خطوط الأساس.
أي في الواقع ، استخدموا NS كطريقة صعبة لتعيين النموذج المادي للهيكل ، والذي قادر ضمنيًا (بفضل بنية NS) على فرض بعض القيود المفيدة على قيم المعلمات (يتم التحكم فيها عن طريق إزالة NS من الطريقة والتحسين المباشر لقيم البكسل).
شفرة المصدر.
نظرة أكثر تفصيلا لهذه المادة على هابر.