
تتطور الشبكات العصبية في رؤية الكمبيوتر بشكل نشط ، ولا تزال العديد من المهام بعيدة عن الحل. للتوجه في مجال عملك ، ما عليك سوى اتباع المؤثرين على Twitter وقراءة المقالات ذات الصلة على arXiv.org. لكن أتيحت لنا الفرصة للذهاب إلى المؤتمر الدولي حول رؤية الكمبيوتر (ICCV) 2019. يعقد هذا العام في كوريا الجنوبية. الآن نريد مشاركتنا مع قراء هبر التي رأيناها وتعلمناها.
كان هناك الكثير منا من Yandex: وصل مطورو المركبات ، والباحثون ، والمشاركون في مهام السيرة الذاتية في الخدمات. لكننا نريد الآن تقديم وجهة نظر ذاتية إلى حد ما لفريقنا - مختبر الذكاء الآلي (Yandex MILAB). ربما نظر رجال آخرون إلى المؤتمر من زواياهم.
ماذا يفعل المختبر؟نقوم بمشاريع تجريبية متعلقة بتوليد الصور والموسيقى لأغراض الترفيه. نحن مهتمون بشكل خاص بالشبكات العصبية التي تسمح لك بتغيير المحتوى من المستخدم (للصورة تسمى هذه المهمة معالجة الصور).
مثال على نتيجة عملنا من مؤتمر YaC 2019.
يوجد الكثير من المؤتمرات العلمية ، لكن أبرز ما يسمى المؤتمرات A * تبرز منها ، حيث يتم نشر مقالات حول التقنيات الأكثر إثارة للاهتمام والأكثر أهمية. لا توجد قائمة محددة للمؤتمرات A * ، إليك مثال وغير مكتمل: NeurIPS (NIPS سابقًا) و ICML و SIGIR و WWW و WSDM و KDD و ACL و CVPR و ICCV و ECCV. آخر ثلاثة متخصصين في موضوع السيرة الذاتية.
ICCV في لمحة: ملصقات ، دروس ، ورش عمل ، مواقف
تم قبول 1075 ورقة في المؤتمر ، وكان المشاركون 7500. جاء 103 أشخاص من روسيا ، وكانت هناك مقالات من موظفي Yandex ، Skoltech ، Samsung AI Center Moscow وجامعة سامارا. في هذا العام ، لم يقم عدد كبير من الباحثين بزيارة ICCV ، ولكن هنا ، على سبيل المثال ، Alexey (Alyosha) Efros ، الذي يجمع دائمًا الكثير من الأشخاص:

في جميع هذه المؤتمرات ، يتم تقديم المقالات في شكل ملصقات (
المزيد عن التنسيق) ، ويتم تقديم الأفضل أيضًا في شكل تقارير قصيرة.
هنا جزء من العمل من روسيا في البرامج التعليمية ، يمكنك الانغماس في بعض المواد الدراسية ، فهي تشبه محاضرة في إحدى الجامعات. يقرأها شخص واحد ، عادةً دون التحدث عن أعمال محددة. مثال تعليمي رائع (
مايكل براون ، فهم اللون وخط أنابيب معالجة الصور في الكاميرا لرؤية الكمبيوتر ):

في ورش العمل ، على العكس ، يتحدثون عن المقالات. عادة ما يكون هذا هو العمل في بعض الموضوعات الضيقة ، أو القصص من قادة المختبرات حول جميع أعمال الطلاب الأخيرة ، أو المقالات التي لم يتم قبولها في المؤتمر الرئيسي.
الشركات الراعية تأتي إلى ICCV مع المدرجات. هذا العام ، وصلت Google و Facebook و Amazon والعديد من الشركات العالمية الأخرى ، بالإضافة إلى عدد كبير من الشركات الناشئة - الكورية والصينية. كان هناك خاصة العديد من الشركات الناشئة التي تتخصص في ترميز البيانات. هناك عروض في المدرجات ، يمكنك أن تأخذ البضائع وطرح الأسئلة. الشركات الراعية لها حفلات للصيد. إنهم قادرون على المضي قدماً إذا ما أقنعت شركات التوظيف أنك مهتم وأنه من المحتمل أن تتم مقابلتك. إذا نشرت مقالًا (أو علاوة على ذلك ، قدمت عرضًا تقديميًا معه) ، بدأت أو أنهيت درجة الدكتوراه - هذه إضافة ، ولكن في بعض الأحيان يمكنك الاتفاق على موقف ، وطرح أسئلة مهمة لمهندسي الشركة.
اتجاهات
يتيح لك المؤتمر إلقاء نظرة على منطقة السيرة الذاتية بأكملها. من خلال عدد ملصقات موضوع معين ، يمكنك تقييم مدى سخونة الموضوع. التسول بعض الاستنتاجات للكلمات الرئيسية:

طلقة واحدة ، طلقة واحدة ، طلقة واحدة ، خاضعة للإشراف الذاتي وشبه خاضعة للإشراف: طرق جديدة للمشاكل التي طالت دراستها
يتعلم الناس استخدام البيانات بشكل أكثر كفاءة. على سبيل المثال ، في
FUNIT ، يمكنك إنشاء تعبيرات الوجه للحيوانات التي لم تكن في مجموعة التدريب (تطبيق العديد من الصور المرجعية في التطبيق). تم تطوير أفكار Deep Image Prior ، ويمكن الآن تدريب شبكات
GAN في صورة واحدة - سنتحدث عن ذلك لاحقًا
في النقاط البارزة . يمكنك استخدام الإشراف الذاتي للتدريب المسبق (حل مشكلة يمكنك من خلالها تجميع البيانات المتوافقة ، على سبيل المثال ، للتنبؤ بزاوية تدوير الصورة) أو التعلم في الوقت نفسه من البيانات المحددة وغير المُعلمة. في هذا المعنى ، يمكن اعتبار تاج الخلق مقالة
S4L: التعلم تحت الإشراف الذاتي . لكن التدريب المسبق على ImageNet
لا يساعد
دائمًا .

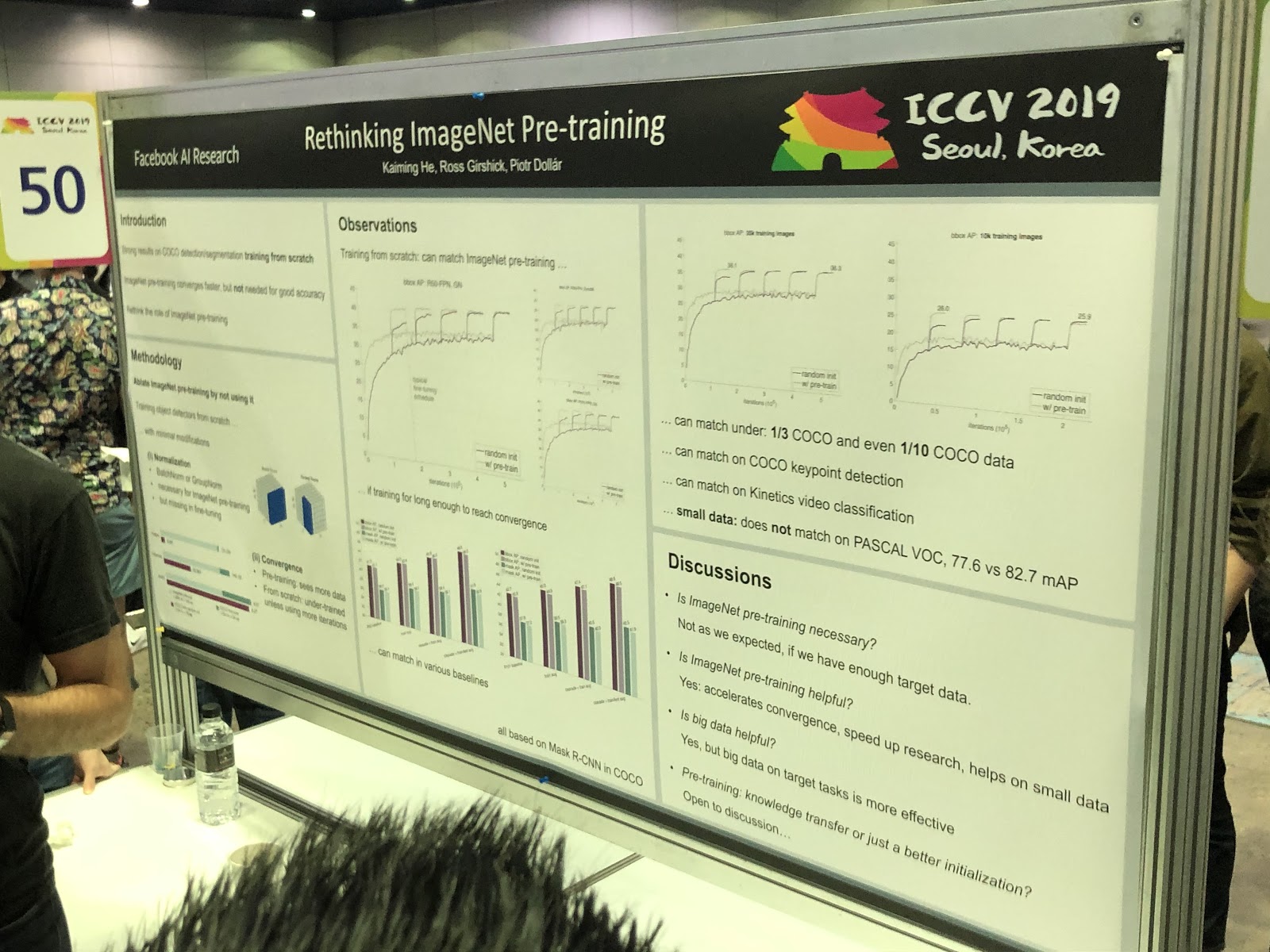
3D و 360 درجة
تتطلب المهام ، التي يتم حلها في الغالب للصور (تجزئة ، اكتشاف) ، إجراء أبحاث إضافية عن النماذج ثلاثية الأبعاد ومقاطع الفيديو البانورامية. رأينا العديد من المقالات حول تحويل RGB و
RGB-D إلى 3D. بعض المهام ، مثل تحديد وضع الشخص (تقدير الوضع) ، يتم حلها بشكل طبيعي إذا ذهبنا إلى نماذج ثلاثية الأبعاد. ولكن حتى الآن لا يوجد توافق في الآراء حول كيفية تمثيل النماذج ثلاثية الأبعاد بالضبط - في شكل شبكة ، أو سحابة من النقاط ، أو
voxels ، أو
SDF . إليك خيار آخر:
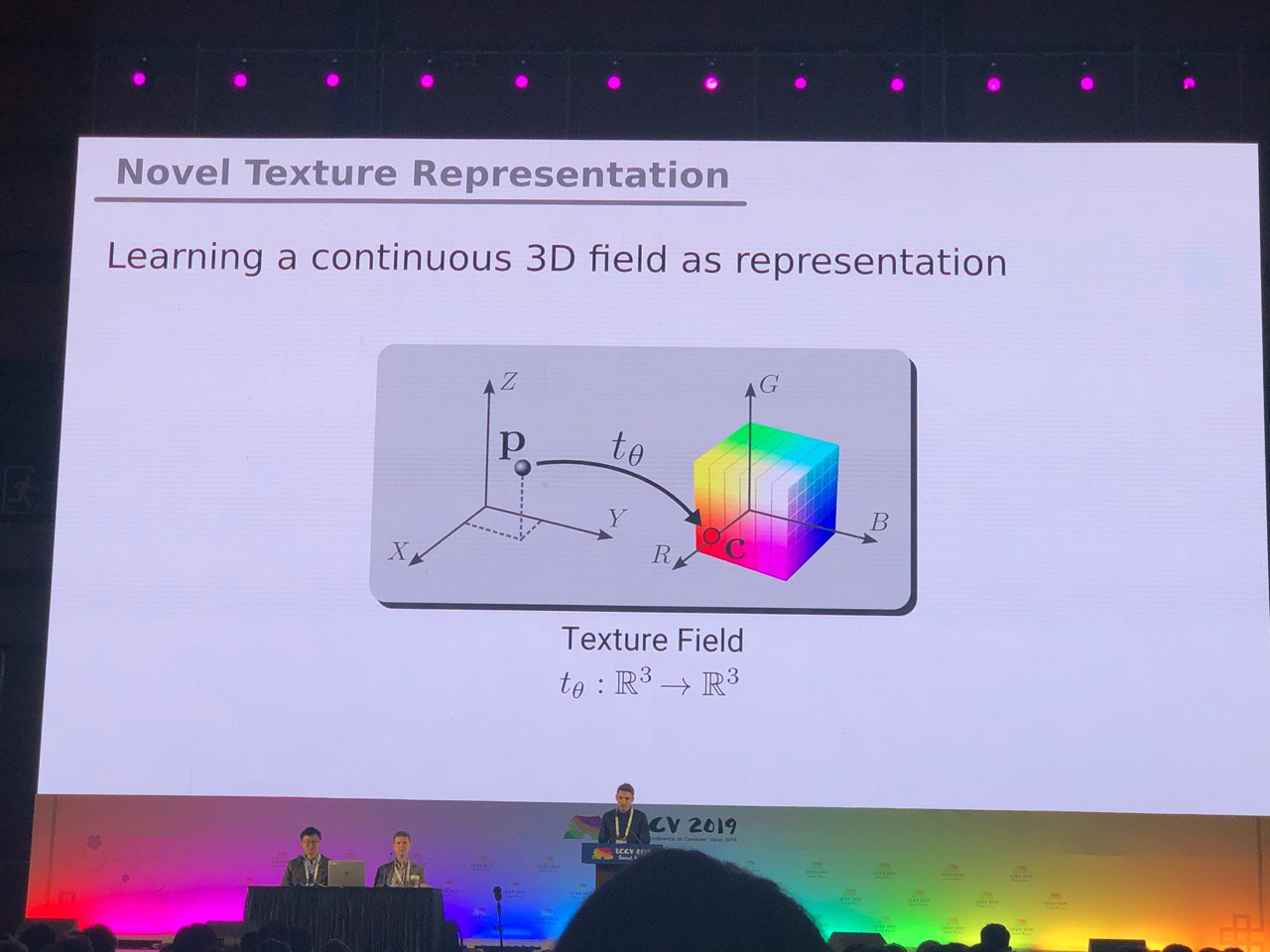
في الصور البانورامية ، تتطور الملتفة على الكرة بشكل نشط (انظر
الانقسام الدلالي المدرك للوجهة على كرات Icosahedron ) والبحث عن الكائنات الرئيسية في الإطار.
تعريف الموقف والتنبؤ بالحركات البشرية
من أجل تحديد الوضع في 2D ، هناك بالفعل نجاح - لقد تحول التركيز الآن نحو العمل مع عدة كاميرات وفي ثلاثي الأبعاد. على سبيل المثال ، يمكنك تحديد الهيكل العظمي عبر الحائط ، وتتبع التغييرات في إشارة Wi-Fi أثناء مرورها عبر جسم الإنسان.
تم القيام بالكثير من العمل في مجال الكشف عن نقاط اليد. ظهرت مجموعات بيانات جديدة ، بما في ذلك تلك القائمة على الفيديو مع حوارات شخصين - الآن يمكنك التنبؤ بالإيماءات اليدوية عن طريق الصوت أو نص المحادثة! تم إحراز نفس التقدم في مهام تقييم النظرات.

يمكنك أيضًا تسليط الضوء على مجموعة كبيرة من الأعمال المتعلقة
بتنبؤ الحركة البشرية (على سبيل المثال ،
Human Motion Prediction عبر Spatio-Temporal Inpainting أو
Structured Prediction يساعد 3D Human Motion Modeling ). المهمة مهمة ، وبناءً على المحادثات مع المؤلفين ، تُستخدم غالبًا لتحليل سلوك المشاة في القيادة المستقلة.
التعامل مع الناس في الصور ومقاطع الفيديو ، وغرف تركيب افتراضية
الاتجاه الرئيسي هو تغيير صور الوجه من حيث المعلمات تفسيرها. الأفكار:
deepfake على صورة واحدة ، وتغيير التعبير عن طريق تجسيد الوجه (
PuppetGAN ) ، وتغيير المعلمات بشكل
فوري (على سبيل المثال ،
العمر ). نقل أسلوب نقل من عنوان الموضوع إلى تطبيق العمل. قصة أخرى - غرف تركيب افتراضية ، تعمل بشكل سيء دائمًا ،
إليك مثال على العرض التوضيحي.


رسم / توليد الرسم البياني
أصبح تطوير فكرة "دع الشبكة تولد شيئًا بناءً على الخبرة السابقة" مختلفًا: "دعونا نوضح الشبكة التي تهمنا".
يسمح لك
SC-FEGAN بالقيام بصياغة إرشادية: يمكن للمستخدم رسم جزء من الوجه في المنطقة التي تمحى من الصورة والحصول على الصورة المستعادة وفقًا للعرض.

في واحدة من 25 مقالة Adobe لـ ICCV ، يتم الجمع بين GANs: واحد يرسم رسمًا للمستخدم ، والآخر يولد صورة واقعية للصورة من المخطط (
صفحة المشروع ).

في وقت سابق من جيل الصور الرسومية لم تكن هناك حاجة ، ولكن الآن أنها أصبحت حاوية من المعرفة حول المشهد. مُنحت جائزة ICCV Best Paper Honorable Mentions أيضًا للمقال الذي
يحدد سمات الكائن والعلاقات في إنشاء مشهد تفاعلي . بشكل عام ، يمكنك استخدامها بطرق مختلفة: إنشاء الرسوم البيانية من الصور ، أو الصور والنصوص من الرسوم البيانية.
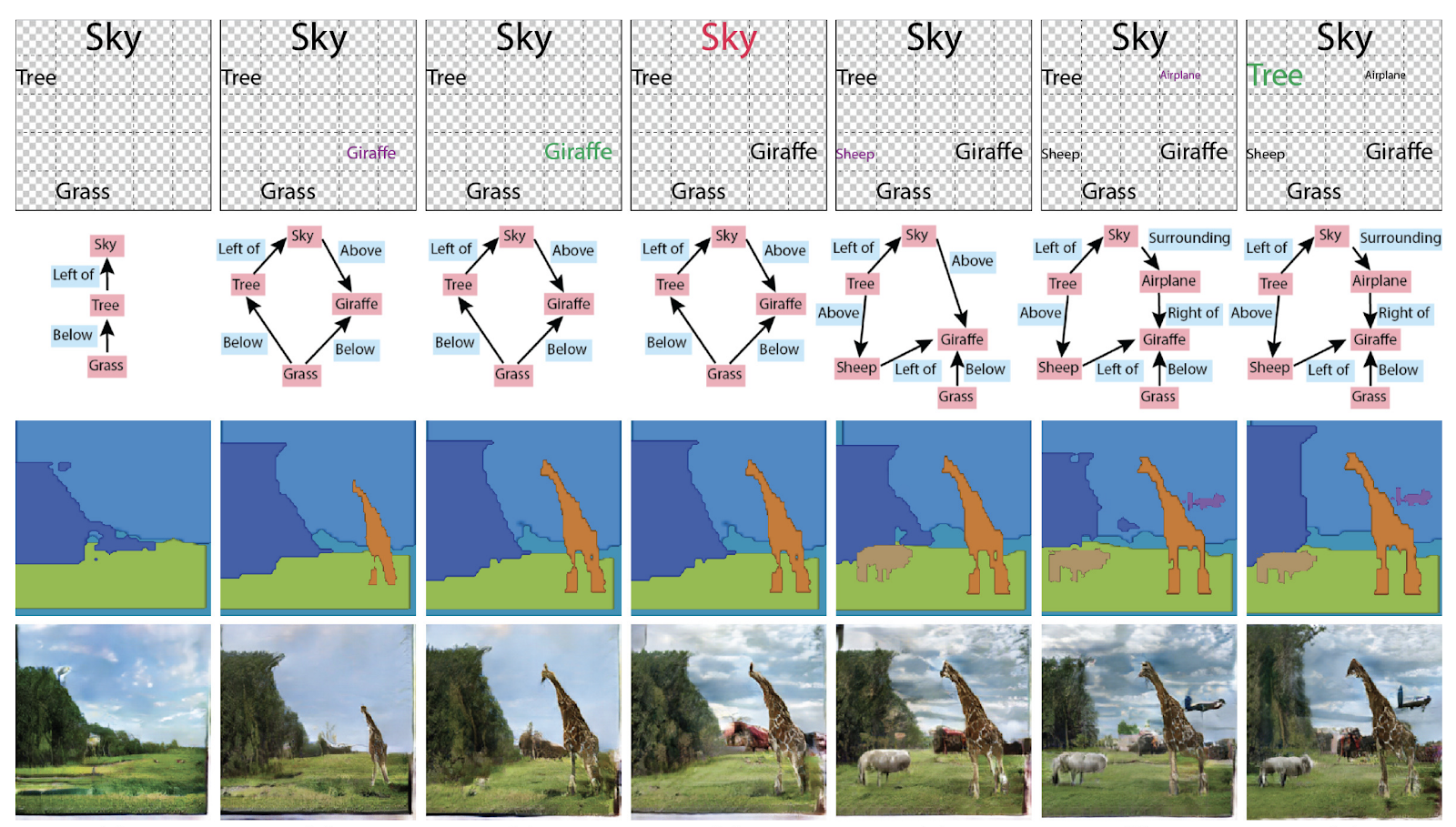
إعادة تحديد الأشخاص والآلات ، مع حساب عدد الحشود (!)
تكرس العديد من المقالات لتتبع الناس وإعادة
تحديد الأشخاص والآلات. ولكن ما فاجأنا كان مجموعة من المقالات حول عد الناس في حشد ، وجميعهم من الصين.
لكن فيسبوك ، على العكس من ذلك ، يكشف عن هويته. علاوة على ذلك ، فإنه يقوم بذلك بطريقة مثيرة للاهتمام: إنه يعلم الشبكة العصبية إنشاء وجه بدون تفاصيل فريدة - متشابهة ، ولكن ليس كثيرًا بحيث يتم اكتشافها بشكل صحيح بواسطة أنظمة التعرف على الوجه.

حماية هجوم الخصم
مع تطور تطبيقات رؤية الكمبيوتر في العالم الحقيقي (في المركبات غير المأهولة ، في التعرف على الوجوه) ، فإن مسألة موثوقية مثل هذه الأنظمة تظهر في كثير من الأحيان. للاستفادة الكاملة من السيرة الذاتية ، يجب عليك التأكد من أن النظام مقاوم للهجمات العدائية - وبالتالي لم تكن هناك مقالات عن الحماية ضدهم أقل من الهجمات نفسها. كان هناك الكثير من العمل حول شرح تنبؤات الشبكة (خريطة الملاءمة) وقياس الثقة في النتيجة.
المهام مجتمعة
في معظم المهام ذات هدف واحد ، تكون إمكانيات تحسين الجودة مستنفدة تقريبًا ؛ ومن المجالات الجديدة لزيادة نمو الجودة تعليم الشبكات العصبية لحل العديد من المشكلات المشابهة في نفس الوقت. الأمثلة على ذلك:
- التنبؤ بالإجراءات + التنبؤ بالتدفق البصري ،
- عرض الفيديو + تمثيل اللغة (
VideoBERT ) ،
-
فائقة الدقة + HDR .
وكانت هناك مقالات عن تجزئة ، وتحديد الموقف وإعادة تحديد الهوية للحيوانات!

تسليط الضوء
كانت جميع المقالات تقريبًا معروفة مسبقًا ، وكان النص متاحًا على arXiv.org. لذلك ، يبدو عرض أعمال مثل "Everybody Dance Now" و "FUNIT" و "Image2StyleGAN" غريبًا إلى حد ما - فهذه أعمال مفيدة للغاية ولكنها ليست جديدة على الإطلاق. يبدو أن العملية الكلاسيكية للنشر العلمي تفشل هنا - العلم يتطور بسرعة كبيرة.
من الصعب جدًا تحديد أفضل الأعمال - فهناك العديد منها ، والموضوعات مختلفة. تلقت عدة مقالات
الجوائز والمراجع .
نريد تسليط الضوء على الأعمال المثيرة للاهتمام من حيث معالجة الصور ، لأن هذا هو موضوعنا. لقد اتضح أنها جديدة ومثيرة للاهتمام بالنسبة لنا (لا ندعي أنها موضوعية).
SinGAN (جائزة أفضل ورقة) و InGAN
SinGAN:
صفحة المشروع ،
arXiv ،
الكود .
InGAN:
صفحة المشروع ،
arXiv ،
الكود .
تطوير فكرة Deep Image Prior بواسطة ديمتري أوليانوف وأندريا فيدالي وفيكتور ليمبيتسكي. بدلاً من تدريب GAN على مجموعة بيانات ، تتعلم الشبكات من أجزاء من نفس الصورة لتتذكر الإحصائيات الموجودة بداخلها. تسمح لك الشبكة المدربة بتحرير وتحريك الصور (SinGAN) أو إنشاء صور جديدة من أي حجم من قوام الصورة الأصلية ، مع الحفاظ على البنية المحلية (InGAN).
SinGAN:

InGAN:

رؤية ما لا يمكن لـ GAN توليده
صفحة المشروع .
غالباً ما تتلقى الشبكات العصبية المولدة للصور متجه ضوضاء عشوائي كمدخل. في شبكة مدربة ، تشكل العديد من متجهات الإدخال مسافة صغيرة وحركات صغيرة تؤدي إلى حدوث تغييرات صغيرة في الصورة. باستخدام التحسين ، يمكنك حل المشكلة العكسية: العثور على ناقل إدخال مناسب لصورة من العالم الحقيقي. يوضح المؤلف أنه يكاد يكون من غير الممكن العثور على صورة مطابقة تمامًا في شبكة عصبية أبدًا. لا يتم إنشاء بعض الكائنات في الصورة (على ما يبدو ، بسبب التباين الكبير لهذه الكائنات).
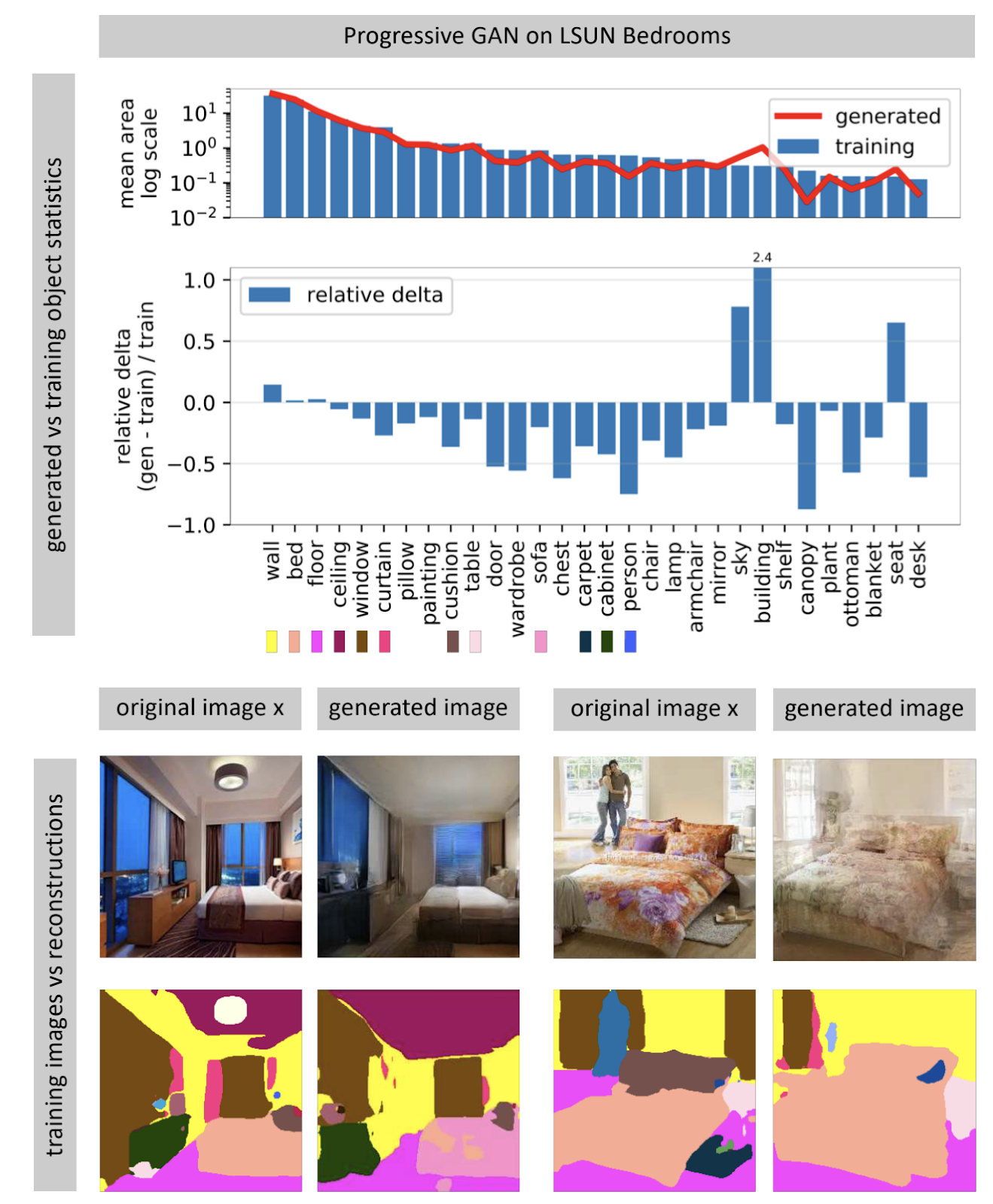
يفترض المؤلف أن GAN لا تغطي كامل مساحة الصور ، ولكن فقط بعض المجموعات الفرعية المحشوة بالثقوب ، مثل الجبن. عندما نحاول العثور على صور من العالم الحقيقي فيها ، سنفشل دائمًا ، لأن شبكة GAN لا تزال تنشئ صورًا غير حقيقية تمامًا. يمكنك التغلب على الاختلافات بين الصور الحقيقية والصور التي تم إنشاؤها فقط عن طريق تغيير وزن الشبكة ، أي إعادة تدريبها على صورة معينة.

عندما تتم إعادة تدريب الشبكة للحصول على صورة معينة ، يمكنك محاولة تنفيذ العديد من التلاعب بهذه الصورة. في المثال أدناه ، تمت إضافة نافذة إلى الصورة ، كما أن الشبكة قد أحدثت انعكاسات على مجموعة المطبخ. هذا يعني أن الشبكة بعد إعادة التدريب للتصوير الفوتوغرافي لم تفقد القدرة على رؤية العلاقة بين كائنات المشهد.

تحليل: نحو التعاريف البصرية لخصائص الصورة المعرفية
صفحة المشروع ،
arXiv .
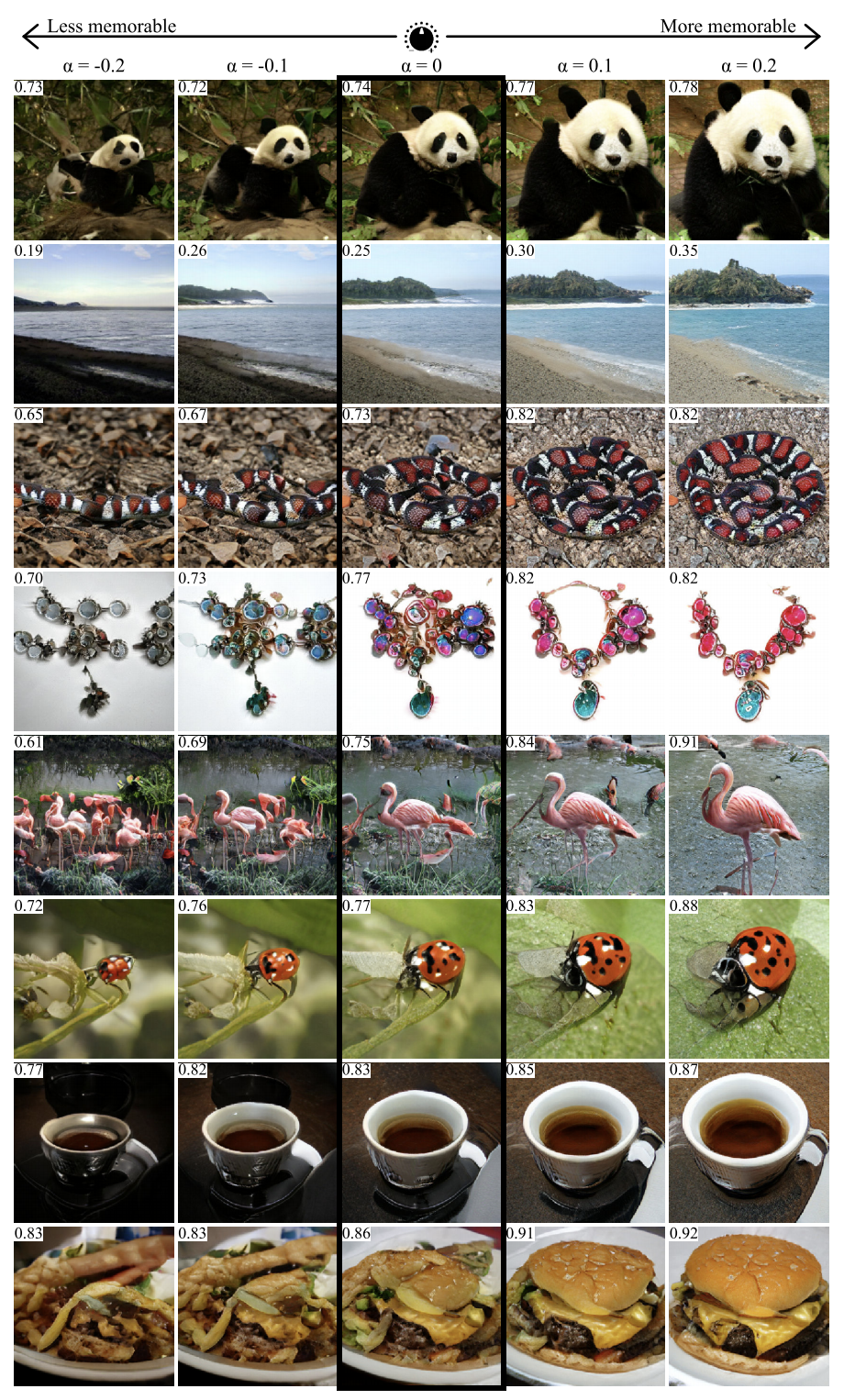
باستخدام النهج من هذا العمل ، يمكنك تصور وتحليل ما تعلمته الشبكة العصبية. يقترح المؤلفون تدريب GAN على إنشاء صور ستنشئ الشبكة لها تنبؤات معينة. تم استخدام العديد من الشبكات كأمثلة في المقالة ، بما في ذلك MemNet ، التي تتنبأ بتذكر الصور. اتضح أنه لتحسين التذكر ، يجب أن يكون الكائن في الصورة:
- كن أقرب إلى المركز
- لها شكل دائري أو مربع وهيكل بسيط ،
- يكون على خلفية موحدة ،
- تحتوي على عيون معبرة (على الأقل لصور الكلاب) ،
- أن تكون أكثر إشراقا ، وأكثر ثراء ، في بعض الحالات - أكثر احمرارا.
Liquid Warping GAN: إطار موحد لتقليد الحركة البشرية ونقل المظهر وتوليف الرؤية الجديدة
صفحة المشروع ،
arXiv ،
رمز .
خط أنابيب لتوليد صور لأشخاص من صورة واحدة. يعرض المؤلفون أمثلة ناجحة على نقل حركة شخص إلى آخر ، ونقل الملابس بين الناس وتوليد وجهات نظر جديدة للشخص - كل ذلك من صورة واحدة. على عكس الأعمال السابقة ، هنا ، لتهيئة الظروف ، لا يتم استخدام النقاط الرئيسية في 2D (تشكل) ، ولكن شبكة ثلاثية الأبعاد من الجسم (تشكل + شكل). اكتشف المؤلفون أيضًا كيفية نقل المعلومات من الصورة الأصلية إلى الصورة الناتجة (Liquid Warping Block). تبدو النتائج مناسبة ، لكن دقة الصورة الناتجة هي فقط 256 × 256. للمقارنة ، فإن vid2vid ، التي ظهرت قبل عام ، قادرة على توليد دقة 2048 × 1024 ، ولكنها تحتاج إلى ما يصل إلى 10 دقائق من تصوير الفيديو مثل مجموعة البيانات.

FSGAN: موضوع مبادج للوجه وإعادة تشريعه
صفحة المشروع ،
arXiv .
في البداية يبدو أنه لا يوجد شيء غير معتاد: deepfake بجودة طبيعية أكثر أو أقل. لكن الإنجاز الرئيسي للعمل هو استبدال الوجوه في صورة واحدة. على عكس الأعمال السابقة ، كان التدريب مطلوبًا على مجموعة متنوعة من الصور الفوتوغرافية لشخص معين. تحول خط الأنابيب إلى أن يكون مرهقًا (إعادة التشريح والتجزئة ، عرض الاستيفاء ، التعرق ، المزج) ومع وجود الكثير من الاختراقات التقنية ، لكن النتيجة تستحق العناء.

اكتشاف ما هو غير متوقع عن طريق إعادة تكوين الصورة
arXiv .
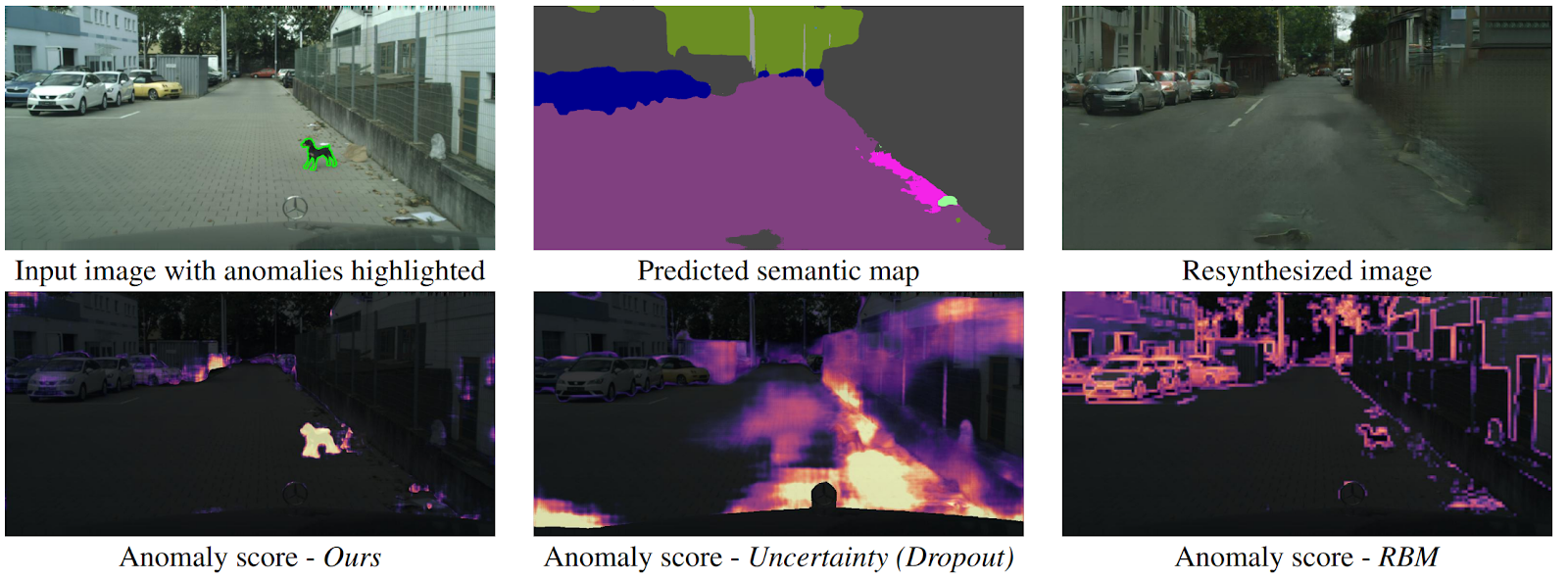
كيف يمكن للطائرة بدون طيار أن تفهم أن جسمًا ظهر فجأة أمامه ولا يقع في أي فئة من فئات الدلالات؟ هناك عدة طرق ، لكن المؤلفين يقدمون خوارزمية جديدة بديهية تعمل بشكل أفضل من سابقاتها. يتم التنبؤ بالتقسيم الدلالي من صورة إدخال الطريق. يتم إدخاله في GAN (pix2pixHD) ، الذي يحاول استعادة الصورة الأصلية فقط من الخريطة الدلالية. تختلف الحالات الشاذة التي لا تقع في أي من القطاعات بشكل كبير في المصدر والصورة التي تم إنشاؤها. ثم يتم إرسال ثلاث صور (أولية ، تجزئة وإعادة بنائها) إلى شبكة أخرى ، والتي تتوقع الشذوذ. تم إنشاء مجموعة البيانات الخاصة بذلك من مجموعة بيانات Cityscapes المعروفة ، والتي تم تغييرها عن طريق الخطأ في الفصل الدلالي. ومن المثير للاهتمام ، في هذا الإعداد ، أن الكلب الذي يقف في منتصف الطريق ، ولكنه مجزأ بشكل صحيح (مما يعني وجود فئة له) ، ليس أمرًا شاذًا ، نظرًا لأن النظام كان قادرًا على التعرف عليه.
استنتاج
قبل المؤتمر ، من المهم معرفة ماهية اهتماماتك العلمية وما هي الخطب التي أود الوصول إليها ومع من تتحدث. ثم كل شيء سيكون أكثر إنتاجية.
ICCV هو الشبكات في المقام الأول. أنت تفهم أن هناك أفضل المؤسسات وكبار العلماء ، وتبدأ في فهم ذلك ، للتعرف على الناس. ويمكنك قراءة مقالات حول arXiv - وبالمناسبة ، من الرائع جدًا أنه لا يمكنك الذهاب إلى أي مكان لمعرفة.
بالإضافة إلى ذلك ، في المؤتمر ، يمكنك الغوص بعمق في الموضوعات غير القريبة منك ، راجع الاتجاهات. حسنًا ، اكتب قائمة بالمقالات المراد قراءتها. إذا كنت طالبًا ، فهذه فرصة لك للتعرف على عالم محتمل ، إذا كنت من الصناعة ، ثم مع صاحب عمل جديد ، وإذا كانت الشركة ، فقم بإظهار نفسك.
اشترك في
loss_function_porn ! هذا مشروع شخصي: نحن مع
karfly . كل الأعمال التي
أحببناها خلال المؤتمر ، نشرنا هنا:
@ loss_function_live .