تحدث فيبي وونج ، وهو عالم ومدير مالي في المساواة بين المواطنين ، عن الصراع الثقافي في العلوم المعرفية. قامت إيلينا كوزمينا بترجمة المقال إلى اللغة الروسية.
قبل بضع سنوات شاهدت مناقشة حول معالجة اللغة الطبيعية. تحدث "أب اللغويات الحديثة"
نعوم تشومسكي والمتحدث باسم الحرس الجديد
بيتر نورفيج ، مدير الأبحاث في Google.
فكر تشومسكي في أي اتجاه يتحرك مجال معالجة اللغة الطبيعية ،
وقال :
لنفترض أن شخصًا ما على وشك تصفية قسم الفيزياء ويريد القيام بذلك وفقًا للقواعد. وفقًا للقواعد ، هذا هو أخذ عدد لا حصر له من مقاطع الفيديو حول ما يحدث في العالم ، وإطعام هذه الجيجابايت من البيانات إلى أكبر وأسرع جهاز كمبيوتر وإجراء تحليل إحصائي معقد - حسنًا ، أنت تفهم: Bayesian "ذهابًا وإيابًا" * - وستحصل على توقعات معينة حول ما الذي سيحدث خارج نافذتك في الواقع ، سوف تحصل على توقعات أفضل من تلك التي قدمتها كلية الفيزياء. حسنًا ، إذا تم تحديد النجاح من خلال مدى قربك من كتلة البيانات الخام الفوضوية ، فمن الأفضل القيام بذلك بدلاً من الطريقة التي يقوم بها الفيزيائيون: عدم إجراء تجارب فكرية على الأسطح المثالية ، وما إلى ذلك. لكنك لن تحصل على نوع من الفهم الذي سعى إليه العلم دائمًا. ما تحصل عليه هو مجرد فكرة تقريبية عما يحدث في الواقع.
* من احتمال بايز - تفسير لمفهوم الاحتمال ، والذي ، بدلاً من التكرار أو الميل إلى بعض الظواهر ، يتم تفسير الاحتمال كتوقع معقول ، يمثل تقييمًا كميًا لمعتقد شخصي أو حالة معرفة. يستخدم باحثو الذكاء الاصطناعي إحصائيات Bayesian في التعلم الآلي لمساعدة أجهزة الكمبيوتر في التعرف على الأنماط واتخاذ القرارات بناءً عليها.
أكد تشومسكي مرارًا وتكرارًا على هذه الفكرة: نجاح اليوم في معالجة اللغة الطبيعية ، أي دقة التنبؤ ، ليس علمًا. ووفقا له ، فإن رمي جزء كبير من النص في "آلة معقدة" هو مجرد تقريب البيانات الخام أو جمع الحشرات ، وهذا لن يؤدي إلى فهم حقيقي للغة.
وفقًا لتشومسكي ، فإن الهدف الرئيسي للعلم هو اكتشاف مبادئ توضيحية لكيفية عمل النظام بالفعل ، والنهج الصحيح لتحقيق هذا الهدف هو السماح للنظرية بتوجيه البيانات. من الضروري دراسة الطبيعة الأساسية للنظام عن طريق الاستخلاص من "الادراج غير الملائمة" بمساعدة تجارب مصممة بعناية ، وهذا هو ، بنفس الطريقة التي تم قبولها في العلم من وقت جاليليو.
في كلماته:
من غير المحتمل أن تقودك محاولة بسيطة للتعامل مع البيانات الفوضوية الخام إلى أي مكان ، تمامًا كما لن يؤدي جاليليو إلى أي مكان.
بعد ذلك ، استجاب نورويغ لمطالب تشومسكي في
مقال طويل . تلاحظ Norvig أنه في جميع مجالات تطبيق معالجة اللغة تقريبًا: محركات البحث والتعرف على الكلام والترجمة الآلية والإجابة على الأسئلة ، تسود النماذج الاحتمالية المدربة لأنها تعمل بشكل أفضل كثيرًا من الأدوات القديمة القائمة على القواعد النظرية أو المنطقية. يقول إن معيار تشومسكي للنجاح في العلوم - التركيز على السؤال "لماذا" وفهم أهمية "كيف" - هو خطأ.
مؤكدا موقفه ، يقتبس من ريتشارد فاينمان: "الفيزياء يمكن أن تتطور دون دليل ، لكن لا يمكننا أن نتطور دون حقائق". يتذكر نورويغ أن النماذج الاحتمالية تولد عدة تريليونات من الدولارات سنويًا ، في حين أن أحفاد نظرية تشومسكي يكسبون أقل بكثير من مليار ، نقلاً عن كتب تشومسكي المباعة على موقع أمازون.
يقترح نورويج أن ازدراء تشومسكي لـ "بايزي ذهابًا وإيابًا" يرجع إلى الانقسام بين
الثقافتين في النمذجة الإحصائية التي وصفها ليو بريمان:
- ثقافة نمذجة البيانات التي تفترض أن الطبيعة هي صندوق أسود حيث يتم توصيل المتغيرات بشكل عشوائي. يتمثل عمل خبراء النمذجة في تحديد النموذج الأنسب للجمعيات التي تقوم عليه.
- تنطوي ثقافة النمذجة الحسابية على أن الارتباطات في الصندوق الأسود معقدة للغاية بحيث لا يمكن وصفها باستخدام نموذج بسيط. يتمثل عمل مطوري النماذج في تحديد الخوارزمية التي تقوم بتقييم النتيجة على أفضل وجه باستخدام متغيرات الإدخال ، دون توقع إمكانية فهم الارتباطات الأساسية الحقيقية للمتغيرات داخل الصندوق الأسود.
يقترح نورويغ أن تشومسكي لا يتسم بالكثير من الجدل بالنماذج الاحتمالية على هذا النحو ، ولكنه لا يقبل النماذج الخوارزمية ذات "معلمات quadrillion": فهي ليست سهلة التفسير ، وبالتالي فهي غير مجدية في حل أسئلة "لماذا".
ينتمي Norwig و Breiman إلى معسكر آخر - حيث يعتقدون أن الأنظمة مثل اللغات معقدة للغاية وعشوائية وتعسفية بحيث لا يتم تمثيلها بمجموعة صغيرة من المعايير. والاستخلاص من الصعوبات يشبه صنع أداة باطنية إلى منطقة دائمة معينة غير موجودة بالفعل ، وبالتالي يتم تجاهل مسألة اللغة وكيف تعمل.
يؤكد نوريج أطروحته في
مقال آخر ، حيث يجادل بأنه يجب علينا التوقف عن التصرف مثل هدفنا هو خلق نظريات أنيقة للغاية. بدلاً من ذلك ، تحتاج إلى قبول التعقيد واستخدام أفضل حلفائنا - كفاءة البيانات غير المعقولة. ويشير إلى أنه في التعرف على الكلام ، والترجمة الآلية ، وجميع تطبيقات التعلم الآلي تقريبًا لبيانات الويب ، تعمل النماذج البسيطة مثل نماذج n-gram أو المصنفات الخطية القائمة على ملايين الوظائف المحددة بشكل أفضل من النماذج المعقدة. الذين يحاولون اكتشاف القواعد العامة.
إن أكثر ما يجذبني في هذا النقاش ليس هو ما يختلف معه تشومسكي ونورفيغ ، لكنهما متحدان. إنهم يوافقون على أن تحليل كميات هائلة من البيانات باستخدام طرق التدريب الإحصائي دون فهم المتغيرات يوفر تنبؤات أفضل من النهج النظري الذي يحاول نمذجة كيفية ارتباط المتغيرات ببعضها البعض.
وأنا لست الشخص الوحيد الذي يشعر بالحيرة من هذا: كثير من الأشخاص الذين لديهم خلفية رياضية والذين تحدثت معهم يجدون هذا التناقض أيضًا. ألا ينبغي أن يكون للنهج الأنسب لنمذجة العلاقات الهيكلية الأساسية أيضًا أكبر قوة تنبؤية؟ أو كيف يمكننا التنبؤ بدقة بشيء دون معرفة كيف يعمل كل شيء؟
توقعات ضد السببية
حتى في المجالات الأكاديمية ، مثل الاقتصاد والعلوم الاجتماعية الأخرى ، غالبًا ما يتم الجمع بين مفاهيم القوة التنبؤية والتوضيحية.
النماذج التي تظهر قدرة عالية على التفسير غالباً ما تعتبر تنبؤية للغاية. لكن النهج المتبع في بناء أفضل نموذج تنبؤي يختلف تمامًا عن النهج المتبع في بناء أفضل نموذج توضيحي ، وغالبًا ما تؤدي قرارات النمذجة إلى حلول وسط بين الهدفين. تم توضيح الاختلافات المنهجية في
مقدمة التعلم الإحصائي (ISL).
النمذجة التنبؤية
المبدأ الأساسي للنماذج التنبؤية بسيط نسبيًا: تقييم Y باستخدام مجموعة من بيانات الإدخال المتوفرة بسهولة X. إذا كان الخطأ X في المتوسط صفر ، فيمكن توقع Y باستخدام:
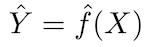
حيث ƒ هي المعلومات المنهجية حول Y المقدمة من X ، والتي تؤدي إلى Ŷ (التنبؤ بـ Y) ل X معين. عادة ما يكون الشكل الوظيفي الدقيق غير مهم إذا توقع Y ، و ƒ يُعتبر "الصندوق الأسود".
يمكن تقسيم دقة هذا النوع من النماذج إلى جزأين: خطأ قابل للاختزال وخطأ فادح:
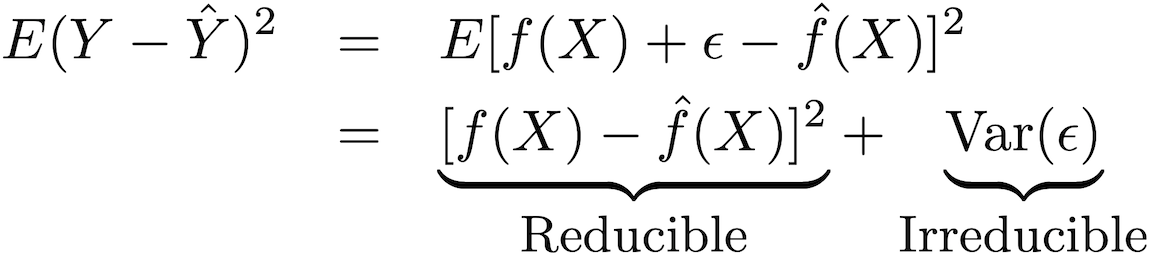
من أجل زيادة دقة التنبؤ بالنموذج ، من الضروري تقليل الخطأ القابل للتقليل إلى الحد الأدنى ، وذلك باستخدام أنسب أساليب التدريب الإحصائي للتقييم لتقييم
نمذجة الانتاج
لا يمكن اعتبار a "الصندوق الأسود" إذا كان الهدف هو فهم العلاقة بين X و Y (كيف يتغير Y كدالة لـ X). لأننا لا نستطيع تحديد تأثير X على Y دون معرفة الشكل الوظيفي ƒ.
دائمًا تقريبًا عند استخدام استنتاجات النمذجة ، يتم استخدام طرق حدودي لتقدير ƒ. يشير المعيار المعياري إلى كيفية تبسيط هذا النهج لتقدير ƒ من خلال أخذ الشكل المعياري ƒ وتقييم ƒ من خلال المعلمات المقترحة. هناك خطوتان رئيسيتان في هذا النهج:
1. قم بعمل افتراض حول الشكل الوظيفي ƒ. الافتراض الأكثر شيوعًا هو أن ƒ خطي في X:
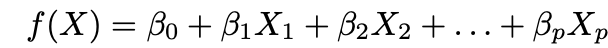
2. استخدم البيانات لتناسب النموذج ، أي ابحث عن قيم المعلمات β₀ و β₁ و ... و βp بحيث:
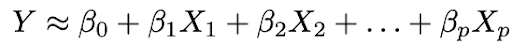
الطريقة الأكثر شيوعًا لتركيب النموذج هي طريقة المربعات الصغرى (OLS).
المفاضلة بين المرونة والتفسير
قد تتساءل بالفعل: كيف نعرف أن lin خطية؟ في الواقع ، لن نعرف ، لأن الشكل الحقيقي ƒ غير معروف. وإذا كان النموذج المحدد بعيدًا عن النموذج الحقيقي ƒ ، فستكون تقديراتنا منحازة. فلماذا نريد أن نضع هذا الافتراض في المقام الأول؟ لأن هناك حل وسط متأصل بين مرونة النموذج وقابلية التفسير.
تشير المرونة إلى مجموعة النماذج التي يمكن أن ينشئها النموذج لتناسب العديد من الأشكال الوظيفية المختلفة الممكنة ƒ. لذلك ، كلما كان النموذج أكثر مرونة ، كان يمكن أن يخلقه بشكل أفضل ، مما يزيد من دقة التنبؤ. لكن النموذج الأكثر مرونة هو أكثر تعقيدًا ويتطلب المزيد من المعلمات ليناسب ، وكثيراً ما تصبح التقديرات معقدة للغاية بحيث لا يمكن تفسير ارتباطات أي تنبئ فردي أو عوامل تنبؤية.
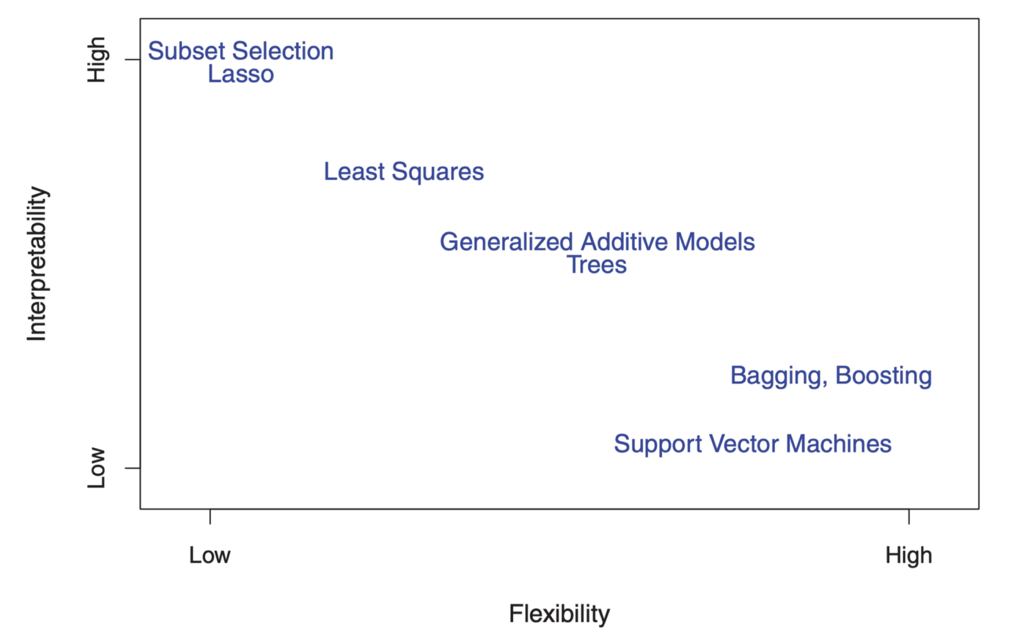
من ناحية أخرى ، فإن المعلمات في النموذج الخطي بسيطة نسبيًا ويمكن تفسيرها ، حتى لو لم ينفذ تنبؤًا دقيقًا جيدًا. فيما يلي رسم تخطيطي رائع في ISL يوضح هذه المقايضة في نماذج التدريب الإحصائي المختلفة:
"
"
كما ترون ، تتميز نماذج التعلم الآلي الأكثر مرونة مع دقة تنبؤ أفضل ، مثل طريقة متجه الدعم وطرق التحسين ، في نفس الوقت بضعف التفسير. يرفض نمذجة الاستدلال أيضًا دقة تنبؤ النموذج المفسر ، مما يجعل افتراضًا واثقًا حول النموذج الوظيفي f.
تحديد السببية والاستنتاج المضاد
لكن انتظر لحظة! حتى إذا كنت تستخدم نموذجًا مُفسرًا جيدًا ولاءً جيدًا ، فلا يزال يتعذر عليك استخدام هذه الإحصاءات كدليل منفصل على السببية. هذا هو بسبب القديم ، مبتذلة "العلاقة ليست السببية".
فيما يلي
مثال جيد : لنفترض أن لديك بيانات عن طول مائة من أعلام العلم وطول ظلالها وموقع الشمس. أنت تعلم أن طول الظل يتم تحديده بواسطة طول القطب وموقع الشمس ، ولكن حتى إذا قمت بتعيين طول القطب كمتغير تابع وطول الظل كمتغير مستقل ، فسيظل نموذجك يناسب المعاملات ذات الأهمية الإحصائية وما إلى ذلك.
لهذا السبب لا يمكن إقامة العلاقات السببية فقط من خلال النماذج الإحصائية وتتطلب معرفة أساسية - يجب تبرير العلاقة السببية المزعومة ببعض الفهم النظري الأولي للعلاقة. لذلك ، فإن تحليل البيانات والنمذجة الإحصائية لعلاقات السبب والنتيجة غالباً ما تستند إلى النماذج النظرية.
وحتى إذا كان لديك مبرر نظري جيد لقولك أن X تسبب Y ، فإن تحديد التأثير السببي لا يزال في كثير من الأحيان صعبًا للغاية. وذلك لأن تقييم العلاقة السببية ينطوي على تحديد ما يمكن أن يحدث في عالم معاكس لم يحدث فيه X ، وهو ما لا يمكن ملاحظته بحكم تعريفه.
فيما يلي
مثال جيد آخر : لنفترض أنك تريد تحديد الآثار الصحية لفيتامين C. هل لديك بيانات حول ما إذا كان شخص ما يأخذ الفيتامينات (X = 1 إذا كان يتناول ؛ 0 - لا يتناول) ، وبعض النتائج الصحية الثنائية (Y = 1 إذا كانت صحية ؛ 0 - ليست صحية) التي يشبه هذا:
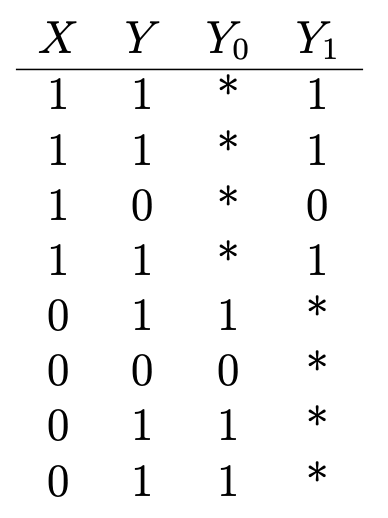
Y₁ هي النتيجة الصحية لأولئك الذين يتناولون فيتامين C ، و Y₀ هي النتيجة الصحية لأولئك الذين ليسوا كذلك. لتحديد تأثير فيتامين C على الصحة ، نقوم بتقييم متوسط تأثير العلاج:
ولكن من أجل القيام بذلك ، من المهم معرفة الآثار الصحية لأولئك الذين يتناولون فيتامين C إذا لم يتناولوا أي فيتامين C ، والعكس بالعكس (أو E (Y₀ | X = 1) و E (Y₁ | X = 0)) ، والتي يشار إليها بالنجمة في الجدول وتمثل نتائج عكسية غير ملحوظة. لا يمكن تقييم متوسط تأثير العلاج بالتتابع دون هذا الإدخال.
الآن تخيل أن الأشخاص الأصحاء بالفعل ، كقاعدة عامة ، يحاولون تناول فيتامين C ، لكن الأشخاص غير الصحيين لا يفعلون ذلك بالفعل. في هذا السيناريو ، ستُظهر التقييمات تأثيرًا قويًا على الشفاء ، حتى لو لم يؤثر فيتامين C فعليًا على الصحة على الإطلاق. هنا ، تُعرف الحالة الصحية السابقة بأنها عامل مختلط ، يؤثر على كل من تناول فيتامين C والصحة (X و Y) ، مما يؤدي إلى تقديرات مشوهة. تتمثل الطريقة الأكثر أمانًا للحصول على درجة ثابتة في جعل العلاج عشوائيًا من خلال التجربة بحيث لا تعتمد X على Y.
عندما يوصف العلاج بشكل عشوائي ، تصبح نتيجة عدم تلقي المجموعة للدواء ، في المتوسط ، مؤشرا موضوعيا للنتائج المضادة للمجموعة التي تتلقى العلاج وتضمن عدم وجود عامل مشوه. يسترشد اختبار A / B بهذا الفهم.
لكن التجارب العشوائية ليست ممكنة دائمًا (أو أخلاقية ، إذا أردنا دراسة الآثار الصحية للتدخين أو تناول الكثير من ملفات تعريف الارتباط الخاصة بشرائح الشوكولاتة) ، وفي هذه الحالات ، ينبغي تقدير الآثار السببية من الملاحظات التي تتم في كثير من الأحيان بمعالجة غير عشوائية.
هناك
العديد من الطرق الإحصائية التي تحدد التأثيرات السببية في الحالات غير التجريبية. يفعلون ذلك عن طريق بناء نتائج عكسية أو نمذجة الوصفات العشوائية للعلاج في بيانات الرصد.
من السهل أن نتخيل أن نتائج هذه الأنواع من التحليل غالبًا ما تكون غير موثوق بها أو قابلة للتكرار. والأهم من ذلك: لا تهدف هذه المستويات من العقبات المنهجية إلى تحسين دقة التنبؤ بالنموذج ، بل تقديم أدلة على السببية من خلال مزيج من الاستنتاجات المنطقية والإحصائية.
من الأسهل بكثير قياس نجاح النذير من النموذج السببي. على الرغم من وجود مؤشرات أداء قياسية لنماذج النذير ، إلا أنه من الصعب تقييم النجاح النسبي للنماذج السببية. ولكن إذا كان من الصعب تتبع السبب والنتيجة ، فهذا لا يعني أننا يجب أن نتوقف عن المحاولة.
النقطة الأساسية هنا هي أن النماذج النذير والسببية تخدم أغراضًا مختلفة تمامًا وتتطلب عمليات مختلفة تمامًا للبيانات والنمذجة الإحصائية ، وغالبًا ما يتعين علينا القيام بالأمرين معا.
يوضح
مثال من صناعة الأفلام : تستخدم الاستوديوهات نماذج التنبؤ للتنبؤ بإيرادات شباك التذاكر والتنبؤ بالنتائج المالية لتوزيع الأفلام وتقييم المخاطر المالية وربحية حافظة أفلامهم ، وما إلى ذلك. لكن نماذج التنبؤ لن تقربنا من فهم هيكل وديناميات سوق الأفلام ولن تساعد في صنع قرارات الاستثمار ، لأنه في المراحل المبكرة من عملية إنتاج الفيلم (عادة قبل سنوات من تاريخ الإصدار) ، عندما يتم اتخاذ قرارات الاستثمار ، يكون التباين ممكنًا النتائج عالية.
لذلك ، يتم تقليل دقة نماذج التنبؤ بناءً على البيانات الأولية في المراحل المبكرة. تقترب النماذج التنبؤية من تاريخ بدء توزيع الأفلام ، عندما تكون معظم قرارات الإنتاج قد اتخذت بالفعل ولم تعد التوقعات مجدية وملائمة بشكل خاص. من ناحية أخرى ، فإن نمذجة علاقات السبب والنتيجة تسمح للاستوديوهات باكتشاف كيف يمكن لخصائص الإنتاج المختلفة التأثير على الدخل المحتمل في المراحل المبكرة من إنتاج الفيلم ، وبالتالي فهي ضرورية للإبلاغ عن استراتيجيات إنتاجها.
زيادة الاهتمام بالتنبؤات: هل كان تشومسكي على حق؟
من السهل أن نفهم سبب غضب تشومسكي: تهيمن النماذج التشخيصية على المجتمع العلمي والصناعة. يوضح
التحليل النصي للنصوص الأكاديمية أن المجالات الأسرع نموًا في البحث الكمي تولي المزيد والمزيد من الاهتمام للتنبؤات. على سبيل المثال ، زاد عدد المقالات في مجال الذكاء الاصطناعي التي تشير إلى "التنبؤ" بأكثر من الضعف ، في حين انخفضت المقالات حول الاستنتاجات إلى النصف منذ عام 2013.
تتجاهل مناهج علم البيانات إلى حد كبير علاقات السبب والنتيجة. ويركز علم البيانات في الأعمال بشكل رئيسي على النماذج التنبؤية. تعتمد المسابقات الميدانية المرموقة مثل جائزة Kaggle و Netflix على تحسين مؤشرات الأداء التنبؤية.
من ناحية أخرى ، لا يزال هناك العديد من المجالات التي يتم فيها إيلاء الاهتمام الكافي للتنبؤ التجريبي ، ويمكنهم الاستفادة من الإنجازات التي تحققت في مجال التعلم الآلي والنمذجة التنبؤية. لكن عرض الحالة الراهنة على أنها حرب ثقافية بين "فريق تشومسكي" و "فريق نورفيج" غير صحيح: لا يوجد سبب يجعل من الضروري اختيار خيار واحد فقط ، لأن هناك العديد من الفرص للإثراء المتبادل بين الثقافتين. تم القيام بالكثير من العمل لجعل نماذج التعلم الآلي أكثر قابلية للفهم. على سبيل المثال ، تستخدم
سوزان آتي من جامعة ستانفورد أساليب التعلم الآلي في منهجية العلاقة السببية.
لإنهاء ملاحظة إيجابية ، تذكر
أعمال Jude Pearl . قاد بيرل مشروعًا بحثيًا حول الذكاء الاصطناعي في الثمانينيات ، والذي سمح للآلات بالتسبب الاحتمالي في استخدام شبكات بايز. ومع ذلك ، أصبح منذ ذلك الحين أكبر منتقدي لكيفية تحول انتباه الذكاء الاصطناعي حصريًا إلى الجمعيات والعلاقات الاحتمالية إلى عقبة أمام الإنجازات.
بتبادل رأي تشومسكي ،
يجادل بيرل بأن جميع الإنجازات المذهلة للتعلم العميق تتناسب مع منحنى البيانات. , ( ), 30 . , — « ».
, - , , — , , .
, - , , .
في واحدة من مقالاته يدعي:يتم تنظيم معظم المعرفة الإنسانية حول العلاقات السببية وليس الاحتمالية ، وقواعد حساب الاحتمال لا تكفي لفهم هذه العلاقات ... ولهذا السبب أعتبر نفسي نصف بايزي فقط.
يبدو أن علم البيانات لن يفوز إلا إذا كان لدينا المزيد من القضم.