مرحبا بالجميع! اسمي فلاد وأنا أعمل كعالم بيانات في فريق Tinkoff لتقنيات الكلام المستخدمة في مساعد الصوت لدينا أوليغ.
في هذه المقالة ، أود أن أقدم لمحة مختصرة عن تقنيات توليف الكلام المستخدمة في الصناعة وتبادل خبرة فريقنا في بناء محرك التوليف الخاص بنا.

توليف الكلام
توليف الكلام هو خلق الصوت على أساس النص. يتم حل هذه المشكلة اليوم بطريقتين:
- اختيار وحدة [1] ، أو نهج تسلسلي. ويستند على شظايا لصق الصوت المسجل. منذ أواخر التسعينيات ، لطالما كان المعيار الفعلي لتطوير محركات تركيب الكلام. على سبيل المثال ، يمكن العثور على صوت يصدر بطريقة تحديد الوحدة في سيري [2].
- توليف الكلام المعلمي [3] ، الذي يتمثل جوهره في بناء نموذج احتمالي يتنبأ بالخصائص الصوتية لإشارة صوتية لنص معين.
خطاب نماذج اختيار الوحدة هو ذات جودة عالية ، وانخفاض التغير ويتطلب كمية كبيرة من البيانات للتدريب. في الوقت نفسه ، لتدريب النماذج البارامترية ، هناك حاجة إلى كمية أقل بكثير من البيانات ، فهي تولد تنبيهات أكثر تنوعًا ، لكن حتى وقت قريب عانوا من جودة صوت رديئة إلى حد ما مقارنة بنهج اختيار الوحدة.
ومع ذلك ، مع تطور تقنيات التعليم العميق ، حققت نماذج التوليف البارامترية نموًا كبيرًا في جميع مقاييس الجودة وقادرة على إنشاء خطاب لا يمكن تمييزه عمليًا عن الكلام البشري.
مقاييس الجودة
قبل التحدث عن نماذج تركيب الكلام الأفضل ، تحتاج إلى تحديد مقاييس الجودة التي سيتم بها مقارنة الخوارزميات.
نظرًا لأن النص نفسه يمكن قراءته بعدد لا حصر له من الطرق ، فإن الطريقة الصحيحة أولاً نطق عبارة معينة غير موجودة. لذلك ، غالبًا ما تكون مقاييس جودة توليف الكلام ذاتية وتعتمد على إدراك المستمع.
المقياس القياسي هو MOS (متوسط درجة الرأي) ، وهو تقييم متوسط لطبيعة الكلام ، يقدمه المقيِّمون للصوت المركب على مقياس من 1 إلى 5. أحدهما يعني الصوت غير المعقول تمامًا ، والخمس يعني الكلام الذي لا يمكن تمييزه عن الإنسان. عادةً ما تحصل سجلات الأشخاص الحقيقيين على حوالي 4.5 ، وتعتبر قيمة أكبر من 4 عالية جدًا.
كيف يعمل تركيب الكلام
الخطوة الأولى لبناء أي نظام توليف الكلام هي جمع البيانات للتدريب. عادة ما تكون هذه تسجيلات صوتية عالية الجودة يقوم المذيع بقراءة العبارات المحددة لها خصيصًا. يبلغ الحجم التقريبي لمجموعة البيانات المطلوبة لنماذج اختيار وحدة التدريب من 10 إلى 20 ساعة من الكلام النقي [2] ، بينما بالنسبة للتقنيات البارامترية للشبكة العصبية ، يكون التقدير العلوي حوالي 25 ساعة [4 ، 5].
نناقش كلا تقنيات التوليف.
اختيار وحدة
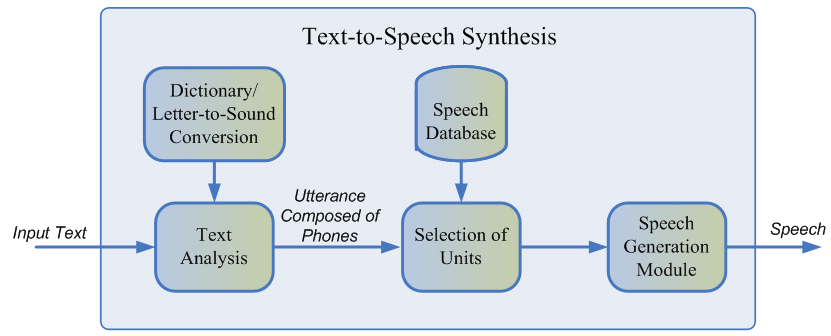
عادة ، لا يمكن للكلام المسجل للمتحدث تغطية جميع الحالات المحتملة التي سيتم فيها استخدام التوليف. لذلك ، فإن جوهر الطريقة هو تقسيم قاعدة الصوت بأكملها إلى أجزاء صغيرة ، تسمى الوحدات ، والتي يتم لصقها معًا باستخدام الحد الأدنى من المعالجة اللاحقة. الوحدات عادة ما تكون وحدات اللغة الصوتية الحد الأدنى ، مثل الهواتف نصف أو diphons [2].
تتكون عملية التوليد بأكملها من مرحلتين: الواجهة الأمامية NLP ، المسؤولة عن استخراج التمثيل اللغوي للنص ، والخلفية ، والتي تحسب وظيفة عقوبة الوحدة للميزات اللغوية المحددة. تتضمن الواجهة الأمامية لـ NLP ما يلي:
- تتمثل مهمة تطبيع النص في ترجمة جميع الأحرف غير الأحرف (الأرقام ، وعلامات النسبة المئوية ، والعملات ، وما إلى ذلك) إلى تمثيلها اللفظي. على سبيل المثال ، يجب تحويل "5٪" إلى "خمسة بالمائة".
- استخراج الميزات اللغوية من نص عادي: تمثيل الصوت والضغط وأجزاء من الكلام وما إلى ذلك.
بشكل عام ، يتم تطبيق الواجهة الأمامية لـ NLP باستخدام قواعد محددة يدويًا بلغة معينة ، ولكن في الآونة الأخيرة ، كان هناك ميل متزايد نحو استخدام نماذج التعلم الآلي [7].
إن العقوبة المقدرة بواسطة النظام الفرعي الخلفي هي مجموع التكلفة المستهدفة ، أو مراسلات التمثيل الصوتي للوحدة لفونيم معين ، وتكلفة السلسلة ، أي مدى ملاءمة توصيل وحدتين متجاورتين. لتقييم الوظائف الدقيقة ، يمكن للمرء استخدام القواعد أو النموذج الصوتي المدرَّب بالفعل لتوليف حدودي [2]. يحدث اختيار التسلسل الأمثل للوحدات من وجهة نظر العقوبات المحددة أعلاه باستخدام خوارزمية Viterbi [1].
القيم التقريبية لنماذج اختيار وحدة MOS للغة الإنجليزية: 3.7-4.1 [2 ، 4 ، 5].
مزايا نهج اختيار الوحدة:
- الصوت الطبيعي.
- توليد سرعة عالية.
- الحجم الصغير للطرز - يتيح لك استخدام التوليف مباشرة على جهازك المحمول.
العيوب:
- الكلام المركب رتيب ، لا يحتوي على العواطف.
- التحف الفنية المميزة.
- يتطلب قاعدة تدريب كبيرة بما فيه الكفاية من البيانات الصوتية لتغطية جميع أنواع السياقات.
- من حيث المبدأ ، لا يمكن إنشاء صوت غير موجود في مجموعة التدريب.
تركيب الكلام البارامترى
يعتمد النهج المعياري على فكرة إنشاء نموذج احتمالي يقدر توزيع الميزات الصوتية لنص معين.
يمكن تقسيم عملية توليد الكلام في التوليف حدودي إلى أربع مراحل:
- واجهة البرمجة اللغوية العصبية NLP هي نفس المرحلة من المعالجة المسبقة للبيانات كما في نهج اختيار الوحدة ، والنتيجة هي وجود عدد كبير من الميزات اللغوية الحساسة للسياق.
- مدة النموذج تتنبأ بمدة الصوت.
- نموذج صوتي يستعيد توزيع الميزات الصوتية على الخصائص اللغوية. تشمل الميزات الصوتية قيم التردد الأساسية والتمثيل الطيفي للإشارة وما إلى ذلك.
- مشفر صوتي يترجم الميزات الصوتية إلى موجة صوتية.
لفترة التدريب والنماذج الصوتية ، يمكن استخدام نماذج ماركوف المخفية [3] ، والشبكات العصبية العميقة ، أو أنواعها المتكررة [6]. المشفر الصوتي التقليدي هو خوارزمية تعتمد على نموذج مرشح المصدر [3] ، والتي تفترض أن الكلام هو نتيجة لتطبيق مرشح الضوضاء الخطية على الإشارة الأصلية.
إن جودة الكلام الكلية للطرق البارامترية الكلاسيكية منخفضة جدًا نظرًا للعدد الكبير من الافتراضات المستقلة حول بنية عملية توليد الصوت.
ومع ذلك ، مع ظهور تقنيات التعلم العميق ، أصبح من الممكن تدريب النماذج الشاملة التي تتنبأ مباشرة بالإشارات الصوتية بحرف. على سبيل المثال ، تقوم الشبكات العصبية Tacotron [4] و Tacotron 2 [5] بإدخال سلسلة من الحروف وإرجاع الطيفية الطيفية باستخدام خوارزمية seq2seq [8]. وبالتالي ، يتم استبدال الخطوات 1-3 من النهج الكلاسيكي بشبكة عصبية واحدة. يوضح الرسم البياني أدناه بنية شبكة Tacotron 2 ، التي تحقق جودة صوت عالية إلى حد ما.
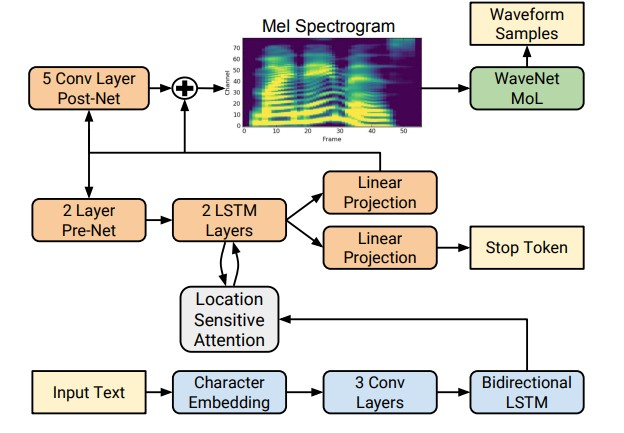
كان العامل الآخر لزيادة كبيرة في جودة الكلام المركب هو استخدام مشفرات الشبكة العصبية بدلاً من خوارزميات معالجة الإشارات الرقمية.
أول مشفر صوتي كان شبكة WaveNet العصبية [9] ، التي تنبأت بالتتابع خطوة بخطوة بسعة الموجة الصوتية.
نظرًا لاستخدام عدد كبير من الطبقات التلافيفية مع وجود ثغرات لالتقاط المزيد من السياق وتخطي الاتصال في بنية الشبكة ، تحقق ما يقرب من 10٪ من التحسن في MOS مقارنةً بنماذج اختيار الوحدة. يوضح الرسم البياني أدناه بنية شبكة WaveNet.

العيب الرئيسي لـ WaveNet هو السرعة المنخفضة المرتبطة بدائرة أخذ عينات الإشارة التسلسلية. يمكن حل هذه المشكلة إما عن طريق استخدام التحسين الهندسي لبنية حديدية محددة ، أو عن طريق استبدال نظام أخذ العينات بنظام أسرع.
تم تنفيذ كلا النهجين بنجاح في الصناعة. الأول في Tinkoff.ru ، وكجزء من النهج الثاني ، قدمت Google شبكة Parallel WaveNet [10] في عام 2017 ، ويتم استخدام إنجازاتها في مساعد Google.
القيم التقريبية ل MOS لأساليب الشبكة العصبية: 4.4-4.5 [5 ، 11] ، أي أن الكلام المركب لا يختلف عملياً عن الكلام البشري.
مزايا التوليف حدودي:
- صوت طبيعي وسلس عند استخدام النهج الشامل.
- تنوع أكبر في التجويد.
- استخدام بيانات أقل من نماذج اختيار الوحدة.
العيوب:
- سرعة منخفضة مقارنة باختيار الوحدة.
- التعقيد الحسابي الكبير.
كيف يعمل تركيب خطاب تينكوف
على النحو التالي من المراجعة ، فإن طرق تخليق الكلام البارامترية القائمة على الشبكات العصبية هي في الوقت الحالي متفوقة بشكل كبير من حيث الجودة على نهج اختيار الوحدة وأسهل بكثير في التطوير. لذلك ، لبناء محرك التوليف الخاص بنا ، استخدمناها.
لنماذج التدريب ، تم استخدام حوالي 25 ساعة من الكلام الخالص للمتحدث المحترف. تم اختيار نصوص القراءة خصيصًا لتغطية معظم الصوتيات للكلام العامي. بالإضافة إلى ذلك ، من أجل إضافة المزيد من التنوع إلى التوليف في التجويد ، طلبنا من المذيع قراءة النصوص بتعبير يعتمد على السياق.
تبدو بنية حلنا من الناحية النظرية كما يلي:
- الواجهة الأمامية NLP ، والتي تتضمن تطبيع نص الشبكة العصبية ونموذجًا لوضع الإيقاف المؤقت والإجهادات.
- Tacotron 2 قبول الرسائل كمدخل.
- الرد التلقائي WaveNet ، والعمل في الوقت الحقيقي على وحدة المعالجة المركزية.
بفضل هذا الهيكل ، يولد محركنا خطابًا تعبيريًا عالي الجودة في الوقت الفعلي ، ولا يتطلب إنشاء قاموس صوتي ، ويجعل من الممكن التحكم في الضغوط بكلمات فردية. يمكن سماع أمثلة الصوت المركب من خلال النقر على الرابط .
المراجع:
[1] AJ Hunt، AW Black. اختيار الوحدة في نظام توليف الكلام المتسلسل باستخدام قاعدة بيانات كبيرة للكلام ، ICASSP ، 1996.
[2] T. Capes، P. Coles، A. Conkie، L. Golipour، A. Hadjitarkhani، Q. Hu، N. Huddleston، M. Hunt، J. Li، M. Neeracher، K. Prahallad، T. Raitio ، R. Rasipuram، G. Townsend، B. Williamson، D. Winarsky، Z. Wu، H. Zhang. نظام اختيار وحدة تحويل النص إلى كلام من Siri على الجهاز بنظام التعليم العميق ، Interspeech ، 2017.
[3] H. Zen، K. Tokuda، AW Black. توليف الكلام الإحصائي حدودي ، الكلام الكلام ، المجلد. 51 ، لا. 11 ، ص. 1039-1064 ، 2009.
[4] Yuxuan Wang ، RJ Skerry-Ryan ، Daisy Stanton ، Yonghui Wu ، Ron J. Weiss ، Navdeep Jaitly ، Zongheng Yang ، Ying Xiao ، Zhifeng Chen ، Samy Bengio ، Quoc Le ، Yannis Agiomyrgiannakis ، Rob Clark . تاكوترون: نحو توليف الكلام من طرف إلى طرف.
[5] جوناثان شين ، رومينغ بانج ، رون ج. فايس ، مايك شوستر ، نافديب جايتلي ، تسونغ هنغ يانغ ، زهيفنغ تشن ، يو زهانغ ، يوكسوان وانغ ، ر ج سكيري ريان ، ريف أ. ساوروس ، يانيس أجيوميرغياناكيس ، يونغ هو وو. توليف تحويل النص إلى كلام الطبيعي عن طريق تكييف WaveNet على توقعات ميل Spectrogram.
[6] هيغا زين ، أندرو سنيور ، مايك شوستر. التوليف الإحصائي حدودي إحصائي باستخدام الشبكات العصبية العميقة.
[7] هاو تشانغ ، ريتشارد سبروت ، أكسل هـ. ن. ، فيليكس ستاهلبرغ ، شياوشانغ بينغ ، كايل جورمان ، برايان رورك. النماذج العصبية لتطبيع النص لتطبيقات الكلام.
[8] ايليا سوتسكيفر ، أوريول فينيالز ، كووك لي. التسلسل إلى التعلم التسلسلي مع الشبكات العصبية.
[9] آرون فان دن أورد ، ساندر ديليمان ، هيغا زين ، كارين سيمونيان ، أوريول فينياليس ، أليكس جريفز ، نال كالشبرنر ، أندرو سنيور ، كوراي كافوكوجلو. WaveNet: نموذج عام لإنتاج الصوت الخام.
[10] آرون فان دن أورد ، ياهي لي ، إيغور بابوشكين ، كارين سيمونيان ، أوريول فينيالس ، كوراي كافوكوجلو ، جورج فان دن دريش ، إدوارد لوكهارت ، لويس سي كوبو ، فلوريان ستيمبرغ ، نورمان كاساجراند ، دومينيك غريوي ، سيب نوري ، ساندر ديليمان ، إريك إلسن ، نال كالشبرنر ، هيغا زن ، أليكس جريفز ، هيلين كينغ ، توم والترز ، دان بيلوف ، ديميس حسابس. WaveNet الموازي: تركيب خطاب عالي الدقة.
[11] وي بينغ كينان بينج جيتونج تشن. ClariNet: توليد الموجة الموازية في تحويل النص إلى كلام من طرف إلى طرف.
[12] داريو ريثاج ، جوردي بونس ، كزافييه سيرا. A Wavenet لتقليل الكلام.