في الآونة الأخيرة ،
تم عقد تحدي ID R&D Voice Antispoofing ، وكانت مهمته الرئيسية هي إنشاء خوارزمية يمكنها التمييز بين الصوت البشري والسجل المركب (محاكاة ساخرة). أنا ML باحث في Dasha AI وأعمل كثيرًا على التعرف على الكلام ، لذلك قررت المشاركة. جنبا إلى جنب مع الفريق اتخذنا المركز الأول. تحت الخفض ، سأتحدث عن أساليب جديدة رائعة لمعالجة الصوت ، وكذلك عن الصعوبات والشذوذات التي واجهناها.
شارك 98 شخصًا في المسابقة - يوجد عدد قليل جدًا من الأشخاص لأن هذه مسابقة لمعالجة الصوت ، وعلى نظام أساسي روسي ، وحتى في منصة شحن. كنت في فريق مع ديمتري دانيفسكي ، Kaggle Master ، الذي قابلناه ووافق على المشاركة أثناء مناقشة المناهج في مسابقة أخرى.
مهمة
لقد حصلنا على 5 جيجابايت من الملفات الصوتية ، مقسمة إلى فصول محاكاة ساخرة / بشرية ، وكان علينا أن نتنبأ باحتمالية الفصل ، ولفه في عامل ميناء وإرساله إلى الخادم. كان من المفترض أن يعمل الحل في 30 دقيقة ويزن أقل من 100 ميجابايت. وفقًا للمعلومات الرسمية ، كان من الضروري التمييز بين صوت الشخص والصوت الذي يتم إنشاؤه تلقائيًا - على الرغم من أنني شخصياً بدا لي أن فئة محاكاة ساخرة تضمنت أيضًا حالات تم فيها إنشاء الصوت عن طريق تعليق السماعة على الميكروفون (كما يفعل المهاجمون بسرقة تسجيل صوت شخص آخر لتحديد هويته).
كان المتري
EER :
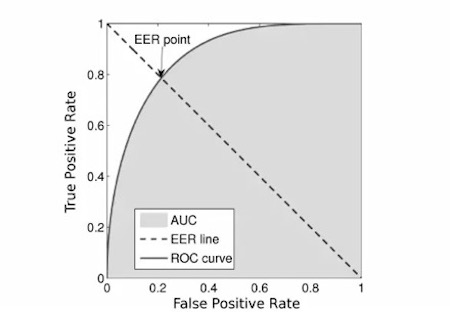
أخذنا
الكود الأول الذي ظهر عبر الشبكة ، لأن
رمز المنظمين بدا مثقلًا.
منافسة
قدم المنظمون خط الأساس وفي الوقت نفسه اللغز الرئيسي للمنافسة. كان الأمر بسيطًا مثل العصا: نحن نأخذ الملفات الصوتية ، ونعد
الطيفية الطيفية ، ونقوم بتدريب MobileNetV2 ونجد أنفسنا في مكان ما حول المركز الثاني عشر أو أقل. لهذا السبب ، اعتقد الكثيرون أن عشرات الأشخاص شاركوا في المسابقة ، لكن هذا لم يكن كذلك. المرحلة الأولى بأكملها من المسابقة ، لم يتمكن فريقنا من كسر هذا الخط الأساسي. أعطت الشفرة المتطابقة بشكل مثالي النتيجة أكثر سوءًا ، وساعدت أي تحسينات (مثل الاستبدال بشبكات أثقل وتنبؤات
OOF ) ، لكنها لم تصل بها إلى خط الأساس.
ثم حدث ما هو غير متوقع: قبل حوالي أسبوع من نهاية المسابقة ، اتضح أن تنفيذ مقاييس المنظمين احتوى على خطأ واعتمد على ترتيب التنبؤات. في نفس الوقت تقريبًا ، وجد أنه في حاويات السفن ، لم يقم المنظمون بإيقاف تشغيل الإنترنت ، لذا قام العديد منهم بتنزيل عينة الاختبار. ثم تم تجميد المسابقة لمدة 4 أيام ، وقمت بتصحيح المقياس وتحديث البيانات وإيقاف تشغيل الإنترنت وبدأت مرة أخرى لمدة أسبوعين آخرين. بعد إعادة فرز الأصوات ، كنا في المركز السابع مع واحدة من الطلبات الأولى لدينا. كان هذا بمثابة حافز قوي لمواصلة المشاركة في المسابقة.
الحديث عن النموذج
استخدمنا شبكة ملتوية تشبه resnet تدربت على الطيفية الطباشير.
- كان هناك خمس كتل من هذا القبيل في المجموع ، وبعد كل كتلة من هذه المجموعات ، قمنا بالإشراف العميق وزادنا عدد المرشحات بمقدار مرة ونصف.
- خلال المسابقة ، انتقلنا من التصنيف الثنائي إلى تصنيف متعدد الطبقات من أجل الاستفادة بشكل أكثر كفاءة من تقنية مزيج ، حيث نمزج بين صوتين ونلخص ملصقات الفئات الخاصة بهم. بالإضافة إلى ذلك ، بعد هذا الانتقال ، تمكنا من زيادة احتمال فئة محاكاة ساخرة بشكل مصطنع بضربها في 1.3. وقد ساعدنا ذلك ، نظرًا لوجود افتراض أن توازن الفصول في عينة الاختبار قد يختلف عن التدريب ، وبالتالي قمنا بتحسين جودة النماذج.
- تم تدريب نماذج الطية ، وبلغ متوسط توقعات العديد من النماذج.
- جاء تقنية تشفير التردد أيضًا في متناول يدي. خلاصة القول هي: تشابك ثنائي الأبعاد غير ثابت للموضع ، وفي القيم الطيفية تكون للقيم على طول المحور العمودي معاني مادية مختلفة للغاية ، لذلك نود نقل هذه المعلومات إلى النموذج. للقيام بذلك ، قمنا بربط السلسلة الطيفية والمصفوفة ، التي تتكون من أرقام في شريحة من -1 إلى 1 من أسفل إلى أعلى.
من أجل الوضوح ، سأقدم الرمز:
n, d, h, w = x.size() vertical = torch.linspace(-1, 1, h).view(1, 1, -1, 1) vertical = vertical.repeat(n, 1, 1, w) x = torch.cat([x, vertical], dim=1)
- قمنا بتدريب كل هذا ، بما في ذلك على البيانات ذات العلامات الزائفة من عينة اختبار تسربت من المرحلة الأولى.
التحقق من صحة
منذ بداية المسابقة ، تعذّب جميع المشاركين على السؤال التالي: لماذا يعطي التحقق من الصحة المحلي EER 0.01 أو أقل ، ولوحة المتصدرين 0.1 ولا ترتبط بشكل خاص؟ كان لدينا فرضيتين: إما أن هناك تكرارات في البيانات ، أو تم جمع بيانات التدريب على مجموعة واحدة من مكبرات الصوت ، واختبار البيانات على مجموعة أخرى.
كانت الحقيقة في مكان ما بينهما. في بيانات التدريب ، تبين أن حوالي 5٪ من البيانات مكررة ، وهذا يعد فقط التكرارات الكاملة للتجزئة (بالمناسبة ، يمكن أن يحتوي أيضًا على مجموعة مختلفة من نفس الملف ، لكن ليس من السهل التحقق - ولهذا السبب لم نكن نتحقق منه).
لاختبار الفرضية الثانية ، قمنا بتدريب شبكة معرف اللغة ، وتلقينا حفلات زفاف لكل متحدث ، وقمنا بتجميعها جميعًا بوسائل k ، وقمنا بطبقة مطوية هذه المجموعات. وهي تدربنا على متحدثين من مجموعة واحدة وتوقعنا متحدثين من الآخرين. لقد بدأت طريقة التحقق من الصحة هذه بالفعل في الارتباط بلوحة المتصدرين ، على الرغم من أنها أظهرت درجة أفضل 3-4 مرات. كبديل ، حاولنا التحقق من صحة فقط على التنبؤات التي كان فيها النموذج على الأقل غير متأكد ، أي أن الفرق بين التنبؤ وعلامة التصنيف كان> 10 ** - 4 (0.0001) ، لكن مثل هذا المخطط لم يحقق نتائج.
وما لم تنجح؟
على شبكة الإنترنت ، يكفي العثور على آلاف الساعات من الكلام البشري. بالإضافة إلى ذلك ، عقدت مسابقة مماثلة بالفعل منذ عدة سنوات. لذلك ، بدا من الواضح أنه يمكنك تنزيل الكثير من البيانات (قمنا بتنزيل ~ 300 جيجابايت) وتدريب المصنف على هذا. في بعض الحالات ، أثبت التدريب على هذه البيانات بعض الشيء إذا قمنا بتدريس بيانات إضافية وعلى بيانات القطار قبل الوصول إلى هضبة ، وبعد ذلك قمنا بالتدريب فقط على بيانات التدريب. ولكن مع هذا المخطط ، التقى النموذج في حوالي يومين ، مما يعني 10 أيام لجميع الطيات. لذلك ، تخلينا عن هذه الفكرة.
بالإضافة إلى ذلك ، لاحظ العديد من المشاركين وجود علاقة بين طول الملف والفئة ؛ ولم يلاحظ هذا الارتباط في عينة الاختبار. شبكات الصور العادية مثل resnext و nasnet-mobile و mobileNetV3 لم تظهر بشكل جيد للغاية.
خاتمة
لم يكن الأمر سهلاً وغريبًا في بعض الأحيان ، ولكن لا يزال لدينا تجربة رائعة وتصدرنا. من خلال التجربة والخطأ ، أدركت الطرق التي تعمل بشكل جيد والتي ليست جيدة جدًا. الآن سوف تستخدم هذه الأفكار معنا عند معالجة الصوت. أعمل بجد من أجل الارتقاء بمستوى الذكاء الاصطناعي التحادثي إلى مستوى لا يمكن تمييزه عن الإنسان ، وبالتالي دائمًا في البحث عن مهام وشرائح مثيرة للاهتمام. أتمنى أن تكون قد تعلمت شيئًا جديدًا.
حسنًا ، أخيرًا ، أنشر
الرمز الخاص بنا .