فك شفرة تقرير "التنفيذ النموذجي للرصد" بقلم نيكولاي سيفكو.
اسمي نيكولاي سيفكو. أنا أيضا القيام الرصد. Okmeter هو 5 الرصد الذي أقوم به. قررت أنني سوف أنقذ جميع الناس من جحيم المراقبة وسوف ننقذ شخصًا من هذه المعاناة. أحاول دائمًا عدم الإعلان عن okmeter في عروضي التقديمية. بطبيعة الحال ، فإن الصور ستكون من هناك. لكن فكرة ما أريد أن أقوله هي أننا نجعل الرصد مختلفًا قليلاً عن النهج المعتاد. نتحدث كثيرا عن هذا. عندما نحاول إقناع كل فرد بهذا ، يصبح في النهاية مقتنعًا. أريد أن أتحدث عن نهجنا على وجه التحديد حتى يتسنى لك القيام بذلك بنفسك ، حتى تتجنب أشعل النار لدينا.

حول عداد المسافات باختصار. نحن نفعل نفس الشيء مثلك ، ولكن هناك كل أنواع الرقائق. رقائق:
- تفاصيل.
- عدد كبير من المشغلات التي تم تكوينها مسبقًا والتي تستند إلى مشاكل عملائنا ؛
- التكوين التلقائي

عميل نموذجي يأتي إلينا. لديه مهمتين:
1) أن نفهم أن كل شيء انهار من المراقبة ، عندما لا يكون هناك شيء على الإطلاق.
2) إصلاحه بسرعة.
إنه يأتي لمراقبة إجابات ما يحدث له.
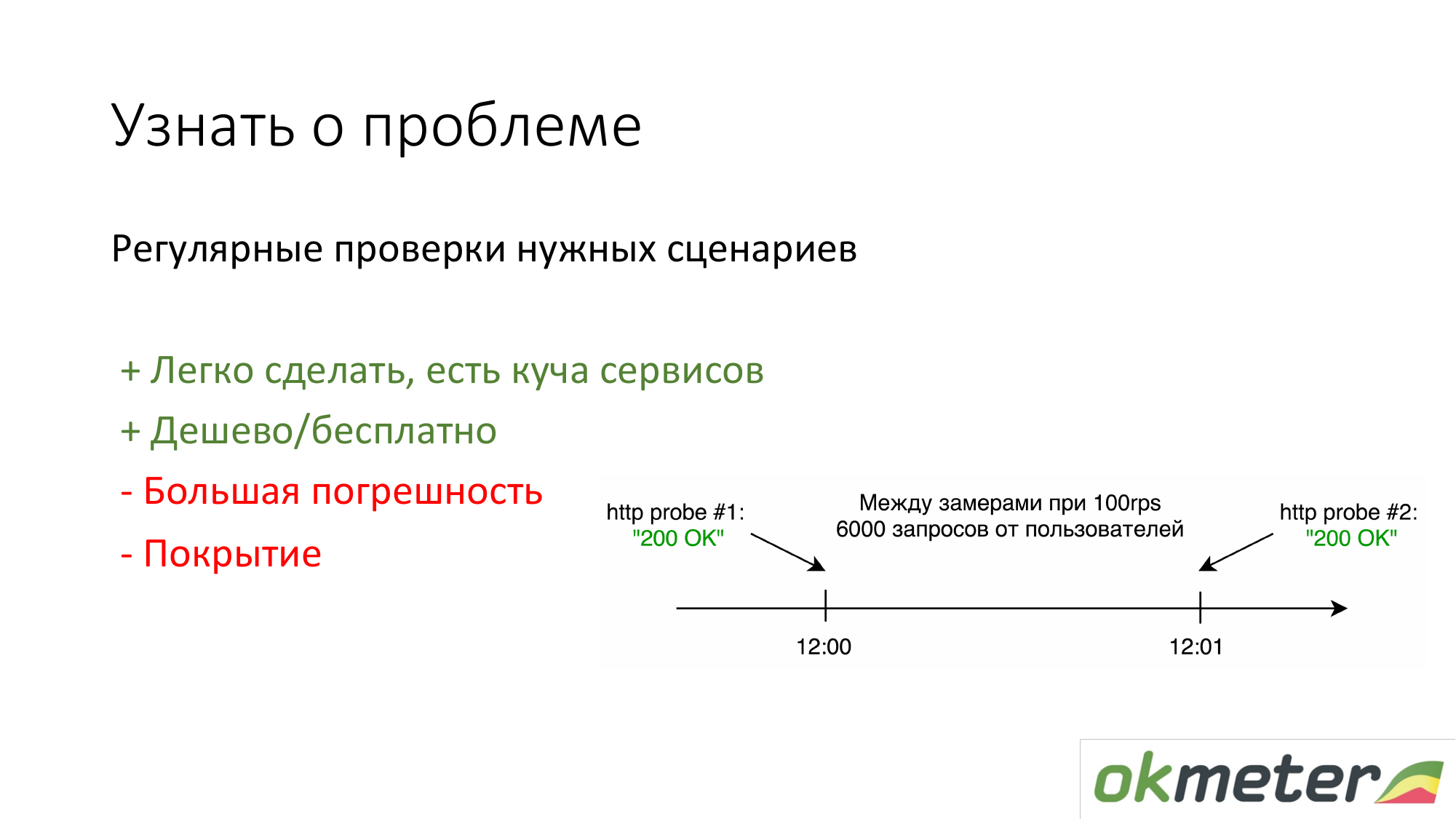
أول شيء يقوم به الأشخاص الذين ليس لديهم أي شيء هو https://www.pingdom.com/ والخدمات الأخرى للتحقق منها. ميزة هذا الحل هو أنه يمكن القيام به في 5 دقائق. لن تتعلم بعد الآن عن المشكلة من خلال مكالمات العملاء. هناك مشاكل في الدقة بحيث يتخطون المشاكل. لكن بالنسبة للمواقع البسيطة ، هذا يكفي.

الشيء الثاني الذي ندعو إليه هو حساب السجلات وفقًا لإحصائيات المستخدمين الحقيقيين. هذا هو مقدار حصول مستخدم معين على أخطاء 5xx. ما هو وقت الاستجابة من قبل المستخدمين. هناك عيوب ، ولكن بشكل عام ، مثل هذا الشيء يعمل.

حول nginx: لقد توصلنا إلى أن أي عميل يأتي فورًا يضع الوكيل على الواجهة الأمامية ويتم التقاط كل شيء تلقائيًا به ، ويبدأ في التحليل ، وتبدأ الأخطاء في الظهور ، وما إلى ذلك. لديه تقريبا أي شيء لتكوين.

لكن معظم العملاء ليس لديهم أجهزة ضبط الوقت في سجلات nginx القياسية. لا يريد 90 في المائة من العملاء معرفة وقت الاستجابة لموقعهم. نحن نواجه هذا في كل وقت. من الضروري توسيع سجل nginx. ثم من خارج الصندوق نبدأ تلقائيًا في عرض الرسوم البيانية خارج الصندوق. ربما هذا هو جانب مهم من حقيقة أنه يجب قياس الوقت.

ما الذي نسحبه من هناك؟ في الممارسة العملية ، نأخذ المقاييس في مثل هذه الأبعاد. هذه ليست مقاييس مسطحة. يسمى المقياس index.request.rate - عدد الاستعلامات في الثانية. يتم تفصيلها بواسطة:
- المضيف الذي قمت بإزالة السجلات منه ؛
- السجل الذي أخذت منه هذه البيانات ؛
- http بواسطة الطريقة ؛
- حالة المتشعب
- حالة ذاكرة التخزين المؤقت.
هذا ليس كل عنوان URL مع كل الحجج. لا نريد إزالة 100000 مقاييس من السجل.

نريد أن نأخذ 1000 متر. لذلك ، نحاول تطبيع عنوان URL ، إن أمكن. خذ عنوان URL العلوي. وبالنسبة لعناوين URL ذات معنى ، نعرض رسم بياني شريطي منفصل ، 5xx على حدة.

إليك مثال على كيفية تحول هذا المقياس البسيط إلى رسومات قابلة للاستخدام. هذا هو DSL لدينا على القمة. حاولت هذا DSL لشرح المنطق التقريبي. أخذنا كل طلب nginx في الثانية ووضعناها على جميع الآلات التي لدينا. حصلت على معرفة حول كيفية موازنته ، ومقدار إجمالي RPS (طلب في الثانية ، طلبات في الثانية).

من ناحية أخرى ، يمكننا تصفية هذا المقياس وإظهار 4xx فقط. على مخطط 4xx ، يمكن وضعها وفقًا للحالة الحقيقية. أنا أذكرك أن هذا هو نفس المقياس.

على الرسم البياني ، يمكنك إظهار 4xx بواسطة عنوان URL. هذا هو نفس المتري.

نحن أيضا اطلاق النار على الرسم البياني من السجلات. الرسم البياني هو مقياس response_histrogram ، وهو في الواقع RPS مع معلمة مستوى إضافية. هذا مجرد فصل من الوقت الذي يتم فيه الحصول على المجموعة.
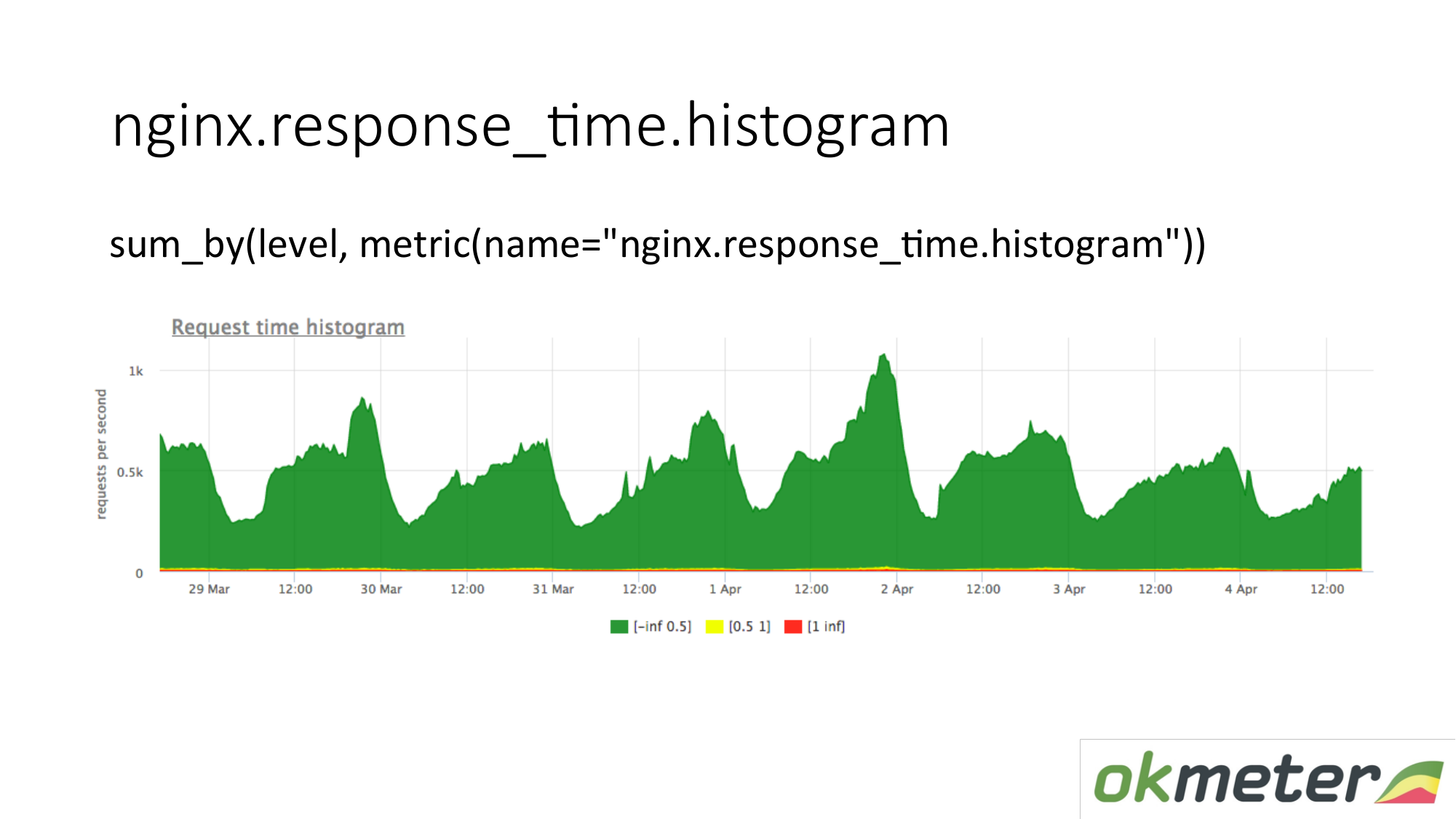
نرسم طلبًا: لخص الرسم البياني بأكمله وصنفه إلى مستويات:
- طلبات بطيئة
- طلبات سريعة
- استفسارات متوسطة
لدينا صورة تم تلخيصها بالفعل بواسطة الخوادم. المتري هو نفسه. معناها الجسدي أمر مفهوم. لكننا نستفيد منه بطرق مختلفة تمامًا.
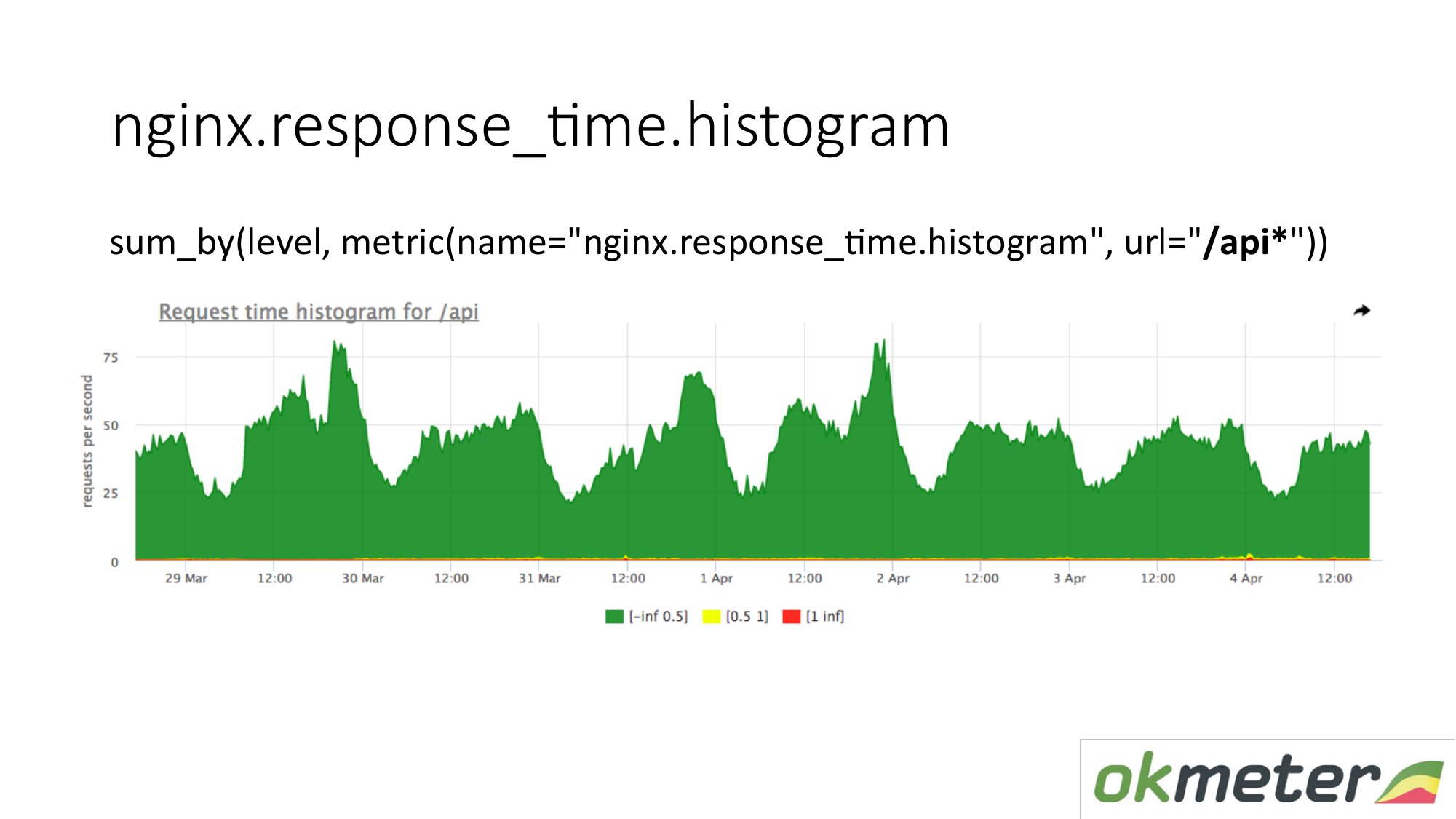
على الرسم البياني ، يمكنك إظهار الرسم البياني فقط عن طريق عنوان URL الذي يبدأ بـ "/ api". وبالتالي فإننا ننظر إلى الرسم البياني بشكل منفصل. نحن ننظر إلى مقدار في هذه اللحظة. نرى عدد RPS في عنوان URL "/ api". نفس القياس ، ولكن تطبيق مختلف.

بضع كلمات حول توقيت في nginx. هناك request_time ، والذي يتضمن الوقت من بداية الطلب إلى نقل البايت الأخير إلى المقبس إلى العميل. وهناك upstream_response_time. انهم بحاجة الى قياس على حد سواء. إذا أزلنا ببساطة request_time ، فسوف ترى هناك تأخيرًا بسبب مشاكل اتصال العميل بالخادم الخاص بك ، فستشهد تأخيرات هناك إذا كان قد تم تكوين حد أقصى للطلب ، وتم تكوين العميل في الحمام. لن تفهم ما إذا كنت بحاجة إلى إصلاح الخادم أو الاتصال بالمضيف. وفقًا لذلك ، نزيل كليهما ومن الواضح تقريبًا ما يحدث.

بمهمة فهم ما إذا كان الموقع يعمل أم لا ، أعتقد أننا قمنا بتصنيفه بشكل أو بآخر. هناك أخطاء. هناك عدم دقة. المبادئ العامة هي على النحو التالي.
الآن حول مراقبة الهندسة المعمارية متعددة المستويات. لأنه حتى أبسط متجر على الإنترنت يحتوي على واجهة أمامية ، متبوعة بتريكس وقاعدة. هذا بالفعل الكثير من الروابط. النقطة العامة هي أنك تحتاج إلى إطلاق بعض المؤشرات من كل مستوى. وهذا هو ، المستخدم يفكر في الواجهة الأمامية. الواجهة الأمامية تفكر في الواجهة الخلفية. الخلفية تفكر في الخلفية المجاورة. وكلهم يفكرون في القاعدة. لذلك ، بالطبقات ، بالتبعيات ، نذهب. نحن نغطي كل شيء مع نوع من المقاييس. نحصل على شيء عند الخروج.

لماذا لا تقتصر على طبقة واحدة؟ عادة ، بين الطبقات هي الشبكة. شبكة كبيرة تحت الحمل هو مادة غير مستقرة للغاية. لذلك ، كل شيء يحدث هناك. بالإضافة إلى ذلك ، تلك القياسات التي تجريها على أي طبقة يمكن أن تقع. إذا أجريت قياسات على الطبقة "أ" و "ب" ، وإذا تفاعلت مع بعضها البعض من خلال الشبكة ، فيمكنك مقارنة قراءاتها والعثور على بعض الحالات الشاذة والتناقضات.

حول الخلفية. نريد أن نفهم كيفية مراقبة الخلفية. ما يجب القيام به معها لفهم ما يحدث بسرعة. أذكرك أننا انتقلنا بالفعل إلى مهمة تقليل وقت التوقف عن العمل إلى الحد الأدنى. وحول الخلفية ، نقترح بشكل موحد فهم:
- كم أكل هذا المورد؟
- هل نتصادم بأي حد؟
- ما الذي يحدث مع وقت التشغيل؟ على سبيل المثال ، نظام التشغيل JVM وقت التشغيل ، Golang وقت التشغيل ، وغيرها من وقت التشغيل.
- عندما يكون لدينا بالفعل تغطية كل هذا ، فمن المثير للاهتمام لنا بالفعل أقرب إلى رمز لدينا. يمكننا إما استخدام intrumetry (statsd ، * -metric) ، والتي سوف تظهر لنا كل هذا. أو قم بتوجيه نفسك من خلال ضبط المؤقتات والعدادات ، إلخ
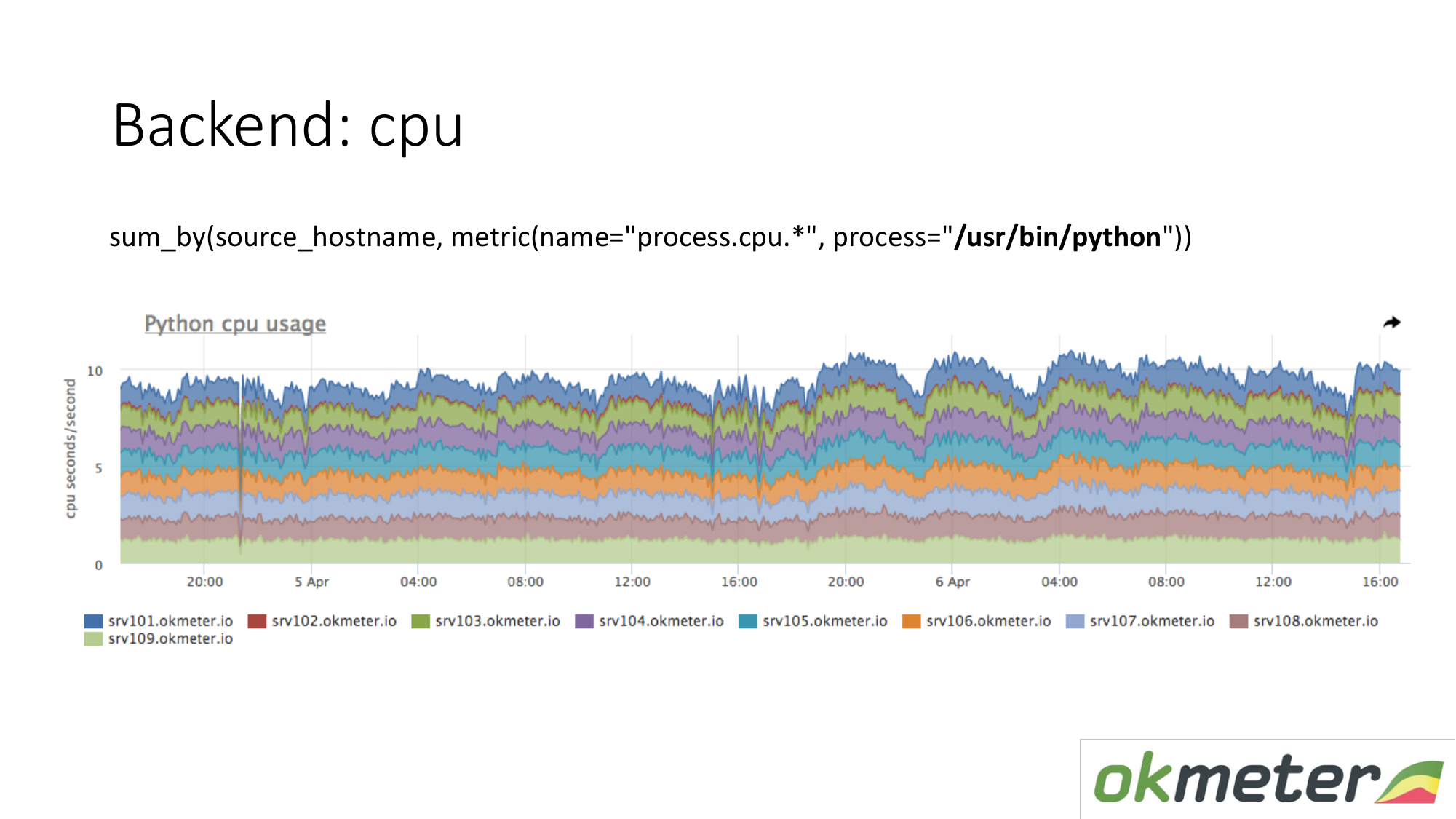
حول الموارد. وكيلنا المعياري يزيل استهلاك الموارد من خلال جميع العمليات. لذلك ، بالنسبة للواجهة الخلفية ، لا نحتاج إلى التقاط البيانات بشكل منفصل. نحن نأخذ ونرى كم تستهلك وحدة المعالجة المركزية هذه العملية ، على سبيل المثال بيثون على الخوادم المقنعة. نعرض جميع الخوادم في المجموعة على نفس الرسم البياني ، لأننا نريد أن نفهم ما إذا كان لدينا اختلالات وإذا حدث شيء ما على نفس الجهاز. نرى الاستهلاك الكلي من أمس إلى اليوم.
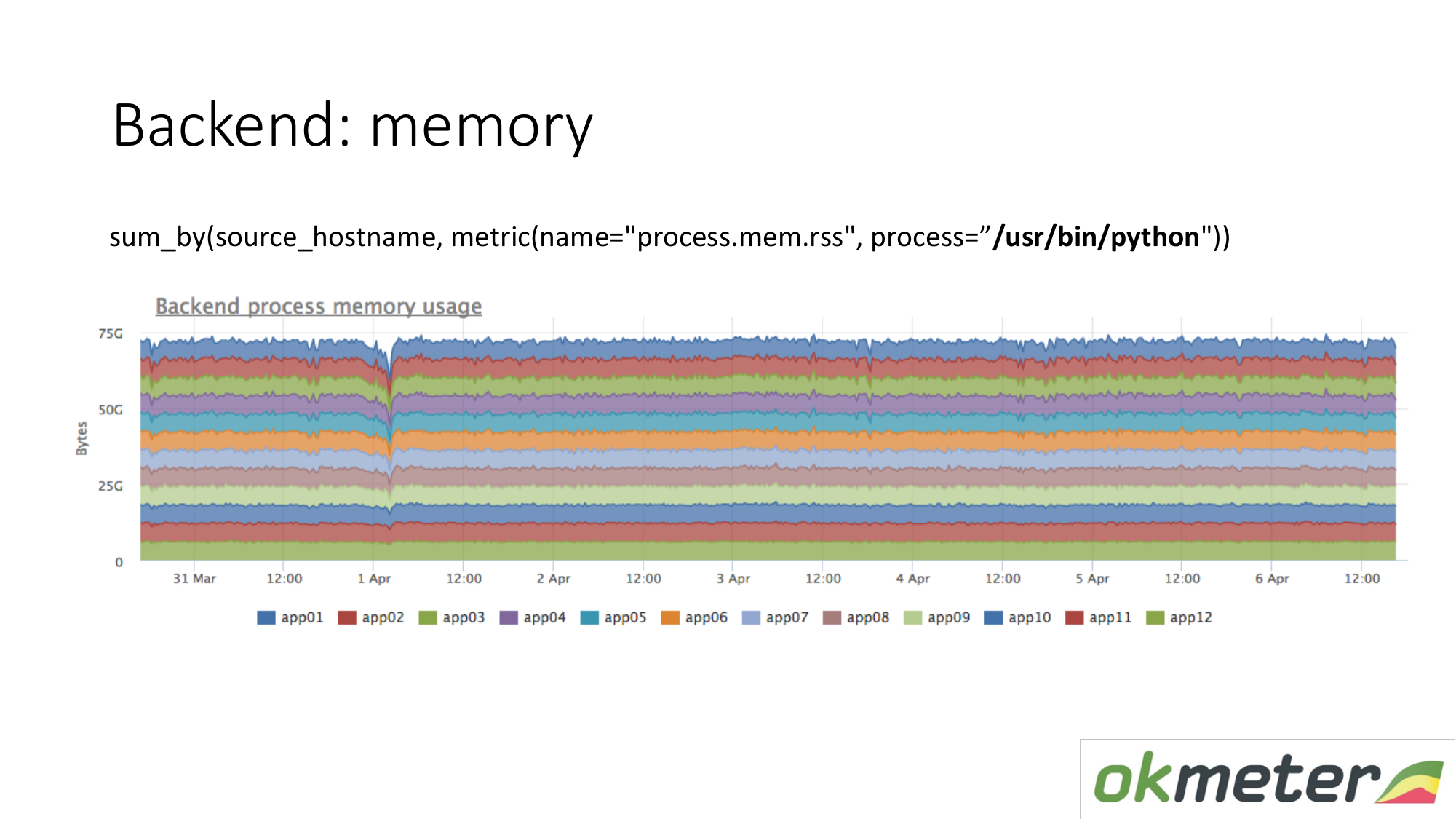
الشيء نفسه ينطبق على الذاكرة. عندما نرسمها هكذا. نختار Python RSS (RSS هو حجم صفحات الذاكرة المخصصة للعملية من قبل نظام التشغيل والموجود حاليا في RAM). مجموع بواسطة المضيف. نحن ننظر إلى أي مكان يتدفق الذاكرة. يتم توزيع الذاكرة في كل مكان بالتساوي. من حيث المبدأ ، تلقينا إجابة على أسئلتنا.
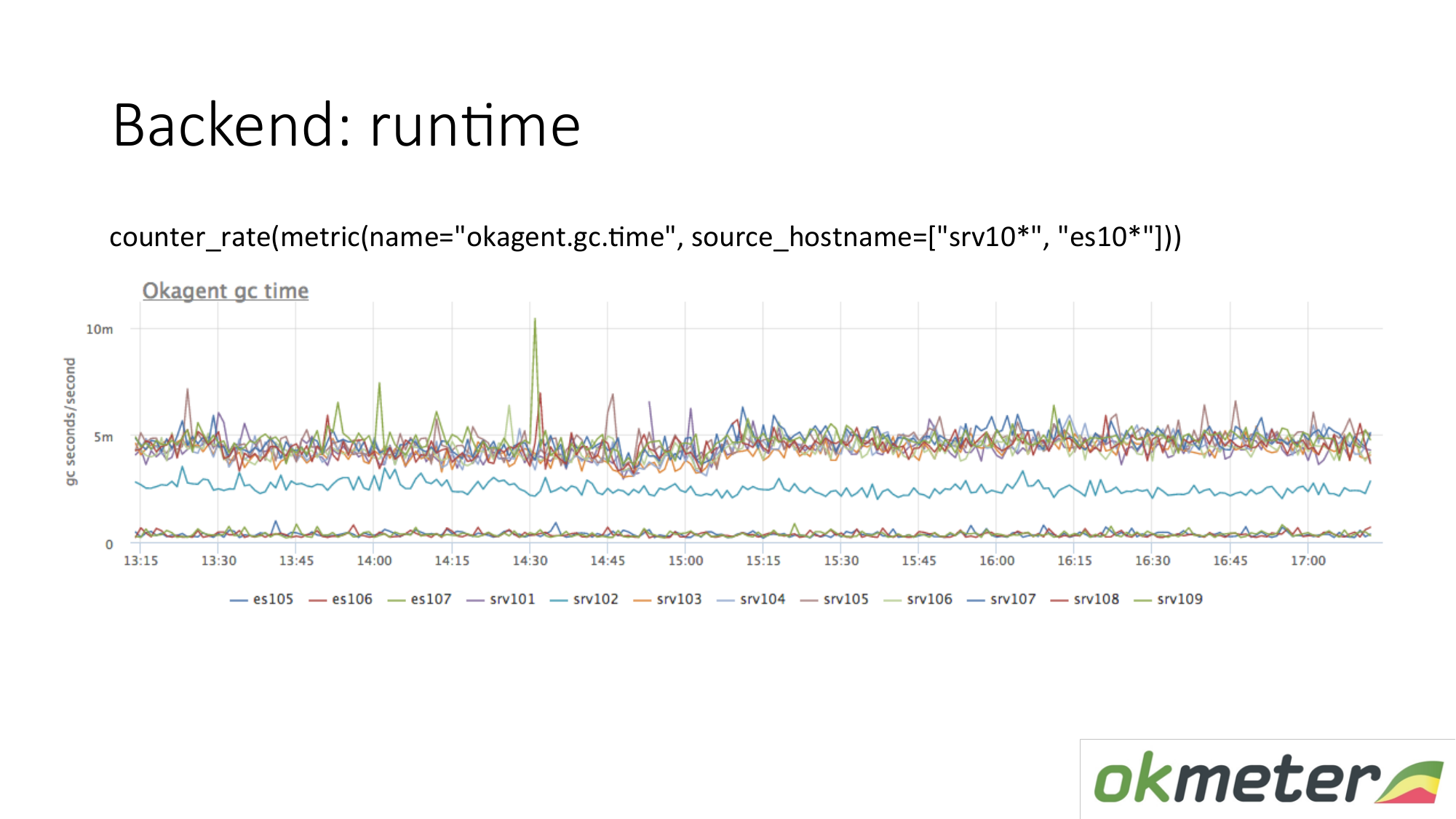
مثال وقت التشغيل. مكتوب وكيلنا في Golang. وكيل Golang يرسل لنفسه مقاييس وقت التشغيل. هذا على وجه الخصوص هو عدد الثواني التي يقضيها جامع البيانات المهملة Golang على تجميع البيانات المهملة في الثانية. نرى هنا أن بعض الخوادم لها مقاييس مختلفة عن الخوادم الأخرى. رأينا شذوذ. نحن نحاول شرح هذا.
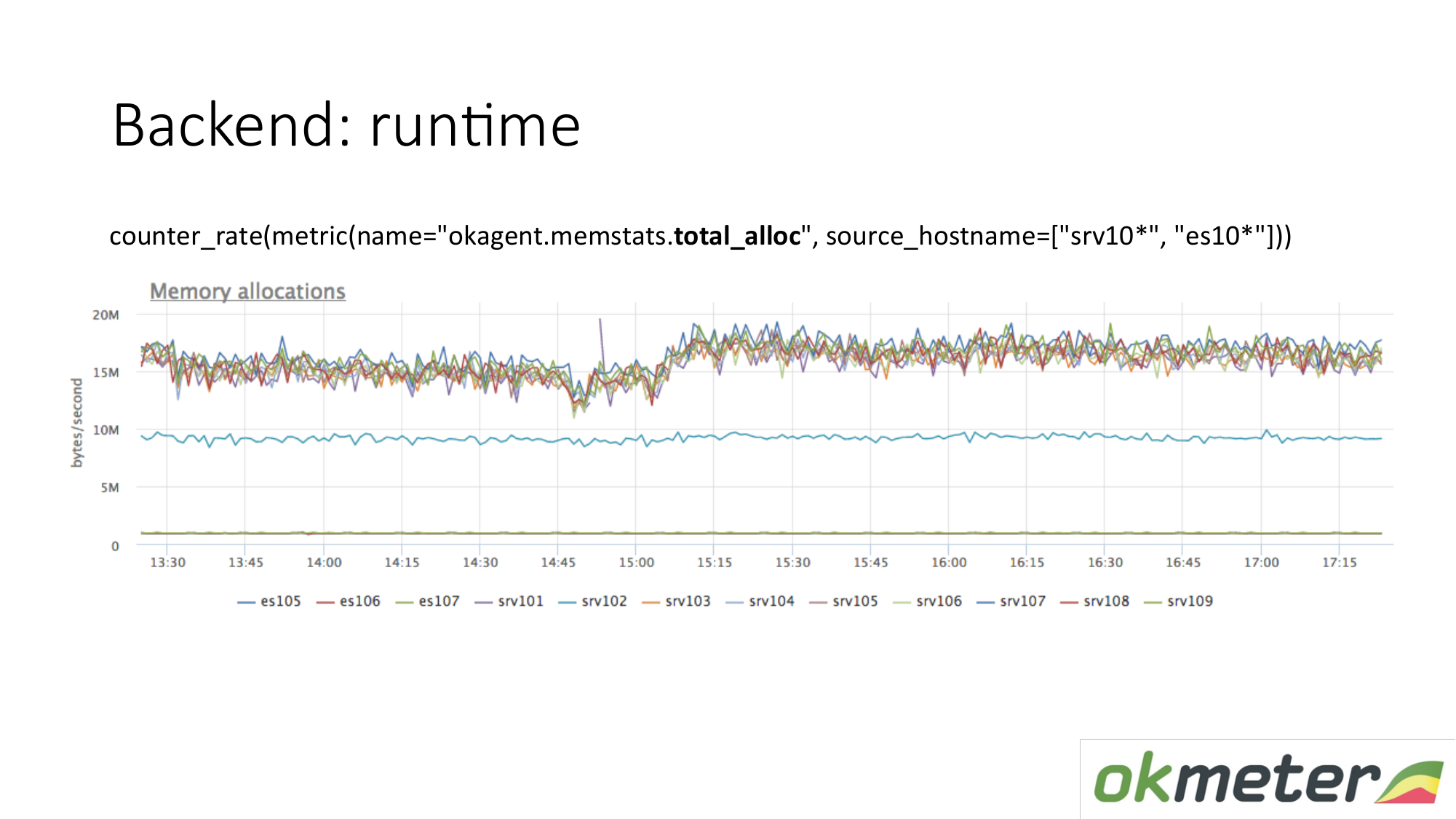
هناك متري وقت التشغيل. مقدار الذاكرة المخصصة لكل وحدة زمنية. نرى أن العملاء الذين لديهم نوع في الأعلى يخصصون ذاكرة أكبر من العوامل التي تنخفض. أدناه وكلاء مع جامع القمامة أقل عدوانية. هذا منطقي. كلما زادت الذاكرة التي تمر عبرك ، تم تخصيصها وتحريرها ، وكلما زاد الحمل على مجمّع البيانات المهملة. علاوة على ذلك ، وفقًا لقياساتنا الداخلية ، فإننا نفهم لماذا نريد الكثير من الذاكرة على هذه الأجهزة وأقل على هذه الأجهزة.
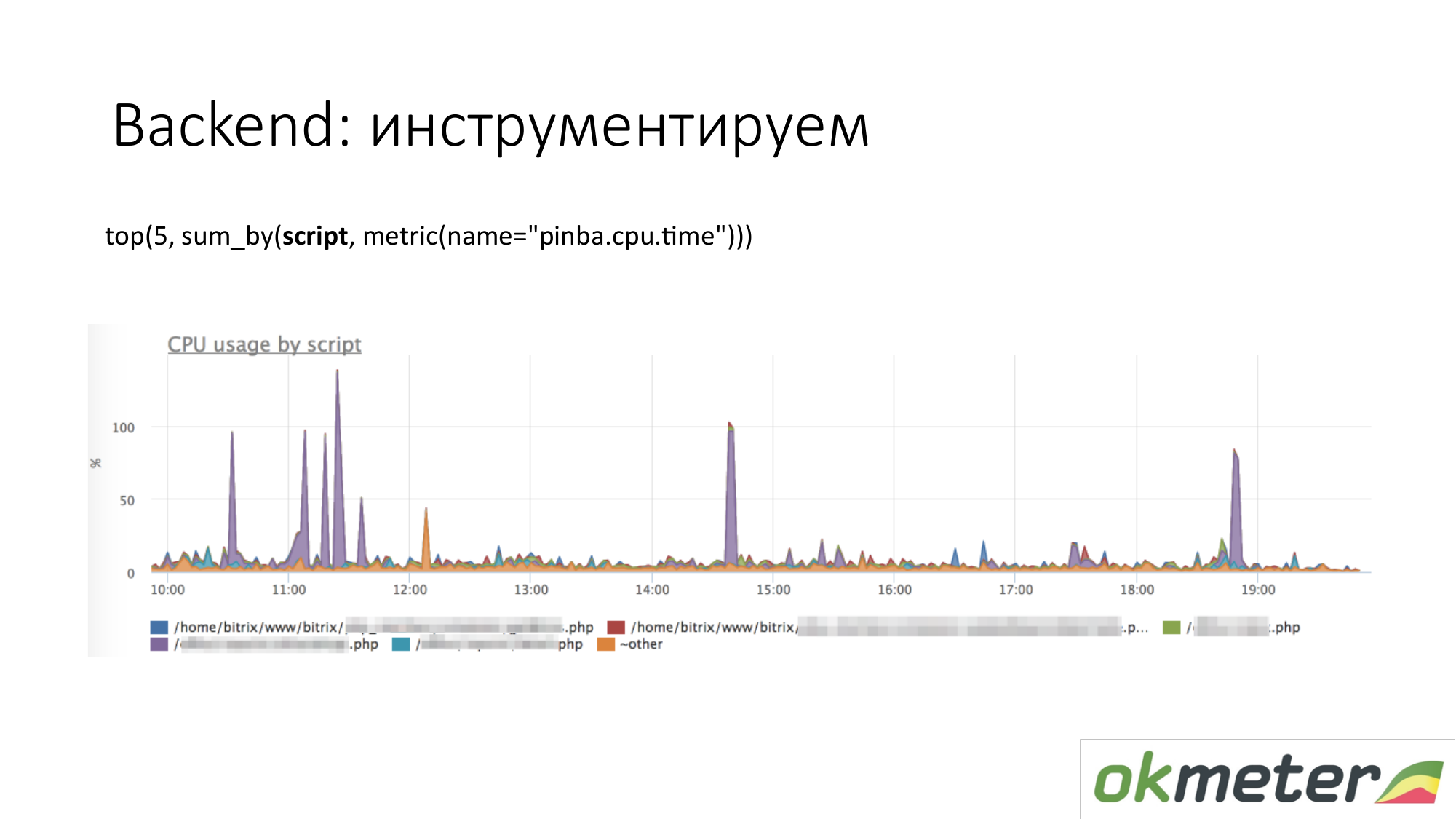
عندما نتحدث عن الأجهزة ، تأتي كل أنواع الأدوات مثل http://pinba.org/ for php. Pinba امتداد ل php من Badoo ، الذي تقوم بتثبيته والاتصال به. يسمح لك بإزالة وإرسال protobuf على الفور عبر UDP. لديهم خادم بينبا. لكننا قدمنا خادم Pinba مضمن في الوكيل. يرسل PHP إلى نفسه مقدار ما أنفقته وحدة المعالجة المركزية والذاكرة لمثل هذه البرامج النصية ، وكم حركة المرور التي تعطى من قبل هذه البرامج النصية ، وهلم جرا. هنا مثال مع Pinba. نعرض أعلى 5 مخطوطات على استهلاك وحدة المعالجة المركزية. نرى خارج البنفسجي الذي هو نقطة لطخت PHP. سنقوم بإصلاح النقطة الملطخة لـ PHP أو لفهم سبب تأكلها على وحدة المعالجة المركزية. لقد قمنا بالفعل بتضييق نطاق المشكلة حتى نفهم الخطوات التالية. نذهب لإلقاء نظرة على الكود وإصلاحه.

الشيء نفسه ينطبق على حركة المرور. نحن ننظر إلى أعلى 5 مخطوطات المرور. إذا كان هذا الأمر مهمًا بالنسبة لنا ، فإننا نذهب ونفهم.

هذا مخطط حول أدواتنا الداخلية. عندما وضعنا الموقت من خلال statsd وقاسنا المقاييس. لقد توصلنا إلى ذلك بحيث يتم تحديد مقدار الوقت الإجمالي الذي يتم إنفاقه في وحدة المعالجة المركزية أو تحسباً لبعض الموارد وفقًا للمعالج الذي نقوم بمعالجته حاليًا ، ووفقًا للمراحل المهمة من التعليمات البرمجية: لقد انتظروا الكسندر ، وانتظروا البحث عن المطاط. يعرض المخطط أعلى 5 مراحل لمعالج / metric / query. على الرسم البياني ، يمكنك إظهار أفضل 5 معالجات لاستهلاك وحدة المعالجة المركزية ، فما يحدث في الداخل. من الواضح ما الذي يجب إصلاحه.
حول الخلفية يمكنك الذهاب أعمق. هناك أشياء تفعل البحث عن المفقودين. وهذا يعني أنه يمكنك رؤية طلب المستخدم المعين هذا باستخدام ملف تعريف ارتباط كبير جدًا و IP ، وبالتالي إنشاء الكثير من الطلبات إلى قاعدة البيانات ، وانتظروا الكثير من الوقت. نحن لسنا قادرين على البحث عن المفقودين. نحن لا تتبع. ما زلنا نعتقد أننا لا نفعل التطبيقات ومراقبة الأداء.

حول قاعدة البيانات. نفس الشيء قواعد البيانات هي نفس العملية. يستهلك الموارد. إذا كانت القاعدة حساسة جدًا للكمون ، فهناك ميزات مختلفة قليلاً. نقترح التحقق من أنه لا توجد موارد أقل ، ولا تدهور في الموارد. من المثالي أن نفهم أنه إذا بدأت القاعدة في الاستهلاك أكثر مما تستهلك ، ففهم بالضبط ما الذي تغير في الكود.
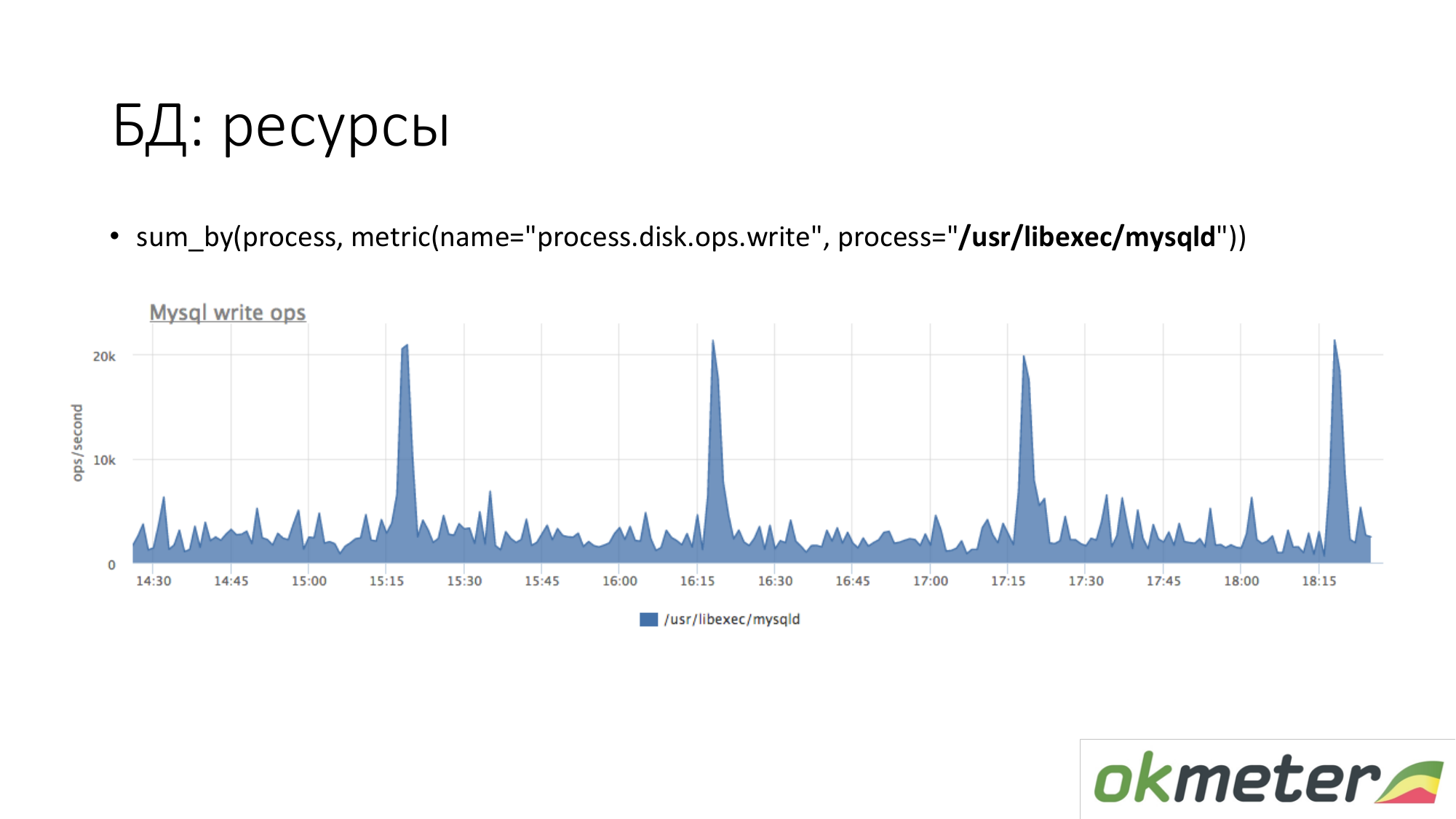
حول الموارد. بنفس الطريقة ، نلقي نظرة على مقدار توليد عملية MySQL على القرص لدينا. نرى أن هناك الكثير في المتوسط ، لكن بعض القمم تحدث. على سبيل المثال ، يأتي الكثير من الإدراج ويبدأ الكتابة إلى القرص في 15.15 و 16.15 و 17.15.
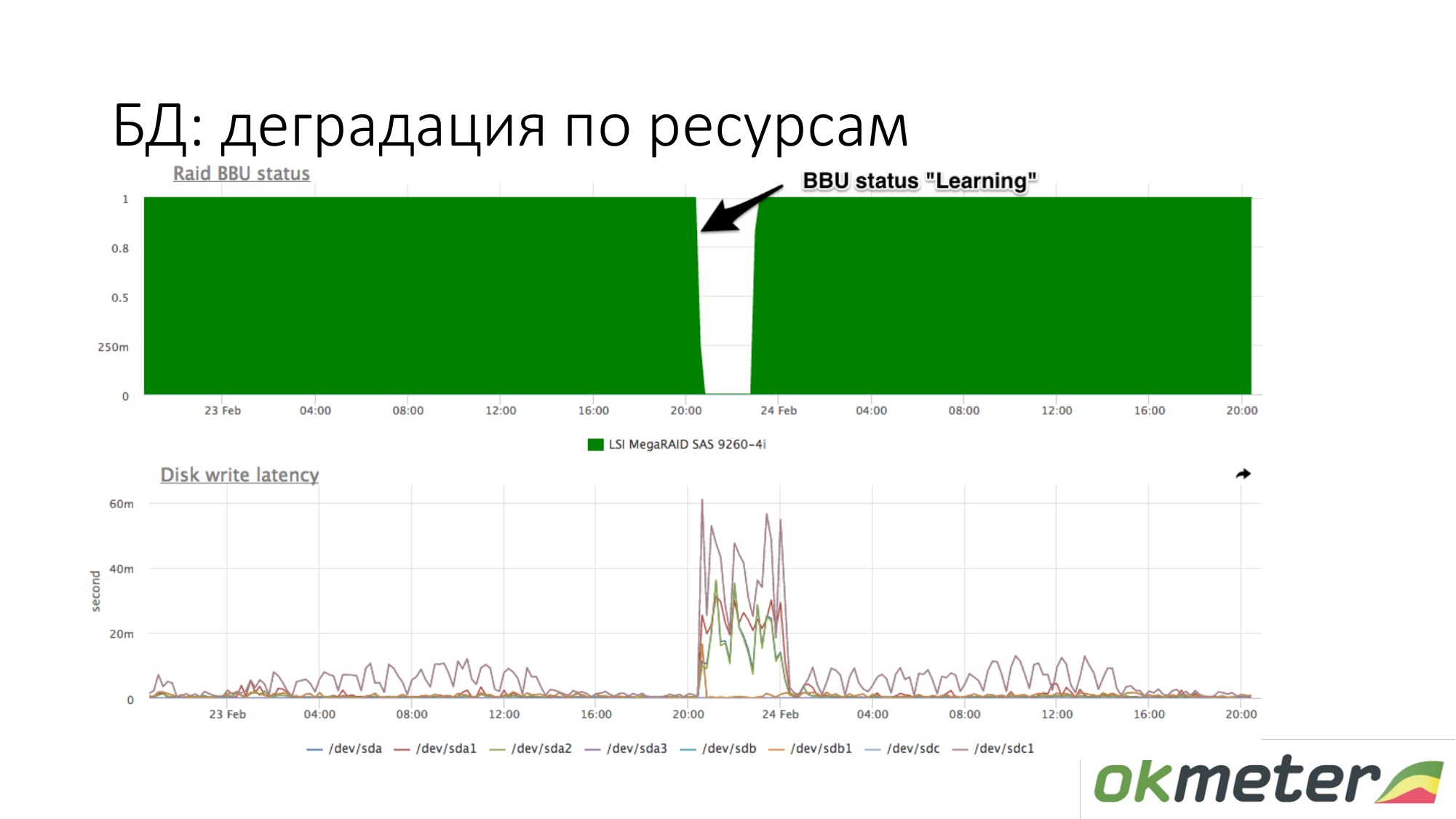
حول تدهور الموارد. على سبيل المثال ، دخلت بطارية RAID في وضع الصيانة. توقفت عن أن تكون وحدة تحكم مثل بطارية حية. في هذه المرحلة ، يتم فصل ذاكرة التخزين المؤقت للكتابة ، ويزداد اتساق أقراص الكتابة. في هذه المرحلة ، إذا بدأت قاعدة البيانات في التململ أثناء انتظار وجود قرص ، وكنت تعرف تقريبًا أن لديك وقتًا كاملاً مختلفًا للكتابة على القرص ، ثم تحقق من البطارية في RAID.

الموارد عند الطلب. انها ليست بهذه البساطة هنا. يعتمد على القاعدة. يجب أن يكون الأساس قادرًا على معرفة نفسه: ما هي الطلبات التي تنفق الموارد ، إلخ. القائد في هذا هو بوستجرس. لديه pg_stat_statements. يمكنك فهم نوع الطلب الذي تستخدمه كثيرًا من وحدة المعالجة المركزية وقراءة وكتابة القرص وحركة المرور.
في MySQL ، أن نكون صادقين ، كل شيء أسوأ بكثير. لديها performance_schema. يعمل بطريقة ما من الإصدار 5.7. على عكس طريقة عرض واحدة في PostgreSQL ، فإن performance_schema هو جدول عرض نظام 27 أو 23 في MySQL. في بعض الأحيان ، إذا قمت بإجراء استعلامات على الجداول الخاطئة (في طريقة العرض الخاطئة) ، يمكنك تبديد MySQL.
لدى Redis إحصائيات الفريق. ترى أن أمرًا معينًا يستخدم الكثير من وحدة المعالجة المركزية ، إلخ.
كاساندرا لديه أوقات لاستعلام جداول محددة. ولكن نظرًا لتصميم الكسندرا بحيث يتم تقديم نوع واحد من الاستعلامات على الطاولة ، فهذا يكفي للمراقبة.
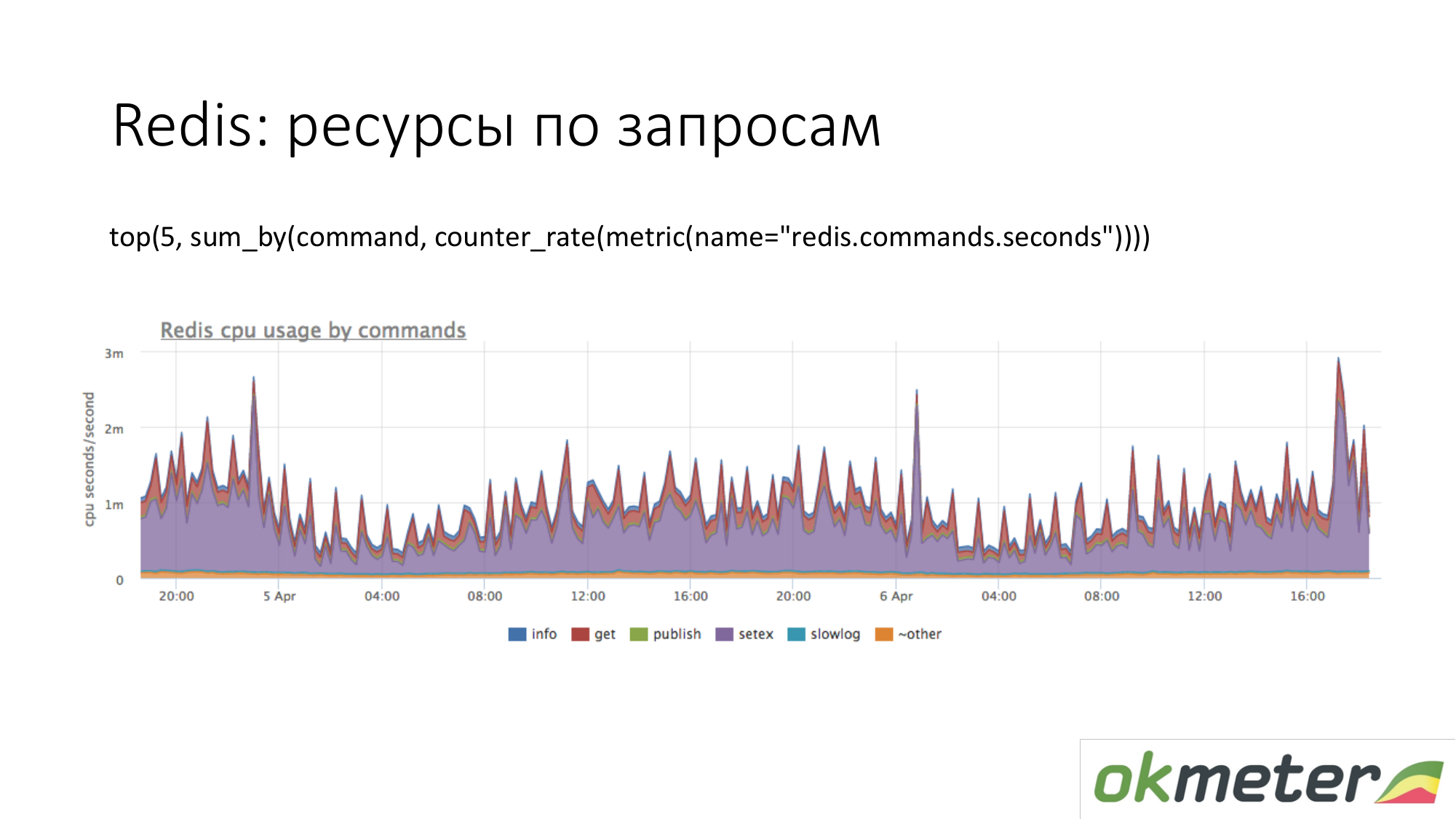
هذا هو رديس. نرى أن الأرجواني يستخدم الكثير من وحدة المعالجة المركزية. البنفسجي هو setex. Setex - سجل رئيسي مع تثبيت TTL. إذا كان هذا الأمر مهمًا بالنسبة لنا ، دعنا نذهب للتعامل معه. إذا لم يكن هذا مهمًا بالنسبة لنا ، فنحن نعرف فقط أين تذهب كل الموارد.
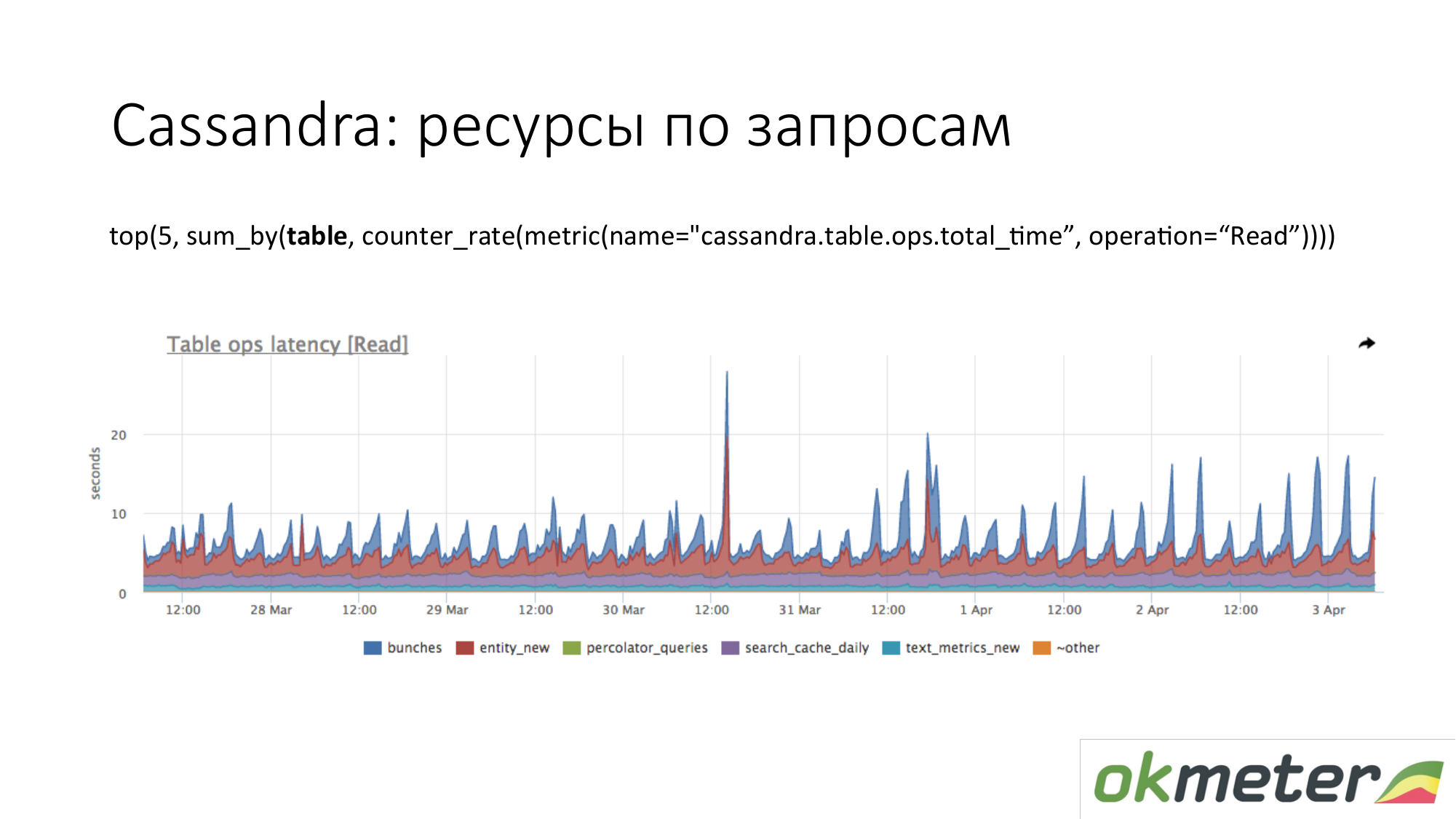
كاساندرا. نرى أعلى 5 جداول لطلبات القراءة حسب إجمالي وقت الاستجابة. نحن نرى هذه الزيادة. هذه استعلامات إلى الجدول ، ونحن نفهم تقريبًا أن استعلام لهذا الجدول يصنع جزءًا واحدًا من التعليمات البرمجية. Cassandra ليست قاعدة بيانات SQL يمكننا من خلالها تقديم استعلامات مختلفة على الجداول. أصبحت كاساندرا بائسة على نحو متزايد.

بضع كلمات عن سير العمل مع الحوادث. كما أراها.
عن حالة تأهب. نظرتنا لسير عمل الحادث مختلفة عن ما هو مقبول عموما.

شديد الخطورة. نعلمك عبر الرسائل القصيرة وجميع قنوات الاتصال في الوقت الحقيقي.
Severy Info عبارة عن مصباح كهربائي يمكنه مساعدتك في شيء عند التعامل مع الحوادث. لا يتم إخطار المعلومات في أي مكان. المعلومات معلقة فقط ويخبرك أن هناك شيئًا ما يحدث.
تحذير Severy هو شيء يمكن إخطاره ، ربما لا.

أمثلة حرجة.
الموقع لا يعمل على الإطلاق. على سبيل المثال ، زادت نسبة 5xx 100٪ أو وقت الاستجابة وبدأ المستخدمون في المغادرة.
أخطاء منطق الأعمال. ما هو الحرج. من الضروري قياس المال في الثانية الواحدة. المال في الثانية الواحدة هو مصدر جيد للبيانات الحرجة. على سبيل المثال ، عدد الطلبات والترويج للإعلانات وغيرها.

سير العمل مع الحرجة بحيث لا يمكن تأجيل هذا الحادث. لا يمكنك النقر فوق "موافق" والعودة إلى المنزل. إذا جاء لك Critical وكنت تأخذ المترو ، فيجب عليك الخروج من المترو ، والخروج من المنزل ، والجلوس في مقعد ، والبدء في الإصلاح. خلاف ذلك ، فإنه ليس حاسما. من هذه الاعتبارات ، نقوم ببناء الشدة المتبقية للسمة المتبقية.

تحذير. أمثلة تحذير.
- مساحة القرص تنفد.
- تعمل الخدمة الداخلية لفترة طويلة ، ولكن إذا لم تكن لديك خدمة حرجة ، فهذا يعني أنك مشروط على أي حال.
- العديد من الأخطاء على واجهة الشبكة.
- الأكثر إثارة للجدل هو الخادم غير متوفر. في الواقع ، إذا كان لديك أكثر من خادم وكان الخادم غير متاح ، فهذا تحذير. إذا لم يكن لديك خلفية واحدة من أصل 100 ، فمن الغباء أن تستيقظ من الرسائل القصيرة وستحصل على مدراء عصبيين.
تم تصميم جميع Severy الأخرى لمساعدتك في التعامل مع Critical.

تحذير. نحن نؤيد هذا النهج للعمل مع تحذير. يفضل تحذير إغلاق خلال اليوم. لقد عطل معظم عملائنا إشعار التحذير. وبالتالي ، ليس لديهم ما يسمى رصد العمى. هذا يعني طي الحروف في البريد دون قراءة دليل منفصل. لقد عطل العملاء تنبيه التحذير.
(كما أفهمها ، فإن المراقبة الخالصة هي تنبيهات غير ضرورية ومشغلات تضاف إلى الاستثناءات - مذكرة من مؤلف المنشور)
إذا كنت تستخدم تقنية المراقبة الخالصة ، إذا كان لديك 5 تحذير جديد ، فيمكنك إصلاحها في وضع هادئ. لم يكن لديهم الوقت لإصلاحها اليوم ، لكنهم أجلوا ذلك حتى يوم غد ، إن لم يكن بشكل حاسم. إذا كان الإنذار يضيء ويطفأ نفسه ، فيجب أن يكون ذلك ملتفًا في المراقبة حتى لا تهتم مرة أخرى. عندها سوف تكون أكثر تسامحًا معهم ، وبالتالي ، ستتحسن الحياة.

أمثلة من المعلومات. ومن الجدل أن استخدام وحدة المعالجة المركزية عالية من الحرجة. في الواقع ، إذا لم يؤثر أي شيء ، فيمكنك تجاهل هذا الإشعار.

تحذير (ربما أرى معلومات - ملاحظة من مؤلف المنشور) هذه هي الأضواء التي تضيء عندما تأتي لإصلاح الحرجة. تشاهد علامتي تحذير جنبًا إلى جنب (ربما يوجد رابط معلومات - مذكرة من مؤلف المنشور). يمكنهم مساعدتك في حل الحادث باستخدام Critical. لماذا ليس من الواضح حول استخدام وحدة المعالجة المركزية عالية بشكل منفصل في SMS أو في رسالة.
معلومات عديمة الفائدة هي أيضا سيئة. إذا قمت بتكوينها كاستثناء ، فستحب المعلومات كثيرًا.

المبادئ العامة لتصميم التنبيه. تنبيه يجب أن تظهر السبب. هذا مثالي. ولكن هذا صعب التحقيق. نحن هنا نعمل بدوام كامل على المهمة ، وتبين مع بعض النجاح.
الجميع يتحدث عن الحاجة إلى الإدمان ، والسحر التلقائي. في الواقع ، إذا لم تتلقى إعلامات حول شيء لا تهتم به ، فلن يكون هناك الكثير. في ممارستي ، تظهر الإحصاءات أن الشخص سوف ينظر في لحظة وقوع حادث حرج بأعينه نحو مائة مصباح قطري. سيجد الشخص المناسب هناك ولن يعتقد أن التبعية قد أخفت أي لمبات من شأنها أن تساعدني الآن. في الممارسة العملية ، وهذا يعمل. كل ما عليك فعله هو تنظيف التنبيهات غير الضرورية.

(هنا تم تخطي الفيديو - ملاحظة لمؤلف المشاركة)

سيكون من الرائع تصنيف هذه التوقف حتى تتمكن من العمل معهم لاحقًا. على سبيل المثال ، استخلص النتائج التنظيمية. عليك أن تفهم لماذا كنت تكذب. نقترح تصنيف / تقسيم إلى الفئات التالية:
- صنع الإنسان
- هوستر اقامة
- جاء السير
إذا قمت بتصنيفها ، فسيكون الجميع سعداء.

وصلت الرسائل القصيرة. ماذا نفعل؟ أولاً نركض لإصلاح كل شيء. حتى الآن ، ليس هناك ما هو مهم بالنسبة لنا ، باستثناء التوقف. لأننا متحمسون للكذب أقل. ثم ، عندما يتم إغلاق الحادث ، يجب إغلاقه في نظام المراقبة. نعتقد أنه يجب فحص الحادث من خلال المراقبة. إذا لم يتم تكوين جهاز المراقبة الخاص بك ، فهذا يكفي للتأكد من انتهاء المشكلة. يجب أن يكون هذا ملتوية. بعد إغلاق الحادث ، لم يتم إغلاقه فعليًا. إنه ينتظر بينما تصل إلى أسفل السبب. أي قائد ، في الواقع ، يحتاج أولاً وقبل كل شيء إلى ضمان عدم تكرار المشكلات. أن المشاكل لم تتكرر ، تحتاج إلى الوصول إلى الجزء السفلي من السبب. بعد أن وصلنا إلى أسفل السبب ، لدينا بيانات لتصنيفها. نحن نحلل الأسباب. ثم ، عندما نصل إلى أسفل السبب ، يتعين علينا القيام به في المستقبل حتى لا يتكرر الحادث:
- يتطلب الأمر شخصين كل ثلاثة أشهر لكتابة هذا المنطق وكذا في الواجهة الخلفية.
- بحاجة إلى وضع المزيد من النسخ المتماثلة.
من الضروري التأكد من عدم حدوث نفس الحادث بالضبط. عندما تعمل في مثل هذا سير العمل من خلال التكرار N ، تنتظرك السعادة ، وقت تشغيل جيد.
لماذا قمنا بتصنيفهم؟ يمكننا أن نأخذ الإحصائيات الخاصة بالربع ونفهم ما هي أوقات التوقف التي أعطاك أكثر. ثم العمل في هذا الاتجاه. يمكنك العمل على جميع الجبهات لن تكون فعالة للغاية ، خاصة إذا كان لديك موارد قليلة هناك.

حسبنا أننا نضع الكثير من الوقت ، على سبيل المثال 90 ٪ بسبب المضيف. نحن تهمة نحن تغيير هذا هوستر. إذا عبث الناس معنا ، فنرسلهم إلى الدورات التدريبية. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
سؤال: عند أي نقطة وكيف يتم تحديد العتبة؟ من يفعل هذا؟
الإجابة: أتيت إلينا وتقول: نريد أن نسأل بعض النقاد عن مشروعنا. إذا وضعت 10 5xx في الثانية الآن ، فكم عدد الإخطارات التي ستتلقاها قبل أسبوع.
سؤال: ما هو عبء كل هذا الرصد الجيد؟
الجواب: في المتوسط ، غير مرئية بشكل عام. ولكن إذا قمت بتحليل 50،000 RPS ، فسيكون ذلك من 1٪ إلى 10٪ من وحدة المعالجة المركزية. بما أننا نراقب فقط ، فقد قمنا بتحسين وكيلنا. نقيس أداء الوكيل. إذا لم يكن لديك الموارد التي يجب مراقبتها على الخادم ، فأنت تقوم بشيء خاطئ. يجب أن يكون هناك دائما موارد لرصد. إذا لم تقم بذلك ، فستكون أعمى عند اللمس لإدارة مشروعك.