
مرحبا يا هبر! أقود عملية تطوير نظام
Vision - هذا هو نظامنا العام ، الذي يوفر الوصول إلى نماذج رؤية الكمبيوتر ويسمح لك بحل المهام مثل التعرف على الوجوه والأرقام والكائنات والمشاهد بأكملها. واليوم أود أن أخبر مثال Vision عن كيفية تنفيذ خدمة سريعة محملة للغاية باستخدام بطاقات الفيديو ، وكيفية نشرها وتشغيلها.
ما هي الرؤية؟
هذا هو أساسا API REST. يقوم المستخدم بإنشاء طلب HTTP مع صورة وإرساله إلى الخادم.
افترض أنك بحاجة إلى التعرف على وجه في صورة. يقوم النظام بالعثور عليه ، وقطعه ، واستخراج بعض الخصائص من الوجه ، وحفظه في قاعدة البيانات وتعيين رقم شرطي. على سبيل المثال ، person42. يقوم المستخدم بعد ذلك بتحميل الصورة التالية ، والتي تحتوي على نفس الشخص. يستخرج النظام الخصائص من وجهه ، ويبحث في قاعدة البيانات ويعيد الرقم الشرطي الذي تم تعيينه للشخص في البداية ، أي person42.
اليوم ، المستخدمون الرئيسيون لـ Vision هم مشاريع مختلفة لمجموعة Mail.ru. معظم الطلبات تأتي من البريد والسحابة.
في السحابة ، يكون لدى المستخدمين مجلدات يتم تحميل الصور فيها. تعمل السحابة على تشغيل الملفات عبر Vision وتجميعها في فئات. بعد ذلك ، يمكن للمستخدم الإبهام بسهولة من خلال صوره. على سبيل المثال ، عندما تريد عرض الصور للأصدقاء أو العائلة ، يمكنك العثور بسرعة على الصور التي تحتاج إليها.
تعد كل من Mail and Cloud خدمات كبيرة للغاية مع ملايين الأشخاص ، لذلك تقوم Vision بمعالجة مئات الآلاف من الطلبات في الدقيقة. أي أنها خدمة كلاسيكية عالية التحميل ، ولكن مع تطور: تحتوي على nginx ، وخادم الويب ، وقاعدة بيانات ، وقوائم الانتظار ، ولكن في أدنى مستوى من هذه الخدمة يتم الاستدلال - تشغيل الصور عبر الشبكات العصبية. إنه تشغيل الشبكات العصبية التي تستهلك معظم الوقت وتتطلب موارد. تتكون شبكات الحوسبة من سلسلة من عمليات المصفوفة التي تستغرق عادة وقتًا طويلاً على وحدة المعالجة المركزية ، لكنها متوازية تمامًا على وحدة معالجة الرسومات. لتشغيل الشبكات بشكل فعال ، نستخدم مجموعة من الخوادم التي تحمل بطاقات فيديو.
أريد في هذه المقالة مشاركة مجموعة من النصائح التي يمكن أن تكون مفيدة عند إنشاء مثل هذه الخدمة.
تطوير الخدمات
وقت المعالجة لطلب واحد
بالنسبة لنظام ذي حمولة ثقيلة ، يكون وقت معالجة طلب واحد وإنتاجية النظام مهمين. يتم توفير سرعة عالية في معالجة الاستعلام ، أولاً وقبل كل شيء ، عن طريق الاختيار الصحيح لهيكل الشبكة العصبية. في ML ، كما هو الحال في أي مهمة برمجة أخرى ، يمكن حل نفس المهام بطرق مختلفة. لنأخذ كشف الوجه: لحل هذه المشكلة ، أخذنا أولاً شبكات عصبية مع بنية R-FCN. تظهر جودة عالية إلى حد ما ، ولكنها استغرقت حوالي 40 مللي ثانية على صورة واحدة ، وهو ما لم يناسبنا ، ثم انتقلنا إلى بنية MTCNN وحصلنا على زيادة مضاعفة في السرعة مع خسارة طفيفة في الجودة.
في بعض الأحيان ، من أجل تحسين وقت حساب الشبكات العصبية ، قد يكون من المفيد تطبيق الاستدلال في إطار آخر ، وليس في الإطار الذي تم تدريسه. على سبيل المثال ، في بعض الأحيان يكون من المنطقي تحويل الطراز الخاص بك إلى NVIDIA TensorRT. إنه يطبق عددًا من التحسينات وهو جيد بشكل خاص على الطرز المعقدة إلى حد ما. على سبيل المثال ، يمكن إعادة ترتيب بعض الطبقات بطريقة ما ، ودمجها ورميها بعيدًا ؛ لن تتغير النتيجة ، وستزداد سرعة حساب الاستدلال. يسمح لك TensorRT أيضًا بإدارة الذاكرة بشكل أفضل ، وبعد بعض الحيل ، يمكنه تقليلها إلى حساب الأرقام بدقة أقل ، مما يزيد أيضًا من سرعة حساب الاستدلال.
تحميل بطاقة الفيديو
يتم إجراء الاستدلال على الشبكة على وحدة معالجة الرسومات (GPU) ، وتعد بطاقة الفيديو أغلى جزء من الخادم ، لذلك من المهم استخدامها بكفاءة قدر الإمكان. كيف نفهم ، هل قمنا بتحميل GPU بالكامل أم يمكننا زيادة الحمل؟ يمكن الإجابة على هذا السؤال ، على سبيل المثال ، باستخدام المعلمة GPU Utilization في الأداة المساعدة nvidia-smi من حزمة برنامج تشغيل الفيديو القياسي. بالطبع ، لا يوضح هذا الرقم عدد نوى CUDA التي يتم تحميلها مباشرة على بطاقة الفيديو ، ولكن كم هي خاملة ، لكنه يسمح لك بتقييم تحميل GPU بطريقة أو بأخرى. من التجربة ، يمكننا القول أن التحميل من 80 إلى 90٪ جيد. إذا تم تحميله بنسبة 10-20 ٪ ، فهذا أمر سيئ ، ولا يزال هناك احتمال.
إحدى النتائج المهمة لهذه الملاحظة: تحتاج إلى محاولة تنظيم النظام لزيادة تحميل بطاقات الفيديو. بالإضافة إلى ذلك ، إذا كان لديك 10 بطاقات فيديو ، يتم تحميل كل واحدة منها بنسبة 10-20٪ ، فعلى الأرجح ، يمكن لبطاقتي فيديو عالي التحميل حل المشكلة نفسها.
صبيب النظام
عند إرسال صورة إلى إدخال شبكة عصبية ، يتم تقليل معالجة الصورة إلى مجموعة متنوعة من عمليات المصفوفة. بطاقة الفيديو عبارة عن نظام متعدد النوى ، وصور الإدخال التي نرسلها عادةً صغيرة. دعنا نقول أن هناك 1000 مركز على بطاقة الفيديو الخاصة بنا ، ولدينا 250 × 250 بكسل في الصورة. وحده ، لن يتمكنوا من تحميل جميع النوى بسبب حجمها المتواضع. وإذا أرسلنا هذه الصور إلى الطراز في وقت واحد ، فلن يتجاوز تحميل بطاقة الفيديو 25٪.
لذلك ، تحتاج إلى تحميل عدة صور للاستدلال في وقت واحد وتشكيل مجموعة منها.
في هذه الحالة ، يرتفع تحميل بطاقة الفيديو إلى 95٪ ، وسيستغرق حساب الاستنتاج وقتًا كصورة واحدة.
ولكن ماذا لو لم يكن هناك 10 صور في قائمة الانتظار حتى نتمكن من دمجها في مجموعة؟ يمكنك الانتظار قليلاً ، على سبيل المثال ، 50-100 مللي ثانية على أمل أن تأتي الطلبات. وتسمى هذه الاستراتيجية إصلاح زمن الاستجابة. يسمح لك بدمج الطلبات من العملاء في مخزن مؤقت داخلي. نتيجة لذلك ، نزيد من تأخيرنا بمقدار ثابت ، لكننا نزيد بشكل كبير من إنتاجية النظام.
إطلاق الاستدلال
نقوم بتدريب النماذج على الصور ذات التنسيق والحجم الثابت (على سبيل المثال ، 200 × 200 بكسل) ، ولكن يجب أن تدعم الخدمة القدرة على تحميل صور متنوعة. لذلك ، كل الصور قبل التقديم إلى الاستدلال ، تحتاج إلى إعداد صحيح (تغيير الحجم ، توسيط ، تطبيع ، ترجمة إلى تعويم ، وما إلى ذلك). إذا تم تنفيذ كل هذه العمليات في عملية تطلق الاستدلال ، فستبدو دورة عملها كما يلي:
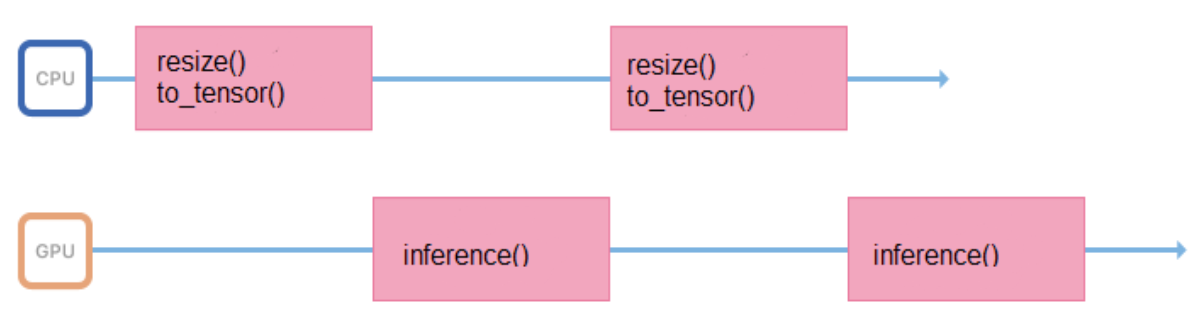
يقضي بعض الوقت في المعالج ، ويقوم بإعداد بيانات الإدخال ، لبعض الوقت في انتظار استجابة من وحدة معالجة الرسومات. من الأفضل تقليل الفواصل الزمنية بين الاستدلالات بحيث يكون الجرافيك أقل خمولًا.
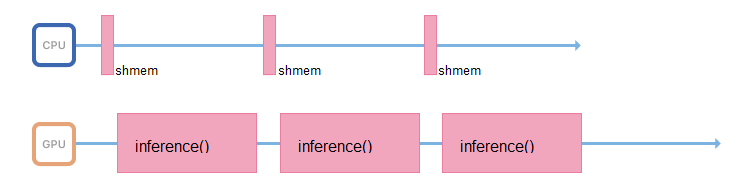
للقيام بذلك ، يمكنك بدء دفق آخر ، أو نقل إعداد الصور إلى خوادم أخرى ، دون بطاقات الفيديو ، ولكن باستخدام معالجات قوية.
إذا كان ذلك ممكنًا ، يجب أن تتعامل العملية المسؤولة عن الاستدلال مع ذلك فقط: الوصول إلى الذاكرة المشتركة ، وجمع بيانات الإدخال ، ونسخها على الفور إلى ذاكرة بطاقة الفيديو وتشغيل الاستدلال.
توربو دفعة
إن إطلاق الشبكات العصبية هو عملية تستهلك الموارد ليس فقط من وحدة معالجة الرسومات ، ولكن أيضًا من المعالج. حتى لو تم تنظيم كل شيء بشكل صحيح من حيث النطاق الترددي ، وكان مؤشر الترابط الذي يؤدي إلى الاستدلال ينتظر بالفعل بيانات جديدة ، على معالج ضعيف لن يكون لديك الوقت الكافي لتشبع هذا الدفق ببيانات جديدة.
تدعم العديد من المعالجات تقنية Turbo Boost. يسمح لك بزيادة وتيرة المعالج ، ولكن لا يتم تمكينه بشكل افتراضي بشكل افتراضي. الأمر يستحق التحقق من ذلك. لهذا ، لدى Linux الأداة المساعدة CPU Power:
$ cpupower frequency-info -m .
تحتوي المعالجات أيضًا على وضع استهلاك الطاقة الذي يمكن التعرف عليه بواسطة أمر CPU Power:
performance .
في وضع powersave ، يمكن للمعالج ضبط تردده وتشغيله بشكل أبطأ. يجب أن تذهب إلى BIOS وتحديد وضع الأداء. ثم سوف يعمل المعالج دائما في أقصى تردد.
نشر التطبيق
Docker رائع لنشر التطبيق ، فهو يسمح لك بتشغيل التطبيقات على وحدة معالجة الرسومات داخل الحاوية. للوصول إلى بطاقات الفيديو ، تحتاج أولاً إلى تثبيت برامج تشغيل بطاقة الفيديو على النظام المضيف - خادم فعلي. بعد ذلك ، لبدء الحاوية ، تحتاج إلى القيام بالكثير من العمل اليدوي: رمي بطاقات الفيديو بشكل صحيح داخل الحاوية باستخدام المعلمات الصحيحة. بعد بدء تشغيل الحاوية ، سيظل من الضروري تثبيت برامج تشغيل الفيديو بداخلها. وفقط بعد ذلك يمكنك استخدام التطبيق الخاص بك.

هذا النهج له تحذير واحد. يمكن أن تختفي الخوادم من الكتلة وتتم إضافتها. من المحتمل أن يكون للخوادم المختلفة إصدارات مختلفة من برامج التشغيل ، وستختلف عن الإصدار المثبت داخل الحاوية. في هذه الحالة ، سيتم تعطيل Docker بسيط: سيتلقى التطبيق خطأ عدم تطابق إصدار برنامج التشغيل عند محاولة الوصول إلى بطاقة الفيديو.

كيف تتعامل معها؟ هناك نسخة من Docker من NVIDIA ، بفضلها يصبح استخدام الحاوية أسهل وأكثر متعة. وفقًا لـ NVIDIA نفسها ووفقًا للملاحظات العملية ، تبلغ النفقات العامة لاستخدام عامل التصفية لـ nvidia حوالي 1٪.
في هذه الحالة ، يجب تثبيت برامج التشغيل فقط على الجهاز المضيف. عند بدء تشغيل الحاوية ، لن تحتاج إلى رمي أي شيء في الداخل ، وسيتمكن التطبيق على الفور من الوصول إلى بطاقات الفيديو.

يسمح لك "استقلال" nvidia-docker عن برامج التشغيل بتشغيل حاوية من نفس الصورة على أجهزة مختلفة مثبتة عليها إصدارات مختلفة من برامج التشغيل. كيف يتم تنفيذ هذا؟ لدى Docker مفهومًا يسمى وقت تشغيل docker: إنه عبارة عن مجموعة من المعايير التي تصف كيف يجب أن تتواصل الحاوية مع kernel المضيف ، وكيف يجب أن تبدأ وتتوقف ، وكيفية التفاعل مع kernel والسائق. بدءًا من إصدار محدد من Docker ، من الممكن استبدال وقت التشغيل هذا. هذا ما فعلته NVIDIA: فهي تحل محل وقت التشغيل ، وتلتقط المكالمات إلى برنامج تشغيل الفيديو بالداخل وتحول الإصدار الصحيح إلى المكالمات إلى برنامج تشغيل الفيديو.
تزامن
لقد اخترنا Kubernetes كأوركسترا. وهو يدعم العديد من الميزات اللطيفة جدا والتي هي مفيدة لأي نظام محملة بشكل كبير. على سبيل المثال ، يسمح الاكتشاف التلقائي للخدمات بالوصول إلى بعضها البعض داخل كتلة دون قواعد توجيه معقدة. أو التسامح مع الخطأ - عندما تحتفظ Kubernetes دائمًا بعدة حاويات جاهزة ، وإذا حدث شيء ما لك ، فسوف تقوم Kubernetes بإطلاق حاوية جديدة على الفور.
إذا كان لديك بالفعل مجموعة Kubernetes مكونة ، فلن تحتاج إلى الكثير لبدء استخدام بطاقات الفيديو داخل المجموعة:
- السائقين جديدة نسبيا
- تثبيت نفيديا عامل ميناء الإصدار 2
- يتم تعيين وقت تشغيل عامل الميناء افتراضيًا على `nvidia` في /etc/docker/daemon.json:
"default-runtime": "nvidia"
- البرنامج المساعد المثبت
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
بعد قيامك بتكوين نظام المجموعة وتثبيت المكون الإضافي للجهاز ، يمكنك تحديد بطاقة فيديو كمورد.
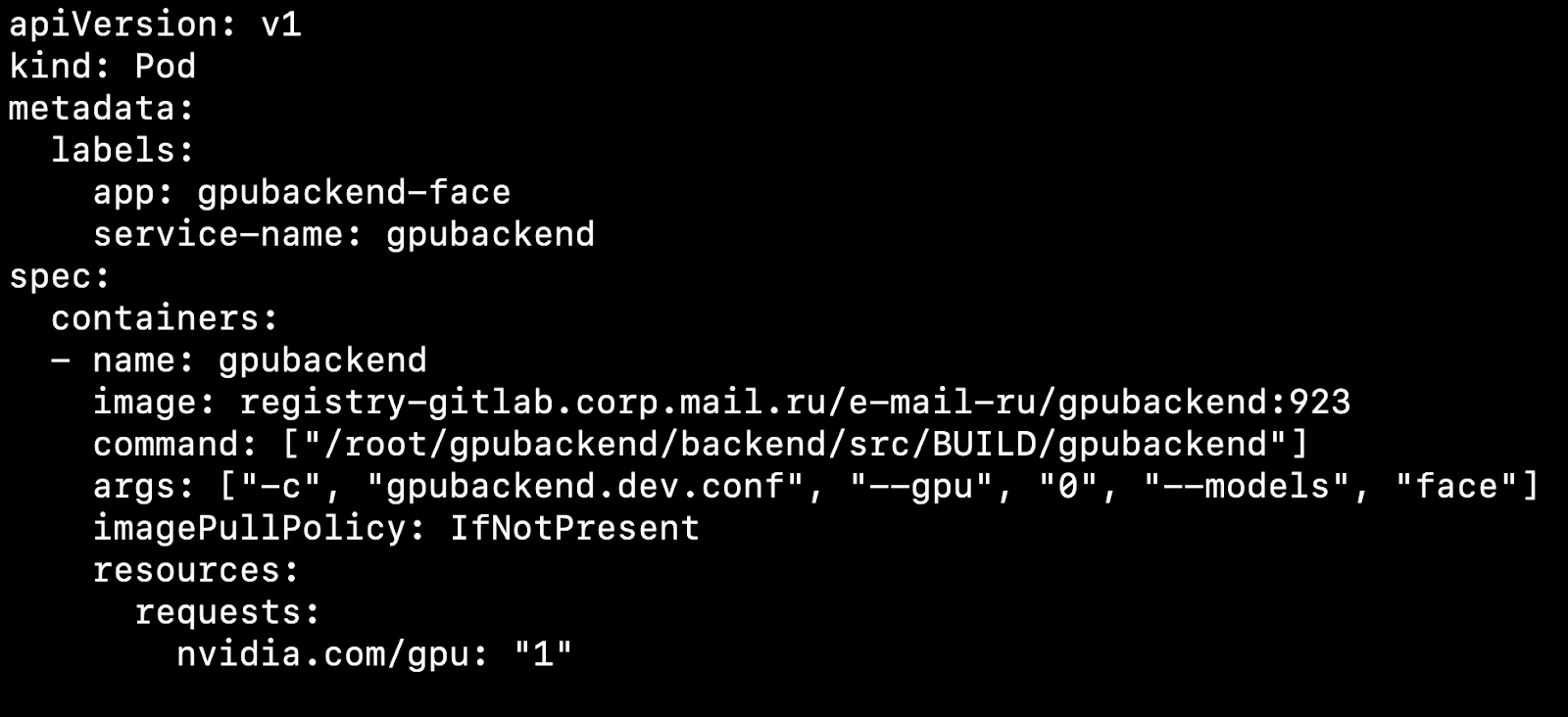
ماذا يؤثر هذا؟ دعنا نقول لدينا اثنين من العقد ، والآلات المادية. على واحد هناك بطاقة الفيديو ، من ناحية أخرى لا. سوف تكتشف Kubernetes آلة بها بطاقة فيديو وتلتقطها.
من المهم أن نلاحظ أن Kubernetes لا يعرف كيفية تلاعب بطاقة الفيديو بكفاءة بين القرون. إذا كان لديك 4 بطاقات فيديو وتحتاج إلى 1 GPU لبدء تشغيل الحاوية ، فلا يمكنك رفع أكثر من 4 قرون على مجموعتك.
نأخذ كقاعدة 1 قرنة = 1 نموذج = 1 GPU.
هناك خيار لتشغيل المزيد من المثيلات على 4 بطاقات فيديو ، لكننا لن نأخذها بعين الاعتبار في هذه المقالة ، لأن هذا الخيار لا ينفد من الصندوق.
إذا كانت عدة نماذج يجب أن تدور في وقت واحد ، فمن الملائم إنشاء Deployment في Kubernetes لكل طراز. في ملف التكوين الخاص به ، يمكنك تحديد عدد الموقد لكل نموذج ، مع مراعاة شعبية النموذج. إذا كان هناك الكثير من الطلبات التي تأتي إلى النموذج ، فأنت بحاجة إلى تحديد الكثير من البرامج ، وإذا كانت هناك طلبات قليلة ، فهناك عدد قليل من البرامج. في المجموع ، يجب أن يكون عدد الموقد مساوياً لعدد بطاقات الفيديو في المجموعة.
النظر في نقطة مثيرة للاهتمام. دعنا نقول لدينا 4 بطاقات الفيديو و 3 نماذج.
على أول بطاقتي فيديو ، دع استدلال طراز التعرف على الوجوه يرتفع ، واعترافًا آخر بالكائنات وباعتراف آخر بأرقام السيارات.
أنت تعمل ، العملاء يأتون ويذهبون ، ومرة واحدة في الليل على سبيل المثال ، ينشأ موقف عندما لا يتم تحميل بطاقة فيديو تحتوي على كائنات استدلالية ، ويبلغ حجمها القليل جدًا من الطلبات ، ويتم تحميل بطاقات الفيديو ذات التعرف على الوجوه. أود أن أطرح نموذجًا به كائنات في هذه اللحظة وأطلق الوجوه في مكانها لتفريغ الخطوط.
للتحجيم التلقائي للنماذج الموجودة على بطاقات الفيديو ، توجد أدوات داخل Kubernetes - التحجيم التلقائي لموقد الموقد الأفقي (HPA ، جهاز فحص الصوت الأفقي).
من خارج الصندوق ، يدعم Kubernetes القياس التلقائي لاستخدام وحدة المعالجة المركزية. ولكن في مهمة مع بطاقات الفيديو ، سيكون من المعقول استخدام المعلومات حول عدد المهام لكل نموذج للتحجيم.
نقوم بذلك: ضع طلبات لكل نموذج في قائمة انتظار. عند اكتمال الطلبات ، نقوم بإزالتها من قائمة الانتظار هذه. إذا تمكنا من معالجة طلبات النماذج الشائعة بسرعة ، فإن قائمة الانتظار لن تنمو. إذا زاد عدد طلبات نموذج معين فجأة ، فإن قائمة الانتظار تبدأ في النمو. يصبح من الواضح أنك تحتاج إلى إضافة بطاقات الفيديو التي ستساعد على تفكيك الخط.
معلومات حول قوائم الانتظار التي نتعامل معها عبر HPA من خلال Prometheus:
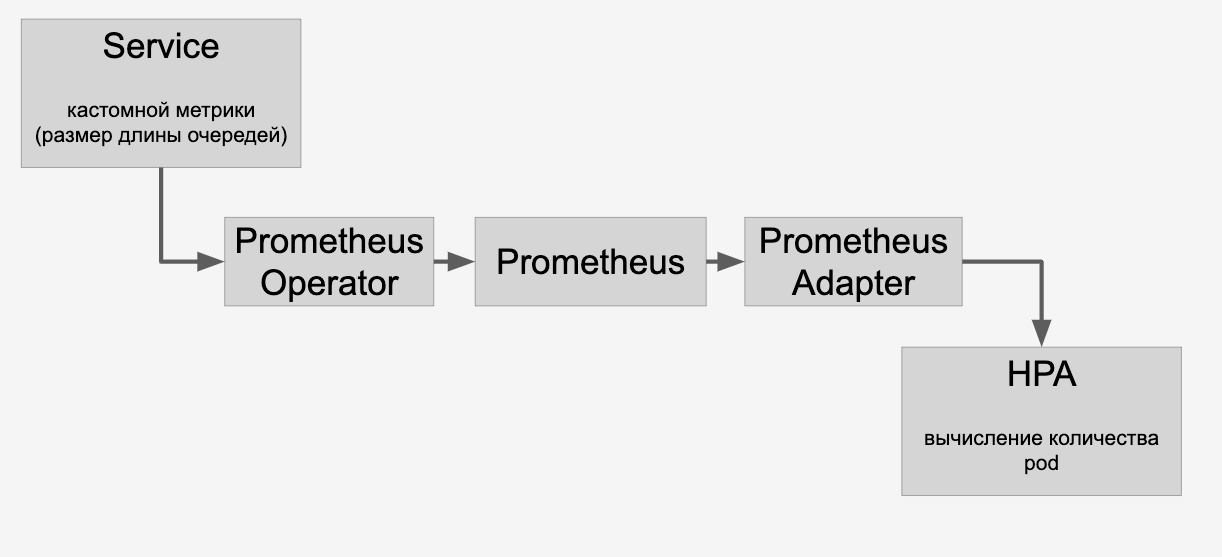
وبعد ذلك نقوم بالتدريج التلقائي للنماذج الموجودة على بطاقات الفيديو في المجموعة وفقًا لعدد الطلبات المقدمة إليها.
CI / CD
بعد إرفاق التطبيق ولفه في Kubernetes ، لديك حرفيًا خطوة واحدة إلى أعلى المشروع. يمكنك إضافة CI / CD ، إليك مثال من خط أنابيبنا:
هنا قام المبرمج بإطلاق الرمز الجديد في الفرع الرئيسي ، وبعد ذلك يتم تلقائيًا تجميع صورة Docker مع الشياطين الخلفية وتشغيل الاختبارات. إذا كانت جميع علامات الاختيار باللون الأخضر ، فسيتم صب التطبيق في بيئة الاختبار. إذا لم تكن هناك مشاكل في ذلك ، يمكنك إرسال الصورة إلى العملية دون أي صعوبات.
استنتاج
في مقالي ، تطرقت إلى بعض جوانب عمل خدمة محملة للغاية باستخدام GPU. تحدثنا عن طرق لتقليل وقت استجابة الخدمة ، مثل:
- اختيار بنية الشبكة العصبية المثلى لتقليل الكمون ؛
- تطبيقات تحسين الأطر مثل TensorRT.
أثارت قضايا زيادة الإنتاجية:
- استخدام الصور الخلط؛
- تطبيق استراتيجية زمن الوصول للإصلاح بحيث يتم تقليل عدد عمليات الاستدلال ، ولكن كل استنتاج سيعالج عددًا أكبر من الصور ؛
- تعظيم الاستفادة من خط أنابيب إدخال البيانات لتقليل تعطل GPU ؛
- "قتال" مع تحديد المعالج ، وإزالة العمليات المرتبطة بوحدة المعالجة المركزية إلى خوادم أخرى.
نظرنا في عملية نشر تطبيق باستخدام GPU:
- باستخدام نفيديا عامل ميناء داخل Kubernetes
- التحجيم على أساس عدد الطلبات و HPA (جراب الأفقي autoscaler).