تحية! اسمي Evgeny Kashin ، وأنا أعمل في مختبر ذكاء آلة ياندكس. أطلقنا مؤخرًا لعبة يتنافس فيها المستخدمون مع Alice في تخمين الدول من الصور الفوتوغرافية.
كيف يتصرف الناس مفهومة: فهم يتعرفون على الأماكن التي رأوها في الرحلات أو في الأفلام ، ويعتمدون على سعة الاطلاع والحس السليم. الشبكة العصبية ليس لديها أي من هذا. تساءلنا ما التفاصيل في الصور التي دفعتها للإجابة. لقد أجرينا دراسة ، نتشارك نتائجها اليوم مع هبر.
سيكون هذا المنشور مثيرًا للاهتمام لكل من المتخصصين في مجال رؤية الكمبيوتر ، ولكل من يرغب في النظر داخل "الذكاء الاصطناعي" وفهم منطق عمله.

بضع كلمات عن لعبة "
تخمين البلد بالصور ". باختصار ، التقطنا صوراً من Yandex.Maps وقسمناها إلى مجموعتين. تم عرض المجموعة الأولى بواسطة شبكات عصبية ، حيث تم تحديد كل لقطة. بعد مراجعة الآلاف من الصور الفوتوغرافية ، قدمت الشبكة العصبية فكرة عن كل بلد - أي أنها حددت بشكل مستقل مجموعات من العلامات التي يمكن التعرف عليها. نستخدم المجموعة الثانية من الصور في اللعبة ، أليس لم تراها ولا تتذكرها خلال اللعبة. تلعب أليس بشكل جيد ، لكن للناس ميزة: لم ندرب الشبكة العصبية للتعرف على أرقام الآلات ونصوص العلامات والعلامات وأعلام الدول.
من أجل اللعبة ، قمنا بتدريب النموذج للتنبؤ بالبلد من صورة واحدة. أخذنا نموذجًا لرؤية الكمبيوتر
SE-ResNeXt-101 ، تم
تدريبه مسبقًا على العديد من المهام. تعتبر العلامات التي تم الحصول عليها من الصورة باستخدام هذه الشبكة العصبية التلافيفية عالمية تمامًا ، لذلك كان من الضروري بالنسبة لمصنف البلد إضافة بضع طبقات إضافية (ما يسمى الرأس). تم استخدام بيانات Yandex.Mart للتدريب: حوالي 2.5 مليون صورة. العديد من الصور لم تتناسب مع اللعبة وفقًا لمعايير الجمال وتمت تصفيتها. يفهم الجمال على أنه مزيج من العوامل: جودة الصورة ، وجود الناس ، النص ، الغابة ، البحر. تمت إزالة صور مماثلة من نفس المكان حتى لا يتذكر النموذج مشاهد محددة. بعد كل التصفية ، بقي حوالي 1 مليون صورة. بعد تدريب النموذج على هذه البيانات ، حصلنا على مصنف دقيق إلى حد ما ، والذي يحدد البلد فقط بالصورة ، دون استخدام معلومات إضافية.
نظرًا لأن التصنيف يتم باستخدام شبكة عصبية ، لا يمكننا بسهولة الحصول على تفسير للتنبؤات ، على عكس النماذج الخطية الأكثر بساطة أو أشجار القرار. لكننا أردنا معرفة كيف تحدد الشبكة العصبية من صورة منتظمة لشارع أو منزل في أي بلد. والحالات الأكثر إثارة للاهتمام هي من دون الجذب السياحي في الإطار.
للقيام بذلك ، قمنا بتدريب الشبكة العصبية من نقطة الصفر ، لن نقوم بإطعام صور كاملة ، ولكن فقط قطع صغيرة من المحاصيل (بحيث لا يتذكر النموذج أماكن أو أشياء كبيرة)
وهكذا ، أصبحت مهمة النموذج أكثر صعوبة بشكل ملحوظ (حاول تخمين البلد بقطعة من السماء) ، انخفضت دقة التعرف إلى حد كبير. ولكن من ناحية أخرى ، كان على الشبكة العصبية إيلاء المزيد من الاهتمام للتفاصيل الصغيرة: البناء غير المعتاد ، وأنماط محددة ، ونوع السقف ، والنباتات. تم تغيير حجم المحصول المطبق على النموذج ، وتم الحصول على نماذج مختلفة نظرت إلى الصورة بمستويات مختلفة من التجريد: فكلما كان المحصول أصغر ، زادت صعوبة المهمة وزاد اهتمام النموذج بالتفاصيل.

يمكن تطبيق خوارزميات لتفسير التنبؤات على النماذج التي تم تدريبها على أحجام المحاصيل بأحجام مختلفة. أود أن أفسر التوقعات في الصور المصدر. تستخدم معظم شبكات الإلتفاف الحديثة "
Global Average Pooling" (GAP) قبل الطبقة الأخيرة - وهذا يجعل من الممكن تدريب الشبكة على حجم واحد ، وتطبيق على آخر. ويرجع ذلك إلى حقيقة أنه قبل الطبقة الأخيرة ، يتم حساب الميزات المكانية ، الموزعة في العرض والارتفاع ، في رقم واحد لكل قناة (خريطة المعالم). لذلك ، يمكن استخدام النماذج المدربة على المحاصيل (على سبيل المثال ، 160 × 160 بكسل) على الصور الأصلية الكبيرة (800 × 800).
في الواقع ، هناك حاجة إلى طبقة GAP ليس فقط لاستخدام النموذج في دقة مختلفة أو لتنظيم. كما أنه يساعد الشبكة العصبية على تخزين معلومات حول موضع الكائنات حتى الطبقة الأخيرة (ما نحتاجه فقط).
الطريقة الأولى التي جربناها هي
تعيين تنشيط الفصل (CAM).
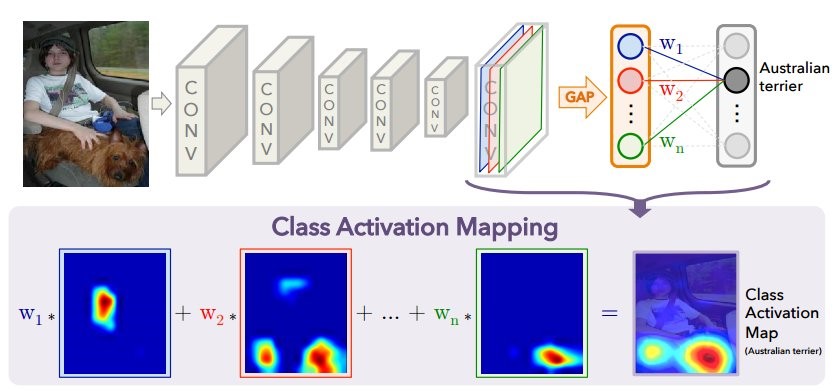
عندما يتم تغذية الصورة لإدخال الشبكة العصبية ، ثم في الطبقة ما قبل الأخيرة ، يتم الحصول على "صورة" مخفضة (في الواقع موتر التنشيط) مع أهم العلامات لكل فئة متوقعة. باستخدام طريقة CAM ، يمكنك تغيير الطبقات الأخيرة بحيث يكون المخرج هو احتمال كل فئة في كل منطقة. على سبيل المثال ، إذا كنت ترغب في التنبؤ بـ 60 فئة (بلدان) ، للحصول على صورة إدخال تبلغ 800 × 800 ، ستتألف الصورة النهائية من 60 بطاقة تنشيط بحجم 25 × 25 ، وهذا موضح بشكل جيد في المنشور
الأصلي .
يُظهر الرسم البياني أعلاه النموذج المعتاد باستخدام GAP: يتم ضغط الميزات المكانية على رقم واحد لكل قناة (خريطة المعالم) ، وبعد ذلك هناك طبقة متصلة تمامًا تتنبأ بالفئات التي تعثر على الأوزان المثلى لكل قناة. يوضح التالي كيفية تغيير البنية للحصول على طريقة CAM: تتم إزالة طبقة GAP ، وتستخدم أوزان آخر طبقة متصلة بالكامل تم الحصول عليها أثناء التدريب مع GAP (أعلاه في الرسم التخطيطي) لكل قناة في كل نقطة. لكل صورة ، يتم الحصول على خرائط التنشيط N لجميع الفئات المتوقعة. بالنسبة لكل بلد ، كلما كانت المنطقة أكثر سطوعًا على "الخريطة" ، زادت مساهمة هذا القسم من الصورة في قرار اختيار بلد معين. ما هو مثير للاهتمام: إذا قمنا بعد هذه العملية بتقييم كل خريطة تنشيط (في جوهرها ، قم بتطبيق GAP) ، ثم نحصل على مجرد التنبؤ الأولي لكل فصل.

في الصورة ، ترى خريطة تنشيط للفئة الأكثر احتمالًا (وفقًا للطراز). تم الحصول عليها عن طريق مد خريطة التنشيط 25 × 25 إلى حجم الصورة الأصلية 800 × 800.
بعد تلقي مثل هذه الخريطة لكل صورة ، يمكننا تجميع المحصول الأكثر أهمية بالنسبة للبلدان من صور مختلفة. يتيح لك ذلك الاطلاع على مجموعة المحاصيل ، ووصف البلد بأفضل طريقة.
الطريقة الثانية ، والتي قررنا مقارنة الأولى ، هي بحث شامل بسيط. ماذا لو أخذنا نموذجًا تم تدريبه على محصول صغير (على سبيل المثال ، 160 × 160 بكسل) وتوقع كل قطعة على صورة كبيرة 800 × 800 معها؟ عند تمرير نافذة انزلاقية تغطي كل منطقة على الصورة ، نحصل على إصدار آخر من خريطة التنشيط ، حيث نوضح مدى احتمال أن تنتمي كل قطعة من الصورة إلى فئة البلد المتوقع.

يتم قص الصورة إلى محاصيل صغيرة بتداخل 160 × 160. لكل محصول ، تقوم الشبكة العصبية بالتنبؤات ، والرقم الموجود أعلى المحصول هو احتمال الانتماء إلى الفئة التي تنبأ بها النموذج أخيرًا.
كما في الطريقة الأولى ، يمكننا مرة أخرى اختيار القطع الأكثر احتمالًا لكل بلد. لكن الصور التي تم الحصول عليها من كلا الطريقتين للبلد يمكن أن تكون موحدة (على سبيل المثال ، مبنى من زوايا مختلفة أو إصدار واحد من الملمس). لذلك ، يتم تجميع أفضل محصول للبلد بالإضافة إلى ذلك - ثم سيتم تجميع معظم الصور المماثلة في مجموعة واحدة. بعد ذلك ، سيكون يكفي التقاط صورة واحدة من كل مجموعة مع أقصى الاحتمالات - لكل بلد تحصل على أكبر عدد ممكن من الصور كما توجد مجموعات. لقد قمنا بالتجميع استنادًا إلى الخصائص التي تم الحصول عليها من طبقة المصنف الأخيرة. المجموعات التجميعية في حالتنا أثبتت أنها الأفضل.

الولايات المتحدة الأمريكية بعد تلقي خط أنابيب مشابه إلى حد ما للطريقتين ، يمكنك التكرار على معلمات الخوارزميات للعثور على التركيبة المثلى. على سبيل المثال ، اخترنا حجم المحصول واستقرنا على خيارين: 160 و 256 بكسل. أعطت المحاصيل التي يقل وزنها عن 160 علامات صغيرة جدًا ، وفقًا لذلك لا يفهم الشخص في الغالب ما يصور. والمحاصيل أكثر من 256 تحتوي في بعض الأحيان على عدة أشياء في وقت واحد. يجب تحديد معلمات مختلفة في مرحلة التجميع: اختيار الخوارزمية الرئيسية ، بالإضافة إلى الميزات التي يتم بها تنفيذ التجميع. بالنسبة للعديد من مجموعات المعلمات ، كان من الواضح على الفور أنها لا تعطي محصولًا "مثيرًا للاهتمام" بشكل كافٍ. ولكن لتحديد الخوارزمية النهائية ، أجرينا تجارب جنبًا إلى جنب على Tolok لفهم أي خيار ، وفقًا للناس ، يصف البلد المحدد بشكل "أكثر ملاءمة".
اتضح أنه ليس من السهل أن تجد طريقة أكثر بساطة للعثور على اقتصاص في الصورة (البحث العادي) تجد كائنات "أكثر إثارة". قد يكون هذا بسبب حقيقة أنه في الطريقة الثانية (التعداد) ، لا ترى الشبكة العصبية الجزء المجاور من الصورة ، وفي طريقة CAM ، تؤثر بيئة النقطة على النتيجة. نتيجة لذلك ، تلقينا تصوراً للميزات المميزة لكل بلد في الوضع التلقائي.
الآن نحن نعرف أجزاء الإطار التي لها أهمية حاسمة بالنسبة للشبكة العصبية ، ويمكننا أن نرى ما الذي وقع عليها. على سبيل المثال ، تعترف هولندا بشبكة عصبية من خلال الجمع بين الجدران المبنية من الطوب الداكن وملامح النوافذ البيضاء ، والإمارات العربية المتحدة - من خلال ناطحات سحاب محددة على خلفية أشجار النخيل ، وإيران - من خلال الأقواس والزخارف المميزة على الواجهات.