تحسبا لبدء سلسلة جديدة في الدورة التدريبية "الشبكات العصبية في بيثون" أعدت لك ترجمة لمقال مثير للاهتمام.
واحدة من المشاكل الرئيسية في تنفيذ الجيل الجديد من أجهزة الكمبيوتر الكمومية تكمن في العملاء الأساسية:
qubit . يمكن أن يتفاعل Qubits مع أي كائنات في المنطقة المجاورة مباشرة والتي تنقل
الطاقة بالقرب من
الفوتونات المتجولة الخاصة بها (مثل الحقول الكهرومغناطيسية غير المرغوب فيها ،
والفونونات (الاهتزازات الميكانيكية لجهاز الكم) أو العيوب الكمومية (مخالفات على سطح الرقائق التي ظهرت أثناء مرحلة التصنيع) ، والتي يمكن أن تتغير بشكل غير متوقع حالة الكيبيتس من تلقاء نفسها.
الأمر معقد بسبب العديد من المهام التي تضع الأدوات المستخدمة للتحكم في البتات. تتم معالجة الكيوبيتات وقراءتها بطرق
كلاسيكية : إشارات تناظرية في شكل حقول كهرومغناطيسية ، مقرونة بلوحة فيزيائية مبنية عليها كيوبيت ، على سبيل المثال ، دائرة كهربائية فائقة التوصيل. تؤدي العيوب في إلكترونيات التحكم (التي تؤدي إلى الضوضاء البيضاء) والتداخل من مصادر الإشعاع الخارجية والتقلبات في المحولات الرقمية إلى التناظرية إلى أخطاء ستوكاستيك أكبر تؤدي إلى تفاقم تشغيل الدوائر الدقيقة الكمومية. تؤثر هذه المشكلات العملية على دقة العمليات الحسابية ، وبالتالي تحد من تطبيق الجيل القادم من الأجهزة الكمومية.
من أجل زيادة القدرة الحاسوبية لأجهزة الكمبيوتر الكمومية وفتح الطريق أمام الحوسبة الكمومية على نطاق واسع ، من الضروري أولاً بناء نماذج مادية تصف بدقة هذه المشكلات التجريبية.
في مقالة
"التحكم الكمي الشامل من خلال التعلم الداعم
العميق" ، المنشورة في دورية Nature Partner Journal (npj) ، (https://www.nature.com/npjqi/articles) ، قدمنا بنية جديدة للتحكم الكمي تم إنشاؤها باستخدام التعلم العميق مع تعزيز حيث يمكن تغليف المشاكل العملية لتحسين التحكم الكمومي بوظيفة فقد واحدة. يوفر الهيكل قيد النظر انخفاضًا في متوسط الخطأ
للبوابة الكمومية لأمرين من حيث الحجم مقارنةً بالمحاليل العشوائية المعيارية لنسب التدرج وتقليلًا كبيرًا في وقت البوابة للقيم المثلى لمناظرات تركيب البوابة. نتائجنا تفتح آفاقا جديدة لنمذجة الكم ، والكيمياء الكمومية واختبارات التميز الكمومي باستخدام الأجهزة الكمومية في المستقبل القريب.
يعتمد ابتكار نموذج التحكم الكمومي هذا على تطوير وظيفة التحكم الكمومي وطريقة التحسين الفعالة القائمة على التعلم العميق مع التعزيز. لتطوير دالة خسارة شاملة ، نحتاج أولاً إلى تطوير نموذج مادي لعملية واقعية للتحكم الكمي يمكننا من خلالها التنبؤ بدقة بحجم الخطأ. أحد أكثر الأخطاء المزعجة في تقييم دقة الحوسبة الكمومية هو التسرب: مقدار المعلومات الكمية المفقودة أثناء الحساب. يحدث هذا التسرب عادةً عندما تتغير الحالة الكمية للبتة إلى مستوى طاقة أعلى أو إلى انخفاض بسبب الانبعاثات التلقائية. نظرًا لحدوث خطأ في التسرب ، لا يتم فقد المعلومات الكمومية المفيدة فحسب ، بل إنه يؤدي أيضًا إلى انخفاض "الكم" ويقلل في النهاية من أداء الكمبيوتر الكمومي إلى أداء جهاز كمبيوتر ذي بنية كلاسيكية.
من الممارسات الشائعة لتقدير المعلومات المفقودة بدقة أثناء حساب الكم هو نمذجة الحساب بالكامل أولاً. ومع ذلك ، فإن هذا ينفي الهدف الكامل المتمثل في إنشاء أجهزة كمبيوتر كمومية كبيرة الحجم ، لأن ميزتها هي أنها قادرة على إجراء حسابات مستحيلة لأجهزة الكمبيوتر الكلاسيكية. مع تحسين النمذجة المادية ، تتيح لنا وظيفة الخسارة الشائعة تحسين أخطاء التسرب المتراكمة ، وانتهاك شروط حدود التحكم ، وزمن الصمام الكامل ودقة الصمام.
مع وظيفة إدارة الخسارة الجديدة ، تتمثل الخطوة التالية في استخدام أداة تحسين فعالة لتقليلها. طرق التحسين الحالية ليست جيدة بما يكفي للبحث عن حلول عالية الدقة يمكن الاعتماد عليها للتحكم في التقلبات. بدلاً من ذلك ، نستخدم طريقة تعتمد على طريقة التعلم العميق مع سياسة التعزيز (RL) ،
RL - وهي منطقة موثوق بها . نظرًا لأن هذه الطريقة توضح الأداء الجيد في جميع مهام الاختبار ، فهي مقاومة بطبيعتها لعينات الضوضاء ويمكنها تحسين مشكلات التحكم المعقدة بمئات الملايين من معلمات التحكم. هناك اختلاف كبير بين طريقة RL هذه الموجودة على السياسة وطرق RL خارج السياسة التي تمت دراستها سابقًا وهي أن سياسة الإدارة يتم تقديمها بشكل مستقل عن إدارة الخسائر. من ناحية أخرى ، تستخدم جميع سياسات RL ، مثل
Q-learning ، شبكة عصبية واحدة لتمثيل مسار التحكم والمكافأة المرتبطة به ، حيث يحدد مسار التحكم إشارات التحكم التي يجب أن ترتبط مع وحدات البت في تدابير مختلفة ، وتقيس مكافأة المكافئة مدى جودة اللباقة مراقبة الكم.
RL On-Policy معروفة جيدًا لقدرتها على استخدام ميزات غير محلية في مسارات التحكم ، والتي تصبح حرجة عندما يكون مشهد التحكم متعدد الأبعاد ومكتظًا بعدد كبير من الحلول غير الشاملة ، كما هو الحال مع الأنظمة الكمومية.
نقوم بتشفير مسار التحكم في شبكة عصبية متصلة بالكامل ثلاثية الطبقات - سياسة NN ، ووظيفة فقدان التحكم في الشبكة العصبية الثانية - قيمة NN ، والتي تعكس جائزة المستقبل المخفضة. تم الحصول على حلول تحكم موثوق بها من خلال عوامل التعلم المعززة التي تقوم بتدريب كل من الشبكات العصبية في بيئة عشوائية والتي تحاكي التحكم الواقعي في الضوضاء. نحن نقدم حلاً للتحكم في مجموعة من البوابات الكمومية ذات المعيارين المستمرتين والتي لها أهمية خاصة عند تطبيقها على كيمياء الكم ، ولكنها مكلفة للغاية بحيث لا يمكن تنفيذها باستخدام مجموعة عالمية قياسية من البوابات.
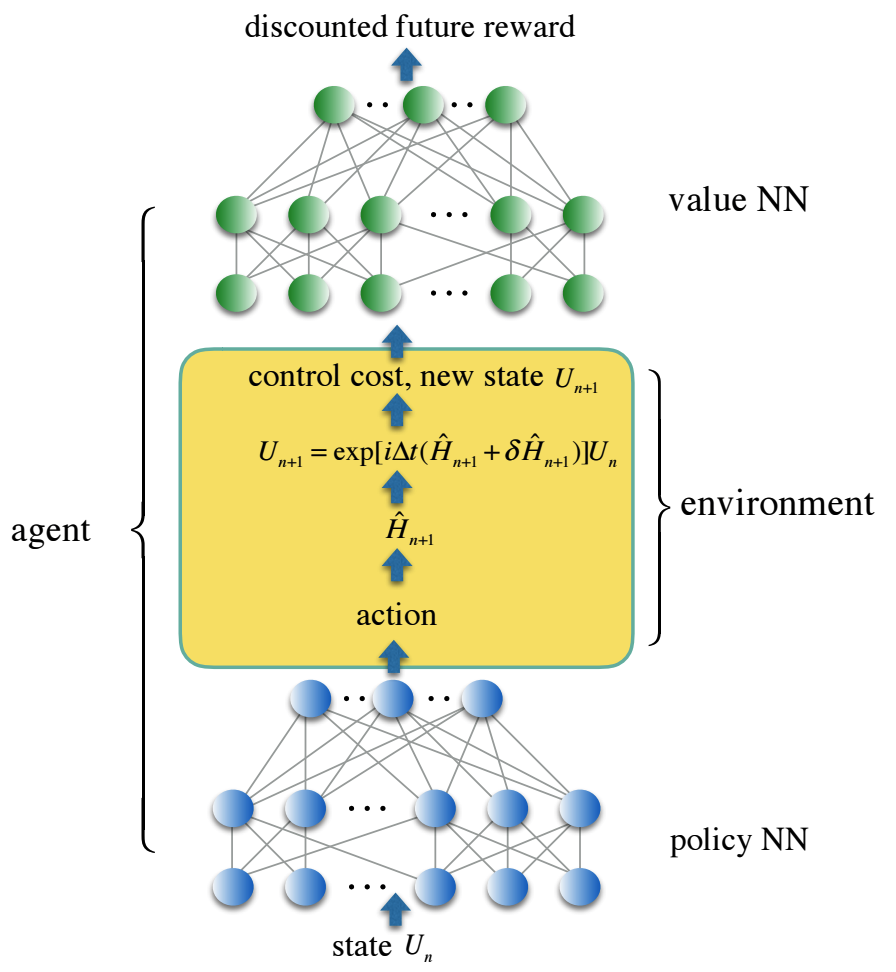
في إطار هذا الهيكل الجديد ، تُظهر المحاكاة العددية لدينا انخفاضًا بمقدار الضعف أضعافًا في أخطاء البوابات الكمومية وانخفاضًا في وقت البوابات لعائلة بوابات الكم المحاكاة ذات المعلمات المستمرة بمعدل واحد من حيث الحجم مقارنة بالنُهج التقليدية باستخدام مجموعة عالمية من البوابات.
يؤكد هذا العمل على أهمية استخدام أساليب جديدة للتعلم الآلي وأحدث خوارزميات الكم التي تستخدم المرونة وقوة المعالجة الإضافية لدائرة التحكم الكمي العالمية. من أجل دمج التعلم الآلي بالكامل وزيادة القدرات الحسابية ، من الضروري إجراء تجارب إضافية ، على غرار ما تم تقديمه في هذا العمل.