مؤتمر هبر - القصة لاول مرة. لقد اعتدنا أن نعقد محمصة الأحداث الكبيرة التي تستوعب من 300 إلى 400 شخص ، لكننا قررنا الآن أن الاجتماعات المواضيعية الصغيرة ستكون ذات صلة ، والتي يمكنك أيضًا تحديد اتجاهها - على سبيل المثال ، في التعليقات. تم عقد المؤتمر الأول لهذا التنسيق في يوليو وتم تكريسه لدعم التطوير. استمع المشاركون إلى تقارير حول ميزات الانتقال من الخلفية إلى ML وعلى تصميم خدمة Quadrupel على بوابة خدمات الدولة ، وشاركوا أيضًا في مائدة مستديرة مخصصة لـ Serverless. بالنسبة لأولئك الذين لم يتمكنوا من حضور الحدث شخصيًا ، في هذا المنشور ، نروي الأكثر إثارة للاهتمام.

من تطوير الخلفية إلى التعلم الآلي
ماذا يفعل مهندسو بيانات ML؟ ما هي أوجه التشابه والاختلاف بين مهام مطور الواجهة الخلفية ومهندس ML؟ ما المسار الذي تحتاجه للذهاب لتغيير المهنة الأولى إلى الثانية؟ صرح بذلك ألكساندر بارينوف ، الذي دخل في التعلم الآلي بعد 10 سنوات من الخلفية.
 الكسندر بارينوف
الكسندر بارينوفاليوم ، يعمل ألكساندر كمهندس لأنظمة رؤية الكمبيوتر في X5 Retail Group ويساهم في المشاريع المفتوحة المصدر المتعلقة برؤية الكمبيوتر والتعلم العميق (github.com/creafz). تم تأكيد مهاراته من خلال مشاركته في أفضل 100 عالمًا من Kaggle Master (kaggle.com/creafz) - وهو النظام الأساسي الأكثر شعبية الذي يستضيف مسابقات التعلم الآلي.
لماذا التحول إلى التعلم الآلي
منذ عام ونصف ، وصف جيف دين ، رئيس Google Brain ، دراسة Google المتعمقة لمشروع أبحاث الذكاء الاصطناعي من Google ، كيف تم استبدال نصف مليون سطر من الشفرة في Google Translate بشبكة عصبية باستخدام Tensor Flow ، والذي يتكون من 500 سطر فقط. بعد تدريب الشبكة ، نمت جودة البيانات وتم تبسيط البنية التحتية. يبدو أن هذا هو مستقبلنا المشرق: لم تعد هناك حاجة لكتابة الكود ، فقط صنع الخلايا العصبية ورميها بالبيانات. لكن في الممارسة العملية ، كل شيء أكثر تعقيدًا.
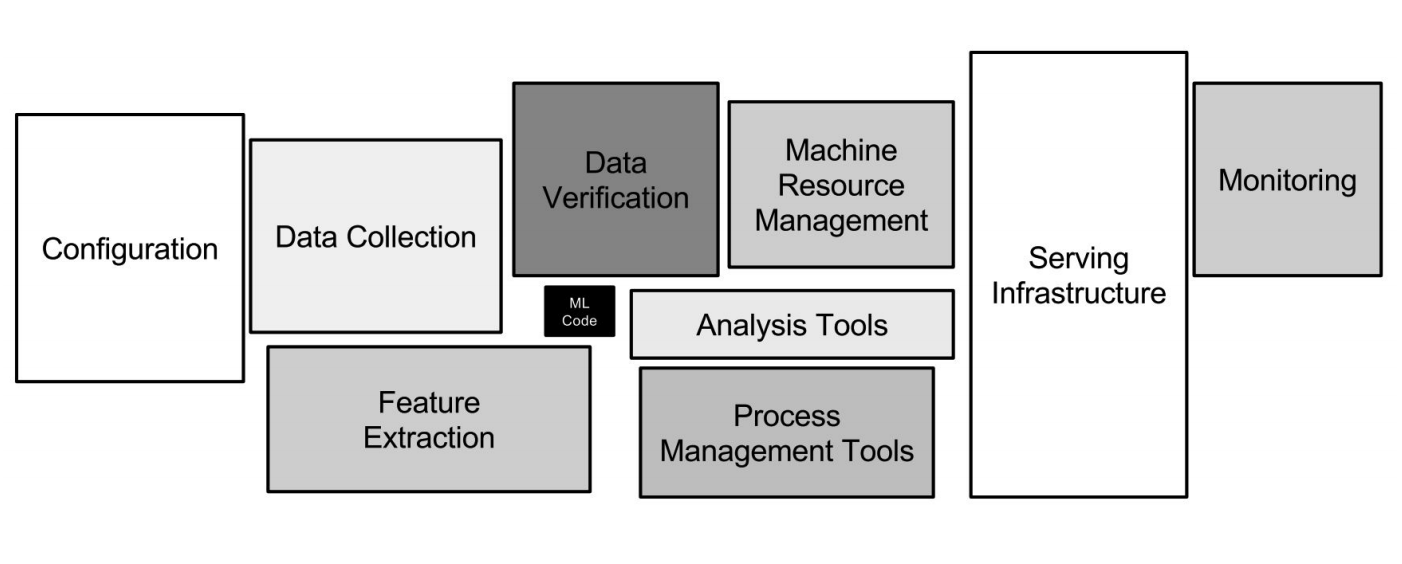 جوجل ML البنية التحتية
جوجل ML البنية التحتيةالشبكات العصبية هي مجرد جزء صغير من البنية التحتية (صندوق أسود صغير في الصورة أعلاه). هناك حاجة إلى العديد من الأنظمة الإضافية لتلقي البيانات ومعالجتها وتخزينها وفحص الجودة ، وما إلى ذلك ، نحتاج إلى بنية تحتية للتدريب ، ونشر شفرة تعلم الآلة في الإنتاج ، واختبار هذا الرمز. كل هذه المهام تشبه ما يفعله مطورو الواجهة الخلفية.
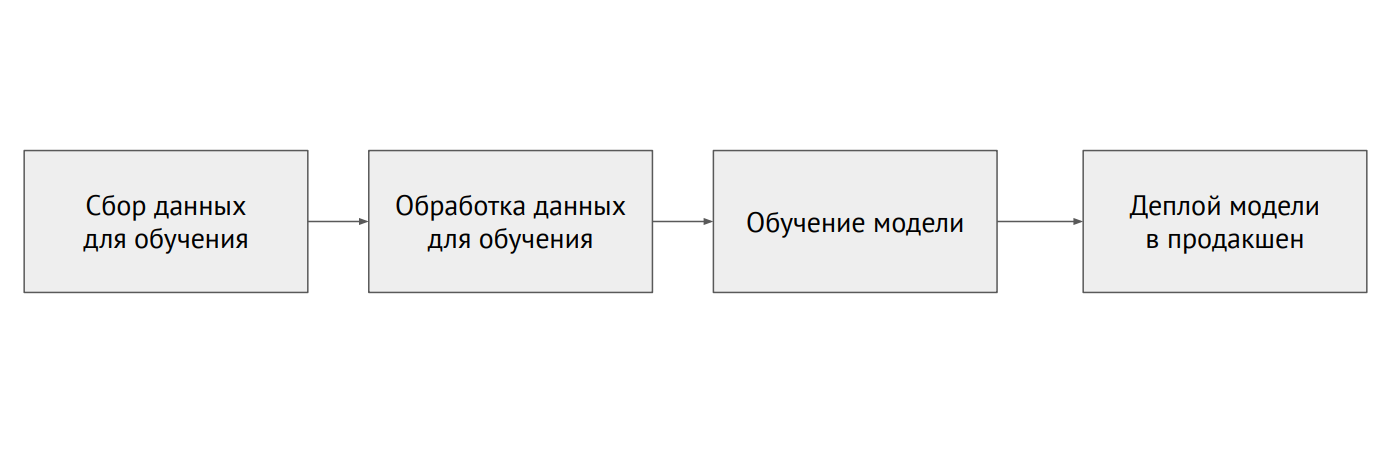 عملية التعلم الآلي
عملية التعلم الآليما هو الفرق بين ML والخلفية
في البرمجة الكلاسيكية ، نكتب الكود ، وهذا يملي سلوك البرنامج. في ML ، لدينا رمز نموذج صغير والعديد من البيانات التي نسقط بها النموذج. تعد البيانات في ML مهمة جدًا: يمكن للنموذج نفسه ، الذي تم تدريبه باستخدام بيانات مختلفة ، إظهار نتائج مختلفة تمامًا. المشكلة هي أن البيانات تكون مجزأة دائمًا وتكمن في أنظمة مختلفة (قواعد البيانات العلائقية وقواعد بيانات NoSQL والسجلات والملفات).
 إصدار البيانات
إصدار البياناتلا يتطلب ML إصدار الكود فقط ، كما في التطور الكلاسيكي ، ولكن أيضًا البيانات: من الضروري أن نفهم بوضوح ما تم تدريب النموذج عليه. يمكنك استخدام مكتبة التحكم في إصدار بيانات العلوم الشائعة (dvc.org) لهذا الغرض.
 ترميز البيانات
ترميز البياناتالمهمة التالية هي ترميز البيانات. على سبيل المثال ، حدد كل الكائنات الموجودة في الصورة أو قل الفئة التي تنتمي إليها. يتم ذلك عن طريق خدمات خاصة مثل Yandex.Tolki ، العمل الذي يبسط إلى حد كبير توافر API. تنشأ الصعوبات بسبب "العامل البشري": من الممكن تحسين جودة البيانات وتقليل الأخطاء عن طريق إسناد نفس المهمة إلى العديد من الفنانين.
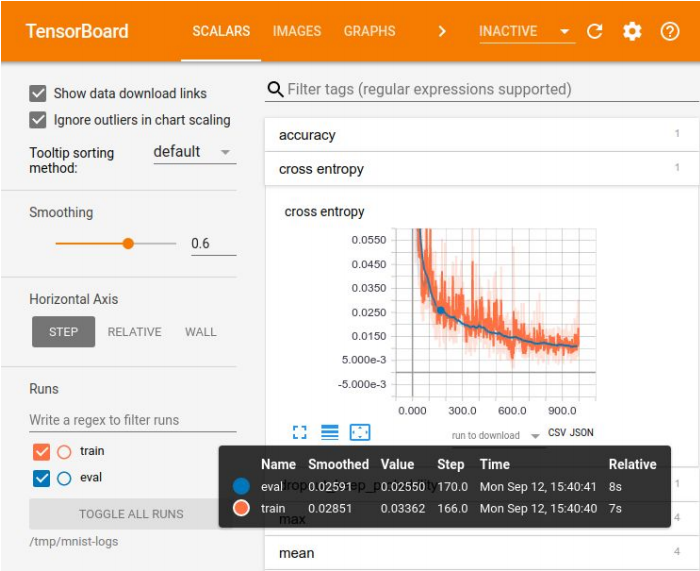 التصور في تينسور المجلس
التصور في تينسور المجلسيعد تسجيل التجارب ضروريًا لمقارنة النتائج واختيار أفضل نموذج لبعض المقاييس. للتصور ، هناك مجموعة كبيرة من الأدوات - على سبيل المثال ، Tensor Board. ولكن لا توجد طرق مثالية لتخزين التجارب. في الشركات الصغيرة ، غالبًا ما يحصلون عليها من خلال لوحة excel ، وفي الشركات الكبيرة يستخدمون منصات خاصة لتخزين النتائج في قاعدة البيانات.
 هناك العديد من المنصات للتعلم الآلي ، ولكن لا تغطي أي منها حتى 70٪ من الاحتياجات
هناك العديد من المنصات للتعلم الآلي ، ولكن لا تغطي أي منها حتى 70٪ من الاحتياجاتتتعلق المشكلة الأولى التي يجب عليك معالجتها عند إحضار نموذج مدرّب بالإنتاج بأداة عالم البيانات المفضلة لديك - Jupyter Notebook. لا توجد أي وحدات نمطية فيه ، أي أن الخرج هو مثل "سقوط القدم" من الكود الذي لا ينقسم إلى أجزاء منطقية - وحدات. كل شيء مختلط: فئات ، وظائف ، تكوينات ، إلخ. هذا الرمز يصعب إصداره واختباره.
كيف تتعامل معها؟ يمكنك طرح Netflix وإنشاء نظام أساسي خاص بك يسمح لك بتشغيل هذه الأجهزة المحمولة مباشرة في الإنتاج ونقل البيانات إليها والحصول على النتيجة. يمكنك إجبار المطورين الذين يقومون بتحويل النموذج إلى إنتاج لإعادة كتابة الكود بشكل طبيعي ، وتقسيمه إلى وحدات. ولكن من خلال هذا النهج ، من السهل ارتكاب خطأ ، ولن يعمل النموذج على النحو المنشود. لذلك ، فإن الخيار المثالي هو حظر استخدام Jupyter Notebook لرمز الطراز. إذا ، بالطبع ، وافق علماء البيانات على هذا.
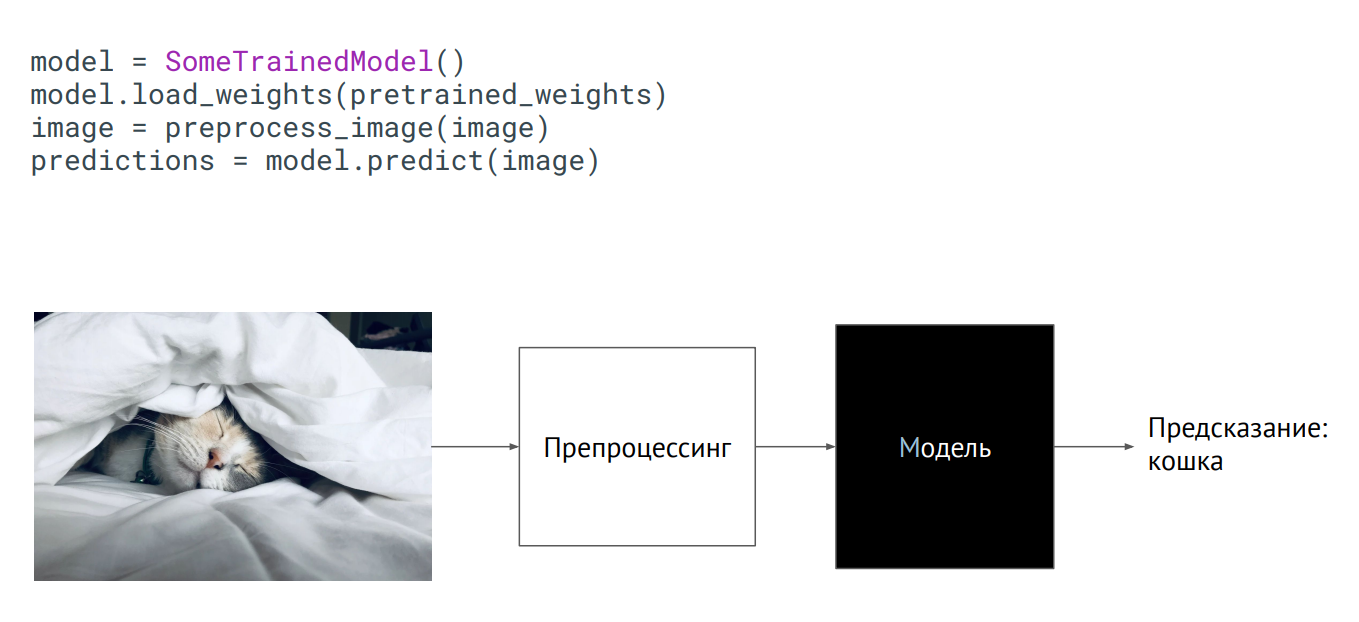 نموذج كمربع أسود
نموذج كمربع أسودأسهل طريقة لإحضار نموذج للإنتاج هي استخدامه كصندوق أسود. لديك فئة معينة من النموذج ، تم تمرير أوزان النموذج (معلمات الخلايا العصبية في الشبكة المدربة) ، وإذا قمت بتهيئة هذا الفصل (استدعاء طريقة التنبؤ ، ووضع صورة عليها) ، فسيحصل الإخراج على نوع من التنبؤ. ما يحدث في الداخل لا يهم.
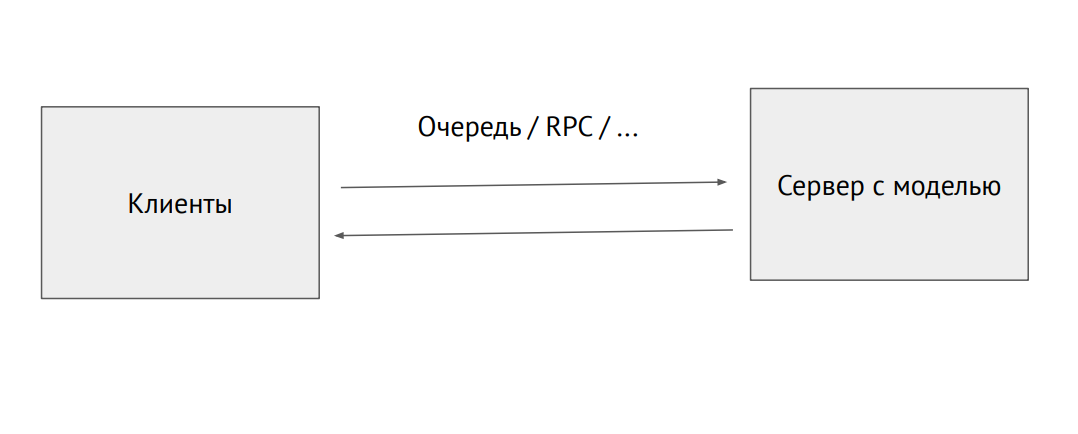 فصل عملية الخادم باستخدام نموذج
فصل عملية الخادم باستخدام نموذجيمكنك أيضًا التقاط عملية منفصلة وإرسالها عبر قائمة انتظار RPC (مع صور أو بيانات مصدر أخرى. عند الإخراج ، سنتلقى تنبؤات.
مثال على استخدام النموذج في Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
المشكلة في هذا النهج هي الحد من الأداء. لنفترض أن لدينا شفرة Phyton كتبها علماء البيانات التي تبطئ ، ونحن نريد الضغط على أقصى أداء. للقيام بذلك ، يمكنك استخدام الأدوات التي تقوم بتحويل الكود إلى أصلي أو تحويله إلى إطار آخر ، يتم تشديده للإنتاج. هناك أدوات من هذا القبيل لكل إطار ، ولكن لا توجد أدوات مثالية ، سيكون عليك الانتهاء منها بنفسك.
البنية التحتية في ML هي نفسها كما في الخلفية العادية. هناك Docker و Kubernetes ، فقط ل Docker تحتاج إلى ضبط وقت تشغيل NVIDIA ، والذي يسمح للعمليات داخل الحاوية بالوصول إلى بطاقات الفيديو في المضيف. يحتاج Kubernetes إلى مكون إضافي حتى يتمكن من إدارة الخوادم باستخدام بطاقات الفيديو.
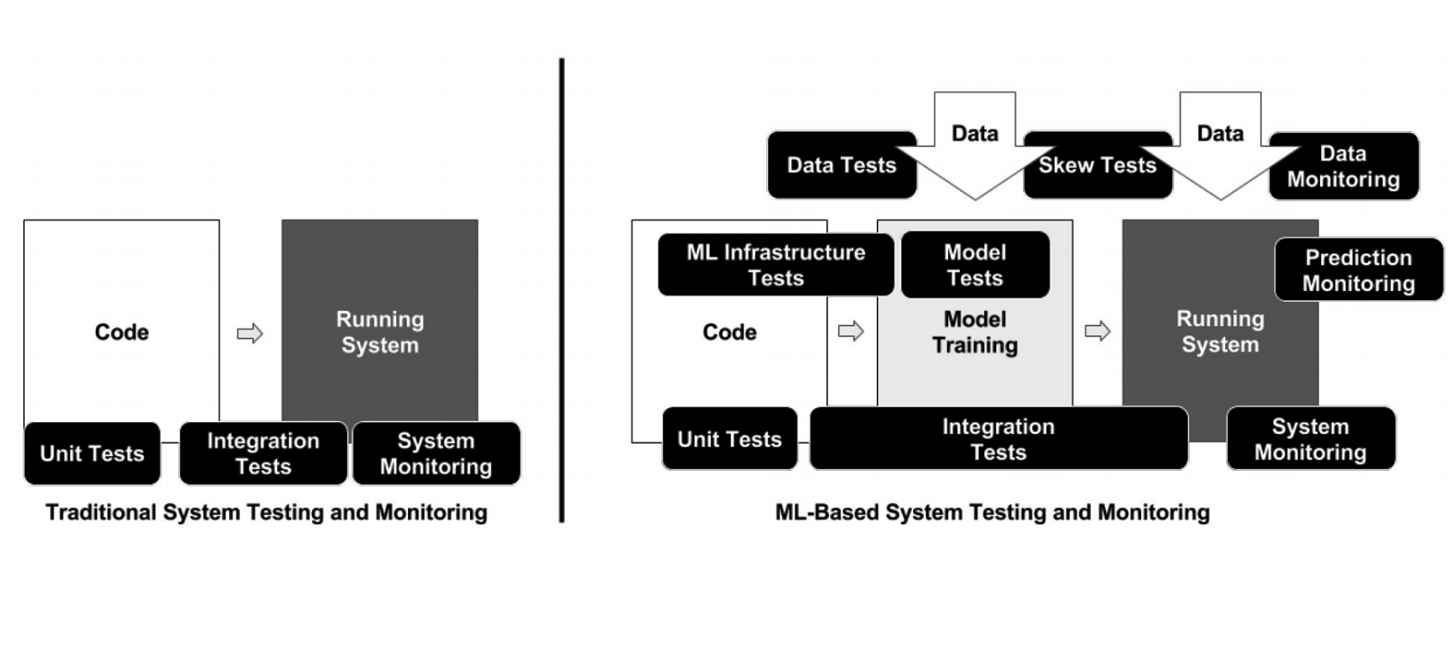
على عكس البرمجة الكلاسيكية ، في حالة ML ، تحتوي البنية التحتية على الكثير من العناصر المتحركة المختلفة التي يجب فحصها واختبارها - على سبيل المثال ، رمز معالجة البيانات ، وخط أنابيب التدريب النموذجي والإنتاج (انظر الرسم البياني أعلاه). من المهم اختبار الكود الذي يربط أجزاء مختلفة من خطوط الأنابيب: هناك الكثير من القطع ، وغالباً ما تنشأ مشاكل على حدود الوحدات.
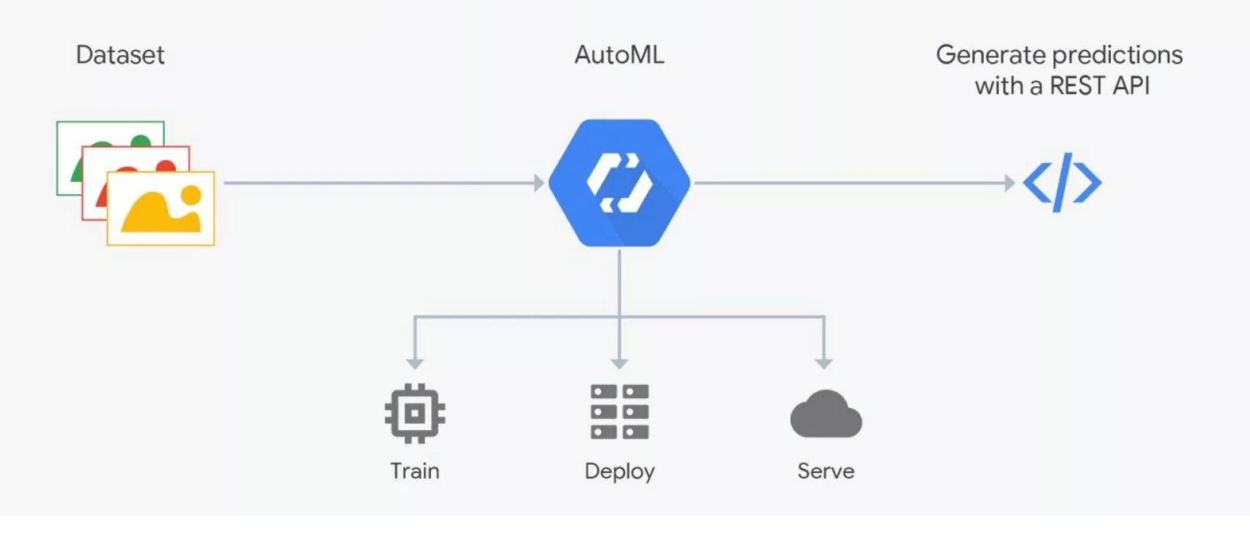 كيف يعمل AutoML
كيف يعمل AutoMLتعد خدمات AutoML بتحديد أفضل نموذج لأهدافك وتدريبه. ولكن عليك أن تفهم: في بيانات ML مهمة للغاية ، والنتيجة تعتمد على إعدادها. الناس ترمز ، وهو محفوف بالأخطاء. وبدون رقابة صارمة ، يمكن أن تنفد القمامة ، لكن الأتمتة لا تنجح بعد ؛ التحقق من الخبراء - هناك حاجة لعلماء البيانات. هذا هو المكان "AutoML" "فواصل". ولكن يمكن أن يكون مفيدًا لاختيار البنية - عندما تكون قد قمت بالفعل بإعداد البيانات وتريد إجراء سلسلة من التجارب للعثور على أفضل نموذج.
كيفية الوصول إلى التعلم الآلي
يعد الحصول على ML أسهل إذا كنت تتطور في Python ، والذي يستخدم في جميع أطر التعلم العميقة (والأطر العادية). هذه اللغة مطلوبة عمليا لهذا المجال من النشاط. يستخدم C ++ لبعض المهام مع رؤية الكمبيوتر - على سبيل المثال ، في أنظمة التحكم في المركبات غير المأهولة. جافا سكريبت وشل - للتصور وأشياء غريبة مثل إطلاق الخلايا العصبية في المتصفح. يتم استخدام Java و Scala عند العمل مع Big Data وللتعلم الآلي. R و Julia محبوبان من قبل أشخاص يقومون بالإحصاءات.
الحصول على خبرة عملية للبدء هو الأكثر ملاءمة في Kaggle ، المشاركة في إحدى مسابقات المنصة تمنح أكثر من عام من دراسة النظرية. على هذا النظام الأساسي ، يمكنك وضع تعليمات برمجية من شخص ما والتعليق عليها ومحاولة تحسينها وتحسين أهدافك. تؤثر رتبة المكافأة على Kaggle على راتبك.
خيار آخر هو الذهاب كمطور خلفي لفريق ML. يوجد الآن الكثير من الشركات الناشئة المشاركة في التعلم الآلي ، والتي تكتسب فيها الخبرة من خلال مساعدة الزملاء في حل مشكلاتهم. أخيرًا ، يمكنك الانضمام إلى أحد مجتمعات عالم البيانات - علوم البيانات المفتوحة (ods.ai) وغيرها.
وضع المتحدث معلومات إضافية حول الموضوع على https://bit.ly/backend-to-ml
"رباعي" - خدمة الإخطارات المستهدفة للبوابة "خدمات الدولة"

يفغيني سميرنوف
المتحدث التالي كان يفغيني سميرنوف ، رئيس قسم تطوير البنية التحتية للحكومة الإلكترونية ، الذي تحدث عن Quadrupel. هذه خدمة إعلام مستهدفة لبوابة Gosuslugi (gosuslugi.ru) ، وهي المورد الحكومي الأكثر زيارة على الإنترنت الروسية. يبلغ عدد الحضور اليومي 2.6 مليون ، الكل في الكل ، 90 مليون مستخدم مسجل على الموقع ، 60 مليون منهم مؤكد. الحمل على API البوابة هو 30 ألف RPS.
 التقنيات المستخدمة في الخلفية Gosuslug
التقنيات المستخدمة في الخلفية Gosuslug"Quadruple" هي خدمة إشعار عنوان ، بمساعدة المستخدم الذي يتلقى عرض خدمة في اللحظة المناسبة له من خلال إعداد قواعد معلومات خاصة. كانت المتطلبات الرئيسية في تطوير الخدمة هي الإعدادات المرنة والوقت الكافي للبريد.
كيف يعمل الرباعي؟

يُظهر الرسم البياني أعلاه إحدى قواعد "الرباعي" على مثال موقف مع الحاجة إلى استبدال رخصة القيادة. أولاً ، تبحث الخدمة عن المستخدمين الذين تنتهي صلاحية تاريخ انتهاء الصلاحية خلال شهر. وضعوا لافتة مع عرض لتلقي الخدمة المقابلة وإرسال رسالة بريد إلكتروني. بالنسبة لأولئك المستخدمين الذين انتهت صلاحيتهم بالفعل ، يتم تغيير الشعار والبريد الإلكتروني. بعد تبادل الحقوق بنجاح ، يتلقى المستخدم إعلامات أخرى - مع اقتراح لتحديث البيانات في الشهادة.
من وجهة نظر تقنية ، هذه نصوص رائعة يتم كتابة التعليمات البرمجية فيها. في المدخلات - البيانات ، في الإخراج - صواب / خطأ ، مطابقة / غير متطابقة. بشكل إجمالي ، هناك أكثر من 50 قاعدة - بدءًا من تحديد تاريخ ميلاد المستخدم (التاريخ الحالي يساوي تاريخ ميلاد المستخدم) إلى المواقف الصعبة. وفقًا لهذه القواعد ، يتم تحديد حوالي مليون مباراة - الأشخاص الذين يحتاجون إلى إخطار.
 قنوات الإعلام الرباعي
قنوات الإعلام الرباعيتحت غطاء محرك السيارة Quadrupel توجد قاعدة بيانات يتم تخزين بيانات المستخدم بها ، وثلاثة تطبيقات:
- تم تصميم العامل لتحديث البيانات.
- تلتقط واجهة برمجة تطبيقات Rest API وتعطي الشعارات نفسها للبوابة وتطبيقات الهاتف المحمول.
- جدولة تطلق إعادة تحميل لافتة أو البريد بالجملة.
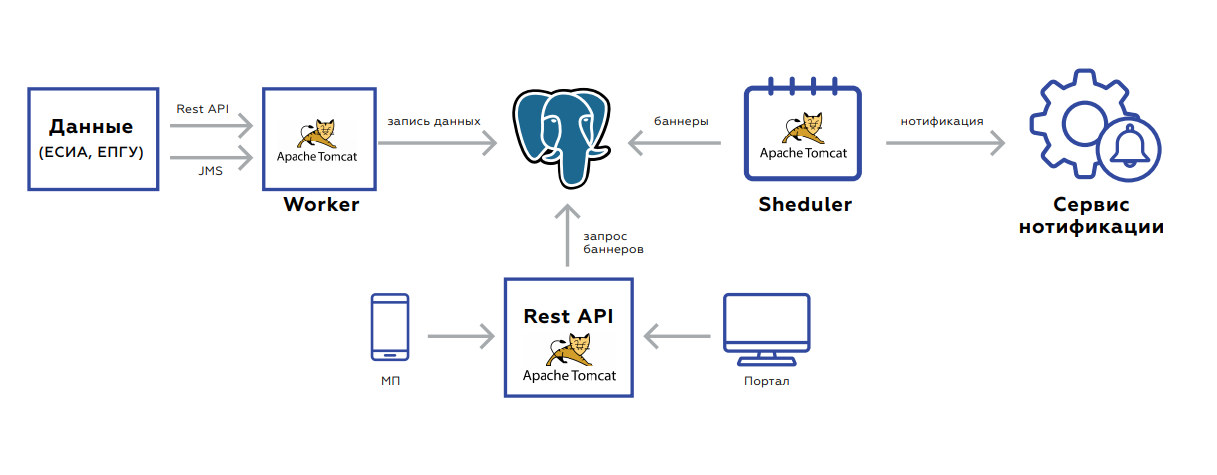
الخلفية موجهة نحو الحدث لتحديث البيانات. واجهات اثنين - الراحة أو JMS. هناك العديد من الأحداث ، قبل حفظها ومعالجتها ، يتم تجميعها حتى لا تقدم طلبات غير ضرورية. تبدو قاعدة البيانات نفسها ، وهي اللوحة التي يتم تخزين البيانات بها ، مثل تخزين قيمة المفتاح - مفتاح المستخدم والقيمة نفسها: إشارات تشير إلى وجود أو عدم وجود مستندات ذات صلة ، وفترة صلاحيتها ، وإحصائيات مجمعة بترتيب الخدمات بواسطة هذا المستخدم ، وهكذا.

بعد حفظ البيانات ، يتم تعيين المهمة في JMS بحيث يتم إعادة فرز الشعارات فورًا - يجب عرض ذلك على الويب. يبدأ النظام في الليل: في JMS يتم طرح المهام على فترات المستخدم ، والتي تحتاج إلى إعادة فرز القواعد وفقًا لها. يتم التقاط هذا من قبل فرز الأصوات. علاوة على ذلك ، تقع نتائج المعالجة في قائمة الانتظار التالية ، والتي تقوم إما بحفظ الشعارات في قاعدة البيانات ، أو إرسال المهام إلى المستخدم لإخطار المستخدم. تستغرق العملية من 5 إلى 7 ساعات ، وهي قابلة للتطوير بسهولة نظرًا لحقيقة أنه يمكنك دائمًا إما إسقاط المعالجات أو رفع مثيلات مع معالجات جديدة.

الخدمة تعمل بشكل جيد. لكن حجم البيانات ينمو مع زيادة عدد المستخدمين. يؤدي ذلك إلى زيادة الحمل على قاعدة البيانات - حتى مع مراعاة حقيقة أن واجهة برمجة تطبيقات Rest ينظر إلى النسخة المتماثلة. النقطة الثانية هي JMS ، والتي ، كما اتضح ، ليست مناسبة للغاية بسبب استهلاك الذاكرة الكبيرة. هناك خطر كبير من تجاوز قائمة الانتظار مع تعطل JMS وتوقف المعالجة. من المستحيل رفع JMS بعد ذلك دون تنظيف السجلات.
تم التخطيط لحل المشكلات باستخدام التقسيم ، مما سيسمح بموازنة الحمل على القاعدة. هناك أيضًا خطط لتغيير نظام تخزين البيانات ، وتغيير JMS إلى Kafka - وهو حل أكثر تحملاً للأخطاء من شأنه حل مشاكل الذاكرة.
Backend-as-a-Service Vs. Serverless
 من اليسار إلى اليمين: ألكساندر بورغارت وأندريه توميلينكو ونيكولاي ماركوف وآرا إسرائيليان
من اليسار إلى اليمين: ألكساندر بورغارت وأندريه توميلينكو ونيكولاي ماركوف وآرا إسرائيليانالخلفية كخدمة أو حل serverless؟ شارك الأشخاص التالية أسماؤهم في مناقشة هذه القضية الملحة في اجتماع المائدة المستديرة:
- آرا إسرائيليان ، CTO CTO ومؤسس Scorocode.
- نيكولاي ماركوف ، كبير مهندسي البيانات في مجموعة أبحاث Aligned.
- أندريه توميلينكو ، رئيس قسم التطوير RUVDS.
أدار المحادثة كبير المطورين ألكسندر بورغارت. نقدم المناقشة ، التي شارك فيها الجمهور ، في نسخة مختصرة.
- ما هو خادم في فهمك؟
أندريه : هذا نموذج حسابي - وظيفة Lambda يجب أن تعالج البيانات بحيث تعتمد النتيجة على البيانات فقط. جاء المصطلح من Google ، أو من Amazon وخدمة AWS Lambda التابعة لها. يسهل على الموفر معالجة هذه الوظيفة عن طريق تخصيص تجمع سعة لهذا الغرض. يمكن اعتبار المستخدمين المختلفين بشكل مستقل على نفس الخوادم.
نيكولاي : إذا كان الأمر بسيطًا ، فنحن ننقل جزءًا من البنية التحتية لتكنولوجيا المعلومات لدينا ، ومنطق العمل إلى السحابة ، إلى جهات خارجية.
آرا : من جانب المطورين - محاولة جيدة لتوفير الموارد ، من جانب المسوقين - لكسب المزيد من المال.
- Serverless - نفس الخدمات microservices؟
نيكولاي : لا ، Serverless هو أكثر تنظيم للهندسة المعمارية. Microservice هي وحدة ذرية لمنطق معين. Serverless هو نهج ، وليس "كيان منفصل".
Ara : وظيفة Serverless يمكن تعبئتها في microservice ، ولكن من هذا ستتوقف عن أن تكون Serverless ، تتوقف عن أن تكون وظيفة Lambda. في Serverless ، تبدأ الوظيفة فقط عند الطلب.
أندرو : إنها تختلف في وقت الحياة. أطلقنا ونسينا وظيفة Lambda. لقد عملت لمدة ثانيتين ، ويمكن للعميل التالي معالجة طلبه على جهاز فعلي آخر.
- ما هي المقاييس بشكل أفضل؟
Ara : مع التحجيم الأفقي ، تتصرف وظائف Lambda بنفس الطريقة تمامًا مثل الخدمات الميكروية.
نيكولاي : كم عدد النسخ المتماثلة التي تسألها - سيكون هناك الكثير منها ، لا توجد مشاكل مع التحجيم Serverless. صنعت Kubernetes مجموعة نسخ متماثلة ، وأطلقت 20 حالة "في مكان ما" ، وعاد 20 رابطًا مجهول الهوية إليك. المضي قدما!
- هل من الممكن كتابة خلفية على Serverless؟
أندرو : من الناحية النظرية ، ولكن ليس هناك نقطة في هذا. ستظل وظائف Lambda مقابل مستودع واحد - نحتاج إلى تقديم ضمان. على سبيل المثال ، إذا أجرى المستخدم معاملة معينة ، فعندئذٍ في المرة التالية التي يجب أن يراها: تم إكمال المعاملة ، تم إضافة الأموال. سيتم حظر جميع وظائف Lambda في هذه المكالمة. في الواقع ، ستتحول مجموعة من وظائف Serverless إلى خدمة واحدة بنقطة ضيقة واحدة للوصول إلى قاعدة البيانات.
- في أي مواقف يكون من المنطقي استخدام هندسة بدون خادم؟
أندرو : المهام التي لا يلزم تخزين مشترك - نفس التعدين ، blockchain. حيث تحتاج إلى حساب الكثير. إذا كان لديك الكثير من الطاقة الحاسوبية ، فيمكنك تحديد وظيفة مثل "حساب تجزئة شيء ما هناك ..." ولكن يمكنك حل مشكلة تخزين البيانات عن طريق أخذ وظائف Amazon و Lambda على سبيل المثال ، والتخزين الموزع. واتضح أنك تكتب خدمة منتظمة. سوف تصل وظائف Lambda إلى المستودع وتعطي نوعًا من الاستجابة للمستخدم.
نيكولاي : الحاويات التي تعمل في Serverless محدودة للغاية للموارد. هناك القليل من الذاكرة وكل شيء آخر. ولكن إذا كان لديك بنية أساسية منتشرة بالكامل على نوع من السحابة - Google و Amazon - وكان لديك عقد دائم معهم ، فهناك ميزانية لكل ذلك ، ومن ثم يمكنك استخدام حاويات بدون خادم لبعض المهام. من الضروري أن تكون موجودًا داخل هذه البنية التحتية تمامًا ، لأن كل شيء مصمم للاستخدام في بيئة معينة. وهذا هو ، إذا كنت مستعدًا لربط كل شيء بالبنية التحتية السحابية ، فيمكنك التجربة. الإضافة هي أنه ليس لديك لإدارة هذه البنية التحتية.
Ara : أن Serverless لا يتطلب منك إدارة Kubernetes ، Docker ، تثبيت Kafka ، وهلم جرا ، هو خداع ذاتي. نفس الأمازون وجوجل هم المدير ووضعوها. شيء آخر هو أن لديك جيش تحرير السودان. مع نفس النجاح ، يمكنك الاستعانة بمصادر خارجية لكل شيء ، وليس برمجته بنفسك.
أندرو : Serverless نفسه غير مكلف ، لكن عليك أن تدفع الكثير لبقية خدمات Amazon - على سبيل المثال ، قاعدة بيانات. لقد قام الأشخاص بالفعل برفع دعوى ضدهم بسبب قيامهم بتمزيق أموال مجنونة لبوابة API.
آرا : إذا كنا نتحدث عن المال ، فأنت بحاجة إلى التفكير في هذه النقطة: سيكون عليك نشر 180 درجة منهجية التطوير بالكامل في الشركة من أجل نقل جميع التعليمات البرمجية إلى Serverless. سوف يستغرق الكثير من الوقت والمال.
- هل هناك أي بدائل لائقة مدفوعة الأجر الأمازون وغوغل؟
نيكولاي : في Kubernetes ، أنت تبدأ نوعًا من العمل ، فهي تنجز وتموت - وهذا أمر لا يحتوي على خادم من وجهة نظر الهندسة المعمارية. إذا كنت ترغب في إنشاء منطق عمل مثير للاهتمام حقًا مع قوائم الانتظار ، مع القواعد ، فأنت بحاجة إلى التفكير أكثر حول هذا الموضوع. يتم حل كل هذا دون مغادرة Kubernetes. لن أبدأ في سحب تطبيق إضافي.
- ما مدى أهمية مراقبة ما يحدث في Serverless؟
آرا : يعتمد على بنية النظام ومتطلبات العمل. في الواقع ، يجب على المزود توفير التقارير التي ستساعد ديفو على اكتشاف المشاكل المحتملة.
نيكولاي : في أمازون يوجد CloudWatch ، حيث يتم دفق جميع السجلات ، بما في ذلك مع Lambda. دمج إعادة توجيه السجل واستخدام أداة منفصلة للعرض والتنبيه وما إلى ذلك. في الحاويات التي تبدأ ، يمكنك حشر وكلاء.
 - دعنا نلخص.
- دعنا نلخص.
أندرو : التفكير في وظائف Lambda مفيد. إذا قمت بإنشاء خدمة على الركبة - وليس خدمة microservice ، ولكنها تكتب طلبًا ، وتصل إلى قاعدة البيانات وترسل إجابة - تعمل وظيفة Lambda على حل عدد من المشكلات: تعدد العمليات ، وقابلية التوسع ، والمزيد. إذا تم بناء منطقك بهذه الطريقة ، فستتمكن في المستقبل من نقل Lambda إلى الخدمات الصغيرة أو استخدام خدمات الجهات الخارجية مثل Amazon. التكنولوجيا مفيدة ، فكرة مثيرة للاهتمام. ما مدى تبريرها للعمل ما زال سؤالًا مفتوحًا.
نيكولاي: Serverless هو أفضل لاستخدام لمهام التشغيل من حساب نوع من منطق الأعمال. أنا دائما تأخذ هذا كما معالجة الحدث. إذا كان لديك في أمازون ، إذا كنت في Kubernetes - نعم. خلاف ذلك ، سوف تضطر إلى بذل الكثير من الجهود لرفع خادم نفسك. تحتاج إلى مشاهدة حالة تجارية محددة. على سبيل المثال ، لديّ إحدى المهام الآن: عندما تظهر الملفات على قرص بتنسيق معين ، فأنت بحاجة إلى تحميلها على Kafka. يمكنني استخدام هذا الوكالة الدولية للطاقة أو Lambda. منطقيا ، كلاهما مناسب ، ولكن من الصعب تطبيق Serverless ، وأنا أفضل الطريقة الأكثر بساطة ، بدون Lambda.
آرا : Serverless - فكرة مثيرة للاهتمام ، وقابلة للتطبيق ، جميلة جدا من الناحية الفنية. عاجلاً أم آجلاً ، ستصل التكنولوجيا إلى النقطة التي سترتفع فيها أي وظيفة في أقل من 100 مللي ثانية. بعد ذلك ، من حيث المبدأ ، لن يكون هناك أي سؤال حول ما إذا كان وقت الانتظار حاسمًا بالنسبة للمستخدم. في الوقت نفسه ، فإن قابلية تطبيق Serverless ، كما قال الزملاء بالفعل ، يعتمد تمامًا على مهمة العمل.
نشكر الرعاة الذين ساعدونا كثيرا:
- مساحة مؤتمرات تكنولوجيا المعلومات " الربيع " وراء منصة المؤتمر.
- أجندة أحداث تكنولوجيا المعلومات Runet-ID ونشر " الإنترنت بالأرقام " لدعم المعلومات والأخبار.
- أكرونيس للهدايا.
- Avito للمشاركة في خلق.
- "جمعية الاتصالات الإلكترونية" RAEC للمشاركة والخبرات.
- الراعي الرئيسي ل RUVDS - لكل شيء!
