تسجيل هو جزء مهم من أي تطبيق. يمر أي نظام تسجيل عبر ثلاث خطوات تطورية رئيسية. الأول هو الإخراج إلى وحدة التحكم ، والثاني هو تسجيل الدخول إلى ملف وظهور إطار عمل للتسجيل المهيكل ، والثالث يتم توزيع تسجيل أو تجميع سجلات الخدمات المختلفة في مركز واحد.
إذا كان التسجيل منظمًا بشكل جيد ، فإنه يسمح لك بفهم ماذا ومتى وكيف يحدث خطأ ، ونقل المعلومات اللازمة إلى الأشخاص الذين يتعين عليهم تصحيح هذه الأخطاء. بالنسبة لنظام يتم فيه إرسال 100 ألف رسالة كل ثانية في 10 مراكز بيانات في 190 دولة ، وينشر 350 مهندسًا شيئًا يوميًا ، فإن نظام التسجيل مهم للغاية.
 إيفان ليتينكو
إيفان ليتينكو هو قائد فريق ومطور في Infobip. لحل مشكلة المعالجة المركزية وتتبع السجل في بنية الخدمات المصغرة تحت مثل هذه الأحمال الهائلة ، جربت الشركة مجموعات متنوعة من المكدس ELK و Graylog و Neo4j و MongoDB. نتيجة لذلك ، بعد الكثير من النشاط ، قاموا بكتابة خدمة السجل الخاصة بهم على Elasticsearch ، وتم أخذ PostgreSQL كقاعدة بيانات للحصول على معلومات إضافية.
تحت القطة بالتفصيل ، مع أمثلة ورسوم بيانية: بنية النظام وتطوره ، وأشعل النار ، وقطع الأشجار والتعقب والمقاييس والمراقبة ، وممارسة العمل مع مجموعات Elasticsearch وإدارتها بموارد محدودة.
لتقديمك إلى السياق ، سوف أخبركم قليلاً عن الشركة. نحن نساعد العملاء من المنظمات على توصيل الرسائل إلى عملائهم: رسائل من خدمة سيارات الأجرة ، أو رسائل نصية من أحد البنوك حول الإلغاء ، أو كلمة مرور لمرة واحدة عند الدخول إلى VC.
يتم إرسال 350 مليون رسالة إلينا يوميًا للعملاء في 190 دولة. كل واحد منهم نقبل ، نعالج ، نرسل ، نتكيف ، نرسل ، نرسل للمشغلين ، وفي الاتجاه المعاكس ، نعالج تقارير التسليم وننشئ تحليلات.
لكي يعمل كل هذا في مثل هذه المجلدات ، لدينا:
- 36 مركز بيانات حول العالم ؛
- 5000+ الأجهزة الافتراضية
- 350+ المهندسين.
- 730+ microservices مختلفة.
هذا نظام معقد ، ولا يستطيع المعلم الوحيد فهم النطاق الكامل بمفرده. أحد الأهداف الرئيسية لشركتنا هو السرعة العالية في تقديم الميزات والإصدارات الجديدة للأعمال. في هذه الحالة ، يجب أن يعمل كل شيء ولا يسقط. نحن نعمل على هذا: 40.000 عملية نشر في عام 2017 ، و 80،000 عملية نشر في 2018 ، و 300 عملية نشر يوميًا.
لدينا 350 مهندسا - اتضح أن
كل مهندس ينشر شيئًا يوميًا . منذ بضع سنوات فقط ، كان لدى شخص واحد فقط في الشركة مثل هذه الإنتاجية - Kreshimir ، المهندس الرئيسي لدينا. لكننا تأكدنا من أن كل مهندس يشعر بالثقة مثل Kresimir عندما يضغط على زر Deploy أو يقوم بتشغيل برنامج نصي.
ما هو المطلوب لهذا؟ بادئ ذي
بدء ،
الثقة في أننا نفهم ما يحدث في النظام وفي ما هو عليه. يتم إعطاء الثقة من خلال القدرة على طرح سؤال على النظام ومعرفة سبب المشكلة أثناء الحادث وخلال تطوير الكود.
لتحقيق هذه الثقة ، نستثمر في
الملاحظة . تقليديا ، يجمع هذا المصطلح بين ثلاثة مكونات:
- تسجيل.
- المقاييس.
- البحث عن المفقودين.
سنتحدث عن هذا. بادئ ذي بدء ، دعنا ننظر إلى حلنا للتسجيل ، لكننا سنتطرق أيضًا إلى المقاييس والآثار.
تطور
يمر أي تطبيق أو نظام تقريبًا تقريبًا ، بما في ذلك تطبيقنا ، بعدة مراحل من التطور.
الخطوة الأولى هي
الإخراج إلى وحدة التحكم .
ثانياً - نبدأ
في كتابة السجلات إلى ملف ما ، ويظهر
إطار عمل للإخراج المنظم إلى ملف. نستخدم عادة Logback لأننا نعيش في JVM. في هذه المرحلة ، يظهر التسجيل المهيكل إلى ملف ، مع إدراك أن السجلات المختلفة يجب أن تحتوي على مستويات وتحذيرات وأخطاء مختلفة.
بمجرد
وجود عدة مثيلات لخدمتنا أو خدمات مختلفة ، تظهر مهمة
الوصول المركزي إلى سجلات المطورين والدعم. ننتقل إلى التسجيل الموزع - ندمج الخدمات المختلفة في خدمة تسجيل واحدة.
تسجيل الموزعة
الخيار الأكثر شهرة هو مكدس ELK: Elasticsearch و Logstash و Kibana ، لكننا اخترنا
Graylog . لديه واجهة باردة موجهة نحو التسجيل. تظهر الإنذارات من العلبة بالفعل في الإصدار المجاني ، وهو ليس في Kibana ، على سبيل المثال. بالنسبة لنا ، هذا اختيار ممتاز من حيث السجلات ، وتحت غطاء محرك السيارة هو نفس Elasticsearch.
 في Graylog ، يمكنك إنشاء تنبيهات ومخططات مثل Kibana وحتى تسجيل المقاييس.
في Graylog ، يمكنك إنشاء تنبيهات ومخططات مثل Kibana وحتى تسجيل المقاييس.المشاكل
كانت شركتنا تنمو ، وفي مرحلة ما أصبح من الواضح أن هناك خطأ ما في Graylog.
الحمل المفرط . كانت هناك مشاكل في الأداء. بدأ العديد من المطورين في استخدام الميزات الرائعة لـ Graylog: لقد قاموا بإنشاء مقاييس ولوحات معلومات تؤدي تجميع البيانات. ليس الخيار الأفضل لإنشاء تحليلات معقدة على مجموعة Elasticsearch ، التي تقع تحت حمولة التسجيل الثقيلة.
الاصطدامات. هناك العديد من الفرق ، لا يوجد مخطط واحد. تقليديًا ، عندما قام أحد المعرّفات أولاً بضرب Graylog كطول ، حدث التعيين تلقائيًا. إذا قرر فريق آخر أنه يجب كتابة UUID كسلسلة - فسيؤدي ذلك إلى كسر النظام.
القرار الأول
سجلات التطبيق المنفصلة وسجلات الاتصالات . سجلات مختلفة لها سيناريوهات مختلفة وطرق التطبيق. هناك ، على سبيل المثال ، سجلات التطبيق التي لها فرق مختلفة لها متطلبات مختلفة للمعلمات المختلفة: من خلال وقت التخزين في النظام ، حسب سرعة البحث.
لذلك ، كان أول شيء فعلناه هو فصل سجلات التطبيق وسجلات الاتصالات. النوع الثاني هو سجلات مهمة تخزن معلومات حول تفاعل نظامنا الأساسي مع العالم الخارجي وعن التفاعل داخل النظام الأساسي. سنتحدث أكثر عن هذا.
استبدال جزء كبير من السجلات بالمقاييس . في شركتنا ، الخيار القياسي هو بروميثيوس وغرافانا. تستخدم بعض الفرق حلولًا أخرى. ولكن من المهم أن تخلصنا من عدد كبير من لوحات المعلومات مع مجموعات داخل Graylog ، وقمنا بنقل كل شيء إلى Prometheus و Grafana. هذا خفف إلى حد كبير الحمل على الخوادم.
دعونا نلقي نظرة على السيناريوهات لتطبيق السجلات والمقاييس والآثار.
السجلات
البعد عالية ، التصحيح والبحث . ما هي سجلات جيدة؟
السجلات هي الأحداث التي نسجلها.
يمكن أن يكون لها بعد كبير: يمكنك تسجيل معرف الطلب ومعرف المستخدم وسمات الطلب والبيانات الأخرى التي لا يقتصر البعد عليها. كما أنها جيدة للتصحيح والبحث ، لطرح أسئلة النظام حول ما حدث والبحث عن الأسباب والآثار.
المقاييس
انخفاض البعد والتجميع والرصد والتنبيهات . تحت غطاء محرك السيارة من جميع أنظمة جمع متري هي قواعد البيانات سلسلة زمنية. تقوم قواعد البيانات هذه بعمل ممتاز للتجميع ، لذلك تعد المقاييس مناسبة للتنبيهات التجميعية والمراقبة والبناء.
المقاييس حساسة للغاية لبعد البيانات.
بالنسبة إلى المقاييس ، يجب ألا يتجاوز بُعد البيانات ألف. إذا أضفنا بعض معرّفات الطلب ، والتي لا يقتصر فيها حجم القيم ، فسوف نواجه مشكلات خطيرة بسرعة. لقد صعدنا بالفعل على هذا أشعل النار.
الارتباط والتتبع
يجب أن تكون مرتبطة سجلات.
سجلات منظم ليست كافية بالنسبة لنا للبحث بسهولة عن طريق البيانات. يجب أن يكون هناك حقول ذات قيم معينة: معرف الطلب ، معرف المستخدم ، بيانات أخرى من الخدمات التي جاءت منها السجلات.
الحل التقليدي هو تعيين معرف فريد للمعاملة (log) عند مدخل النظام. ثم يتم إعادة توجيه هذا المعرف (السياق) من خلال النظام بأكمله من خلال سلسلة من المكالمات داخل خدمة أو بين الخدمات.
 الارتباط والتتبع.
الارتباط والتتبع.هناك شروط راسخة. يتم تقسيم التتبع إلى مسافات ويوضح مكدس الاستدعاء لخدمة ما بالنسبة إلى خدمة أخرى ، طريقة مرتبطة بأخرى تتعلق بالجدول الزمني. يمكنك تتبع مسار الرسالة بوضوح ، كل التوقيتات.
أولاً استخدمنا Zipkin. بالفعل في عام 2015 ، حصلنا على دليل إثبات (مشروع رائد) لهذه الحلول.
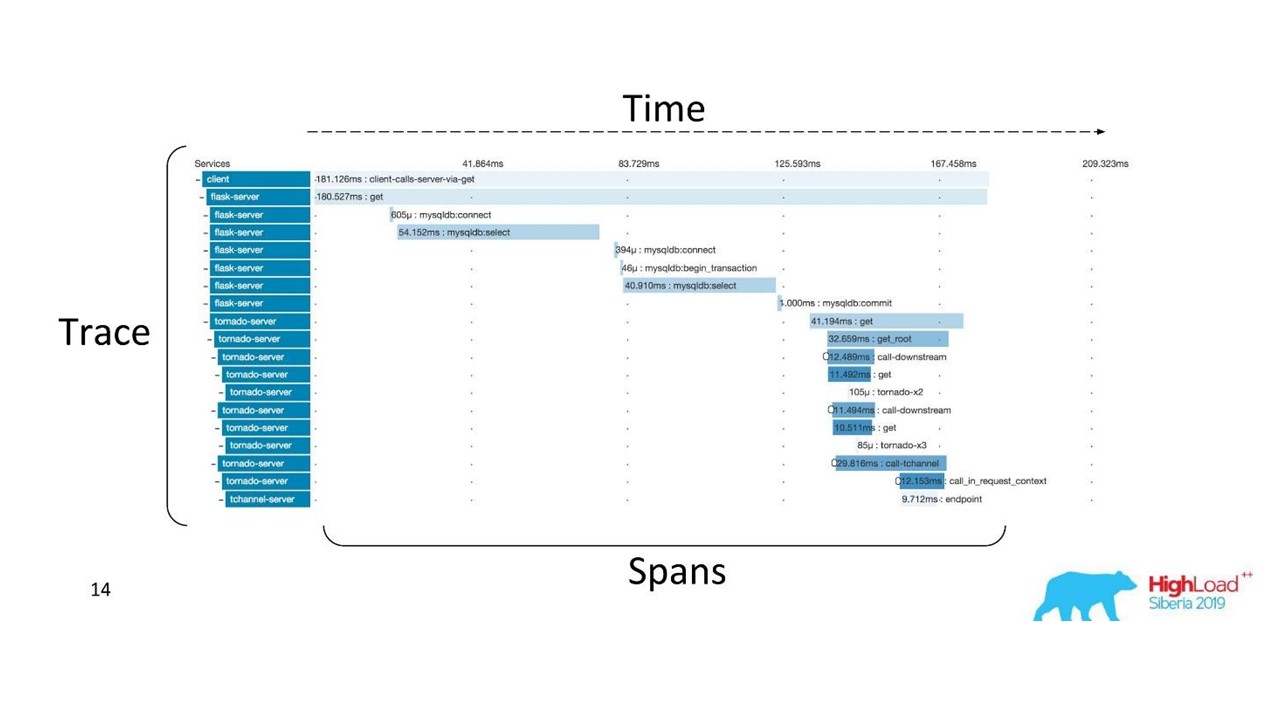 تتبع الموزعة
تتبع الموزعةللحصول على مثل هذه الصورة ،
يجب أن تكون الشفرة محددة . إذا كنت تعمل بالفعل مع قاعدة شفرة موجودة ، فأنت بحاجة إلى المرور بها - فهي تتطلب تغييرات.
للحصول على الصورة الكاملة والاستفادة من التتبعات ، يلزمك
استخدام جميع الخدمات الموجودة في السلسلة ، وليس مجرد خدمة واحدة تعمل عليها حاليًا.
هذه أداة قوية ، ولكنها تتطلب تكاليف إدارية وجهازية كبيرة ، لذلك انتقلنا من Zipkin إلى حل آخر ، يتم توفيره بواسطة "كخدمة".
تقارير التسليم
يجب أن تكون مرتبطة سجلات. يجب أيضًا ربط الآثار. نحتاج إلى معرف واحد - سياق مشترك يمكن إعادة توجيهه عبر سلسلة الاتصال. لكن هذا غير ممكن في كثير من الأحيان -
يحدث الارتباط داخل النظام نتيجة تشغيله . عندما نبدأ معاملة واحدة أو أكثر ، ما زلنا لا نعرف أنها جزء من مجموعة كبيرة واحدة.
النظر في المثال الأول.
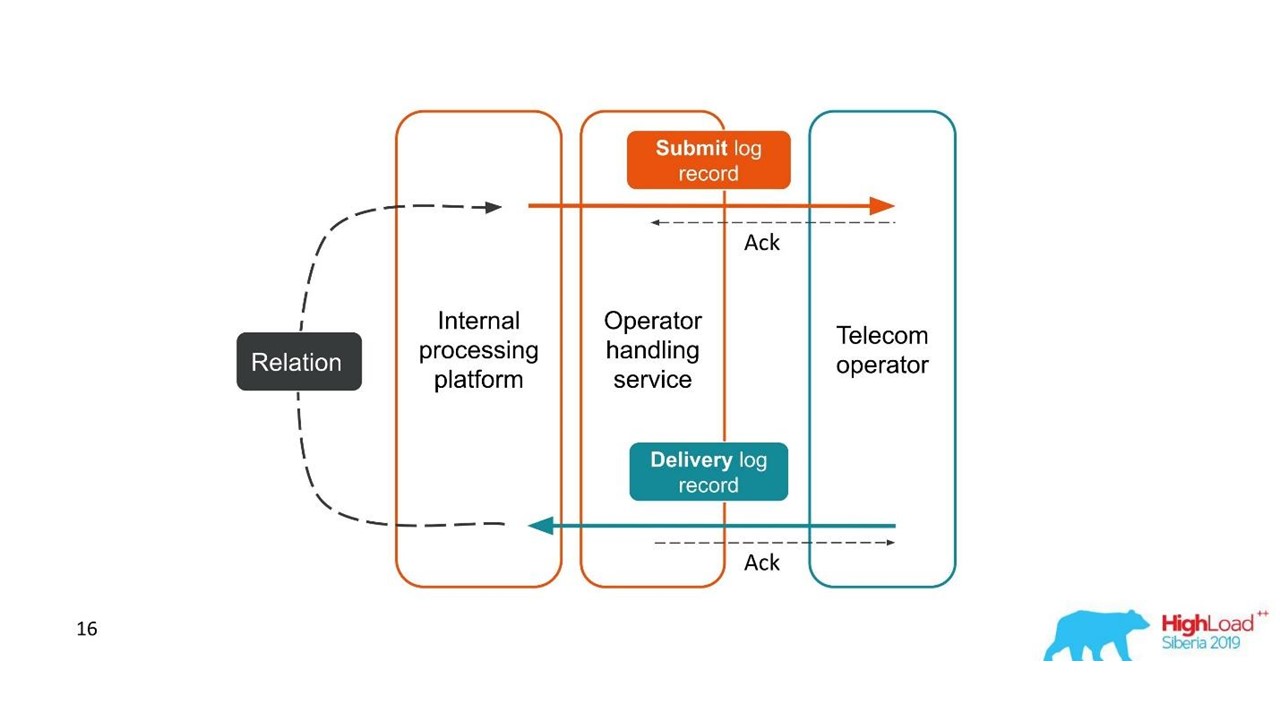 تقارير التسليم.
تقارير التسليم.- أرسل العميل طلبًا للحصول على رسالة ، وقام نظامنا الداخلي بمعالجتها.
- أرسلت الخدمة ، التي تتفاعل مع المشغل ، هذه الرسالة إلى المشغل - ظهر إدخال في نظام السجل.
- في وقت لاحق ، يرسل المشغل لنا تقرير التسليم.
- لا تعرف خدمة المعالجة الرسالة التي يتعلق بها تقرير التسليم. يتم إنشاء هذه العلاقة لاحقًا في نظامنا الأساسي.
اثنين من المعاملات ذات الصلة هي أجزاء من معاملة واحدة كاملة. هذه المعلومات مهمة للغاية لمهندسي الدعم ومطوري التكامل. ولكن هذا مستحيل تمامًا على أساس تتبع واحد أو معرف واحد.
الحالة الثانية مماثلة - يرسل العميل رسالة في حزمة كبيرة ، ثم نقوم بتفكيكها ، ويعودون أيضًا على دفعات. قد يختلف عدد العبوات ، ولكن يتم دمجها جميعًا.
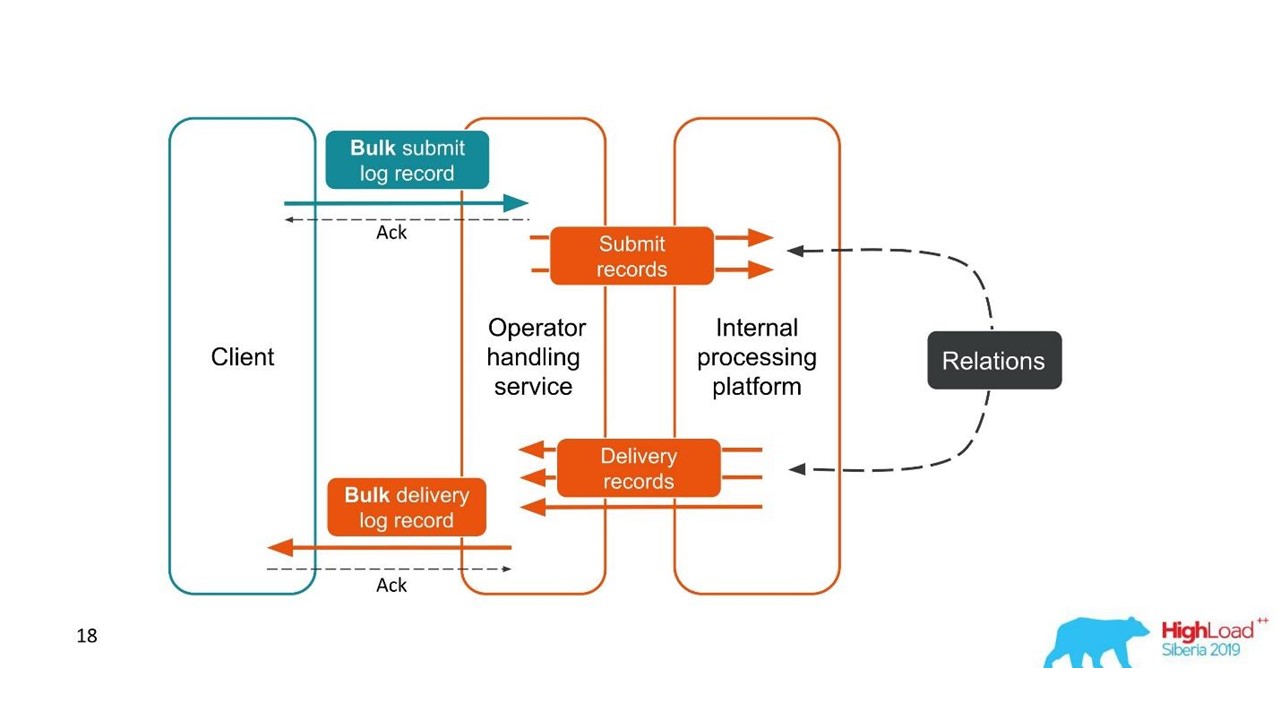
من وجهة نظر العميل ، أرسل رسالة وتلقى ردًا. ولكن حصلنا على العديد من المعاملات المستقلة التي تحتاج إلى الجمع. لقد تبين وجود علاقة رأس بأطراف ، مع تقرير التسليم - واحد إلى واحد. هذا هو في الأساس رسم بياني.
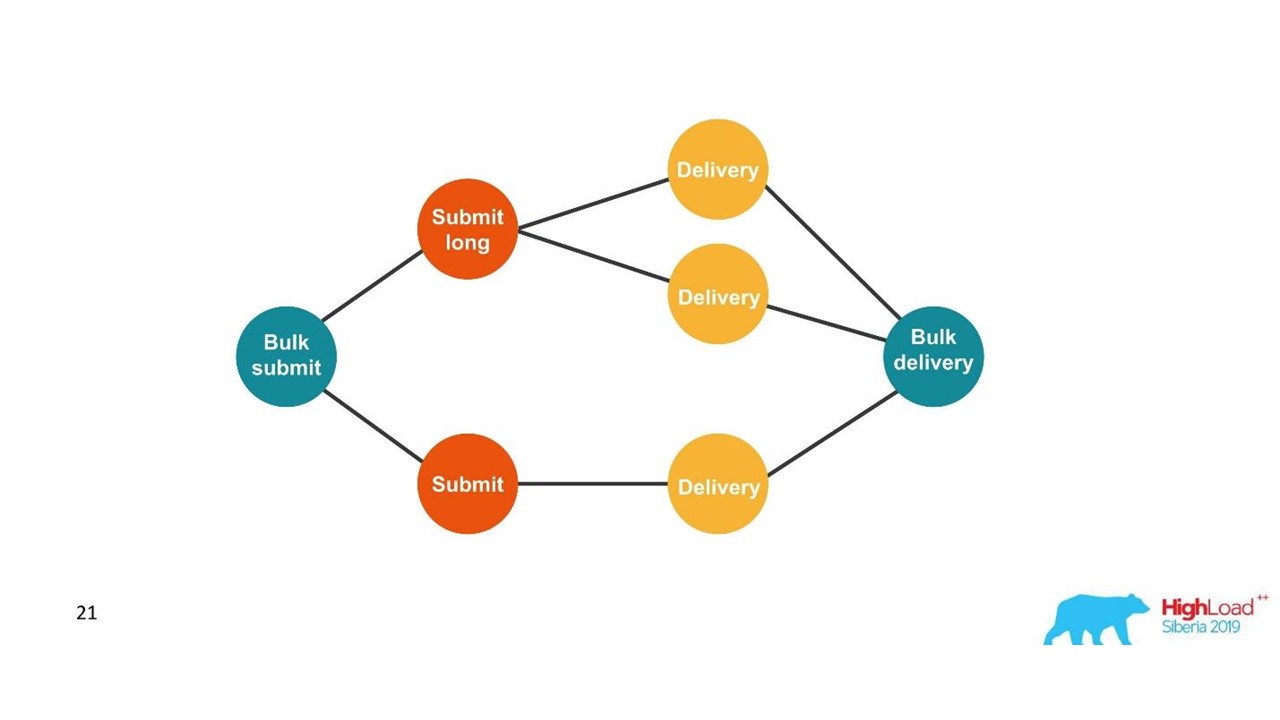 نحن نبني الرسم البياني.
نحن نبني الرسم البياني.بمجرد أن نرى رسمًا بيانيًا ، يكون الاختيار المناسب هو قواعد بيانات الرسم البياني ، على سبيل المثال ، Neo4j. كان الاختيار واضحًا لأن Neo4j يوفر قمصانًا رائعة وكتبًا مجانية في المؤتمرات.
Neo4j
قمنا بتطبيق Proof of Concept: مضيف مكون من 16 نواة يمكنه معالجة رسم بياني قدره 100 مليون عقدة و 150 مليون ارتباط. احتل الرسم البياني 15 غيغابايت فقط من القرص - ثم تناسبنا.
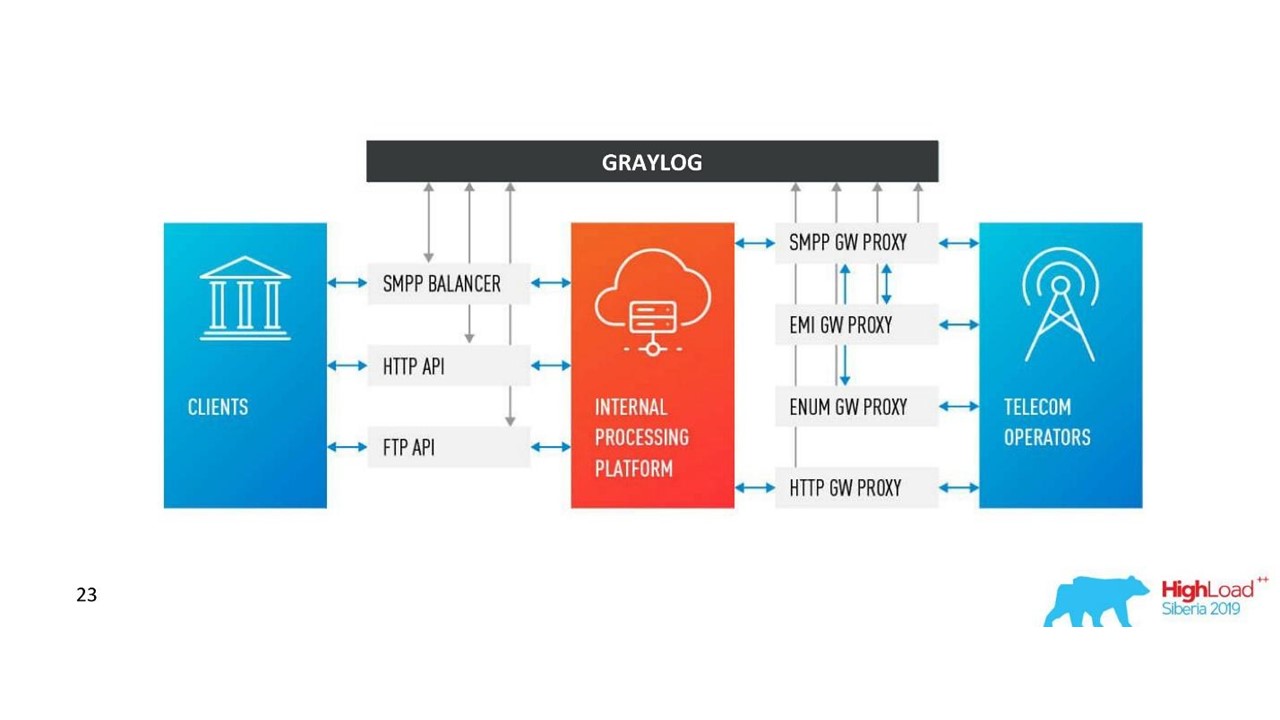 قرارنا. سجل العمارة.
قرارنا. سجل العمارة.بالإضافة إلى Neo4j ، لدينا الآن واجهة بسيطة لعرض السجلات ذات الصلة. معه ، يرى المهندسون الصورة كاملة.
ولكن بسرعة كبيرة ، أصبحنا بخيبة أمل في قاعدة البيانات هذه.
مشاكل مع Neo4j
تناوب البيانات . لدينا وحدات تخزين قوية ويجب تدوير البيانات. ولكن عندما يتم حذف عقدة من Neo4j ، لا يتم مسح البيانات الموجودة على القرص. اضطررت إلى بناء حل معقد وإعادة بناء الرسوم البيانية بالكامل.
الأداء . جميع قواعد بيانات الرسم البياني للقراءة فقط. عند التسجيل ، يكون الأداء أقل بشكل ملحوظ. حالتنا هي عكس ذلك تمامًا: نكتب كثيرًا ونادراً ما نقرأ - إنها وحدات طلبات في الثانية أو حتى في الدقيقة.
توافر عالية وتحليل الكتلة مقابل رسوم . على نطاقنا ، وهذا يترجم إلى تكاليف لائقة.
لذلك ، ذهبنا في الاتجاه الآخر.
حل مع بوستجرس
قررنا أنه نظرًا لأننا نادرًا ما نقرأ ، فيمكن بناء الرسم البياني على الطاير عند القراءة. لذلك نحن في قاعدة البيانات العلائقية PostgreSQL نقوم بتخزين قائمة المتاخمة لمعرفاتنا في شكل لوحة بسيطة مع عمودين وفهرس على حد سواء. عندما يصل الطلب ، فإننا نتجاوز الرسم البياني للاتصال باستخدام خوارزمية DFS مألوفة (اجتياز العمق) ، والحصول على جميع معرفات المرتبطة. لكن هذا ضروري.
تدوير البيانات هو أيضا من السهل حلها. نبدأ كل يوم بلوحة جديدة وبعد بضعة أيام عندما يحين الوقت ، نحذفها ونصدر البيانات. حل بسيط.
لدينا الآن 850 مليون اتصال في PostgreSQL ، يشغلونها 100 جيجابايت من القرص. نكتب هناك بسرعة 30 ألف في الثانية ، ولهذا في قاعدة البيانات لا يوجد سوى اثنين من VMs مع 2 وحدات المعالجة المركزية و 6 غيغابايت من ذاكرة الوصول العشوائي. كما هو مطلوب ، يمكن لـ PostgreSQL كتابة صفقات شراء بسرعة.
لا تزال هناك آلات صغيرة للخدمة نفسها ، والتي تدور وتتحكم.
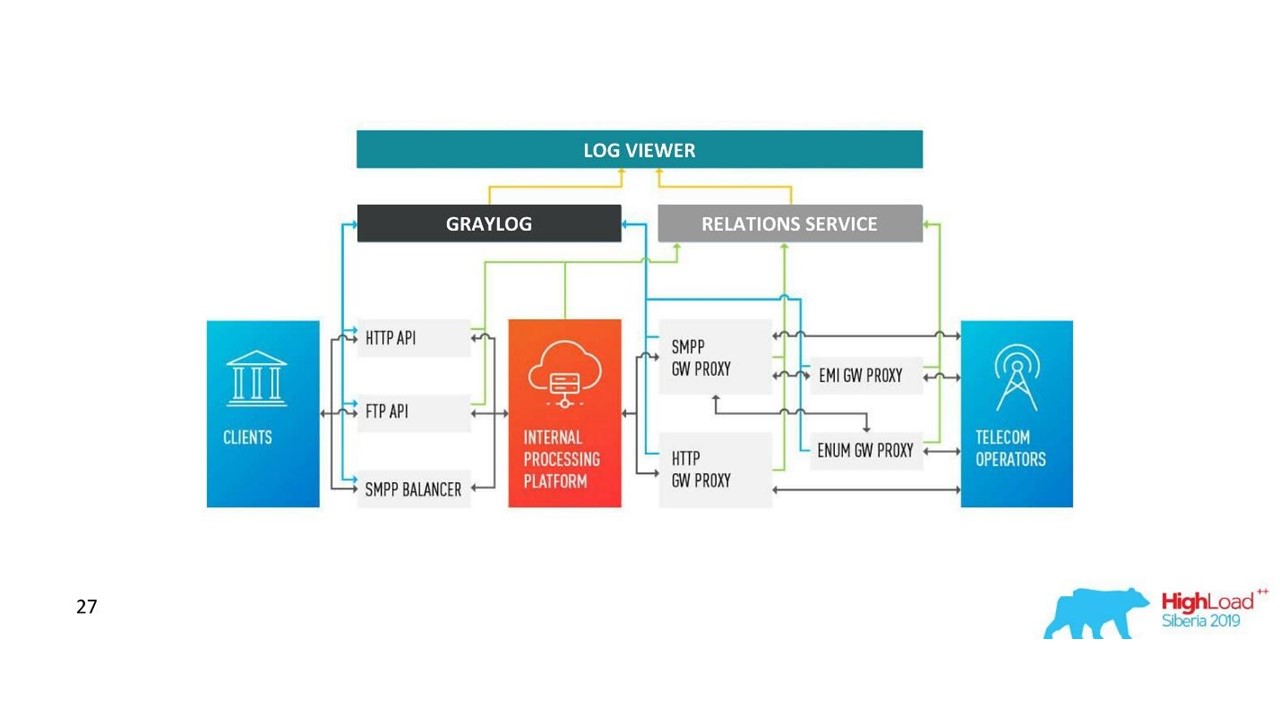 كيف تغيرت الهندسة المعمارية لدينا.
كيف تغيرت الهندسة المعمارية لدينا.التحديات مع Graylog
نمت الشركة ، ظهرت مراكز بيانات جديدة ، زاد الحمل بشكل ملحوظ ، حتى مع وجود حل مع سجلات الاتصالات. كنا نظن أن Graylog لم تعد مثالية.
مخطط موحد والمركزية . أرغب في الحصول على أداة إدارة نظام مجموعة واحدة في 10 مراكز بيانات. أيضا ، نشأ السؤال عن مخطط موحد لرسم الخرائط البيانات بحيث لم تكن هناك اصطدامات.
API. نحن نستخدم واجهة المستخدم الخاصة بنا لعرض الاتصالات بين السجلات ولم يكن تطبيق Graylog API القياسي مناسبًا دائمًا ، على سبيل المثال ، عندما تحتاج إلى عرض البيانات من مراكز بيانات مختلفة ، قم بتصنيفها ووضع علامة عليها بشكل صحيح. لذلك ، أردنا أن نكون قادرين على تغيير واجهة برمجة التطبيقات كما نشاء.
الأداء ، من الصعب تقييم الخسارة . حركة المرور لدينا هي 3 تيرابايت من سجلات في اليوم الواحد ، وهو أمر لائق. لذلك ، لم يعمل Graylog دائمًا بثبات ، فقد كان من الضروري الدخول إلى الداخل من أجل فهم أسباب الفشل. اتضح أننا لم نعد نستخدمها كأداة - كان علينا القيام بشيء حيال ذلك.
معالجة التأخير (قوائم الانتظار) . لم نحب التنفيذ القياسي لقائمة الانتظار في Graylog.
الحاجة لدعم MongoDB . Graylog تستمر MongoDB ، كان من الضروري لإدارة هذا النظام كذلك.
لقد أدركنا أننا في هذه المرحلة نريد حلنا الخاص. ربما يكون هناك عدد أقل من الميزات الرائعة للتنبيه التي لم يتم استخدامها ، ولوحة المعلومات ، ولكن ميزاتها أفضل.
قرارنا
قمنا بتطوير خدمة السجلات الخاصة بنا.
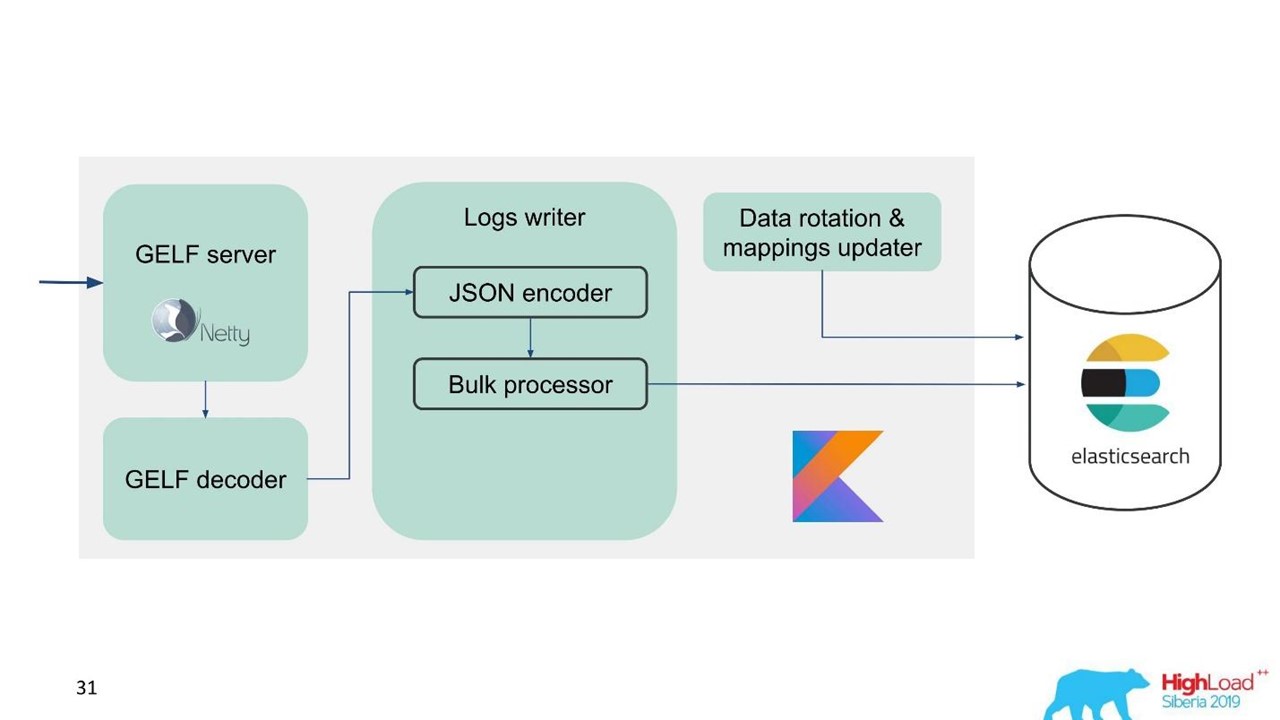
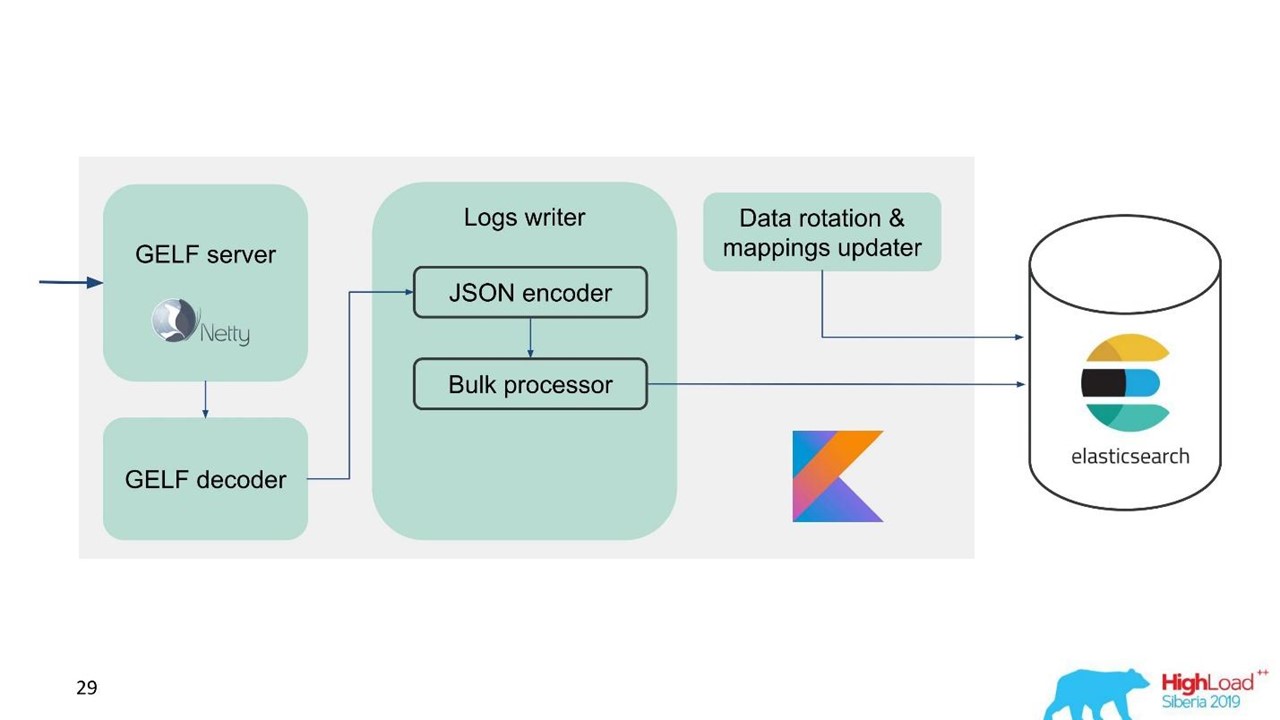 سجل الخدمة.
سجل الخدمة.في تلك اللحظة ، كان لدينا بالفعل خبرة في خدمة وصيانة مجموعات Elasticsearch الكبيرة ، لذلك أخذنا Elasticsearch كأساس. المكدس القياسي في الشركة هو JVM ، ولكن بالنسبة للواجهة الخلفية ، نستخدم أيضًا Kotlin بشكل مشهور ، لذلك أخذنا هذه اللغة للخدمة.
السؤال الأول هو كيفية تدوير البيانات وماذا تفعل مع التعيين. نحن نستخدم رسم الخرائط الثابتة. في Elasticsearch ، من الأفضل أن يكون لديك فهارس من نفس الحجم. ولكن مع مثل هذه المؤشرات ، نحتاج إلى تعيين بيانات بطريقة أو بأخرى ، خاصة بالنسبة لمراكز بيانات متعددة ونظام موزع وحالة موزعة. كانت هناك أفكار لربط ZooKeeper ، ولكن هذا مرة أخرى من مضاعفات الصيانة والكود.
لذلك ، قررنا ببساطة - الكتابة في الوقت المحدد.
مؤشر واحد لمدة ساعة واحدة ، في مراكز البيانات الأخرى 2 فهارس لمدة ساعة ، في فهرس واحد ثالث لمدة 3 ساعات ، ولكن كل ذلك في الوقت المناسب. يتم الحصول على الفهارس بأحجام مختلفة ، لأن حركة المرور في الليل أقل مما كانت عليه خلال النهار ، ولكن بشكل عام تعمل. وقد أظهرت التجربة أنه لا توجد مضاعفات مطلوبة.
لسهولة الترحيل ونظرا للكمية الكبيرة من البيانات ، اخترنا بروتوكول GELF ، وهو بروتوكول Graylog بسيط يستند إلى TCP. لذلك ، حصلنا على خادم GELF لـ Netty وجهاز فك تشفير GELF.
ثم يتم ترميز JSON للكتابة إلى Elasticsearch. نستخدم واجهة برمجة تطبيقات Java الرسمية من Elasticsearch والكتابة بالجملة.
لسرعة التسجيل العالية ، تحتاج إلى كتابة Bulk'ami.
هذا هو تحسين مهم. توفر واجهة برمجة التطبيقات (API) معالجًا ضخمًا يجمع الطلبات تلقائيًا ثم يرسلها للتسجيل في حزمة أو بمرور الوقت.
مشكلة مع معالج بالجملة
يبدو أن كل شيء على ما يرام. لكننا بدأنا وأدركنا أننا نستريح على معالج السائبة - لم يكن ذلك متوقعًا. لا يمكننا تحقيق القيم التي كنا نعول عليها - المشكلة جاءت من العدم.
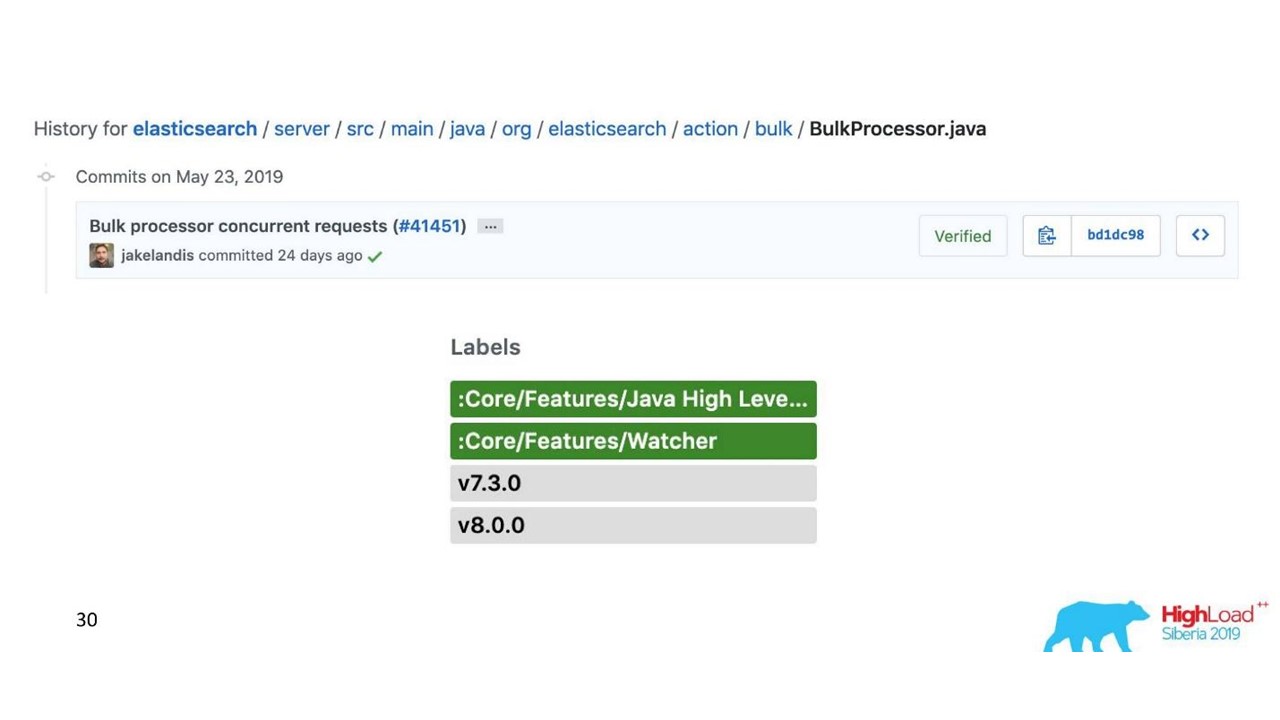
في التطبيق القياسي ، يكون معالج Bulk مترابط ومتزامن ، على الرغم من وجود إعداد موازٍ. كانت هذه هي المشكلة.
بحثنا حولنا واتضح أن هذا خطأ معروف ولكنه لم يحل. لقد قمنا بتغيير المعالج Bulk قليلاً - قدم قفلًا صريحًا من خلال ReentrantLock. فقط في مايو ، تم إجراء تغييرات مماثلة على مستودع Elasticsearch الرسمي وستكون متاحة فقط من الإصدار 7.3. الإصدار الحالي هو 7.1 ، ونحن نستخدم الإصدار 6.3.
إذا كنت تعمل أيضًا مع معالج مجمّع وترغب في رفع تردد التشغيل عن إدخال في Elasticsearch - فراجع هذه
التغييرات على GitHub ثم
انتقل إلى الإصدار الخاص بك. تؤثر التغييرات فقط على معالج Bulk. لن تكون هناك صعوبات إذا كنت بحاجة إلى منفذ إلى الإصدار أدناه.
كل شيء على ما يرام ، لقد ذهب المعالج السائبة ، وتسارعت السرعة.
أداء كتابة Elasticsearch غير مستقر بمرور الوقت ، حيث تجري عمليات متنوعة هناك: دمج الفهرس ، التدفق. أيضا ، يتباطأ الأداء لفترة من الوقت أثناء الصيانة ، عندما يتم إسقاط جزء من العقد من الكتلة ، على سبيل المثال.
في هذا الصدد ، أدركنا أننا بحاجة إلى تنفيذ ليس فقط المخزن المؤقت في الذاكرة ، ولكن أيضًا قائمة الانتظار. قررنا أننا لن نرسل سوى الرسائل المرفوضة إلى قائمة الانتظار - فقط تلك التي لا يمكن لمعالج Bulk معالجتها إلى Elasticsearch.
إعادة المحاولة الاحتياطية
هذا هو تنفيذ بسيط.
- نحن نحفظ الرسائل المرفوضة في الملف -
RejectedExecutionHandler .
- إعادة إرسال في الفاصل الزمني المحدد في منفذا منفصلا.
- ومع ذلك ، نحن لا تأخير حركة المرور الجديدة.
بالنسبة للمهندسين والمطورين الداعمين ، تعد الحركة الجديدة في النظام أكثر أهمية بشكل ملحوظ من تلك التي تأخرت لسبب ما أثناء الارتفاع أو التباطؤ في Elasticsearch. كان باقيا ، لكنه سيأتي لاحقا - لا صفقة كبيرة. يتم إعطاء الأولوية لحركة المرور الجديدة.
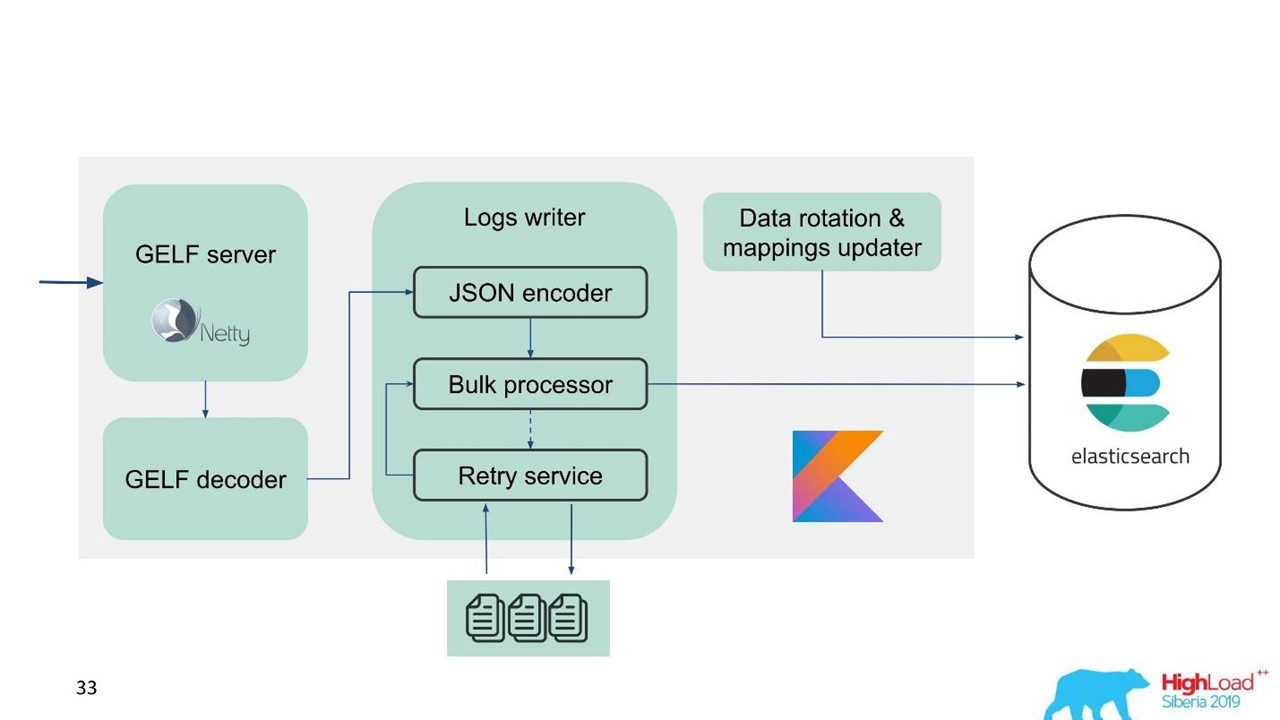 بدأ مخططنا لتبدو مثل هذا.
بدأ مخططنا لتبدو مثل هذا.الآن دعنا نتحدث عن كيفية تحضير Elasticsearch ، ما المعلمات التي استخدمناها وكيف أنشأناها.
التكوين Elasticsearch
المشكلة التي نواجهها هي الحاجة إلى رفع تردد التشغيل على Elasticsearch وتحسينه للكتابة ، لأن عدد القراءات أصغر بشكل ملحوظ.
استخدمنا العديد من المعلمات.
"ignore_malformed": true -
تجاهل الحقول ذات النوع الخطأ ، وليس المستند بأكمله . ما زلنا نريد تخزين البيانات ، حتى لو تسربت الحقول ذات التعيين غير الصحيح لسبب ما. لا يرتبط هذا الخيار تمامًا بالأداء.
للحديد ، Elasticsearch له فارق بسيط. عندما بدأنا في طلب مجموعات كبيرة ، قيل لنا أن مصفوفات RAID من محركات أقراص SSD لوحدات التخزين الخاصة بك مكلفة للغاية. ولكن ليست هناك حاجة المصفوفات لأن التسامح مع الخطأ هو بالفعل بنيت في Elasticsearch. حتى على الموقع الرسمي ، هناك توصية باتخاذ المزيد من الحديد الرخيص أكثر من تكلفة وأقل تكلفة. هذا ينطبق على كلا القرصين وعدد نوى المعالج ، لأن Elasticsearch كله يماثل بشكل جيد للغاية.
"index.merge.scheduler.max_thread_count": 1 -
يوصى به "index.merge.scheduler.max_thread_count": 1 الأقراص الصلبة .
إذا لم تحصل على محركات أقراص صلبة ، ولكن محركات الأقراص الثابتة العادية ، فقم بتعيين هذه المعلمة على واحدة. تتم كتابة الفهارس في أجزاء ، ثم يتم تجميد هذه القطع. هذا يحفظ قليلاً من القرص ، ولكن قبل كل شيء ، يسرع البحث. أيضًا ، عند إيقاف الكتابة إلى الفهرس ، يمكنك القيام
force merge . عندما يكون الحمل على الكتلة أقل ، يتجمد تلقائيًا.
"index.unassigned.node_left.delayed_timeout": "5m" -
تأخير النشر عندما تختفي العقدة . هذا هو الوقت الذي ستبدأ Elasticsearch بعده في تطبيق الفهارس والبيانات في حالة إعادة تشغيل العقدة أو نشرها أو سحبها للصيانة. ولكن إذا كان لديك حمولة ثقيلة على القرص والشبكة ، فإن عملية النشر ستكون عملية صعبة. من أجل عدم التحميل الزائد ، من الأفضل أن تتحكم مهلة التحكم في التأخيرات المطلوبة وفهمها.
"index.refresh_interval": -1 -
لا تقم بتحديث الفهارس إذا لم تكن هناك استعلامات بحث . ثم سيتم تحديث الفهرس عند ظهور استعلام البحث. يمكن ضبط هذا الفهرس بالثواني والدقائق.
"index.translogDurability": "async" - عدد مرات تنفيذ fsync: مع كل طلب أو حسب الوقت. يعطي مكاسب الأداء لمحركات الأقراص البطيئة.
لدينا أيضا وسيلة مثيرة للاهتمام لاستخدامها. يريد الدعم والمطورون أن يكونوا قادرين على البحث عن النص الكامل واستخدام regexp'ov في نص الرسالة. ولكن في Elasticsearch هذا غير ممكن - يمكن فقط البحث عن طريق الرموز الموجودة بالفعل في نظامها. يمكن استخدام RegExp و wildcard ، لكن لا يمكن أن يبدأ الرمز المميز مع بعض RegExp. لذلك ، أضفنا
word_delimiter إلى عامل التصفية:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
يقسم الكلمات تلقائيًا إلى رموز:
- "Wi-Fi" → "Wi" ، "Fi" ؛
- "PowerShot" → "Power" ، "Shot" ؛
- "SD500" → "SD" ، "500".
بطريقة مماثلة يتم كتابة اسم الفصل ، مع معلومات تصحيح مختلفة. مع ذلك ، قمنا بإغلاق بعض مشاكل البحث عن النص الكامل. أنصحك بإضافة هذه الإعدادات عند العمل مع تسجيل الدخول.
حول الكتلة
يجب أن يساوي عدد القطع عدد عقد البيانات لموازنة التحميل . الحد الأدنى لعدد النسخ المتماثلة هو 1 ، ثم سيكون لكل عقدة شارب رئيسي واحد ونسخة متماثلة واحدة. ولكن إذا كان لديك بيانات قيمة ، على سبيل المثال ، المعاملات المالية ، فمن الأفضل أن يتم إجراء 2 أو أكثر.
حجم القشرة من بضع غيغابايت إلى عدة عشرات غيغابايت . عدد القطع على عقدة لا يزيد عن 20 لكل 1 غيغابايت من Elasticsearch ، بطبيعة الحال. مزيد من Elasticsearch يبطئ - هاجمنا أيضا. في مراكز البيانات التي يوجد فيها عدد قليل من الزيارات ، لم يتم تدوير البيانات في الحجم ، وظهرت الآلاف من الفهارس وتعطل النظام.
استخدم allocation awareness ، على سبيل المثال ، بواسطة اسم برنامج Hypervisor في حالة الخدمة. يساعد على انتثار الفهارس والأشكال عبر برامج مراقبة متعددة بحيث لا تتداخل عندما يسقط برنامج Hypervisor.
إنشاء فهارس مسبقا . ممارسة جيدة ، خاصة عند الكتابة في الوقت المحدد. المؤشر ساخن على الفور وجاهز ولا يوجد أي تأخير.
تحديد عدد القطع من فهرس واحد لكل عقدة .
"index.routing.allocation.total_shards_per_node": 4 هو الحد الأقصى لعدد شظايا فهرس واحد لكل عقدة. في الحالة المثالية ، هناك 2 منهم ، وضعنا 4 فقط في حالة إذا كان لا يزال لدينا عدد أقل من السيارات.
ما هي المشكلة هنا؟ نحن نستخدم
allocation awareness - يعرف Elasticsearch كيفية نشر الفهارس بشكل صحيح عبر برامج Hypervisor. لكننا اكتشفنا أنه بعد إيقاف تشغيل العقدة لفترة طويلة ، ثم العودة مرة أخرى إلى المجموعة ، يرى Elasticsearch أن هناك فهارس أقل من ذلك رسميًا ويتم استعادتها. إلى أن تتم مزامنة البيانات ، يوجد عدد قليل من الفهارس على العقدة. إذا لزم الأمر ، قم بتخصيص فهرس جديد ، يحاول Elasticsearch التوصل إلى هذا الجهاز بأكثر كثافة ممكنة باستخدام فهارس جديدة. لذلك تحصل العقدة على تحميل ليس فقط من حقيقة أن البيانات يتم نسخها نسخًا متماثلاً إليها ، ولكن أيضًا مع حركة مرور جديدة ، فهارس وبيانات جديدة تقع على هذه العقدة. السيطرة والحد منها.
توصيات صيانة Elasticsearch
أولئك الذين يعملون مع Elasticsearch على دراية بهذه التوصيات.
أثناء الصيانة المجدولة ، قم بتطبيق التوصيات الخاصة بالترقية المستمرة: تعطيل تخصيص الحصة ، تدفق متزامن.
تعطيل تخصيص الحصة . تعطيل تخصيص النسخ المتماثلة حادة ، وترك القدرة على تخصيص الأولية فقط. يساعد هذا بشكل ملحوظ Elasticsearch - لن يعيد تخصيص البيانات التي لا تحتاجها. على سبيل المثال ، أنت تعلم أن العقدة سترتفع خلال نصف ساعة - لماذا تنقل كل القطع من عقدة إلى أخرى؟ لن يحدث شيء فظيع إذا كنت تعيش مع الكتلة الصفراء لمدة نصف ساعة ، عندما تتوفر القطع الأولية فقط.
تدفق مزامن . في هذه الحالة ، تتم مزامنة العقدة بشكل أسرع عندما تعود إلى نظام المجموعة.
مع وجود عبء ثقيل على الكتابة إلى الفهرس أو الاسترداد ، يمكنك تقليل عدد النسخ المتماثلة.
إذا قمت بتنزيل كمية كبيرة من البيانات ، على سبيل المثال ، حمل الذروة ، فيمكنك إيقاف تشغيل القطع وإعطاء أمر إلى Elasticsearch فيما بعد لإنشائها عندما يكون التحميل أقل بالفعل.
فيما يلي بعض الأوامر التي أحب استخدامها:
GET _cat/thread_pool?v - يسمح لك بمشاهدة thread_pool على كل عقدة: ما هو ساخن الآن ، ما هي قوائم الانتظار للكتابة والقراءة.
GET _cat/recovery/?active_only=true - أي الفهارس يتم نشرها إلى أين وأين يحدث الاسترداد.
GET _cluster/allocation/explain - في شكل بشري مناسب لماذا وما هي الفهارس أو النسخ المتماثلة التي لم يتم تخصيصها.
للمراقبة نستخدم Grafana.
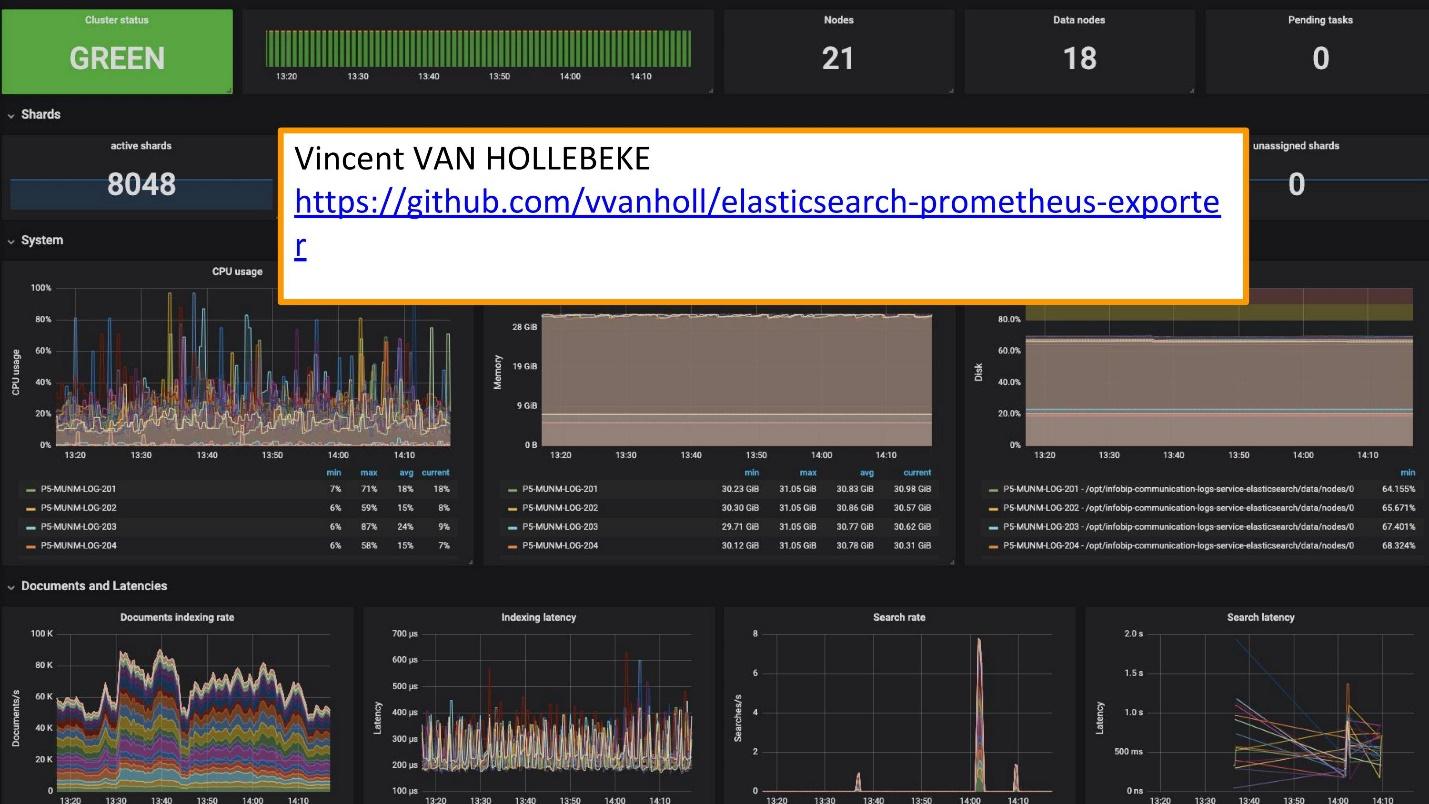
يوجد
مصدر ممتاز ولعب جرافانا من
Vincent van Hollebeke ، مما يتيح لك رؤية حالة المجموعة بصريًا وجميع معالمها الرئيسية. لقد أضفناها إلى صورة Docker الخاصة بنا وجميع المقاييس عند النشر من صندوقنا.
استنتاجات تسجيل الدخول
يجب أن تكون السجلات:
- مركزية - نقطة دخول واحدة للمطورين ؛
- المتاحة - القدرة على البحث بسرعة.
- مهيكل - للاستخراج السريع والمريح للمعلومات القيمة ؛
- مترابط - ليس فقط فيما بينها ، ولكن أيضًا مع مقاييس وأنظمة أخرى تستخدمها.
عقدت مسابقة
Melodif Festivalen السويدية مؤخرا. هذا هو مجموعة مختارة من ممثلي السويد ليوروفيجن. قبل المسابقة ، اتصلت بنا خدمة الدعم: "الآن في السويد سيكون هناك عبء كبير. حركة المرور حساسة للغاية ونريد ربط بعض البيانات. لديك بيانات في السجلات المفقودة على لوحة بيانات Grafana. لدينا مقاييس يمكن أخذها من Prometheus ، لكننا نحتاج إلى بيانات عن طلبات معرف محددة. "
وأضافوا Elasticsearch كمصدر لغرافانا وتمكنوا من ربط هذه البيانات وإغلاق المشكلة والحصول على نتائج جيدة بسرعة كافية.
استغلال الحلول الخاصة بك أسهل بكثير.
الآن ، بدلاً من 10 مجموعات Graylog التي عملت من أجل هذا الحل ، لدينا العديد من الخدمات. هذه 10 مراكز بيانات ، لكن ليس لدينا حتى فريق متخصص وأشخاص يخدمونها. هناك العديد من الأشخاص الذين عملوا عليها وتغيير شيء حسب الحاجة. تم دمج هذا الفريق الصغير تمامًا في بنيتنا التحتية - أصبح النشر والخدمة أسهل وأرخص.
حالات منفصلة واستخدام الأدوات المناسبة.
هذه أدوات منفصلة للتسجيل ، التتبع والمراقبة. لا يوجد "أداة ذهبية" تغطي جميع احتياجاتك.
لفهم الأداة المطلوبة ، وما الذي يجب مراقبته ، ومكان استخدام السجلات ، وما متطلبات السجلات ، يجب عليك بالتأكيد الانتقال إلى
SLI / SLO - مؤشر مستوى الخدمة / هدف مستوى الخدمة. تحتاج إلى معرفة ما هو مهم لعملائك وعملك ، وما هي المؤشرات التي ينظرون إليها.
بعد أسبوع ، ستستضيف SKOLKOVO HighLoad ++ 2019 . في مساء يوم 7 نوفمبر ، سوف يخبرك Ivan Letenko كيف يعيش مع Redis على المنتج ، وفي المجموع هناك 150 تقريرًا في البرنامج حول مجموعة متنوعة من الموضوعات.
إذا كنت تواجه مشكلات في زيارة HighLoad ++ 2019 مباشرة ، فلدينا أخبار جيدة. سيعقد المؤتمر هذا العام في ثلاث مدن في وقت واحد - في موسكو ونوفوسيبيرسك وسانت بطرسبرغ. في نفس الوقت كيف ستكون وكيف تصل إلى هناك - تعرف على صفحة ترويجية منفصلة للحدث.