TL. DR: JSONB يمكن أن تبسط إلى حد كبير تطوير مخطط قاعدة البيانات دون التضحية بأداء الاستعلام.
مقدمة
دعنا نعطي مثالًا كلاسيكيًا ، على الأرجح ، لإحدى أقدم حالات الاستخدام لقواعد البيانات العلائقية (قاعدة البيانات): لدينا كيان ، ومن الضروري الحفاظ على خصائص معينة (سمات) لهذا الكيان. لكن قد لا تحتوي جميع الحالات على نفس مجموعة الخصائص ، بالإضافة إلى ذلك ، في المستقبل ، الإضافة المحتملة لمزيد من الخصائص.
أسهل طريقة لحل هذه المشكلة هي إنشاء عمود في جدول قاعدة البيانات لكل قيمة خاصية ، وملء ببساطة تلك اللازمة لمثيل كيان محدد. ! ممتاز تم حل المشكلة ... حتى يحتوي الجدول الخاص بك على ملايين السجلات ولن تحتاج إلى إضافة سجل جديد.
النظر في نمط EAV (
Entity-Attribute-Value ) ، إنه أمر شائع جدًا. يحتوي جدول واحد على كيانات (سجلات) ، بينما يحتوي جدول آخر على أسماء الخصائص (السمات) ، بينما يربط الجدول الثالث الكيانات بسماتها ويتضمن قيمة هذه السمات للكيان الحالي. يمنحك هذا فرصة الحصول على مجموعات مختلفة من الخصائص لكائنات مختلفة ، بالإضافة إلى إضافة خصائص على الطاير ، دون تغيير بنية قاعدة البيانات.
ومع ذلك ، لن أكتب هذه الملاحظة إذا لم تكن هناك أوجه قصور في النهج باستخدام EVA. لذلك ، على سبيل المثال ، للحصول على واحد أو أكثر من الكيانات التي تحتوي على سمة واحدة لكل منهما ، هناك حاجة إلى 2 join'a (صلات) في الاستعلام: الأول هو اتحاد مع جدول السمات ، والثاني هو الاتحاد مع جدول القيمة. إذا كان الكيان له سمتان ، فثمة حاجة إلى 4 روابط بالفعل! بالإضافة إلى ذلك ، يتم عادةً تخزين كل السمات كسلسلة ، مما يؤدي إلى كتابة casting لكل من النتيجة وعبارة WHERE. إذا كنت تكتب الكثير من الطلبات ، فهذا أمر مضلل إلى حد ما من حيث استخدام الموارد.
على الرغم من هذه العيوب الواضحة ، فقد استخدمت EAV منذ فترة طويلة لحل هذه الأنواع من المشاكل. كانت هذه عيوب لا مفر منها ، ولم يكن هناك بديل أفضل.
ولكن بعد ذلك ظهرت "تقنية" جديدة في PostgreSQL ...
بدءًا من PostgreSQL 9.4 ، تمت إضافة نوع بيانات JSONB لتخزين بيانات JSON الثنائية. على الرغم من أن تخزين JSON بهذا التنسيق عادة ما يستغرق مساحة ووقتًا أكبر بقليل من JSON للنص العادي ، إلا أن العمليات التي تتم به أسرع بكثير. JSONB يدعم الفهرسة ، مما يجعل الاستعلام عنها أسرع.
يتيح لنا نوع بيانات JSONB استبدال نمط EAV الضخم بإضافة عمود JSONB واحد فقط إلى جدول كياننا ، مما يبسط تصميم قاعدة البيانات إلى حد كبير. لكن الكثيرين يجادلون بأن هذا يجب أن يصاحبه انخفاض في الإنتاجية ... لهذا السبب ظهرت في هذا المقال.
اختبار إعداد قاعدة البيانات
في هذه المقارنة ، قمتُ بإنشاء قاعدة بيانات حول تثبيت جديد لبرنامج PostgreSQL 9.5 على إنشاء
DigitalOcean Ubuntu 14.04 دولارًا بقيمة 80 دولارًا. بعد تعيين بعض المعلمات في postgresql.conf ، قمت بتشغيل
هذا البرنامج النصي باستخدام psql. تم إنشاء الجداول التالية لتمثيل البيانات كـ EAV:
CREATE TABLE entity ( id SERIAL PRIMARY KEY, name TEXT, description TEXT ); CREATE TABLE entity_attribute ( id SERIAL PRIMARY KEY, name TEXT ); CREATE TABLE entity_attribute_value ( id SERIAL PRIMARY KEY, entity_id INT REFERENCES entity(id), entity_attribute_id INT REFERENCES entity_attribute(id), value TEXT );
يوجد أدناه جدول حيث سيتم تخزين نفس البيانات ، ولكن مع سمات في عمود نوع JSONB -
الخصائص .
CREATE TABLE entity_jsonb ( id SERIAL PRIMARY KEY, name TEXT, description TEXT, properties JSONB );
يبدو أسهل كثيرا ، أليس كذلك؟ بعد ذلك ، تمت إضافة 10 ملايين سجل إلى جداول الكيانات (
الكيان &
الكيان_جسونب ) ، وبناءً على ذلك ، تم ملء نفس بيانات الجدول باستخدام نموذج EAV والنهج باستخدام عمود
JSONB -
الكيان_ jsonb.properties . وبالتالي ، تلقينا عدة أنواع مختلفة من البيانات بين مجموعة الخصائص بأكملها. بيانات العينة:
{ id: 1 name: "Entity1" description: "Test entity no. 1" properties: { color: "red" lenght: 120 width: 3.1882420 hassomething: true country: "Belgium" } }
لذلك ، لدينا الآن نفس البيانات ، لخيارين. لنبدأ بمقارنة التطبيقات في العمل!
تبسيط التصميم
لقد قيل بالفعل أن تصميم قاعدة البيانات تم تبسيطه إلى حد كبير: جدول واحد ، باستخدام عمود JSONB للخصائص ، بدلاً من استخدام ثلاثة جداول ل EAV. ولكن كيف ينعكس هذا في الطلبات؟ تحديث خاصية واحدة لكيان ما يلي:
كما ترى ، فإن الطلب الأخير لا يبدو أسهل. لتحديث قيمة خاصية في كائن JSONB ، يجب أن نستخدم
دالة jsonb_set () ، ويجب أن نمرر قيمتنا الجديدة ككائن JSONB. ومع ذلك ، نحن لسنا بحاجة لمعرفة أي معرف مقدما. عند النظر إلى مثال EAV ، نحتاج إلى معرفة كيان__ الكيان_ كيان_أحد_الخاصية_ من أجل التحديث. إذا كنت تريد تحديث خاصية في عمود JSONB بناءً على اسم الكائن ، فسيتم ذلك كله في صف واحد بسيط.
الآن دعنا نختار الكيان الذي قمنا بتحديثه للتو ، وفقًا لحالة لونه الجديد:
أعتقد أنه يمكننا الاتفاق على أن الثانية أقصر (بدون الانضمام!) ، وبالتالي أكثر قابلية للقراءة. هنا انتصار JSONB! نستخدم عامل التشغيل JSON - >> للحصول على اللون كقيمة نصية من كائن JSONB. هناك أيضًا طريقة ثانية لتحقيق نفس النتيجة في نموذج JSONB باستخدام عامل التشغيل @>:
هذا الأمر أكثر تعقيدًا: نتحقق مما إذا كان كائن JSON في عمود الخاصية يحتوي على الكائن الموجود على يمين العامل @>. أقل قابلية للقراءة وأكثر إنتاجية (انظر أدناه).
تبسيط استخدام JSONB أكثر عندما تحتاج إلى تحديد خصائص متعددة في وقت واحد. هذا هو المكان الذي يأتي منهج JSONB حقًا: نختار الخصائص كعمود إضافية في مجموعة النتائج الخاصة بنا دون الحاجة إلى روابط:
مع EAV ، ستحتاج إلى 2 صلات لكل خاصية تريد طلبها. في رأيي ، تُظهر الاستعلامات أعلاه تبسيطًا كبيرًا في تصميم قاعدة البيانات. اطلع على المزيد من الأمثلة حول كيفية كتابة طلبات JSONB ، أيضًا في
هذا المنشور.
الآن حان الوقت للحديث عن الأداء.
إنتاجية
لمقارنة الأداء ، استخدمت "توضيح
التحليل" في الاستعلامات ، لحساب وقت التشغيل. تم تنفيذ كل طلب على الأقل ثلاث مرات لأن المرة الأولى التي يستغرق فيها مخطط الاستعلام وقتًا أطول. في البداية ، قمت بتشغيل الاستعلامات دون أي فهارس. من الواضح أن هذا كان بمثابة ميزة لـ JSONB ، حيث إن الصلة المطلوبة لـ EAV لم تتمكن من استخدام الفهارس (لم تتم فهرسة حقول المفاتيح الخارجية). بعد ذلك ، قمت بإنشاء فهرس لعمودين من المفاتيح الخارجية في جدول قيم EAV ، بالإضافة إلى فهرس
GIN لعمود JSONB.
أظهرت تحديثات البيانات النتائج التالية في الوقت المناسب (بالمللي ثانية). لاحظ أن المقياس لوغاريتمي:

نرى أن JSONB أسرع بكثير من (EAV-X) من EAV إذا لم تستخدم الفهارس ، للسبب المشار إليه أعلاه. عندما نفهرس الأعمدة بالمفاتيح الأساسية ، يختفي الفرق تقريبًا ، لكن JSONB لا يزال أسرع بـ 1.3 مرة من EAV. يرجى ملاحظة أن الفهرس في عمود JSONB ليس له أي تأثير هنا ، لأننا لا نستخدم عمود الخاصية في معايير التقييم.
لتحديد البيانات بناءً على قيمة العقار ، نحصل على النتائج التالية (المقياس العادي):
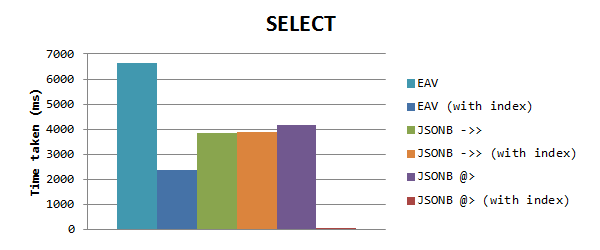
قد تلاحظ أن JSONB أسرع مرة أخرى من EAV بدون فهارس ، ولكن عندما تكون EAV مع الفهارس ، فإنها لا تزال تعمل بشكل أسرع من JSONB. ولكن بعد ذلك رأيت أن وقت طلبات JSONB كان هو نفسه ، وهذا دفعني إلى حقيقة أن فهرس GIN لم يعمل. على ما يبدو ، عند استخدام فهرس GIN لعمود به خصائص ممتلئة ، فإنه يعمل فقط عند استخدام عامل التضمين @>. لقد استخدمت هذا في اختبار جديد ، والذي كان له تأثير كبير في الوقت المحدد: 0.153 مللي ثانية فقط! هذا هو 15000 مرة أسرع من EAV ، و 25000 مرة أسرع من المشغل - >>.
أعتقد أنه كان بالسرعة الكافية!
حجم الجدول ديسيبل
دعونا نقارن أحجام الجدول لكلا النهجين. في psql ، يمكننا إظهار حجم جميع الجداول والفهارس باستخدام الأمر
\ dti +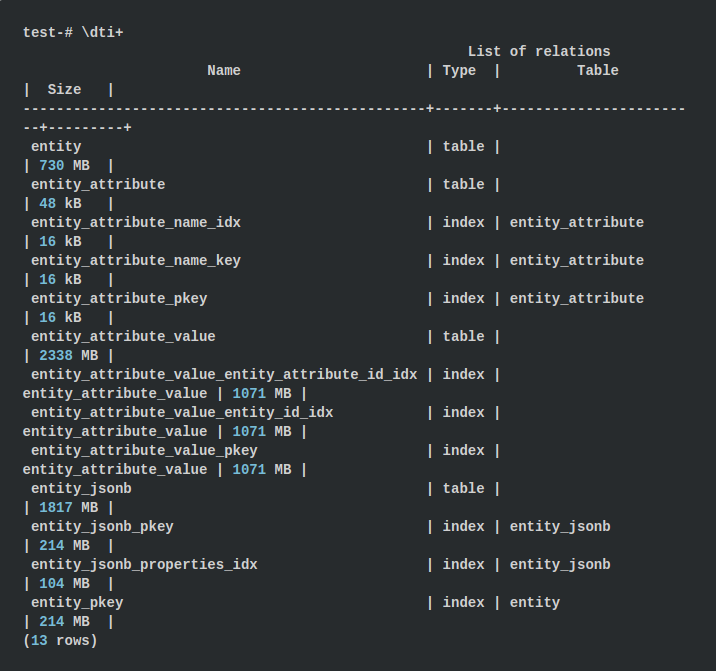
بالنسبة لنهج EAV ، تبلغ أحجام الجدول حوالي 3068 ميغابايت ، والفهارس تصل إلى 3427 ميغابايت ، والتي تعطي إجماليًا 6.43 جيجابايت. باستخدام نهج JSONB ، يتم استخدام 1817 ميغابايت للجدول و 318 ميغابايت للفهارس ، وهو 2.08 جيجابايت. اتضح 3 مرات أقل! هذه الحقيقة فاجأتني قليلاً لأننا نخزن أسماء العقارات في كل كائن JSONB.
ولكن على نفس المنوال ، فإن الأرقام تتحدث عن نفسها: في EAV نقوم بتخزين مفتاحين خارجيين صحيحين لقيمة السمة ، ونتيجة لذلك نحصل على 8 بايتات من البيانات الإضافية. بالإضافة إلى ذلك ، في EAV ، يتم تخزين جميع قيم الخصائص كنص ، في حين أن JSONB سوف تستخدم القيم العددية والمنطقية في الداخل ، حيثما أمكن ، مما يؤدي إلى انخفاض حجم الصوت.
النتائج
بشكل عام ، أعتقد أن تخزين خصائص الكيان بتنسيق JSONB يمكن أن يسهل بشكل كبير تصميم وصيانة قاعدة البيانات الخاصة بك. إذا قمت بتنفيذ الكثير من الاستعلامات ، فسيعمل كل شيء مخزّن في نفس الجدول مع الكيان بالفعل بشكل أكثر كفاءة. وحقيقة أن هذا يبسط التفاعل بين البيانات بالفعل زائد ، ولكن قاعدة البيانات الناتجة أصغر 3 مرات في الحجم.
أيضا ، وفقا للاختبار ، يمكننا أن نستنتج أن فقدان الأداء طفيف جدا. في بعض الحالات ، يعمل JSONB بشكل أسرع من EAV ، مما يجعله أفضل. ومع ذلك ، لا يغطي هذا المعيار ، بالطبع ، جميع الجوانب (على سبيل المثال ، الكيانات التي تحتوي على عدد كبير جدًا من الخصائص ، أي زيادة كبيرة في عدد خصائص البيانات الموجودة ، ...) ، وبالتالي ، إذا كان لديك أي اقتراحات حول كيفية تحسينها ، فالرجاء لا تتردد في ترك تعليق!