سيناقش المقال تصنيف نغمة الرسائل النصية باللغة الروسية (وبصفة أساسية أي تصنيف للنصوص باستخدام نفس التكنولوجيا). لنأخذ
هذه المقالة كأساس ، حيث تم اعتبار تصنيف الدرجة اللونية على بنية CNN باستخدام نموذج Word2vec. في مثالنا ، سنحل المشكلة نفسها المتمثلة في فصل التغريدات على إيجابية وسلبية على مجموعة البيانات نفسها باستخدام نموذج
ULMFit . سيتم قبول نتيجة المقال (متوسط درجة F1 = 0.78142) كخط أساسي.
مقدمة
تم تقديم نموذج ULMFIT بواسطة مطوري fast.ai (جيريمي هوارد ، سيباستيان رودير) في عام 2018. يتمثل جوهر هذا النهج في استخدام تعلم النقل في مهام البرمجة اللغوية العصبية (NLP) عند استخدام النماذج المدربة مسبقًا ، وتقليل الوقت اللازم لتدريب النماذج الخاصة بك وتقليل متطلبات حجم عينة الاختبار المصنفة.
سيبدو مخطط التدريب في حالتنا كما يلي:

معنى نموذج اللغة هو القدرة على التنبؤ بالكلمة التالية بالتسلسل. من الصعب الحصول على نصوص طويلة متصلة بهذه الطريقة ، ولكن مع ذلك ، فإن نماذج اللغة قادرة على التقاط خصائص اللغة ، وفهم سياق استخدام الكلمات ، وبالتالي فإن نموذج اللغة (وليس ، على سبيل المثال ، عرض المتجهات للكلمات) هو أساس التكنولوجيا. لمهمة نمذجة اللغة ، يستخدم
ULMFit بنية
AWD-LSTM ، والتي تنطوي على الاستخدام النشط للتسرب كلما كان ذلك ممكنًا
ومعقولًا . أحيانًا ما يسمى نوع التدريب على نموذج اللغة بالتعليم شبه الخاضع للإشراف ، لأن التسمية هنا هي الكلمة التالية ولا يجب تمييز أي شيء بأيديك.
كنموذج لغوي تم تدريبه مسبقًا ، سوف نستخدم النموذج الوحيد
المتاح تقريبًا للجمهور.
دعنا نذهب من خلال خوارزمية التعلم من البداية.
نقوم بتحميل المكتبات (نتحقق من إصدار Fast.ai في حالة عدم التوافق):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
نحن نستعد البيانات للتدريب
وقياسًا على ذلك ، سنجري تدريبًا على
مجموعة النصوص القصيرة RuTweetCorp من إعداد يوليا روبتسوفا ، التي تم تشكيلها على أساس رسائل باللغة الروسية من Twitter. يحتوي الجسم على 114،991 تغريدة إيجابية و 111،923 تغريدة سلبية بتنسيق CSV. بالإضافة إلى ذلك ، هناك قاعدة بيانات من التغريدات غير المخصصة مع وحدة تخزين 17 639 674 السجلات في تنسيق SQL. ستكون مهمة المصنف هي تحديد ما إذا كانت تغريدة إيجابية أم سلبية.
نظرًا
لأنه كان وقتًا طويلاً لإعادة تدريب نموذج اللغة على 17 مليون تغريدة وكانت مهمة إظهار عملية نقل التعلم هي
الكسل ، سنقوم بإعادة تدريب نموذج اللغة على جزء من النص من مجموعة البيانات التدريبية ، متجاهلاً تمامًا قاعدة التغريدات غير المخصصة. ربما ، باستخدام هذه القاعدة "لتوضيح" نموذج اللغة ، يمكنك تحسين النتيجة الإجمالية.
نحن تشكيل مجموعات البيانات للتدريب والاختبار مع معالجة النصوص الأولية. نأخذ الكود من المقال
الأصلي :
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
نحن ننظر إلى ما حدث:
df_train.groupby('Label').count()
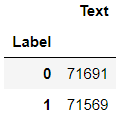
df_val.groupby('Label').count()
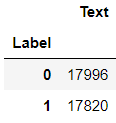
df_test.groupby('Label').count()

تعلم نموذج اللغة
تحميل البيانات:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
نحن ننظر إلى المحتويات:
data_lm.show_batch()

نحن نقدم روابط للأوزان المخزنة للنموذج
المدرّب مسبقًا وقاموس:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
نخلق المتعلم ، ولكن قبل ذلك - عكاز واحد ل fast.ai. تم تدريب النموذج المُدرَّب مسبقًا على إصدار أقدم من المكتبة ، لذلك تحتاج إلى ضبط عدد العقد في الطبقة المخفية للشبكة العصبية.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
نحن نبحث عن معدل التعلم الأمثل:
learn_lm.lr_find() learn_lm.recorder.plot()

نقوم بتدريب نموذج الحقبة الثالثة (في النموذج ، يتم تجميد المجموعة الأخيرة من الطبقات فقط).
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
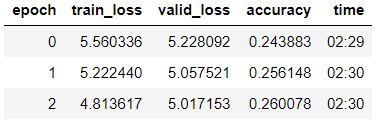
إزالة الجليد من النموذج ، وتعليم 5 عصور أخرى مع انخفاض معدل التعلم:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
نحاول توليد نص على نموذج مدرّب.
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
نرى - شيء يفعله هذا النموذج. لكن مهمتنا الرئيسية هي التصنيف ، ولحلها سنأخذ مشفرًا من النموذج.
learn_lm.save_encoder('ft_enc')
نحن ندرب المصنف
تحميل البيانات للتدريب
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
دعونا نلقي نظرة على البيانات ، ونرى أن التصنيفات قد تم حسابها بنجاح (0 تعني سلبية ، و 1 تعني تعليقًا إيجابيًا):
data_clas.show_batch()

إنشاء متعلم مع عكاز مماثل:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
نقوم بتحميل المشفر الذي تم تدريبه في المرحلة السابقة وتجميد النموذج ، باستثناء المجموعة الأخيرة من الأوزان:
learn.load_encoder('ft_enc') learn.freeze()
نحن نبحث عن معدل التعلم الأمثل:
learn.lr_find() learn.recorder.plot(skip_start=0)

نقوم بتدريب النموذج مع ذوبان الطبقات تدريجيا.
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
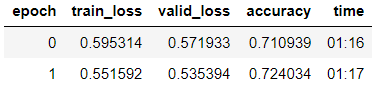
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
نرى أنه في عينة التحقق من الصحة حققوا دقة = 80.1 ٪.
سنختبر النموذج على تعليق
ZlodeiBaal على مقالتي السابقة:
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
نرى أن النموذج أرجع هذا التعليق إلى سلبي :-)
التحقق من النموذج على عينة اختبار
المهمة الرئيسية في هذه المرحلة هي اختبار النموذج لقدرة التعميم. للقيام بذلك ، نقوم بالتحقق من صحة النموذج الموجود على مجموعة البيانات المخزنة في DataFrame df_test ، والذي لم يكن متاحًا حتى ذلك الحين لطراز اللغة أو المصنف.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
نرى أن الدقة في عينة الاختبار تبين أن 79.7 ٪.
ألقِ نظرة على مصفوفة الارتباك:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
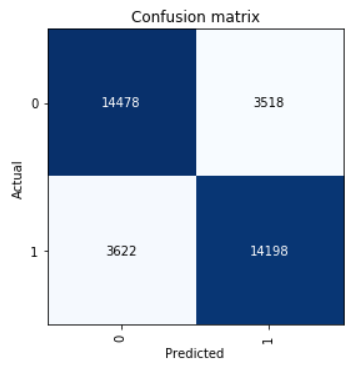
نحن نحسب المعلمات الدقة ، استدعاء ، و F1 النتيجة.
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
النتيجة المبينة في عينة الاختبار هي متوسط درجة F1 = 0.80064.
يمكن حفظ أوزان النموذج المحفوظة
هنا .