لم تعد طوبولوجيا مراكز البيانات الحديثة والأجهزة فيها تسمح لنا بأن نكون راضين حصريًا عن
طريق مراقبة الصندوق الأبيض . بمرور الوقت ، كنت بحاجة إلى أداة تُظهر أداء أجهزة معينة ، استنادًا إلى الموقف الحقيقي مع نقل حركة المرور (dataplane) في أي مكان في
شبكة Clos . قبل بضعة أسابيع في مؤتمر
Next Hop ، تبادل ألكساندر كليمنكو مهندس شبكة ياندكس تجربته في حل هذه المشكلة.
- أعمل في قسم التشغيل والتطوير في شبكة ياندكس ، وأحيانًا يجبرونني على حل بعض المشاكل ، بدلاً من رسم السحب الجميلة على المنشورات أو ابتكار مستقبل مشرق. يأتي الناس ويقولون أن شيئا ما لا يعمل لصالحهم. إذا تم رصد هذه المسألة ، وإذا رأى مهندسون واجبنا أنها لا تعمل ، فسيكون ذلك أسهل بالنسبة لي. لذلك سيتم تخصيص هذه نصف ساعة للرصد.

عاجلاً أم آجلاً ، يأتي الجميع بفكرة المراقبة. هذا هو ، في البداية يمكنك جمع نداءات من المستخدمين أنفسهم ، وسوف يقرعونك ويقولون إن شيئًا ما لا يصلح لهم. لكن من الواضح أن مثل هذا النظام لا يتطور بشكل جيد. إذا كان لديك أكثر من مفتاح ، إذا كان لديك شبكة كبيرة بما فيه الكفاية ، فلن تتمكن من الذهاب بعيدًا باستخدام خيار المراقبة هذا.
وعاجلاً أم آجلاً توصل الجميع إلى استنتاج مفاده أنه من الضروري جمع بعض البيانات من الجهاز. هذه هي الخطوة الأولى. يمكن أن تكون سجلات ، بيانات مختلفة عن SNMP ، قطرات ، يمكنك إنشاء طبولوجيا وفقًا لـ LLDP ، وما إلى ذلك. هناك ناقص واضح - الجهاز نفسه يوفر لك كل هذه المعلومات. قد لا يقول أي شيء ، يخدعك ، إلخ.
المرحلة المنطقية في تطوير المراقبة هي المراقبة على الأجهزة المضيفة. يمكننا القول أن هناك فرع صغير. إذا كنت محظوظًا - أو محظوظًا - لديك شبكة على بائع واحد ، فيمكن أن يقدم لك البائع بعض خيارات المراقبة الخاصة بك. لكن في العام الماضي في Next Hop ،
قالت ديما Ershov أن مصنعنا تم إنشاؤه من بائعين أساسيين ولا يمكننا تحمل تكلفة مثل هذا الرفاهية. أو نستطيع ، ولكن جزئيا فقط.
أخيرًا ، الخيار الأخير ، والذي يصل إليه الجميع بطريقة أو بأخرى مع تطوير الشبكة. هذا هو رصد على نهاية المضيفين. ياندكس لديه مثل هذا الرصد. يطلق عليه Netmon.

يوجد أسفل الشريحة
رابط مع عرض تقديمي مفصل حول كيفية عمل Netmon. سأقول حرفيا ضمن شريحة واحدة. إذا كان أي شخص يريد ذلك ، يرجى قراءة الحديث من مؤتمر Netmon آخر.
Netmon عبارة عن عوامل تم تثبيتها على كل مضيف تقريبًا على الشبكة. تصل المهمة إلى الوكلاء: لإرسال بعض الحزم إلى بعض عقدة الشبكة. يمكن أن تكون مختلفة تماما: UDP ، TCP ، ICMP. يمكن أن يكون مثل الدهانات المختلفة ، وهذا هو ، DSCP ، والوجهة. يمكن أن تكون منافذ المصدر والوجهة مختلفة أيضًا.
يتم تجميع هذه البيانات وتحميلها على مساحة تخزين منفصلة ، ونصل إلى هنا شريحة مثل تلك الموجودة على اليمين في الشكل. يمكن أن تكون الشريحة أكثر تجميعًا أو أقل تجميعًا ، وفقًا لما نريد رؤيته. على سبيل المثال ، هنا ، حسب ما أراه ، لدينا شريحة من جميع اتصالات مركز البيانات ، أي بين جميع مراكز البيانات لدينا. يمكننا التعمق في المربعات - انظر الاتصال بين POD أو داخل مبنى مركز بيانات واحد ؛ أعمق - داخل POD بين الرفوف. وحتى أعمق - حتى داخل الرف.

ما الذي يمكن أن يحدث خطأ هنا؟ استطرادا صغيرا لأولئك الذين لم يشاهدوا قفزة العام الماضي.
استخدمنا 400 غيغابايت لكل ToR ، وفي اللحظة الأولى من تنفيذ هذا المصنع ، قمنا بتضمين 200 فقط ، لأنه كانت هناك مهام أكثر أهمية. لا يهم لماذا. تحولوا على 200 ، وجاءت الخدمات وقال: لماذا 200؟ نريد 400! بدأت لتشغيله. وحدث ما حدث أن الجزء الثاني من المصنع ، الذي قمنا بإدراجه ، كان له نوع من الزواج في ذاكرة البطاقات. نتيجة لذلك ، نفتح المصنع ونرى هذه الصورة:

نتمون ، المربعات الحمراء ، على النار. نحن نفهم أن كل شيء ضائع. نحن نمسك برؤوسنا ، مثل هومر ، ونحاول دفع شيء بشكل محموم. وما للضغط ، ما لإيقاف ، نحن لا نفهم. أي أن Netmon يُظهر لنا وجود مشكلة ، لكنه لا يُظهر مكان المشكلة في الشبكة.

لقد توصلنا إلى المهمة التي نحتاج إلى إكمالها. ما يجب القيام به؟ حدد أي جهاز على الشبكة يوجد مشكلة وأخرجه من الخدمة - إما تلقائيًا أو عن طريق القوات ، على سبيل المثال ، المهندسين في الخدمة.
علاوة على ذلك ، فإن الشروط الأولية هي أن لدينا طوبولوجيا منتظمة إلى حد ما ، أي أنه لا توجد روابط غريبة بين يدور المستوى الثاني أو بين توري. لدينا معظم حركة المرور - TCP ، يوجد مكان مركزي ، وقد تم إخبارنا به بالفعل ، وتتم إدارة الخوادم بشكل أو بآخر بشكل مركزي. يمكننا أن نأتي إلى هذا المكان المركزي ونعلن بشكل معقول: أيها الرجال ، نريد أن نفعل ذلك ، يرجى القيام بذلك.
ما هي الخيارات التي درسناها؟

أول ما يتبادر إلى الذهن هو البحث عن المفقودين. لماذا؟ لأن نفس Netmon يفرغ أزواج المصدر والوجهة الفاشلة في أداة تجميع منفصلة. وفقًا لذلك ، يمكننا أن نأخذ هذا 5-tuple ، وننظر إليه ونعمل على تتبع نفس المعلمات. ولتجميع البيانات حول أي رابط أو من خلال الأجهزة التي يمر بها أكبر عدد من التتبعات.
لكن لسوء الحظ ، يتم استخدام MPLS في المصنع (الآن نحن نتحرك في الاتجاه المعاكس من MPLS ، لكننا نحتاج أيضًا إلى مراقبة المصانع القديمة بطريقة أو بأخرى ، ولكن لا نرميها فعليًا). لدينا MPLS في المصنع ، والمشكلة مع MPLS والتتبع هي أنه يحتاج إلى نفق TTL تجاوز رسالة ICMP ، والتي تقوم عليها التتبع. بعد فقد مثل هذه الرسالة من الدخول إلى الخروج ، يمكننا أن نفقد المراقبة ذاتها. وهذا يعني أننا لن نفهم من خلال العقد التي مرت هذه الرسالة. هذا لم يناسبنا للمراقبة.
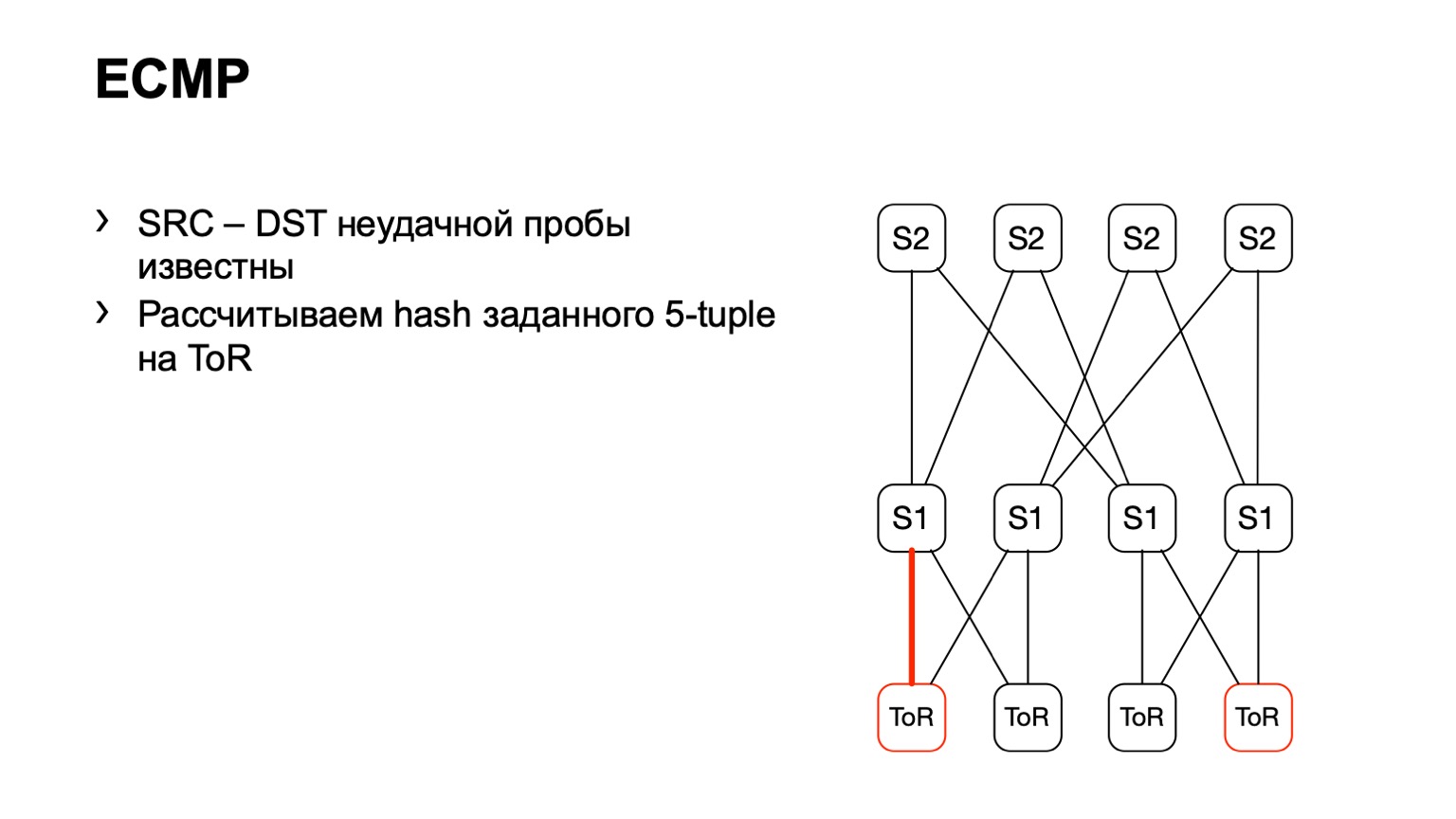
هناك خيار ثان متعلق بـ ECMP. نحن نأخذ نفس زوج المصدر والوجهة ، بالإضافة إلى منفذ منفذ المصدر. نأتي إلى قطعة واحدة من الحديد ، من خلال API أو من خلال CLI نقوم بتغذية هذه القطعة من الحديد بقطعة من الحديد ، ونحصل على واجهة الإخراج. تدعم العديد من الأجهزة هذا النوع من الإخراج.
نأتي إلى ToR ، نرى أن ToR قد اختار رابطًا يسارًا أو يمينًا. في هذه الحالة ، يكون الرابط الأيسر باتجاه S1 الأيسر.
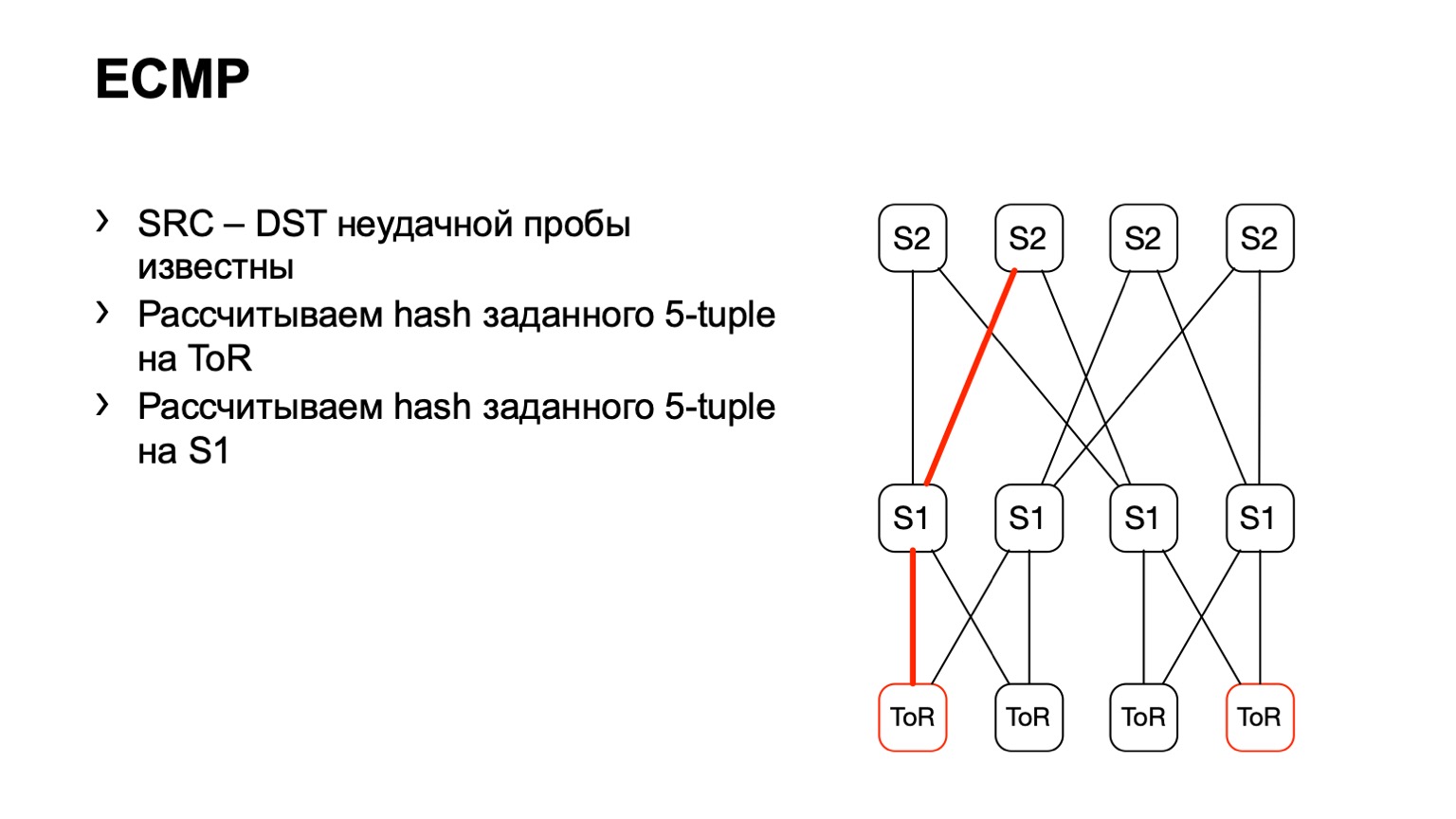
لقد جئنا إلى هذا S1 ، نظرنا ، S2 الصحيح ، وبهذه الطريقة تشكل مسار جاهز.
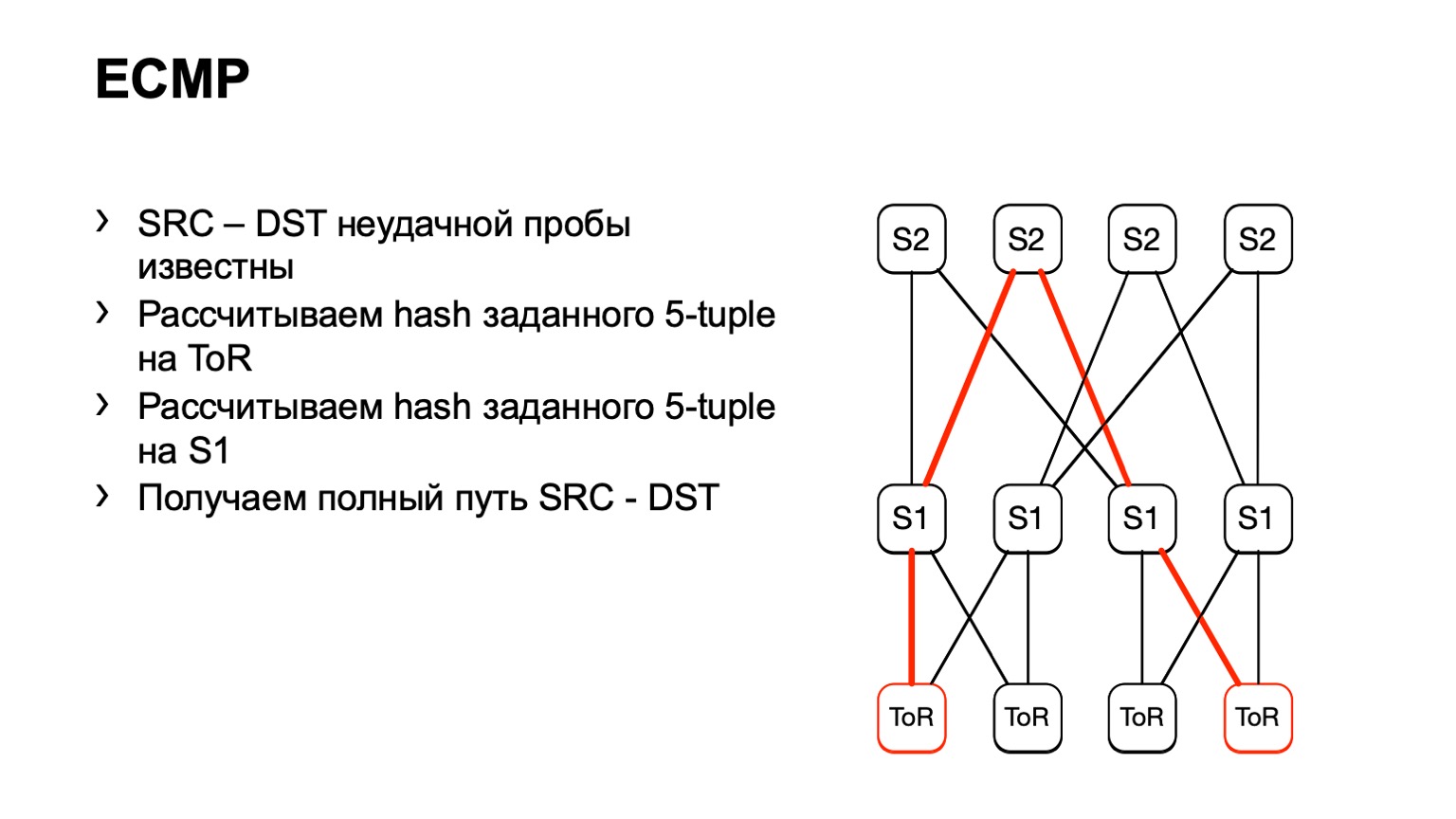
هناك بعض العيوب. أولاً ، لا يمكن لجميع الأجهزة عادة قبول بيانات الإدخال هذه التي نقدمها لهم. هذا يرجع إلى حقيقة أن لدينا IPv6 و MPLS ، وكذلك حقيقة أن بعض البائعين ببساطة لم تنفذ هذا. الثاني ناقص هذا الحل: نحن نعتمد على ما سوف يخبرنا قطعة الحديد مرة أخرى ، بدلاً من النظر إلى ما يحدث على المضيفين. وأخيرًا ، الطرح الثالث - خلال الوقت الذي تذهب فيه لترى ما يحدث هناك ، يمكن أن يتغير شيء بالفعل على الشبكة ولن تكون بياناتك ذات صلة.

ثم صادفنا عرضًا مثيرًا للاهتمام قدمه Facebook. لقد أحببنا الفكرة التي اقترحها Facebook ، فقررنا محاولة القيام بشيء مماثل.
ما هي الفكرة الرئيسية؟ استخدم برنامج eBPF على المضيف لتلوين إعادة إرسال TCP ثم حساب عدد هذه الحزم. لسوء الحظ ، لم نتمكن من فعل ذلك على Facebook ، كان علينا أن نخترع دراجتنا الخاصة. سأحاول إخبارك عن طريق الألم والمعاناة الذي مررنا به.
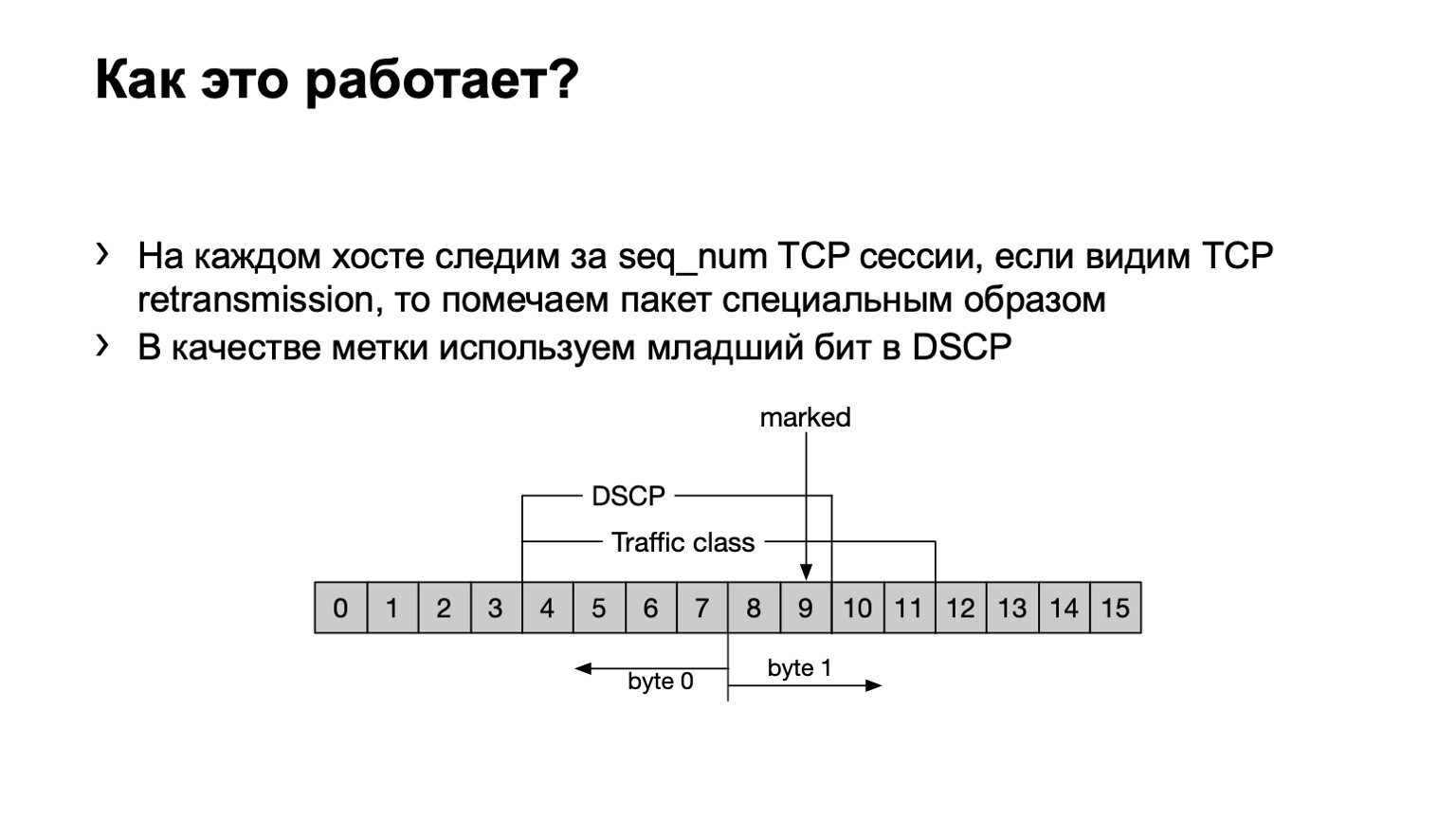
ماذا فعلنا؟ فقط في حالة حدوث ذلك ، سأشير إلى أن إعادة إرسال TCP عبارة عن رسائل TCP تتكرر عدة مرات بسبب عدم تأكيد استلامها. لدينا برنامج eBPF مثبت على المضيف وننظر فيما إذا كانت رسالة TCP هذه تعاد إرسالها أو لا تعيد إرسالها. يفعل ذلك مبتذل - رقم التسلسل. إذا تم إرسال نفس الرقم التسلسلي في جلسة TCP ، فسيتم إعادة الإرسال.
ماذا نفعل مع هذه الحزم؟ لقد قمنا بتعيين البت الأخير في حقل DSCP على واحد لزيادة حساب الشيء بالكامل.
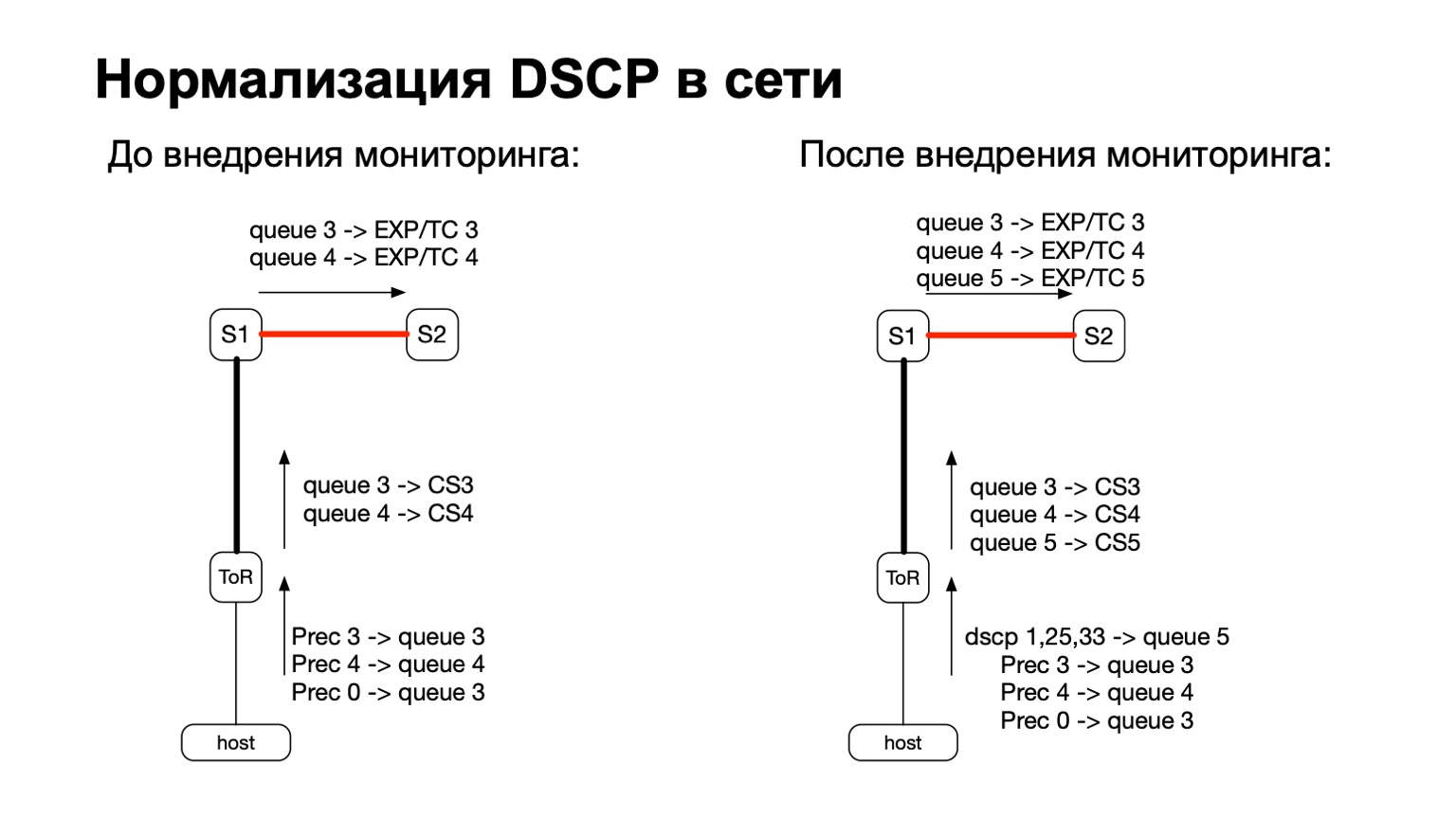
بشكل عام ، يرتبط DSCP بطريقة أو بأخرى بجودة الخدمة ، أليس كذلك؟ ومع جودة الخدمة ، فإن التاريخ في شبكتنا معقد للغاية وطويل الأمد. لدينا سياسات معينة يتم مراقبتها على مفاتيح ToR. في هذه السياسات ، أضفنا فقط الحاجة إلى حساب المزيد من هذه الحزم الملونة.
وبالتالي ، بالنسبة للحزم الملونة (اقرأ: لإعادة TCP إعادة إرسال الحزم من المضيف) ، قمنا ببساطة بإضافة قائمة انتظار جودة خدمة أخرى. كان هذا سهلا بما فيه الكفاية ، لأنه لا يزال لدينا خطوط حرة. بالإضافة إلى ذلك ، يعد هذا مناسبًا ، لأنه في مرحلة الانتقال بين IPv6 و MPLS في المصنع ، أي في المرحلة عندما تطير الحزمة S1 وتترك إلى جزء MPLS الخاص بنا من المصنع ، من الملائم أخذ EXP / TC وإعادة طلائه في رأس حزمة MPLS لكل قائمة انتظار محددة .
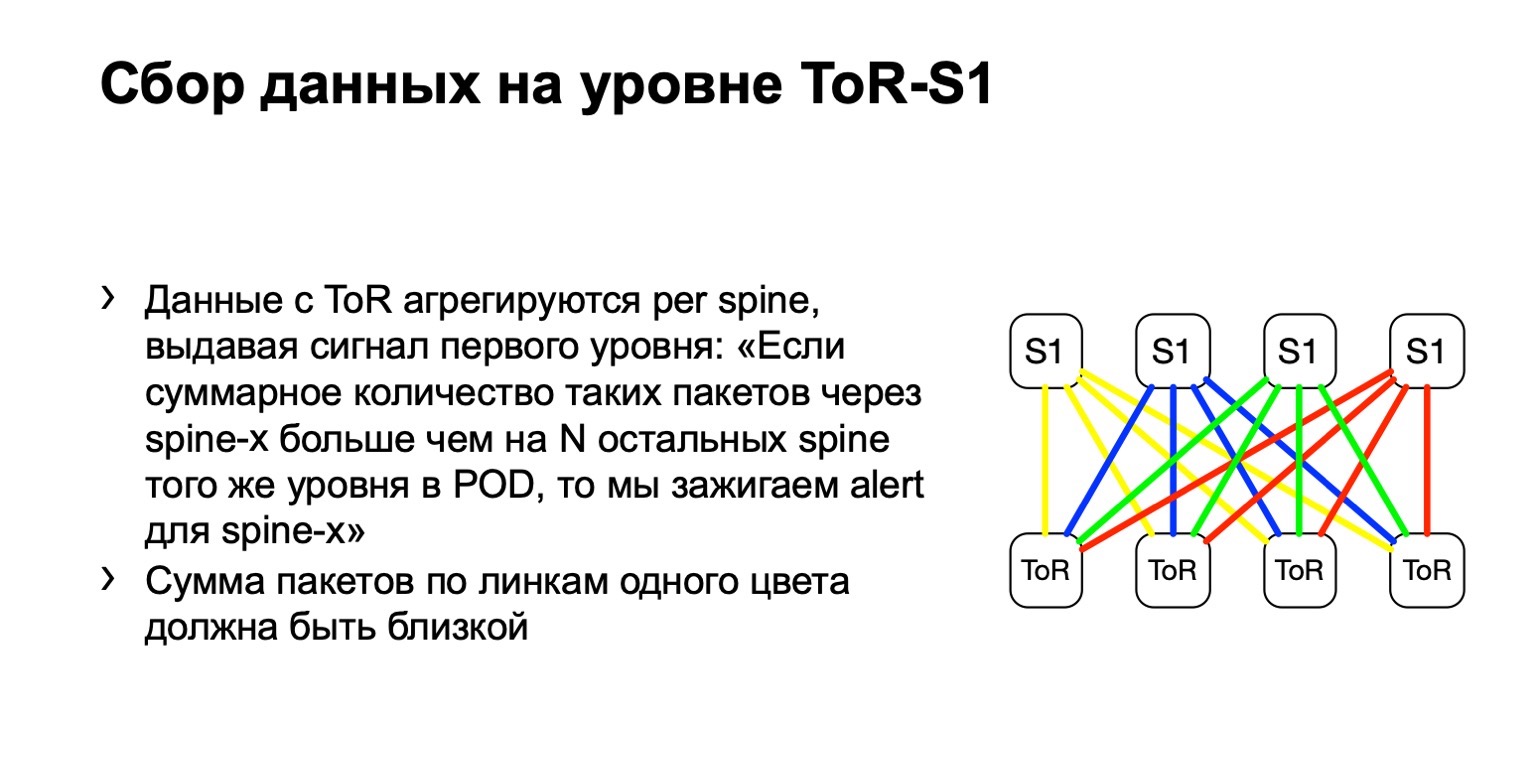
ماذا نفعل مع هذه البيانات؟ نجمعها مع مرشحات ACL القياسية ، فئة المرور. وهذا هو ، وأنها تعمل ، من حيث المبدأ ، على أي بائع. يمكننا جمع وحساب عدد هذه الحزم في كل مكان.
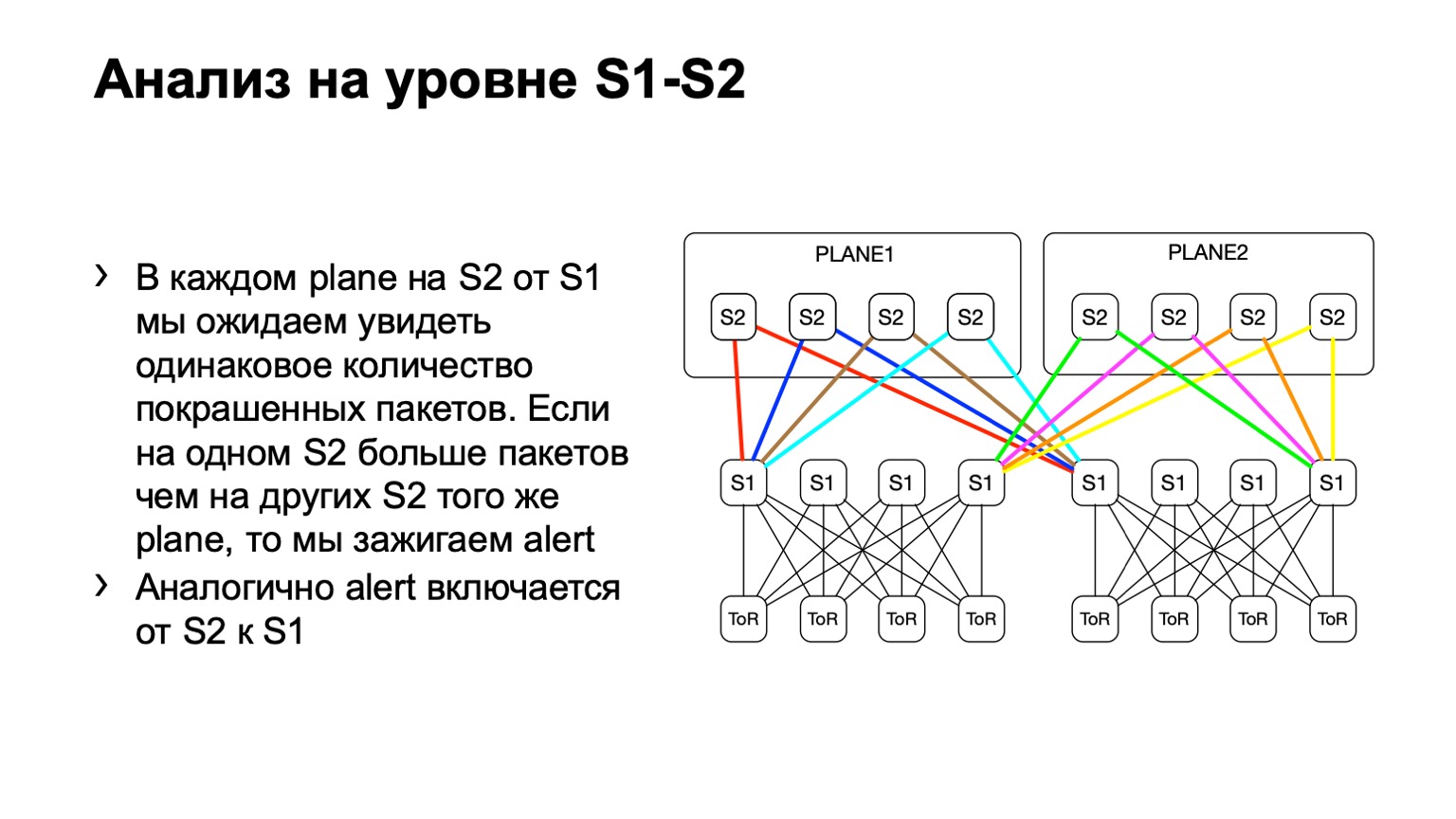
بعد ذلك ، ننظر إلى التوزيع غير المتكافئ لهذه الحزم على POD. في ذلك ، على سبيل المثال ، أربعة العمود الفقري ، كما في الصورة. إذا كان عدد الحزم على الوصلات الصفراء والأزرق والأخضر والأحمر هو نفسه ، فإننا نعتقد أن كل شيء جيد إلى حد ما. إذا رأينا في وقت ما زيادة ، على سبيل المثال ، في أقصى اليمين من العمود الأول من المستوى الأول ، ندرك أن هذا الجهاز يجذب إعادة الإرسال ، هناك خطأ في ذلك. ثم نحاول إما إيقاف تشغيله ، أو على الأقل تأجيره. على الأقل عندما نرى مشاكل على Netmon ، سنعرف مع الجهاز الذي قد تنشأ.
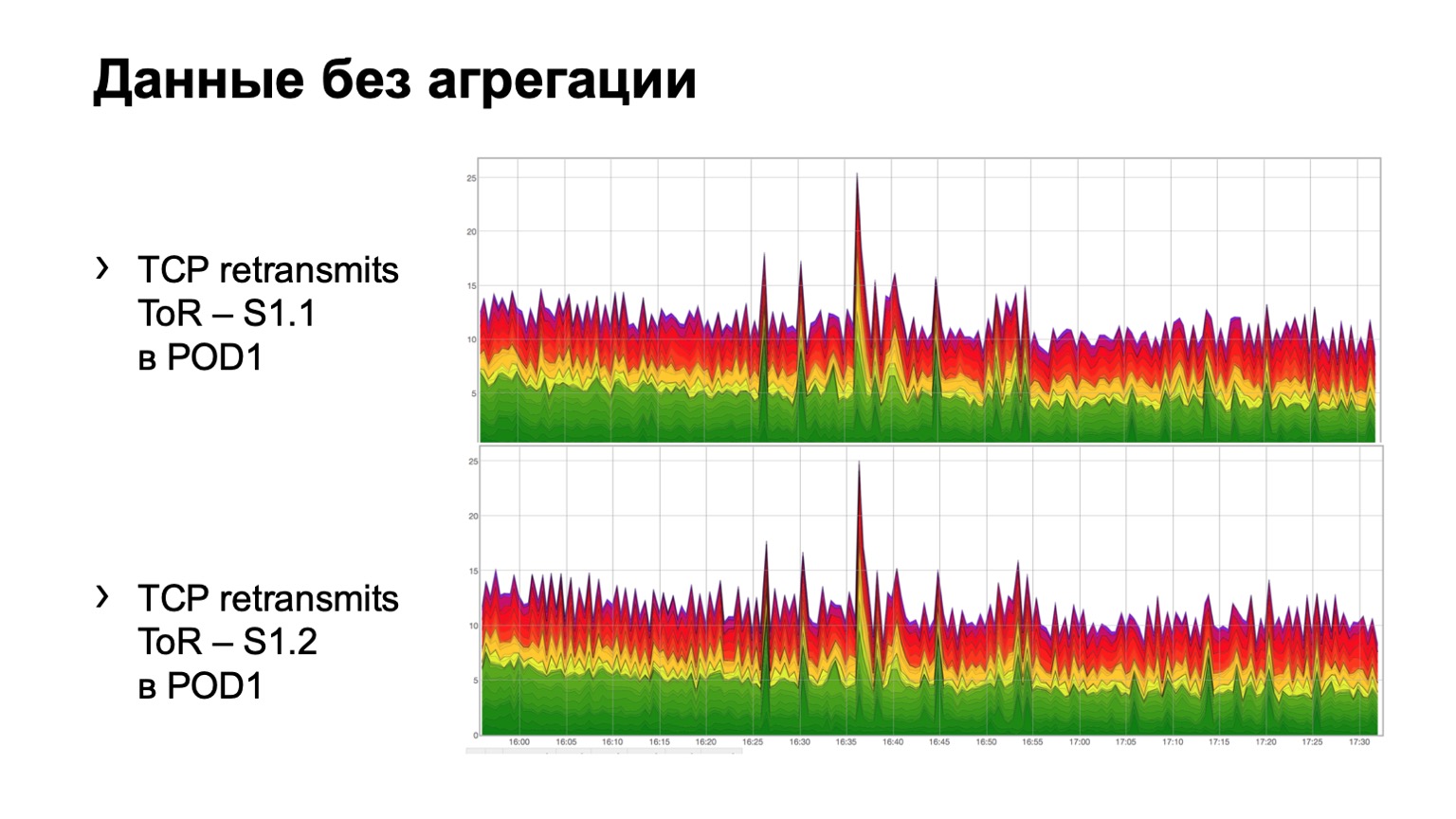
كيف تبدو البيانات الأولية البسيطة؟ هنا اثنين من الرسوم البيانية. في الواقع ، هذه هي مخططات إعادة إرسال مع ToR نحو العمود الفقري المستوى الأول. في المثال ، وهما العمود الفقري في الوحدة النمطية. الرسم البياني العلوي هو تجميع العمود الفقري الأول ، الرسم البياني السفلي هو العمود الفقري الثاني. مشاهدة هذا في هذا النموذج ليست مريحة للغاية ، لذلك أضفنا تجميع هذه المعلومات.
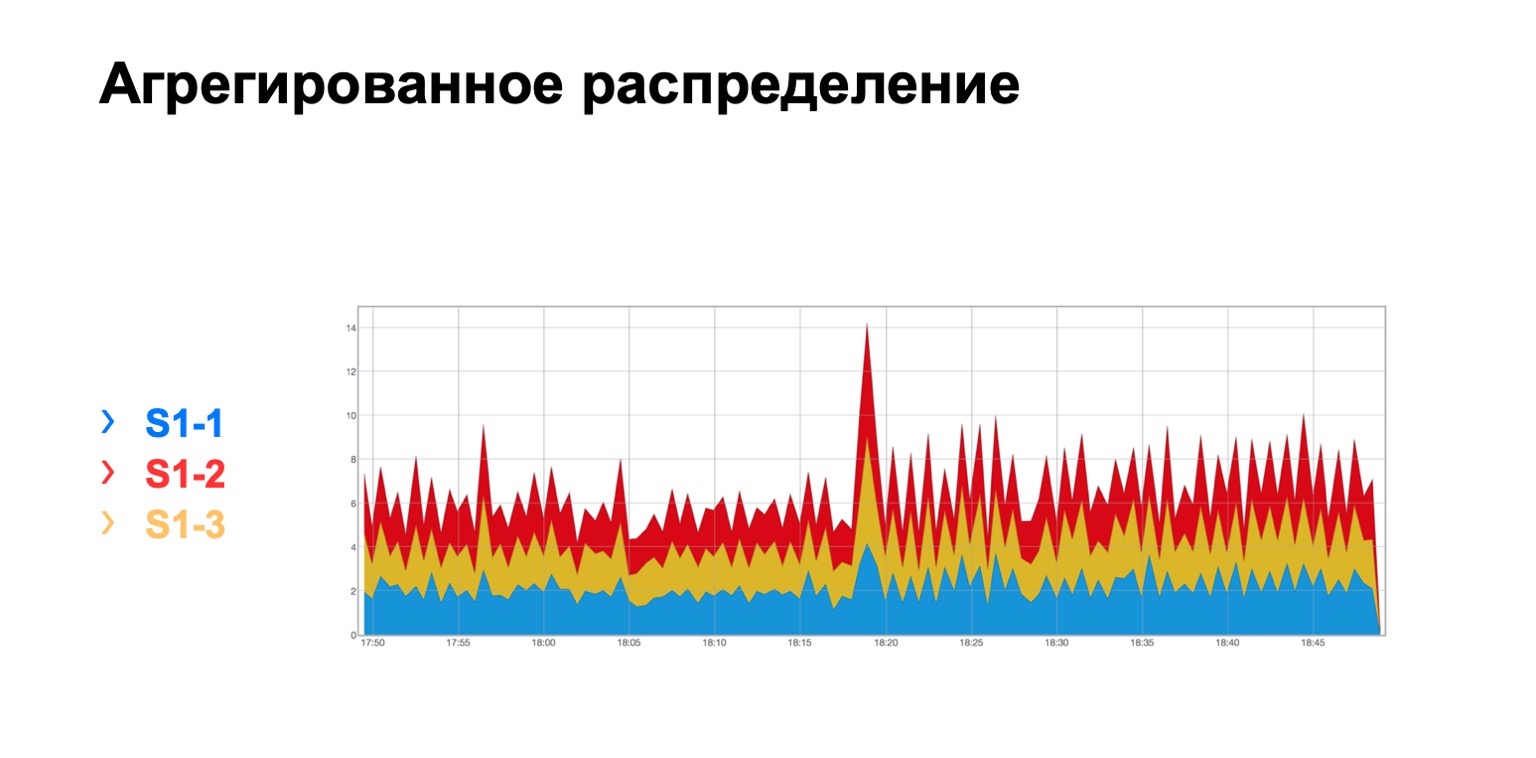
يبدو مثل هذا. هناك وحدة نمطية فيها ثلاثة أشواك ، لسبب ما ، بغض النظر عن أي منها ، ونرى هنا هذا التوزيع الكلي لإعادة الإرسال إلى ثلاثة أشواك. هو ، من حيث المبدأ ، موحدة إلى حد ما.
بالنسبة إلى العمود الفقري من المستوى الثاني ، قد يكون لدينا انحرافات مختلفة ، دعنا نسميها ذلك. لا يزال الطوبولوجيا منتظمًا ، ولكن وفقًا لمركز البيانات ، قد نستخدم أو لا نستخدم بنية تشبه اللوحة. النقطة هنا هي بالضبط نفس الشيء. عند مستوى واحد ، يجب أن يكون لدينا نفس التوزيع تقريبًا للحزم الملونة.
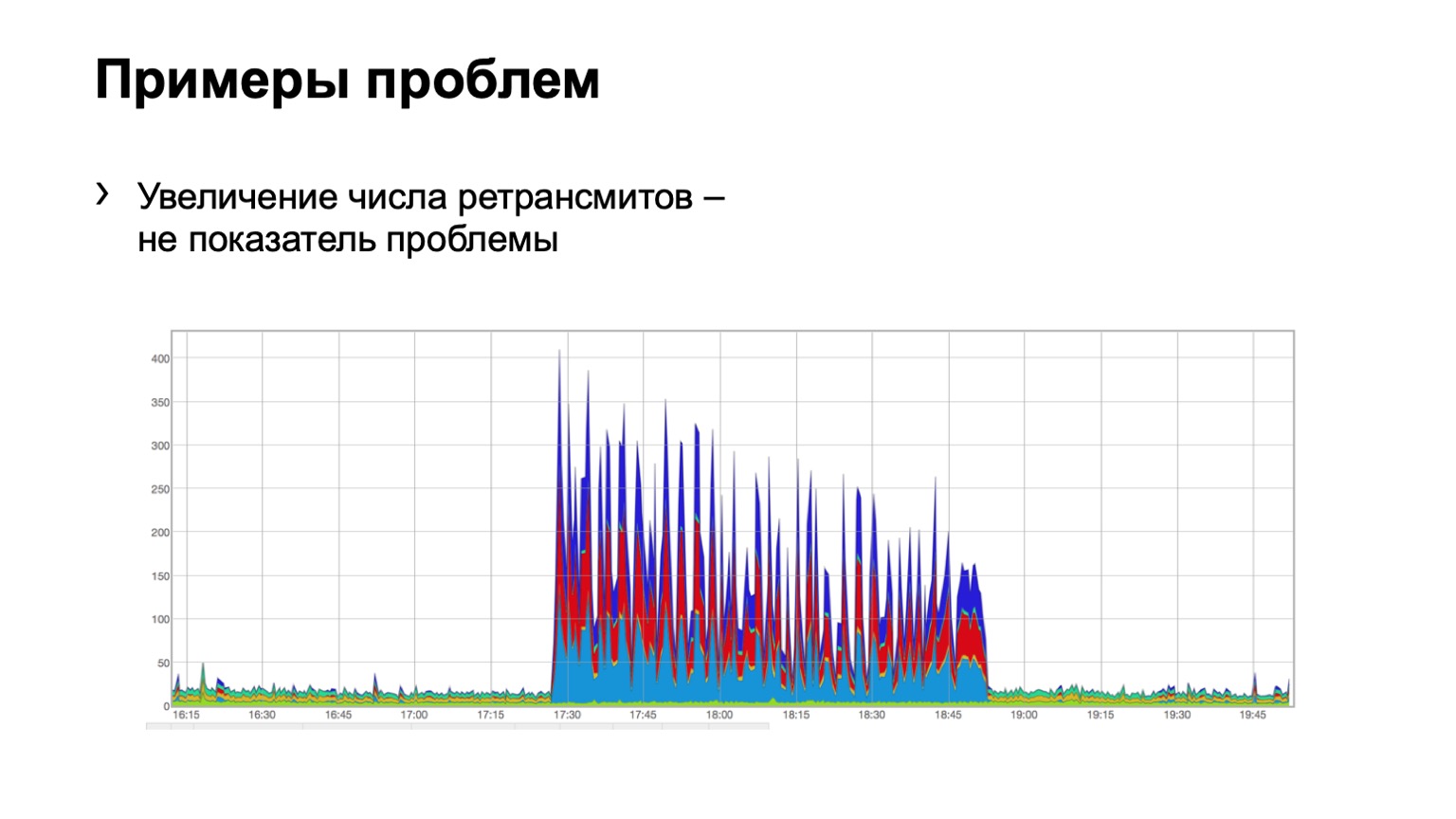
لنلقي نظرة على بعض الأمثلة. هل هناك مشكلة في مثل هذا المخطط؟ هناك مشكلة هنا ، لكنها ليست موجودة في نفس الوقت. نعم ، هذه مشكلة شرودنغر. لماذا هي هناك وليس؟ لأننا نرى زيادة في عدد عمليات إعادة الإرسال ، فمن الواضح بشكل مباشر أن شيئًا ما حدث لنا. لكن في الوقت نفسه ، نرى أن هذا النمو موحد تمامًا. وهذا هو ، ثلاثة البلوز العمود الفقري ، والأحمر ، والبلوز ، وحتى توزيع عليها. ماذا يعني هذا؟ أن هناك مشكلة ما في الشبكة ، لكنها لا تتعلق بهذا المستوى من تجميع البيانات. هي في مكان آخر.
ربما قام شخص ما بإغلاق المنفذ على جدران الحماية ، وقطع بعض الكتلة ، أي حدث شيء ما. لكننا لسنا مهتمين على الإطلاق بما كان هناك ولماذا. وهذا هو ، حتى أننا لا نعتبر هذه المشكلة.
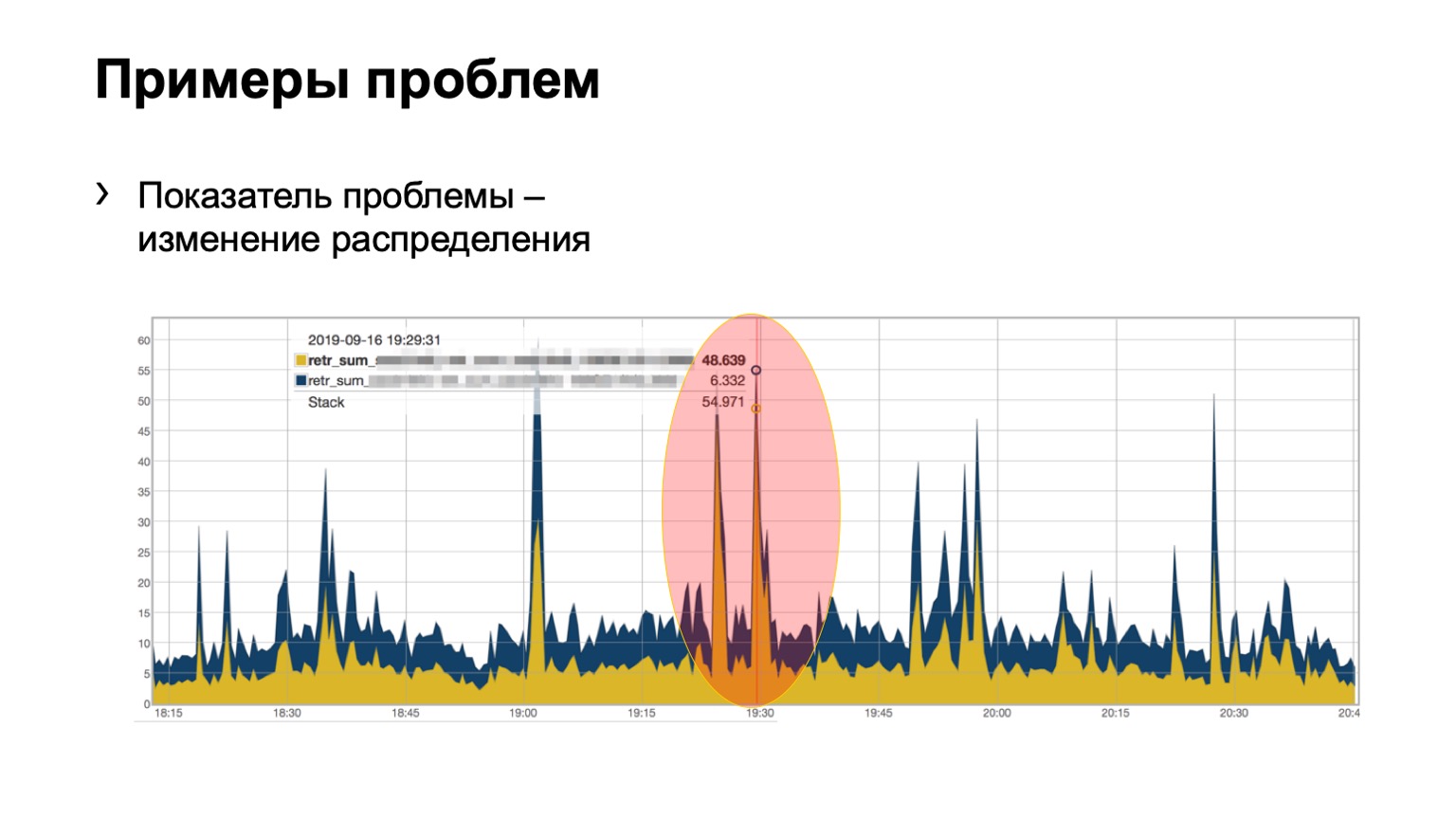
وهنا ، ربما ، ليس بشكل واضح ، لكن المشكلة واضحة. حلقت وحدتان في الوحدة ، 46 حزمة مرسومة على واحدة ، والثانية على الثانية. نحن نتفهم أن لدينا مشكلة في نوع من العمود الفقري على الشبكة ، وعلينا أن نفعل شيئًا حيال ذلك.
لماذا تحدثت أولاً عن طريق الألم والمعاناة؟ لأن هناك الكثير من المشاكل مع مثل هذا الحل. المشكلة الرئيسية هي ، بطبيعة الحال ، مشكلة أي رصد ، وهذا هو إيجابي كاذب. كان إيجابي كاذب الكثير. ويرجع ذلك أساسا إلى حقيقة أننا نستخدم DSCP وترتبط عموما بجودة الخدمة.

وجدنا أن حزم الأشخاص الآخرين تطير في الدهان وتنبهنا لرصدنا. هذا هو ، نعتقد أن هذا هو إعادة الإرسال ، وشخص آخر يضع حزمهم هناك ، وبشكل عام ، يفسد الصورة بالنسبة لنا. بطبيعة الحال ، بدأنا نفهم ، وجدنا الكثير من الأماكن التي اعتقدنا أنها تعمل ، لكنها في الواقع لا تعمل بالطريقة التي نفكر بها. على سبيل المثال ، يجب إعادة طلاء حركة المرور التي تدخل الشبكة ، ولا ينبغي أن تدخل شبكة الاتصال بفئات CS6 و CS7 على الحدود. ولكن في بعض الأماكن كانت هناك عيوب ، على سبيل المثال ، لقد تعاملنا معها بنجاح.
قدمت بعض الشركات المصنعة مفاجآت في النموذج الذي تقوم بحساب عدادات في الاتجاه الخارج من هذه الحزم ، وتعمل الشريحة بطريقة ، في الواقع ، لمعالجة قائمة الوصول الصادرة التي تلتف بها حركة المرور من خلال نفسها مرة أخرى ، العض من نصف عرض النطاق الترددي للرقاقة . كان 900 غيغابايت لكل رقاقة ، أصبح نصف ذلك.
وقد حققنا بعض التحسن بسبب حقيقة أن الإعدادات على المضيف يمكن أن تكون مختلفة. وهذا يعني أن بعض المضيفين يمكنهم إرسال عمليات إعادة الإرسال بشكل متكرر ، بينما يمكن لبعض المضيفين أن يقوموا في كثير من الأحيان ، أو اثنان ، أو نحو خمسة ، وكل هذا التنبيه الذي نراقبه ، وكل هذا إيجابي كاذب.
أولاً ، لقد تخلينا عن فكرة رسم كل بروتوكول TCP لإعادة الإرسال. لقد أدركنا أننا ، من حيث المبدأ ، لا نحتاج إلى كل عملية إعادة إرسال لفهم مكان المشكلة. بدأنا في الطلاء فقط SYN - إعادة الإرسال. SYN هي الحزمة الأولى في الجلسة ، وهذا يكفي لنا لتلقي إشارة. نحن طلاء SYN-ACL أيضا.
ومع ذلك ، أعطى بعض إيجابية كاذبة. ذهبنا أبعد من ذلك بقليل. بدأنا في الطلاء فقط أول TCP SYN - إعادة إرسال في الدورة. وهذا هو ، في الواقع هناك العديد منهم أرسلت ، ورسم كل منهما ، - بدأت واحدة فقط يتم رسمها. لذلك وصلنا إلى ما لدينا الآن.
في المجموع ، يوجد Netmon ، وهناك وكلاء على الأجهزة المضيفة يلونون إعادة إرسال SYN الأولى في الجلسة ، ونحسب عمليات إعادة الإرسال هذه على كل جهاز ، على كل رابط في شبكتنا تقريبًا.

لكن أنظر بعينيك إلى الصورة التي اعتدت أن أبدوها ليست مريحة للغاية. وهذا يعني أنه لا يمكنك بيعه إلى موظف واجب ، لأنه في كل قسم يجب عليك تقييم كل شيء بعينيك. وصلنا إلى حقيقة أنني أريد أن يكون في حالة تأهب. أريد أن يضيء مصباح: جهاز كذا وكذا مشكلة ؛ جهاز آخر يمثل مشكلة.
دعنا نتذكر بعض الإحصاءات الرياضية. الفكرة في حالة تأهب هي أن كل جهاز يمثل سلة. لدينا احتمال نجاح واحتمال فشل لأربعة أجهزة. احتمال إعادة الإرسال في السلة ، وهذا هو النجاح ، هو ¼. اتضح توزيع ذات الحدين.
ما هي صعوبة وضع تنبيه هنا؟ حقيقة أننا لا نستطيع أن نجعل العتبات ثابتة ، لا يمكننا القول: إذا وصلت عشر عمليات إعادة إرسال على جهاز وتسعة على جهاز آخر ، فلا مشكلة. وإذا كان العشر والخمسون ، فهناك مشكلة. لأنه إذا قمنا بتوسيعه إلى ألف PPS ، فلن تكون هذه البيانات ذات صلة بعد الآن. 1000 PPS و 800 PPS بين الأجهزة المختلفة هي بالتأكيد مشكلة.
لا يمكننا تعيين عتبات ثابتة في PPS أو بايت ، لا يمكننا تعيينها كنسبة مئوية - نفس المشكلة معهم. لذلك ، نحتاج إلى حل يجعل هذه العتبة ديناميكية إلى حد ما ، اعتمادًا على عدد الحزم.
وسحر التوزيع ذو الحدين هو أنه عند زيادة PPS ، فإنه يميل إلى طبيعته ، وبالنسبة للتوزيع الطبيعي ، يمكننا بالفعل حساب التوقع والتباين وحساب فاصل الثقة ، وهو ما فعلناه. الفاصل الزمني الثقة بالنسبة لنا هو 3NPQ ، وهذا يعتمد على عدد الحزم من خلال الجهاز. نتيجة لذلك ، لدينا عتبة التحول الديناميكي.
هذه هي الطريقة التي تبدو لدينا إشارة في الصورة. إذا تم إخراج بعض الأجهزة من التوزيع ، فسنرفع العلم عليها - هناك خطأ في ذلك.

أين نريد أن نطور أكثر ، ماذا نريد أن نحسن هنا ، بالإضافة إلى ، بالطبع ، مكافحة الكاذبة الإيجابية؟ بادئ ذي بدء ، سنكون مهتمين لمعرفة ما كان هناك في وقت المشكلة؟ للقيام بذلك ، لدينا مثل هذا الخيار في الوكيل - تصحيح. يمكننا تحميل ما تم إعادة إرساله بالتحديد ، أي حزمة مكونة من 5 أجزاء ، على سبيل المثال ، في مجمع منفصل ، ثم ننظر إليها. ولكن هذا يعطي بعض الحمل على المضيفين ، لذلك نحن محظورون في بعض الأحيان للقيام بذلك. نريد تثبيت ERSPAN وتفريغ مثل هذه الحزم على المجمع من الجهاز نفسه ، لأن لا أحد يمنعنا من القيام بذلك على الجهاز.
أخبرت ديما أفاناسييف كيف سنقوم بتطوير مصانعنا ، وكانت إحدى النقاط الانتقال من مصنع MPLS إلى IPv6 فقط. ماذا يعطينا هذا؟ تحتوي MPLS على ثلاث بتات لتمييز جودة الخدمة. في IPv6 ، ستة على الأقل. يتم استخدام ثلاث بتات فقط في شبكتنا الآن. أي أنه لا يزال لدينا ثلاث وحدات بت يمكننا من خلالها وضع أي معلومات من المضيف في الواقع.
على سبيل المثال ، نحن الآن نرسم فقط إعادة إرسال SYN الأولى في الجلسة. ويمكننا تلوين الجزء الثاني ، على سبيل المثال ، إذا انتقلت الحزمة إلى شبكة خارجية. ويمكننا إعادة إرسال ، أي تسليط الضوء على إشارة أخرى ، والتي سننظر فيها بشكل منفصل.
بالإضافة إلى ذلك ، فإن الانتقال إلى التصميم باستخدام الحافة المرنة ، عندما نفعل DCI في مكان معين ، يهددنا بحقيقة أنه في هذا المكان يمكننا التحكم بدقة أكبر في مجال الاختلاف. وهذا هو ، إعادة طلاء وفعل شيء مع الدهانات لقطع إيجابية كاذبة.
ونتيجة لذلك ، تبين أن كل ما سبق ذكره كان مؤلمًا ولكنه مثير للاهتمام. لم يكن هناك شيء يدعو للقلق. في الواقع ، قمنا بتطوير حل يمكن للجميع استخدامه. يتم اختباره على كل بائع تقريبًا ، إنه يعمل ، إنه ليس بالأمر الصعب. ويظهر حقا أي جهاز على الشبكة هناك مشكلة. لذلك ، رسالتي هي - لا تخف من أن تفعل الشيء نفسه ، ودع المراقبة تبقى خضراء. شكرا لك على الاستماع