بدأت Redash مؤخرًا في التغيير من نظام تنفيذ مهمة إلى آخر. وهي ، بدأوا الانتقال من الكرفس إلى RQ. في المرحلة الأولى ، تم نقل المهام التي لا تنفذ طلبات مباشرة إلى النظام الأساسي الجديد. من بين هذه المهام إرسال رسائل بريد إلكتروني ، وتحديد الطلبات التي ينبغي تحديثها وتسجيل أحداث المستخدم والمهام الداعمة الأخرى.

بعد نشر كل هذا ، لوحظ أن عمال RQ يحتاجون إلى موارد حوسبية أكثر بكثير لحل نفس حجم المهام التي اعتاد سيلري حلها.
المواد ، التي نُنشر اليوم ترجمة لها ، مكرسة لقصة كيف اكتشف Redash سبب المشكلة وتعامل معها.
بضع كلمات عن الاختلافات بين الكرفس و RQ
الكرفس و RQ لديها مفهوم العمال العملية. كل من هناك وهناك لتنظيم التنفيذ الموازي للمهام باستخدام إنشاء الشوك. عند بدء تشغيل عامل Celery ، يتم إنشاء العديد من عمليات الشوكة ، كل منها تقوم بمعالجة المهام بشكل مستقل. في حالة RQ ، يحتوي مثيل العامل على عملية فرعية واحدة فقط (تُعرف باسم "العمود الفقري") ، والتي تؤدي مهمة واحدة ثم يتم إتلافها. عندما يقوم العامل بتنزيل المهمة التالية من قائمة الانتظار ، فإنه ينشئ "العمود الفقري" الجديد.
عند العمل مع RQ ، يمكنك تحقيق نفس مستوى التوازي مع العمل مع Celery ، ببساطة عن طريق تشغيل المزيد من العمليات المنفذة. ومع ذلك ، هناك فرق واحد دقيق بين الكرفس و RQ. في Celery ، ينشئ العامل العديد من حالات العمليات الفرعية عند بدء التشغيل ، ثم يستخدمها بشكل متكرر لإكمال العديد من المهام. وفي حالة RQ ، لكل وظيفة تحتاج إلى إنشاء شوكة جديدة. كلا النهجين لهما إيجابيات وسلبيات ، ولكن هنا لن نتحدث عن هذا.
قياس الأداء
قبل أن بدأت التوصيف ، قررت أن أقيس أداء النظام من خلال معرفة المدة التي تحتاجها حاوية العامل لمعالجة 1000 وظيفة. قررت التركيز على مهمة
record_event ، لأن هذه عملية خفيفة الوزن شائعة. لقياس الأداء ، وأنا استخدم الأمر
time . هذا يتطلب اثنين من التغييرات على رمز المشروع:
- لقياس أداء أداء 1000 مهمة ، قررت استخدام وضع الدُفعات RQ ، حيث يتم إنهاء العملية بعد معالجة المهام.
- أردت تجنب التأثير على قياساتي بمهام أخرى ربما كان من المقرر إجراؤها في الوقت الذي كنت أقيس فيه أداء النظام. لذلك قمت بنقل
record_event إلى قائمة انتظار منفصلة تسمى benchmark ، واستبدال @job('default') بـ @job('benchmark') . تم ذلك قبل record_event في tasks/general.py .
الآن كان من الممكن بدء القياسات. بالنسبة للمبتدئين ، كنت أرغب في معرفة المدة التي يستغرقها بدء العامل وإيقافه دون تحميل. هذه المرة يمكن طرحها من النتائج النهائية التي تم الحصول عليها في وقت لاحق.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
استغرق الأمر 14.7 ثانية لتهيئة العامل على جهاز الكمبيوتر الخاص بي. أتذكر ذلك.
ثم وضعت 1000
record_event اختبار
record_event في قائمة الانتظار
benchmark :
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
بعد ذلك ، بدأت تشغيل النظام بنفس الطريقة التي بدأت بها من قبل ، واكتشفت كم من الوقت يستغرق لمعالجة 1000 وظيفة.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
بطرح 14.7 ثانية مما حدث ، اكتشفت أن 4 عمال يعالجون 1000 مهمة في 102 ثانية. الآن دعونا نحاول معرفة سبب ذلك. للقيام بذلك ، ونحن ، بينما العمال مشغولون ،
py-spy باستخدام
py-spy .
جانبي
نضيف 1000 مهمة أخرى إلى قائمة الانتظار (يجب أن يتم ذلك بسبب حقيقة أنه خلال القياسات السابقة تمت معالجة جميع المهام) ، وقم بتشغيل العمال وتجسس عليهم.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
أعلم أن الفريق السابق كان طويلاً. من الناحية المثالية ، من أجل تحسين قابلية قراءتها ، يجدر بك تقسيمها إلى أجزاء منفصلة ، وتقسيمها في تلك الأماكن التي توجد بها سلاسل من الأحرف
&& . ولكن يجب تنفيذ الأوامر بالتسلسل في نفس جلسة
docker-compose exec worker bash التنفيذ
docker-compose exec worker bash ، بحيث يبدو كل شيء هكذا. فيما يلي وصف لما يفعله هذا الأمر:
- تطلق 4 عمال دفعة في الخلفية.
- ينتظر 15 ثانية (يلزم تقريبًا الكثير لإكمال التنزيل).
- يثبت
py-spy . - يعمل
rq-info ويكتشف PID لأحد العمال. - يسجل معلومات حول عمل العامل مع PID الذي تم استلامه مسبقًا لمدة 10 ثوانٍ ويحفظ البيانات في ملف
profile.svg
نتيجة لذلك ، تم الحصول على "الجدول الناري" التالي.
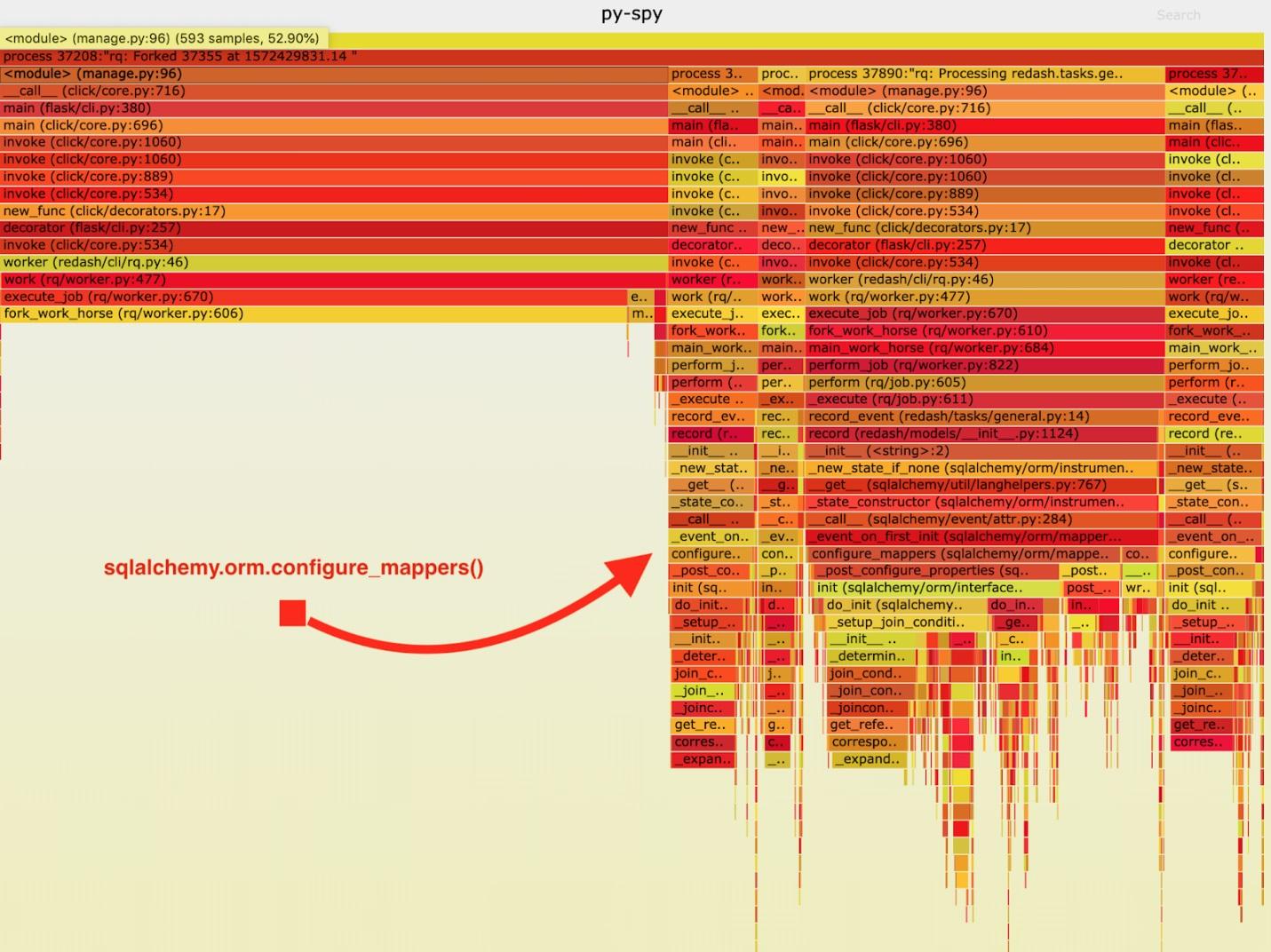 تصور البيانات التي تم جمعها بواسطة py-spy
تصور البيانات التي تم جمعها بواسطة py-spyبعد تحليل هذه البيانات ، لاحظت أن مهمة
record_event تقضي وقتًا طويلاً في تشغيلها في
sqlalchemy.orm.configure_mappers . يحدث هذا خلال كل مهمة. من الوثائق التي تعلمتها أنه في الوقت الذي يهمني ، تتم تهيئة علاقات جميع المخططين الذين تم إنشاؤها مسبقًا.
هذه الأشياء ليست مطلوبة على الإطلاق لتحدث مع كل شوكة. يمكننا تهيئة العلاقة مرة واحدة في العامل الأصل وتجنب تكرار هذه المهمة في "workhorses".
نتيجةً لذلك ، أضفت مكالمة إلى
sqlalchemy.org.configure_mappers() إلى الكود قبل بدء "العمود الفقري" وأخذت القياسات مرة أخرى.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
إذا قمت بطرح 14.7 ثانية من هذه النتائج ، اتضح أننا قمنا بتحسين الوقت اللازم لـ 4 عمال لمعالجة 1000 مهمة من 102 ثانية إلى 24.6 ثانية. هذا هو تحسين الأداء أربعة أضعاف! بفضل هذا الإصلاح ، تمكنا من مضاعفة موارد إنتاج RQ أربعة أضعاف والحفاظ على نفس النطاق الترددي للنظام.
النتائج
من هذا كله ، توصلت إلى الاستنتاج التالي: تجدر الإشارة إلى أن التطبيق يتصرف بشكل مختلف إذا كانت العملية الوحيدة ، وإذا كان الأمر يتعلق بالشوكة. إذا كان من الضروري خلال كل مهمة حل بعض المهام الرسمية الصعبة ، فمن الأفضل حلها مسبقًا ، بعد القيام بذلك مرة واحدة قبل اكتمال الشوكة. لا يتم اكتشاف مثل هذه الأشياء أثناء الاختبار والتطوير ، لذلك ، بعد أن شعرت بوجود خطأ في المشروع ، وقياس سرعته والوصول إلى النهاية أثناء البحث عن أسباب مشاكل أدائه.
أعزائي القراء! هل واجهت مشاكل في الأداء في مشاريع بيثون يمكنك حلها عن طريق تحليل نظام العمل بعناية؟
