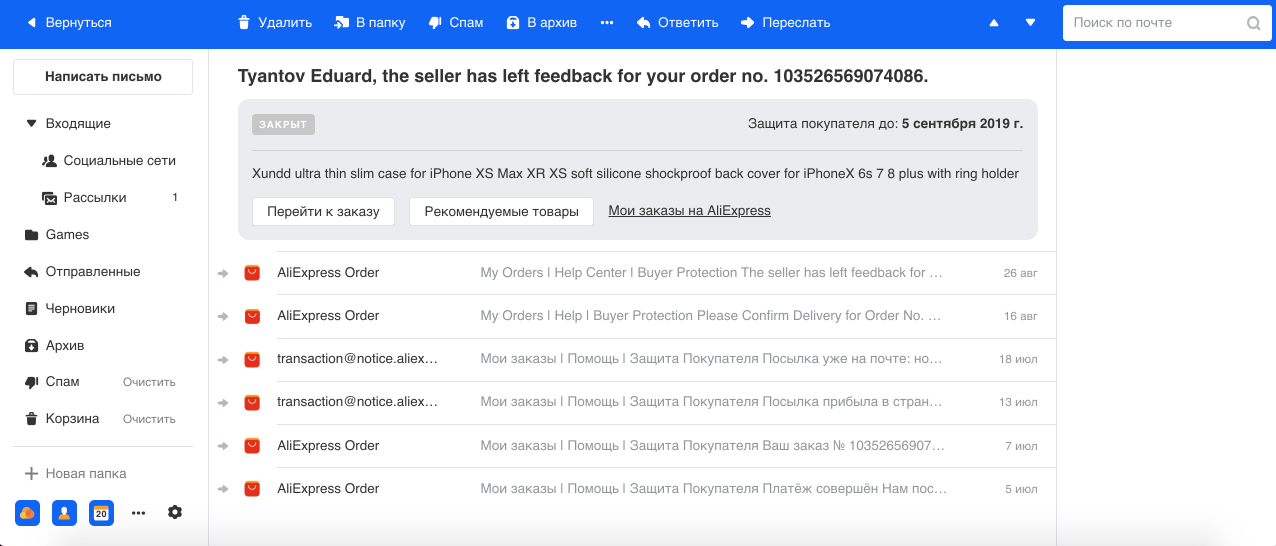
 بناءً على أدائي في Highload ++ و DataFest Minsk 2019
بناءً على أدائي في Highload ++ و DataFest Minsk 2019بالنسبة للكثيرين ، يعد البريد اليوم جزءًا لا يتجزأ من الحياة على الإنترنت. من خلال مساعدتها ، نجري المراسلات التجارية ، ونخزن جميع أنواع المعلومات المهمة المتعلقة بالتمويلات ، وحجوزات الفنادق ، والمغادرة ، وأكثر من ذلك بكثير. في منتصف عام 2018 ، قمنا بصياغة استراتيجية لتطوير منتجات البريد. ما ينبغي أن يكون البريد الحديث؟
يجب أن يكون البريد
ذكيًا ، أي أن يساعد المستخدمين على التنقل في كمية المعلومات المتزايدة: التصفية والبنية وتوفيرها بالطريقة الأكثر ملاءمة. يجب أن يكون
مفيدًا ، والسماح مباشرة في صندوق البريد بحل المشكلات المختلفة ، على سبيل المثال ، دفع الغرامات (وهي وظيفة استخدمها ، لسوء الحظ ،). وفي الوقت نفسه ، بطبيعة الحال ، ينبغي أن يوفر البريد حماية المعلومات عن طريق قطع البريد المزعج والحماية من الاختراقات ، أي أن تكون
آمنة .
تحدد هذه المناطق عددًا من المهام الأساسية ، والتي يمكن حل الكثير منها بفعالية باستخدام التعلم الآلي. فيما يلي أمثلة على الميزات الموجودة التي تم تطويرها كجزء من الاستراتيجية - واحدة لكل اتجاه.
- الرد الذكي . هناك وظيفة الإجابة الذكية في البريد. تقوم الشبكة العصبية بتحليل نص الرسالة ، وتفهم معناه وغرضه ، ونتيجة لذلك تقدم خيارات الإجابة الثلاثة الأكثر ملاءمة: إيجابية ، سلبية ، ومحايدة. هذا يساعد على توفير الوقت بشكل كبير عند الرد على الرسائل ، وكذلك في كثير من الأحيان الاستجابة غير القياسية ومتعة لنفسك.
- تجميع الرسائل المتعلقة بالطلبات في المتاجر عبر الإنترنت. غالبًا ما نجري عمليات شراء على الإنترنت ، وكقاعدة عامة ، يمكن للمتاجر إرسال عدة رسائل لكل طلب. على سبيل المثال ، من AliExpress ، أكبر خدمة ، هناك الكثير من الحروف لأمر واحد ، وقد وجدنا أن عددهم في الحالة النهائية يمكن أن يصل إلى 29. لذلك ، باستخدام نموذج التعرف على الكيانات المسماة ، نختار رقم الطلب والمعلومات الأخرى من النص والمجموعة جميع الرسائل في موضوع واحد. نعرض أيضًا المعلومات الأساسية المتعلقة بالترتيب في مربع منفصل ، مما يسهل العمل باستخدام هذا النوع من الحروف.
- الجشع . يعد الخداع نوعًا من رسائل البريد الإلكتروني الاحتيالية الخطيرة بشكل خاص بمساعدة المهاجمين الذين يحاولون الحصول على معلومات مالية (بما في ذلك بطاقات بنك المستخدم) وتسجيلات الدخول. مثل هذه الرسائل تحاكي تلك الحقيقية التي ترسلها الخدمة ، بما في ذلك بصريا. لذلك ، بمساعدة Computer Vision ، ندرك شعارات وأسلوب خطابات الشركات الكبيرة (على سبيل المثال ، Mail.ru و Sberbank و Alpha) ونأخذ ذلك في الاعتبار ، إلى جانب النص وعلامات أخرى في مصنّفي البريد العشوائي والتصيّد.
تعلم الآلة
قليلا عن التعلم الآلي في البريد بشكل عام. Mail نظام محمّل بدرجة عالية: على خوادمنا ، يصل متوسط عدد الرسائل التي تصل إلى 1.5 مليار رسالة يوميًا إلى 30 مليون مستخدم DAU. خدمة جميع الوظائف والميزات اللازمة لنحو 30 نظامًا للتعلم الآلي.
كل حرف يمر عبر ناقل التصنيف بأكمله. أولاً ، نقطع الرسائل غير المرغوب فيها ونترك رسائل بريد إلكتروني جيدة. غالبًا ما لا يلاحظ المستخدمون عملية مكافحة البريد العشوائي ، لأن 95-99٪ من البريد العشوائي لا يدخلون حتى المجلد المقابل. يعد التعرف على الرسائل غير المرغوب فيها جزءًا مهمًا للغاية من نظامنا ، والأكثر صعوبة ، لأنه في مجال مكافحة البريد العشوائي هناك تكيف مستمر بين أنظمة الدفاع والهجوم ، مما يوفر تحديًا هندسيًا مستمرًا لفريقنا.
بعد ذلك ، نفصل الرسائل عن الأشخاص والروبوتات. الرسائل من الناس هي الأكثر أهمية ، لذلك نقدم لهم وظائف مثل Smart Reply. تنقسم رسائل الروبوتات إلى قسمين: المعاملات - هذه هي خطابات مهمة من الخدمات ، على سبيل المثال ، تأكيد المشتريات أو حجوزات الفنادق ، الشؤون المالية ، والمعلومات - هذه إعلانات تجارية ، خصومات.
نعتقد أن خطابات المعاملات متساوية في القيمة مع المراسلات الشخصية. يجب أن تكون في متناول اليد ، لأنه غالبًا ما يكون من الضروري العثور بسرعة على معلومات حول الطلب أو حجز تذكرة ، ونحن نقضي وقتًا في البحث عن هذه الرسائل. لذلك ، للراحة ، نقوم تلقائيًا بتقسيمها إلى ست فئات رئيسية: السفر ، والحجوزات ، والمالية ، وتذاكر السفر ، والتسجيلات ، وأخيرًا الغرامات.
النشرات الإخبارية هي أكبر مجموعة ، وربما أقل أهمية ، لا تتطلب رد فعل فوري ، حيث لن يتغير شيء مهم في حياة المستخدم إذا لم يقرأ مثل هذه الرسالة. في الواجهة الجديدة الخاصة بنا ، نقوم بتقسيمها إلى موضوعين: الشبكات الاجتماعية والنشرات الإخبارية ، وبالتالي يتم مسح صندوق البريد بشكل مرئي وترك الرسائل المهمة فقط في الأفق.

استغلال
يتسبب عدد كبير من الأنظمة في صعوبات كثيرة في التشغيل. بعد كل شيء ، تتحلل النماذج بمرور الوقت ، مثل أي برنامج: تعطل العلامات ، تعطل الأجهزة ، تدور الشفرة. بالإضافة إلى ذلك ، تتغير البيانات باستمرار: تتم إضافة بيانات جديدة ، ويتم تحويل نمط سلوك المستخدم ، وما إلى ذلك ، وبالتالي ، فإن النموذج الذي لا يحتوي على دعم مناسب سيعمل بشكل أسوأ وأسوأ مع مرور الوقت.
يجب ألا ننسى أن التعلم الآلي الأعمق يخترق حياة المستخدمين ، وكلما زاد تأثيرهم على النظام الإيكولوجي ، ونتيجة لذلك ، زادت الخسائر أو الأرباح المالية التي يمكن أن يحققها اللاعبون في السوق. لذلك ، في عدد متزايد من المجالات ، يتكيف اللاعبون مع عمل خوارزميات ML (الأمثلة الكلاسيكية هي الإعلان والبحث ومكافحة البريد العشوائي الذي سبق ذكره).
تتميز أيضًا مهام التعلم الآلي بميزة: أي تغيير - على الرغم من أنه غير مهم - يمكن أن يؤدي إلى الكثير من العمل في النموذج: العمل باستخدام البيانات ، وإعادة التدريب ، والنشر ، والذي يمكن أن يستمر لأسابيع أو أشهر. لذلك ، كلما كانت البيئة التي تعمل فيها النماذج أسرع ، كلما تطلب الأمر دعمًا أكبر. يمكن للفريق إنشاء العديد من الأنظمة والاستمتاع بها ، ثم إنفاق جميع الموارد تقريبًا على دعمهم ، دون القدرة على القيام بشيء جديد. واجهنا مرة واحدة مثل هذا الموقف مرة واحدة في فريق مكافحة البريد المزعج. وقد توصلوا إلى استنتاج واضح بأن الصيانة يجب أن تكون آلية.
أتمتة
ما يمكن أن يكون آليا؟ في الواقع ، كل شيء تقريبا. لقد حددت أربعة مجالات تحدد البنية الأساسية للتعلم الآلي:
- جمع البيانات
- التعليم المستمر.
- نشر.
- اختبار ومراقبة.
إذا كانت البيئة غير مستقرة ومتغيرة باستمرار ، فإن البنية التحتية بأكملها حول النموذج أكثر أهمية بكثير من النموذج نفسه. قد يكون المصنف الخطي القديم الجيد ، ولكن إذا قمت بتطبيق العلامات بشكل صحيح وقمت بتكوين ملاحظات جيدة من المستخدمين ، فستعمل بشكل أفضل من طرازات أحدث طراز مع كل الأجراس وصفارات.
حلقة ردود الفعل
تجمع هذه الدورة بين جمع البيانات والتدريب الإضافي والنشر - في الواقع ، الدورة الكاملة لتحديث النموذج. لماذا هذا مهم؟ انظر إلى جدول التسجيل في البريد:

قام مطور التعلم الآلي بتقديم نموذج antibot يمنع برامج الروبوت من التسجيل في البريد. يسقط الرسم البياني إلى قيمة حيث يبقى المستخدمون الحقيقيون فقط. كل شيء رائع! لكن بعد مرور أربع ساعات ، شدّ botvods نصوصهم ، وكل شيء يعود إلى المربع رقم واحد. في هذا التطبيق ، قضى المطور شهرًا في إضافة الميزات ونموذج التدريب ، ولكن تمكن مرسلي البريد العشوائي من التكيف في غضون أربع ساعات.
حتى لا نكون مؤلمين للغاية ولا يتعين علينا إعادة كل شيء لاحقًا ، يجب أن نفكر في البداية في كيفية ظهور حلقة التعليقات وماذا سنفعل إذا تغيرت البيئة. لنبدأ من خلال جمع البيانات - وهذا هو الوقود لخوارزمياتنا.
جمع البيانات
من الواضح أن الشبكات العصبية الحديثة ، والمزيد من البيانات ، كان ذلك أفضل ، وأنها ، في الواقع ، تولد مستخدمي المنتج. يمكن للمستخدمين مساعدتنا بترميز البيانات ، لكن لا يمكنك إساءة استخدامها ، لأن المستخدمين سئموا في مرحلة ما من إكمال النماذج وسيحولون إلى منتج آخر.
أحد الأخطاء الأكثر شيوعًا (أشير هنا إلى أندرو نغ) هو أن التوجه نحو المقاييس الموجودة في مجموعة بيانات الاختبار قوي للغاية ، وليس لردود الفعل من المستخدم ، وهو في الواقع المقياس الرئيسي لجودة العمل ، حيث نقوم بإنشاء منتج للمستخدم. إذا كان المستخدم لا يفهم أو يكره عمل النموذج ، فعندئذ يكون كل شيء قابلاً للتلف.
لذلك ، يجب أن يكون المستخدم قادرًا دائمًا على التصويت ، ويجب أن يعطيه أداة للتعليقات. إذا اعتقدنا أن هناك خطابًا يتعلق بالتمويل قد وصل إلى الصندوق ، فنحن بحاجة إلى وضع علامة عليه "تمويل" ورسم زر يمكن للمستخدم النقر فوقه والقول إن هذا ليس تمويلًا.
جودة ردود الفعل
دعنا نتحدث عن جودة تعليقات المستخدمين. أولاً ، يمكنك أنت والمستخدم وضع معاني مختلفة في مفهوم واحد. على سبيل المثال ، تعتقد أنت ومديرو المنتجات أن "التمويل" هو خطابات من البنك ، ويعتقد المستخدم أن خطاب جدتي حول التقاعد يشير أيضًا إلى الموارد المالية. ثانياً ، هناك مستخدمون يحبون الضغط على الأزرار بدون تفكير. ثالثًا ، قد يكون المستخدم مخطئًا في استنتاجاته. مثال حي على ممارستنا هو تقديم مصنف
الرسائل غير المرغوب فيها النيجيرية ، وهو نوع مضحك للغاية من الرسائل غير المرغوب فيها ، عندما يُطلب من المستخدم جمع عدة ملايين من الدولارات من قريب قريب وجد فجأة في إفريقيا. بعد تقديم هذا المصنف ، قمنا بفحص نقرات "عدم البريد العشوائي" على هذه الحروف ، واتضح أن 80٪ منهم عبارة عن رسائل غير مرغوب فيها من نيجيريا ، مما يوحي بأن المستخدمين يمكن أن يثقوا للغاية.
ودعونا لا ننسى أنه لا يمكن للناس فقط الضغط على الأزرار ، ولكن كل أنواع برامج الروبوت التي تتظاهر بأنها متصفح. حتى ردود الفعل الخام ليست جيدة للتعلم. ما الذي يمكن عمله بهذه المعلومات؟
نستخدم طريقتين:
- ردود الفعل من ML ذات الصلة . على سبيل المثال ، لدينا نظام مضاد على الإنترنت ، والذي ، كما ذكرت ، يتخذ قرارًا سريعًا استنادًا إلى عدد محدود من العلامات. وهناك نظام بطيء ثانٍ يعمل بشكل مسبق. لديها المزيد من البيانات حول المستخدم ، وعن سلوكه ، إلخ. نتيجة لذلك ، يتم اتخاذ القرار الأكثر توازناً ، على التوالي ، فإنه يتميز بدقة ودقة أعلى. يمكنك توجيه الفرق في عمل هذه الأنظمة في الأول كبيانات للتدريب. وبالتالي ، سيحاول نظام أبسط دائمًا الاقتراب من أداء أكثر تعقيدًا.
- تصنيف النقرات . يمكنك ببساطة تصنيف كل نقرة للمستخدم ، وتقييم صلاحيتها والقدرة على استخدامها. نقوم بذلك في البريد المضاد للبريد العشوائي باستخدام سمات المستخدم وتاريخه وسمات المرسل والنص نفسه ونتائج المصنفات. نتيجة لذلك ، نحصل على نظام تلقائي يتحقق من آراء المستخدمين. ولأنه من الضروري تدريبه بشكل أقل تواترا ، يمكن أن يصبح عمله هو العمل الرئيسي لجميع الأنظمة الأخرى. الدقة هي الأولوية الرئيسية في هذا النموذج ، لأن تدريب نموذج على بيانات غير دقيقة محفوف بالعواقب.
بينما نقوم بتنظيف البيانات وإعادة تدريب أنظمة ML الخاصة بنا ، يجب ألا ننسى المستخدمين ، لأن الآلاف من الملايين من الأخطاء في الرسم البياني تمثل إحصائيات بالنسبة للمستخدم ، وكل خطأ يمثل مأساة. بالإضافة إلى حقيقة أن المستخدم يحتاج إلى العيش بطريقة أو بأخرى مع خطأك في المنتج ، فإنه بعد ردود الفعل يتوقع استبعاد موقف مماثل في المستقبل. لذلك ، يجب دائمًا منح المستخدمين ليس فقط فرصة التصويت ، ولكن أيضًا تصحيح سلوك أنظمة ML ، وإنشاء ، على سبيل المثال ، الاستدلال الشخصي لكل نقرة من ردود الفعل ، في حالة البريد ، قد يكون من الممكن تصفية هذه الرسائل عن طريق المرسل ورأس هذا المستخدم.
تحتاج أيضًا إلى تحطيم الطراز على أساس بعض التقارير أو مكالمات الدعم في الوضع شبه التلقائي أو اليدوي ، حتى لا يعاني المستخدمون الآخرون من مشكلات مماثلة أيضًا.
الأساليب البحثية للتعلم
هناك مشكلتان مع هذه الاستدلال والعكازات. الأول ، هو صعوبة الحفاظ على العدد المتزايد من العكازات ، ناهيك عن جودتها وأدائها لمسافات طويلة. المشكلة الثانية هي أن الخطأ قد لا يكون التردد ، ولن يكفي عدد قليل من النقرات لإعادة تدريب النموذج. يبدو أن هذين التأثيرين غير المرتبطين يمكن تعادلهما بشكل كبير إذا تم تطبيق النهج التالي.
- إنشاء عكاز مؤقت.
- نقوم بتوجيه البيانات منه إلى النموذج ؛ يتم استرجاعها بانتظام ، بما في ذلك البيانات الواردة. هنا ، بالطبع ، من المهم أن يكون للكشف عن مجريات الأمور دقة عالية حتى لا يقلل من جودة البيانات في مجموعة التدريب.
- ثم نقوم بتعليق المراقبة لتشغيل العكاز ، وإذا لم يعد العكاز يعمل بعد فترة من الزمن وكان مغطى بالكامل بالنموذج ، يمكنك إزالته بأمان. الآن هذه المشكلة من غير المرجح أن تتكرر.
لذلك جيش العكازات مفيد جدا. الشيء الرئيسي هو أن خدمتهم عاجلة وليست دائمة.
التعليم الإضافي
إعادة التدريب هي عملية إضافة بيانات جديدة تم الحصول عليها نتيجة لتعليقات المستخدمين أو الأنظمة الأخرى ، وتدريب النموذج الحالي عليها. يمكن أن يكون هناك عدة مشاكل في إعادة التدريب:
- قد لا يدعم النموذج ببساطة التعليم الإضافي ، ويتعلم فقط من نقطة الصفر.
- في أي مكان في كتاب الطبيعة هو مكتوب أن التعليم المستمر سيحسن بالتأكيد نوعية العمل في الإنتاج. في كثير من الأحيان يحدث العكس تماما ، وهذا هو التدهور الوحيد هو ممكن.
- التغييرات يمكن أن تكون غير متوقعة. هذه نقطة خفية إلى حد ما حددناها لأنفسنا. حتى إذا أظهر النموذج الجديد في اختبار A / B نتائج مماثلة مقارنة بالنتائج الحالية ، فإن هذا لا يعني على الإطلاق أنه سيعمل بنفس الطريقة. قد يختلف عملهم بنسبة واحد بالمائة ، مما قد يؤدي إلى حدوث أخطاء جديدة أو إرجاع أخطاء قديمة تم تصحيحها بالفعل. كلانا والمستخدمين يعرفون بالفعل كيف نتعايش مع الأخطاء الحالية ، وعندما يحدث عدد كبير من الأخطاء الجديدة ، قد لا يفهم المستخدم أيضًا ما يحدث ، لأنه يتوقع سلوكًا متوقعًا.
لذلك ، فإن أهم شيء في إعادة التدريب مضمون لتحسين النموذج ، أو على الأقل عدم تفاقمه.
أول ما يتبادر إلى الذهن عندما نتحدث عن التعليم المستمر هو نهج التعلم النشط. ماذا يعني هذا؟ على سبيل المثال ، يحدد المصنف ما إذا كانت الرسالة تتعلق بالتمويل ، وحول حدود صنع القرار ، نضيف مجموعة مختارة من الأمثلة المحددة. يعمل هذا بشكل جيد ، على سبيل المثال ، في الإعلانات ، حيث يوجد الكثير من الملاحظات ويمكنك تدريب النموذج عبر الإنترنت. وإذا كان هناك القليل من التغذية المرتدة ، فسنحصل على عينة منحازة بشدة فيما يتعلق بإنتاج توزيع البيانات ، والتي على أساسها يستحيل تقييم سلوك النموذج أثناء التشغيل.
في الواقع ، هدفنا هو الحفاظ على الأنماط القديمة ، والنماذج المعروفة بالفعل ، والحصول على نماذج جديدة. هنا ، الاستمرارية مهمة. النموذج ، الذي غالبًا ما طرحناه بصعوبة كبيرة ، يعمل بالفعل ، حتى نتمكن من التركيز على أدائه.
في البريد ، يتم استخدام نماذج مختلفة: الأشجار والشبكات الخطية والعصبية. لكل منها ، نقوم بإعداد خوارزمية إعادة التدريب الخاصة بنا. في عملية إعادة التدريب ، لا نحصل فقط على بيانات جديدة ، ولكن في كثير من الأحيان ميزات جديدة سنأخذها في الاعتبار في جميع الخوارزميات أدناه.
النماذج الخطية
دعنا نقول لدينا الانحدار اللوجستي. نعوض نموذج الخسارة من المكونات التالية:
- LogLoss على البيانات الجديدة.
- نقوم بتنظيم أوزان العلامات الجديدة (لا نلمس العلامات القديمة) ؛
- نتعلم من البيانات القديمة من أجل الحفاظ على الأنماط القديمة ؛
- وربما الأهم: نحن نعلق "التوافقي" ، والذي يضمن تغييرًا طفيفًا في الأوزان بالنسبة للنموذج القديم وفقًا للقاعدة.
نظرًا لأن كل مكون من مكونات الخسارة له معاملات ، يمكننا اختيار القيم المثلى لمهمتنا للتحقق من الصحة أو بناءً على متطلبات المنتج.

الأشجار
دعنا ننتقل إلى الأشجار القرار. قمنا بتصوير خوارزمية إعادة تدريب الشجرة التالية:
- غابة من 100-300 شجرة تعمل على همز ، والتي تم تدريبها على مجموعة البيانات القديمة.
- في النهاية ، نقوم بحذف M = 5 قطع ونضيف 2M = 10 أجزاء جديدة ، مدربة على مجموعة البيانات بأكملها ، ولكن مع زيادة الوزن من البيانات الجديدة ، والتي تضمن بشكل طبيعي تغييرًا إضافيًا في النموذج.
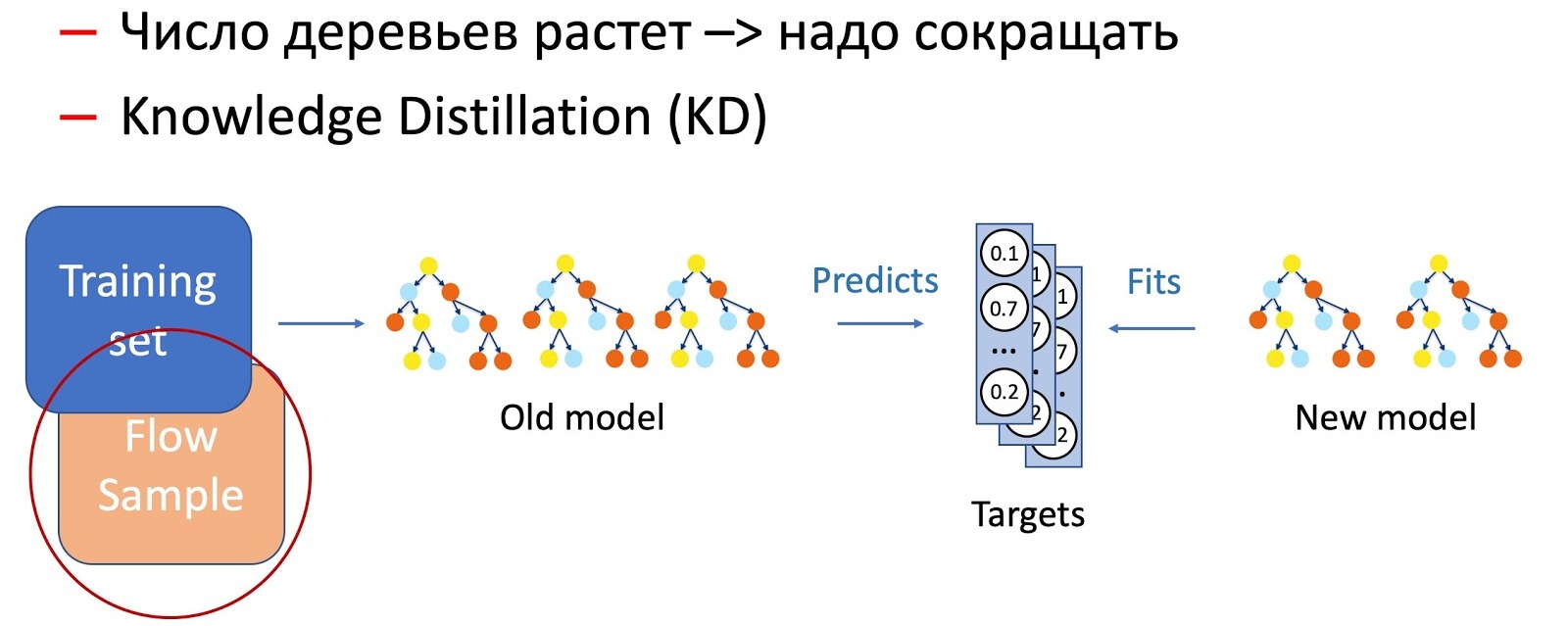
من الواضح ، بمرور الوقت ، يزداد عدد الأشجار بشكل كبير ، ويجب تقليلها بشكل دوري لتتوافق مع التوقيت. للقيام بذلك ، نستخدم الآن تقطير المعرفة في كل مكان (KD). باختصار عن مبدأ عملها.
- لدينا النموذج الحالي "المعقد". نبدأ تشغيله في مجموعة بيانات التدريب ونحصل على توزيع الاحتمالات للفصول في المخرجات.
- بعد ذلك ، نقوم بتدريس نموذج الطالب (نموذج يحتوي على عدد أقل من الأشجار في هذه الحالة) لتكرار نتائج النموذج ، باستخدام توزيع الفصول كمتغير مستهدف.
- من المهم أن نلاحظ هنا أننا لا نستخدم علامات مجموعة البيانات بأي طريقة ، وبالتالي يمكننا استخدام البيانات التعسفية. بالطبع ، نحن نستخدم عينة من البيانات من المقاتل القتالي كعينة تدريب لنموذج الطالب. وبالتالي ، فإن مجموعة التدريب تسمح لنا بضمان دقة النموذج ، وتضمن عينة من التدفق أداءً مماثلاً في توزيع الإنتاج ، مما يعوض عن تعويض عينة التدريب.
إن الجمع بين هاتين الطريقتين (إضافة الأشجار وتقليل عددها بشكل دوري باستخدام تقطير المعرفة) يضمن إدخال أنماط جديدة واستمرارية كاملة.
بمساعدة KD ، نؤدي أيضًا التمييز بين العمليات بخصائص النموذج ، على سبيل المثال ، إزالة الخصائص والعمل على التمريرات. في حالتنا ، لدينا عدد من الميزات الإحصائية المهمة (بواسطة المرسلين ، وتجزئة النص ، وعناوين URL ، وما إلى ذلك) التي يتم تخزينها في قاعدة بيانات تحتوي على الخاصية التي يجب رفضها. النموذج ، بالطبع ، ليس جاهزًا لمثل هذا التطور للأحداث ، حيث لا توجد حالات فشل في مجموعة التدريب. في مثل هذه الحالات ، نجمع بين تقنيات KD وزيادة الحجم: عند التدريب على جزء من البيانات ، نقوم بحذف العلامات الضرورية (أو إخراجها من الصفر) ، ونأخذ العلامات (مخرجات النموذج الحالي) كتلك الأولية ، حيث يعلمنا نموذج الطالب أن نكرر هذا التوزيع.
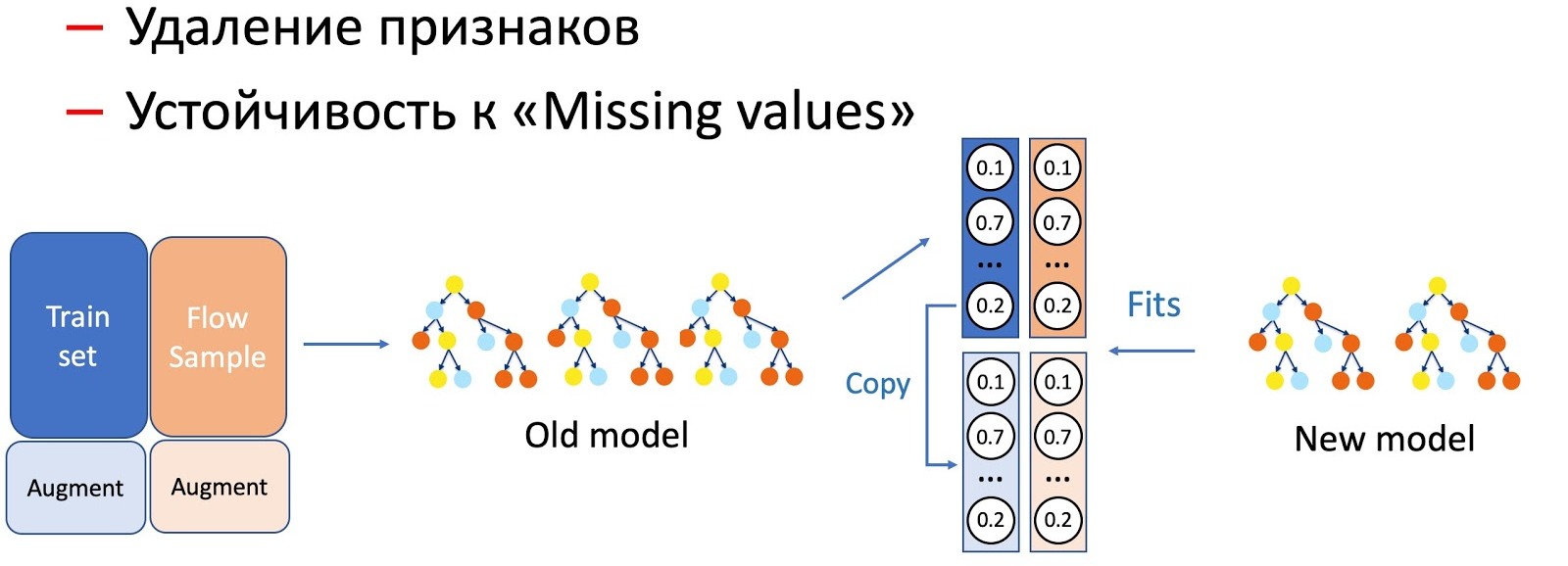
لاحظنا أن حدوث تلاعب أكثر خطورة في النماذج ، كلما زادت نسبة تدفق العينة المطلوبة.
لإزالة الميزات ، أبسط عملية ، لا يلزم سوى جزء صغير من التدفق ، حيث يتغير فقط بعض الميزات ، والنموذج الحالي الذي تمت دراسته على نفس المجموعة - يكون الفرق ضئيلًا. لتبسيط النموذج (تقليل عدد الأشجار عدة مرات) ، يلزم بالفعل 50 إلى 50. ويتطلب حذف الميزات الإحصائية المهمة التي تؤثر بشكل خطير على أداء النموذج تدفقًا أكبر حتى لعمل النموذج الجديد ، الذي يقاوم الإغفال ، على جميع أنواع الحروف.
FastText
دعنا ننتقل إلى FastText. واسمحوا لي أن أذكركم بأن تمثيل (تضمين) كلمة ما يتكون من مجموع تضمين الكلمة نفسها وكل حرفها N-grams ، عادةً ما تكون ثلاثية. نظرًا لأن الأشكال الثلاثة يمكن أن تكون كبيرة جدًا ، يتم استخدام Bucket Hashing ، أي تحويل المساحة بأكملها إلى علامة تجزئة ثابتة معينة. نتيجة لذلك ، يتم الحصول على مصفوفة الوزن من خلال بُعد الطبقة الداخلية بعدد الكلمات + المجموعة.
أثناء التعليم الإضافي ، تظهر علامات جديدة: الكلمات والبرامج ثلاثية الأبعاد. في ما بعد التدريب القياسي من Facebook ، لا يحدث شيء كبير. يتم إعادة تدريب فقط الأوزان القديمة مع إنتروبيا على البيانات الجديدة. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
نشر
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
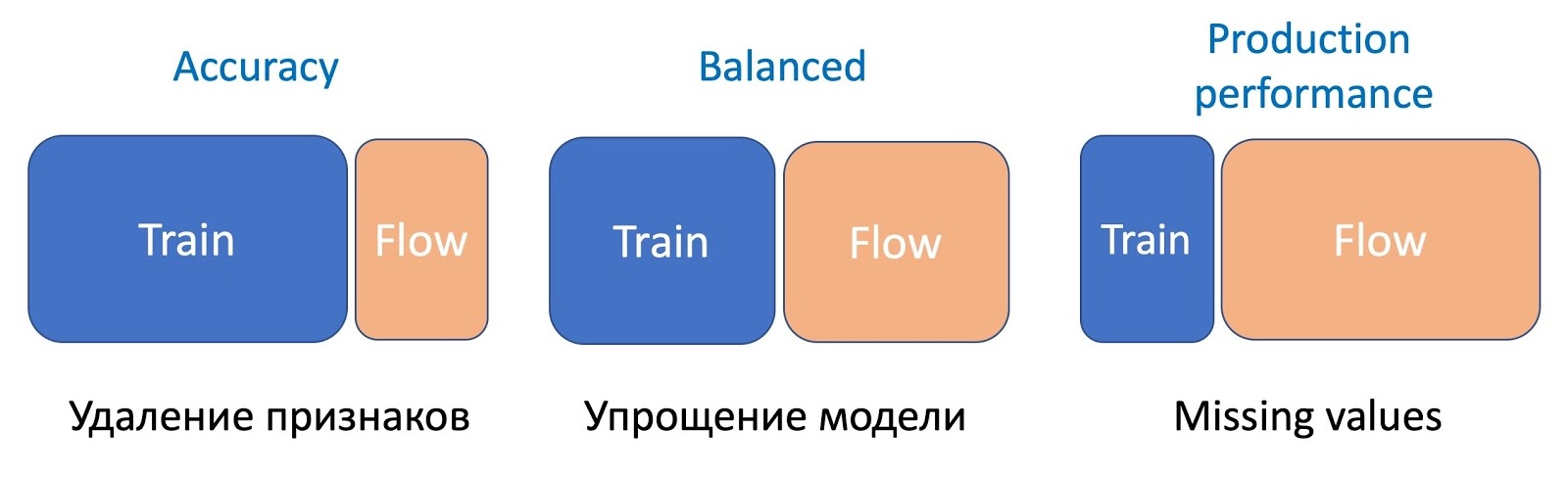
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
النتائج
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- نشر . المقاييس التلقائية تقلل إلى حد كبير الوقت الذي يستغرقه تنفيذ النماذج. مراقبة الإحصاءات وتوزيع عملية صنع القرار ، فإن عدد حالات السقوط من المستخدمين إلزامي لنومك الجيد وأيام الراحة.
حسنًا ، آمل أن يساعدك ما تقرأه على تحسين أنظمة ML لديك بشكل أسرع ، وتسريع إطلاقها في الأسواق وجعلها أكثر موثوقية ، مما يقلل من مقدار الضغط الناتج عن العمل.