إن مشكلة البحث التلقائي عن النص في الصور موجودة منذ فترة طويلة ، على الأقل منذ بداية التسعينيات من القرن الماضي. يمكن أن يتذكرها القديمون من خلال التوزيع الواسع لـ ABBYY FineReader ، الذين يمكنهم ترجمة عمليات المسح الضوئي للوثائق إلى إصداراتهم القابلة للتحرير.
تعمل الماسحات الضوئية المتصلة بأجهزة الكمبيوتر الشخصية بشكل جيد في الشركات ، لكن التقدم لا يزال صامداً ، وقد استحوذت الأجهزة المحمولة على العالم. تم تغيير نطاق مهام العمل مع النص أيضًا. أنت الآن بحاجة إلى البحث عن النص ليس على أوراق A4 مستقيمة تمامًا مع نص أسود على خلفية بيضاء ، ولكن على بطاقات العمل المختلفة ، والقوائم الملونة ، وعلامات المتجر ، وأكثر من ذلك بكثير حول ما يمكن للشخص أن يجتمع في غابة مدينة حديثة.
 مثال حقيقي على عمل شبكتنا العصبية. الصورة قابلة للنقر
مثال حقيقي على عمل شبكتنا العصبية. الصورة قابلة للنقرالمتطلبات الأساسية والقيود
مع مجموعة متنوعة من الشروط لتقديم النص ، لم تعد الخوارزميات المكتوبة بخط اليد قادرة على التعامل معها. هنا ، الشبكات العصبية مع قدرتها على التعميم تأتي للإنقاذ. في هذا المنشور ، سنتحدث عن أسلوبنا في إنشاء بنية شبكة عصبية تكتشف النص في صور معقدة بجودة جيدة وسرعة عالية.
تفرض الأجهزة المحمولة قيودًا إضافية على اختيار الطريقة:
- لا تتاح للمستخدمين دائمًا فرصة استخدام شبكة للهاتف المحمول للاتصال بالخادم بسبب ارتفاع تكلفة التجوال أو مشكلات الخصوصية. لذلك لن تساعد حلول مثل Google Lens هنا.
- نظرًا لأننا نركز على معالجة البيانات المحلية ، سيكون من الجيد حلنا:
- استغرق القليل من الذاكرة.
- عملت بسرعة باستخدام القدرات التقنية للهاتف الذكي.
- يمكن استدارة النص ويكون على خلفية عشوائية.
- الكلمات يمكن أن تكون طويلة جدا. في الشبكات العصبية التلافيفية ، لا يغطي نطاق نواة الالتفاف عادةً الكلمة الممتدة بأكملها ، لذلك يلزم بعض الحيل للتغلب على هذا التقييد.

- قد تختلف أحجام النص على صورة واحدة:

قرار
إن أبسط الحلول لمشكلة البحث عن النص التي تتبادر إلى الذهن هو الحصول على أفضل شبكة من
مسابقات ICDAR (المؤتمر الدولي لتحليل الوثائق والاعتراف بها) المتخصصة في هذه المهمة والأعمال! لسوء الحظ ، تحقق مثل هذه الشبكات الجودة بسبب ضخامتها وتعقيدها الحسابي ، وهي مناسبة فقط كحل سحابة ، والتي لا تلبي الفقرتين 1 و 2 من متطلباتنا. ولكن ماذا لو أخذنا شبكة كبيرة تعمل بشكل جيد في السيناريوهات التي نحتاج إلى تغطيتها ومحاولة تقليلها؟ هذا النهج هو بالفعل أكثر إثارة للاهتمام.
اقترح
Baoguang Shi et al. في شبكتهم العصبية
SegLink [1] ما يلي:
- لا تجد كلمات كاملة دفعة واحدة (مساحات خضراء في الصورة أ ) ، ولكن أجزائها ، تسمى الأجزاء ، مع التنبؤ بالتناوب والإمالة والانتقال. دعنا نستعير هذه الفكرة.
- تحتاج إلى البحث عن مقاطع الكلمات على عدة جداول في وقت واحد للوفاء بالمتطلبات 5. يتم عرض الأجزاء بواسطة مستطيلات خضراء في الصورة ب .
- من أجل إنقاذ أي شخص من اختراع كيفية الجمع بين هذه القطاعات ، فإننا ببساطة نجعل الشبكة العصبية تتنبأ بالاتصالات (الروابط) بين القطاعات ذات الصلة بالكلمة ذاتها
أ. ضمن النطاق نفسه (الخطوط الحمراء في الصورة ج )
ب. وبين المقاييس (الخطوط الحمراء في الصورة د ) ، حل مشكلة الفقرة 4 من المتطلبات.
توضح المربعات الزرقاء في الصورة أدناه مساحات الرؤية لبكسل طبقات طبقات الشبكة العصبية بمقاييس مختلفة ، والتي "ترى" جزءًا على الأقل من الكلمة.
 أمثلة على المقطع والارتباط
أمثلة على المقطع والارتباطيستخدم SegLink بنية VGG-16 المعروفة كأساس لها. يتم تنفيذ تنبؤات الأجزاء والروابط الموجودة بها على 6 موازين. كتجربة أولى ، بدأنا في تنفيذ الهيكل الأصلي. اتضح أن الشبكة تحتوي على 23 مليون معلمة (الأوزان) التي تحتاج إلى تخزينها في ملف من 88 ميغا بايت في الحجم. إذا قمت بإنشاء تطبيق يستند إلى VGG ، فسيكون ذلك أحد أوائل المرشحين للإزالة إذا لم تكن هناك مساحة كافية ، وسيعمل البحث عن النص نفسه ببطء شديد ، لذلك تحتاج الشبكة إلى فقدان الوزن بشكل عاجل.
 SegLink هندسة الشبكات
SegLink هندسة الشبكاتسر نظامنا الغذائي
يمكنك تقليل حجم الشبكة ببساطة عن طريق تغيير عدد الطبقات والقنوات فيه ، أو عن طريق تغيير الإلتواء نفسه والتواصل بينهما. قام مارك ساندلر
وشركاؤه في الوقت المناسب باختيار البنية في شبكة
MobileNetV2 الخاصة بهم [2] بحيث تعمل بسرعة على الأجهزة المحمولة ،
وتحتل مساحة صغيرة ، ولا تزال متأخرة في جودة العمل من نفس VGG. يكمن سر السرعة وتقليل استهلاك الذاكرة في ثلاث خطوات رئيسية:
- يتم تقليل عدد القنوات التي تحتوي على خرائط المعالم عند مدخل الكتلة عن طريق تحويل النقطة إلى العمق بأكمله (ما يسمى عنق الزجاجة) دون وظيفة التنشيط.
- يتم استبدال الإلتواء الكلاسيكي بإلتواء قابل للفصل لكل قناة. مثل هذا الالتواء يتطلب وزنا أقل وأقل حساب.
- يتم توجيه بطاقات الأحرف بعد عنق الزجاجة إلى إدخال الكتلة التالية للتجميع دون تشويش إضافي.
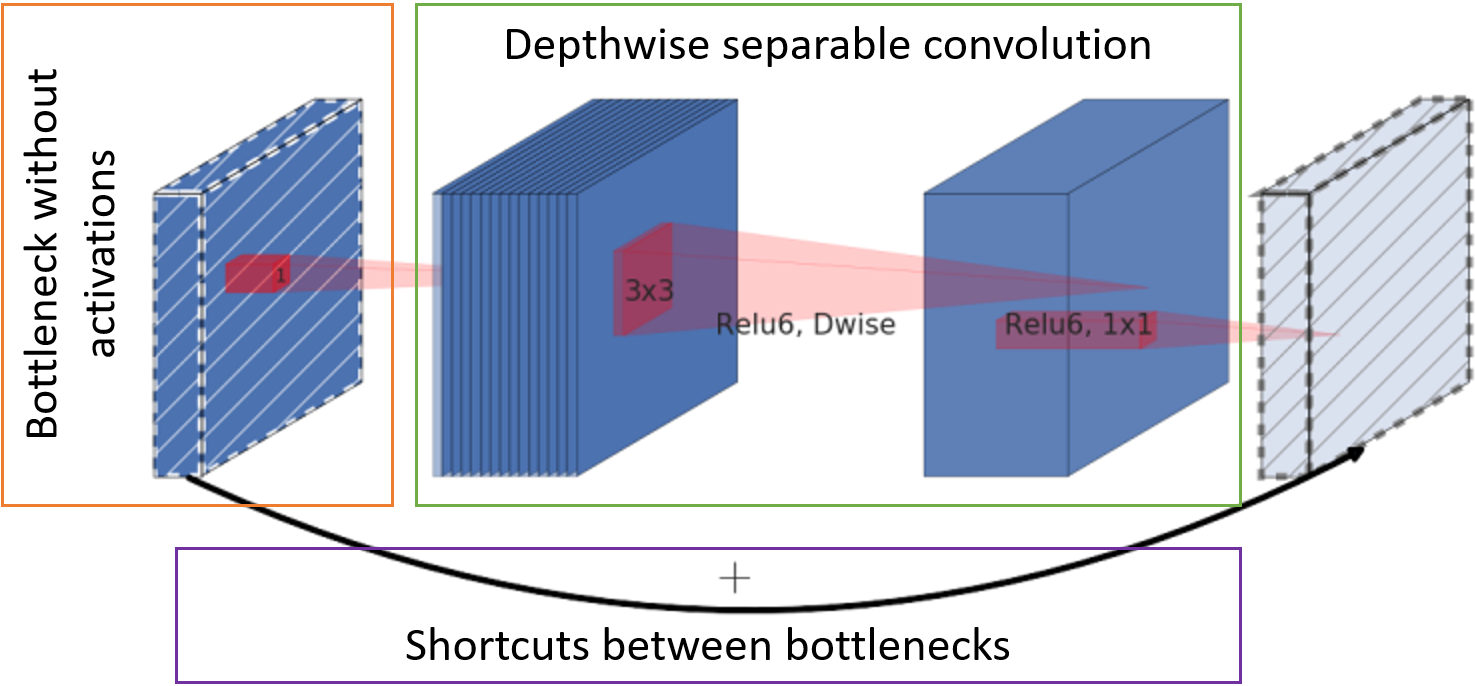 الوحدة الأساسية MobileNetV2
الوحدة الأساسية MobileNetV2
مما تسبب في الشبكة العصبية
باستخدام الأساليب المذكورة أعلاه ، توصلنا إلى بنية الشبكة التالية:
- نحن نستخدم شرائح وروابط من SegLink
- استبدل VGG بجهاز MobileNetV2 أقل حدة
- قلل من عدد مقاييس البحث عن النص من 6 إلى 5 للسرعة
 شبكة ملخص البحث عن النص
شبكة ملخص البحث عن النص
فك تشفير القيم في كتل بنية الشبكة
يشار إلى خطوة الخطوة والرقم الأساسي للقنوات في القنوات على أنها <stride> c <القنوات> ، على التوالي. على سبيل المثال ، يعني s2c32 32 قناة بإزاحة 2. يتم الحصول على العدد الفعلي للقنوات في طبقات الالتفاف عن طريق ضرب الرقم الأساسي الخاص بهم بعامل تحجيم α ، والذي يسمح لك بمحاكاة "سمك" مختلفة للشبكة بسرعة. يوجد أدناه جدول به عدد المعلمات في الشبكة وفقًا α.

نوع كتلة:
- Conv2D - عملية الالتواء كاملة.
- D-wise Conv - الإلتفاف القابل للفصل لكل قناة ؛
- كتل - مجموعة من كتل MobileNetV2 ؛
- الإخراج - الالتواء للحصول على طبقة الإخراج. تشير القيم العددية للنوع NxN إلى حجم الحقل التلقي للبكسل.
كدالة تنشيط ، تستخدم الكتل ReLU6.

طبقة الإخراج لديها 31 قناة:
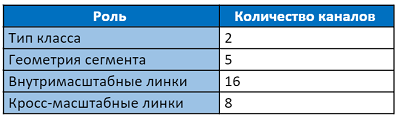
تصوّت القناتان الأوليان لطبقة الإخراج على أن ينتمي البيكسل إلى النص وليس إلى النص. تحتوي القنوات الخمس التالية على معلومات لإعادة هيكلة قطاع بدقة: تحولات رأسية وأفقية بالنسبة إلى موضع البيكسل ، وعوامل العرض والارتفاع (بما أن القطعة غير مربعة عادةً) ، وزاوية الدوران. تشير 16 قيمة للوصلات داخل القناة إلى ما إذا كان هناك اتصال بين ثمانية بكسلات مجاورة على نفس المقياس. أخبرنا آخر 8 قنوات عن وجود روابط لأربعة بكسل من المقياس السابق (المقياس السابق دائمًا أكبر مرتين). كل القيم 2 من قطاعات ، يتم تطبيع الروابط داخل وعبر النطاق بواسطة وظيفة softmax. لا يحتوي الوصول إلى النطاق الأول على روابط عبر النطاق.
تجميع الكلمات
تتوقع الشبكة ما إذا كانت شريحة معينة وجيرانها ينتمون إلى النص. يبقى لجمعها في الكلمات.
للبدء ، ادمج جميع القطاعات المرتبطة بالارتباطات. للقيام بذلك ، نؤلف رسمًا بيانيًا حيث تكون الرؤوس جميعها قطاعات بجميع المقاييس ، وتكون الحواف عبارة عن روابط. ثم نجد المكونات المتصلة بالرسم البياني. لكل مكون ، أصبح من الممكن الآن حساب المستطيل المحاط بالكلمة كما يلي:
- نحسب زاوية دوران كلمة θ
- أو كقيمة متوسطة للتنبؤات بزاوية دوران الأجزاء ، إذا كان هناك الكثير منها ،
- أو كما زاوية دوران الخط الذي حصل عليه الانحدار على نقاط مراكز القطاعات ، إذا كان هناك عدد قليل من القطاعات.
- يتم تحديد مركز الكلمة كمركز للكتلة في نقاط المركز للقطاعات.
- قم بتوسيع جميع الشرائح بواسطة -θ لترتيبها أفقيًا. العثور على حدود الكلمة.
- يتم تحديد الحدود اليسرى واليمنى للكلمة كحدود للجزءين الأيسر والأقصى ، على التوالي.
- للحصول على حدود الكلمة العليا ، يتم فرز الأجزاء حسب ارتفاع الحافة العليا ، ويتم قطع 20٪ من الأجزاء العليا ، ويتم تحديد قيمة الشريحة الأولى من القائمة المتبقية بعد التصفية.
- يتم الحصول على الحد الأدنى من أقل القطاعات بقطع قدره 20٪ من الأدنى ، عن طريق القياس مع الحد العلوي.
- أدر المستطيل الناتج إلى θ.
الحل النهائي يسمى
FaSTExt : النازع السريع والنص الصغير [3]
وقت التجربة!
تفاصيل التدريب
تم اختيار الشبكة نفسها ومعلماتها للعمل الجيد على عينة داخلية كبيرة ، والتي تعكس السيناريو الرئيسي لاستخدام التطبيق على الهاتف - لقد صمم الكاميرا على كائن مع نص والتقاط صورة. اتضح أن شبكة كبيرة مع α = 1 يتجاوز الجودة في الإصدار مع α = 0.5 بنسبة 2 ٪ فقط. هذه العينة ليست في المجال العام ، لذلك ، من أجل الوضوح ، اضطررت إلى تدريب الشبكة على العينة العامة
ICDAR2013 ، والتي تكون فيها ظروف التصوير مماثلة
لظروفنا . العينة صغيرة جدًا ، لذلك تم تدريب الشبكة مسبقًا على كمية هائلة من البيانات الاصطناعية من
SynthText في مجموعة البيانات Wild . استغرقت عملية التدريب المسبق حوالي 20 يومًا من العمليات الحسابية لكل تجربة على GTX 1080 Ti ، وبالتالي ، تم فحص تشغيل الشبكة على البيانات العامة فقط للخيارات α = 0.75 و 1 و 2.
كمحسّن ، تم استخدام إصدار
AMSGrad من آدم.
وظائف الخطأ:
- عبر إنتروبيا لتصنيف القطاعات والروابط ؛
- Huber فقدان وظيفة لقطاع الهندسة.
النتائج
فيما يتعلق بجودة أداء الشبكة في السيناريو المستهدف ، يمكننا القول إنها لا تتخلف كثيراً عن المنافسين من حيث الجودة ، بل إنها تتفوق على بعضها. MS هي شبكة ثقيلة متعددة المنافسين.
 * في مقال "الشرق" لم تكن هناك نتائج على العينة التي نحتاجها ، لذلك أجرينا التجربة بأنفسنا.
* في مقال "الشرق" لم تكن هناك نتائج على العينة التي نحتاجها ، لذلك أجرينا التجربة بأنفسنا.تُظهر الصورة أدناه مثالًا عن كيفية عمل FaSTExt على الصور من ICDAR2013. يوضح السطر الأول أن الأحرف المضيئة للكلمة ESPMOTO لم يتم تعليمها ، لكن الشبكة تمكنت من العثور عليها. النسخة الأقل رحابة مع α = 0.75 تعاملت مع نص صغير أسوأ من الإصدارات الأكثر "سميكة". يعرض الخط السفلي مرة أخرى عيوب الترميز في العينة مع النص المفقود في الانعكاس. FaSTExt في نفس الوقت يرى مثل هذا النص.

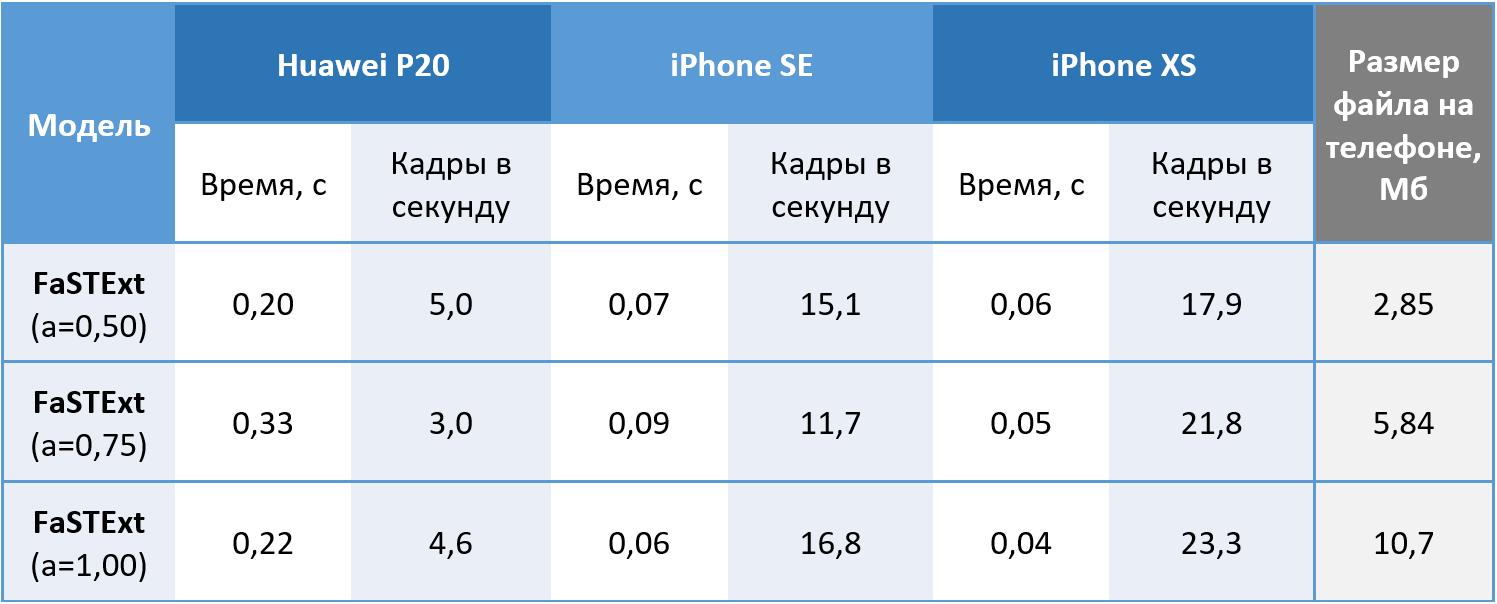
لذلك ، فإن الشبكة تؤدي مهامها. يبقى للتحقق ما إذا كان يمكن فعلا استخدامها على الهواتف؟ تم إطلاق النماذج على 512 × 512 صورة ملونة على Huawei P20 باستخدام وحدة المعالجة المركزية وعلى iPhone SE و iPhone XS باستخدام GPU ، لأن نظام التعلم الآلي الخاص بنا لا يزال يسمح باستخدام GPU على iOS فقط. القيم التي تم الحصول عليها عن طريق المتوسط 100 يبدأ. على Android ، تمكنا من تحقيق سرعة 5 إطارات في الثانية مقبولة لمهمتنا. أظهر جهاز iPhone XS تأثيرًا مثيرًا للاهتمام مع انخفاض متوسط الوقت اللازم لإجراء العمليات الحسابية أثناء تعقيد الشبكة. يقوم جهاز iPhone العصري باكتشاف النص بأقل قدر من التأخير ، والذي يمكن تسميته النصر.
مراجع
[1] B. Shi و X. Bai و S. Belongie ، "اكتشاف النص الموجه في الصور الطبيعية عن طريق ربط القطاعات" ، هاواي ، 2017.
رابط[2] M. Sandler و A. Howard و M. Zhu و A. Zhmoginov و L.-C. تشن ، "MobileNetV2: البقايا المقلوبة والاختناقات الخطية" ، سولت ليك سيتي ، 2018.
رابط[3] A. Filonenko، K. Gudkov، A. Lebedev، N. Orlov and I. Zagaynov، "FastExt: Quick and Small Text Extractor،" في ورشة العمل الدولية الثامنة حول تحليل المستندات والوثائق المستندة إلى الكاميرا ، سيدني ، 2019 .
صلة[4] Z. Zhang و C. Zhang و W. Shen و C. Yao و W. Liu و X. Bai ، "اكتشاف نص متعدد الاتجاهات مع شبكات تلافيفية بالكامل" ، لاس فيجاس ، 2016.
link[5] X. Zhou و C. Yao و H. Wen و Y. Wang و S. Zhou و W. He و J. Liang ، "EAST: أداة كشف نص المشهد بكفاءة ودقة" ، في مؤتمر IEEE لعام 2017 حول الكمبيوتر رؤية ونمط ، هونولولو ، 2017.
رابط[6] M. Liao، Z. Zhu، B. Shi، G.-s. Xia و X. Bai ، "الانحدار الحساسة للدوران لكشف نص المشهد الموجه" ، في مؤتمر IEEE / CVF 2018 حول رؤية الكمبيوتر ونمطه ، سولت ليك سيتي ، 2018.
رابط[7] X. Liu و D. Liang و S. Yan و D. Chen و Y. Qiao و J. Yan ، "Fots: اكتشاف نص موجه سريعًا باستخدام شبكة موحدة" ، في مؤتمر IEEE / CVF لعام 2018 حول رؤية الكمبيوتر و نمط ، سولت ليك سيتي ، 2018.
رابطمجموعة رؤية الكمبيوتر