تحية!
هل ترى في كثير من الأحيان تعليقات سامة على الشبكات الاجتماعية؟ ربما يعتمد ذلك على المحتوى الذي تشاهده. أقترح تجربة القليل حول هذا الموضوع وتعليم الشبكة العصبية لتحديد تعليقات كاره.
لذلك ، فإن هدفنا العالمي هو تحديد ما إذا كان التعليق عدوانيًا ، أي أننا نتعامل مع التصنيف الثنائي. سنكتب شبكة عصبية بسيطة ، ونقوم بتدريبها على مجموعة من تعليقات الشبكات الاجتماعية المختلفة ، ثم سنقوم بإجراء تحليل بسيط باستخدام التصور.
للعمل سأستخدم Google Colab. تتيح لك هذه الخدمة تشغيل Jupyter Notebooks ، والوصول إلى GPU (NVidia Tesla K80) مجانًا ، مما يسرع عملية التعلم. سأحتاج إلى الواجهة الخلفية TensorFlow ، الإصدار الافتراضي في Colab 1.15.0 ، لذلك فقط قم بالترقية إلى 2.0.0.
نحن استيراد الوحدة النمطية والتحديث.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
يمكنك رؤية الإصدار الحالي مثل هذا.
print(tf.__version__)
يتم العمل التحضيري ، ونحن استيراد جميع الوحدات اللازمة.
import os import numpy as np
وصف المكتبات المستخدمة
- السراج - للعمل مع نظام الملفات
- الباندا - مكتبة لتحليل البيانات الجدولية
- keras.preprocessing.Text - من أجل معالجة النصوص ، لإرسالها في شكل رقمي لتدريب شبكة عصبية
- sklearn.train_test_split - لفصل بيانات الاختبار عن التدريب
- matplotlib - لتصور عملية التعلم
- sklearn.normalize - لتطبيع بيانات الاختبار والتدريب
تحليل البيانات مع Kaggle
يمكنني تحميل البيانات مباشرة إلى الكمبيوتر المحمول Colab نفسه. علاوة على ذلك ، دون أي مشاكل ، أنا بالفعل استخراجها.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
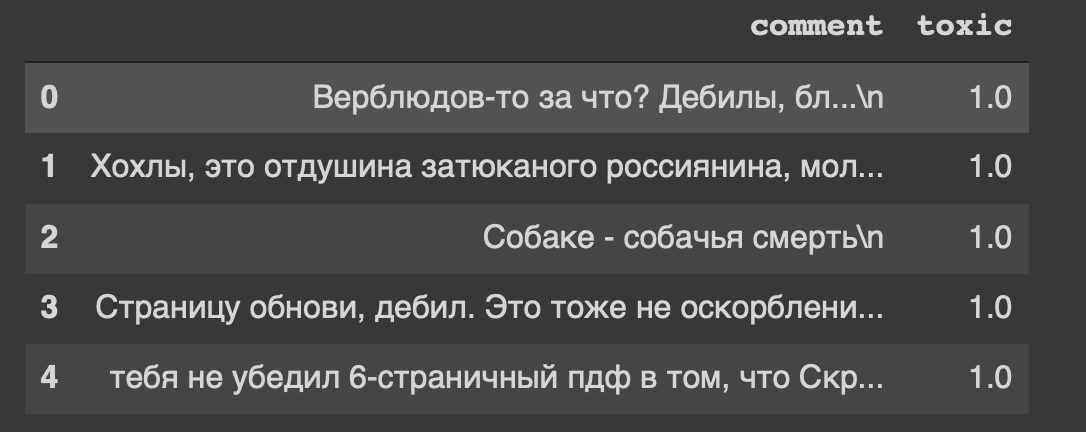
وهذا هو عنوان مجموعة البيانات الخاصة بنا ... أنا أيضًا ، بطريقة ما ، أشعر بعدم الارتياح من "تحديث الصفحة ، معتوه".
لذلك ، توجد بياناتنا في الجدول ، وسوف نقسمها إلى قسمين: بيانات للتدريب واختبار النماذج. ولكن هذا هو النص كله ، هناك شيء يجب القيام به.
معالجة البيانات
إزالة أحرف السطر الجديد من النص.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
تحتوي التعليقات على نوع بيانات حقيقي ، نحتاج إلى ترجمتها إلى عدد صحيح. بعد ذلك ، احفظه في متغير منفصل.
target = np.array(df['toxic'].astype('uint8')) target[:5]
الآن سنقوم بمعالجة النص قليلاً باستخدام فئة Tokenizer. دعنا نكتب نسخة منه.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
بسرعة حول المعلمات- num_words - عدد الكلمات الثابتة (الأكثر شيوعًا)
- مرشحات - سلسلة من الشخصيات ليتم حذفها
- السفلي - معلمة منطقية تتحكم في ما إذا كان النص سيكون صغيرًا
- انقسام - الرمز الرئيسي للعرض الانقسام
- char_level - يشير إلى ما إذا كان سيتم اعتبار كلمة واحدة كلمة أم لا
والآن سنقوم بمعالجة النص باستخدام الفصل.
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
لقد حصلنا على 14 عينة من الصفوف وأعمدة ميزات 30 كيلو.

أقوم بإنشاء نموذج من طبقتين: Dense و Dropout.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
نحن نطبيع المصفوفة ونقسم البيانات إلى جزأين ، على النحو المتفق عليه (التدريب والاختبار).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
التدريب النموذجي
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
سأعرض عملية التعلم في التكرارات الأخيرة.

تصور لعملية التعلم
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
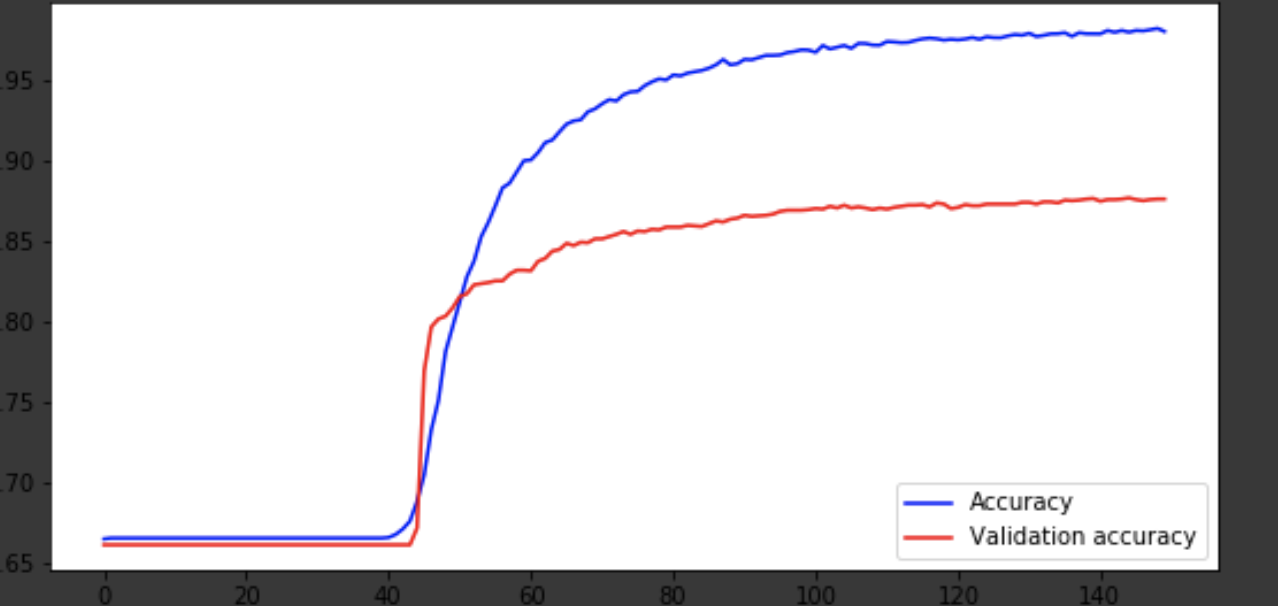
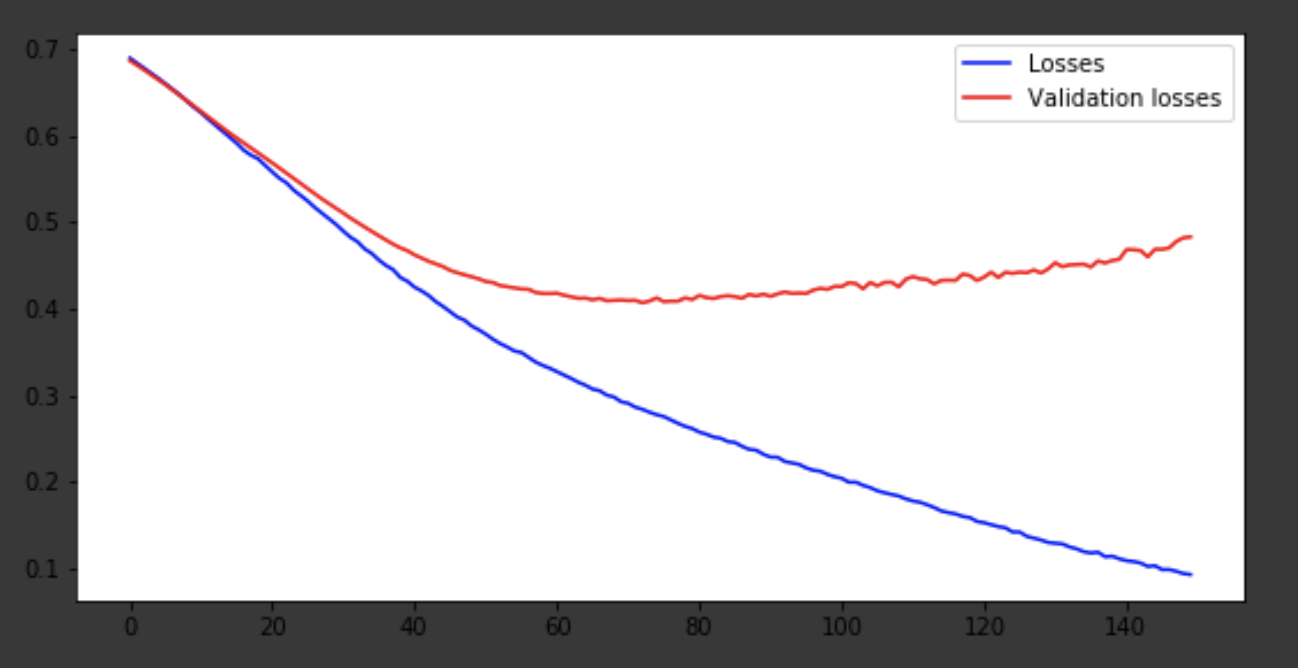
استنتاج
خرج النموذج في وقت قريب من عصر 75 ، ثم يتصرف بشكل سيء. دقة 0.85 لا ينزعج. يمكنك أن تستمتع بعدد الطبقات ، والمعايير الفوقية ومحاولة تحسين النتيجة. انها دائما مثيرة للاهتمام وجزء من العمل. اكتب عن أفكارك في التعليقات ، وسنرى عدد القبعات التي ستكسبها هذه المقالة.