
العالم من حولنا مليء بجميع أنواع المعلومات التي يعالجها دماغنا باستمرار. يتلقى هذه المعلومات من خلال الحواس ، كل منها مسؤول عن حصتها من الإشارات: العيون (الرؤية) ، واللسان (الذوق) ، والأنف (الرائحة) ، والجلد (اللمس) ، والجهاز الدهليزي (التوازن ، والمكان المكاني ، والإحساس بالوزن) و آذان (الصوت). من خلال تجميع إشارات من جميع هذه الأجهزة ، يمكن لعقلنا بناء صورة دقيقة للبيئة. ولكن ليست كل جوانب معالجة الإشارات الخارجية معروفة لنا. واحدة من هذه الأسرار هي آلية تعريب مصدر الصوت.
اقترح علماء من مختبر الهندسة العصبية للنطق والسمع (معهد نيوجيرزي للتكنولوجيا) نموذجًا جديدًا للعملية العصبية لتوطين الصوت. ما هي بالضبط العمليات التي تحدث في الدماغ أثناء إدراك الصوت ، وكيف يفهم عقلك موقف مصدر الصوت وكيف يمكن لهذه الدراسة أن تساعد في مكافحة عيوب السمع. نتعرف على هذا من تقرير مجموعة الأبحاث. دعنا نذهب.
أساس الدراسة
المعلومات التي يتلقاها دماغنا من الحواس تختلف عن بعضها البعض سواء من حيث المصدر أو من حيث معالجتها. تظهر بعض الإشارات على الفور أمام عقولنا في شكل معلومات دقيقة ، بينما يحتاج البعض الآخر إلى عمليات حسابية إضافية. تحدث تقريبًا ، فنحن نشعر باللمس على الفور ، ولكن عندما نسمع الصوت ، لا يزال يتعين علينا العثور على مصدره.
أساس توطين الأصوات في المستوى الأفقي هو
الفارق الزمني بين الوقت
* (ITD من
الفارق الزمني بين الوقت ) للأصوات التي تصل إلى آذان المستمع.
قاعدة interaural * - المسافة بين الأذنين.
هناك منطقة معينة في المخ (زيت الزيتون متفوق أو MBO) المسؤولة عن هذه العملية. في لحظة تلقي إشارة الصوت في MBO ، يتم تحويل الاختلافات interaural في الوقت إلى معدل رد فعل الخلايا العصبية. يشبه شكل منحنيات سرعة خرج MBO كدالة ITD شكل وظيفة الارتباط المتبادل لإشارات الإدخال لكل أذن.
تظل طريقة معالجة المعلومات وتفسيرها في MBO غير واضحة تمامًا ، وهذا هو سبب وجود العديد من النظريات المتضاربة جدًا. النظرية الأكثر شهرة والكلاسيكية في حقيقة توطين الصوت هي نموذج Jeffress (
Lloyd A. Jeffress ). يعتمد على
خط محدد * للكشف عن الخلايا العصبية الحساسة للتزامن بكلتا الأذنين من إشارات الإدخال العصبي من كل أذن ، وكل خلية عصبية هي الأكثر حساسية لقيمة ITD محددة (
1A ).
مبدأ الخط المحدد * هو فرضية تشرح كيف أن الأعصاب المختلفة ، والتي تستخدم جميعها نفس المبادئ الفسيولوجية لنقل النبضات على محاورها ، قادرة على توليد أحاسيس مختلفة. يمكن للأعصاب المتشابهة من الناحية الهيكلية توليد تصورات حسية مختلفة إذا كانت مرتبطة بخلايا عصبية فريدة في الجهاز العصبي المركزي قادرة على فك تشفير الإشارات العصبية المماثلة بطرق مختلفة.
 الصورة رقم 1
الصورة رقم 1يشبه هذا النموذج حسابيًا الترميز العصبي استنادًا إلى الارتباطات غير المحدودة للأصوات التي تصل إلى كلتا الأذنين.
يوجد أيضًا نموذج يُفترض فيه أن توطين الصوت يمكن نمذجه على أساس الاختلافات في معدل تفاعل مجموعات معينة من الخلايا العصبية من نصفي الكرة المخية المختلفين ، أي نموذج التباين بين الكريات (
1B ).
حتى الآن ، كان من الصعب تحديد أي النظريتين (النماذج) صحيحة بشكل لا لبس فيه ، بالنظر إلى أن كل منهما يتوقع تبعات مختلفة لتوطين الصوت على شدة الصوت.
في الدراسة التي ندرسها اليوم ، قرر العلماء الجمع بين كلا النموذجين من أجل فهم ما إذا كان تصور الأصوات يعتمد على الترميز العصبي أو على الفرق في استجابة المجموعات العصبية الفردية. أجريت عدة تجارب شارك فيها أشخاص تتراوح أعمارهم بين 18 و 27 عامًا (5 نساء و 7 رجال). كان قياس السمع (قياس حدة السمع) للمشاركين 25 ديسيبل أو أعلى بتردد من 250 إلى 8000 هرتز. تم وضع المشاركين في التجربة في غرفة عازلة للصوت حيث تم معايرة المعدات الخاصة بدقة عالية. يجب على المشاركين ، بعد سماع إشارة صوت ، الإشارة إلى الاتجاه الذي تأتي منه.
نتائج البحوث
لتقييم اعتماد
تباعد نشاط الدماغ على شدة الصوت استجابةً لخلايا عصبية ملحوظة ، استخدمنا بيانات عن معدل تفاعل الخلايا العصبية في قلب الطبقة الدماغية لبومة الحظيرة.
اللصوصية * - عدم تناسق نصفي اليسار واليمين من الجسم.
لتقييم اعتماد الاعتماد على نشاط الدماغ على معدل تفاعل مجموعات معينة من الخلايا العصبية ، استخدمنا بيانات النشاط الخاصة بالدماغين السفليين لقرد الريسوس ، وبعد ذلك تم حساب الاختلافات في سرعة الخلايا العصبية من نصفي الكرة الأرضية المختلفة.
يشير نموذج الخط المرتبط بكاشفات الخلايا العصبية إلى أنه مع انخفاض شدة الصوت ، تتقارب أفقية المصدر المدرك في قيم متوسطة مماثلة لنسبة الأصوات الهادئة والصاخبة (
1C ).
يوحي نموذج عدم التماثل بين الكرة الأرضية ، بدوره ، بانخفاض شدة الصوت إلى الحد الأدنى تقريبًا ، فإن الأفقية المدركة ستنتقل إلى خط الوسط (
1D ).
في شدة الصوت الكلية الأعلى ، من المفترض أن تكون الخطوط الجانبية ثابتة في شدتها (تدرج في
1C و
1D ).
لذلك ، يتيح لك تحليل كيفية تأثير شدة الصوت على الاتجاه المتصوَّر للصوت تحديد طبيعة العمليات التي تجري في تلك اللحظة بدقة - الخلايا العصبية من منطقة مشتركة أو خلايا عصبية من نصفي الكرة الأرضية المختلفة.
من الواضح أن قدرة الشخص على التمييز بين ITD قد تختلف باختلاف كثافة الصوت. ومع ذلك ، يقول العلماء أنه من الصعب تفسير النتائج السابقة المتعلقة بالحساسية للـ ITD وتقييم المستمع لاتجاه مصدر الصوت كدالة لشدة الصوت. تشير بعض الدراسات إلى أنه عندما تصل شدة الصوت إلى الحد الفاصل ، تتناقص الجوانب المتصورة للمصدر. تشير دراسات أخرى إلى أنه لا يوجد تأثير للشدة على الإدراك على الإطلاق.
بمعنى آخر ، أشار العلماء "بلطف" إلى أنه لا توجد معلومات كافية في الأدبيات المتعلقة بعلاقة الـ ITD ، وكثافة الصوت ، وتحديد اتجاه مصدره. هناك نظريات موجودة كنوع من البديهيات مقبولة بشكل عام من قبل المجتمع العلمي. لذلك ، تقرر اختبار جميع النظريات والنماذج والآليات الممكنة لتصور السمع في الممارسة العملية بالتفصيل.
أُجريت التجربة الأولى باستخدام النموذج النفسي - الفيزيائي ، الذي سمح لنا بدراسة الترابط القائم على الـ ITD كدالة لكثافة الصوت في مجموعة من عشرة من المشاركين عادةً في سماع التجربة.
 الصورة رقم 2
الصورة رقم 2تم ضبط مصادر الصوت خصيصًا لتغطية معظم نطاق التردد الذي يمكن للناس من خلاله التعرف على ITD ، أي 300 إلى 1200 هرتز (
2A ).
في كل اختبار من الاختبارات ، كان على المستمع أن يشير إلى الجانب الجانبي المتوقع ، ويقاس كدالة لمستوى الأحاسيس ، في نطاق قيم ITD من 375 إلى 375 مللي ثانية. لتحديد تأثير شدة الصوت ، تم استخدام نموذج التأثير المختلط غير الخطي (NMLE) ، والذي تضمن شدة الصوت الثابتة والعشوائية.
يُبيِّن الرسم البياني
2B الشكل الجانبي المقدر مع ضوضاء مسطحة طيفية بكثافة صوتية لمستمع تمثيلي. يوضح الرسم البياني
2C البيانات الأولية (الدوائر) والمخصصة لنموذج (خطوط) NMLE لجميع المستمعين.
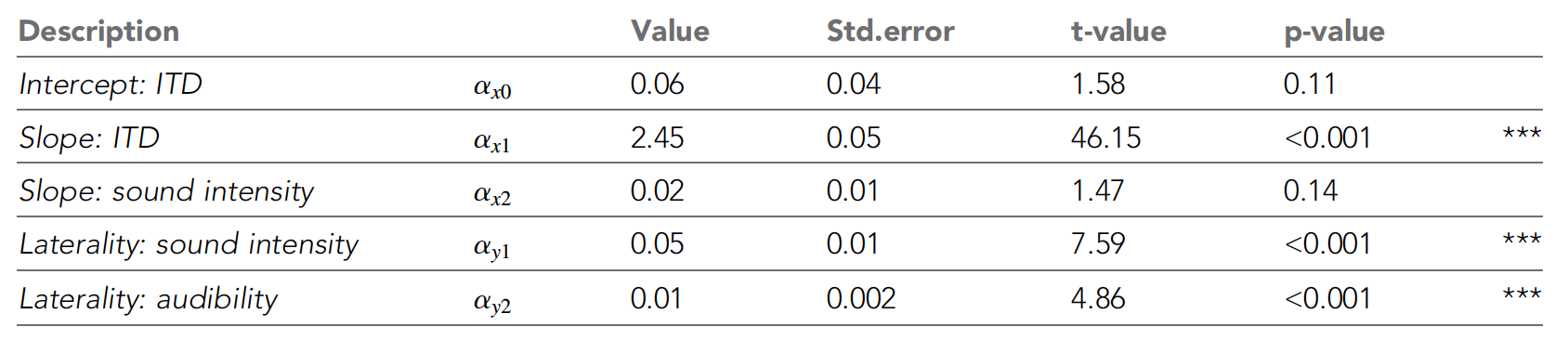 الجدول رقم 1
الجدول رقم 1يوضح الجدول أعلاه جميع معلمات NLME. يمكن أن نرى أن الأفقية المتصورة زادت مع زيادة ITD ، كما توقع العلماء. مع انخفاض في كثافة الصوت ، تحول التصور أكثر فأكثر نحو خط الوسط (أدخل على الرسم البياني
2C ).
تم تعزيز هذه الاتجاهات من خلال نموذج NLME ، الذي أظهر تأثيرًا كبيرًا على تقنية ITD وكثافة الصوت على أقصى درجة من الجوانب الجانبية ، مما يؤكد نموذج الاختلافات بين الكرة الأرضية.
بالإضافة إلى ذلك ، كان متوسط العتبات السمعية للنغمات الصافية له تأثير ضئيل على الجوانب الجانبية المتصورة. لكن شدة الصوت لم تؤثر بشكل كبير على أداء الوظائف السيكومترية.
كان الهدف الرئيسي للتجربة الثانية هو تحديد كيفية تغيير النتائج التي تم الحصول عليها في التجربة السابقة عند أخذ الخصائص الطيفية للمنبهات (الأصوات) في الاعتبار. إن الحاجة إلى اختبار الضوضاء المسطحة الطيفية عند شدة الصوت المنخفضة هي أنه قد لا يتم سماع أجزاء من الطيف ، وقد يؤثر ذلك على تحديد اتجاه الصوت. لذلك ، يمكن الخلط بين الحقيقة المتمثلة في أن عرض الجزء المسموع من الطيف مع انخفاض كثافة الصوت لنتائج التجربة الأولى.
لذلك ، تقرر إجراء تجربة أخرى ، ولكن باستخدام ضجيج
A * الموزون بالفعل.
يتم تطبيق A-weighting * على مستويات الصوت لتأخذ في الاعتبار ارتفاع الصوت النسبي الذي تصوره الأذن البشرية ، لأن الأذن أقل حساسية للترددات الصوتية المنخفضة. يتم تطبيق الترجيح A عن طريق إضافة حساب من القيم المدرجة في نطاقات الأوكتاف إلى مستويات ضغط الصوت المقاسة بوحدة dB.
يعرض الرسم البياني
ثنائي الأبعاد البيانات الأولية (الدوائر) والبيانات (الخطوط) المصممة وفقًا لنموذج NMLE لجميع المشاركين في التجربة.
أظهر تحليل للبيانات أنه عندما تكون جميع أجزاء الصوت مسموعة تقريبًا (في كلتا التجربتين الأولى والثانية) ، فإن الأفقية والانحدار المتصورين على الرسم البياني الذي يفسر التغير في الأرفف مع ITD ينخفض بتناقص كثافة الصوت.
وهكذا ، أكدت نتائج التجربة الثانية نتائج التجربة الأولى. وهذا هو ، في الممارسة العملية ، تبين أن النموذج الذي اقترحه جيفريس عام 1948 ، غير صحيح
اتضح أن توطين الأصوات يتدهور مع انخفاض في كثافة الصوت ، ويعتقد جيفريس أن الأصوات يتم إدراكها ومعالجتها على قدم المساواة بغض النظر عن شدتها.
للتعرف أكثر تفصيلاً على الفروق الدقيقة في الدراسة ، أوصي بأن تنظر في
تقرير العلماء .
خاتمة
أظهرت الافتراضات النظرية والتجارب العملية التي تؤكدها أن الخلايا العصبية في مخ الثدييات يتم تنشيطها بسرعات مختلفة اعتمادًا على اتجاه إشارة الصوت. بعد ذلك ، يقوم الدماغ بمقارنة هذه السرعات بين جميع الخلايا العصبية المشاركة في العملية لتخطيط بيئة الصوت ديناميكيًا.
نموذج Jeffresson ليس في الواقع خاطئًا بنسبة 100٪ ، لأنه يمكن استخدامه لوصف موقع مصدر الصوت في بومة الحظيرة تمامًا. نعم ، بالنسبة لبوم الحظيرة ، لا يهم شدة الصوت ، فهم سيحددون على أي حال موضع مصدره. ومع ذلك ، هذا النموذج لا يعمل مع القرود rhesus ، كما هو موضح في التجارب السابقة. لذلك ، لا يمكن لنموذج جيفريسون وصف توطين الأصوات لجميع الكائنات الحية.
أكدت التجارب مع الناس مرة أخرى أن توطين الأصوات يحدث في كائنات مختلفة بطرق مختلفة. تعذر على العديد من المشاركين تحديد موقع مصدر إشارات الصوت بشكل صحيح بسبب شدة الأصوات المنخفضة.
يعتقد العلماء أن عملهم يدل على وجود تشابه معين بين الطريقة التي نرى بها وكيف نسمع. ترتبط كلتا العمليتين بسرعة الخلايا العصبية في أجزاء مختلفة من الدماغ ، وكذلك مع تقييم هذا الاختلاف لتحديد موقع الأشياء التي نراها في الفضاء وموقع مصدر الصوت الذي نسمعه.
في المستقبل ، سيقوم الباحثون بإجراء سلسلة من التجارب لدراسة العلاقة بين السمع والبصر البشري عن كثب ، مما سيساعدنا على فهم أفضل لكيفية قيام دماغنا بإنشاء خريطة للعالم من حولنا ديناميكيًا.
شكرا لك على اهتمامك ، ابقَ فضوليًا ولديك أسبوع عمل جيدًا يا شباب! :)
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ تريد أن ترى المزيد من المواد المثيرة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية لأصدقائك ،
سحابة VPS للمطورين من 4.99 دولار ،
خصم 30 ٪ لمستخدمي Habr على تناظرية فريدة من الخوادم على مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2650 v4 (6 النوى) 10GB DDR4 240GB SSD 1Gbps من 20 دولار أو كيفية مشاركة خادم؟ (تتوفر خيارات مع RAID1 و RAID10 ، ما يصل إلى 24 مركزًا وما يصل إلى 40 جيجابايت من ذاكرة DDR4).
ديل R730xd 2 مرات أرخص؟ فقط لدينا
2 من Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6 جيجا هرتز 14 جيجا بايت 64 جيجا بايت DDR4 4 × 960 جيجا بايت SSD 1 جيجابت في الثانية 100 TV من 199 دولار في هولندا! Dell R420 - 2x E5-2430 سعة 2 جيجا هرتز 6 جيجا بايت 128 جيجا بايت ذاكرة DDR3 2x960GB SSD بسرعة 1 جيجابت في الثانية 100 تيرابايت - من 99 دولارًا! اقرأ عن
كيفية بناء البنية التحتية فئة باستخدام خوادم V4 R730xd E5-2650d تكلف 9000 يورو عن بنس واحد؟