مجموعة البيانات المستخدمة فيما يلي مأخوذة من مسابقة kaggle التي تم اجتيازها بالفعل
من هنا .
في علامة التبويب "البيانات" ، يمكنك قراءة وصف جميع الحقول.
كل شفرة المصدر في شكل الكمبيوتر المحمول
هنا .
نقوم بتحميل البيانات ، تحقق من أن لدينا عمومًا:
import numpy as np import pandas as pd dataset = pd.read_csv('../input/ghouls-goblins-and-ghosts-boo/train.csv')
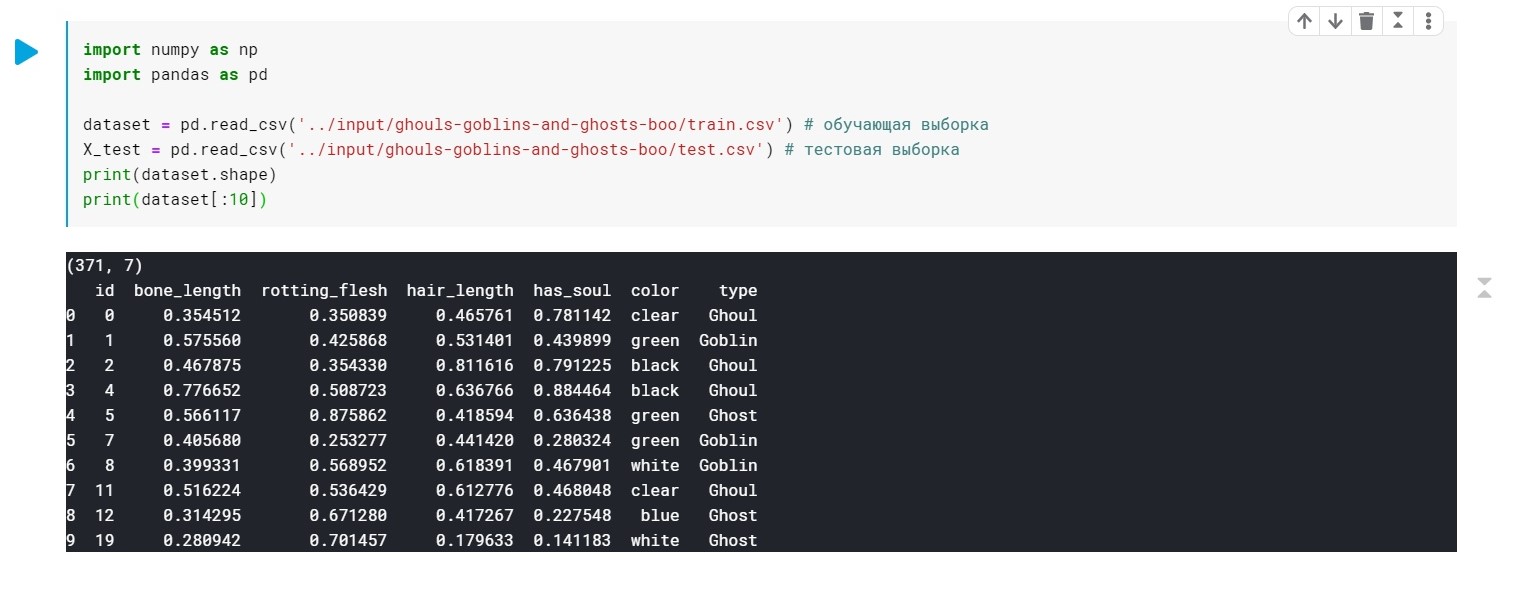
يتم استبدال قيم حقل الكتابة (Ghoul و Ghost و Goblin) بكلمة 0 و 1 و 2.
اللون - يحتاج أيضًا إلى المعالجة المسبقة (نحتاج فقط إلى قيم رقمية لإنشاء النموذج). سوف نستخدم LabelEncoder و OneHotEncoder لهذا الغرض.
مزيد من التفاصيل .
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X_train[:, 4] = labelencoder_X_1.fit_transform(X_train[:, 4]) labelencoder_X_2 = LabelEncoder() X_test[:, 4] = labelencoder_X_2.fit_transform(X_test[:, 4]) labelencoder_Y_2 = LabelEncoder() Y_train = labelencoder_Y_2.fit_transform(Y_train) one_hot_encoder = OneHotEncoder(categorical_features = [4]) X_train = one_hot_encoder.fit_transform(X_train).toarray() X_test = one_hot_encoder.fit_transform(X_test).toarray()
حسنًا ، في هذه المرحلة ، بياناتنا جاهزة. يبقى لتدريب نموذجنا.
أول تطبيق
Adagrad :
في جوهره ، يعد هذا تعديلًا
لنسب الانحدار العشوائي ، والذي كتبت عنه آخر مرة:
habr.com/en/post/472300تأخذ هذه الطريقة في الاعتبار تاريخ جميع التدرجات السابقة لكل معلمة فردية (فكرة القياس). يتيح لك ذلك تقليل حجم خطوة التعلم للمعلمات التي لها تدرج كبير:
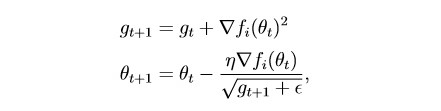
g هي معلمة القياس (g0 = 0)
parameter - المعلمة (الوزن)
إبسيلون عبارة عن ثابت صغير تم إدخاله من أجل منع الانقسام بمقدار صفر
قسّم مجموعة البيانات إلى قسمين:
عينة التدريب (القطار) والتحقق من الصحة (فال):
from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size = 0.2)
القليل من التحضير للتدريب النموذجي:
import torch import numpy as np device = 'cuda' if torch.cuda.is_available() else 'cpu' def make_train_step(model, loss_fn, optimizer): def train_step(x, y): model.train() yhat = model(x) loss = loss_fn(yhat, y) loss.backward() optimizer.step() optimizer.zero_grad() return loss.item() return train_step
نموذج التدريب الذاتي:
from torch import optim, nn model = torch.nn.Sequential( nn.Linear(10, 270), nn.ReLU(), nn.Linear(270, 3)) lr = 0.01 n_epochs = 500 loss_fn = torch.nn.CrossEntropyLoss() optimizer = optim.Adagrad(model.parameters(), lr=lr) train_step = make_train_step(model, loss_fn, optimizer) from sklearn.utils import shuffle for epoch in range(n_epochs): x_train, y_train = shuffle(x_train, y_train)
تصنيف النموذج:
هنا ، بالإضافة إلى الطبقات ، لدينا فقط معلمتان قابلتان للتكوين (الآن):
معدل التعلم و n_epochs (عدد العصور).
اعتمادًا على كيفية دمج هاتين المعلمتين ، قد تنشأ 3 حالات:
1 - كل شيء على ما يرام ، أي يُظهر النموذج خسارة منخفضة في عينة التدريب ودقة عالية في التحقق من الصحة.
2 - تجهيز - خسارة كبيرة على عينة التدريب ودقة منخفضة على التحقق من صحة واحد.
3- التجاوز - خسارة منخفضة في عينة التدريب ، لكن دقة منخفضة على التحقق من الصحة واحد.
مع الأول ، كل شيء واضح :)
مع الثاني ، يبدو أيضًا - أن تجرب معدل التعلم و n_epochs.
وماذا تفعل مع الثالث؟ الجواب بسيط - التنظيم!
سابقا ، كان لدينا وظيفة فقدان الشكل:
L = MSE (Y، y) دون شروط إضافية
إن جوهر التنظيم هو بالتحديد ، بإضافة مصطلح إلى الوظيفة الهدف ، "ضبط" التدرج اللوني إذا كان كبيرًا جدًا. بمعنى آخر ، نحن نفرض قيودًا على وظيفتنا الموضوعية.
هناك العديد من أساليب التنظيم. المزيد عن L1 و L2 - التنظيم:
craftappmobile.com/l1-vs-l2-regularization/#_L1_L2طريقة Adagrad تنفذ L2 ، دعونا نطبقها!
أولاً ، من أجل الوضوح ، ننظر إلى مؤشرات النموذج دون تنظيم:
lr = 0.01 ، n_epochs = 500:
الخسارة = 0.44 ...
الدقة: 0.71
lr = 0.01 ، n_epochs = 1000:
الخسارة = 0.41 ...
الدقة: 0.75
lr = 0.01 ، n_epochs = 2000:
الخسارة = 0.39 ...
الدقة: 0.75
lr = 0.01 ، n_epochs = 3000:
الخسارة = 0.367 ...
الدقة: 0.76
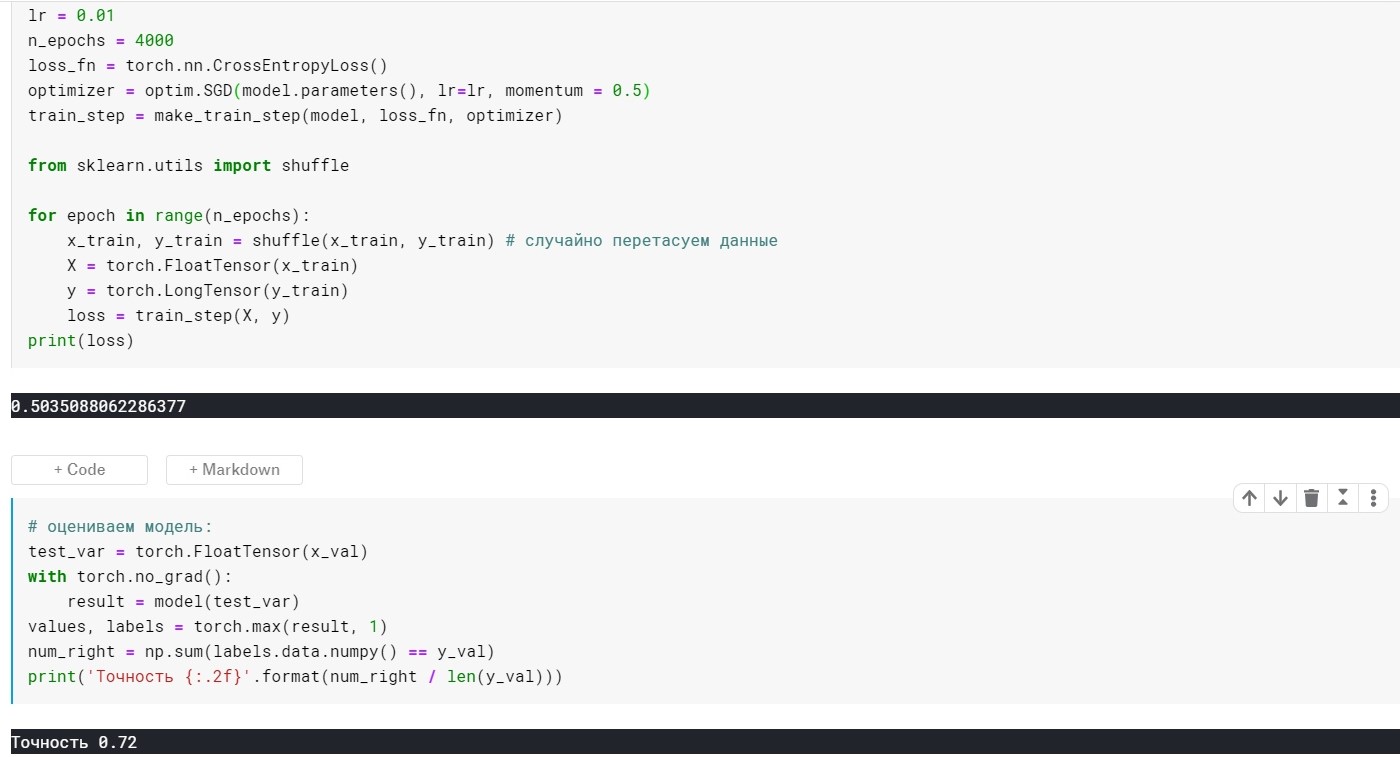
lr = 0.01 ، n_epochs = 4000:
الخسارة = 0.355 ...
الدقة: 0.72
lr = 0.01 ، n_epochs = 10000:
الخسارة = 0.285 ...
الدقة: 0.69
هنا يمكنك أن ترى أنه في 4K + عصور - النموذج هو بالفعل overfit. الآن دعونا نحاول تجنب هذا:
للقيام بذلك ، أضف المعلمة weight_decay لطريقة التحسين الخاصة بنا:
optimizer = optim.Adagrad(model.parameters(), lr=lr, weight_decay = 0.001)
مع lr = 0.01 ، m_epochs = 10000:
الخسارة = 0.367 ...
الدقة: 0.73
في 4000 عصور:
الخسارة = 0.389 ...
الدقة: 0.75
اتضح أفضل بكثير ، لكننا أضفنا معلمة واحدة فقط في محسن :)
الآن ، ضع في اعتبارك SGDm (هذا هو نزول تدرج عشوائي مع امتداد صغير - استدلال ، إذا أردت).
خلاصة القول هي أن
SGD بتحديث المعلمات بقوة بعد كل تكرار. سيكون من المنطقي "سلاسة" التدرج اللوني باستخدام التدرجات من التكرارات السابقة (فكرة القصور الذاتي):
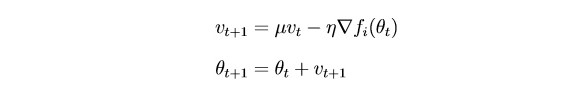
parameter - المعلمة (الوزن)
hyper - القصور الجامح
SGD دون معلمة الزخم:
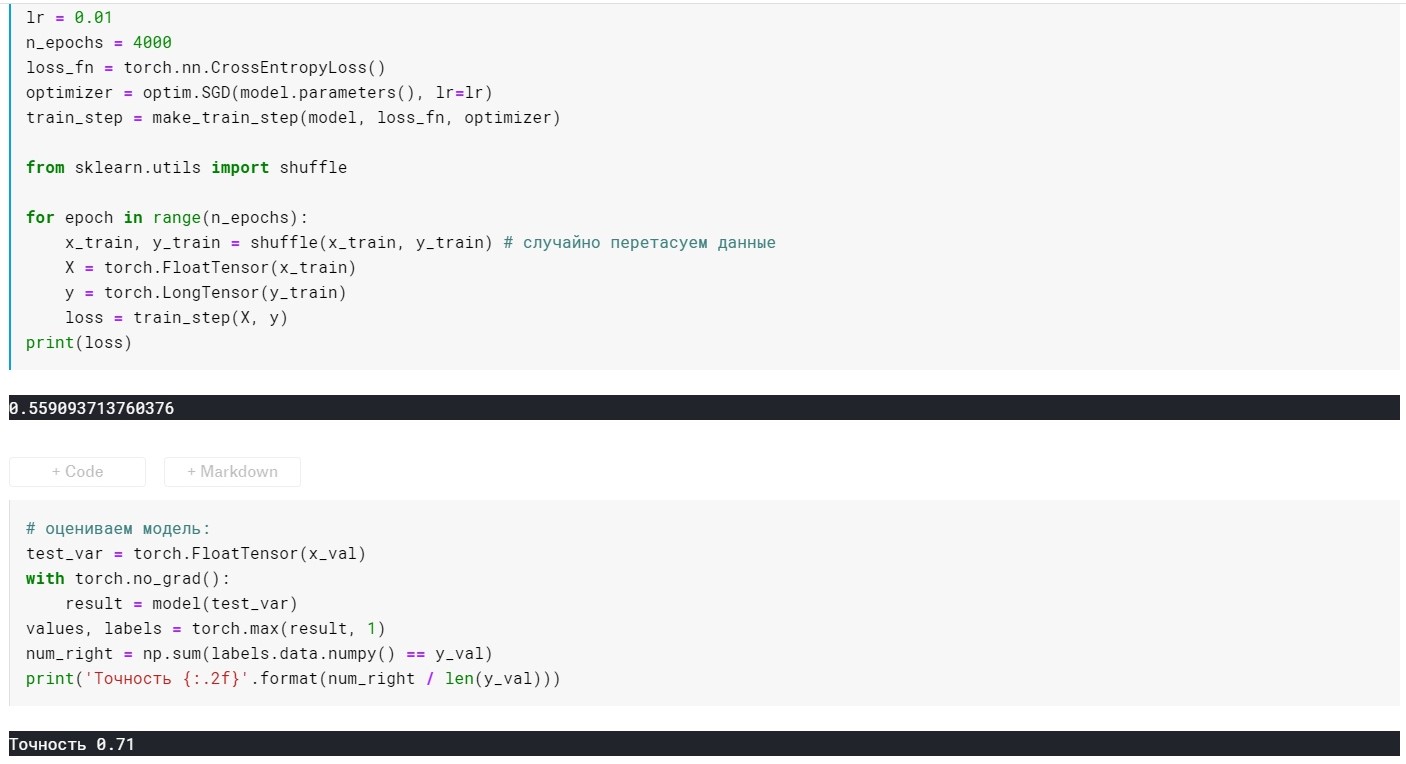
SGD مع المعلمة الزخم:
اتضح أنه ليس أفضل بكثير ، لكن النقطة هنا هي أن هناك طرقًا تستخدم على الفور أفكار التحجيم والقصور الذاتي. على سبيل المثال ، آدم أو Adadelta ، والتي تظهر الآن نتائج جيدة. حسنًا ، من أجل فهم هذه الأساليب ، أعتقد أنه من الضروري فهم بعض الأفكار الأساسية المستخدمة في أساليب أكثر بساطة.
شكرا لكم جميعا على اهتمامكم!