
في
مقال سابق ، درسنا تجميع RabbitMQ للتسامح مع الخطأ وتوافر عالية. الآن دعنا نحفر بعمق في أباتشي كافكا.
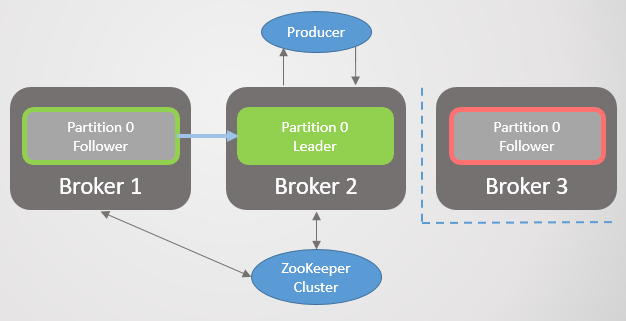
هنا ، وحدة النسخ المتماثل هي قسم. كل موضوع له قسم واحد أو أكثر. كل قسم لديه زعيم مع أو بدون أتباع. عند إنشاء موضوع ، تتم الإشارة إلى عدد الأقسام ومعدل النسخ المتماثل. القيمة المعتادة هي 3 ، مما يعني ثلاث ملاحظات: قائد واحد واثنين من المتابعين.
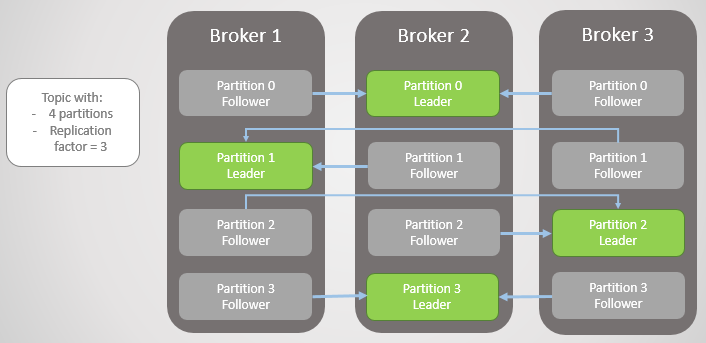 التين. 1. يتم توزيع أربعة أقسام بين ثلاثة وسطاء
التين. 1. يتم توزيع أربعة أقسام بين ثلاثة وسطاءجميع طلبات القراءة والكتابة تذهب إلى القائد. يقوم المتابعين بإرسال طلبات إلى القائد بشكل دوري لتلقي أحدث الرسائل. لا يلجأ المستهلكون أبدًا إلى المتابعين ، فالأخير موجود فقط للتكرار والتسامح مع الخطأ.

فشل القسم
عندما يسقط الوسيط ، يفشل قادة العديد من الأقسام. في كل واحد منهم ، يصبح التابع من عقدة أخرى هو الزعيم. في الواقع ، ليست هذه هي الحالة دائمًا ، نظرًا لأن عامل المزامنة يؤثر أيضًا على ما إذا كان هناك متابعين متزامنين ، وإذا لم يكن الأمر كذلك ، فإن الانتقال إلى نسخة متماثلة غير متزامنة مسموح به. لكن في الوقت الحالي ، دعونا لا نعقّد ذلك.
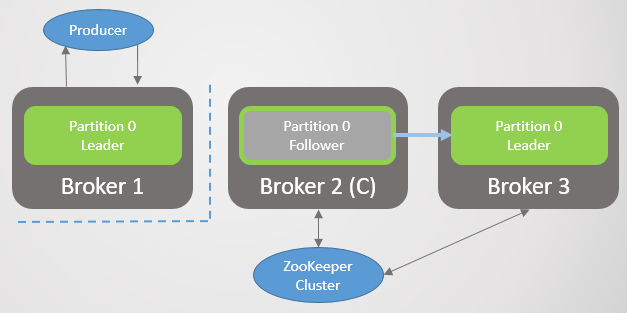
يغادر الوسيط 3 الشبكة - وبالنسبة للقسم 2 ، يتم انتخاب قائد جديد للوسيط 2.
 التين. 2. وفاة الوسيط 3 وانتخاب أتباعه على الوسيط 2 كقائد جديد للقسم 2
التين. 2. وفاة الوسيط 3 وانتخاب أتباعه على الوسيط 2 كقائد جديد للقسم 2ثم يغادر وسيط 1 ويخسر القسم 1 أيضًا قائده ، الذي يذهب دوره للوسيط 2.
 التين. 3. لا يوجد سوى وسيط واحد اليسار. جميع القادة على نفس وسيط التكرار صفر.
التين. 3. لا يوجد سوى وسيط واحد اليسار. جميع القادة على نفس وسيط التكرار صفر.عندما يعود الوسيط 1 إلى الشبكة ، يضيف أربعة متابعين ، مما يوفر بعض التكرار لكل قسم. لكن كل القادة ظلوا في الوسيط 2.
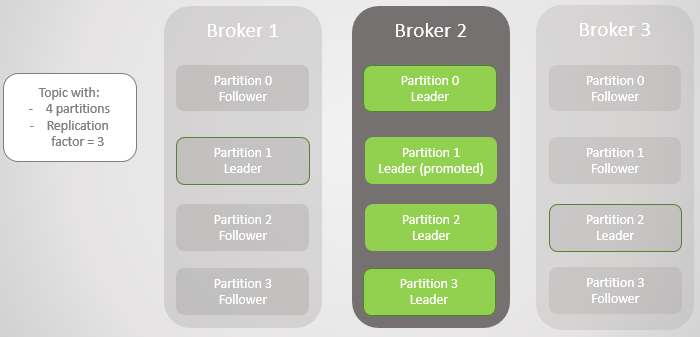
 التين. 4. يبقى القادة على وسيط 2
التين. 4. يبقى القادة على وسيط 2عندما يرتفع الوسيط 3 ، نعود إلى ثلاث نسخ متماثلة لكل قسم. ولكن جميع القادة لا يزالون على وسيط 2.
 التين. 5. وضع غير متوازن للقادة بعد استعادة الوسطاء 1 و 3
التين. 5. وضع غير متوازن للقادة بعد استعادة الوسطاء 1 و 3كافكا لديه أداة لقادة إعادة التوازن أفضل من RabbitMQ. هناك ، كان عليك استخدام مكون إضافي أو برنامج نصي تابع لجهة أخرى غير السياسات الخاصة بترحيل العقدة الرئيسية عن طريق تقليل التكرار أثناء الترحيل. بالإضافة إلى ذلك ، كان على طوابير كبيرة لتحمل صعوبة الوصول إليها أثناء التزامن.
لدى كافكا مفهوم "الإشارات المفضلة" لدور القيادة. عندما يتم إنشاء أقسام الموضوع ، يحاول كافكا توزيع القادة بالتساوي عبر العقد ويميز هؤلاء القادة الأوائل على أنهم الأفضل. بمرور الوقت ، بسبب إعادة تشغيل الخادم ، وفشل ، وفشل الاتصال ، قد ينتهي القادة في العقد الأخرى ، كما في الحالة القصوى الموصوفة أعلاه.
لإصلاح ذلك ، يقدم Kafka خيارين:
- يتيح الخيار auto.leader.rebalance.enable = true لعقدة التحكم إعادة تعيين القادة تلقائيًا إلى النسخ المتماثلة المفضلة ومن ثم استعادة التوزيع الموحد.
- يمكن للمسؤول تشغيل البرنامج النصي kafka-preferred-replica-election.sh لإعادة التعيين يدويًا.
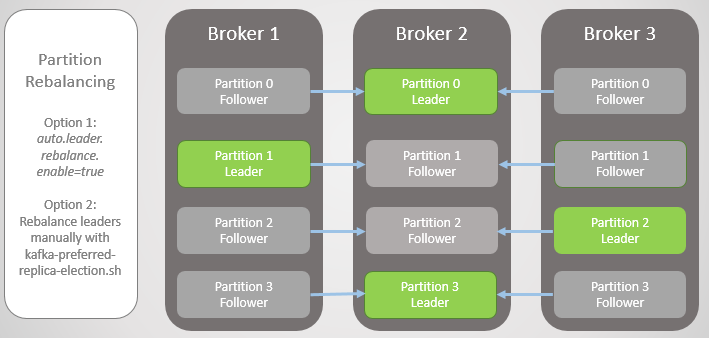 التين. 6. النسخ المتماثلة بعد إعادة التوازن
التين. 6. النسخ المتماثلة بعد إعادة التوازنلقد كانت نسخة مبسطة من الفشل ، ولكن الواقع أكثر تعقيدًا ، رغم أنه لا يوجد شيء معقد للغاية هنا. كل ذلك يأتي إلى النسخ المتماثلة المتزامنة (النسخ المتماثلة في المزامنة ، ISR).
النسخ المتماثلة المتزامنة (ISR)
ISR عبارة عن مجموعة من النسخ المتماثلة لقسم يعتبر "متزامن" (متزامن). هناك قائد ، لكن قد لا يكون هناك متابعون. يعتبر متابعا متزامنا إذا قام بعمل نسخ دقيقة لجميع رسائل القائد قبل انتهاء الفاصل الزمني
replica.lag.time.max.ms .
تتم إزالة التابع من مجموعة ISR إذا:
- لم تقدم طلبًا لأخذ عينات للنسخة المتماثلة للفاصل الزمني. lag.time.max.ms (تعتبر ميتة)
- لم يكن لديك الوقت لتحديث النسخة المتماثلة الفاصل الزمني. lag.time.max.ms (تعتبر بطيئة)
يقدم المتابعون طلبات جلب في الفاصل الزمني
replica.fetch.wait.max.ms ، والذي يكون افتراضيًا هو 500 مللي ثانية.
لتوضيح الغرض من ISR بوضوح ، تحتاج إلى إلقاء نظرة على التأكيدات من المنتج (المنتج) وبعض سيناريوهات الفشل. يمكن للمنتجين الاختيار عندما يرسل وسيط تأكيدًا:
- aks = 0 ، لا يتم إرسال التأكيد
- acks = 1 ، يتم إرسال التأكيد بعد أن كتب القائد رسالة إلى سجله المحلي
- acks = الكل ، يتم إرسال التأكيد بعد أن كتبت جميع النسخ المتماثلة في ISR رسالة إلى السجلات المحلية
في مصطلحات كافكا ، إذا كان ISR قد أنقذ الرسالة ، فهو "ملتزم". أكس = كل شيء هو الخيار الأكثر أمانا ، ولكن أيضا تأخير إضافي. دعونا نلقي نظرة على مثالين للفشل وكيف تتفاعل خيارات "aks" المختلفة مع مفهوم ISR.
أكس = 1 و ISR
في هذا المثال ، سنرى أنه في حالة عدم انتظار القائد حتى يتم حفظ كل رسالة من جميع المتابعين ، في حالة فشل القائد ، قد يتم فقد البيانات. يمكن تمكين أو تعطيل الانتقال إلى متابع غير متزامن من خلال تعيين
unclean.leader.election.enable .
في هذا المثال ، تم ضبط الشركة المصنعة على acks = 1. يتم توزيع القسم على جميع الوسطاء الثلاثة. الوسيط 3 متخلف ، تزامن مع القائد قبل ثماني ثوان ، وهو الآن متخلفًا عن طريق 7456 رسالة. الوسيط 1 هو وراء ثانية واحدة فقط. يرسل منتجنا رسالة ويتلقى بسرعة عودة ، دون النفقات العامة للتابعين البطيئين أو القتلى الذين لا يتوقعهم الزعيم.
 التين. 7. ISR مع ثلاثة النسخ المتماثلة
التين. 7. ISR مع ثلاثة النسخ المتماثلةفشل الوسيط 2 ، وتتلقى الشركة المصنعة خطأ في الاتصال. بعد انتقال القيادة إلى وسيط 1 ، نفقد 123 رسالة. كان تابع الوسيط 1 جزءًا من ISR ، لكنه لم يتزامن تمامًا مع القائد عندما سقط.
 التين. 8. عند الفشل ، يتم فقد الرسائل
التين. 8. عند الفشل ، يتم فقد الرسائلفي تكوين
bootstrap.servers ، يسرد الصانع العديد من الوسطاء ، ويمكنه أن يسأل وسيطًا آخر أصبح القائد الجديد للقسم. ثم يقوم بإنشاء اتصال مع وسيط 1 ويستمر في إرسال الرسائل.
 التين. 9. إرسال الرسائل يستأنف بعد استراحة قصيرة
التين. 9. إرسال الرسائل يستأنف بعد استراحة قصيرةوسيط 3 يتخلف أكثر من ذلك. يجعل طلبات جلب ، ولكن لا يمكن مزامنتها. قد يكون هذا بسبب اتصال الشبكة البطيء بين السماسرة ومشكلة التخزين وما إلى ذلك. تتم إزالته من ISR. الآن ISR يتكون من نسخة واحدة - القائد! تواصل الشركة المصنعة إرسال الرسائل وتلقي التأكيد.
 التين. 10. تتم إزالة التابع على وسيط 3 من ISR
التين. 10. تتم إزالة التابع على وسيط 3 من ISRالسمسار 1 يسقط ، ودور القائد يذهب إلى الوسيط 3 بخسارة 15286 رسالة! تتلقى الشركة المصنعة رسالة خطأ اتصال. كان الذهاب إلى الزعيم خارج ISR ممكنًا فقط بسبب الإعداد
unclean.leader.election.enable = true . إذا تم ضبطه على "
خطأ" ، فلن يكون الانتقال قد حدث ، وسيتم رفض جميع طلبات القراءة والكتابة. في هذه الحالة ، ننتظر عودة الوسيط 1 ببياناته التي لم تمسها في النسخة المتماثلة ، والتي ستتولى القيادة مرة أخرى.
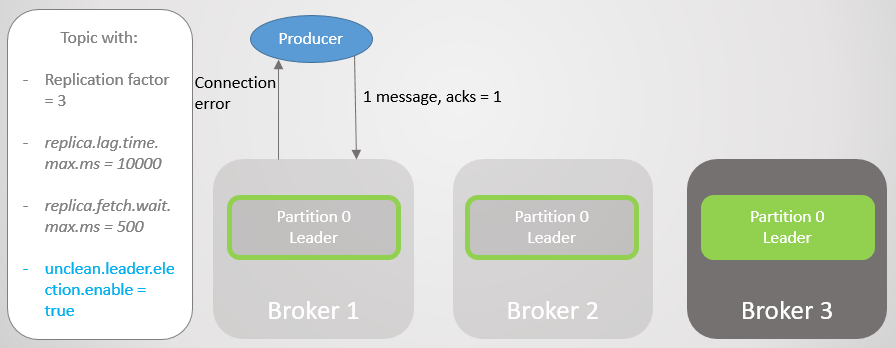 التين. 11. الوسيط 1 قطرات. في حالة حدوث فشل ، يتم فقد عدد كبير من الرسائل
التين. 11. الوسيط 1 قطرات. في حالة حدوث فشل ، يتم فقد عدد كبير من الرسائلتقوم الشركة المصنعة بتأسيس اتصال مع آخر وسيط وترى أنه هو الآن قائد القسم. يبدأ بإرسال رسائل إلى وسيط 3.
 التين. 12. بعد استراحة قصيرة ، يتم إرسال الرسائل مرة أخرى إلى القسم 0
التين. 12. بعد استراحة قصيرة ، يتم إرسال الرسائل مرة أخرى إلى القسم 0لقد رأينا أنه بالإضافة إلى الانقطاعات القصيرة لإقامة اتصالات جديدة والبحث عن قائد جديد ، فإن الشركة المصنعة ترسل الرسائل باستمرار. يوفر هذا التكوين إمكانية الوصول من خلال التناسق (أمان البيانات). كافكا فقدت الآلاف من الرسائل ، لكنها استمرت في قبول إدخالات جديدة.
أكس = الكل و ISR
دعنا نكرر هذا السيناريو مرة أخرى ، ولكن مع
acks = الكل . تأخير وسيط 3 بمعدل أربع ثوان. يرسل الصانع رسالة مع
acks = الكل ، والآن لا يتلقى استجابة سريعة. ينتظر القائد حتى تخزن كل الرسائل في ISR الرسالة.
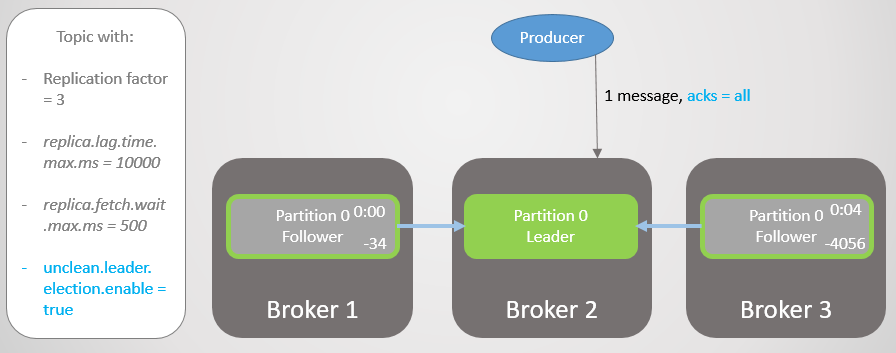 التين. 13. ISR مع ثلاثة النسخ المتماثلة. واحد بطيء ، مما تسبب في تأخير في التسجيل
التين. 13. ISR مع ثلاثة النسخ المتماثلة. واحد بطيء ، مما تسبب في تأخير في التسجيلبعد أربع ثوانٍ من التأخير الإضافي ، يرسل الوسيط 2 الأمر. يتم الآن تحديث كافة النسخ المتماثلة بالكامل.
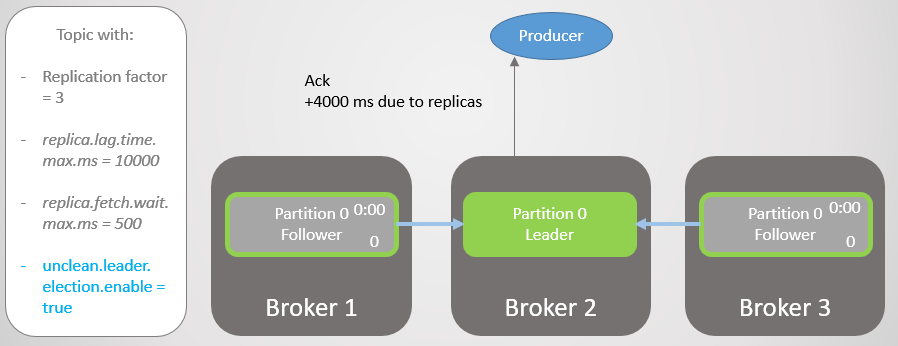 التين. 14. حفظ جميع النسخ المتماثلة للرسائل و ack
التين. 14. حفظ جميع النسخ المتماثلة للرسائل و ackأصبح الوسيط 3 متخلفًا عن الخدمة ويتم إزالته من ISR. يتم تقليل التأخير بشكل كبير لأنه لا توجد نسخ متماثلة بطيئة في ISR. ينتظر Broker 2 الآن الوسيط 1 فقط ، ولديه متوسط تأخير قدره 500 مللي ثانية.
 التين. 15. تتم إزالة النسخة المتماثلة على وسيط 3 من ISR
التين. 15. تتم إزالة النسخة المتماثلة على وسيط 3 من ISRثم يسقط الوسيط 2 ، وتنتقل القيادة إلى الوسيط 1 دون فقد الرسائل.
 التين. 16. السمسار 2 يسقط
التين. 16. السمسار 2 يسقطيجد الصانع قائدًا جديدًا ويبدأ في إرسال رسائل إليه. لا يزال يتم تقليل التأخير ، لأن ISR يتكون الآن من نسخة متماثلة واحدة! لذلك ، لا يضيف الخيار
= الكل خيار التكرار.
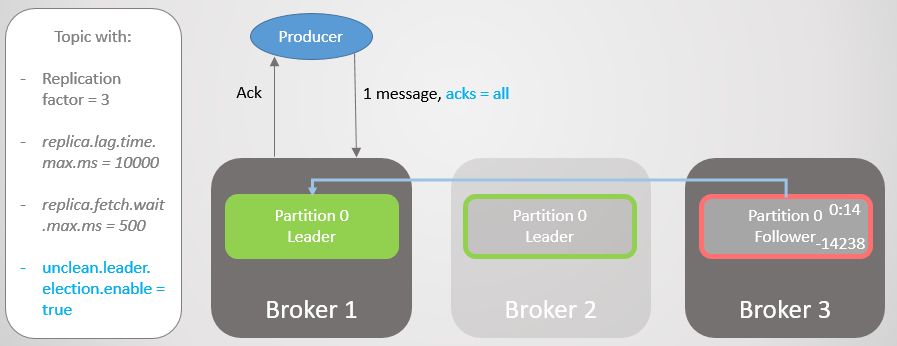 التين. 17. النسخة المتماثلة على وسيط 1 تأخذ زمام المبادرة دون فقدان الرسائل
التين. 17. النسخة المتماثلة على وسيط 1 تأخذ زمام المبادرة دون فقدان الرسائلثم يسقط الوسيط 1 ، وتنتقل القيادة إلى الوسيط 3 بخسارة 14،238 رسالة!
 التين. 18. وفاة الوسيط 1 ، ويؤدي انتقال القيادة مع الإعداد غير النظيف إلى فقدان واسع للبيانات
التين. 18. وفاة الوسيط 1 ، ويؤدي انتقال القيادة مع الإعداد غير النظيف إلى فقدان واسع للبياناتلم نتمكن من ضبط الخيار
unclean.leader.election.enable على
true . افتراضيا ، هذا
خطأ . يؤدي إعداد
acks = all باستخدام
unclean.leader.election.enable = true إلى توفير إمكانية الوصول مع بعض أمان البيانات الإضافي. ولكن ، كما ترون ، لا يزال بإمكاننا فقد الرسائل.
لكن ماذا لو أردنا زيادة أمان البيانات؟ يمكنك تعيين
unclean.leader.election.enable = false ، لكن هذا لا يحمينا بالضرورة من فقدان البيانات. إذا سقط القائد بشدة وأخذ البيانات معه ، فلا تزال الرسائل مفقودة ، بالإضافة إلى فقد إمكانية الوصول إلى أن يسترد المسؤول الموقف.
من الأفضل ضمان تكرار جميع الرسائل ، ورفض التسجيل بطريقة أخرى. بعد ذلك ، على الأقل من وجهة نظر الوسيط ، لا يمكن فقد البيانات إلا بفشلين متزامنين أو أكثر.
Akss = الكل ، min.insync.replicas و ISR
باستخدام
تكوين موضوع
min.insync.replicas ، نزيد من أمان البيانات. دعنا نذهب إلى الجزء الأخير من السيناريو الأخير مرة أخرى ، ولكن هذه المرة مع
min.insync.replicas = 2 .
لذلك ، لدى الوسيط 2 قائد متماثلة ، وتتم إزالة التابع على وسيط 3 من ISR.
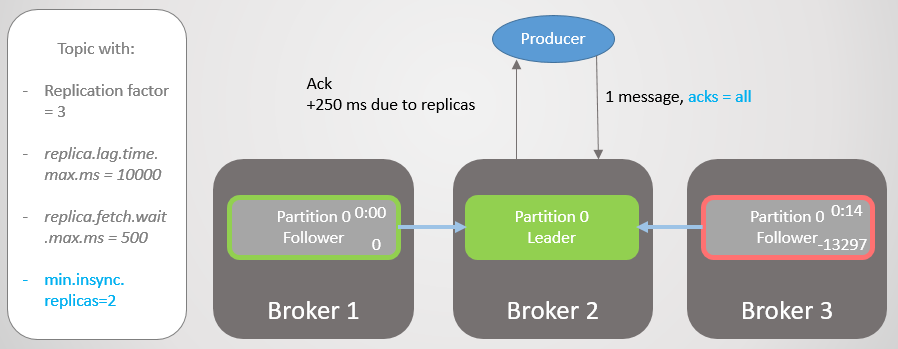 التين. 19. ISR من اثنين من النسخ المتماثلة
التين. 19. ISR من اثنين من النسخ المتماثلةيقع السمسار 2 ، وتنتقل القيادة إلى الوسيط 1 دون فقد الرسائل. ولكن الآن ISR يتكون من نسخة متماثلة واحدة فقط. هذا لا يتوافق مع الحد الأدنى لعدد تلقي السجلات ، وبالتالي يستجيب الوسيط لمحاولة التسجيل مع خطأ
NotEnoughReplicas .
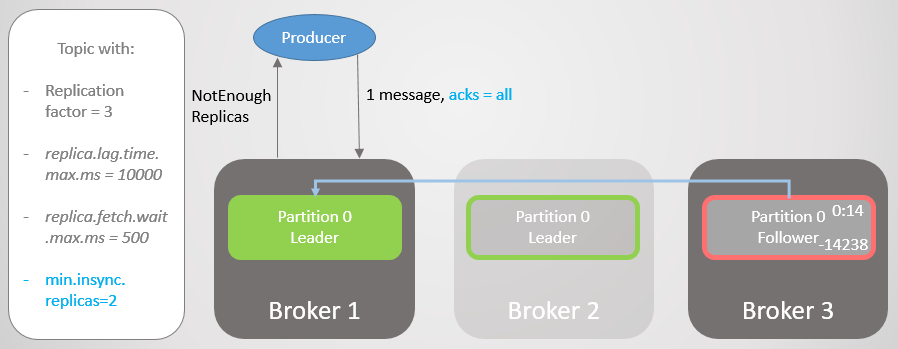 التين. 20. عدد ISRs أقل من الرقم المحدد في min.insync.replicas
التين. 20. عدد ISRs أقل من الرقم المحدد في min.insync.replicasهذا التكوين التضحية توافر من أجل الاتساق. قبل تأكيد الرسالة ، نضمن تسجيلها على نسختين متماثلتين على الأقل. هذا يعطي الشركة المصنعة ثقة أكبر بكثير. هنا ، يكون فقدان الرسالة ممكنًا فقط في حالة فشل نسختين متماثلتين في وقت واحد في فترة زمنية قصيرة ، حتى يتم نسخ الرسالة إلى متابِع إضافي ، وهو أمر غير مرجح. ولكن إذا كنت superparanoid ، فيمكنك ضبط نسبة النسخ المتماثل على 5 ، و
min.insync.replicas إلى 3. ثم يجب أن يسقط ثلاثة وسطاء في وقت واحد في نفس الوقت من أجل فقد السجل! بالطبع ، لمثل هذه الموثوقية سوف تدفع تأخيرًا إضافيًا.
عندما تكون هناك حاجة للوصول إلى أمن البيانات
كما هو الحال
مع RabbitMQ ، في بعض الأحيان تكون إمكانية الوصول ضرورية لأمان البيانات. تحتاج إلى التفكير في هذا:
- هل يمكن للناشر فقط إرجاع خطأ ، وخدمة أو مستخدم أعلى حاول مرة أخرى لاحقًا؟
- هل يمكن للناشر حفظ رسالة محليًا أو في قاعدة بيانات لإعادة المحاولة لاحقًا؟
إذا كانت الإجابة "لا" ، فإن تحسين إمكانية الوصول يحسن من أمان البيانات. ستفقد بيانات أقل إذا اخترت التوفر بدلاً من تجاهل التسجيل. وبالتالي ، كل هذا يتوقف على إيجاد توازن ، والقرار يعتمد على الموقف المحدد.
معنى ISR
تسمح لك مجموعة ISR باختيار التوازن الأمثل بين أمان البيانات والكمون. على سبيل المثال ، للتأكد من أن معظم النسخ المتماثلة يمكن الوصول إليها في حالة الفشل ، مما يقلل من تأثير النسخ المتماثلة الميتة أو البطيئة من حيث التأخير.
نحن أنفسنا اختيار قيمة
replica.lag.time.max.ms وفقا لاحتياجاتنا. في جوهرها ، تعني هذه المعلمة التأخير الذي نحن على استعداد لقبوله مع
aks = الكل . القيمة الافتراضية هي عشر ثوانٍ. إذا كان هذا طويلًا جدًا بالنسبة لك ، فيمكنك تقليله. ثم سوف يزداد معدل تكرار التغييرات في ISR ، حيث سيتم حذف المتابعين وإضافتهم في أغلب الأحيان.
RabbitMQ هو مجرد مجموعة من المرايا التي تحتاج إلى تكرارها. تقدم المرايا البطيئة تأخيرًا إضافيًا ، ويمكن توقع استجابة المرايا الناقصة قبل انتهاء صلاحية الحزم التي تتحقق من توفر كل عقدة (علامة التجزئة). تعد ISRs طريقة ممتعة لتجنب هذه المشكلات مع الكمون المتزايد. لكننا نخاطر بفقدان التكرار ، نظرًا لأن ISR لا يمكن تحويله إلا إلى قائد. لتجنب هذا الخطر ، استخدم إعداد
min.insync.replicas .
ضمان اتصال العملاء
في إعدادات
bootstrap.servers الخاصة بالشركة المصنعة والمستهلك ، يمكنك تحديد العديد من الوسطاء لربط العملاء. تتمثل الفكرة في أنه عندما تقوم بفصل عقدة واحدة ، هناك عدة عقد احتياطية يمكن للعميل فتح اتصال بها. هذه ليست بالضرورة قادة القسم ، ولكن ببساطة نقطة انطلاق ل bootstrapping. يمكن للعميل أن يسألهم عن العقدة التي يوجد بها قائد قسم القراءة / الكتابة.
في RabbitMQ ، يمكن للعملاء الاتصال بأي مضيف ، والتوجيه الداخلي يرسل طلبًا عند الضرورة. هذا يعني أنه يمكنك تثبيت موازن التحميل أمام RabbitMQ. يتطلب Kafka من العملاء الاتصال بالمضيف الذي يستضيف قائد القسم المقابل. في هذه الحالة ، لا يحقق موازن التحميل. تعد قائمة
bootstrap.servers مهمة للغاية بحيث يمكن للعملاء الوصول إلى العقد الصحيحة والعثور عليها بعد حدوث أي عطل.
إجماع كافكا
حتى الآن ، لم نفكر في كيفية معرفة المجموعة بسقوط الوسيط وكيف يتم اختيار قائد جديد. لفهم كيفية عمل Kafka مع أقسام الشبكة ، تحتاج أولاً إلى فهم بنية الإجماع.
يتم نشر كل مجموعة من مجموعات Kafka مع نظام Zookeeper - إنها خدمة إجماع موزعة تسمح للنظام بالتوصل إلى إجماع بشأن حالة معينة مع إعطاء الأولوية للتناسق على التوفر. تتطلب الموافقة على عمليات القراءة والكتابة موافقة معظم عقد Zookeeper.
Zookeeper يخزن حالة الكتلة:
- قائمة المواضيع ، الأقسام ، التكوين ، النسخ المتماثلة للزعيم الحالي ، النسخ المتماثلة المفضلة.
- أعضاء الكتلة. كل وسيط الأصوات في كتلة Zookeeper. إذا لم يتسلم الأمر ping لفترة زمنية محددة ، فسيكتب Zookeeper عن الوسيط الذي يتعذر الوصول إليه.
- اختيار العقد الابتدائية والثانوية لوحدة التحكم.
عقدة التحكم هي واحدة من وسطاء Kafka المسؤولين عن انتخاب قادة النسخ المتماثلة. يرسل Zookeeper إعلامات وحدة التحكم لعضوية الكتلة وتغييرات الموضوع ، ويجب أن تعمل وحدة التحكم وفقًا لهذه التغييرات.
على سبيل المثال ، خذ موضوعًا جديدًا يتكون من عشرة أقسام ومعامل نسخ متماثل قدره 3. يجب أن تختار وحدة التحكم قائد كل قسم ، في محاولة لتوزيع القادة على النحو الأمثل بين الوسطاء.
لكل قسم ، وحدة التحكم:
- تحديث المعلومات في Zookeeper حول ISR والقائد ؛
- يرسل أمر LeaderAndISRCommand إلى كل وسيط يقوم بنشر نسخة طبق الأصل من هذا القسم ، لإبلاغ الوسطاء عن ISR والزعيم.
عندما يقع وسيط مع زعيم ، يرسل Zookeeper إخطارًا إلى وحدة التحكم ، ويختار قائدًا جديدًا. مرة أخرى ، يقوم جهاز التحكم أولاً بتحديث Zookeeper ، ثم يرسل أمرًا إلى كل وسيط ، لإعلامهم بتغيير القيادة.
كل قائد مسؤول عن تجنيد ISR. يحدد
إعداد replica.lag.time.max.ms من سيذهب إلى هناك. عندما يتغير ISR ، يقوم القائد بتمرير المعلومات الجديدة إلى Zookeeper.
يتم إبلاغ Zookeeper دائمًا بأي تغييرات ، لذلك في حالة حدوث فشل ، تنتقل الإدارة بسلاسة إلى الزعيم الجديد.
 التين. 21. توافق كافكا
التين. 21. توافق كافكابروتوكول النسخ المتماثل
يساعدك فهم تفاصيل النسخ المتماثل على فهم سيناريوهات فقد البيانات المحتملة بشكل أفضل.
طلبات نموذج ، إزاحة نهاية السجل (LEO) وعلامة Highwater (HW)
لقد اعتبرنا أن المتابعين يرسلون طلبات جلب بشكل دوري إلى القائد. الفاصل الزمني الافتراضي هو 500 مللي ثانية. هذا يختلف عن RabbitMQ في أنه في RabbitMQ ، يتم بدء النسخ المتماثل ليس بواسطة نسخة متطابقة قائمة الانتظار ، ولكن بواسطة المعالج. سيد يدفع التغييرات على المرايا.
يحتفظ الزعيم وجميع المتابعين بعلامة Log End Offset (LEO) و Highwater (HW). تخزن علامة LEO إزاحة الرسالة الأخيرة في النسخة المتماثلة المحلية ، وتقوم HW بتخزين إزاحة الالتزام الأخير. تذكر أنه بالنسبة لحالة الالتزام ، يجب حفظ الرسالة في جميع النسخ المتماثلة لـ ISR. هذا يعني أن LEO عادة ما تكون متقدمة قليلاً عن المخلفات الخطرة.
عندما يتلقى زعيم رسالة ، فإنه يحفظها محليا. يقدم التابع طلب إحضار ، ويمرر LEO. يقوم القائد بعد ذلك بإرسال حزمة من الرسائل التي تبدأ بهذا المدار الأرضي المنخفض ، كما ينقل الخطاف الحالي. عندما يتلقى الزعيم معلومات تفيد بأن جميع النسخ المتماثلة قد حفظت الرسالة في إزاحة معينة ، فإنه يحرك علامة الخط. يمكن للزعيم فقط تحريك المخلفات الخطرة ، وبالتالي يعرف جميع المتابعين القيمة الحالية في الردود على طلبهم. هذا يعني أن المتابعين يمكنهم أن يتخلفوا عن القائد في كل من الإبلاغ ومعرفة المخلفات الخطرة. يتلقى المستهلكون الرسائل حتى الحد الأقصى الحالي.
لاحظ أن كلمة "الدائمة" تعني الكتابة إلى الذاكرة وليس إلى القرص. للأداء ، يتزامن تطبيق كافكا مع القرص في فاصل زمني محدد. يحتوي RabbitMQ أيضًا على مثل هذا الفاصل الزمني ، لكنه لن يرسل تأكيدًا للناشر إلا بعد المعلم وكتبت جميع المرايا الرسالة على القرص. قرر مطورو شركة Kafka لأسباب تتعلق بالأداء إرسال رسالة بمجرد كتابة الرسالة إلى الذاكرة. تعتمد كافكا على حقيقة أن التكرار يعوض عن خطر التخزين القصير الأجل للرسائل المؤكدة في الذاكرة فقط.
فشل القائد
عندما يسقط زعيم ، يقوم Zookeeper بإعلام وحدة التحكم ، ويقوم بتحديد نسخة متماثلة جديدة للزعيم. يضع القائد الجديد علامة جديدة على المخلفات الخطرة تتماشى مع معدل ضربات الأرض المنخفض. ثم يتلقى المتابعون معلومات عن الزعيم الجديد. اعتمادًا على إصدار Kafka ، سيختار المتابع أحد السيناريوهين التاليين:
- اقتطاع السجل المحلي إلى HW الشهيرة وإرسال رسالة إلى الزعيم الجديد بعد هذه العلامة.
- سوف يرسل طلبًا إلى القائد لاكتشاف الأب في وقت انتخابه كقائد ، ثم اقتطاع السجل إلى هذا الإزاحة. ثم ستبدأ في تقديم طلبات دورية لأخذ العينات ، بدءًا من هذا الإزاحة.
قد يحتاج المتابع إلى قص السجل للأسباب التالية:- , ISR, Zookeeper, . ISR, «», . , . Kafka , . , , HW . , acks=all .
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
1. , Zookeeper
 . 22. 1. ISR
. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
 . 23. 1. ISR, replica.lag.time.max.ms
. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 . 24. 2.
. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 . 25. 2. ISR
. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
 . 26. 3.
. 26. 3.4. , Zookeeper
 . 27. 4.
. 27. 4.Zookeeper, .
 . 28. 4. Zookeeper
. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 . 29. 4. 1
. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
 . 30. 5. ISR
. 30. 5. ISR6. Kafka, Zookeeper
 . 31. 6.
. 31. 6., Zookeeper.
acks=1 .
 . 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
 . 33. 6.
. 33. 6., . 60 . .
 . 34. 6.
. 34. 6., . , Zookeeper , . HW .
 . 35. 6.
. 35. 6.,
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync كل بضع مئات من المللي ثانية
- لا يمكن اكتشاف المرايا إلا بعد عمر الحزم التي تتحقق من توفر كل عقدة (علامة التجزئة). إذا تباطأت المرآة أو سقطت ، فهذا يضيف تأخيرًا.
يعتمد كافكا على حقيقة أنه إذا تم تخزين الرسالة على عدة عقد ، فيمكنك تأكيد الرسائل بمجرد وجودها في الذاكرة. لهذا السبب ، هناك خطر فقدان الرسائل من أي نوع (حتى
acks = الكل ،
min.insync.replies = 2 ) في حالة حدوث فشل في وقت واحد.
بشكل عام ، يُظهر Kafka أداءً أفضل وقد تم تصميمه في الأصل للمجموعات. يمكن زيادة عدد المتابعين إلى 11 ، إذا لزم الأمر للموثوقية. عامل النسخ المتماثل 5 والحد الأدنى لعدد النسخ المتماثلة في حالة متزامنة من
min.insync.replicas = 3 سيجعل فقدان الرسالة حدثًا نادرًا للغاية. إذا كانت البنية الأساسية لديك قادرة على توفير معدل النسخ المتماثل هذا ومستوى التكرار ، فيمكنك اختيار هذا الخيار.
مجموعات RabbitMQ جيدة لقوائم الانتظار الصغيرة. ولكن حتى الطوابير الصغيرة يمكن أن تنمو بسرعة مع حركة المرور العالية. بمجرد أن تصبح قوائم الانتظار كبيرة ، يجب عليك اتخاذ خيار صعب بين التوفر والموثوقية. تعتبر مجموعات RabbitMQ مناسبة تمامًا للمواقف غير التقليدية حيث تفوق مزايا مرونة RabbitMQ أيًا من عيوب تجميعها.
أحد الترياق لضعف قائمة انتظار RabbitMQ هو تقسيمها إلى العديد من الأصغر منها. إذا كنت لا تحتاج إلى ترتيب كامل لقائمة الانتظار بالكامل ، ولكن فقط الرسائل ذات الصلة (على سبيل المثال ، رسائل عميل معين) ، أو لا
تطلب أي شيء على الإطلاق ، فإن هذا الخيار مقبول: انظر إلى مشروع
Rebalanser الخاص بي لتقسيم قائمة الانتظار (لا يزال المشروع في مرحلة مبكرة).
أخيرًا ، لا تنسَ عددًا من الأخطاء في آليات التجميع والتكرار لكل من RabbitMQ و Kafka. بمرور الوقت ، أصبحت الأنظمة أكثر نضجًا واستقرارًا ، ولكن لن يتم حماية رسالة واحدة أبدًا بنسبة 100٪ من الضياع! بالإضافة إلى ذلك ، تحدث حوادث واسعة النطاق في مراكز البيانات!
إذا فاتني شيء أو ارتكبت خطأ أو كنت لا توافق على أي من النقاط ، فلا تتردد في كتابة تعليق أو الاتصال بي.
غالبًا ما يسألني الناس: "ماذا تختار ، كافكا أو رابيت أم كيو؟" ، "ما هي المنصة الأفضل؟". الحقيقة هي أن الأمر يعتمد حقًا على موقفك ، وتجربتك الحالية ، وما إلى ذلك. لا أجرؤ على التعبير عن رأيي ، لأنه سيكون من التبسيط المفرط التوصية بأية منصة واحدة لجميع حالات الاستخدام والقيود المحتملة. كتبت هذه السلسلة من المقالات حتى تتمكن من تكوين رأيك.
أريد أن أقول إن كلا النظامين قادة في هذا المجال. ربما أكون متحيزًا بعض الشيء ، لأنه من خلال تجربة مشاريعي ، أميل أكثر إلى تقدير أشياء مثل ترتيب الرسائل المضمونة والموثوقية.
أرى التقنيات الأخرى التي تفتقر إلى هذه الموثوقية والطلب المضمون ، ثم انظر إلى RabbitMQ و Kafka - وأنا أفهم القيمة المذهلة لكل من هذين النظامين.