 يُظهر الرسم التخطيطي للكمبيوتر CS-1 أن معظمها مخصص لتشغيل وتبريد محرك رقاقة مقياس (WSE) العملاق (المعالج على اللوحة). الصورة: نظم Cerebras
يُظهر الرسم التخطيطي للكمبيوتر CS-1 أن معظمها مخصص لتشغيل وتبريد محرك رقاقة مقياس (WSE) العملاق (المعالج على اللوحة). الصورة: نظم Cerebrasفي أغسطس 2019 ، أعلنت Cerebras Systems وشريكها في التصنيع TSMC
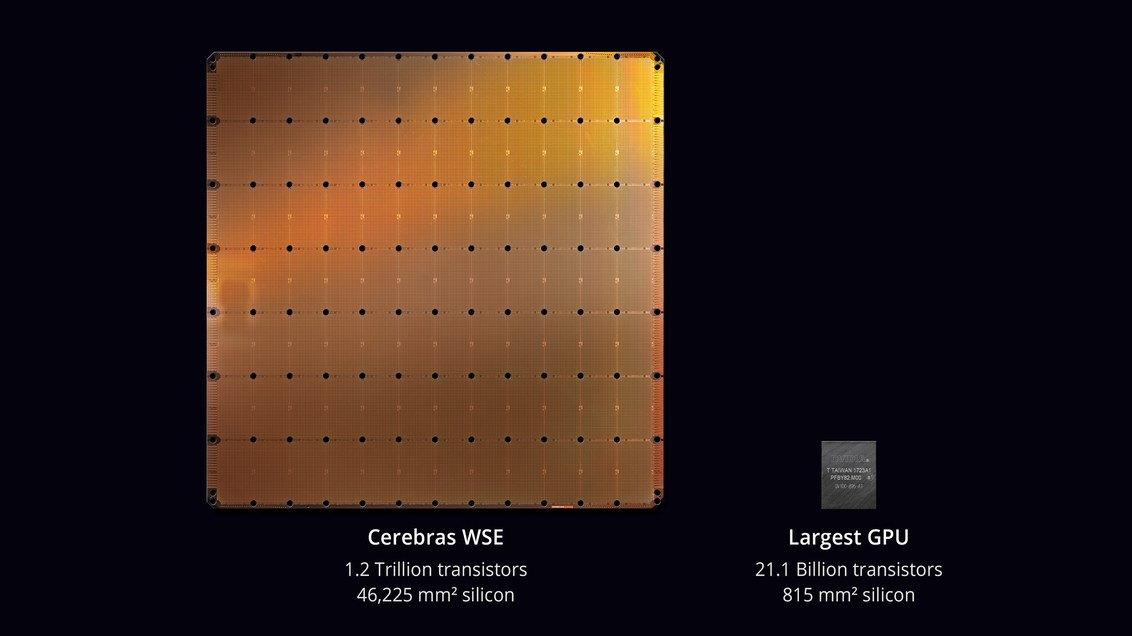
أكبر شريحة في تاريخ تكنولوجيا الكمبيوتر . تبلغ مساحتها 46،225 مم مربع و 1.2 ترليون ترنزستور ، رقاقة رقاقة مقياس (WSE) أكبر بحوالي 56.7 مرة من أكبر GPU (21.1 مليار ترنزستور ، 815 ملم مربع).
قال المشككون إن تطوير معالج ليس المهمة الأكثر صعوبة. ولكن هنا كيف ستعمل في جهاز كمبيوتر حقيقي؟ ما هي النسبة المئوية للعمل المعيب؟ ما السلطة والتبريد سوف تكون هناك حاجة؟ كم سيكلف هذا الجهاز؟
يبدو أن المهندسين في Cerebras Systems و TSMC كانوا قادرين على حل هذه المشكلات. في 18 نوفمبر 2019 ، في مؤتمر
الحوسبة الفائقة 2019 ، كشفوا رسمياً عن
CS-1 ، "أسرع جهاز كمبيوتر في العالم للحوسبة في مجال التعلم الآلي والذكاء الاصطناعي".
تم بالفعل إرسال النسخ الأولى من CS-1 إلى العملاء. تم تثبيت أحدهما في مختبر Argonne الوطني التابع لوزارة الطاقة الأمريكية ، والذي يبدأ فيه تجميع أقوى حاسوب عملاق في الولايات المتحدة الأمريكية من
وحدات Aurora على بنية Intel GPU الجديدة . عميل آخر هو مختبر ليفرمور الوطني.
تم تصميم المعالج مع 400000 النوى لمراكز البيانات لمعالجة الحوسبة في مجال التعلم الآلي والذكاء الاصطناعي. تدعي Cerebras أن الكمبيوتر يدرب أنظمة الذكاء الاصطناعي بأوامر من حجم أكثر كفاءة من المعدات الموجودة. الأداء CS-1 مكافئ لـ "المئات من الخوادم القائمة على GPU" التي تستهلك مئات الكيلووات. في الوقت نفسه ، تشغل 15 وحدة فقط في حامل الخادم وتستهلك حوالي 17 كيلو واط.
 WSE المعالج. الصورة: نظم Cerebras
WSE المعالج. الصورة: نظم Cerebrasيقول أندرو فيلدمان ، الرئيس التنفيذي والمؤسس المشارك لشركة Cerebras Systems ، إن CS-1 هو "أسرع جهاز كمبيوتر في العالم". قارنه بمجموعات TPU من Google وأشار إلى أن كل منها "يأخذ 10 رفوف ويستهلك أكثر من 100 كيلووات لتوفير ثلث أداء تثبيت CS-1 واحد."
 الكمبيوتر CS-1. الصورة: نظم Cerebras
الكمبيوتر CS-1. الصورة: نظم Cerebrasيمكن أن يستغرق تعلم الشبكات العصبية الكبيرة أسابيع على جهاز كمبيوتر قياسي. يؤدي تثبيت CS-1 مع شريحة معالج تبلغ 400000 قلب و 1.2 ترليون ترنزستور إلى تنفيذ هذه المهمة في دقائق أو حتى ثوانٍ ، كما
يكتب IEEE Spectrum. ومع ذلك ، لم تقدم Cerebras نتائج اختبار حقيقية لاختبار عبارات عالية الأداء مثل
اختبارات MLPerf . بدلاً من ذلك ، أقامت الشركة اتصالات مباشرة مع العملاء المحتملين - وسمح لها بتدريب نماذجها الخاصة بالشبكات العصبية على CS-1.
يقول المحلل
كارل فريند ، محلل الذكاء الاصطناعي في Moor Insights & Strategies: "هذا النهج ليس غريباً ، حيث يدير الجميع نماذجهم الخاصة التي طوروها من أجل أعمالهم الخاصة". "هذا هو الشيء الوحيد الذي يهم العملاء."
تقوم العديد من الشركات بتطوير رقائق متخصصة لـ AI ، بما في ذلك ممثلو الصناعة التقليدية مثل Intel و Qualcomm ، بالإضافة إلى العديد من الشركات الناشئة في الولايات المتحدة والمملكة المتحدة والصين. طورت Google شريحة خاصة بالشبكات العصبية - معالج التنسور أو TPU. يتبع العديد من الشركات المصنعة الأخرى حذوها. تعمل أنظمة الذكاء الاصطناعي في وضع متعدد الخيوط ، ويقوم عنق الزجاجة بنقل البيانات بين الرقائق: "توصيل الرقائق يبطئها بالفعل ويتطلب الكثير من الطاقة" ،
يوضح سوبرامانيان أيير ، الأستاذ بجامعة كاليفورنيا في لوس أنجلوس المتخصص في تطوير رقائق للذكاء الاصطناعي. الشركات المصنعة للمعدات تستكشف العديد من الخيارات المختلفة. يحاول البعض توسيع اتصالات interprocess.
تأسست شركة Cerebras ، التي تأسست منذ ثلاث سنوات ، والتي حصلت على أكثر من 200 مليون دولار من التمويل الاستثماري ، على مقاربة جديدة. تتمثل الفكرة في حفظ جميع البيانات الموجودة على شريحة عملاقة - وبالتالي تسريع العمليات الحسابية.

تنقسم لوحة الدائرة الدقيقة بالكامل إلى 400000 مقطع أصغر (في القلب) ، نظرًا لأن بعضها لن يعمل. تم تصميم الشريحة مع القدرة على التوجيه حول المناطق المعيبة. حبات البرمجة القابلة للبرمجة SLAC (نوى الجبر الخطي المتناثر) هي الأمثل للجبر الخطي ، أي للحسابات في الفضاء المتجه. طورت الشركة أيضًا تقنية "حصاد المتفرق" لتحسين أداء الحوسبة تحت أعباء العمل المتفرقة (التي تحتوي على أصفار) ، مثل التعلم العميق. تحتوي المتجهات والمصفوفات في مساحة المتجهات عادةً على الكثير من العناصر الصفرية (من 50٪ إلى 98٪) ، وهكذا على وحدات معالجة الرسومات التقليدية ، يتم إهدار معظم العمليات الحسابية. في المقابل ، فإن SLAC تقوم بتصفية البيانات الخالية مسبقًا.
يتم توفير الاتصالات بين النوى عن طريق نظام سرب مع سرعة إنتاجية تصل إلى 100 بت في الثانية. توجيه الأجهزة ، الكمون المقاس بالنانو ثانية.
لا يسمى تكلفة الكمبيوتر. يعتقد الخبراء المستقلون أن السعر الحقيقي يعتمد على نسبة الزواج. كما أن أداء الرقاقة وعدد النوى العاملة في عينات حقيقية غير معروف بشكل موثوق.
البرمجيات
أعلنت Cerebras عن بعض التفاصيل حول جزء البرنامج لنظام CS-1. يتيح البرنامج للمستخدمين إنشاء نماذج تعلم الآلة الخاصة بهم باستخدام أطر عمل قياسية مثل
PyTorch و
TensorFlow . يقوم النظام بعد ذلك بتوزيع 400000 نواة و 18 غيغابايت من ذاكرة SRAM على الشريحة إلى طبقات الشبكة العصبية بحيث تكمل جميع الطبقات عملهم في نفس الوقت تقريبا مع جيرانهم (مهمة التحسين). ونتيجة لذلك ، تتم معالجة المعلومات بواسطة جميع الطبقات دون تأخير. من خلال النظام الفرعي I / O لشبكة جيجابت إيثرنت I / O سعة 12 منفذًا ، والذي يتسع لـ 12 منفذًا ، يمكنه معالجة 1.2 تيرابايت من البيانات في الثانية.
يتم تحويل الشبكة العصبية المصدر إلى تمثيل قابل للتنفيذ الأمثل (Cerebras Linear Algebra Intermediate تمثيل ، CLAIR) بواسطة Cerebras Graph Compiler (CGC). يقوم المحول البرمجي بتخصيص موارد الحوسبة والذاكرة لكل جزء من الرسم البياني ، ثم يقوم بمقارنتها بمصفوفة الحوسبة. ثم ، يتم حساب مسار الاتصال وفقًا للهيكل الداخلي للوحة ، وهو فريد لكل شبكة.
 توزيع العمليات الرياضية للشبكة العصبية بواسطة نوى المعالج. الصورة : سيريبراس
توزيع العمليات الرياضية للشبكة العصبية بواسطة نوى المعالج. الصورة : سيريبراسنظرًا لحجم WSE الضخم ، توجد جميع الطبقات في الشبكة العصبية في نفس الوقت وتعمل بشكل متوازٍ. هذا النهج فريد من نوعه بالنسبة لـ WSE - لا يوجد أي جهاز آخر لديه ذاكرة داخلية كافية لتناسب جميع الطبقات على شريحة واحدة في وقت واحد ، كما يقول Cerebras. مثل هذه البنية مع وضع الشبكة العصبية بأكملها على شريحة توفر مزايا كبيرة بسبب الإنتاجية العالية والكمون المنخفض.
يمكن للبرنامج تنفيذ مهمة التحسين لأجهزة كمبيوتر متعددة ، مما يسمح لمجموعة أجهزة الكمبيوتر بالعمل كجهاز واحد كبير. تظهر مجموعة من 32 جهاز كمبيوتر CS-1 زيادة في الأداء تقارب 32 ضعفًا ، مما يدل على قابلية جيدة جدًا للتطوير. يقول فيلدمان إن هذا يختلف عن المجموعات القائمة على GPU: "اليوم ، عندما تشكل مجموعة من وحدات معالجة الرسومات ، لا يتصرف مثل جهاز كبير. تحصل على الكثير من السيارات الصغيرة. "
وذكر
البيان الصحفي أن مختبر أرجون الوطني يعمل مع Cerebras منذ عامين: "من خلال نشر CS-1 ، قمنا بزيادة سرعة تدريب الشبكات العصبية بشكل كبير ، مما سمح لنا بزيادة إنتاجية أبحاثنا وتحقيق نجاح كبير."
سيكون أحد أول تحميلات لـ CS-1 هو
محاكاة شبكة عصبية لتصادم الثقوب السوداء والأمواج التثاقلية ، التي يتم إنشاؤها نتيجة لهذا التصادم. عملت الإصدار السابق من هذه المهمة على 1024 من 4392 عقدًا من الكمبيوتر العملاق
Theta .