لقد مر ما يزيد قليلاً عن عام منذ أن أعلنت MIT عن إطلاق لغة جوليا عالية الأداء للأغراض العامة. منذ ذلك الحين ، اكتسبت اللغة شعبية: يتم استخدامها في أكثر من 1500 جامعة (في بعض يتم تدريسها كلغة أولى للتدريس) ، ومجالات تغطية التطبيق من التشخيص الطبي والتخطيط للبعثة الفضائية إلى المشاكل الملحة مثل تحسين حركة الحافلات المدرسية .
أحد مجالات النشاط الرئيسية للعديد من المشاريع ، ليس من الصعب تخمينه ، هو التعلم الآلي ، حيث تمتلك جوليا العديد من الأدوات القوية ، وتم نشر مشروع مثير للاهتمام إلى حد ما - نظام برمجة الاحتمالات العامة "GEN" .
اليوم سننتبه إلى حزمة Flux ، كما يوحي الاسم ، والتي توفر كل قوة الشبكات العصبية. سنحاول الانتقال من معالجة مجموعات الصور والبحث فيها إلى شبكة عصبية مدربة للحصول على مصنف كامل!
تركيب
قم بتنزيل مجموعة التوزيع من الموقع الرسمي وتثبيت مترجم جوليا ( REPL ) على جهاز الكمبيوتر الخاص بك.
لكي يعمل مدير الحزم بشكل صحيح ، يجب أيضًا تثبيت مستخدمي Windows 7 / Windows Server 2012 :
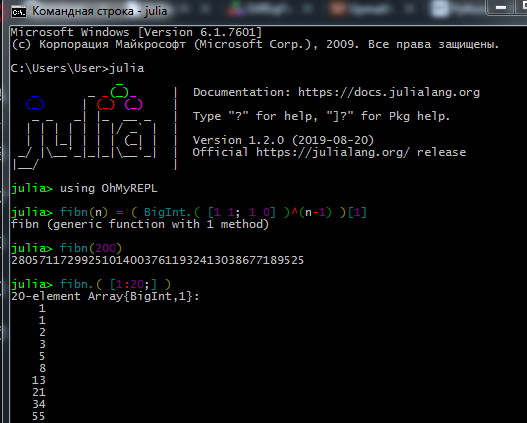
تبدو عملية العمل في REPL مثل هذا:
ويفضل علماء البيانات الحقيقيون وعلماء الآلات أن يستخدموا Jupyter . يمكنك هنا الاطلاع على التثبيت ، بالإضافة إلى العثور على دروس تفاعلية للدراسة المستقلة مع تعيينات باللغة الروسية (روابط إلى البرامج التعليمية الأصلية ودليل للغة هناك).
هنا يمكنك معرفة كيفية العمل مع Jupyter Notebook.
إذا مشاكل التثبيت- لا يمكن إنشاء اتصال - تحقق من حقوق الوصول الخاصة بك (هل لديك قيود على الكتابة إلى المجلدات على C: \ ، تسجيل الدخول كمسؤول أو بدء جوليا في وضع المسؤول) ، إذا كنت تستخدم وكيل ، فتأكد من تكوينه ليس فقط للمتصفح
- بعض الحزم لا تحب الأبجدية السيريلية في مسار الملف ، لذلك بسبب اسم المستخدم باللغة الروسية واجهتني الكثير من المشاكل
- إذا لم تعرض حزمة التفاعل النتائج ، فربما تكون قد قمت بتثبيت WebIO بشكل غير صحيح ، ويمكن إصلاحه
- لكي تعمل بعض الحزم بشكل صحيح على Windows ، يجب إدخال المسارات إلى Julia و Jupyter في متغيرات البيئة.
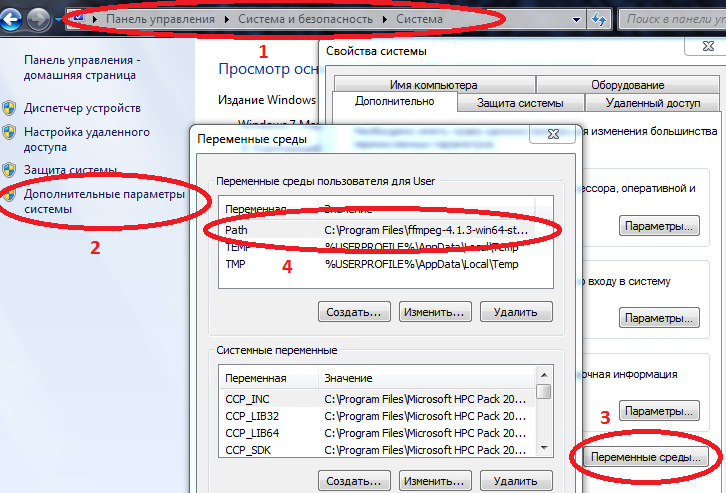
خصائص الكمبيوتر / النظام / معلمات النظام المتقدمة / متغيرات البيئة / المسار (إنشاء إن لم يكن) وإضافة المسار إلى julia.exe هناك
مثال C: \ Users \ User \ AppData \ Local \ Julia-1.2.0 \ bin
إذا كان Path يحتوي بالفعل على قيم ، فافصل بينها بفاصلة منقوطة.
الآن إذا كنت تقود julia إلى وحدة التحكم بالأوامر ( cmd ) ، فسيبدأ المترجم الفوري.
بعد تثبيت كل ما تحتاجه ، يمكنك متابعة تنزيل الحزم التي تحتاج إليها اليوم. أدخل الأوامر في REPL أو Jupyter
قانون using Pkg pkgs = ["Plots", "TextParse", "CSV", "DataFrames", "ImageMagick", "Images", "Interact", "Flux"] for p in pkgs Pkg.add(p) end for p in pkgs Pkg.build(p) end
بعد تعلم أساسيات اللغة (العمل مع المصفوفات ، إنشاء الوظائف ، تنزيل الحزم ، رسم الرسوم البيانية) ، يمكنك المتابعة إلى المواد التالية.
تحميل البيانات ومعالجتها
جمع وتنظيم البيانات هو فن منفصل. فيما يتعلق بجوليا ، تحتوي الشبكة على الكثير من المواد القديمة ، ولكن أولاً يمكنك تجربة البرنامج التعليمي أعلاه ، ولإجراء دراسة أكثر شمولاً ، اقرأ كتاب " علوم البيانات مع جوليا" (في المجال العام)
واليوم ، ربما ، سنعمل مع البيانات المعدة بالفعل: مجموعة بيانات من عدد كبير من الصور من الفواكه من زوايا مختلفة - الذين يريدون الفاكهة الطازجة؟


في الواقع هذه هي المهمة - سنقوم بتعليم الشبكة العصبية لتمييز التفاح عن الموز!
أول الأشياء أولاً ، قم بتحميل بعض صور الاختبار:
using Images fnames = [ "data/10_100.jpg", "data/107_100.jpg", "data/yellow_apple_2.jpg", "data/8_100.jpg", "data/104_100.jpg", "data/3_100.jpg" ]

كيف الكائنات في الصور تختلف عن بعضها البعض؟ أولاً ، حسب النموذج ، وثانياً بالألوان ، ثم عن طريق القوام والسمات الأخرى. يعد تحليل الصور موضوعًا مثيرًا للاهتمام في حد ذاته ، ويمكن إجراء التصنيف ليس فقط عن طريق الخلايا العصبية ، ولكن أيضًا عن طريق الموجات . سنبدأ مع أبسط علامة اللون.
كما تعلم ، يتم تخزين الصور في ذاكرة الكمبيوتر في شكل صفائف ، في حالتنا هذه هي مصفوفات ، تحتوي كل خلية منها على ثلاثة أرقام ، تشير إلى كميات الألوان الأحمر والأخضر والأزرق في كل بكسل من الصورة. دعونا نرى متوسط كمية كل لون في هذه الصور:
using Statistics: mean M1 = [ mean(float.(c.(img))) for c = [red,green,blue], img = fruits ] 3×6 Array{Float32,2}: 0.570278 0.652852 0.977111 0.835252 0.903998 0.842564 0.338118 0.468729 0.950773 0.806882 0.880692 0.755442 0.322406 0.379424 0.835212 0.707626 0.799643 0.761916
نحن ننظر بعناية إلى السطر الأول - ألا يزعجك ذلك؟ تفاحة صفراء وموز أكثر احمراراً من تفاح مجموعة بربرن! كيف ذلك؟ هيا ، اصنع الألغام الحامضة ، وربما يقرأ تلاميذ هذا البرنامج التعليمي ، أو الطلاب الأصغر سنا من معهد الباليه والجرارات. لذلك ، سنحاول تجنب الإغفالات. الحقيقة هي أن خلفية كل صورة بيضاء ، ويتم تدوينها في تدوين RGB بالقيم (1،1،1). ونظرًا لوجود 6 خلفيات إضافية في صور الصور الثلاثة ، بالإضافة إلى تلوين الموز والتفاحة الصفراء أيضًا باللون الأحمر ، اتضح أن أول صورتين تفقدان باللون الأحمر. من أجل الوضوح ، نقسم الصور إلى ألوان أساسية:
function tweaking(img) R = colorview( RGB, red.(img),zeroarray,zeroarray ) G = colorview( RGB, zeroarray,green.(img),zeroarray ) B = colorview( RGB, zeroarray,zeroarray, blue.(img) ) [R; G; B] end tweaking( hcat(fruits...) )

هل سمعت من قبل كلمة خفية "أساس؟" لذلك ، يمكننا القول أن هذه الصور وضعت على أساس RGB . اللون الأسود - كلما كان لون معين أقل ، وكما توقعنا ، فإن خلفية ثرائها تجعل حساب المتوسط صاخبة. احذفها.
function remove_background(img) mtrx = copy( channelview(img) ) for i = 1:size(mtrx, 2), j = 1:size(mtrx, 3) if reduce(&, mtrx[:,i,j] .> [0.8, 0.8, 0.8])

M3 = [ mean(float.(c.(img))) for c = [red,green,blue], img = greyfruits ] 3×6 Array{Float32,2}: 0.451008 0.532696 0.578967 0.527727 0.52849 0.500276 0.218805 0.348609 0.552679 0.499192 0.505136 0.412946 0.203528 0.260142 0.439354 0.400631 0.424784 0.419291
لا يزال الاختلاف في المنطقة التي يشغلها كل كائن يؤثر ، ولكن بشكل عام ، يمكن الاستنتاج أن الموز عبارة عن تفاح أكثر خضرة ( وزرقاء ). سيكون هذا هو معيار التقييم ، أي - علامة. الآن دعنا نلقي نظرة على بقية الصور:
pth = "C:\\Users\\User\\Desktop\\Banana"
لكل صورة ، نقوم بتحييد مساهمة الخلفية ، نجد متوسط مقدار كل لون ، مع تذكر حجم الصور في نفس الوقت ...
dataz = [] for fname in fnames img_i = load("$pth\\$fname") gbimg = remove_background(img_i) colorz = [ mean(c.(gbimg)) for c = [red,green,blue] ] inform = [size(gbimg, 1) size(gbimg, 2) colorz' ] push!(dataz, inform) end dataz
... وبعد ذلك يمكنك ترتيب بياناتنا في هياكل ملائمة للعمل - إطارات البيانات:
using DataFrames, CSV banans = DataFrame( vcat(dataz...), [:height, :width, :red, :green, :blue] ) CSV.write("data/bananas.csv", banans)
apples = CSV.read("data/Apple_Braeburn.csv")
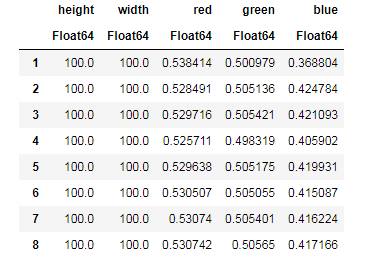
Desc = describe(apples, :all)
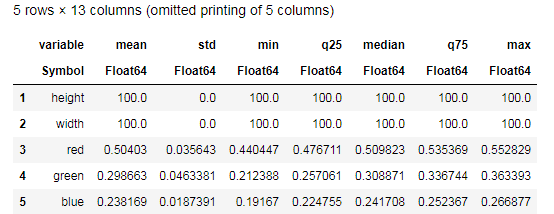
حاول فهم البيانات التي توفرها وظيفة describe() ومقارنتها بجدول مشابه للموز. حسنًا ، أي نوع من تحليل البيانات يمكن أن يكون بدون رسوم بيانية؟
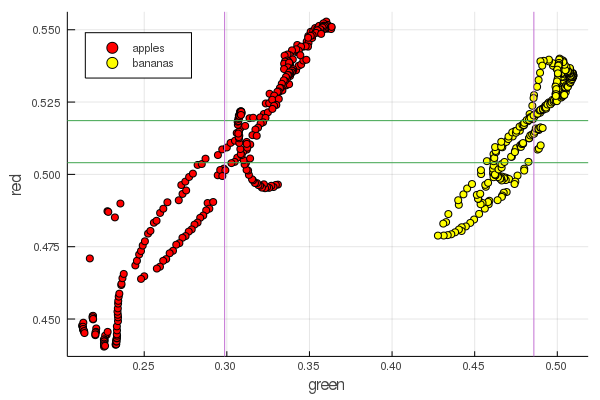
function plot2features(clr) x_apples = apples[:, :green] x_banans = banans[:, :green] y_apples = apples[:, clr] y_banans = banans[:, clr] scatter(x_apples, y_apples, lab = "apples", colour = :red) scatter!(x_banans, y_banans, lab = "bananas", legend = :topleft, colour = :yellow) hline!([mean(y_apples), mean(y_banans) ], lab = "" ) vline!([mean(x_apples), mean(x_banans) ], lab = "" ) xaxis!("green") yaxis!("$clr") end plot2features(:red)
plot2features(:blue)
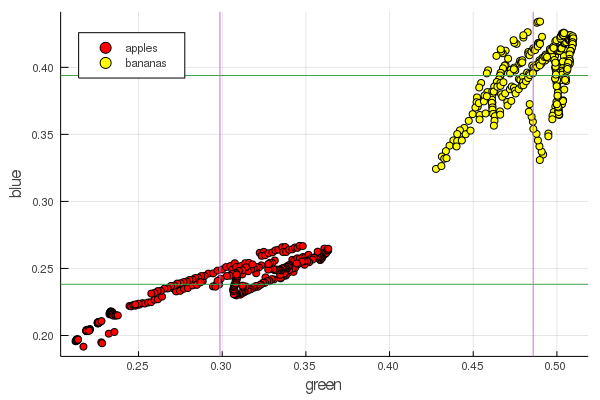
أحمر منتصف الموز قريب جدًا من حيث القيمة مقابل منتصف التفاح. ولكن على الرسم البياني الثاني ، يتم على الفور تتبع عزلة الثمار بشكل أوضح من خلال خصائص اللون اثنين في وقت واحد. يمكن تحسين الفواصل عن طريق إعادة التهيئة الصحيحة ، على سبيل المثال ، تتغير قيمنا الخضراء من 0.2 إلى 0.55 ، وإذا قمت بإجراء التحويل
ثم نحصل على البيانات التي تم تغييرها بواسطة [0،1] ، مما سيزيد من الفجوة بين هذه أكوام مجموعات من النقاط.
المستقبلات
تتمثل مهمة التصنيف في تحديد نموذج واختيار المعلمات التي ستتلقى فيها مختلف البيانات تقييماً فريدًا لانتمائها لفئة معينة. ببساطة ، نحتاج إلى تقديم وظيفة معينة وتعيين معاييرها بحيث تفصل تفاحنا عن الموز.
النموذج الأكثر شهرة وشعبية لهذه الأغراض هو الخلايا العصبية الاصطناعية McCulloch-Pitts ، التي تم تطويرها في أوائل الأربعينيات. بعد ذلك ، اقترح فرانك روزنبلات شبكة عصبية مدربة - المدركة. ليس من الصعب العثور على تفسيرات شاملة حول الشبكات العصبية ، بما في ذلك على هذا المورد (على سبيل المثال الشبكات العصبية للمبتدئين ، واستخدام الشبكات العصبية في التعرف على الصور ، والشبكات العصبية ، ومبادئ التشغيل الأساسية والتنوع والطوبولوجيا )
اختيار السيني كدالة تنشيط وتحديد مخرجات الكائنات المصنفة (ثمار) وفقًا لمخرجاتها
حدد هذه المعلمات و بحيث تتوافق قيم السيجويد الناتج للبيانات المستلمة مع الترميز
using Interact sigmo(x,w,b) = 1 / (1 + exp(-w*x+b)) r_apples, g_apples, b_apples = apples[:, :red], apples[:, :green], apples[:, :blue] r_banans, g_banans, b_banans = banans[:, :red], banans[:, :green], banans[:, :blue]; @manipulate for w in 10:1:60, b in -5:1:25 plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(g_apples[1:5], zeros(10), label="Apple", colour = :red) scatter!(g_banans[1:5], ones(10), label="Banana", colour = :yellow) end
foon(x) = sigmo(x,60,24) plot(foon, 0, 1, label="Model", legend = :topleft, lw=3) scatter!(foon, g_apples, label="Apple", colour = :red) scatter!(foon, g_banans, label="Banana", colour = :yellow) xaxis!("green")
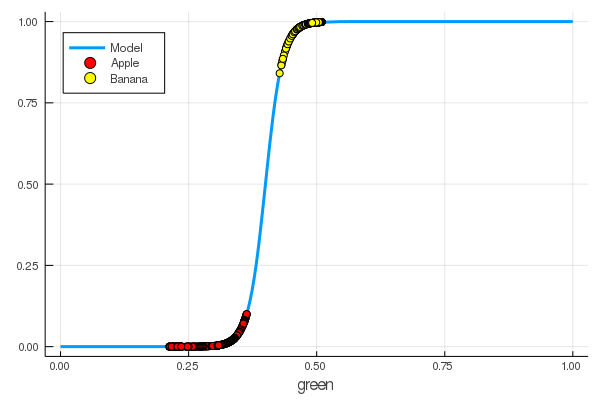
لقد علمنا يدويًا خلية عصبية لتمييز التفاح عن الموز بمقدار اللون الأخضر!
بطبيعة الحال ، الرغبة في أتمتة هذه العملية. نقدم وظيفة الخسارة
الآن ستتألف عملية التعلم من تقليل هذه الوظيفة إلى الحد الأدنى :
قانون apples_mean_green = mean(g_apples) banans_mean_green = mean(g_banans) L(w, b) = (0 - sigmo(apples_mean_green,w,b))^2 + (1 - sigmo(banans_mean_green,w,b))^2 w_range = 10:0.5:30 b_range = 0:0.5:20 L_values = [L(w,b) for b in b_range, w in w_range] @manipulate for w in w_range, b in b_range p1 = surface(w_range, b_range, L_values, xlabel="b", ylabel="w", cam=(80,40), cbar=false, leg=false) scatter!(p1, [w], [b], [L(w,b)+1e-2], markersize=5, color = :blue) p2 = plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(p2, [apples_mean_green], [0.0], label="Apple", markersize=10) scatter!(p2, [banans_mean_green], [1.0], label="Banana", markersize=10, xlim=(0,1), ylim=(0,1)) plot(p1, p2, layout=(2,1)) end
في وقت سابق درسنا حزم لجوليا التي تسمح بحل مشاكل التحسين بطرق مختلفة. لحسن الحظ ، الأساسيات موجودة بالفعل في بيئة Flux!
الجريان
using Flux
أولاً ، نقدم بيانات التدريب في شكل سهل الهضم:
Y = [zeros(length(g_apples)); ones(length(g_banans)) ] |> permutedims X = [g_apples; g_banans] |> permutedims;
التالي بالترتيب:
- نقوم بإنشاء مجموعة بيانات تدريب من خلال الجمع بين بيانات الإدخال والإجابات الصحيحة فيما يتعلق بتصنيف هذه البيانات
- نحن نضع المعلمتين W و b وفقًا لمصفوفات القيم العشوائية (توجد علامة واحدة على المدخلات والأخرى في الخرج ، بحيث تكون المصفوفات بحجم 1 × 1 )
- كنموذج ، وضعنا طبقة كثيفة - مدركة مع وظيفة التنشيط السيني
- قمنا بتعيين دالة الخسارة - مجموع الفروق التربيعية (لا يزال بإمكانك استخدام
Flux.crossentropy() الأكثر شيوعًا) - كوسيلة للتحسين ، نختار النسب التدرج . يستغرق المعلمة - سرعة النسب
- قمنا بتعيين وظيفة تقييم تقريب قيم مخرجات النموذج ومقارنتها بالإجابات الصحيحة.
- وطباعة معالم نموذجنا غير المدربين
dataz = [(X, Y)] W = param(rand(1)) b = param(rand(1)) model = Dense(W, b, σ) loss(x, y) = mse(model(x), y) opt = Descent(0.1) accuracy(x, y) = mean( round.(model(x)) .== y ) params(model) Params([[0.3372841444115968] (tracked), [0.8430399003786011] (tracked)])
دعونا نرى ما هو الناتج من وظيفة الخسارة لبياناتنا.
loss(X, Y)
وتحقق من نتائج وظيفة التقييم
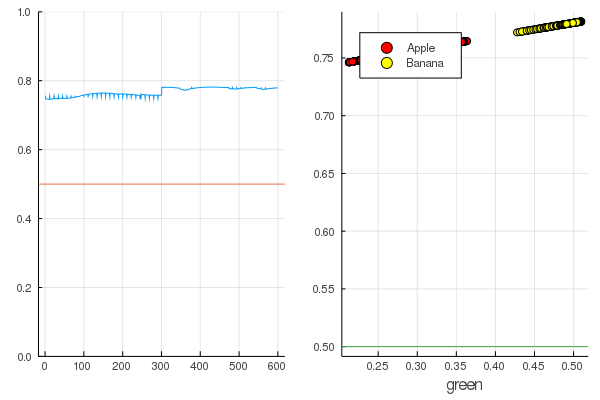
accuracy(X, Y) 0.5
والنتيجة طبيعية تمامًا - يتم توزيع المخرجات بشكل موحد تمامًا ويتم تصنيف نصف البيانات بشكل صحيح:
قانون modeldataz(x) = x |> model |> data |> permutedims
modelX = modeldataz(X) modelapples = modeldataz(g_apples') modelbanans = modeldataz(g_banans') plot(modelX, legend = false) hline!([0.5]) p1 = yaxis!((0,1)) curv = [-1:0.01:1;]' |> modeldataz plot( [-1:0.01:1;], curv, label="Model", legend = :topleft, lw=3) scatter!(g_apples, modelapples, label="Apple", colour = :red) scatter!(g_banans, modelbanans, label="Banana",colour = :yellow) hline!([0.5], lab = "", legend = :topleft) p2 = xaxis!("green") plot(p1, p2)
لنبدأ: الأمر بسيط للغاية. تحتاج فقط إلى الصراخ على الشبكة العصبية: "تدريب!" ، مع الإشارة إلى ما يجب التدريب عليه وما يجب تقليله ، وستكمل جلسة تدريب واحدة. لذلك ، سوف نجبرها على إبطال كل شيء كما ينبغي ، ولكن فقط بدون تعصب ، حتى لا يكون هناك إعادة تدريب
for i in 1:7000 train!(loss, params(model), dataz, opt) end model.W, model.b ([9.578663260720564] (tracked), [-3.7540362587506464] (tracked))
أصبحت الخسائر أقل بكثير:
loss(X, Y) 0.09152783090457564 (tracked)
تصنيف أفضل:
accuracy(X, Y) 1.0
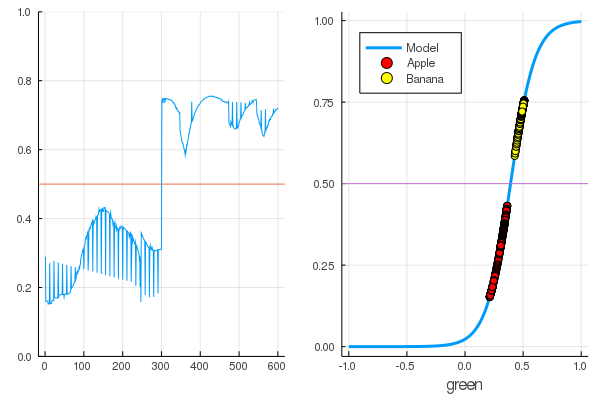
يتم تقسيم البيانات ، وسيؤدي المزيد من التدريب إلى جعل وظيفة النموذج أكثر رأسية. تحقق من النموذج المدرّب على المجموعة الأولى من الفواكه:
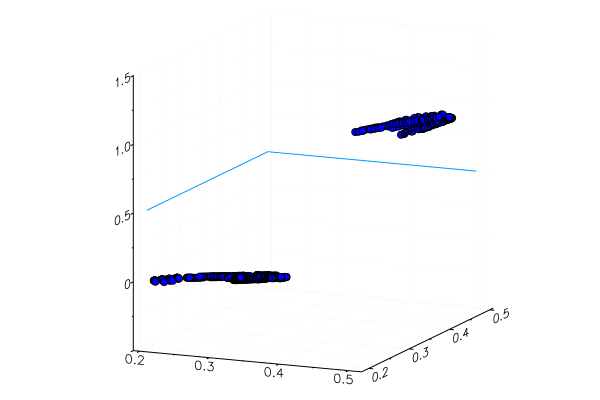
function classifier(img) gbimg = remove_background(img) greenmean = mean(float.(green.(gbimg))) answ = data( model( [ greenmean ]' ) )[1] fr = answ > 0.5 ? "Banana" : "Apple" "$fr $(round(200abs(0.5-answ)))%" end hcat(fruits...)
classifier.(fruits) 6-element Array{String,1}: "Apple 68.0%" "Apple 20.0%" "Banana 65.0%" "Banana 47.0%" "Banana 49.0%" "Banana 10.0%"
بطبيعة الحال ، لم يتم التعرف على تفاحة صفراء مزروعة خصيصًا بشكل صحيح ، بالكاد دخل موزة حمراء في فئتها. لكن الخلايا العصبية تحصل على رقم واحد فقط من الصورة - متوسط مقدار اللون الأخضر. يمكنك إضافة علامة أخرى ، على سبيل المثال ، مقدار اللون الأزرق ، مما يجعل النموذج أكثر قابلية للتكيف.
أو لا يمكنك استخدام تمثيل RGB ، ولكن HSV (تدرج اللون ، التشبع ، القيمة) ، حيث تحتوي قناة تدرج اللون على معلومات حول لون الصورة.
إن كل ما يتعلق بالشبكات العصبية هو أنها تستطيع تمييز الميزات التي ليست واضحة في بعض الأحيان (ارتباط اللون ، توزيعها ، الخطوط العريضة والمنحنيات ...) ، ولكن يمكنك مساعدتهم بمساعدة الأساليب البحثية والتقنيات الخاصة ، والتي تحول العمل مع الشبكات العصبية إلى الفن الحقيقي.

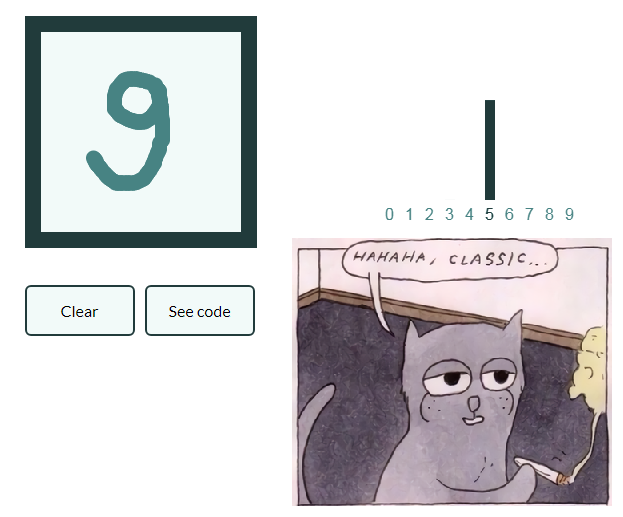
بحيث لا تنمو القيادة أكثر من اللازم والقيام سلسلة من المقالات كسول جدا دعونا أيضًا نعطي مثالًا على تصنيف الصور بأرقام مكتوبة بخط اليد ، وسيعمم القارئ المهتم بنفسه المعرفة المكتسبة في الصور ذات الثمار وسيخلق شبكته العصبية الخاصة ، القادرة ، على سبيل المثال ، وضع علامات على الكائنات في حياة ثابتة!
MNIST
using Images using Flux, Flux.Data.MNIST, Statistics using Flux: onehotbatch, onecold, crossentropy, throttle using Base.Iterators: repeated
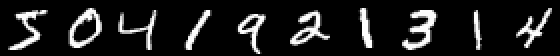
مثال مثير للاهتمام في أن هناك بالفعل عشرة مخارج. ما يسمى ناقلات واحدة الساخنة تأتي في متناول اليدين هنا.
labels = MNIST.labels()
10×60000 Flux.OneHotMatrix{Array{Flux.OneHotVector,1}}: 0 1 0 0 0 0 0 0 0 0 0 0 0 … 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 … 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0
نعرّف سلسلة من الخلايا العصبية كنموذج ، حيث يكون الانتروبيا المتقاطع وظيفة خسارة ، ويعد آدم طريقة تحسين:
m = Chain( Dense(28^2, 32, relu), Dense(32, 10), softmax) loss(x, y) = crossentropy(m(x), y) accuracy(x, y) = mean(onecold(m(x)) .== onecold(y)) dataset = repeated((X, Y), 20) evalcb = () -> @show(loss(X, Y)) opt = ADAM()
تدريب في وضع تجنيب ، ولكن طباعة الخسائر كل 10 ثوان:
for i = 1:10 Flux.train!(loss, params(m), dataset, opt, cb = throttle(evalcb, 10)) end
accuracy(X, Y) 0.64545
وتحقق من البيانات غير المستخدمة في التدريب
الشبكات العصبية على جوليا بسيطة ومثيرة للغاية! حتى إذا لم تكن هناك حاجة للبحث عن روابط بين مجال نشاطك والتعلم الآلي ، فيجب أن تشعر على الأقل بهذا الفضول الذي يصرخ من جميع الزوايا ، ولن يكون هناك نقص في الأدوات!
كل الحرارة وحدة المعالجة المركزية المعتدلة!