عربة الطيران ، عفو تشانأنا أعمل في
Mail.ru Cloud Solutons كمهندس معماري ومطور ، بما في ذلك السحابة الخاصة بي. من المعروف أن البنية التحتية السحابية الموزعة تحتاج إلى مساحة تخزينية منتجة تعتمد عليها تشغيل خدمات وحلول PaaS المصممة باستخدامها.
في البداية ، عند استخدام مثل هذه البنية التحتية ، استخدمنا Ceph فقط ، ولكن تطور كتلة التخزين تدريجيًا. لقد أردنا
أن تعمل قواعد البيانات الخاصة بنا وتخزين الملفات والخدمات المختلفة بأقصى قدر من الأداء ، لذلك قمنا بإضافة وحدات تخزين محلية وإعداد مراقبة متقدمة Ceph.
سوف أخبركم كيف كانت - ربما هذه القصة ، والمشاكل التي واجهناها ، وسوف تكون حلولنا مفيدة لأولئك الذين يستخدمون Ceph أيضًا. بالمناسبة ،
إليك نسخة فيديو لهذا التقرير.
من عمليات DevOps إلى السحابة الخاصة بك
تهدف ممارسات DevOps إلى طرح المنتج في أسرع وقت ممكن:
- أتمتة العمليات - دورة الحياة بأكملها: التجميع ، الاختبار ، التسليم إلى الاختبار والإنتاجية. أتمتة العمليات تدريجيا ، بدءا من خطوات صغيرة.
- تعتبر البنية التحتية كرمز نموذجًا عندما تكون عملية تكوين البنية الأساسية مشابهة لعملية برمجة البرمجيات. أولاً ، يقومون باختبار المنتج ، ويحتوي المنتج على متطلبات معينة للبنية التحتية ، ويجب اختبار البنية التحتية. في هذه المرحلة ، أتمنى ظهورها ، أريد "تعديل" البنية التحتية - أولاً في بيئة الاختبار ، ثم في البقالة. في المرحلة الأولى ، يمكن القيام بذلك يدويًا ، ولكن بعد ذلك ينتقلون إلى التشغيل الآلي - إلى نموذج "البنية التحتية كرمز".
- المحاكاة الافتراضية والحاويات - تظهر في الشركة عندما يكون من الواضح أنك تحتاج إلى وضع العمليات على المسار الصناعي ، وطرح ميزات جديدة بشكل أسرع مع الحد الأدنى من التدخل اليدوي.
 تتشابه بنية جميع البيئات الافتراضية: أجهزة الضيف مع الحاويات والتطبيقات والشبكات العامة والخاصة والتخزين.
تتشابه بنية جميع البيئات الافتراضية: أجهزة الضيف مع الحاويات والتطبيقات والشبكات العامة والخاصة والتخزين.تدريجيا ، يتم نشر المزيد والمزيد من الخدمات في البنية التحتية الافتراضية التي بنيت داخل وحول عمليات DevOps ، وأصبحت البيئة الافتراضية ليس فقط اختبار (يستخدم للتطوير والاختبار) ، ولكن أيضا إنتاجية.
كقاعدة عامة ، في المراحل الأولية يتم تجاوزها بواسطة أبسط أدوات التشغيل الآلي الأساسية. ولكن نظرًا لاجتذاب أدوات جديدة ، فهناك حاجة عاجلة أو آجلاً إلى نشر نظام أساسي سحابي متكامل لاستخدام الأدوات الأكثر تطوراً مثل Terraform.
في هذه المرحلة ، تتحول البنية التحتية الافتراضية من "برامج التحكم والشبكات والتخزين" إلى بنية تحتية سحابية كاملة مع أدوات ومكونات متطورة لعمليات التنسيق. ثم تظهر السحابة الخاصة بهم ، حيث تتم عمليات الاختبار والتسليم التلقائي للتحديثات إلى الخدمات الحالية ونشر خدمات جديدة.
الطريقة الثانية للسحابة الخاصة بك هي الحاجة إلى عدم الاعتماد على الموارد الخارجية ومقدمي الخدمات الخارجيين ، أي توفير بعض الاستقلالية التقنية للخدمات الخاصة بك.
 تشبه السحابة الأولى بنية تحتية افتراضية تقريبًا - جهاز مراقبة (جهاز واحد أو عدة أجهزة) وأجهزة افتراضية مزودة بحاويات وتخزين مشترك: إذا كنت تقوم بإنشاء السحابة لا على حلول خاصة ، فهي عادةً Ceph أو DRBD.
تشبه السحابة الأولى بنية تحتية افتراضية تقريبًا - جهاز مراقبة (جهاز واحد أو عدة أجهزة) وأجهزة افتراضية مزودة بحاويات وتخزين مشترك: إذا كنت تقوم بإنشاء السحابة لا على حلول خاصة ، فهي عادةً Ceph أو DRBD.سحابة خاصة المرونة والأداء
السحابة تنمو ، والأعمال تعتمد عليها أكثر فأكثر ، وبدأت الشركة في المطالبة بمزيد من الموثوقية.
هنا ، تتم إضافة التوزيع إلى السحابة الخاصة ، وتظهر البنية التحتية السحابية الموزعة: نقاط إضافية حيث يوجد الجهاز. تدير السحابة اثنين أو ثلاثة أو أكثر من المنشآت المصممة لتوفير حل متسامح مع الخطأ.
في الوقت نفسه ، هناك حاجة إلى البيانات من جميع المواقع ، وهناك مشكلة: لا يوجد داخل موقع واحد أي تأخير كبير في نقل البيانات ، ولكن بين المواقع يتم نقل البيانات بشكل أبطأ.
 مواقع التثبيت والتخزين المشترك. المستطيلات الحمراء هي اختناقات على مستوى الشبكة.
مواقع التثبيت والتخزين المشترك. المستطيلات الحمراء هي اختناقات على مستوى الشبكة.الجزء الخارجي من البنية التحتية من وجهة نظر شبكة الإدارة أو الشبكة العامة ليس مشغولاً للغاية ، ولكن على الشبكة الداخلية تكون أحجام البيانات المنقولة أكبر بكثير. وفي الأنظمة الموزعة ، تبدأ المشاكل ، معبراً عنها في مدة خدمة طويلة. إذا جاء العميل إلى مجموعة واحدة من عقد التخزين ، فيجب نسخ البيانات على الفور إلى المجموعة الثانية حتى لا تضيع التغييرات.
بالنسبة لبعض العمليات ، يكون زمن انتقال النسخ المتماثل للبيانات مقبولًا ، لكن في حالات مثل معالجة المعاملات ، لا يمكن فقد المعاملات. في حالة استخدام النسخ المتماثل غير المتزامن ، يحدث تأخير زمني يمكن أن يؤدي إلى فقد جزء من البيانات في حالة فشل أحد "ذيول" نظام التخزين (نظام تخزين البيانات). في حالة استخدام النسخ المتماثل المتزامن ، يزداد وقت الخدمة.
ومن الطبيعي أيضًا أنه عندما تزداد مدة المعالجة (زمن الوصول) للتخزين ، تبدأ قواعد البيانات في التباطؤ وهناك تأثيرات سلبية يجب محاربتها.
في السحابة الخاصة بنا ، نبحث عن حلول متوازنة للحفاظ على الموثوقية والأداء. إن أبسط التقنيات هي ترجمة البيانات - ثم أضفنا مجموعات Ceph محلية إضافية.
 يشير اللون الأخضر إلى مجموعات Ceph محلية إضافية.
يشير اللون الأخضر إلى مجموعات Ceph محلية إضافية.ميزة هذه البنية المعقدة هي أن أولئك الذين يحتاجون إلى إدخال / إخراج سريع للبيانات يمكنهم استخدام المستودعات المحلية. البيانات التي توفرها الكامل أمر بالغ الأهمية ضمن موقعين تقع في كتلة موزعة. يعمل بشكل أبطأ - ولكن يتم نسخ البيانات الموجودة به إلى كلا الموقعين. إذا كان أداءه غير كافٍ ، يمكنك استخدام مجموعات Ceph المترجمة.
تأتي معظم السحب العامة والخاصة في النهاية إلى نفس نمط العمل تقريبًا ، عندما يتم نشر الحمل في أنواع مختلفة من المستودعات (وفقًا لمتطلبات مختلفة) ، وفقًا للمتطلبات.
تشخيص Ceph: كيفية بناء المراقبة
عندما نشرنا البنية التحتية وأطلقناها ، فقد حان الوقت لضمان عملها ، لتقليل وقت وعدد الإخفاقات. لذلك ، كانت الخطوة التالية في تطوير البنية التحتية هي بناء التشخيص والمراقبة.
ضع في اعتبارك مهمة المراقبة بطولها بالكامل - لدينا مجموعة من التطبيقات في بيئة سحابية افتراضية: تطبيق ، ونظام تشغيل الضيف ، وجهاز كتلة ، وبرامج تشغيل هذا الجهاز الفائق على برنامج Hypervisor ، وشبكة تخزين ، ونظام التخزين الفعلي (نظام التخزين). وكل هذا لم تتم تغطيته بعد بواسطة المراقبة.
 عناصر لا يغطيها الرصد.
عناصر لا يغطيها الرصد.يتم تنفيذ الرصد على عدة مراحل ، نبدأ مع الأقراص. نحصل على عدد عمليات القراءة / الكتابة ، إلى حد ما ، وقت الخدمة (ميغا بايت في الثانية) ، وعمق قائمة الانتظار ، وغيرها من الخصائص ، كما نقوم بجمع SMART حول حالة الأقراص.
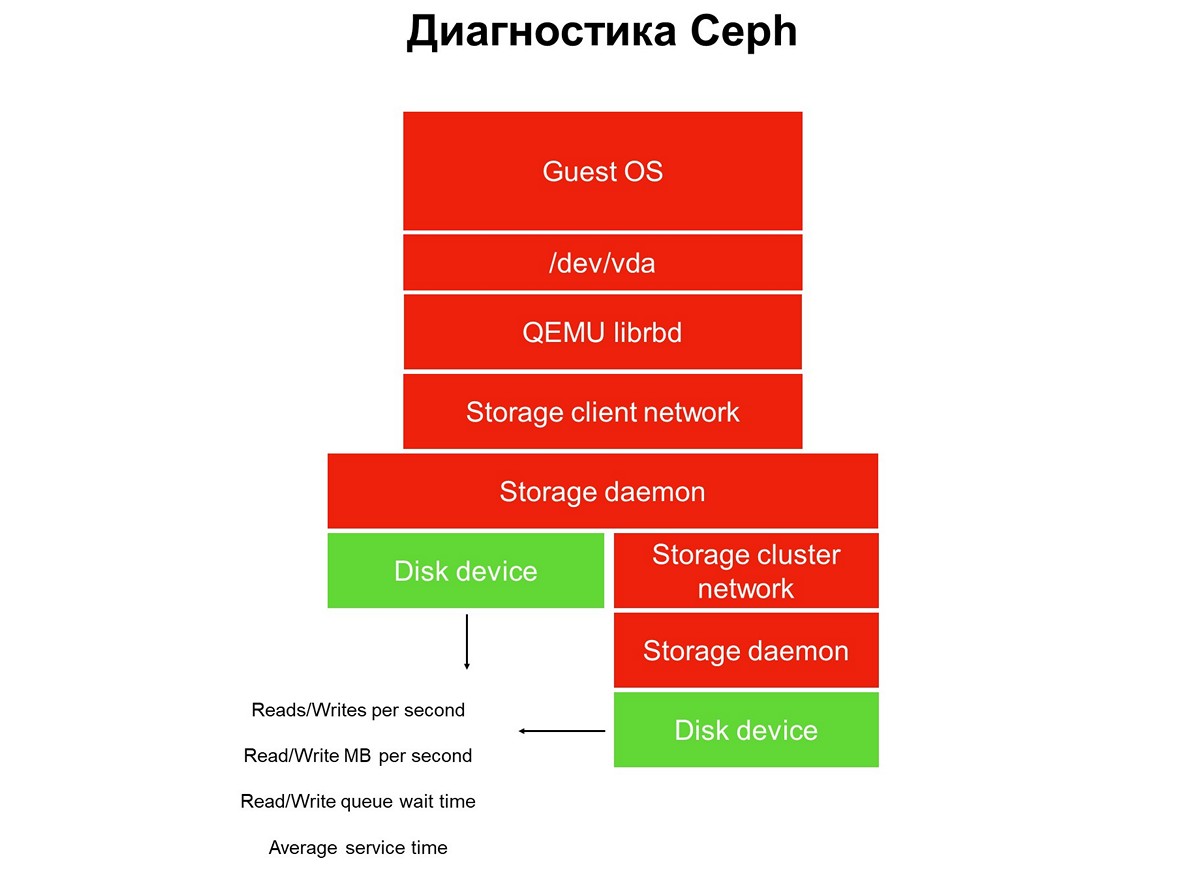 المرحلة الأولى: نحن نغطي أقراص المراقبة.
المرحلة الأولى: نحن نغطي أقراص المراقبة.مراقبة القرص ليست كافية للحصول على صورة كاملة لما يجري في النظام. لذلك ، ننتقل إلى مراقبة عنصر حاسم في البنية التحتية - شبكة نظام التخزين. يوجد بالفعل اثنين منهم - المجموعة الداخلية والعميل ، الذي يربط مجموعات التخزين مع برامج Hypervisor. هنا نحصل على معدلات نقل حزم البيانات (ميغابايت في الثانية ، وحزم في الثانية) ، وحجم قوائم انتظار الشبكة ، والمخازن المؤقتة ، وربما مسارات البيانات.
 المرحلة الثانية: مراقبة الشبكة.
المرحلة الثانية: مراقبة الشبكة.غالبًا ما يتوقفون عند هذا ، لكن هذا لا يمكن القيام به ، لأن معظم البنية التحتية لم يتم إغلاقها بعد من خلال المراقبة.
كل التخزين الموزع المستخدم في السحب العامة والخاصة هو SDS ، تخزين المعرفة بالبرنامج. يمكن تنفيذها على حلول بائع معين ، حلول مفتوحة المصدر ، يمكنك القيام بشيء بنفسك باستخدام مجموعة من التقنيات المعروفة. ولكنه دائمًا SDS ، ويجب مراقبة عمل أجزاء البرامج هذه.
 الخطوة الثالثة: مراقبة تخزين الخفي.
الخطوة الثالثة: مراقبة تخزين الخفي.يستخدم معظم مشغلي Ceph البيانات المجمعة من شياطين مراقبة ومراقبة Ceph (مراقبة ومدير ، ويعرف أيضًا باسم mgr). في البداية ، ذهبنا بنفس الطريقة ، لكننا أدركنا بسرعة كبيرة أن هذه المعلومات لم تكن كافية - تظهر التحذيرات حول تعليق الطلبات في وقت متأخر: تم تعليق الطلب لمدة 30 ثانية ، وعندها فقط رأيناها. وطالما يتعلق الأمر بالمراقبة ، بينما تثير المراقبة الإنذار ، ستمر ثلاث دقائق على الأقل. في أفضل الأحوال ، هذا يعني أن جزءًا من التخزين والتطبيقات سيكون خاملاً لمدة ثلاث دقائق.
بطبيعة الحال ، قررنا توسيع نطاق المراقبة وتوجهنا إلى العنصر الرئيسي في Ceph - برنامج OSD الخفي. من مراقبة البرنامج الخفي لتخزين الكائنات ، نحصل على وقت التشغيل التقريبي كما يراه OSD ، بالإضافة إلى إحصائيات حول طلبات التعليق - من ، متى ، في PG ، إلى متى.
لماذا فقط Ceph لا يكفي وماذا تفعل حيال ذلك
Ceph وحدها ليست كافية لعدد من الأسباب. على سبيل المثال ، لدينا عميل لديه ملف تعريف قاعدة بيانات. لقد قام بنشر جميع قواعد البيانات في المجموعة التي تعمل بنظام الفلاش ، وكان تأخر العمليات التي صدرت هناك يناسبه ، ومع ذلك ، كانت هناك شكاوى من التوقف.
لا يسمح لك نظام المراقبة برؤية ما يحدث داخل عملاء البيئة الافتراضية. نتيجة لذلك ، لتحديد المشكلة ، استخدمنا التحليل المتقدم ، الذي تم طلبه باستخدام أداة blktrace من جهازه الافتراضي.
 نتيجة تحليل موسع.
نتيجة تحليل موسع.تحتوي نتائج التحليل على عمليات مميزة بالعلمين W و WS. علامة W هي سجل ، علامة WS هي سجل متزامن ، في انتظار أن يكمل الجهاز العملية. عندما نعمل مع قواعد البيانات ، تحتوي جميع قواعد بيانات SQL تقريبًا على عنق الزجاجة - WAL (سجل الكتابة المسبق).
تقوم قاعدة البيانات دائمًا أولاً بكتابة البيانات إلى السجل ، وتتلقى التأكيد من القرص باستخدام وحدات التخزين المؤقتة ، ثم تقوم بكتابة البيانات إلى قاعدة البيانات نفسها. إذا لم تتلق تأكيدًا لإعادة تعيين المخزن المؤقت ، فهي تعتقد أن إعادة تعيين القدرة يمكن أن تمحو معاملة أكدها العميل. هذا غير مقبول بالنسبة لقاعدة البيانات ، لذلك يعرض "الكتابة SYNC / FLUSH" ، ثم يكتب البيانات. عندما تكون السجلات ممتلئة ، يحدث رمز التبديل الخاص بهم ، ويتم أيضًا وميض كل ما يدخل ذاكرة التخزين المؤقت للصفحة.
أضيفت: لا توجد إعادة تعيين في الصورة نفسها - أي عمليات بعلم ما قبل التدفق. تبدو مثل FWS - pre-flush + write + sync أو FWSF - pre-flush + كتابة + sync + FUAعندما يكون لدى العميل العديد من المعاملات الصغيرة ، تتحول كل عمليات الإدخال / الإخراج الخاصة به تقريبًا إلى سلسلة متسلسلة: كتابة - تدفق - كتابة - تدفق. نظرًا لأنه لا يمكنك القيام بشيء ما باستخدام قاعدة البيانات ، نبدأ العمل مع نظام التخزين. في هذه اللحظة ، نحن نفهم أن قدرات Ceph ليست كافية.
بالنسبة لنا ، في هذه المرحلة ، كان أفضل حل هو إضافة مستودعات محلية صغيرة وسريعة لم يتم تنفيذها باستخدام أدوات Ceph (استنفدنا قدراتها بشكل أساسي). ونحول التخزين السحابي إلى شيء أكثر من Ceph. في حالتنا ، أضفنا العديد من القصص المحلية (محلية من حيث مركز البيانات ، وليس برنامج Hypervisor).
 مستودعات محلية إضافية الهدف A و B.
مستودعات محلية إضافية الهدف A و B.تبلغ مدة خدمة هذا التخزين المحلي حوالي 0.3 مللي ثانية لكل تيار. إذا كان موجودًا في مركز بيانات آخر ، فهو يعمل ببطء أكثر - مع أداء يبلغ حوالي 0.7 مللي ثانية. هذه زيادة كبيرة مقارنة بـ Ceph ، التي تنتج 1.2 مللي ثانية ، ويتم توزيعها على مراكز البيانات - 2 مللي ثانية. أداء هذه المصانع الصغيرة ، التي لدينا أكثر من عشرة ، حوالي 100 ألف لكل وحدة ، 100 ألف IOPS لكل سجل.
بعد هذا التغيير في البنية التحتية ، تقوم السحابة لدينا بالضغط على أقل من مليون IOPS للكتابة ، أو ما يقرب من مليونين إلى ثلاثة ملايين IOPS للقراءة إجمالاً لجميع العملاء:

من المهم ملاحظة أن هذا النوع من التخزين ليس هو الطريقة الرئيسية للتوسع ، فنحن نضع الرهان الرئيسي على Ceph ، ووجود التخزين السريع مهم فقط للخدمات التي تتطلب وقت استجابة للقرص.
التكرارات الجديدة: تحسينات الكود والبنية التحتية
جميع قصصنا هي الموارد المشتركة. تتطلب مثل هذه البنية التحتية
تنفيذ سياسة مستوى الخدمة : يجب علينا تقديم مستوى معين من الخدمة وعدم السماح لأحد العملاء بالتداخل مع الآخر عن طريق الصدفة أو عن قصد ، عن طريق تعطيل التخزين.
للقيام بذلك ، كان يتعين علينا القيام بالتنفيذ النهائي وغير التافه - التسليم التكراري للمنتج.
كانت عملية النشر هذه مختلفة عن ممارسات DevOps المعتادة ، عندما تبدأ جميع العمليات: التجميع والاختبار ونشر الكود وخدمة إعادة التشغيل ، عند الضرورة ، بنقرة زر واحدة ، ثم يعمل كل شيء. إذا قمت بتطبيق ممارسات DevOps على البنية التحتية ، فسيستمر ذلك حتى الخطأ الأول.
هذا هو السبب في أن "الأتمتة الكاملة" لم تتجذر بشكل خاص في فريق البنية التحتية. بالطبع ، هناك طريقة معينة لاختبار التشغيل الآلي للتسليم والتوصيل - لكن يتم التحكم فيه دائمًا ويتم بدء التسليم بواسطة مهندسي SRE في الفريق السحابي.
طرحنا التغييرات في العديد من الخدمات: في Cinder backend و Cinder frontend (عميل Cinder) وفي خدمة Nova. تم تطبيق التغييرات في عدة تكرارات - تكرار واحد في كل مرة. بعد التكرار الثالث ، تم تطبيق التغييرات المناظرة على أجهزة الضيف الخاصة بالعملاء: قام شخص ما بالترحيل أو قام شخص ما بإعادة تشغيل VM (إعادة التمهيد الثابت) أو الترحيل المخطط له لخدمة برامج Hypervisor.
المشكلة التالية التي نشأت هي
القفزات في سرعة الكتابة . عندما نتعامل مع التخزين المتصل بالشبكة ، فإن برنامج hypervisor الافتراضي يعتبر الشبكة بطيئة ، وبالتالي يقوم بتخزين جميع البيانات. يكتب بسرعة ، حتى عشرات الميجابايت ، ثم يبدأ في مسح ذاكرة التخزين المؤقت. كانت هناك لحظات كثيرة غير سارة بسبب هذه القفزات.
وجدنا أنه إذا قمت بتشغيل ذاكرة التخزين المؤقت ، فإن أداء SSD يتراجع بنسبة 15٪ ، وإذا قمت بإيقاف تشغيل ذاكرة التخزين المؤقت ، فإن أداء الأقراص الصلبة يتراجع بنسبة 35٪. استغرق الأمر تطوراً آخر ، تم طرحه لإدارة التخزين المؤقت المدارة ، عندما يتم تعيين التخزين المؤقت بشكل صريح لكل نوع من أنواع الأقراص. هذا سمح لنا بقيادة SSD دون ذاكرة التخزين المؤقت ، والأقراص الصلبة - مع ذاكرة التخزين المؤقت ، ونتيجة لذلك ، توقفنا عن فقدان الأداء.
ممارسة تقديم التنمية إلى منتج مماثل - التكرار. لقد طرحنا الرمز ، وأعدنا تشغيل البرنامج الخفي ، ثم ، عند الضرورة ، أعدنا تشغيل الأجهزة الظاهرية الخاصة بالضيف أو نرحلها ، والتي يجب أن تخضع للتغيير. تم ترحيل العميل VM من محرك الأقراص الصلبة ، أو تشغيل ذاكرة التخزين المؤقت الخاصة به - كل شيء يعمل ، أو على العكس من ذلك ، تم ترحيل العميل بواسطة SSD ، تم إيقاف تشغيل ذاكرة التخزين المؤقت الخاصة به - يعمل كل شيء.
المشكلة الثالثة هي
التشغيل غير الصحيح للأجهزة الافتراضية التي تم نشرها من صور GOLD إلى محرك الأقراص الثابتة .
هناك العديد من هؤلاء العملاء ، وخصوصية الموقف هي أن عمل VM تم ضبطه بنفسه: تم ضمان حدوث المشكلة أثناء النشر ، ولكن تم حلها أثناء وصول العميل إلى الدعم الفني. في البداية ، طلبنا من العملاء الانتظار لمدة نصف ساعة حتى يتم تثبيت VM ، ولكن بعد ذلك بدأنا العمل على جودة الخدمة.
في عملية البحث ، أدركنا أن قدرات البنية التحتية للمراقبة لا تزال غير كافية.
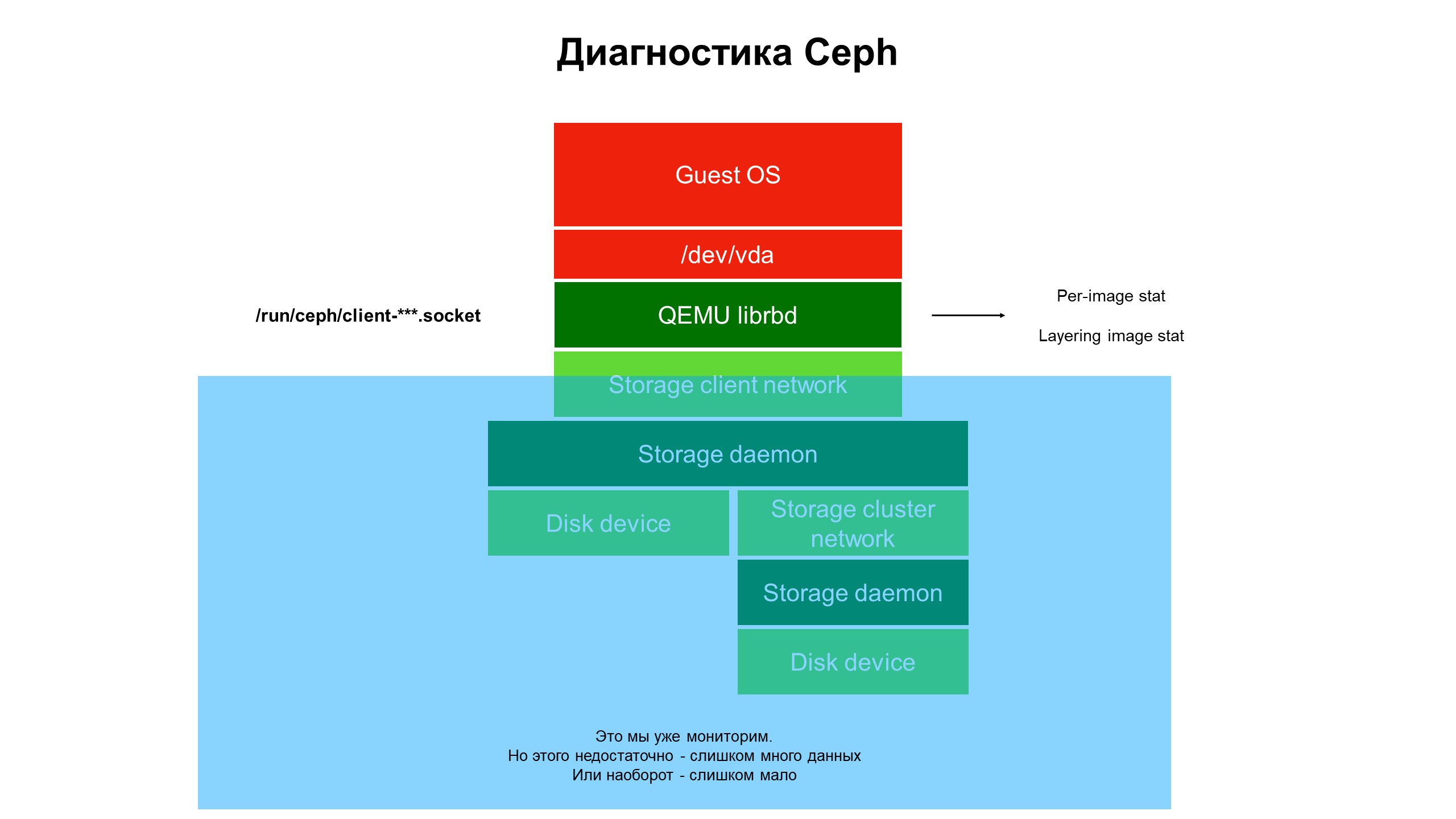 أغلقت المراقبة الجزء الأزرق ، وكانت المشكلة في الجزء العلوي من البنية التحتية ، لا تغطيها المراقبة.
أغلقت المراقبة الجزء الأزرق ، وكانت المشكلة في الجزء العلوي من البنية التحتية ، لا تغطيها المراقبة.بدأنا في التعامل مع ما يحدث في جزء من البنية التحتية التي لم تتم تغطيتها بواسطة المراقبة. للقيام بذلك ، استخدمنا تشخيصات Ceph المتقدمة (أو بالأحرى ، أحد أنواع عميل Ceph - librbd). باستخدام أدوات التشغيل الآلي ، أجرينا تغييرات على تكوين عميل Ceph للوصول إلى هياكل البيانات الداخلية من خلال مقبس مجال Unix ، وبدأنا في أخذ الإحصائيات من عملاء Ceph على برنامج hypervisor.
ماذا رأينا؟ لم نر إحصائيات حول Ceph cluster / OSD / cluster ، لكن إحصائيات على كل قرص من الجهاز الظاهري للعميل الذي كانت أقراصه في Ceph - أي ، إحصاءات مرتبطة بالجهاز.
 نتائج إحصاءات الرصد المتقدمة.
نتائج إحصاءات الرصد المتقدمة.كانت الإحصائيات الموسعة التي أوضحت أن المشكلة تحدث فقط على الأقراص المستنسخة من الأقراص الأخرى.
بعد ذلك ، نظرنا في إحصائيات العمليات ، خاصة عمليات القراءة والكتابة. اتضح أن الحمل على صور المستوى العلوي صغير نسبيًا ، وعلى الصور الأولية ، التي يأتي منها المستنسخ ، فهو كبير لكن لا يوجد توازن: كمية كبيرة من القراءة بدون تسجيل على الإطلاق.
يتم ترجمة المشكلة ، والآن هناك حاجة إلى حل - رمز أو البنية التحتية؟
لا يمكن فعل شيء باستخدام كود Ceph ، إنه "صعب". بالإضافة إلى ذلك ، تعتمد سلامة بيانات العميل عليها. ولكن هناك مشكلة ، يجب حلها ، وقمنا بتغيير بنية المستودع. تحولت مجموعة الأقراص الصلبة (HDD) إلى مجموعة مختلطة - تمت إضافة كمية معينة من SSD إلى القرص الصلب ، ثم تم تغيير أولويات شياطين OSD بحيث كان SSD دائمًا في الأولوية وأصبح OSD الأساسي داخل مجموعة المواضع (PG).
الآن ، عندما ينشر العميل الجهاز الظاهري من القرص المستنسخ ، تنتقل عمليات القراءة إلى SSD. نتيجة لذلك ، أصبح الاسترداد من القرص سريعًا ، ويتم كتابة بيانات العميل فقط بخلاف الصورة الأصلية على محرك الأقراص الصلبة. تلقينا زيادة ثلاثة أضعاف في الإنتاجية مجانًا تقريبًا (نسبة إلى التكلفة الأولية للبنية التحتية).
لماذا مراقبة البنية التحتية مهمة
- يجب تضمين البنية التحتية للمراقبة إلى الحد الأقصى في المجموعة بالكامل ، بدءًا من الجهاز الظاهري وتنتهي بالقرص. بعد كل شيء ، بينما يحصل العميل الذي يستخدم سحابة خاصة أو عامة على بنيته الأساسية ويوفر المعلومات اللازمة ، ستتغير المشكلة أو تنتقل إلى مكان آخر.
- لا تؤدي مراقبة برنامج hypervisor أو الجهاز الظاهري أو الحاوية "بالكامل" إلى أي شيء تقريبًا. لقد حاولنا أن نفهم من خلال حركة مرور الشبكة ما يحدث مع Ceph - إنه عديم الفائدة ، وتنتقل البيانات بسرعة عالية (من 500 ميجابايت في الثانية) ، ومن الصعب للغاية تحديد ما يلزم منها. سوف يستغرق الأمر حجمًا هائلاً من الأقراص لتخزين هذه الإحصاءات وكثير من الوقت لتحليلها.
- من الضروري جمع أكبر قدر ممكن من بيانات الرصد ، وإلا فهناك خطر فقدان شيء مهم. والجانب الآخر: إذا قمت بجمع الكثير من البيانات ، لكن لا يمكنك تحليلها والعثور على ما تحتاجه ، مما يجعل الإحصائيات المتراكمة عديمة الفائدة ، ستضيع البيانات المجمعة مساحة القرص لديك بلا هدف.
- الغرض من المراقبة ليس فقط تحديد فشل البنية التحتية. فشل سترى عندما يحدث ذلك. الهدف الرئيسي هو التنبؤ بالفشل ورؤية الاتجاهات ، وجمع الإحصاءات لتحسين جودة الخدمة. للقيام بذلك ، نحتاج إلى تدفقات بيانات جيدة التنظيم في المراقبة ، مرتبطة بالبنية التحتية. من الناحية المثالية ، من قرص جهاز ظاهري معين إلى أدنى مستوى - إلى أقراص التخزين التي توجد فيها البيانات التي تم الوصول إليها بواسطة الجهاز الظاهري للعميل.
- Cloud MCS Cloud Solutions هي بنية أساسية تتخذ قرارات التطوير الخاصة بها إلى حد كبير على أساس البيانات المتراكمة من خلال المراقبة. نقوم بتحسين المراقبة واستخدام بياناتها لتحسين مستوى الخدمة للعملاء.