منذ فترة طويلة تعتبر النتيجة التراكمية (التراكمية) واحدة من مكالمات SQL. من المستغرب ، حتى بعد ظهور وظائف النافذة ، أنها لا تزال فزاعة (في أي حال ، للمبتدئين). نلقي نظرة اليوم على آليات الحلول العشرة الأكثر إثارة لهذه المشكلة - من وظائف النافذة إلى الاختراقات المحددة للغاية.
في جداول البيانات مثل Excel ، يتم حساب الإجمالي قيد التشغيل بكل بساطة: النتيجة في السجل الأول تطابق قيمتها:
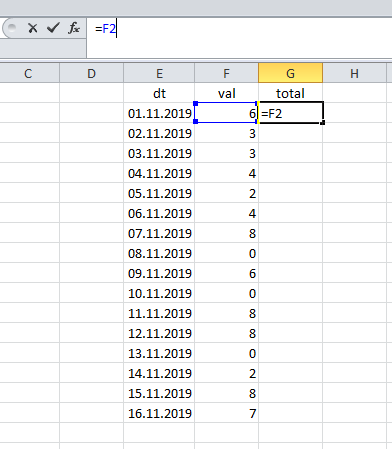
... ثم نلخص القيمة الحالية والإجمالي السابق.

وبعبارة أخرى
Total1=Value1Total2=Total1+Value2Total3=Total2+Value3 ldotsTotaln=Totaln−1+Valuen
... أو:
startcasesTotal1=Value1،n=1Totaln=Totaln−1+Valuen،n geq2 endcases
يؤدي ظهور مجموعتين أو أكثر في الجدول إلى تعقيد المهمة إلى حد ما: الآن نحسب عدة نتائج (لكل مجموعة على حدة). ومع ذلك ، هنا يكمن الحل على السطح: في كل مرة يكون من الضروري التحقق من المجموعة التي ينتمي إليها السجل الحالي.
انقر واسحب ، ويتم العمل:
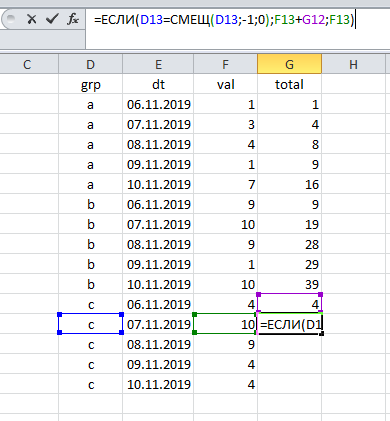
كما ترون ، يرتبط حساب الإجمالي التراكمي بمكونين لم يتغير:
(أ) فرز البيانات حسب التاريخ و
(ب) في اشارة الى السطر السابق.
ولكن ما هو SQL؟ لفترة طويلة جدا لم يكن هناك وظيفة ضرورية في ذلك. أداة ضرورية - وظائف النافذة - ظهرت لأول مرة فقط في معيار
SQL: 2003 . في هذه المرحلة ، كانوا بالفعل في Oracle (الإصدار 8i). لكن التنفيذ في قواعد بيانات إدارة قواعد البيانات الأخرى تأخر لمدة 5-10 سنوات: SQL Server 2012 ، MySQL 8.0.2 (2018) ، MariaDB 10.2.0 (2017) ، PostgreSQL 8.4 (2009) ، DB2 9 for z / OS (2007 العام) ، وحتى SQLite 3.25 (2018).
1. وظائف النافذة
وظائف النافذة هي على الأرجح أسهل طريقة. في الحالة الأساسية (جدول بدون مجموعات) ، نعتبر البيانات مرتبة حسب التاريخ:
order by dt
... لكننا مهتمون فقط بالخطوط قبل السطر الحالي:
rows between unbounded preceding and current row
في النهاية ، نحتاج إلى مبلغ مع هذه المعلمات:
sum(val) over (order by dt rows between unbounded preceding and current row)
سيبدو الطلب كاملاً كما يلي:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
في حالة المجموع التراكمي للمجموعات (حقل
grp ) ، نحتاج إلى تعديل صغير واحد فقط. الآن نعتبر البيانات مقسمة إلى "windows" استنادًا إلى المجموعة:

لحساب هذا الفصل ، يجب عليك استخدام
partition by الكلمة الأساسية:
partition by grp
ووفقًا لذلك ، ضع في اعتبارك مقدار هذه الإطارات:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
ثم يتم تحويل الاستعلام بأكمله مثل هذا:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
يعتمد أداء وظائف النافذة على خصائص نظام إدارة قواعد البيانات لديك (وإصداره!) ، وحجم الجدول ، وتوافر الفهارس. ولكن في معظم الحالات ، ستكون هذه الطريقة هي الأكثر فعالية. ومع ذلك ، لا تتوفر وظائف النافذة في الإصدارات الأقدم من DBMS (التي لا تزال قيد الاستخدام). بالإضافة إلى ذلك ، فهي ليست في نظم إدارة قواعد البيانات مثل Microsoft Access و SAP / Sybase ASE. إذا كانت هناك حاجة إلى حل مستقل عن البائع ، فينبغي النظر في البدائل.
2. استعلام فرعي
كما ذكر أعلاه ، تم تقديم وظائف النافذة متأخرة جدًا في نظام إدارة قواعد البيانات الرئيسية. لا ينبغي أن يكون هذا التأخير مفاجئًا: في النظرية العلائقية ، لا يتم ترتيب البيانات. أكثر من ذلك بكثير لروح نظرية العلائقية يتوافق مع حل من خلال استعلام فرعي.
يجب أن يأخذ هذا الاستعلام الفرعي في الاعتبار مجموع القيم التي لها تاريخ قبل التاريخ الحالي (بما في ذلك الحالي):
dtrow leqdtالحاليصف .
ما في الكود يشبه هذا:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
سيكون هناك حل أكثر فاعلية حيث يعتبر الاستعلام الفرعي الإجمالي حتى التاريخ الحالي (ولكن ليس بما في ذلك) ، ثم يلخصه بالقيمة في الصف:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
في حالة وجود نتيجة تراكمية لعدة مجموعات ، نحتاج إلى استخدام استعلام فرعي مرتبط:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
الشرط
g.grp = t2.grp يتحقق من خطوط التضمين في المجموعة (والتي ، من حيث المبدأ ، تشبه عمل
partition by grp في وظائف النافذة).
3. اتصال داخلي
نظرًا لأن الاستعلامات الفرعية والوصلات قابلة للتبادل ، يمكننا بسهولة استبدال أحدها بالآخر. للقيام بذلك ، يجب عليك استخدام "الانضمام الذاتي" ، توصيل مثيلين من نفس الجدول:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
كما ترون ، فإن شرط التصفية في الاستعلام الفرعي
t2.dt <= s.dt أصبح شرط
t2.dt <= s.dt . بالإضافة إلى ذلك ، من أجل استخدام مجموع الدالة
sum() نحتاج إلى التجميع حسب التاريخ والقيمة حسب
group by s.dt, s.val .
وبالمثل ، يمكنك القيام به في حالة استخدام مجموعات
grp مختلفة:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. المنتج الديكارتي
بما أننا استبدلنا الاستعلام الفرعي بـ join ، فلماذا لا نجرب المنتج الديكارتي؟ سيتطلب هذا الحل الحد الأدنى من التعديلات:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
أو لحالة المجموعات:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
تتوافق الحلول المدرجة (استعلام فرعي ، صلة داخلية ، صلة ديكارتية) مع
SQL-92 و
SQL: 1999 ، وبالتالي ستكون متاحة في أي من قواعد البيانات تقريبًا. المشكلة الرئيسية في كل هذه الحلول هي الأداء الضعيف. هذه ليست مشكلة كبيرة إذا حققنا جدولًا بالنتيجة (لكنك لا تزال تريد المزيد من السرعة!). تعتبر الطرق الأخرى أكثر فاعلية (يتم ضبطها وفقًا لخصائص نظم إدارة قواعد البيانات المعينة وإصداراتها المحددة بالفعل ، حجم الجدول ، الفهارس).
5. العودية طلب
أحد الأساليب الأكثر تحديدًا هو استعلام تكراري في تعبير جدول شائع. للقيام بذلك ، نحتاج إلى "مرساة" - استعلام يُرجع السطر الأول:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
بعد ذلك ، بمساعدة
union all ، تتم إضافة نتائج الاستعلام العودية إلى "المرساة". للقيام بذلك ، يمكنك الاعتماد على حقل تاريخ
dt ، إضافة يوم واحد إليه:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
جزء الكود الذي يضيف يومًا ما ليس عالميًا. على سبيل المثال ، هذا هو
r.dt = dateadd(day, 1, cte.dt) لـ SQL Server ،
r.dt = cte.dt + 1 لـ Oracle ، إلخ.
بالجمع بين "المرساة" والطلب الرئيسي ، نحصل على النتيجة النهائية:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
لن يكون حل القضية مع المجموعات أكثر تعقيدًا:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6. تكراري الاستعلام مع وظيفة row_number()
استند القرار السابق إلى استمرارية حقل تاريخ
dt بزيادة متتابعة قدرها يوم واحد. نتجنب هذا باستخدام وظيفة نافذة
row_number() ، والتي
row_number() الصفوف. بالطبع ، هذا غير عادل - لأننا سننظر في بدائل لوظائف النوافذ. ومع ذلك ، قد يكون هذا الحل بمثابة
دليل على المفهوم : في الممارسة العملية ، قد يكون هناك حقل يستبدل أرقام الأسطر (معرف السجل). بالإضافة إلى ذلك ، في SQL Server ، ظهرت دالة
row_number() قبل تقديم الدعم الكامل لوظائف الإطار (بما في ذلك
sum() ).
لذلك ، للحصول على استعلام عودي مع
row_number() نحتاج إلى
row_number() . في الأول ، نرقّم فقط الخطوط:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... وإذا كان رقم الصف موجودًا بالفعل في الجدول ، فيمكنك الاستغناء عنه. في الاستعلام التالي ،
cte1 بالفعل إلى
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
والطلب بأكمله يشبه هذا:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... أو لحالة المجموعات:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY / LATERAL
إحدى الطرق الأكثر غرابة لحساب إجمالي قيد التشغيل هي استخدام عبارة
CROSS APPLY (SQL Server أو Oracle) أو ما يعادلها
LATERAL (MySQL ، PostgreSQL). ظهرت هذه العوامل متأخرة إلى حد ما (على سبيل المثال ، في Oracle فقط من الإصدار 12c). وفي بعض نظم إدارة قواعد البيانات (على سبيل المثال ،
MariaDB ) فهي ليست على الإطلاق. لذلك ، هذا القرار له مصلحة جمالية بحتة.
من الناحية الوظيفية ، فإن استخدام
CROSS APPLY أو
LATERAL مماثل
LATERAL الفرعي: نعلق نتيجة الحساب بالطلب الرئيسي:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... الذي يبدو مثل هذا:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
سيكون حل القضية مع المجموعات مشابهًا:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
المجموع: درسنا الحلول الرئيسية المستقلة عن النظام الأساسي. ولكن هناك حلول محددة ل DBMS محددة! نظرًا لوجود الكثير من الخيارات هنا ، دعونا نتناول بعض الخيارات الأكثر إثارة للاهتمام.
8. بيان MODEL (أوراكل)
يوفر بيان
MODEL في Oracle أحد الحلول الأكثر أناقة. في بداية المقال ، درسنا الصيغة العامة للمجموع التراكمي:
startcasesTotal1=Value1،n=1Totaln=Totaln−1+Valuen،n geq2 endcases
يسمح لك
MODEL بتطبيق هذه الصيغة حرفيًا واحدًا إلى واحد! للقيام بذلك ، نملأ أولاً الحقل
total بقيم الصف الحالي
select dt, val, val as total from test_simple
... ثم نحسب رقم الصف كـ
row_number() over (order by dt) as rn (أو نستخدم الحقل النهائي بالرقم ، إن وجد). وأخيرًا ، نقدم قاعدة لجميع الأسطر باستثناء الأول:
total[rn >= 2] = total[cv() - 1] + val[cv()] .
الدالة
cv() هنا مسؤولة عن قيمة السطر الحالي. وسيبدو الطلب بأكمله كما يلي:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. المؤشر (خادم SQL)
يعد إجمالي التشغيل أحد الحالات القليلة التي لا يكون فيها المؤشر في SQL Server مفيدًا فحسب ، بل يفضل أيضًا الحلول الأخرى (على الأقل حتى الإصدار 2012 ، حيث ظهرت وظائف النافذة).
التنفيذ من خلال المؤشر تافهة جدا. تحتاج أولاً إلى إنشاء جدول مؤقت وملء التواريخ والقيم من الرئيسي:
create table
ثم نقوم بتعيين المتغيرات المحلية التي سيتم من خلالها التحديث:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
بعد ذلك نقوم بتحديث الجدول المؤقت من خلال المؤشر:
declare cur cursor local static read_only forward_only for select dt, val from
وأخيرا ، نحصل على النتيجة المرجوة:
select dt, val, total from
10. التحديث من خلال متغير محلي (SQL Server)
يعتمد التحديث من خلال متغير محلي في SQL Server على سلوك غير موثق ، لذلك لا يمكن اعتباره موثوقًا. ومع ذلك ، ربما يكون هذا هو الحل الأسرع ، وهذا مثير للاهتمام.
لنقم بإنشاء متغيرين: واحد للمجمل التراكمي ومتغير جدول:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
أولاً ، املأ
@tv بالبيانات من الجدول الرئيسي
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
ثم
@tv بتحديث متغير الجدول
@tv باستخدام
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... وبعد ذلك نحصل على النتيجة النهائية:
select * from @tv order by dt;
ملخص: قمنا بمراجعة أفضل 10 طرق لحساب الإجماليات التراكمية في SQL. كما ترون ، حتى بدون وظائف النافذة ، فإن هذه المشكلة قابلة للحل تمامًا ، ولا يمكن وصف ميكانيكا الحل بالتعقيد.