
مرحبا يا هبر. في الآونة الأخيرة كانت هناك منافسة من تينكوف وماكينزي. أقيمت المسابقة على مرحلتين: الأولى - التصفيات ، في شكل kaggle ، أي إرسال تنبؤات - الحصول على تقييم لجودة التنبؤ ؛ الفائز هو صاحب أفضل نتيجة. والثاني هو hackathon في الموقع في موسكو ، والذي يستضيف أفضل 20 فريق من المرحلة الأولى. سأتحدث في هذه المقالة عن مرحلة التصفيات ، حيث تمكنت من الحصول على المركز الأول والفوز في MacBook. كان الفريق على لوحة المتصدرين يطلق عليه "أطفال ليشا".
عقدت المسابقة من 19 سبتمبر إلى 12 أكتوبر. بدأت في حل قبل أسبوع بالضبط من النهاية وقررت بدوام كامل تقريبا.
وصف قصير للمسابقة:
في الصيف ، ظهرت قصص على تطبيق Tinkoff المصرفي (كما هو الحال على Instagram). في القصة ، يمكنك التفاعل مثل ، أو عدم الإعجاب ، أو تخطي أو عرض حتى النهاية. المهمة هي التنبؤ برد فعل المستخدم للقصة.
المسابقة جدولية في معظمها ، لكن القصص نفسها تحتوي على نصوص وصور.
خطة القصة

متري
يمكن أن تأخذ توقعات التفاعل قيمة من -1 إلى 1 شاملة - كلما اقتربت من القيمة 1 ، كلما زاد احتمال الحصول على مثل. وبقيمة -1 ، من الأفضل إزالة هذه القصة من عيون المستخدم.
للتحقق من دقة الحلول ، يتم استخدام صيغة ، وتطبيعها إلى أقصى نتيجة ممكنة:
\ start {array} {l} {\ text {weight (event)} = \ left \ {\ start {array} {ll} {- 10} & {\ text {dislike}} \\ {-0.1} & {\ text {skip}} \\ {0.1} & {\ text {view}} \\ {0.5} & {\ text {like}} \ end {array} \ right.} \\ [15pt] {\ text {Metric} \ left (y _ {\ text {pred}} \ right) = \ sum_ {i = 1} ^ {n} \ left (\ text {weight} \ left (\ text {event} _ {i} \ right) \ cdot y _ {\ text {pred،} i} \ right)} \ end {array}
ما هي البيانات هناك:
- معلومات المستخدم الأساسية
- معاملات المستخدم
- معلومات حول القصة (json يمكنك من خلالها بنائها)
- تاريخ ردود فعل المستخدم على القصص.
بعد ذلك ، سأتحدث بالتفصيل عن كل جزء من البيانات ، وكيفية معالجتها والميزات (المشار إليها فيما يلي باسم الميزات) التي استخرجتها.

ما هو في الأصل:
- معرف المستخدم
- منتجات مصرفية مجهولة قام المستخدم بفتحها (OPN) أو يستخدم (UTL) أو مغلق (CLS)
- الجنس ، والعمر bin bin ، والحالة الزواجية ، أول دخول في التطبيق
- job_title - ما يكتبه الناس عن أنفسهم
- job_position_cd - المسمى الوظيفي للشخص ، كواحد من 22 فئة
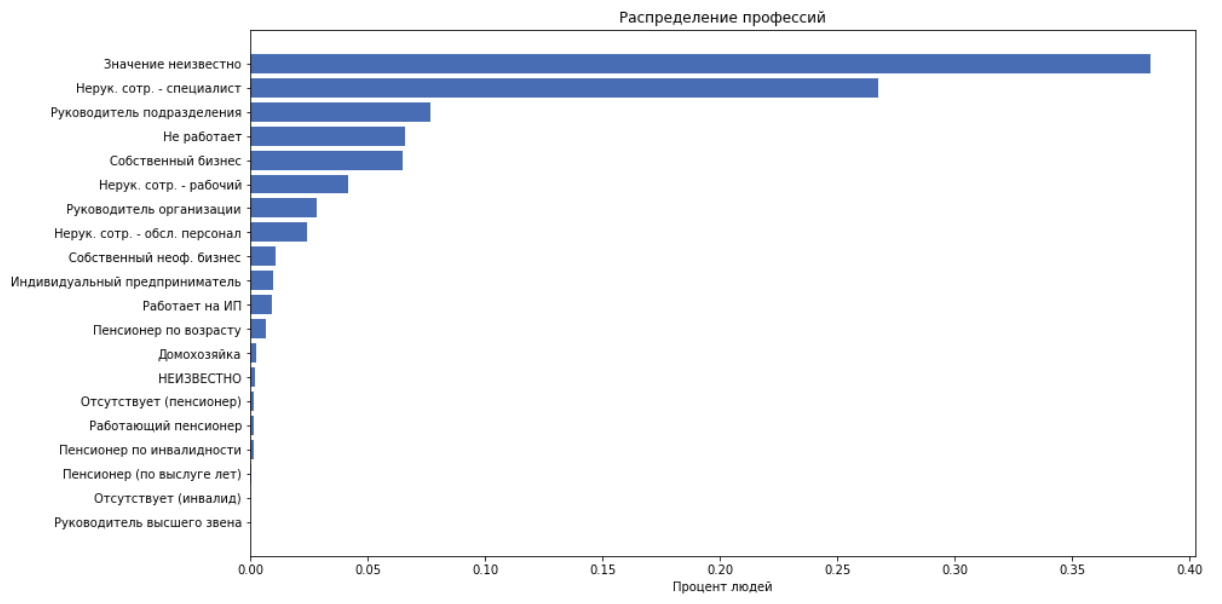
كمزايا نستخدم كل ما سبق باستثناء job_title ، لأن نحن نفترض أن job_position_cd يصف عادة موقف الشخص.
المعاملات

ما هو في الأصل:
- معرف المستخدم
- اليوم ، شهر المعاملة
- مبلغ المعاملة (بالتبادل بزيادات 250)
- merchant_id - معرف البنك الداخلي لتسجيل النقدية. كذلك لا تستخدم.
- merchant_mcc
مركز عملائي - رمز فئة التاجر. هذا هو رمز الخدمة الموحد المقدم من المستلم. هذه المعلومات مفتوحة ، إليك نسخة . يمكن تقسيم هذه الرموز إلى فئات ، على سبيل المثال: الترفيه ، الفنادق ، إلخ.
لكل عميل ، نقوم بمقارنة الميزات التالية:
- حساب مقدار النفقات ، متوسط الشيك ، الانحراف المعياري
- عدد المعاملات
- نقسم أكواد mcc إلى 20 فئة ، احسب عدد الأشخاص الذين أنفقوا أموالًا على هذه الفئة. احصل على 20 ميزة
- سنحصل على 20 ميزة أخرى بقسمة النفقات في الفئة على مقدار النفقات. أي الحصول على نسبة الأموال التي تنفق على هذه الفئة.
قصص
في المجموع ، لدينا 959 قصص.
ما هو في الأصل:
json يشبه هذا:

هذه عبارة عن شجرة عناصر ، حيث يتم وصف كل عنصر بالمفاتيح: ['guid' ، و 'type' ، و 'description' ، و 'Properties' ، و 'content']. يحتوي "المحتوى" على قائمة بالأطفال. القصة تتكون من صفحات. يتم إلقاء الخلفية والنص والصور على الصفحة. لم يكن لدينا مُنشئ للقصص ، واستخلاص كل هذا أمر صعب وليس حقيقة ، الأمر الذي سيساعد كثيراً في المستقبل.
يسحب النظاميون كل النص وحجم الخط المقابل. نستخرج الميزات التالية:
- عدد الصفحات ، الروابط ، إجمالي العناصر
- متوسط حجم خط النص
- عدد عناصر النص
- "حجم النص" هو مجريات الأمور للنظر بعناية في طول النص حسب حجم الخط.
حجم الكود رمزdef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- الآن لنأخذ النص بالكامل ، باستخدام dostoevsky ، نحدد دلالات النص: ["محايد" ، "سلبي" ، "تخطي" ، "خطاب" ، "إيجابي"]. وأضف هذا إلى 5 ميزات
رد فعل

ما هو في الأصل:
- معرف المستخدم والتاريخ
- الوقت
- رد فعل
نقوم بمعالجة الوقت وإضافة ميزات كميزات:
- يوم من أيام الأسبوع
- ساعة ، دقيقة
بعد ذلك ، ستتم إضافة مجموعة من الميزات استنادًا إلى بيانات ردود الفعل ، ولكن في الوقت الحالي ، سنخوض معركة مع ترسانة الميزات هذه لإنشاء خط أساسي.
الطريقة الأفضل التي استخدمتها القمة بأكملها هي ما يلي: نقوم بتقليل المشكلة إلى تصنيف متعدد الفئات ، أي: توقع احتمال كل رد فعل. نحن نعتبر توقع التقييم لهذه القصة :
Binarizuem :
- جوابنا للكائن والتي يمكن أن تأخذ على القيمة
نموذج
من البداية إلى النهاية ، اعتدت CatBoost. هذا يرجع إلى حقيقة أن CatBoost من خارج الصندوق يبني إحصائيات مفيدة للميزات الفئوية. والإحصاءات على المستخدم - إلى أي مدى يميل إلى ردود الفعل ، وإحصاءات عن التاريخ - كيف لا يتفاعلون في أغلب الأحيان ، هي أقوى الميزات في هذه المهمة.
يتم شرح كيفية عمل CatBoost مع الميزات الفئوية في الوثائق .
TLDR:
- يولد تباديل البيانات متعددة
- يذهب بالترتيب ويعني ترميز الهدف (mte) على تلك الكائنات التي رآها بالفعل
لفترة وجيزة حول معهد ماساتشوستس للتكنولوجيا في مثالنانحن نأخذ قيمة العلامة ، على سبيل المثال ، واحدة من customer_id ، ونحن نعتبر النسبة المئوية للحالات عندما كان رد فعل هذا العميل مثل ، يكره ، تخطي أو عرضها. نحصل على 4 أرقام. نستبدل customer_id بهذه الأرقام الأربعة ونستخدمها كعلامات. نحن نفعل هذا لكل عميل.
النتيجة الحالية
مع الميزات الحالية ، مع catbust غير محسنة ، على المتصدرين العامة في ذلك الوقت ، احتلت المركز الحادي عشر بنتيجة 0.31209
ميزات القاتل
في مرحلة ما ، ظهرت فرضية مفادها أن التطبيق قد يعرض قصصًا في كثير من الأحيان أو أقل اعتمادًا على كيفية تفاعل المستخدم معه مسبقًا. لنقم بعد ذلك بإضافة ميزات ستقول:
- كم مرة شاهد المستخدم السجل المطابق في الماضي / المستقبل ، خلال الشهر / اليوم / ساعة / الإجمالي
- الوقت منذ آخر عرض لنفس القصة
- الوقت الذي بعده يبحث المستخدم في المرة القادمة في نفس القصة
- في الواقع ، يقوم المستخدم بتحميل العديد من القصص دفعة واحدة في ثانية واحدة ، عادة حوالي 5-7. نسمي هذه المجموعة من القصص مجموعة . أضفت هذا العدد من القصص في المجموعة كميزة ، مما أعطى زيادة كبيرة في الجودة.
بالطبع ، هذه الميزات لا يمكن استخدامها في الإنتاج ، لأن لن يكونوا مبتذلون في وقت تطبيق النموذج ، ولكن بأي وسيلة جيدة في المنافسة.
لذلك ، يقال - القيام به. حصلت على 0.35657 على اليافطة.
تحسين النموذج
ذهبت من خلال المعلمات باستخدام التحسين بايزي
من المثير للاهتمام ، يمكننا أن نذكر المعلمة max_ctr_complexity ، المسؤولة عن الحد الأقصى لعدد الميزات الفئوية التي يمكن دمجها. مثال تحت المفسد.
مقتطف من الوثائقافترض أن الكائنات الموجودة في مجموعة التدريب تنتمي إلى ميزتين قاطعتين: النوع الموسيقي ("موسيقى الروك" ، "إيندي") والأسلوب الموسيقي ("الرقص" ، "الكلاسيكي"). يمكن أن تحدث هذه الميزات في مجموعات مختلفة. يمكن أن تنشئ CatBoost ميزة جديدة تمثل مزيجًا من تلك المدرجة ("صخرة الرقص" ، أو "الصخرة الكلاسيكية" ، أو "رقصة إيندي" ، أو "إيندي الكلاسيكية").
ملاحظات مثيرة للاهتمام
يمكن تدريب CatBoost على GPU ، مما يسرع عملية التعلم بشكل كبير ، ولكنه يقدم أيضًا العديد من القيود ، خاصة فيما يتعلق بالميزات الفئوية. في هذه المهمة ، أعطى التدريب على وحدة معالجة الرسومات نتائج أسوأ بكثير من وحدة المعالجة المركزية.
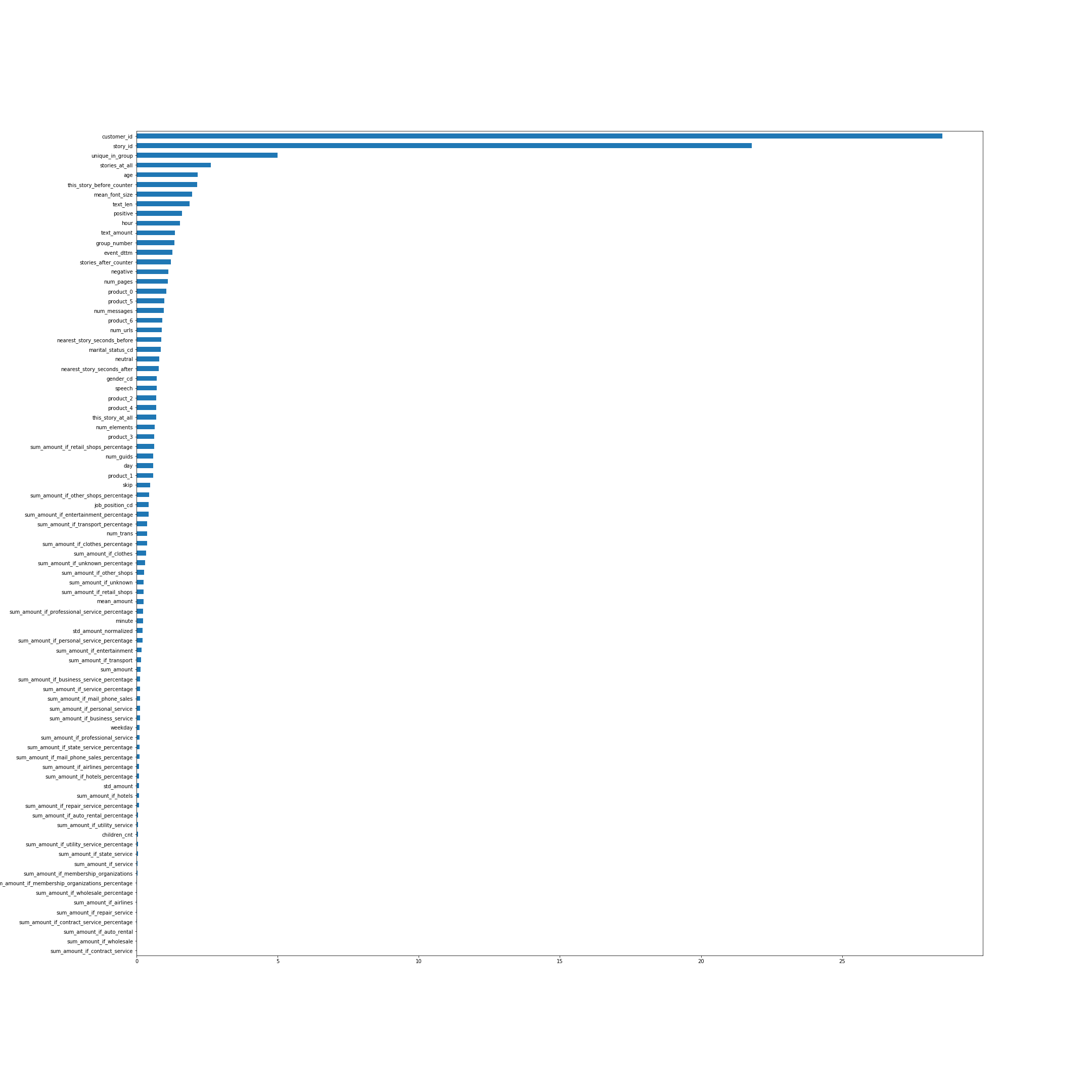
أهمية الميزات وفقا ل CatBoost. من نواح كثيرة ، تتحدث أسماء الميزات عن نفسها ، لكن بعضها ، وليس الأكثر وضوحًا من الأعلى ، سأشرح لك:
- unique_in_group - عدد القصص في المجموعة. (داخل المجموعة ، تكون دائمًا فريدة من نوعها ، في الوقت الذي تم فيه إنشاء الميزة لم أكن أعرف ذلك)
- story_at_all - عدد القصص التي شاهدها الشخص في المستقبل وفي الماضي.
- this_story_before_counter - كم مرة شاهد الناس هذه القصة من قبل.
- text_amount - هذا إرشادي مع حجم النص.
- group_number - الرقم التسلسلي للمجموعة.
- الأقرب /_الثواني_أمام / بعد - هذا هو الوقت المناسب حتى يتم عرض المجموعة التالية.
الصورة قابلة للنقر
دعونا نلقي نظرة على توزيع ردود الفعل مع مرور الوقت:

أي في مرحلة ما ، يختلف توزيع التفاعلات اختلافًا كبيرًا.
بعد ذلك ، أرغب في الحصول على بعض التأكيد بأن التوزيع في الاختبار هو نفسه كما في نهاية عينة التدريب. دعنا نرسل كل التنبؤات ، نحصل على النتيجة 0.00237. نحن نتوقع كل تلك الموجودة في الجزء الأخير من القطار - نحصل على حوالي 0.009 ، في الجزء الأول - حول -0.22. لذا فإن التوزيع على الاختبار هو نفسه على الأرجح في نهاية القطار وبالتأكيد لا يبدو الجزء الرئيسي. هذا يؤدي إلى فرضية أنه إذا تم تصحيح التوزيع في توقعاتنا ، فإن النتيجة على المتصدرين تتحسن كثيرا ، لأنه التوزيعات على القطار والاختبار مختلفة.
توقعات العتبة
في الخطوة الأخيرة من الحصول على التنبؤات النهائية ، أضف صراعا:
في النموذج الأخير ، حصلت على حوالي 66٪ من الوحدات ، إذا تم تسريبها باستخدام حاوية تراكمية تساوي 0. واتضح ذلك بالفعل ، فقد أدى انخفاض عدد +1 إلى زيادة قوية في الجودة. تم تقييم المباني الثلاثة الأخيرة فقط ، لذلك قمت بإرسال تنبؤات لأفضل طراز مع مختلف المهملات بحيث كانت النسبة المئوية زائد واحد حوالي 62 و 58 و 54.
نتيجة لذلك ، على أفضل المتصدرين ، كانت أفضل نتيجة هي 0.37970 .
نتائج المنافسة
حول المتصدرين العام / الخاصكما هو معتاد في مسابقات التعلم الآلي ، عندما ترسل تنبؤات إلى النظام ، يتم تقييم النتيجة فقط لجزء من عينة الاختبار بأكملها. عادة حوالي 30 ٪. تنعكس النتائج لهذا الجزء في المتصدرين العامة. بالنسبة لبقية الاختبار ، يتم تقييم النتيجة النهائية ، والتي يتم عرضها بعد نهاية المسابقة على ليدربورد خاص.
في نهاية المسابقة على المتصدرين العامين ، كان الوضع على النحو التالي:
- 0.382 - هنا يمكن أن يكون الإعلان الخاص بك
- 0.379 - أطفال ليشا
- 0.372 - بستاني
- 0.35 - كسول و akulov
على لوح المتصدرين الخاصين ، والذي تم بموجبه النظر في النتائج النهائية ، كنت محظوظًا وهبط الرجال لسبب ما من المركز الرابع إلى الرابع. هنا هو الموقف النهائي.
- 0.45807 أبناء ليشا
- 0.45264 البستانيين
- 0.44136 جوك
- 0.43704 هنا يمكن أن يكون الإعلان الخاص بك
- 0.43474 كسول و akulov
ما لم ينجح
- حاولت ترجمة كل النص من القصة إلى متجه باستخدام fasttext ، ثم تجميعت المتجهات واستخدمت رقم المجموعة كميزة مميزة. كانت هذه الميزة في المرتبة الثالثة (بعد story_id و customer_id) في أهمية ميزة CatBoost ، ولكن لسبب ما كانت مستقرة وتفاقمت بشكل كبير نتيجة التحقق من الصحة.
- بفضل المجموعات ، يمكن للمرء أن يجد قصصًا تتعلق بكأس العالم وكانت موجودة فقط في مجموعة التدريب.
ومع ذلك ، لم يؤدي إخراج هذه الكائنات من مجموعة البيانات إلى تحسين النتيجة. - بشكل افتراضي ، يولد CatBoost تباينات عشوائية من الكائنات وينظر في علامات الميزات الفئوية بناءً عليها. ولكن يمكننا أن نقول لل katbust أن لدينا وقت في البيانات - has_time = صحيح. بعد ذلك سوف يتم الترتيب ، دون خلط مجموعة البيانات. في هذه المشكلة ، على الرغم من أن لدينا وقتًا ، كانت النتيجة مع has_time أسوأ بثبات.
في الحالة العامة ، إذا كان هناك وقت ، ولكن لا ينبغي أن يؤخذ في الاعتبار عند إنشاء Mean Target Encoding ، فإن النموذج سوف يستخدم معلومات حول الإجابات الصحيحة من المستقبل ويمكن إعادة تدريبها. في هذه المشكلة ، على ما يبدو ، لم يكن لهذا تأثير كبير وكان من المهم تجاوز عدة مرات في التباديل المختلفة. - كانت هناك فكرة عن إعطاء وزن أكبر للأشياء في نهاية القطار ، أي أن تأخذ في الاعتبار المزيد من الكائنات مع التوزيع الصحيح لردود الفعل. ولكن على كل من التحقق من الصحة وعلى المتصدرين العامة أعطى هذا نتيجة أسوأ.
- يمكنك أن تأخذ في الاعتبار ردود الفعل المختلفة مع أوزان مختلفة أثناء التدريب. رغم أن هذا لم يتحسن بالنسبة لي ، إلا أنه ساعد بعض الفرق.
النتائج
تبين أن المنافسة كانت مثيرة للاهتمام ، لأنها جمعت العديد من المكونات ، مثل البيانات الجدولية والنصوص والصور. كان هناك مساحة كبيرة للبحث ، والكثير الذي لا يزال من الممكن تجربته. بشكل عام ، لم يكن لدي للحصول على الملل.
شكرا لمنظمي المسابقة!
يتم نشر كل رمز على جيثب .