اليوم نريد أن نتحدث عن مفهوم Insight-Driven وكيفية وضعها موضع التنفيذ باستخدام DataOps و ModelOps. يعد أسلوب Insight-Driven موضوعًا شاملاً نتحدث عنه بالتفصيل في مكتبتنا التي تم إنشاؤها مؤخرًا للمواد المفيدة حول إدارة البيانات (سيكون الرابط أدناه). في habratopica اليوم ، سوف نركز على المراحل الرئيسية من دورة حياة نماذج التعلم الآلي ، كذلك هذا هو واحد من الموضوعات الرئيسية داخل المفهوم.

ما هو جوهر مقاربة البصيرة
لقد تحدث العديد من الخبراء عن أهمية "تشغيل
البيانات" لفترة طويلة ، وهو بالطبع صحيح تمامًا بشكل عام ، لأن هذا النهج ينطوي على جعل قرارات الإدارة أكثر فاعلية من خلال تحليل البيانات ، وليس فقط تجربة الحدس والقيادة الشخصية.
يلاحظ محللو Forrester أن الشركات التي تعتمد على تحليل البيانات في أنشطتها تنمو بمعدل 30 ٪ في المتوسط أسرع من المنافسين.
لكننا ندرك جميعًا أن الشركة تمضي قدمًا ليس من توفر البيانات على هذا النحو ، ولكن من القدرة على العمل معها - أي لإيجاد رؤى يمكن تحقيق الدخل منها ، والتي تستحق تجميع البيانات ومعالجتها وتحليلها. لذلك ، نحن نتحدث بالتحديد عن نهج Insight-Driven ، كإصدار أكثر تقدماً من Data-Driven.
في معظم الأحيان ، عندما يتعلق الأمر بالعمل مع البيانات ، فإن معظم المتخصصين يعنيون في المقام الأول المعلومات المنظمة داخل الشركة ، ومع ذلك ، منذ وقت ليس ببعيد تحدثنا عن سبب عدم استخدام الغالبية العظمى من الأعمال حوالي 80 ٪ من البيانات المتاحة المحتملة. تنشئ Insight-Driven أساسًا لتكملة الصورة بمعلومات غير منظمة خارجية ، وكذلك نتائج تفسير البيانات للبحث عن التبعيات الضمنية بينها.
الرابط الموعود بمكتبة كاملة من المواد حول إدارة البيانات ، حيث يوجد الفيديو المذكور حول البيانات غير المستخدمة.
DevOps + DataOps + ModelOps
تعتمد ممارسات Insight-Driven على DevOps و DataOps و ModelOps. دعنا نتحدث عن سبب تمكن مجموعة من هذه الممارسات الخاصة من ضمان التنفيذ الكامل للنهج.
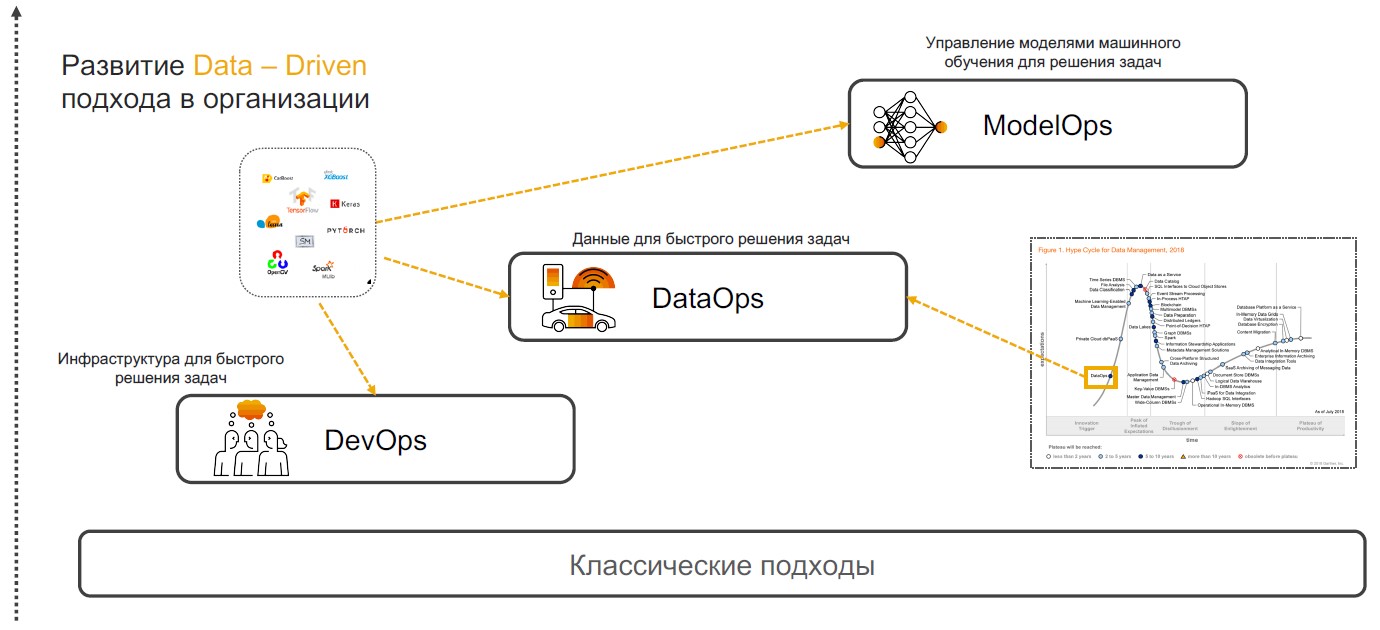 DevOps + DataOps
DevOps + DataOps . تتضمن DevOps تقليل وقت إصدار المنتج وتحديثاته وتقليل تكلفة الدعم الإضافي إلى الحد الأدنى من خلال استخدام أدوات للتحكم في الإصدار والتكامل المستمر والاختبار والمراقبة وإدارة الإصدار. إذا أضفنا إلى هذه الممارسات فهمًا للبيانات الموجودة داخل الشركة ، وكيفية إدارة التنسيق والهيكل والعلامة وجودة
التتبع والتحويل والتجميع ولدينا القدرة على التحليل والتصور بسرعة ،
فسنحصل على
DataOps . ينصب تركيز هذا النهج على تنفيذ سيناريوهات باستخدام نماذج التعلم الآلي التي توفر دعم القرار والبحث عن البصيرة والتنبؤ.
ModelOps . بمجرد أن تبدأ الشركة في استخدام نماذج التعلم الآلي بفعالية ، يصبح من الضروري إدارتها ومراقبة مقاييس الجودة وإعادة التدريب والمقارنة والتحديث والإصدار. ModOps هي مجموعة من الممارسات والأساليب التي تبسط إدارة دورة الحياة لمثل هذه النماذج. يتم استخدامه من قبل الشركات التي تتعامل مع عدد كبير من النماذج في مختلف مجالات العمل ، على سبيل المثال ، خدمات البث.
إن تطبيق نهج Insight-Driven في الشركة ليس مهمة تافهة. ولكن بالنسبة لأولئك الذين ما زالوا يرغبون في بدء العمل معه ، سنخبرك بكيفية القيام بذلك.
البحث وإعداد البيانات
يبدأ تطبيق ممارسات Insight-Driven بالبحث عن البيانات وإعدادها. في وقت لاحق يتم تحليلها واستخدامها لبناء نماذج من MOs ، ولكن تم تحديد الحالات من قبل في أي خوارزميات ذكية يمكن أن تكون مفيدة.
تعريف المهام . في هذه المرحلة ، تحدد الشركة أهداف العمل ، على سبيل المثال ، زيادة الأرباح في السوق. بعد ذلك ، يتم تحديد مقاييس العمل لتحقيقها ، مثل زيادة عدد العملاء الجدد ، وحجم الفحص المتوسط ، والنسبة المئوية للتحويل. لذلك هناك سيناريوهات يمكن من خلالها البحث عن البيانات ذات الصلة.
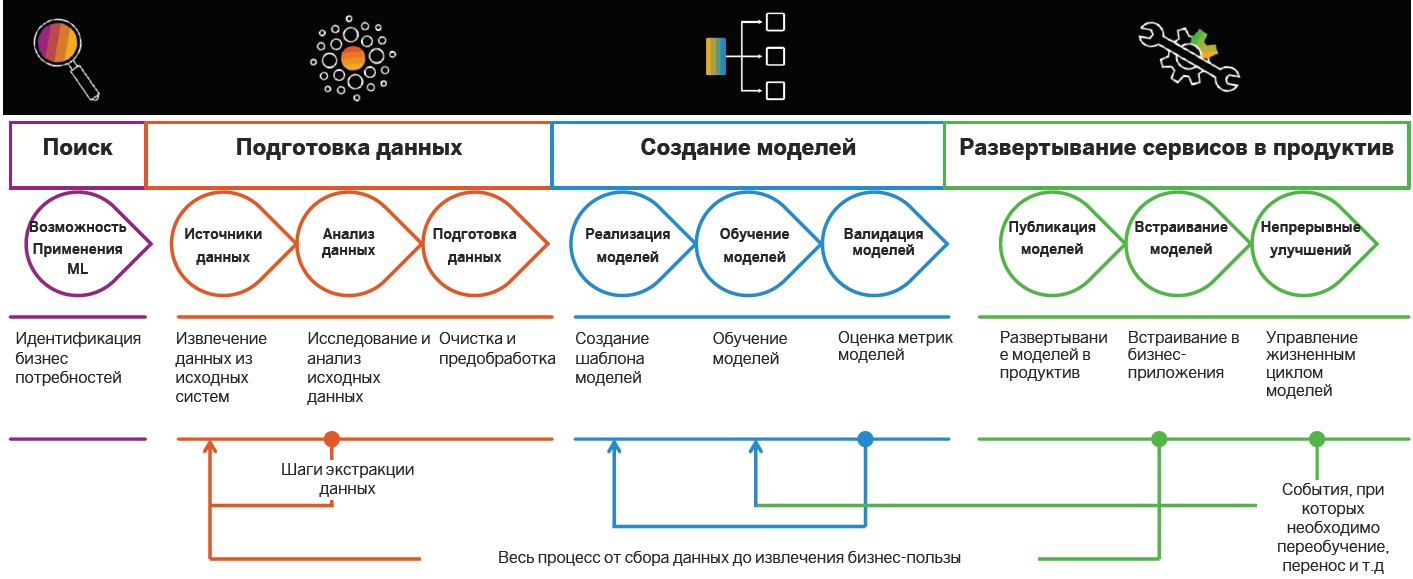 تحديد المصادر وتحليل البيانات
تحديد المصادر وتحليل البيانات . عندما يتم تحديد الأهداف والاتجاهات لاسترجاع البيانات ، فقد حان الوقت لتحليل المصادر. هذا والمراحل اللاحقة لتطوير سيناريوهات ذكية تتعلق بالإعداد
تأخذ 70-80 ٪ من ميزانيات الشركات في التنفيذ. الحقيقة هي أن جودة مجموعة البيانات تؤثر على دقة نماذج تعلم الآلة المصممة. لكن المعلومات الضرورية غالبًا ما تكون "منتشرة" عبر أنظمة مختلفة - يمكن أن تكمن في قواعد البيانات العلائقية ، مثل MS SQL و Oracle و PostgreSQL ، على منصة Hadoop والعديد من المصادر الأخرى. وفي هذه المرحلة ، تحتاج إلى فهم موقع البيانات ذات الصلة وكيفية جمعها.
في كثير من الأحيان ، يقوم المحللون بتفريغ ومعالجة كل شيء يدويًا ، مما يؤدي إلى إبطاء العمليات إلى حد كبير ويزيد من مخاطر الأخطاء. نحن في SAP نقدم لعملائنا تطبيق نظام التعريف الذي يتصل بالمصادر الصحيحة ويجمع البيانات عند الطلب.
لذلك ، يمكنك فهرسة جميع الجداول والتجمعات الخارجية مع بيانات غير منظمة ومصادر أخرى - تعيين علامات (بما في ذلك التدرجات الهرمية) وجمع المعلومات ذات الصلة بسرعة. بشرط ، إذا كانت المعلومات الموجودة على العميل تكمن في قواعد بيانات مختلفة ، فهذا يكفي للإشارة إلى هذه الكيانات. في المرة القادمة التي تحتاج فيها إلى "مجموعة بيانات العميل" ، ستختار عرضًا جاهزًا.
بمجرد تحديد مصادر البيانات ، يمكنك الانتقال
إلى تتبع جودة البيانات والتوصيف . هذه العملية ضرورية لفهم عدد الثغرات والقيم الفريدة والتحقق من الجودة الإجمالية للبيانات. لهذا كله ، يمكنك إنشاء لوحات معلومات مع قواعد وتتبع أي تغييرات.
تحويل البيانات . والخطوة التالية هي العمل المباشر مع البيانات التي ينبغي أن تحل المهام. للقيام بذلك ، يتم مسح البيانات: محددة ، مكررة ، وتملأ الفجوات. يمكن تبسيط هذه العملية من خلال البرمجة المستندة إلى التدفق. في هذه الحالة ، نحن نتعامل مع سلسلة من العمليات - خط أنابيب. يمكن إرسال ناتجه إلى واجهة رسومية أو نظام آخر للعمل اللاحق. هنا ، يتم تجميع معالجات البيانات كمنشئ (واعتمادًا على السيناريو). يمكن أن يكون هذا معالجة دورية أو متدفقة ، أو خدمة REST.

يعد مفهوم البرمجة المعتمدة على التدفق مناسبًا لحل مجموعة واسعة من المهام: بدءًا من التنبؤ بالمبيعات وتقييم جودة الخدمة إلى إيجاد أسباب التدفق الخارجي للعملاء. هناك أداتان للبحث عن البيانات وإعدادها في SAP. الأول هو
SAP Data Intelligence لمحللي البيانات. بخلاف الأنظمة الأساسية المماثلة ، يعمل هذا الحل مع البيانات الموزعة ولا يحتاج إلى مركزية - فهو يوفر بيئة موحدة لتنفيذ النماذج ونشرها وتكاملها وتوسيع نطاقها ودعمها. الأداة الثانية هي
SAP Agile Data Preparation ، وهي خدمة صغيرة لإعداد البيانات تستهدف المحللين ومستخدمي الأعمال. لديه واجهة بسيطة تساعد على جمع معلومات مجموعة ، تصفية ، معالجة وخريطة المعلومات. يمكن نشره في عرض لنقل Self-Service BI - أنظمة الخدمة الذاتية لإنشاء سيناريوهات تحليلية (لا تتطلب معرفة متعمقة في مجال علم البيانات).
خلق نموذج
بعد الإعداد ، حان دور إنشاء نماذج للتعلم الآلي. هنا تتميز: البحوث والنماذج والإنتاجية. تتضمن المرحلة الأخيرة تنفيذ خطوط أنابيب للتدريب وتطبيق النماذج.
البحوث والنماذج . حاليا ، هناك العديد من الأطر المواضيعية والمكتبات المتاحة. الشركة الرائدة في تواتر الاستخدام هما TensorFlow و PyTorch ، اللتان زادت شعبيتهما على مدار العام الماضي بنسبة 243٪. تتيح لك منصة SAP استخدام أي من هذه الأطر ويمكن أن تستكمل بمرونة مع مكتبات مثل CatBoost من Yandex و LightGBM من Microsoft و scikit-learn و pandas. لا يزال بإمكانك استخدام
HANA DataFrame في مكتبة hanaml. يحاكي هذا الباندا API ، و HANA يتيح لك معالجة كميات كبيرة من البيانات باستخدام "الحوسبة كسول".
لنماذج النماذج ، نحن نقدم Jupyter Lab. هذه أداة مفتوحة المصدر لمحترفي علوم البيانات. لقد بنيناها في نظام SAP البيئي ، مع توسيع نطاق الوظيفة. يعمل Jupyter Lab في النظام الأساسي Data Intelligence وبسبب مكتبة sapdi المدمجة ، يمكنه الاتصال بأي مصادر بيانات متصلة في الخطوات السابقة ومراقبة التجارب ومقاييس الجودة لمزيد من التحليل.
بشكل منفصل ، تجدر الإشارة إلى أن دفاتر الملاحظات ومجموعات البيانات
وأنابيب التدريب والتدريب بالإضافة إلى خدمات نشر النماذج يجب أن تكون متسقة. لدمج كل هذه الكائنات ، استخدم البرنامج النصي ML (كائن مُصدّر).
التدريب النموذجي . هناك خياران للعمل مع البرامج النصية ML. هناك نماذج لا تحتاج إلى تدريب على الإطلاق. على سبيل المثال ، في SAP Data Intelligence ، نقدم أنظمة التعرف على الوجوه ، والترجمة التلقائية ، التعرف الضوئي على الحروف (التعرف الضوئي على الحروف) وغيرها. انهم جميعا العمل من خارج منطقة الجزاء. من ناحية أخرى ، هناك تلك النماذج التي تحتاج إلى تدريب وإنتاجية. يمكن أن يحدث هذا التدريب في كل من مجموعة Data Intelligence نفسها وعلى موارد الحوسبة الخارجية المتصلة فقط طوال مدة العمليات الحسابية.
توجد منصة Kubernetes "تحت الغطاء" في SAP Data Intelligence ، لذا فإن جميع المشغلين مرتبطون بحاويات الإرساء. للعمل مع النموذج ، يكفي وصف ملف عامل ميناء وإرفاق علامات به للمكتبات والإصدارات المستخدمة.
هناك طريقة أخرى لإنشاء النماذج وهي استخدام AutoML. هذه هي نظم MO الآلي. يتم تطوير هذه الأدوات بواسطة
H2O و
Microsoft و
Google وما إلى ذلك. انهم يعملون
في هذا الاتجاه
في معهد ماساتشوستس للتكنولوجيا . لكن مهندسي الجامعة لا يركزون على التضمين والإنتاجية. يحتوي SAP أيضًا على نظام AutoML يركز على نتائج سريعة. تعمل في HANA وتتمتع بوصول مباشر إلى البيانات - فهي لا تحتاج إلى نقلها أو تعديلها في أي مكان. الآن نقوم بتطوير حل يركز على جودة النماذج - سنعلن عن إصدار لاحقًا.
إدارة دورة الحياة . تتغير الظروف ، وتصبح المعلومات قديمة ، وبالتالي تنخفض دقة نماذج MO بمرور الوقت. وفقًا لذلك ، وبعد تجميع البيانات الجديدة ، يمكننا إعادة تدريب النموذج وصقل النتائج. على سبيل المثال ،
يستخدم أحد كبار منتجي المشروبات معلومات تفضيل المستهلك في 200 دولة مختلفة لإعادة تدريب الأنظمة الذكية. تأخذ الشركة في الاعتبار أذواق الناس ، وكمية السكر ، ومحتوى السعرات الحرارية من المشروبات ، وحتى المنتجات التي توفرها العلامات التجارية المنافسة في الأسواق المستهدفة. تحدد نماذج MO تلقائيًا أيًا من مئات المنتجات التي ستقبلها الشركة بشكل أفضل في منطقة معينة.
 إعادة استخدام المكونات المعتمدة على الوكيل في SAP Data Hub
إعادة استخدام المكونات المعتمدة على الوكيل في SAP Data Hubولكن هناك حاجة أيضًا إلى عمل نماذج الإصدار والتحديث عند إصدار تحديثات جديدة للخوارزميات وتحديث مكونات الأجهزة. يمكن أن يؤدي تنفيذها إلى تحسين دقة وجودة النماذج المستخدمة في العمل.
البصيرة مدفوعة لنمو الأعمال
إن النهج المتبع في إدارة مراحل دورة حياة نماذج تعلم الآلة الموضحة أعلاه هو ، في الواقع ، إطار عمل عالمي يسمح للشركة بأن تصبح مستندة إلى البصيرة واستخدام العمل مع البيانات كمحرك رئيسي لنمو الأعمال. المؤسسات التي تجسد هذا المفهوم تعرف أكثر ، وتنمو بشكل أسرع ، وفي رأينا ، تعمل أكثر إثارة للاهتمام في هذه التكنولوجيا المتطورة!
تعرّف على المزيد حول إنشاء مفهوم Insight-Driven في
مكتبتنا لمواد إدارة البيانات المفيدة ، حيث قمنا بجمع مقاطع الفيديو والكتيبات المفيدة والوصول التجريبي إلى أنظمة SAP.