يوم جيد واحترامي ، قراء هبر!
قبل التاريخ
في مكاننا ، من المعتاد تبادل النتائج المثيرة للاهتمام في فرق التطوير. في الاجتماع التالي ، لمناقشة مستقبل .NET و .NET 5 على وجه الخصوص ، ركزنا أنا وزملائي على رؤية نظام أساسي موحد من هذه الصورة:
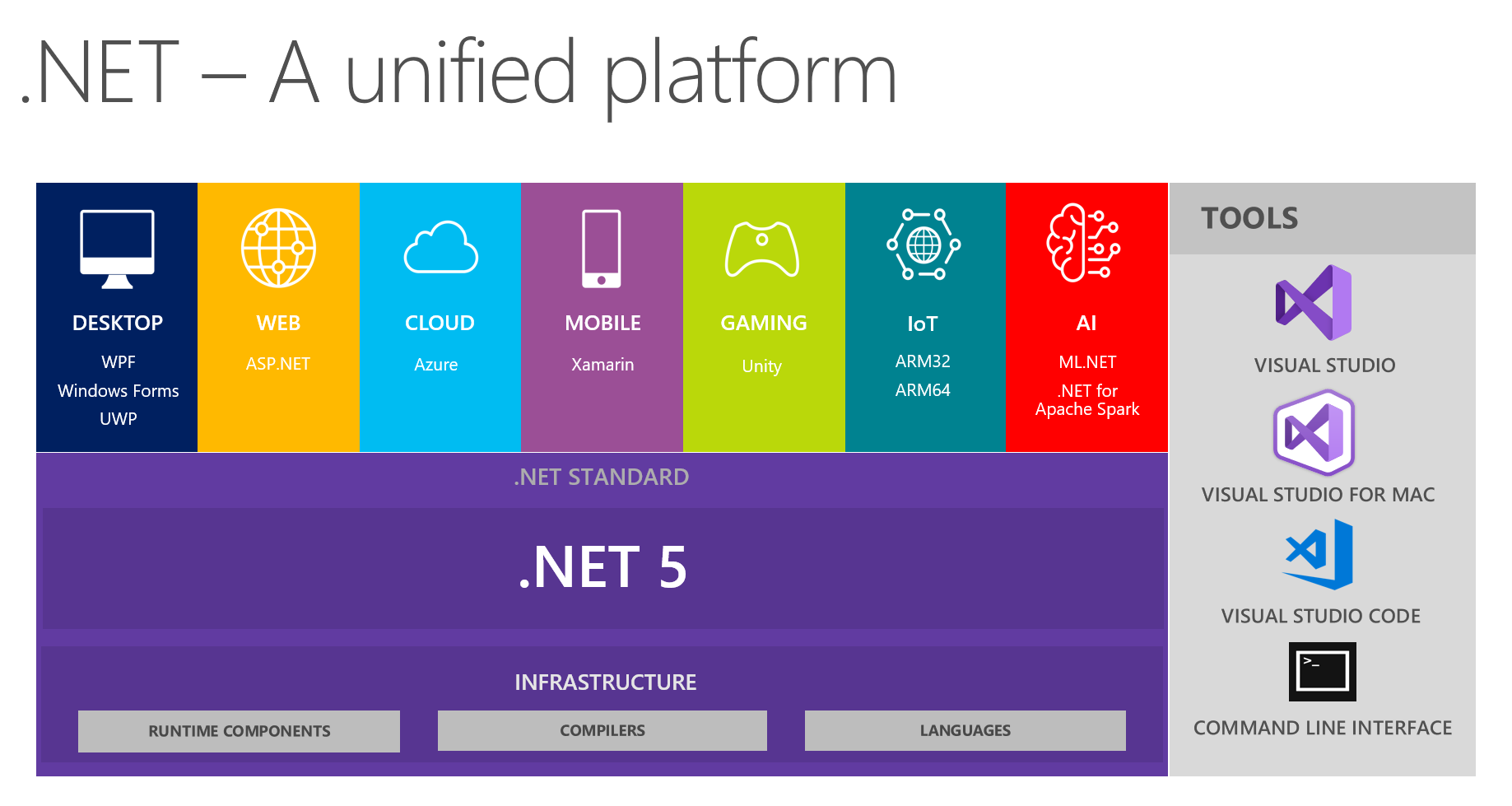
إنه يوضح أن المنصة تجمع بين DESKTOP و WEB و CLOUD و MOBILE و GAMING و IoT و AI. حصلت على فكرة لإجراء محادثة في شكل تقرير صغير + أسئلة / إجابات على كل موضوع في الاجتماعات القادمة. يقوم الشخص المسؤول عن موضوع معين بالتحضير المبدئي لقراءة المعلومات حول الابتكارات الرئيسية ومحاولة تطبيق شيء ما باستخدام التكنولوجيا المختارة ، ثم مشاركة أفكاره وانطباعاته معنا. نتيجةً لذلك ، يتلقى الجميع تعليقات حقيقية على الأدوات من مصدر موثوق مباشرةً - إنه مناسب جدًا ، نظرًا لأن محاولة اقتحام جميع المواضيع التي قد لا تكون في متناول يديك ، لن تصل يديك.
نظرًا لأنني كنت مهتمًا بالتعلم الآلي كهواية لبعض الوقت (وأحيانًا تستخدمها في مهام غير تجارية في العمل) ، فقد حصلت على موضوع AI و ML.NET. في عملية التحضير ، صادفت أدوات ومواد رائعة ، ولمفاجأتي اكتشفت أن هناك القليل جدًا من المعلومات عنها بشأن حبري. في وقت سابق في المدونة الرسمية ، كتبت Microsoft عن إصدار ML.Net ، و Model Builder على وجه الخصوص. أود أن أشارك كيف أتيت إليه وما هي الانطباعات التي حصلت عليها من العمل معه. المقالة حول Model Builder أكثر من ML في .NET ككل ؛ سنحاول إلقاء نظرة على ما يقدمه MS لمطور .NET المتوسط ، ولكن بأعين شخص ذكي في ML. في الوقت نفسه ، سأحاول الحفاظ على التوازن بين إعادة تشغيل البرنامج التعليمي ، ومضغ المبتدئين تمامًا ووصف التفاصيل الخاصة بأخصائيي ML ، والذين يحتاجون لسبب ما للوصول إلى .NET.
الجسم الرئيسي
لذلك ، googling سريعة حول ML في .NET ينقلني إلى صفحة البرنامج التعليمي :
اتضح أن هناك امتدادًا خاصًا لبرنامج Visual Studio يسمى Model Builder ، والذي "يسمح لك بإضافة التعلم الآلي إلى مشروعك باستخدام زر الماوس الأيمن" (ترجمة مجانية). سوف أتناول بإيجاز الخطوات الرئيسية للبرنامج التعليمي التي يتم تقديمها ، وسأضيف التفاصيل وأفكاري.
تحميل وتثبيت
اضغط على الزر ، تنزيل ، تثبيت. الاستوديو سوف تضطر إلى إعادة تشغيل.
أنشئ تطبيقك
أولاً ، قم بإنشاء تطبيق C # منتظم. في البرنامج التعليمي ، يُقترح إنشاء Core ، ولكنه يناسب أيضًا Framework. ثم ، في الواقع ، يبدأ ML - انقر بزر الماوس الأيمن على المشروع ، ثم Add -> Machine Learning. سيتم تحليل النافذة التي ستظهر لإنشاء النموذج ، لأنه يحدث فيه كل السحر.
اختيار السيناريو
حدد "البرنامج النصي" للتطبيق الخاص بك. في الوقت الحالي ، يتوفر 5 (البرنامج التعليمي قديم قليلاً ، بينما هناك 4):
- تحليل الشعور - تحليل الدرجة اللونية ، التصنيف الثنائي (التصنيف الثنائي) ، يحدد النص لونه العاطفي ، إيجابي أو سلبي.
- تصنيف المشكلة - تصنيف متعدد الفئات ، يمكن تحديد الملصق المستهدف للإصدار (التذاكر ، الأخطاء ، مكالمات الدعم ، إلخ) كواحد من ثلاثة خيارات متبادلة
- التنبؤ بالأسعار - الانحدار ، مشكلة الانحدار الكلاسيكي عندما يكون الناتج عددًا مستمرًا ؛ في المثال ، هذا تقدير شقة
- تصنيف الصورة - تصنيف متعدد الطبقات ، ولكن بالفعل للصور
- سيناريو مخصص - السيناريو الخاص بك. أُجبرت على الحزن لأنه لن يكون هناك شيء جديد في هذا الخيار ، في مرحلة لاحقة فقط ، سوف يسمحون لي باختيار أحد الخيارات الأربعة المذكورة أعلاه.
لاحظ أنه لا يوجد تصنيف متعدد المرات عندما تكون الطريقة المستهدفة متعددة في نفس الوقت (على سبيل المثال ، يمكن أن يكون البيان مسيئًا أو عنصريًا أو فاحشًا في نفس الوقت ، وقد لا يكون أيًا من ذلك). بالنسبة للصور ، لا يوجد خيار لتحديد مهمة تجزئة. أفترض أنه بمساعدة الإطار ، يمكن حلها بشكل عام ، لكننا نركز اليوم على المنشئ. يبدو أن توسيع نطاق المعالج لتوسيع عدد المهام ليست مهمة صعبة ، لذلك يجب أن تتوقعها في المستقبل.
تحميل وإضافة البيانات
يُقترح تنزيل مجموعة البيانات. من الحاجة إلى التنزيل إلى جهازك ، نخلص تلقائيًا إلى أن التدريب سيتم على جهازك المحلي. هذا لديه كلا الإيجابيات:
- يمكنك التحكم في جميع البيانات ، يمكنك تصحيح وتغيير محليا وتكرار التجارب.
- لا تقم بتحميل البيانات إلى السحابة ، وبالتالي الحفاظ على الخصوصية. بعد كل شيء ، لا تحميل ، نعم مايكروسوفت ؟ :)
وسلبيات:
- سرعة التعلم محدودة بموارد جهازك المحلي.
يُقترح كذلك تحديد مجموعة البيانات التي تم تنزيلها كمدخلات من نوع "ملف". هناك أيضًا خيار لاستخدام "SQL Server" - ستحتاج إلى تحديد تفاصيل الخادم الضرورية ، ثم حدد الجدول. إذا فهمت بشكل صحيح ، فليس من الممكن بعد تحديد برنامج نصي معين. أدناه ، أكتب عن المشكلات التي واجهت هذا الخيار.
تدريب النموذج الخاص بك
في هذه الخطوة ، يتم تدريب مختلف الطرز بالتتابع ، ويتم عرض السرعة لكل منها ، وفي النهاية يتم اختيار الأفضل. أوه نعم ، لقد نسيت أن أذكر أن هذا هو AutoML - أي سيتم اختيار أفضل الخوارزمية والمعلمات (غير متأكد ، انظر أدناه) تلقائيًا ، لذلك لا تحتاج إلى القيام بأي شيء! يُقترح قصر وقت التدريب الأقصى على عدد الثواني. الأساليب البحثية لتعريف هذا الوقت: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . على الجهاز الخاص بي ، في غضون 10 ثوانٍ الافتراضي ، يتعلم نموذج واحد فقط ، لذلك يجب أن أراهن كثيرًا. نبدأ ، ننتظر.
أنا هنا أريد حقًا أن أضيف أن أسماء النماذج شخصيًا بدت غير عادية بالنسبة لي ، على سبيل المثال: AveragedPerceptronBinary و FastTreeOva و SdcaMaximumEntropyMulti. لا يتم استخدام كلمة "Perceptron" في كثير من الأحيان هذه الأيام ، وربما تكون كلمة "Ova" واحدة مقابل كل شيء ، و "FastTree" أجد صعوبة في قول ما.
حقيقة أخرى مثيرة للاهتمام هي أن LightGbmMulti هو من بين خوارزميات المرشح. إذا فهمت بشكل صحيح ، فهذا هو نفس LightGBM ، محرك التدرج التدريجي الذي ، إلى جانب CatBoost ، ينافس الآن مع قاعدة XGBoost الفردية. إنه محبط بعض الشيء بسبب سرعته في الأداء الحالي - على بياناتي ، استغرق تدريبه معظم الوقت (حوالي 180 ثانية). على الرغم من أن المدخلات عبارة عن نص ، إلا أنه بعد توجيه آلاف الأعمدة أكثر من أمثلة المدخلات ، فإن هذا ليس هو أفضل حالة للتعزيز والأشجار بشكل عام.
تقييم النموذج الخاص بك
في الواقع ، وتقييم نتائج النموذج. في هذه الخطوة ، يمكنك الاطلاع على المقاييس المستهدفة التي تم تحقيقها ، وكذلك توجيه النموذج مباشرة. حول المقاييس نفسها يمكن قراءتها هنا: MS و sklearn .
كنت مهتمًا بشكل أساسي بالسؤال - ما الذي تم اختباره؟ يعطي البحث في صفحة المساعدة نفسها إجابة - القسم محافظ للغاية ، من 80 ٪ إلى 20 ٪. لم أجد القدرة على تكوين هذا في واجهة المستخدم. في الممارسة العملية ، أود التحكم في هذا ، لأنه عندما يكون هناك الكثير من البيانات ، يمكن أن يكون القسم 99٪ و 1٪ (وفقًا لأندرو أنغ ، أنا شخصياً لم أعمل مع هذه البيانات). قد يكون من المفيد أيضًا أن تكون قادرًا على تعيين عينات عشوائية من بيانات البذور ، لأن التكرار أثناء إنشاء واختيار أفضل نموذج يصعب تقديره. يبدو أن إضافة هذه الخيارات ليست صعبة ، للحفاظ على الشفافية والبساطة ، يمكنك إخفاؤها وراء مربع اختيار خيارات إضافية.
في عملية بناء النموذج ، يتم عرض الأجهزة اللوحية المزودة بمؤشرات السرعة على وحدة التحكم ، ويمكن العثور على رمز التوليد الخاص بها في المشروعات من الخطوة التالية. يمكننا أن نستنتج أن الشفرة التي تم إنشاؤها تعمل حقًا ، وأن ناتجها الصادق هو الإخراج ، وليس مزيفًا.
ملاحظة مثيرة للاهتمام - أثناء كتابة المقال ، مشيت مرة أخرى خطوات المنشئ ، واستخدمت مجموعة البيانات المقترحة للتعليقات من ويكيبيديا. ولكن كمهمة اخترت "مخصص" ، ثم تصنيف متعدد الفئات كهدف (على الرغم من وجود فئتين فقط). ونتيجة لذلك ، تحولت السرعة إلى حوالي 10٪ (حوالي 73٪ مقابل 83٪) عن السرعة من لقطة الشاشة ذات التصنيف الثنائي. بالنسبة لي هذا غريب بعض الشيء ، لأن النظام كان يمكن أن يخمن أن هناك فصلين فقط. من حيث المبدأ ، يجب على المصنّعين من النوع الواحد مقابل الكل (a la one مقابل الكل ، عندما يتم تقليل مشكلة تصنيف multiclass إلى الحل المتسلسل للمشاكل الثنائية N لكل فئة من فئات N) أيضًا إظهار سرعة ثنائية مماثلة في هذا الموقف.
توليد رمز
في هذه الخطوة ، سيتم إنشاء مشروعين وإضافتهما إلى الحل. يحتوي أحدهما على مثال كامل لاستخدام النموذج ، ولا ينبغي النظر إلى الآخر إلا إذا كانت تفاصيل التنفيذ مثيرة للاهتمام.
بالنسبة لي ، اكتشفت أن عملية التعلم بأكملها يتم تشكيلها بإيجاز في خط أنابيب (مرحباً بالأنابيب من sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(لمست قليلا تنسيق التعليمات البرمجية لتناسب بشكل جيد)
تذكر ، كنت أتحدث عن المعلمات؟ لا أرى أي معلمة مخصصة ، كل القيم الافتراضية. بالمناسبة ، باستخدام تسمية SentimentText_tf على إخراج FeaturizeText يمكننا أن نستنتج أن هذا عبارة عن تردد مصطلح (تشير الوثائق إلى أن هذه عبارة عن n-gram و char-grams من النص ؛ وأتساءل عما إذا كان هناك IDF ، تردد مستند معكوس).
تستهلك النموذج الخاص بك
في الواقع ، مثال للاستخدام. أستطيع أن أشير فقط إلى أن التنبؤ يتم بشكل أولي.
حسنًا ، هذا كل شيء ، في الواقع - لقد درسنا جميع خطوات المنشئ ولاحظنا النقاط الرئيسية. لكن هذه المقالة ستكون غير مكتملة بدون اختبار على بياناتهم الخاصة ، لأن أي شخص واجه ML و AutoML يعرف جيدًا أن أي صناعة تلقائية جيدة في المهام القياسية والاختبارات الاصطناعية ومجموعات البيانات من الإنترنت. لذلك ، فقد تقرر التحقق من البناء على مهامهم ؛ فيما يلي يعمل دائمًا مع ميزات نصية أو نصية + نصية.
لم يكن من قبيل الصدفة أن لدي مجموعة بيانات تحتوي على بعض الأخطاء / المشكلة / العيوب المسجلة في أحد المشاريع. لديها 2949 خطوط ، 8 فصول مستهدفة غير متوازنة ، 4 ميجابايت.
ML.NET (التحميل والتحويلات والخوارزميات من القائمة أدناه ؛ استغرق 219 ثانية)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(فراغات لاذع في الصفيحة لتناسب في تخفيض السعر)
إصدار My Python (التحميل والتنظيف والتحويل ثم LinearSVC ؛ استغرق 41 ثانية):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0.80 مقابل 0.747 Micro و 0.73 مقابل 0.542 ماكرو (قد يكون هناك بعض عدم الدقة في تعريف الماكرو ، إذا كان هذا مثيرًا للاهتمام ، فسأخبرك في التعليقات).
أنا مفاجأة سارة ، فقط 5 ٪ من الفرق. في بعض مجموعات البيانات الأخرى ، كان الفرق أصغر ، وأحيانًا لم يكن على الإطلاق. عند تحليل حجم الفرق ، تجدر الإشارة إلى أن عدد العينات في مجموعات البيانات صغير ، وأحيانًا بعد التحميل التالي (يتم حذف شيء ما ، تتم إضافة شيء ما) ، لاحظت حركات سرعة تبلغ 2-5 بالمائة.
بينما كنت أجربها بمفردي ، لم تكن هناك مشاكل في استخدام الباني. ومع ذلك ، خلال العرض التقديمي ، لا يزال الزملاء يجتمعون بعدة عضادات:
- لقد حاولنا بصدق تحميل إحدى مجموعات البيانات من الجدول في قاعدة البيانات ، لكننا عثرنا على رسالة خطأ غير معلوماتية. كانت لدي فكرة تقريبية عن نوع خطة البيانات النصية الموجودة هناك ، وعلى الفور اكتشفت أن المشكلة يمكن أن تكون في موجز ويب. حسنًا ، قمت بتنزيل مجموعة البيانات باستخدام pandas.read_csv ، وقمت بتنظيفها من \ n \ r \ t ، وقمت بحفظها في tsv ، ثم انتقلت إليها.
- أثناء تدريب النموذج التالي ، تلقوا استثناءً ، حيث أبلغوا أن مصفوفة تبلغ حوالي 220،000 لكل 1000 لا يمكن وضعها في الذاكرة بشكل مريح ، بحيث يتم إيقاف التدريب. في نفس الوقت ، لم يتم إنشاء النموذج أيضًا. ما يجب القيام به بعد ذلك غير واضح ؛ لقد خرجنا من الموقف عن طريق استبدال الحد الزمني للتعلم "بالعين" - بحيث لا يكون لخوارزمية السقوط الوقت لبدء العمل.
بالمناسبة ، من الفقرة الثانية ، يمكننا أن نستنتج أن عدد الكلمات و n-gram خلال عملية النقل لا يقتصر فعليًا على الحدود العليا ، و "n" ربما تساوي كلمتين. أستطيع أن أقول من تجربتي الخاصة أنه من الواضح أن 200 ألف أكثر من اللازم. عادةً ما يكون مقصورًا على أكثر الأحداث تكرارًا ، أو يتم تطبيقه على أنواع مختلفة من خوارزميات تقليل الأبعاد ، على سبيل المثال ، SVD أو PCA.
النتائج
يوفر المنشئ اختيارًا لعدة سيناريوهات لم أجد فيها أماكن حرجة تتطلب الانغماس في ML. من وجهة النظر هذه ، فهو مثالي كأداة "البدء" أو حل المشاكل البسيطة النموذجية هنا والآن. حالات الاستخدام الفعلي متروكة تمامًا لخيالك. يمكنك الذهاب للخيارات التي تقدمها MS:
- لحل مشكلة تقييم المعنويات (تحليل المعنويات) ، على سبيل المثال ، في التعليقات على المنتجات الموجودة على الموقع
- تصنيف التذاكر حسب الفئات أو الفرق (تصنيف الإصدار)
- مواصلة يسخر تذاكر ، ولكن مع مساعدة من التنبؤ السعر - تقدير تكاليف الوقت
ويمكنك إضافة شيء خاص بك ، على سبيل المثال ، لأتمتة مهمة توزيع الأخطاء / الحوادث الواردة بين المطورين ، وتقليلها إلى مهمة التصنيف حسب النص (التسمية المستهدفة هي معرف / اسم المطور للمطور). أو يمكنك إرضاء مشغلي محطة العمل الداخلية الذين يقومون بملء الحقول الموجودة في البطاقة بمجموعة ثابتة من القيم (القائمة المنسدلة) للحقول الأخرى أو الوصف النصي. للقيام بذلك ، تحتاج فقط إلى إعداد تحديد في csv (حتى عدة مئات من الأسطر كافية للتجارب) ، وتعليم النموذج مباشرةً من UI Visual Studio وتطبيقه في مشروعك عن طريق نسخ الكود من المثال الذي تم إنشاؤه. أفضي إلى حقيقة أن ML.NET في رأيي مناسب تمامًا لحل المهام العملية والواقعية التي لا تتطلب مؤهلات خاصة وتغمر وقتًا طويلًا. علاوة على ذلك ، يمكن تطبيقه في أكثر المشاريع العادية ، والتي لا تدعي أنها مبتكرة. يمكن لأي مطور .NET جاهز لإتقان مكتبة جديدة أن يصبح مؤلف مثل هذا النموذج.
لدي خلفية ML أكثر قليلاً من مطور .NET العادي ، لذلك قررت بنفسي: بالنسبة للصور ، ربما لا ، بالنسبة للحالات المعقدة ، ولكن بالنسبة لمهام الجدول البسيطة ، بالتأكيد نعم. في الوقت الحالي ، أصبح من الأسهل بالنسبة لي القيام بأي مهمة ML على حزمة تكنولوجيا Python / numpy / pandas / sk-learn / keras / pytorch الأكثر دراية ، ومع ذلك ، كنت قد فعلت حالة نموذجية للتضمين لاحقًا في تطبيق .NET باستخدام ML.NET .
بالمناسبة ، من الجيد أن يعمل إطار النص بشكل مثالي دون أي إيماءات غير ضرورية والحاجة إلى توليف من قبل المستخدم. بشكل عام ، هذا ليس مفاجئًا ، لأنه في الممارسة العملية ، على كميات صغيرة من البيانات ، تعمل ملفات TfIDF القديمة الجيدة مع المصنفات مثل SVC / NaiveBayes / LR بشكل جيد. نوقش هذا في فصل الصيف DataFest في تقرير من iPavlov - على بعض مجموعة اختبار word2vec ، وتمت مقارنة GloVe ، ELMo (نوعا ما) و BERT مع TfIdf. في الاختبار ، كان من الممكن تحقيق تفوق اثنين في المئة في حالة واحدة فقط من 7 إلى 10 حالات ، على الرغم من أن كمية الموارد التي تنفق على التدريب ليست قابلة للمقارنة على الإطلاق.
ملاحظة: أصبح تعميم ML بين الجماهير في الاتجاه ، حتى مع استخدام " أداة Google لإنشاء الذكاء الاصطناعى ، والتي يمكن أن يستخدمها حتى تلميذ ." كل شيء مضحك وبديهية للمستخدم ، ولكن ما يجري بالفعل وراء الكواليس في السحابة غير واضح. في هذا ، لمطوري .NET ، يبدو ML.NET مع منشئ نماذج كخيار أكثر جاذبية.
ذهب PSS العرض التقديمي مع اثارة ضجة ، وكان الدافع الزملاء لمحاولة :)
ردود الفعل
بالمناسبة ، قالت إحدى الرسائل الإخبارية التي تحمل العنوان "ML.NET Model Builder":
يقدم لنا ملاحظاتك
إذا واجهت أية مشكلات ، أو شعرت أن هناك شيئًا ما مفقودًا ، أو كنت تحب شيئًا ما عن ML.NET Model Builder ، فأخبرنا عن طريق إنشاء مشكلة في تقرير GitHub الخاص بنا.
لا يزال Model Builder في المعاينة ، وتعليقاتك مهمة للغاية في قيادة الاتجاه الذي نتخذه باستخدام هذه الأداة!
هذه المادة يمكن اعتبار ردود الفعل!
مراجع
على ML.NET
لمقال قديم مع التوجيه