تحية! سأخبر اليوم قراء هابر عن كيفية ابتكارنا تقنية التعرف على النصوص التي تعمل بـ 45 لغة ويمكن لمستخدمي Yandex.Cloud الوصول إليها ، وما المهام التي حددناها وكيف حلناها. سيكون من المفيد إذا كنت تعمل في مشاريع مماثلة أو ترغب في معرفة كيف حدث ذلك ، فأنت بحاجة فقط اليوم لتصوير علامة المتجر التركي حتى تترجمه أليس إلى الروسية.

تتطور تقنية التعرف الضوئي على الحروف (OCR) في العالم منذ عقود. بدأنا في Yandex بتطوير تقنية التعرف الضوئي على الحروف الخاصة بنا لتحسين خدماتنا ومنح المستخدمين المزيد من الخيارات. الصور جزء كبير من الإنترنت ، وبدون القدرة على فهمها ، سيكون البحث على الإنترنت غير مكتمل.
حلول تحليل الصور أصبحت شعبية متزايدة. ويرجع ذلك إلى انتشار الشبكات والأجهزة العصبية الاصطناعية مع أجهزة استشعار عالية الجودة. من الواضح أننا نتحدث في المقام الأول عن الهواتف الذكية ، ولكن ليس عنهم فقط.
يزداد تعقيد المهام في مجال التعرف على النص باستمرار - كل ذلك بدأ بالتعرف على المستندات الممسوحة ضوئيًا. ثم تم إضافة
التعرف على صور Born-Digital-text مع نص من الإنترنت. ثم ، مع تزايد شعبية الكاميرات المحمولة ، التعرف على لقطات الكاميرا الجيدة (
نص مشهد مركّز ). والأكثر تعقيدًا ، كلما كانت المعلمات أكثر تعقيدًا: يمكن أن يكون النص غامضًا (
نص مشهد عرضي ) ،
مكتوبًا بأي ثني أو دوامة ، بمختلف الفئات - بدءًا من
صور الإيصالات وحتى تخزين
الأرفف واللافتات.
بأي طريقة ذهبنا؟
التعرف على النص هو فئة منفصلة من مهام رؤية الكمبيوتر. مثل العديد من خوارزميات رؤية الكمبيوتر ، قبل شعبية الشبكات العصبية ، كان يعتمد إلى حد كبير على الميزات اليدوية والاستدلال. ومع ذلك ، في الآونة الأخيرة ، مع الانتقال إلى نهج الشبكات العصبية ، نمت جودة التكنولوجيا بشكل كبير. انظر إلى المثال في الصورة. كيف حدث هذا ، سأقول المزيد.
قارن نتائج التعرف اليوم بالنتائج في بداية 2018:
ما الصعوبات التي واجهناها في البداية؟
في بداية رحلتنا ، صنعنا تقنية التعرف على اللغتين الروسية والإنجليزية ، وكانت حالات الاستخدام الرئيسية عبارة عن صفحات نصية وصور من الإنترنت. ولكن في أثناء العمل ، أدركنا أن هذا ليس كافيًا: تم العثور على النص الموجود في الصور بأي لغة وبأي سطح ، وكانت الصور في بعض الأحيان ذات جودة مختلفة تمامًا. هذا يعني أن الاعتراف يجب أن يعمل في أي موقف وعلى جميع أنواع البيانات الواردة.
وهنا نواجه عددًا من الصعوبات. هنا مجرد أمثلة قليلة:
- التفاصيل. بالنسبة إلى الشخص الذي اعتاد على الحصول على المعلومات من النص ، فإن النص الموجود في الصورة هو الفقرات والخطوط والكلمات والحروف ، لكن بالنسبة إلى الشبكة العصبية ، يبدو كل شيء مختلفًا. نظرًا للطبيعة المعقدة للنص ، تُجبر الشبكة على رؤية كل من الصورة بأكملها (على سبيل المثال ، إذا تضافرت أيدي الناس وصنعت نقشًا) ، وأصغر التفاصيل (في اللغة الفيتنامية والرموز المماثلة و ừ غير معنى الكلمات). هناك تحديات منفصلة تتمثل في التعرف على النص التعسفي والخطوط غير القياسية.
- تعدد اللغات . كلما زاد عدد اللغات التي أضفناها ، كلما واجهنا تفاصيلها: في الكلمات السيريلية واللاتينية ، تتألف من حروف منفصلة ، مكتوبة باللغة العربية معًا ، ولا يتم تمييز الكلمات المنفصلة باللغة اليابانية. تستخدم بعض اللغات الهجاء من اليسار إلى اليمين ، والبعض الآخر من اليمين إلى اليسار. بعض الكلمات مكتوبة أفقيا ، بعضها عموديا. يجب أن تأخذ الأداة العالمية في الاعتبار كل هذه الميزات.
- هيكل النص . للتعرف على صور معينة ، مثل عمليات الفحص أو المستندات المعقدة ، فإن البنية التي تأخذ في الاعتبار تخطيط الفقرات والجداول وعناصر أخرى أمر بالغ الأهمية.
- الأداء . يتم استخدام التكنولوجيا على مجموعة واسعة من الأجهزة ، بما في ذلك دون الاتصال بالإنترنت ، لذلك كان علينا أن نأخذ في الاعتبار متطلبات الأداء الصارمة.
اختيار نموذج الكشف
الخطوة الأولى للتعرف على النص هي تحديد موضعه (الكشف).
يمكن اعتبار اكتشاف النص مهمة التعرف على الكائنات ، حيث يمكن أن تعمل
الأحرف الفردية أو
الكلمات أو
الأسطر ككائن.
كان من المهم بالنسبة لنا أن النموذج في وقت لاحق إلى لغات أخرى (الآن نحن ندعم 45 لغة).
تستخدم العديد من المقالات البحثية حول الكشف عن النص نماذج تتنبأ بموضع
الكلمات الفردية. ولكن في حالة وجود
نموذج عالمي ، فإن لهذا النهج قيودًا متعددة - على سبيل المثال ، مفهوم كلمة اللغة الصينية يختلف اختلافًا جوهريًا عن مفهوم الكلمة ، على سبيل المثال ، في اللغة الإنجليزية. لا يتم فصل الكلمات الفردية باللغة الصينية بمسافة. في التايلاندية ، يتم تجاهل جمل واحدة فقط بمسافة.
فيما يلي أمثلة على النص نفسه بالروسية والصينية والتايلاندية:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วالخطوط ، بدورها ، متغيرة للغاية من حيث نسبة العرض إلى الارتفاع. ولهذا السبب ، فإن إمكانيات نماذج الكشف الشائعة هذه (على سبيل المثال ، SSD أو RCNN) للتنبؤ بالخط محدودة ، نظرًا لأن هذه النماذج تستند إلى مناطق مرشح / مربعات ربط مع العديد من نسب الارتفاع المحددة مسبقًا. بالإضافة إلى ذلك ، يمكن أن يكون للخطوط شكل تعسفي ، على سبيل المثال ، منحني ، وبالتالي للحصول على وصف نوعي للخطوط ، فإنه لا يكفي حصريًا لوصف الزوايا الرباعية ، حتى بزاوية الدوران.
على الرغم من حقيقة أن مواضع
الأحرف الفردية محلية وموصوفة ، فإن عيبها هو أن هناك حاجة إلى خطوة ما بعد المعالجة المنفصلة - تحتاج إلى تحديد الاستدلال للأحرف اللاصقة في الكلمات والأسطر.
لذلك ، اتخذنا
نموذج SegLink كأساس للكشف ، تتمثل الفكرة الرئيسية في تحليل الخطوط / الكلمات في كيانين محليين آخرين هما: القطاعات والعلاقات بينهما.
معمارية الكاشف
تعتمد بنية النموذج على SSD ، والذي يتنبأ بموقف الكائنات على عدة مقاييس للميزات. فقط بالإضافة إلى التنبؤ بإحداثيات "القطع" الفردية يتم أيضًا توقع "اتصالات" بين القطاعات المجاورة ، أي ما إذا كان الجزءان ينتميان إلى نفس السطر. يتم توقع "التوصيلات" للقطاعات المجاورة على نفس نطاق الميزات ، وللقطاعات الموجودة في المناطق المجاورة في المقاييس المجاورة (قد تختلف المقاطع من المقاييس المختلفة للميزات قليلاً في الحجم وتنتمي إلى نفس السطر).
لكل مقياس ، ترتبط كل خلية معالم بـ "قطعة" مقابلة. لكل قطعة s
(x ، y ، l) عند النقطة (x ، y) على مقياس l ، يتم تدريب التالي:
- ع ما إذا كان الجزء المعطى نصًا ؛
- x
s ، y
s ، w
s ، h
s ، -
s - إزاحة إحداثيات القاعدة وزاوية ميل المقطع ؛
- 8 نقاط لوجود "اتصالات" بشرائح مجاورة لمقياس l (L
w s، s ' ، s' من {s
(x '، y'، l) } / s
(x، y، l) ، حيث x –1 ≤ x '≤ x + 1، y - 1 ≤ y' ≤ y + 1)؛
- 4 نقاط لوجود "اتصالات" مع شرائح مجاورة لمقياس l-1 (L
c s، s ' ، s' من {s
(x '، y'، l-1) }، حيث 2x ≤ x '≤ 2x + 1 ، 2y ≤ y '≤ 2y + 1) (وهذا صحيح بسبب حقيقة أن البعد من الميزات على المقاييس المجاورة يختلف بالضبط 2 مرات).
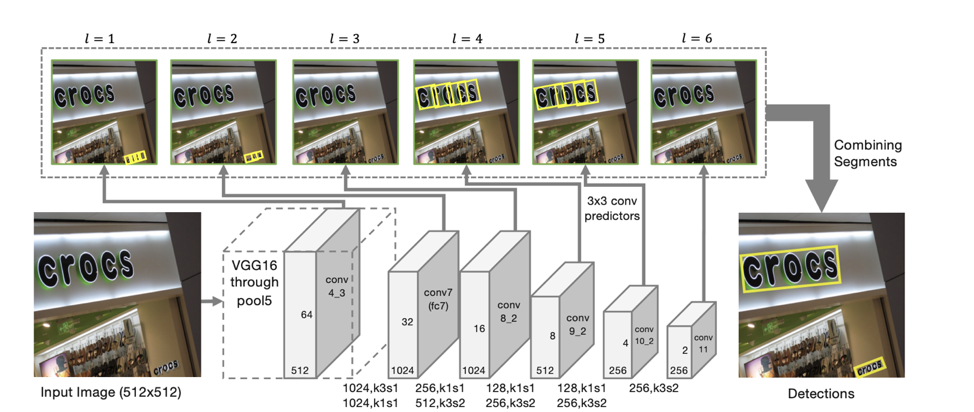
وفقًا لهذه التنبؤات ، إذا أخذنا كرؤوس جميع القطاعات التي يكون احتمال أن تكون نصًا فيها أكبر من العتبة α ، وتكون الحواف جميع الروابط التي يكون احتمالها أكبر من العتبة β ، ثم تشكل الأجزاء مكونات متصلة ، وكل منها يصف سطرًا من النص .
يتمتع النموذج الناتج
بقدرة تعميم عالية : حتى المدربين على النهج الأول على البيانات الروسية والإنجليزية ، وجد نوعًا من النص الصيني والعربية.
عشرة مخطوطات
إذا تمكنا للكشف من إنشاء نموذج يعمل على الفور لجميع اللغات ، فعندئذٍ من الصعب التعرف على الخطوط التي وجدت مثل هذا النموذج. لذلك ، قررنا استخدام
نموذج منفصل لكل نص (السيريلية واللاتينية والعربية والعبرية واليونانية والأرمنية والجورجية والكورية والتايلاندية). يتم استخدام نموذج عام منفصل للصينية واليابانية بسبب التقاطع الكبير في الهيروغليفية.
يختلف النموذج المشترك للنص بأكمله عن النموذج المنفصل لكل لغة بأقل من 1 صفحة. الجودة. في نفس الوقت ، يكون إنشاء نموذج واحد وتطبيقه أبسط من ، على سبيل المثال ، 25 نموذجًا (عدد اللغات اللاتينية التي يدعمها نموذجنا). ولكن نظرًا لوجود اللغة الإنجليزية بشكل متكرر بجميع اللغات ، فإن جميع النماذج لدينا قادرة على التنبؤ ، بالإضافة إلى النص الرئيسي ، الأحرف اللاتينية.
لفهم النموذج الذي يجب استخدامه للاعتراف ، نقرر أولاً ما إذا كانت الخطوط المستلمة تنتمي إلى أحد البرامج النصية العشرة المتاحة للتعرف عليها.
يجب الإشارة بشكل منفصل إلى أنه ليس من الممكن دائمًا تحديد البرنامج النصي بشكل فريد على طول الخط. على سبيل المثال ، يتم احتواء الأرقام أو الأحرف اللاتينية الفردية في العديد من البرامج النصية ، لذلك أحد فئات الإخراج للنموذج هو برنامج نصي "غير محدد".
تعريف البرنامج النصي
لتحديد البرنامج النصي ، قمنا بعمل مصنف منفصل. إن مهمة تعريف البرنامج النصي أبسط بكثير من مهمة التعرف ، ويتم بسهولة إعادة تدريب الشبكة العصبية على البيانات الاصطناعية. لذلك ، في تجاربنا ، حدث تحسن كبير في جودة النموذج من خلال
التدريب المسبق على مشكلة التعرف على السلسلة . للقيام بذلك ، قمنا أولاً بتدريب الشبكة على مشكلة التعرف على جميع اللغات المتاحة. بعد ذلك ، تم استخدام العمود الفقري الناتج لتهيئة النموذج لمهمة تصنيف البرنامج النصي.
في حين أن البرنامج النصي على سطر فردي غالبًا ما يكون صاخبًا تمامًا ، فإن الصورة ككل غالبًا ما تحتوي على نص بلغة واحدة ، إما بالإضافة إلى النص الرئيسي المتخلل باللغة الإنجليزية (أو في حالة مستخدمينا الروس). لذلك ،
لزيادة الاستقرار ، نقوم بتجميع تنبؤات الأسطر من الصورة من أجل الحصول على تنبؤ أكثر استقرارًا للنص البرمجي للصورة. لا يتم أخذ الخطوط التي تحتوي على فئة متوقعة من "غير مسمى" في الاعتبار عند التجميع.
خط الاعتراف
الخطوة التالية ، عندما نحدد بالفعل موضع كل سطر ونصه ، نحتاج إلى
التعرف على تسلسل الأحرف من البرنامج النصي المحدد الذي يظهر عليه ، أي من تسلسل البكسلات للتنبؤ بتسلسل الأحرف. بعد العديد من التجارب ، توصلنا إلى النموذج التالي القائم على الانتباه التالي:

يتيح لك استخدام CNN + BiLSTM في المشفر الحصول على علامات تلتقط السياقات المحلية والعالمية. بالنسبة للنص ، هذا مهم - غالبًا ما يتم كتابته بخط واحد (التمييز بين الأحرف المتشابهة ومعلومات الخطوط أسهل كثيرًا). ومن أجل التمييز بين حرفين مكتوبين بمسافة من الحروف المتتالية ، هناك حاجة أيضًا إلى إحصائيات عالمية للخط.
ملاحظة مهمة : في النموذج الناتج ، يمكن استخدام مخرجات قناع الانتباه لرمز معين للتنبؤ بموضعه في الصورة.
ألهمنا ذلك لمحاولة
"تركيز" انتباه النموذج بوضوح . تم العثور على مثل هذه الأفكار أيضًا في المقالات - على سبيل المثال ، في مقال
تركيز الاهتمام: نحو التعرف على النص بدقة في الصور الطبيعية .
نظرًا لأن آلية الانتباه تعطي توزيعًا محتملاً على مساحة الميزة ، إذا أخذنا كخسارة إضافية في مجموع مخرجات الانتباه داخل القناع المطابق للحرف المتوقعة في هذه الخطوة ، سنحصل على جزء "الاهتمام" الذي يركز عليه مباشرة.
من خلال إدخال سجل الخسارة (∑
i و j∈M t α
i و j ) ، حيث M
t هو قناع الحرف tth ، α هو إخراج الانتباه ، سنشجع "الانتباه" للتركيز على الرمز المحدد وبالتالي المساعدة الشبكات العصبية تتعلم بشكل أفضل.
بالنسبة إلى أمثلة التدريب التي يكون موقع شخصياتها غير معروف أو غير دقيق (لا تحتوي جميع بيانات التدريب على علامات على مستوى الأحرف الفردية ، وليس الكلمات) ، لم يتم أخذ هذا المصطلح في الاعتبار في الخسارة النهائية.
ميزة أخرى لطيفة: تسمح لك هذه البنية بالتنبؤ
بالتعرف على الخطوط من اليمين إلى اليسار دون تغييرات إضافية (وهو أمر مهم ، على سبيل المثال ، بالنسبة للغات مثل العربية والعبرية). النموذج نفسه يبدأ في إصدار الاعتراف من اليمين إلى اليسار.
نماذج سريعة وبطيئة
في هذه العملية ، واجهنا مشكلة:
بالنسبة للخطوط "الطويلة" ، أي الخطوط الممتدة رأسياً ، فإن النموذج يعمل بشكل سيئ. كان السبب في ذلك هو أن بُعد العلامات على مستوى الانتباه أصغر بثمانية أضعاف من بُعد الصورة الأصلية بسبب الخطوات الواسعة والشد في بنية الجزء التلافيفي من الشبكة. وقد تتوافق مواقع العديد من الأحرف المجاورة في الصورة المصدر مع موقع متجه الميزة نفسه ، مما قد يؤدي إلى حدوث أخطاء في مثل هذه الأمثلة. أدى استخدام البنية مع تضييق أصغر لبعد الميزات إلى زيادة في الجودة ، ولكن أيضًا إلى زيادة في وقت المعالجة.
لحل هذه المشكلة
وتجنب زيادة وقت المعالجة ، قمنا بإجراء التحسينات التالية على النموذج:
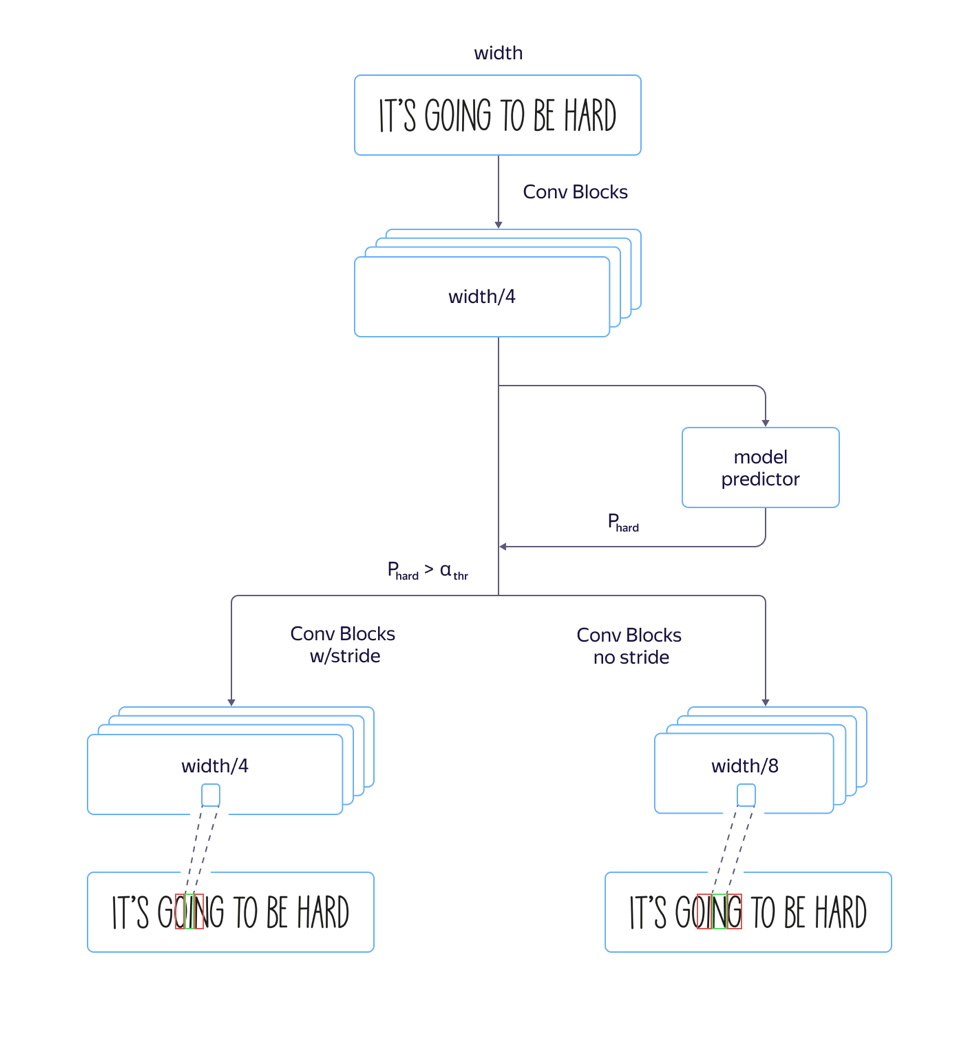
قمنا بتدريب كل من نموذج سريع مع الكثير من الخطوات وبطيئة مع أقل. على الطبقة التي بدأت فيها معلمات النموذج في الاختلاف ، أضفنا مخرجات شبكة منفصلة تنبأت بالنموذج الذي سيكون به خطأ أقل في التعرف. كانت الخسارة الكلية للنموذج مكونة من L L + L +
كبير الجودة L. وهكذا ، على الطبقة الوسيطة ، تعلم النموذج تحديد "التعقيد" لهذا المثال. علاوة على ذلك ، في مرحلة التطبيق ، تم النظر في الجزء العام والتنبؤ بـ "تعقيد" المثال لجميع الخطوط ، واعتمادًا على مخرجاته ، تم استخدام نموذج سريع أو بطيء في المستقبل وفقًا للقيمة الدنيا. سمح لنا ذلك بالحصول على جودة لا تختلف تقريبًا عن جودة الطراز الطويل ، بينما زادت السرعة بنسبة 5٪ فقط بدلاً من النسبة المقدرة بـ 30٪.
بيانات التدريب
تتمثل مرحلة هامة في إنشاء نموذج عالي الجودة في إعداد نموذج تدريبي كبير ومتنوع. تتيح الطبيعة "التركيبية" للنص توليد كميات كبيرة من الأمثلة والحصول على نتائج جيدة على البيانات الحقيقية.
بعد النهج الأول لتوليد البيانات الاصطناعية ، نظرنا بعناية في نتائج النموذج الذي تم الحصول عليه ووجدنا أن النموذج لا يتعرف على الأحرف المفردة "أنا" بسبب التحيز في النصوص المستخدمة لإنشاء مجموعة التدريب. لذلك ، أنشأنا بوضوح
مجموعة من الأمثلة "الإشكالية" ، وعندما أضفناها إلى البيانات الأولية للنموذج ، زادت الجودة بشكل كبير. كررنا هذه العملية عدة مرات ، بإضافة شرائح أكثر وأكثر تعقيدًا ، والتي أردنا تحسين جودة التعرف عليها.
النقطة المهمة هي أن
البيانات التي يتم إنشاؤها
يجب أن تكون متنوعة ومماثلة للبيانات الحقيقية . وإذا كنت تريد أن يعمل النموذج على صور فوتوغرافية للنص على أوراق ، وتحتوي مجموعة البيانات الاصطناعية بالكامل على نص مكتوب أعلى المناظر الطبيعية ، فقد لا يعمل هذا.
هناك خطوة أخرى مهمة وهي استخدام هذه الأمثلة لتدريب الأمثلة التي يتم فيها التعرف على الخطأ الحالي. إذا كان هناك عدد كبير من الصور التي لا يوجد بها ترميز ، فيمكنك أخذ تلك المخرجات من نظام التعرف الحالي الذي لا تعرفه ، وتمييزها فقط ، مما يقلل من تكلفة الترميز.
للحصول على أمثلة معقدة ، طلبنا من مستخدمي خدمة Yandex.Tolok رسومًا لتصوير
صور مجموعة معينة "معقدة" وإرسالها إلينا - على سبيل المثال ، صور حزم البضائع:


جودة العمل على البيانات "المعقدة"
نود أن نعطي مستخدمينا الفرصة للعمل مع صور فوتوغرافية لأي تعقيد ، لأنه قد يكون من الضروري التعرف على النص أو ترجمته ، ليس فقط على صفحة الكتاب أو المستند الممسوح ضوئيًا ، ولكن أيضًا في إشارة الشارع أو الإعلان أو تغليف المنتج. لذلك ، مع الحفاظ على الجودة العالية للعمل على تدفق الكتب والمستندات (سنكرس قصة منفصلة لهذا الموضوع) ، فإننا نولي اهتمامًا خاصًا لـ "مجموعات الصور المعقدة".
بالطريقة الموضحة أعلاه ، قمنا بتجميع مجموعة من الصور التي تحتوي على نص في البرية قد تكون مفيدة لمستخدمينا: صور من لوحات إعلانية وإعلانات وأقراص وأغلفة كتب ونصوص على الأجهزة المنزلية والملابس والأشياء. في مجموعة البيانات هذه (الرابط أدناه) ، قمنا بتقييم جودة الخوارزمية الخاصة بنا.
كمقياس للمقارنة ، استخدمنا المقياس القياسي للدقة واكتمال التعرّف على الكلمات في مجموعة البيانات ، وكذلك المقياس F. تعتبر الكلمة المعترف بها موجودة بشكل صحيح إذا كانت إحداثياتها تتوافق مع إحداثيات الكلمة التي تم ترميزها (IoU> 0.3) وتزامن التعرف مع العلامة المحددة للحالة تمامًا. الأرقام على مجموعة البيانات الناتجة:
تتوفر مجموعة البيانات والمقاييس والبرامج النصية لإعادة إنتاج النتائج
هنا .
محدث. الأصدقاء ، مقارنة التكنولوجيا لدينا مع حل مماثل من Abbyy تسبب الكثير من الجدل. نحن نحترم آراء المجتمع وأقران الصناعة. لكن في الوقت نفسه نحن واثقون من نتائجنا ، لذلك قررنا بهذه الطريقة: سنقوم بإزالة نتائج المنتجات الأخرى من المقارنة ، ومناقشة منهجية الاختبار معهم مرة أخرى والعودة إلى النتائج التي توصلنا إليها إلى اتفاق عام.
الخطوات التالية
عند تقاطع الخطوات الفردية ، مثل الاكتشاف والاعتراف ، تنشأ المشاكل دائمًا: تستلزم أدنى التغييرات في نموذج الاكتشاف الحاجة إلى تغيير نموذج التعرُّف ، لذلك نحن نجرب بنشاط على إنشاء حل شامل.
بالإضافة إلى الطرق الموصوفة بالفعل لتحسين التكنولوجيا ، سنقوم بتطوير اتجاه لتحليل بنية المستند ، وهو أمر مهم للغاية عند استخراج المعلومات والطلب بين المستخدمين.
استنتاج
لقد اعتاد المستخدمون بالفعل على التقنيات المريحة وبدون تردد ، قم بتشغيل الكاميرا ، وأشر إلى علامة المتجر ، والقائمة في المطعم أو الصفحة في كتاب بلغة أجنبية ، وسرعان ما تلقى ترجمة. نحن نتعرف على النص بـ 45 لغة بدقة مثبتة ، وسيتم توسيع الفرص فقط. تتيح مجموعة من الأدوات الموجودة داخل Yandex.Cloud لأي شخص يريد استخدام أفضل الممارسات التي يقوم بها Yandex من أجل نفسه لفترة طويلة.
اليوم يمكنك فقط أخذ التكنولوجيا النهائية ودمجها في التطبيق الخاص بك واستخدامها من أجل إنشاء منتجات جديدة وأتمتة العمليات الخاصة بك. الوثائق الخاصة بـ OCR متاحة
هنا .
ماذا تقرأ:
- D. Karatzas ، SR Mestre ، J. Mas ، F. Nourbakhsh ، و PP Roy ، "ICDAR 2011 منافسة قوية في القراءة - التحدي 1: قراءة النص في الصور الرقمية المولودة (الويب والبريد الإلكتروني)" ، في تحليل المستندات والاعتراف بها (ICDAR ) ، 2011 المؤتمر الدولي على. IEEE ، 2011 ، ص. 1485-1490.
- Karatzas D. وآخرون. مسابقة ICDAR 2015 حول القراءة القوية // 2015 المؤتمر الدولي الثالث عشر لتحليل الوثائق والاعتراف بها (ICDAR). - IEEE ، 2015. - S. 1156-1160.
- تشي-كنج تشينج وآخرون الله. ICDAR2019 تحدي قوي في القراءة على النص التعسفي (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 تحدي قراءة قوي على الإيصالات الممسوحة ضوئيًا OCR واستخراج المعلومات rrc.cvc.uab.es/؟ch=13
- ShopSign: مجموعة بيانات نص مشهد متنوعة من لافتات تسوق صينية في طرق عرض الشوارع [ arxiv: 1903.10412 ]
- Baoguang Shi، Xiang Bai، Serge Belongie Detectioning Oriented Text in Images Natural by Linking Segments [ arxiv: 1703.06520 ].
- Zhanzhan Cheng و Fan Bai و Yunlu Xu و Gang Zheng و Shiliang Pu و Shuigeng Zhou التركيز على التركيز: نحو التعرف على النص بدقة في الصور الطبيعية [ arxiv: 1709.02054 ].