
تحية! اسمي Askhat Nuryev ، أنا مهندس أتمتة رائد في DINS.
لقد عملت في شركة Dino Systems منذ 7 سنوات. خلال هذا الوقت ، كان عليّ التعامل مع العديد من المهام: من كتابة الاختبارات الوظيفية الآلية إلى اختبار الأداء والتوافر العالي. تدريجيا ، أصبحت أكثر مشاركة في تنظيم الاختبارات وتحسين العمليات بشكل عام.
في هذه المقالة سأقول:
- ماذا لو تسربت الحشرات بالفعل إلى الإنتاج؟
- كيف تتنافس على جودة النظام ، إذا لم تتمكن من حساب الأخطاء بيديك ولم تعدل عينيك؟
- ما هي المزالق في معالجة الأخطاء التلقائي؟
- ما المكافآت التي يمكنني الحصول عليها من تحليل إحصاءات الاستعلام؟
تعد DINS مركز تطوير RingCentral ، الشركة الرائدة في السوق بين مزودي خدمات الاتصالات السحابية الموحدة. يوفر Ringentral كل شيء للاتصالات التجارية من الاتصالات الهاتفية الكلاسيكية والرسائل النصية القصيرة والاجتماعات إلى وظائف مراكز الاتصال والمنتجات للعمل الجماعي المعقد (لا سلاك). يوجد هذا الحل السحابي في مراكز البيانات الخاصة به ، ويحتاج العميل فقط إلى الاشتراك في الموقع.
يخدم النظام ، الذي نشارك فيه ، مليوني مستخدم نشط ويعالج أكثر من 275 مليون طلب يوميًا. الفريق الذي أعمل عليه يعمل على تطوير واجهة برمجة التطبيقات.
يحتوي النظام على API معقدة إلى حد ما. مع ذلك ، يمكنك إرسال رسائل نصية قصيرة ، وإجراء المكالمات ، وجمع مؤتمرات الفيديو ، وإعداد الحسابات ، وحتى إرسال الفاكسات (مرحبًا ، 2019). في شكل مبسط ، يبدو مخطط تفاعل الخدمات مثل هذا. أنا لا أمزح.

من الواضح أن مثل هذا النظام المعقد والمحمّل للغاية يخلق عددًا كبيرًا من الأخطاء. على سبيل المثال ، قبل عام تلقينا عشرات الآلاف من الأخطاء في الأسبوع. هذه هي الألف من المئة نسبة إلى العدد الإجمالي للطلبات ، ولكن لا يزال هناك الكثير من الأخطاء في حالة من الفوضى. لقد اكتشفناهم بفضل خدمة الدعم المتقدمة ، لكن هذه الأخطاء تؤثر على المستخدمين. علاوة على ذلك ، يتطور النظام باستمرار ، ويزداد عدد العملاء. وعدد الاخطاء ايضا.
أولاً ، حاولنا حل المشكلة بطريقة كلاسيكية.
اجتمعنا ، طلبنا سجلات من الإنتاج ، وقمنا بتصحيح شيء ما ، ونسينا شيئًا ، وقمنا بإنشاء لوحات معلومات في Kibana و Sumologic. ولكن عموما لم يساعد. البق تسربت على أي حال ، اشتكى المستخدمون. أصبح من الواضح أن هناك شيئًا ما يحدث بشكل خاطئ.
أتمتة
بالطبع ، بدأنا نفهم ورأينا أن 90 ٪ من الوقت الذي يقضيه في إصلاح الخطأ ينفق على جمع المعلومات المتعلقة به. إليك ما بالضبط:
- الحصول على المعلومات المفقودة من الإدارات الأخرى.
- فحص سجلات الخادم.
- التحقيق في سلوك نظامنا.
- فهم ما إذا كان هذا السلوك أو هذا النظام خاطئًا.
وفقط 10 ٪ المتبقية قضيناها مباشرة على التنمية.
لقد فكرنا - لكن ماذا لو صنعنا نظامًا يجد الأخطاء بحد ذاته ، ويضعها في الأولوية ويظهر جميع البيانات اللازمة لإصلاحها؟
يجب أن أقول إن فكرة هذه الخدمة تسببت في بعض المخاوف.
قال أحدهم: "إذا وجدنا كل الخلل بأنفسنا ، فلماذا نحتاج إلى ضمان الجودة؟"
قال آخرون عكس ذلك: "سوف تغرق في كومة الحشرات هذه".
باختصار ، كان الأمر يستحق تقديم خدمة إذا فهم فقط أي منهم على حق.
المفسد(كلتا المجموعتين من المشككين كانوا مخطئين)
حلول جاهزة
بادئ ذي بدء ، قررنا معرفة أي من الأنظمة المماثلة الموجودة بالفعل في السوق. اتضح أن هناك الكثير منهم. يمكنك تسليط الضوء على Raygun ، Sentry ، Airbrake ، وهناك خدمات أخرى.
لكن لا أحد منهم يناسبنا ، وهنا السبب:
- بعض الخدمات تتطلب منا إجراء تغييرات كبيرة للغاية على البنية التحتية الحالية ، بما في ذلك التغييرات على الخادم. سيتعين على Airbrake.io تحسين العشرات ، ومئات مكونات النظام.
- قام آخرون بجمع بيانات حول أخطائنا وأرسلوها في مكان ما إلى الجانب. لا تسمح سياسة الأمان الخاصة بنا بهذا - يجب أن تظل بيانات المستخدم والخطأ معنا.
- حسنًا ، إنها أيضًا باهظة الثمن.
نحن نفعل لدينا
أصبح من الواضح أننا يجب أن نجعل خدمتنا ، خاصة وأننا قمنا بالفعل ببناء بنية تحتية جيدة جدًا لها:
- جميع الخدمات كتبت بالفعل سجلات إلى مستودع واحد - مرن. في سجلات ألقيت معرفات موحدة للطلبات من خلال جميع الخدمات.
- بالإضافة إلى ذلك سجلت إحصاءات الأداء في Hadoop. لقد عملنا مع سجلات باستخدام Impala و Metabase.
من بين جميع أخطاء الخادم (
وفقًا لتصنيف رموز حالة HTTP ) ، فإن 500 رمز هو الأكثر واعدة من حيث تحليل الأخطاء. استجابة للأخطاء 502 و 503 و 504 ، في بعض الحالات ، يمكنك ببساطة تكرار الطلب بعد مرور بعض الوقت دون حتى تقديم إجابة للمستخدم. ووفقًا لتوصيات RC Platform API ، يجب على المستخدمين الاتصال بالدعم إذا تلقوا رمز الحالة 500 ردًا على مكالمة.
قام الإصدار الأول من النظام بتجميع سجلات تنفيذ الاستعلام ، وكل آثار المكدس التي نشأت ، وبيانات المستخدم ، ووضع الخلل في المتعقب ، في حالتنا ، كانت JIRA.
مباشرة بعد تشغيل الاختبار ، لاحظنا أن النظام يخلق عددًا كبيرًا من الأخطاء المكررة. ومع ذلك ، من بين هذه التكرارات ، كان لدى العديد من تتبعات المكدس نفس تقريبا.
كان من الضروري تغيير طريقة تحديد الأخطاء نفسها. من تحليل البيانات الإحصائية البحتة ، انتقل إلى العثور على السبب الجذري للخطأ. توصيفات المكدس تميز المشكلة جيدًا ، لكن يصعب مقارنة بعضها ببعض - تتغير أرقام الأسطر من إصدار إلى آخر ، وبيانات المستخدم والضوضاء الأخرى. بالإضافة إلى ذلك ، فإنها لا تدخل دائمًا في السجل - بالنسبة لبعض الطلبات التي تم إسقاطها ، فهي ببساطة غير موجودة.
في أنقى صوره ، تتبعات المكدس غير ملائمة للاستخدام لتتبع الأخطاء.
كان من الضروري تحديد أنماط وقوالب لتتبعات المكدس ومسحها من المعلومات التي تتغير في كثير من الأحيان. بعد سلسلة من التجارب ، قررنا استخدام تعبيرات منتظمة لمسح البيانات.
ونتيجة لذلك ، أصدرنا إصدارًا جديدًا ، حيث تم التعرف على الأخطاء بواسطة هذه القوالب الفريدة ، إذا كانت آثار المكدس متوفرة. وإذا لم تكن متوفرة ، بالطريقة القديمة ، من خلال طريقة http ومجموعة API.
وبعد ذلك لم يكن هناك عمليا أي تكرارات. ومع ذلك ، تم العثور على العديد من الأخطاء الفريدة.
والخطوة التالية هي فهم كيفية تحديد أولويات الأخطاء ، أي منها يحتاج إلى إصلاح في وقت سابق. لقد أعطينا الأولوية من قبل:
- وتيرة الخطأ.
- عدد المستخدمين الذين تشعر بالقلق.
بناءً على الإحصاءات التي تم جمعها ، بدأنا في نشر تقارير أسبوعية. تبدو مثل هذا:
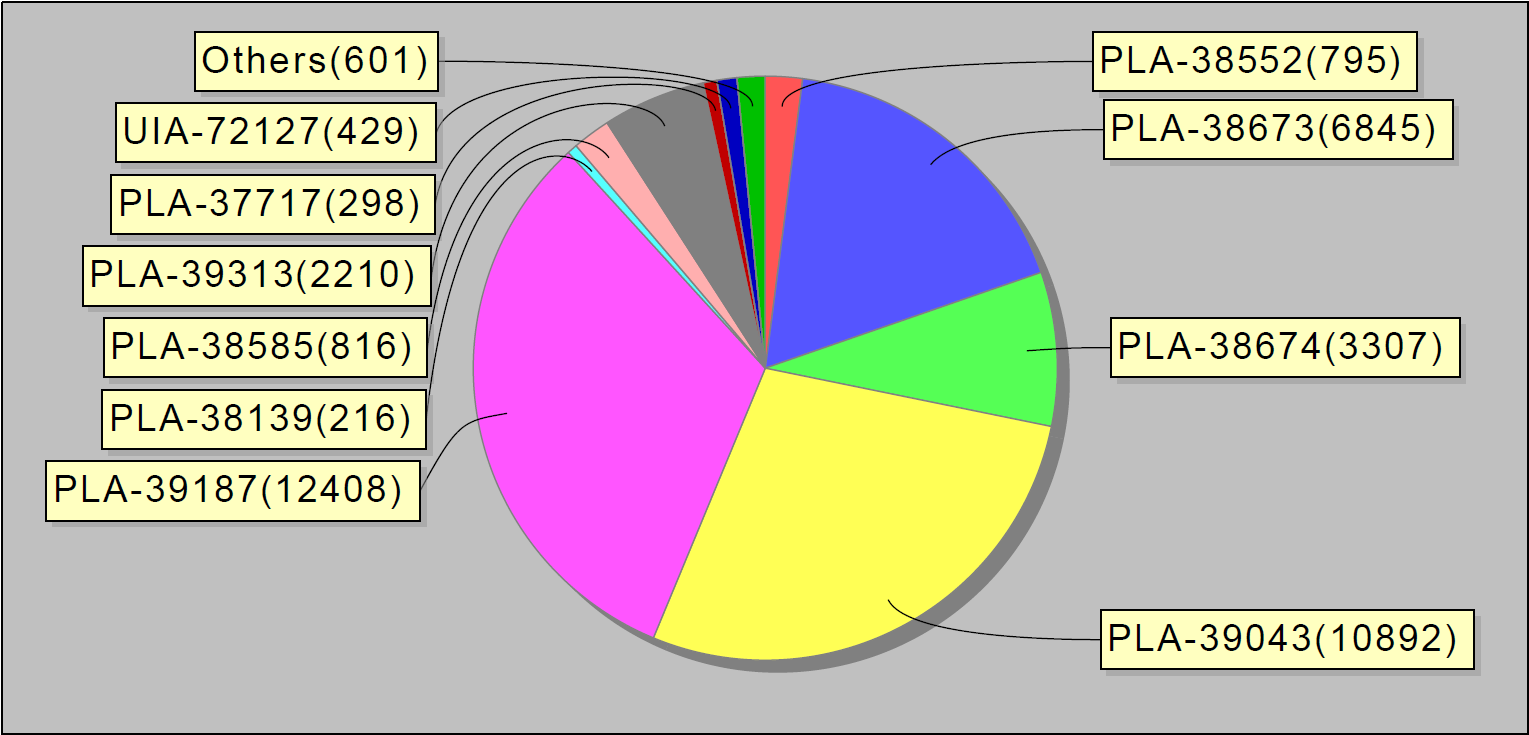
أو ، على سبيل المثال ، أهم 10 أخطاء في الأسبوع. ومن المثير للاهتمام ، أن هذه الأخطاء العشر في jira تمثل 90٪ من أخطاء الخدمة:
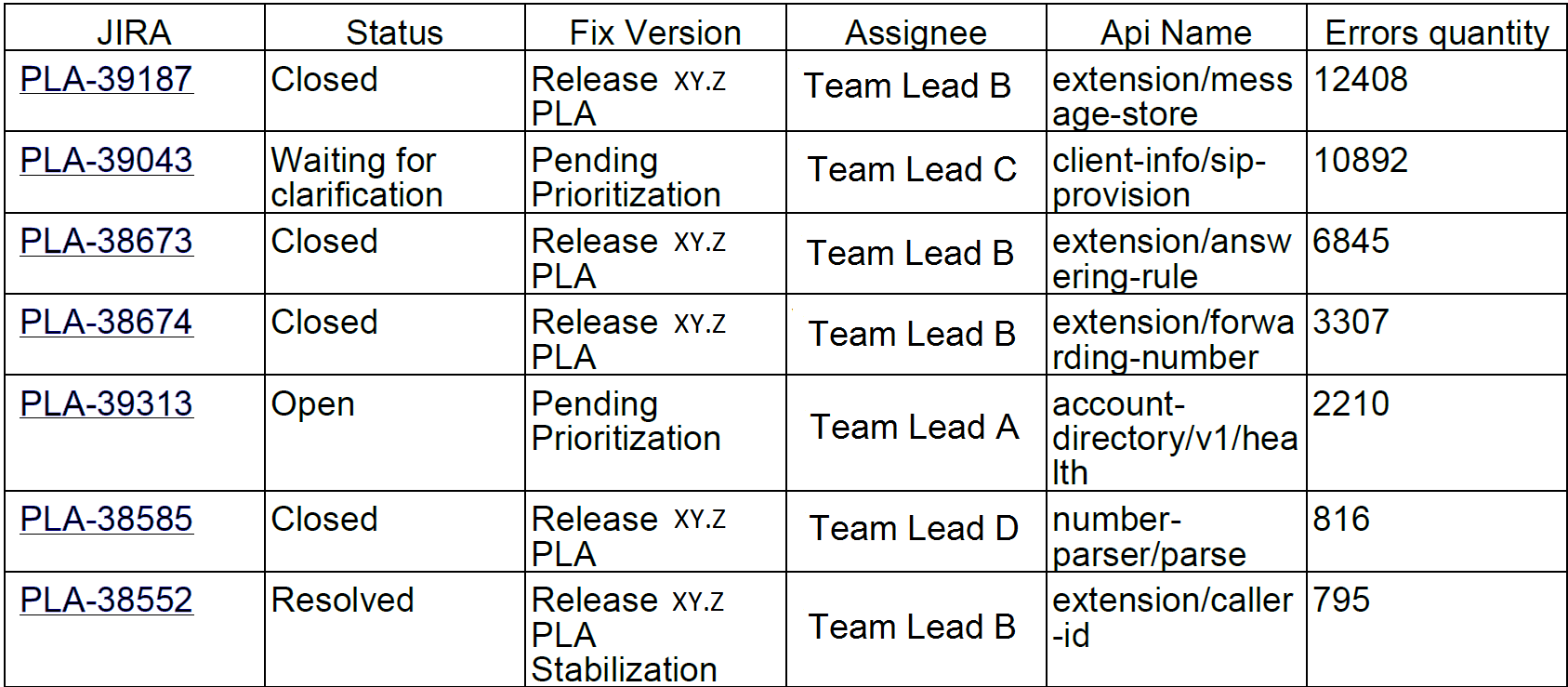
أرسلنا هذه التقارير للمطورين وقادة الفريق.
بعد مرور شهرين على إطلاق النظام ، أصبح عدد المشكلات أقل بشكل ملحوظ. حتى لدينا MVP الصغيرة (منتج قابلة للحياة الحد الأدنى) ساعد على فرز الأخطاء بشكل أفضل.
المشكلة
ربما سنتوقف هنا ، إن لم يكن لحادث واحد.
بمجرد وصولي إلى العمل ولاحظت أن النظام يقوم برش الخلل مثل الكعك الساخن: واحدا تلو الآخر. بعد إجراء تحقيق قصير ، أصبح من الواضح أن العشرات من هذه الأخطاء جاءت من خدمة واحدة. لمعرفة ما هو الأمر ، ذهبت إلى غرفة دردشة فريق النشر. كان هناك شباب يشاركون في تثبيت إصدارات جديدة من الخدمات على الإنتاج والتأكد من أنهم عملوا كما هو متوقع.
سألت: "يا شباب ، ما الذي حدث مع هذه الخدمة؟".
وأجابوا: "منذ ساعة قمنا بتثبيت نسخة جديدة هناك."
خطوة بخطوة ، حددنا المشكلة ووجدنا حلاً مؤقتًا ، بمعنى آخر ، أعدنا تشغيل الخادم.
أصبح من الواضح أن النظام "الخاطئ" مطلوب ليس فقط من قبل المطورين والمهندسين المسؤولين عن الجودة. والمهندسون المسؤولون عن حالة الخوادم قيد الإنتاج ، وكذلك الرجال الذين يقومون بتثبيت إصدارات جديدة على الخوادم ، مهتمون بها أيضًا. ستوضح الخدمة التي نقوم بتطويرها بالضبط الأخطاء التي تحدث في الإنتاج أثناء تغييرات النظام ، مثل تثبيت الخوادم وتطبيق تكوين جديد وما إلى ذلك.
وقررنا القيام بتكرار تطوير آخر.
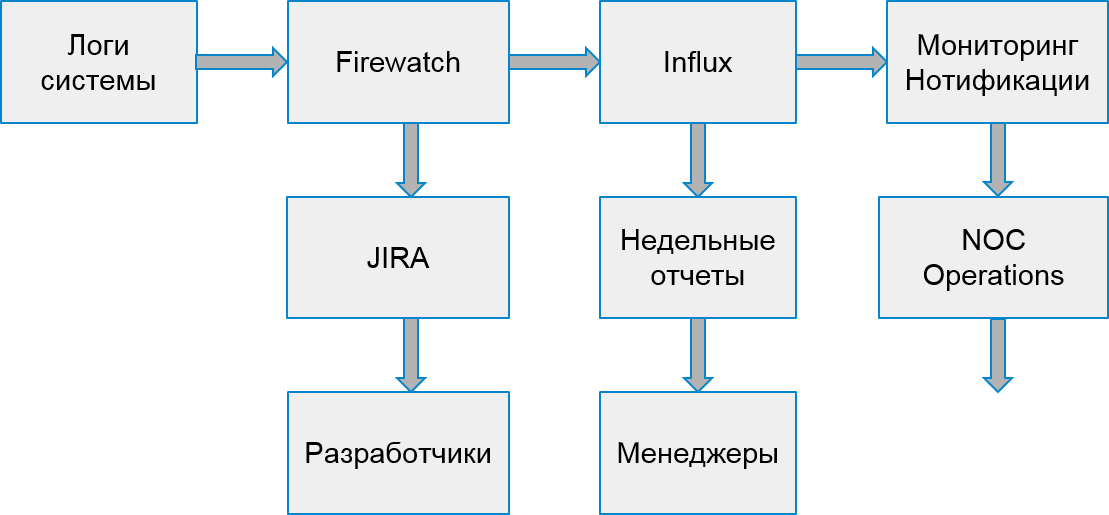
في عملية معالجة الأخطاء ، أضفنا سجلًا من إحصائيات تشغيل المشكلات إلى قاعدة البيانات ولوحات المعلومات في Grafana. هذه هي الطريقة التي يظهر بها التوزيع الرسومي للأخطاء يوميًا عبر النظام:

وهكذا - الأخطاء في الخدمات الفردية.

لقد قمنا أيضًا بتثبيط المشغلات بالتصعيد على الفرق الهندسية المسؤولة - في حالة وجود الكثير من الأخطاء. نقوم أيضًا بإعداد جمع البيانات مرة واحدة كل 30 دقيقة (بدلاً من مرة واحدة يوميًا ، كما كان من قبل).
بدأت عملية نظامنا لتبدو هكذا:
أخطاء العملاء
ومع ذلك ، عانى المستخدمون ليس فقط من أخطاء الخادم. كما حدث أن الخطأ حدث بسبب تطبيق تطبيقات العميل.
لمعالجة أخطاء العميل ، قررنا إنشاء عملية بحث وتحليل أخرى. للقيام بذلك ، اخترنا نوعين من الأخطاء التي تؤثر على الشركات: أخطاء الترخيص وأخطاء الاختناق.
الاختناق هو وسيلة لحماية النظام من الحمل الزائد. إذا تجاوز التطبيق أو المستخدم حصة الطلب الخاصة به ، فسوف يُرجع النظام رمز الخطأ 429 ورأس إعادة المحاولة ، وتشير قيمة الرأس إلى الوقت الذي يجب بعده تكرار الطلب للتنفيذ الناجح.
يمكن أن تظل التطبيقات مخبأة إلى أجل غير مسمى إذا توقفوا عن إرسال طلبات جديدة. لا يمكن للمستخدمين النهائيين التمييز بين هذه الأخطاء عن الآخرين. نتيجة لذلك ، يؤدي هذا إلى تقديم شكاوى إلى خدمة الدعم.
لحسن الحظ ، فإن نظام البنية التحتية والإحصاءات يجعل من الممكن تتبع أخطاء العملاء. يمكننا القيام بذلك لأن مطوري التطبيقات التي تستخدم واجهة برمجة التطبيقات (API) الخاصة بنا يجب عليهم التسجيل المسبق واستلام مفتاحهم الفريد. يجب أن يحتوي كل طلب من العميل على رمز تفويض ، وإلا سيتلقى العميل خطأ. باستخدام هذا الرمز المميز ، نحسب التطبيق.
هذه هي الطريقة التي تبدو مراقبة الخطأ الاختناق. تتوافق قمم الأخطاء مع أيام الأسبوع وفي عطلات نهاية الأسبوع - على العكس من ذلك ، لا توجد أخطاء:

بالطريقة نفسها كما في حالة الأخطاء الداخلية ، بناءً على إحصائيات Hadoop ، وجدنا تطبيقات مشبوهة. أولاً ، فيما يتعلق بعدد الطلبات الناجحة بعدد الطلبات التي أكملت بالرمز 429. إذا تلقينا أكثر من نصف هذه الطلبات ، فكرنا أن التطبيق لا يعمل بشكل صحيح.
في وقت لاحق بدأنا في تحليل سلوك التطبيقات الفردية مع مستخدمين محددين. من بين التطبيقات المشبوهة ، وجدنا الجهاز المحدد الذي يعمل عليه التطبيق وشاهد عدد المرات التي ينفذ فيها الطلبات بعد تلقي أول خطأ في الاختناق. إذا لم ينقص تردد الطلب ، فلن يتعامل التطبيق مع الخطأ كما هو متوقع.
تم تطوير جزء من التطبيقات في شركتنا. لذلك ، تمكنا من العثور على المهندسين المسؤولين على الفور وتصحيح الأخطاء بسرعة. وقررنا إرسال الأخطاء المتبقية إلى فريق اتصل بالمطورين الخارجيين وساعدهم في إصلاح تطبيقاتهم.
لكل تطبيق من هذا القبيل ، نحن:
- نخلق مهمة في جيرة.
- نسجل الإحصاءات في التدفق.
- نحن نستعد مشغلات للتدخل الجراحي في حالة حدوث زيادة حادة في عدد الأخطاء.
يبدو نظام العمل مع أخطاء العميل كما يلي:
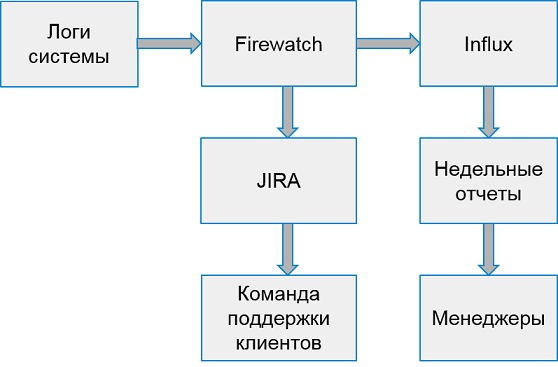
مرة واحدة في الأسبوع ، نقوم بجمع تقارير من أسوأ 10 تطبيقات حسب عدد الأخطاء.
لا تمسك ، لكن حذر
لذلك ، تعلمنا كيفية العثور على أخطاء في نظام الإنتاج ، وتعلمنا كيفية التعامل مع كل من أخطاء الخادم وأخطاء العميل. يبدو أن كل شيء على ما يرام ، ولكن ...
ولكن في الواقع ، نحن نرد متأخرا جدا - الأخطاء تؤثر بالفعل على المستخدمين!
لماذا لا تحاول العثور على أخطاء في وقت سابق؟
بالطبع ، سيكون من الرائع العثور على كل شيء في بيئات الاختبار. لكن بيئات الاختبار هي مسافات من الضوضاء البيضاء. إنها قيد التطوير النشط ، كل يوم تعمل عدة إصدارات مختلفة من الخوادم. إن اكتشاف الأخطاء بشكل مركزي أمر مبكر للغاية. هناك الكثير من الأخطاء فيها ، وغالبا ما يتغير كل شيء.
ومع ذلك ، فإن الشركة لديها بيئات خاصة حيث يتم دمج جميع التجميعات المستقرة للتحقق من الأداء ، والانحدار اليدوي المركزي واختبار توافر عالية. وكقاعدة عامة ، لا تزال هذه البيئات غير مستقرة بدرجة كافية. ومع ذلك ، هناك فرق مهتمة بتحليل المشكلات في هذه البيئات.
ولكن هناك عقبة أخرى - Hadoop لا تجمع البيانات من هذه البيئات! لا يمكننا استخدام نفس الأسلوب للكشف عن الأخطاء ؛ نحتاج إلى البحث عن مصدر بيانات مختلف.
بعد بحث قصير ، قررنا معالجة تدفق الإحصاءات ، وقراءة البيانات من قائمة الانتظار التي تكتب خدماتنا لنقلها إلى Hadoop. كان يكفي لتجميع الأخطاء الفريدة ومعالجتها على دفعات ، على سبيل المثال ، مرة واحدة كل 30 دقيقة. من السهل إنشاء نظام قائمة انتظار يقدم البيانات - كل ما تبقى هو تحسين الاستلام والمعالجة.
بدأنا نلاحظ كيف تتصرف الأخطاء التي تم العثور عليها بعد الاكتشاف. اتضح أن معظم الأخطاء التي تم العثور عليها وغير الثابتة تظهر لاحقًا في الإنتاج. لذلك ، وجدنا لهم بشكل صحيح.
وبالتالي ، قمنا ببناء نموذج أولي للنظام والمؤسسات وتتبع الأخطاء. بالفعل في شكله الحالي ، يسمح لك بتحسين جودة النظام ، وإشعار وتصحيح الأخطاء قبل أن يعرف المستخدمون عنها. إذا قمنا في وقت سابق بمعالجة عشرات الآلاف من الطلبات الخاطئة أسبوعيًا ، فقد أصبح عددها الآن 2-3 آلاف فقط. ونحن تصحيحها بشكل أسرع بكثير.
ما التالي
بالطبع ، لن نتوقف عند هذا الحد وسنواصل تحسين نظام البحث وتتبع الأخطاء. لدينا خطط:
- تحليل الأخطاء API أكثر.
- التكامل مع الاختبارات الوظيفية.
- ميزات إضافية للتحقيق في الحوادث في نظامنا.
ولكن المزيد عن ذلك في المرة القادمة.