
وفقًا للمحللين ، سينمو سوق مراكز البيانات في السنوات المقبلة بنسبة 38٪ سنويًا وسيزداد إلى 35 مليار دولار على مدار خمس سنوات ، وأهم مكان في استخدام الموارد (من حيث كثافة الحوسبة) هو التعلم العميق والشبكات العصبية ومهام الذكاء الاصطناعي.
بالطبع ، لن تكون إنتل غير مبالية بمشاهدة كيف تستحوذ نفيديا (و AMD ، إلى حد أقل) مع وحدات معالجة الرسومات الخاصة بها على هذا السوق ، بما في ذلك القطاع الأسرع نموًا. في الأسبوع الماضي ، أصدر عملاق الصناعة الإلكترونية الدقيقة العديد من الإعلانات البارزة في آن واحد:
- معالجات للشبكات العصبية Nervana NNP-T1000 و NNP-I1000 (NNP: معالجات الشبكة العصبية) ، وكذلك شريحة Movidius VPU ؛
- 10nm Xeon Scalable معالجات (الاسم الرمزي Sapphire Rapids)؛
- واجهات برمجة موحدة oneAPI (لوحدة المعالجة المركزية ، GPU ، FPGA) - منافس لـ Nvidia CUDA ؛
- وحدة معالجة الرسومات 7nm لمراكز البيانات ، المسمى الرمز بونتي فيكيو ، على بنية X الإلكترونية الجديدة.
أورورا الحوسبة وحدات
على وحدات المعالجة المركزية (CPU) ووحدات معالجة الرسومات (GPU) و oneAPI ، سيقومون بتكوين وحدات حوسبة Aurora للحاسوب العملاق مسمى بمستوى أداء يبلغ 1 exaflops (10 ^ 18 عملية في الثانية). من المفترض أن يتم تثبيت هذا الجهاز في مختبر أرجون الوطني التابع لوزارة الطاقة الأمريكية.

تحتوي كل وحدة حسابية على معالجات Sapphire Rapids وستة وحدات معالجة رسومات متصلة عبر ناقل CXL.

وفقًا
لتقديرات AnandTech ، في نظام يتكون من 200 رف ، كما هو مذكور ، إذا قمت بطرح الاحتياطي للشبكة ومحركات الأقراص ، فسيتم احتواء حوالي 2400 عقدة Aurora من وحدتين. هذا هو ما مجموعه حوالي 5000 معالجات Sapphire Rapids و 15000 بونتي فيكيو. إذا قمنا بتقسيم الأداء المعلن لـ 1 exaflops على عدد وحدات معالجة الرسومات ، فسيظهر حوالي 66.6 teraflops لكل GPU. علاوة على ذلك ، بافتراض أن أداء وحدة المعالجة المركزية يبلغ 14 teraflops ، ما زلنا نحصل على حوالي 50 teraflops ، وهذا يمثل زيادة خمسة أضعاف في أداء وحدة معالجة الرسومات في مراكز البيانات بحلول عام 2021.
بالطبع ، لا تقتصر الخطط على كمبيوتر عملاق لوزارة الطاقة. أعلنت إنتل أن لينوفو وأتوس يستعدان بالفعل لإطلاق منصات الخادم القائمة على Xeon CPU و X
e GPU و oneAPI. وبالتالي ، فإن وحدات الحوسبة أورورا في شكل ما سوف تجد التطبيق في مراكز البيانات الأخرى.
ينبغي إطلاق الحاسوب العملاق في عام 2021. في الوقت نفسه ، يجب أن تظهر وحدات معالجة الرسومات X-7 نانومتر في السوق.
وفقًا لشركة Intel ، تتوافق الآن الحلول عالية الأداء التقليدية (HPC) مع الذكاء الاصطناعي ، لتنتقل إلى أعباء العمل التي تستخدم التعلم العميق. HPC و AI والتحليلات هي أعباء العمل الرئيسية الثلاثة التي تدفع الطلب على موارد الحوسبة: "مجموعة متنوعة من احتياجات الحوسبة هذه تشجع الحوسبة غير المتجانسة.
سعيد رجب حضرة ، نائب الرئيس والمدير العام لشركة إنتل إنتربرايز والحكومة. - الحلول العالمية لم تعد مناسبة هنا. في عصر التقارب هذا ، يجب أن تنظر إلى البنى التي تم ضبطها حسب الاحتياجات المختلفة لأنواع مختلفة من أعباء العمل. "
GPU لمراكز البيانات

بونتي فيكيو هو أول GPU في بنية X
e الجديدة. سوف تصبح البنية نفسها الأساس لوحدة معالجة الرسومات في مختلف القطاعات:
- الحوسبة عالية الأداء ؛
- التعلم العميق.
- الحوسبة السحابية
- الرسومات.
- ترميز الوسائط ؛
- محطات العمل
- أجهزة الكمبيوتر المحمولة
- أجهزة الكمبيوتر المكتبية العادية.
- الأجهزة المحمولة و ultramobile.

يقول آري راوخ ، نائب رئيس شركة إنتل للهندسة المعمارية والرسومات والبرامج ، إن إحدى هندسة GPU ستمنح المطورين "بنية مشتركة" ، ولكن كجزء من هذه الهندسة المعمارية ، تقوم الشركة بتطوير "الكثير من البنى الدقيقة التي توفر الأداء الأكثر كفاءة لكل منهم." هذه أعباء العمل ".
تعتمد وحدة معالجة الرسومات Ponte Vecchio GPU على البنية الدقيقة X
e خصيصًا لـ HPC و AI ، وتتضمن ميزات البنية الدقيقة محرك مصفوفة متوازي مرن مع مصفوفات متجه ، وإنتاجية عالية لحسابات الفاصلة العائمة المزدوجة الدقة (FP64) والإنتاجية الفائقة للذاكرة المؤقتة والذاكرة. بالنسبة إلى تنسيقات INT8 و Bfloat16 و FP32 ، سيكون هناك Matrix Engine منفصل للمعالجة المتوازية للمصفوفات (ربما تمثيلية من TensorCore) ، وبالنسبة إلى FP64 ، فإن التسارع سوف يصل إلى 40 مرة لكل وحدة حسابية.
"يتطلب عبء العمل هذا أداءً حسابيًا مرتفعًا ، لذلك ركزنا على إضافة عدد كبير من وحدات الموجه والمصفوفة والحوسبة المتوازية التي تم تكييفها وتحسينها لتناسب عبء العمل" ، قال راوخ.
ستكون بونتي فيكيو أول وحدة معالجة الرسومات من الجيل الجديد. تطبق العديد من التقنيات الجديدة التي طورتها إنتل في السنوات الأخيرة:
- عملية الإنتاج 7 نانومتر.
- تخطيط الطبقات للدوائر المتكاملة Foveros 3D ؛
- EMIB (جسر ربط متعدد الأجزاء مضمن) لتوصيل العديد من البلورات على ركيزة واحدة ؛
- X e Link على معيار ربط CXL الجديد (استنادًا إلى PCI Express 5.0) - الوصول إلى وحدة معالجة الرسومات عبر مساحة ذاكرة واحدة.

 دوائر Foveros ثلاثية الأبعاد المتكاملة من عرض إنتل ديسمبر 2018
دوائر Foveros ثلاثية الأبعاد المتكاملة من عرض إنتل ديسمبر 2018لم يتم الإعلان عن المواصفات الفنية للرقاقة. يقولون أنه في وحدات معالجة الرسومات هذه ، سيكون هناك الآلاف من الوحدات التنفيذية المتصلة عبر XEMF (نسيج ذاكرة XE) مع الذاكرة وذاكرة التخزين المؤقت.

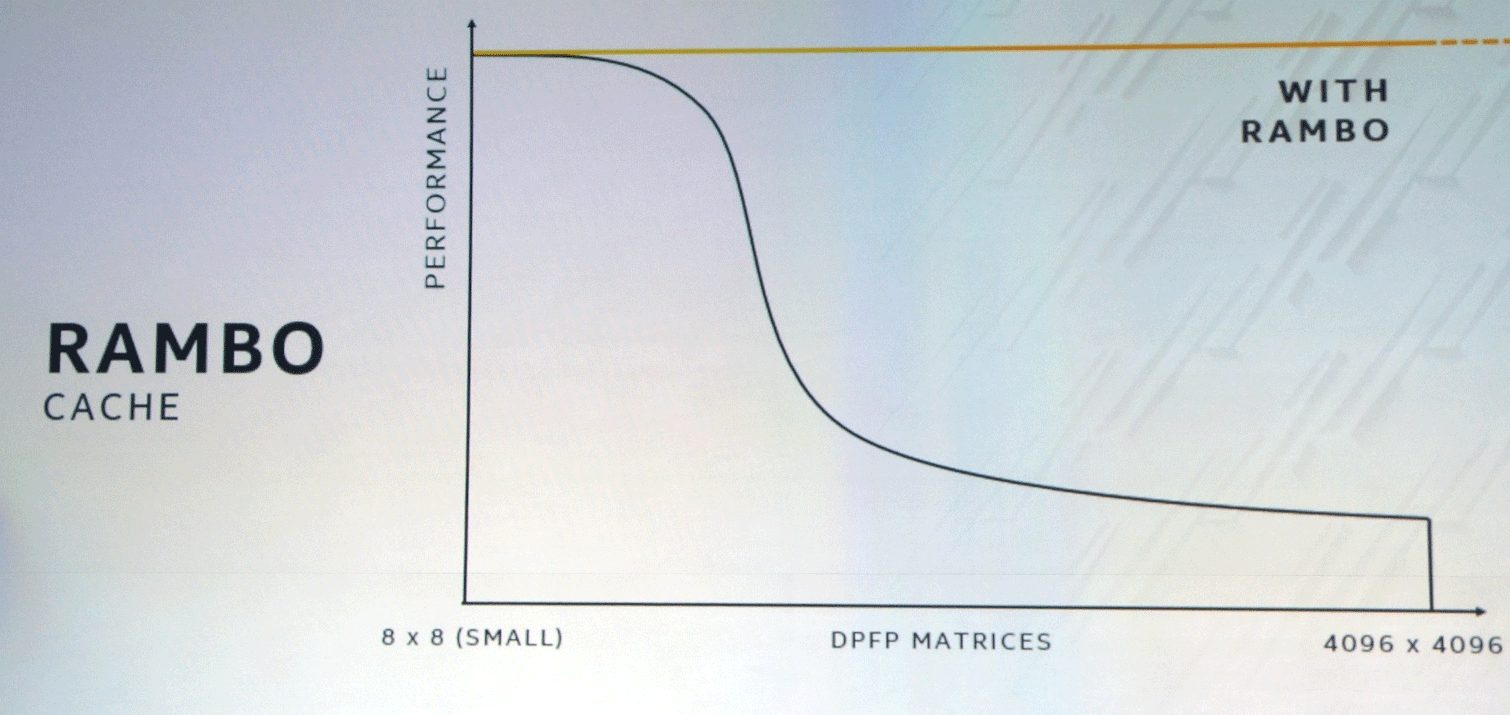
تعمل حافلة XEMF مع ذاكرة التخزين المؤقت Rambo Cache فائقة السرعة للتخلص من عنق الزجاجة في الوصول إلى الذاكرة. يتصل هذا التخزين المؤقت بوحدات الحوسبة من خلال Foveros ، وسيتم استخدام EMIB لتوصيل ذاكرة HBM.
مزيج من SIMT و SIMD النهج الخاصة GPU و CPU ، على التوالي ، وتعليمات متجه بطول متغيرة ستوفر زيادة كبيرة في الأداء في بعض فئات المهام.

يتوقع الكثيرون أن تتنافس Intel مع Nvidia و AMD في السوق لمراكز البيانات و AI. لا يتعلق الأمر فقط بالمنافسة السعرية ، ولكن أيضًا بروز منصات تكنولوجية بديلة ، والتي ستحفز التقدم التكنولوجي الشامل.
OneAPI: قمة التجريد للحديد غير المتجانس
بالإضافة إلى الإعلان عن معدات جديدة ، أصدرت Intel نسخة تجريبية من واجهات البرنامج الموحد oneAPI. وهي مصممة لتسهيل عمل المطورين الذين ، من أجل تحسين برامجهم إلى أقصى حد ، كان عليهم تقليديا التبديل بين لغات البرمجة المختلفة والمكتبات باستخدام البرامج الوسيطة والأطر.
بشكل افتراضي ، من المقبول في الصناعة أنه على مستوى منخفض ، يجب إعداد كود مختلف لكل هندسة. على سبيل المثال ، تم تحسين TensorFlow في البداية تمامًا في وقت إصدار وحدة معالجة الرسومات (GPU) لبائع واحد (لـ Nvidia CUDA).
وقال بيل سافاج ، نائب رئيس قسم العمارة والرسومات والبرمجيات بشركة إنتل: "يحاول OneAPI حل هذه المشكلات من خلال تقديم واجهة مشتركة منخفضة المستوى لأجهزة غير متجانسة ذات أداء لا يضاهى". "بحيث يمكن للمطورين كتابة البرامج مباشرة على الأجهزة من خلال اللغات والمكتبات المشتركة بين مختلف البنيات والبائعين ، وكذلك التأكد من أن البرامج الوسيطة والأطر تعمل على oneAPI وأن تكون مُحسّنة تمامًا للمطورين الذين هم في قمة هذا التجريد".
توصف Intel oneAPI بأنها "معيار مفتوح لدعم المجتمع والصناعة" ، مما سيتيح "إعادة استخدام الكود عبر الهياكل والأجهزة من مختلف الشركات المصنعة."
ستتضمن مواصفات oneAPI لغة برمجة DPC ++ للهيكل المتقاطع المعتمد على C ++ و SYCL ، بالإضافة إلى "واجهات برمجة تطبيقات قوية لتسريع الوظائف الرئيسية الخاصة بالمجال".
بالإضافة إلى برنامج التحويل البرمجي DPC ++ ومكتبة واجهة برمجة التطبيقات ، سيتم إصدار أدوات خاصة ، بما في ذلك VTune Inspector Advisor ، ومصحح الأخطاء ، و "أداة التوافق" لنقل رمز CUDA (Nvidia) إلى DPC ++.
لتحفيز الانتقال إلى oneAPI ، أطلقت Intel صندوق حماية في
DevCloud لتطوير واختبار البرامج على عدد من وحدات المعالجة المركزية (CPU) ووحدات معالجة الرسومات ووحدات معالجة البيانات (FPGA). لا يتطلب العمل مع الصندوق الرمل تثبيت أي جهاز أو برنامج.
وفي الوقت نفسه ، ارتفعت إيرادات نفيديا للربع
إلى 3 مليارات دولار ، بينما في سوق مراكز البيانات ، كان النمو خلال الأشهر الثلاثة 11 ٪ (726 مليون دولار). مبيعات معالجات V100 و T4 تحطيم جميع الأرقام القياسية. لا تزال إنتل تنظر إليها من الخارج ، لكننا نعرف بالفعل ماهية الإجابة. الأكثر إثارة للاهتمام هو مجرد بداية.