استمرارًا لموضوع
لعب الذكاء الاصطناعي الذي تم طرحه في مدونتنا ، سنتحدث عن كيفية تطبيق التعلم الآلي عليه وعلى أي شكل. شارك جاكوب راسموسن ، وهو خبير في قضايا الذكاء الاصطناعي في أدوات ألعاب Apex ، تجربته والحلول التي تم اختيارها على أساسها.

في السنوات الأخيرة ، كان هناك الكثير من الحديث بأن التعلم الآلي سيغير صناعة الألعاب تغييراً جذرياً ، لأن هذه التكنولوجيا أصبحت بالفعل طفرة في العديد من التطبيقات الرقمية الأخرى. لكن لا تنسَ أن الألعاب أكثر تعقيدًا من محاكاة قيادة السيارة أو برنامج التحكم في الطائرة أو خوارزميات التعرف على الوجوه في صورة ما.
حتى الآن ، في صناعة الألعاب ، لا يزال من المعتاد استخدام أساليب AI التقليدية ، مثل طريقة آلة الحالة المحدودة ، وأشجار السلوك ، و- في الآونة الأخيرة - AI (الأنظمة القائمة على المنفعة). وتسمى أيضًا هذه الأدوات (أنظمة الذكاء الاصطناعي) أو أنظمة الخبراء القائمة على التصميم. ولكن أصبح من الواضح بشكل متزايد - ولاعبين في المقام الأول - أن هذه الأنظمة أقل ملاءمة لإنشاء خصوم متقدمين حقًا يمكنهم تقليد سلوك اللاعبين. هذا صحيح بشكل خاص للحلول الإبداعية. يمكن تفسير ذلك من خلال حقيقة أن مطوري الذكاء الاصطناعي غير قادرين على مراعاة جميع التكتيكات واستراتيجيات السلوك الممكنة وتنفيذها بنجاح في أنظمة الذكاء الاصطناعي التقليدية. بالنسبة للاعبين ، غالبًا ما يكون هذا مملًا ويمكن التنبؤ به للعب مع خصم يسهل تذكر سلوكه.
العديد من الأسباب تؤدي إلى هذه النتيجة ، ولكن أحد الأسباب الرئيسية هو عدم قدرة منظمة العفو الدولية على التعلم. لذلك ، عند إنشاء الذكاء الاصطناعي للعدو ، فإن قرار الانتقال إلى التعلم الآلي ، والذي أثبت نفسه في العديد من التطبيقات الأخرى ، يتبادر إلى الذهن من تلقاء نفسه. ولكن هناك العديد من الفروق الدقيقة التي تستحق النظر. لذلك ، يجب أن تكون لعبة AI قادرة على التكيف مع أي موقف واستخدام المزايا التي توفرها لها ، وكذلك التكيف مع أنماط لعبة مختلفة من المنافسين - اللاعبين المباشرين وغيرهم من الذكاء الاصطناعي.
كيف هي الأمور الآن
أظهرت شركة DeepMind البريطانية ، المنخرطة في تطوير الذكاء الاصطناعي ، مؤخرًا كيف يمكن لمنظمة العفو الدولية أن تتعلم بشكل مستقل ممارسة الألعاب وتعلم قواعدها وإيجاد طرق لتمرير اللعبة أو الفوز بها - حتى الآن فقط على سبيل المثال من الألعاب البسيطة ، مثل ألعاب
Atari المبكرة - على سبيل المثال ، لعبة الشطرنج واللعبة اليابانية تذهب. توضح النتائج التي تم الحصول عليها بالنسبة لهم أن الذكاء الاصطناعي قادر على تكوين تقييم مناسب لما يحدث في هذا المجال. إذا تحدثنا عن تكيف الذكاء الاصطناعي مع أنماط مختلفة من لعبة الخصم ، فإن النتائج ليست مثيرة للإعجاب.
في الوقت الحاضر ، تعلمت الشبكات العصبية بالفعل التعرف على الصور وقيادة السيارات. ولكن يمكن تحقيق هذه الوظائف بمساعدة بنيات بسيطة نسبيًا ، حتى لو كانت نتيجةً لذلك عميقة وحجمية. لذا ، فإن الذكاء الاصطناعى للتعرف على الصور على Facebook لديه عمق حوالي 100 طبقة ، وهذا هو السبب في أنه يشبه الدماغ البيولوجي - في عدد وتعقيد العلاقة بين الخلايا العصبية التي تشكل شبكة كبيرة واحدة.
لعبة الذكاء الاصطناعى
بالنسبة لتطبيق التعلم الآلي في صناعة الألعاب ، فهناك عدد من القيود ، بسبب أنه ليس من الممكن دائمًا استخدام هذا النوع من الهندسة المعمارية. وتشمل هذه متطلبات النظام ، لا سيما فيما يتعلق بوحدة المعالجة المركزية ، والتي تحدد قدرة الكمبيوتر على معالجة هياكل اللعبة المعقدة ومدى ملاءمتها لرواية اللعبة ولعبها.
وبالتالي ، اتضح أنه في العديد من الألعاب لتطبيق نظام الذكاء الاصطناعي المعقد ، لا يمكن تنظيم الأجهزة الضرورية علاوة على مجموعة الخوادم الموجودة ، على سبيل المثال ، لشبكات التعرف على الصور على Facebook. في بعض الأحيان ، يجب أن تعمل العديد من الأجهزة الذكية في نفس الوقت - ليس فقط على أجهزة الكمبيوتر ، ولكن أيضًا على الأجهزة المحمولة ، وعلى منصات أخرى أقل إنتاجية. كل هذا يفرض قيودًا على حجم وتعقيد بنية التعلم الآلي ، لأنه يجب أيضًا إجراء جميع العمليات الحسابية مع مدة إطار تصل إلى 1 أو 2 مللي ثانية. بالطبع ، يمكنك استخدام العديد من تقنيات التحسين وموازنة التحميل بين الإطارات ، ولكن لا يزال لا يمكنك التخلص من هذه القيود على الإطلاق.
يمكن أن تتسبب المشاكل الخطيرة التي تحدث في الذكاء الاصطناعي في تعقيد اللعبة. في الواقع ، في ألعاب مثل StarCraft II ، تكون آليات اللعبة أكثر تعقيدًا من ألعاب Atari مرات عديدة. لذلك ، يجب ألا تتوقع أنه بالنسبة لتكرار إطار معين ومع متطلبات النظام المعروفة ، فإن التعلم الآلي سوف يتعامل بالتأكيد مع دراسة الحالة الكاملة للعبة وسيكون قادرًا على التفاعل معها. نظرًا لأن اللاعب غالباً ما يسترشد بالحدس في المراحل المبكرة من اللعبة ، لذلك يجب أن تتعلم منظمة العفو الدولية كيفية معالجة حالة اللعبة من أجل تبسيط مرورها. على سبيل المثال ، في واحدة من أحدث
واجهات برمجة التطبيقات لـ Starcraft II على الخرائط ، تم عرض المعلومات التي اعتبرها المطورون مهمة فقط: في حالة واحدة ، استخدم الذكاء الاصطناعي وجهة نظر مخفضة لكامل أراضي الخريطة ، في الحالة الثانية - مثل اللاعب ، كان بإمكانه تحريك الكاميرا ، ثم اقتصر تصوره على المعلومات على الشاشة.
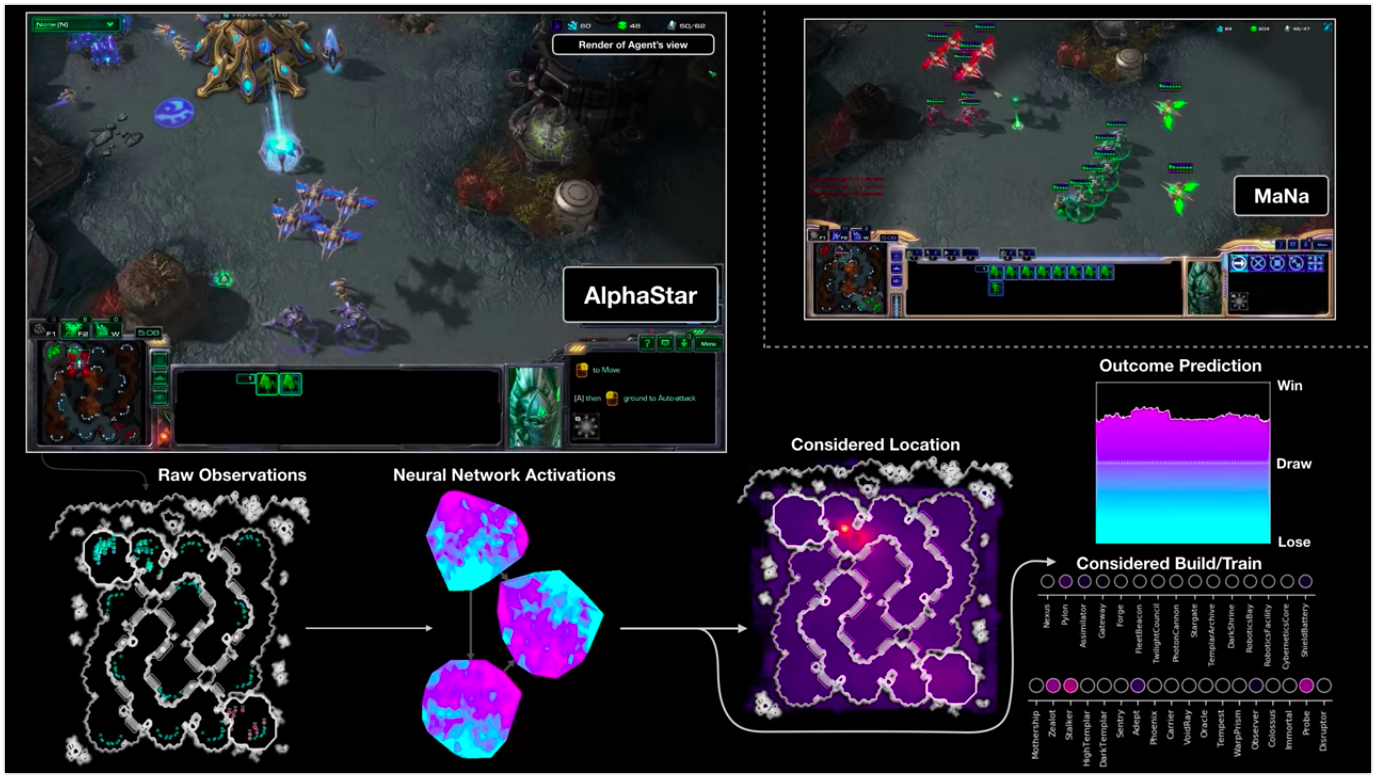 تصور لعبة AlphaStar AI ضد لاعب في StarSraft II: تعرض لقطة الشاشة ملاحظات المدخلات الأولية ونشاط الشبكة العصبية وبعض تصرفاتها وإحداثياتها المحتملة ، وكذلك النتيجة المتوقعة للمباراة
تصور لعبة AlphaStar AI ضد لاعب في StarSraft II: تعرض لقطة الشاشة ملاحظات المدخلات الأولية ونشاط الشبكة العصبية وبعض تصرفاتها وإحداثياتها المحتملة ، وكذلك النتيجة المتوقعة للمباراةهذا هو الجانب المتعلق بشكل خاص في حالة الألعاب. في كثير من الأحيان ، لا يتم تطبيق الأساليب المقبولة عمومًا لحل مشكلات تعلم الآلة على ألعاب الذكاء الاصطناعي. على سبيل المثال ، عادة ما يكون غير ملزم بالفوز أو بذل كل ما في وسعه للفوز ، كما كان الحال مع ألعاب أتاري. في كثير من الأحيان دور منظمة العفو الدولية هو جعل لعبة تمرير أكثر إثارة. قد يكون من الضروري له أن يلعب دوراً وأن يتصرف كما توحي شخصية الشخصية المسؤولة عنه. وبالتالي ، فإن ألعاب الذكاء الاصطناعي المرتبطة بالألعاب مرتبطة بدرجة أكبر بتصميم اللعبة ورواية القصص ويجب أن تكون لديها الأدوات اللازمة للتحكم في سلوكياتها لتحقيق أهدافها. تعلم الآلة الخالص لا يناسب دائمًا هذا - مما يعني أنك بحاجة إلى البحث عن شيء آخر.
قضايا عملية تعلم الآلة
ظهرت هذه المشكلات في تطوير الذكاء الاصطناعي القائم على التعلم الآلي لـ
Unleash ، حيث ينبغي أن تتصرف الذكاء الاصطناعي مثل اللاعبين العاديين - أي أن يكونوا مرنين وواسعي الحيلة.
مثل Starcraft II ، يعد Unleashed أكثر تعقيدًا بكثير من لعبة الشطرنج ويذهب إلى Atari. طريقة اللعب فيها سهلة وبسيطة للتعلم ، ولكن لكي تنجح حقًا ، فأنت بحاجة إلى مهارات إدارة ميتا معينة. يتعين على اللاعب بناء متاهات ، ووضع الوحوش على الأعداء والتفكير من خلال استراتيجيته في الاقتصاد ، والهجوم والدفاع عن الهياكل في جميع أنحاء اللعبة. للقيام بذلك ، يحتاج إلى خداع وحساب تحركات الآخرين للأمام ، بالإضافة إلى إدارة ميتا نفسية - هي التي تجعل من لعبة البوكر شيئًا أكثر من مجرد لعبة إحصائية.
 لقطة من العنان
لقطة من العنانبحثًا عن البنية الأكثر ملاءمة لهذه الأغراض ، تم تقديم تقنيات مثل
التطور العصبي والتعلم العميق لأول مرة في اللعبة في شكل لم يتغير تقريبًا ، وتأكدنا من أنها ستظهر بنفسها كعدو لمنظمة العفو الدولية.
كان مروعا.
سرعان ما أصبح من الواضح أن العنان يحتاج إلى حل العديد من المشاكل العالمية التي كان من الصعب التكيف مع التعلم الآلي.
واحد منهم هو بناء متاهة فعالة. كما هو الحال في العديد من الألعاب التي تهدف إلى حماية البرج ، يحتاج اللاعبون هنا إلى بناء متاهة من حوله ، من خلالها ستخترق الوحوش. هم ، بدورهم ، يجب القضاء عليهم بمساعدة الأسلحة الموضوعة في متاهة. من الناحية المثالية ، يجب أن تكون المتاهة أطول فترة ممكنة حتى تتمكن من إلحاق ضرر كاف بالوحوش ومنعها من الوصول إلى البرج. بالنسبة لبعض أنواع الأسلحة ، تكون الوحوش أكثر عرضة للضرر من غيرها ، لذا من أجل زيادة الفعالية ، يجب وضعها في المتاهة قبل الجميع. خصوصية إطلاق العنان هو أنه لا توجد متاهة مثالية: هناك العديد من أنواع الوحوش في اللعبة بحيث يمكن للمرء أن يمر واحد أو آخر بحرية من خلال أي جزء من المتاهة. يجب تكييف أي متاهة للوحوش الجديدة التي أطلقها لاعبون آخرون. وبالتالي ، كان من الضروري ليس فقط لتعليم الذكاء الاصطناعي بناء المتاهات - كان من الضروري أن يعلمه كيفية إنشاء متاهات فعالة لمختلف السيناريوهات ، والتي لا يمكن مواجهتها إلا في كل من الإصدارات المبكرة والمتأخرة من اللعبة.
أيضا ، كان على منظمة العفو الدولية أن تتعلم كيف تعرف الوحوش التي ستظهر في المتاهة. هذا هو نوع من مشكلة معكوس فيما يتعلق ببناء المتاهة. كما هو الحال في العديد من الألعاب الأخرى ، في إطلاق العنان ، لا يكفي فقط بناء جيش وإرساله إلى معسكر العدو: أنت بحاجة أيضًا للتجسس على دفاع العدو وهيكلة جيشك بطريقة تصل إلى نقاط الألم لدى العدو بأكبر قدر ممكن من الفعالية. يجب أن يتفاعل جيش الوحوش مع بعضهم البعض بطريقة لاجتياز المتاهة بنجاح كبير. في بعض الأحيان يكون من الضروري أيضًا إطلاق الوحوش بترتيب معين اعتمادًا على وظائفها ودورها. هذا يزيد أيضًا من عدد المجموعات المختلفة.
أخيرًا ، نظرًا لأن على اللاعب إنشاء متاهات وتجميع جيش من الوحوش ، يحتاج الذكاء الاصطناعي أيضًا إلى تعلم كيفية إيجاد التوازن في الهجوم والدفاع. تجدر الإشارة أيضًا إلى أنه كلما زاد بناء اللاعب لجيش الوحوش وكلما بنى المتاهة ، زادت الموارد التي يحتاجها لهذا الغرض. لذلك ، تعتبر استراتيجية الهجوم الصحيحة مهمة للغاية للاقتصاد أثناء اللعبة وللانتصار فيها. ولضمان القدرة التنافسية ، يجب أن تكون منظمة العفو الدولية قادرة على التخلص من الموارد بطريقة تؤدي إلى إنشاء جيش قوي من الوحوش ، دون تعريض قوة المتاهة للخطر. يمكن أن يكون الاستثمار في الوحوش إلى الحد الأقصى فعالًا من حيث التكلفة ، لكن هذا يزيد من خطر قيام الوحوش المعادية بأخذ المتاهة. إذا راهنت على تعزيز حماية المتاهة ، فقد يؤدي ذلك إلى تقويض اقتصادك. لن يؤدي أي من هذه السيناريوهات إلى النصر. وبالتالي ، فإن مشكلة التحسين في Unleashed أكبر منها في حالة لعبة الشطرنج أو Starcraft ، وتتضمن الحاجة إلى التضحية بشيء وحساب الربح عدة خطوات إلى الأمام.
كما يتم تدريب الذكاء الاصطناعي ، يطفو على السطح العديد من المشاكل التي لم يتم حصرها. لذلك ، في البداية ، وصل الذكاء الاصطناعى في كثير من الأحيان إلى مستوى معين من التطور ، حيث بدأ في فهم بعض جوانب اللعبة - على سبيل المثال ، ما هي الأسلحة في المتاهة التي تكون فعالة ضد أنواع معينة من الوحوش أو التي تنقل فيها الوحوش أقسامًا معينة من المتاهة بشكل أفضل. لكن التعلم كان بطيئاً وأدى إلى تطوير استراتيجيات موحدة.
الحاجة إلى النهج الموازية
في حين أن تعلم الذكاء الاصطناعى القائم على التعلم الآلي قد تطور ببطء وليس بشكل خاص ، إلا أن المراحل الأخرى من الاختبار والتطوير تطلبت الذكاء الاصطناعى الأفضل وأفضل المنافسات القوية. لتنفيذها ، تم استخدام بنية الأداة المساعدة ، والتي يمكنك من خلالها إنشاء AIs خاصة لاختبار ومراقبة جودة اللعبة ، والاختبارات داخل اللعبة وموازنة الأسلحة والوحوش ، وإنشاء متاهات وحوش محددة. ومع ذلك ، أثناء تطوير برنامج Unleash ، قام المبدعون أنفسهم بتطوير مهاراتهم في اجتيازها ، ثم قرروا استخدام المعرفة المكتسبة لإنشاء أداة AI Utility أكثر تعقيدًا. لذلك أصبح من الواضح أن العديد من المشكلات التي تنشأ في أنظمة التعلم الاصطناعي القائمة على التعلم الآلي يمكن حلها بسهولة بمساعدة أنظمة الأداة المساعدة التي تستخدم معارفها ، والعكس صحيح.
على سبيل المثال ، من الأفضل بناء متاهات أكثر فاعلية باستخدام الأداة المساعدة AI ، بناءً على قواعد المعرفة التي تم تجميعها من الاختبارات الداخلية. يمكنك بسهولة وصف الخوارزمية وبرمجتها لبناء المتاهة وموقع الأسلحة فيها بطريقة أسهل للدفاع عن البرج من الوحوش المحددة إلى لاعب حي. لكن إنشاء جيش من الوحوش على أساس معرفة قاعدة العدو كان مهمة صعبة لمثل هذه الذكريات ، لأن عدد الظروف والتركيبات المختلفة التي يجب أخذها في الاعتبار كان مذهلاً. مع هذا النوع من هندسة الذكاء الاصطناعى ، فإن إيجاد مجموعات مناسبة من الوحوش سوف يستغرق وقتًا طويلاً بلا حدود. بعد ذلك ، في ضوء القيود المعطاة ، سيكون التعلم العميق حلاً مثاليًا لهذه المهمة.
الهجين خلق الذكاء الاصطناعى
لذلك ، تقرر الجمع بين الطريقتين ، وبالتالي إنشاء نظام هجين من الذكاء الاصطناعي يعتمد على التعلم الآلي والمنفعة. كانت الفكرة أنه عندما كان من الضروري معالجة عدد كبير من المجموعات وحالات اللعبة ، أو حيث كان مطلوبًا تدريبها على شيء ما ، تم استخدام التعلم الآلي. بالنسبة للمهام الأخرى ، حيث يكون من الأفضل الاعتماد على الخبرة الشخصية للمطورين ، تم استخدام أنظمة الأدوات المساعدة. تكمن ميزة هذا النهج أيضًا في أنه ، إذا لزم الأمر ، من الممكن التحكم بشكل أفضل في سلوك الذكاء الاصطناعي من أجل ضمان تمسكه بشكل أكثر دقة بهدف معين. على سبيل المثال ، يمكنك استخدام الأداة المساعدة AI لضمان التوازن بين الهجوم والدفاع وبالتالي إنشاء مستويات مختلفة من العدوان ، أو يمكنك إنشاء تكوينات متاهة مختلفة لمختلف أدوات الذكاء لإنشاء أنماط ألعاب فردية لها. يمكنك أيضًا تعيين أنظمة قيمة معينة للشبكات العصبية لتكوين تفضيلات مختلفة عند تجنيد الوحوش الجوية أو الأرضية ، وبالتالي إضافة شخصية إلى أجهزة الذكاء الفردية. هناك العديد من الخيارات الأخرى لتنفيذ قرارات التصميم ، وكلها تؤكد على نقاط القوة في نوع معين من بنية الذكاء الاصطناعي.
أجاب النهج الهجين أيضًا على سؤال آخر واجهه فريق التطوير في عملية تطوير الذكاء الاصطناعي لـ Unleash: هل يستحق تطبيق شبكة عصبية عميقة عالمية واحدة تستند إلى تعلم الآلة أن تأخذ في الاعتبار جميع بيانات المدخلات والمخرجات ، أم أنه من الأفضل تصميم AIs بهيكل هرمي؟
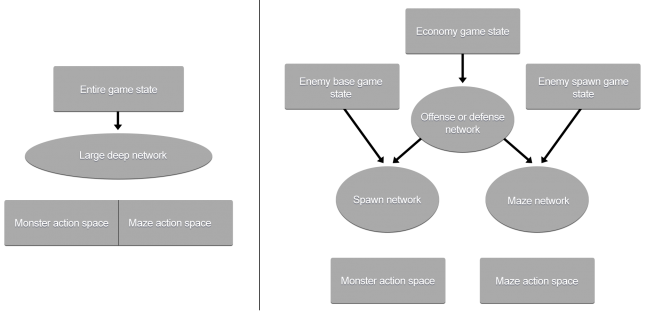 معماريتان مستخدمان في Unleash: على اليسار عبارة عن شبكة عصبية عميقة كبيرة ذات هيكلها الموحد ، على اليمين نظام هرمي حيث لكل شبكة مهمة خاصة بها
معماريتان مستخدمان في Unleash: على اليسار عبارة عن شبكة عصبية عميقة كبيرة ذات هيكلها الموحد ، على اليمين نظام هرمي حيث لكل شبكة مهمة خاصة بهاومع ذلك ، أود إنشاء نهج مشترك لنظام الذكاء الاصطناعي ، في الهندسة المعمارية التي لا يضع المطورون تجربتهم الخاصة. ومع ذلك ، كلما تم إدخال مداخل اللعبة ، زادت شبكة العصبية. في الوقت نفسه ، كان من المستحيل فصل تدريب منظمة العفو الدولية وتعليمهم شيئًا واحدًا فقط: إما الدفاع أو الهجوم. وكانت هناك مخاوف من أن اتباع نهج أكثر عمومية من شأنه أن يؤدي إلى زيادة كبيرة في عدد العمليات الحسابية.
من هذا جاءت فكرة إنشاء بنية هرمية يتم فيها تنفيذ كل مهمة محددة بواسطة شبكة عصبية متخصصة. وفقًا لهذه الفكرة ، يجب أن يتخذ الذكاء الاصطناعي الأول قرارًا بشأن توزيع الموارد للهجوم (زيادة جيش الوحوش) والدفاع (بناء المتاهة). بمجرد أن يقوم بذلك ، ينتقل إلى الطبقة التالية وفقًا لاختياره ويحصل على الجزء الضروري من حالة اللعبة ، وبعد ذلك يتخذ قرارات مفصلة حول الوحوش التي يختارها وأي أسلحة ليتم تثبيتها في المتاهة.
الخلاصة والخطوات التالية
في نهج الأدوات المساعدة المختلطة ، تشبه الذكاء الاصطناعى مع الشبكات التي تدعم التعلم الآلي بنية هندسية. وهذا بدوره يشبه الدماغ البيولوجي الذي يكون فيه كل مركز عصبي مختلف مسؤولاً عن مهمته.
من الصعب الآن هزيمة العدو AI في Unleash: فهم قادرون على التكيف مع أي موقف في اللعبة - ولكن في الوقت نفسه ، يمكن للمطورين تغيير إعداداتهم وفقًا لتقديرهم. وفقًا لمؤلف المقال ، مع مرور الوقت ، يجب أن يصبح النهج المختلط أكثر انتشارًا وأن يظهر في العديد من الألعاب الأخرى. ربما في يوم من الأيام سيكون من الممكن إدخال الذكاء الاصطناعي القائم على التعلم الآلي في أنقى صوره في طريقة اللعب. لكن من الواضح أن هذا سيستغرق بعض الوقت. في هذه الأثناء ، يتمثل الهدف في إيجاد مثل هذه البنية التي تتكيف مع التحديات التي تواجهها وتجد الطرق المثلى لحلها.