أريد أن أشاطركم أول تجربة ناجحة لي في استعادة الوظائف الكاملة لقاعدة بيانات بوستجرس. قابلت Postgres DBMS منذ نصف عام ، قبل ذلك لم يكن لدي أي خبرة في إدارة قواعد البيانات على الإطلاق.

أعمل كمهندس شبه مطور في شركة تكنولوجيا معلومات كبيرة. تقوم شركتنا بتطوير برامج للخدمات المحملة للغاية ، لكنني مسؤول عن الأداء والصيانة والنشر. قاموا بتعيين مهمة معيارية: تحديث التطبيق على خادم واحد. تتم كتابة التطبيق في جانغو ، أثناء الترقية ، يتم تنفيذ عمليات الترحيل (تغيير بنية قاعدة البيانات) ، وقبل هذه العملية ، نقوم بإزالة تفريغ قاعدة البيانات الكاملة من خلال برنامج pg_dump القياسي فقط في حالة.
حدث خطأ غير متوقع أثناء إزالة التفريغ (إصدار Postgres هو 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
الخطأ
"صفحة غير صالحة في كتلة" يشير إلى مشاكل على مستوى نظام الملفات ، وهو أمر سيء للغاية. في المنتديات المختلفة ، اقترحوا جعل
FULL VACUUM مع خيار
zero_damaged_pages لحل هذه المشكلة. حسنا ، popprobeum ...
إعداد الانتعاش
تحذير! تأكد من نسخ Postgres قبل أي محاولة لاستعادة قاعدة البيانات. إذا كان لديك جهاز افتراضي ، فأوقف تشغيل قاعدة البيانات والتقط لقطة سريعة. إذا لم يكن من الممكن التقاط لقطة ، فأوقف قاعدة البيانات وانسخ محتويات دليل Postgres (بما في ذلك ملفات wal) إلى مكان آمن. الشيء الرئيسي في أعمالنا هو عدم جعل الأمور أسوأ. اقرأ
هذانظرًا لأن قاعدة البيانات عملت بالنسبة لي ككل ، فقد قصرت نفسي على تفريغ قاعدة البيانات المعتادة ، لكنني استبعدت الجدول مع البيانات التالفة (الخيار
-T ، - excclude-table = TABLE في pg_dump).
كان الخادم فعليًا ، كان من المستحيل التقاط لقطة. تتم إزالة النسخ الاحتياطي ، والمضي قدما.
فحص نظام الملفات
قبل محاولة استعادة قاعدة البيانات ، تحتاج إلى التأكد من أن كل شيء متوافق مع نظام الملفات نفسه. وفي حالة وجود أخطاء ، قم بتصحيحها ، لأنه بخلاف ذلك يمكنك فقط أن تزيد الأمر سوءًا.
في حالتي ، تم تثبيت نظام الملفات مع قاعدة البيانات في
"/ srv" وكان النوع ext4.
نوقف قاعدة البيانات:
systemctl stop postgresql@9.5-main.service ونتأكد من أن نظام الملفات لا يستخدمه أي شخص وأنه يمكن إلغاء
تركيبه باستخدام
الأمر lsof :
lsof + D / srvلا يزال يتعين علي إيقاف قاعدة بيانات redis ، لأنها تستخدم أيضًا
"/ srv" . بعد ذلك ، قمت بإلغاء
التثبيت / srv (umount).
تم إجراء التحقق من نظام الملفات باستخدام الأداة المساعدة
e2fsck مع الخيار -f (
فرض التحقق حتى إذا تم تمييز نظام الملفات ):
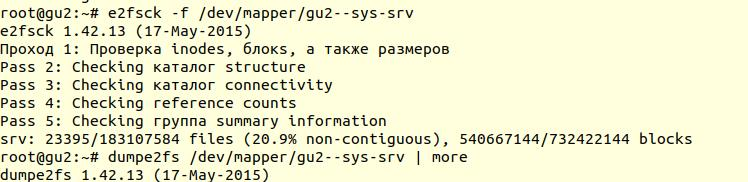
بعد ذلك ، باستخدام الأداة المساعدة
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - فحص sys-srv | grep ) ، يمكنك التحقق من أنه قد تم إجراء التحقق بالفعل:

يقول
e2fsck أنه لم يتم العثور على أي مشاكل على مستوى نظام الملفات ext4 ، مما يعني أنه يمكنك الاستمرار في محاولة استعادة قاعدة البيانات ، أو العودة إلى
الفراغ بالكامل (بالطبع ، تحتاج إلى إعادة تشغيل نظام الملفات وبدء قاعدة البيانات).
إذا كان الخادم لديك فعليًا ، فتأكد من التحقق من حالة الأقراص (عبر
smartctl -a / dev / XXX ) أو وحدة تحكم RAID للتأكد من أن المشكلة ليست على مستوى الجهاز. في حالتي ، تحولت RAID إلى "حديد" ، لذلك طلبت من المسؤول المحلي التحقق من حالة RAID (كان الخادم على بعد مئات الكيلومترات مني). قال إنه لا توجد أخطاء ، مما يعني أنه يمكننا بالتأكيد البدء في عملية الترميم.
محاولة 1: zero_damaged_pages
نحن نتصل بقاعدة البيانات من خلال حساب psql مع حقوق المستخدم الخارق. نحتاج بالضبط الخارق ، ل فقط يمكنه تغيير خيار
zero_damaged_pages . في حالتي ، هذا هو postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]يلزم استخدام خيار
zero_damaged_pages لتجاهل أخطاء القراءة (من موقع postgrespro):
عند اكتشاف عنوان صفحة تالف ، عادةً ما يقوم Postgres Pro بالإبلاغ عن خطأ وإحباط المعاملة الحالية. إذا تم تمكين المعلمة zero_damaged_pages ، فبدلاً من ذلك ، يصدر النظام تحذيراً ، ويمسح الصفحة التالفة في الذاكرة ، ويستمر في المعالجة. هذا السلوك يدمر البيانات ، أي جميع الخطوط في الصفحة التالفة.
قم بتشغيل الخيار وحاول إنشاء جداول فراغ كاملة:
VACUUM FULL VERBOSE
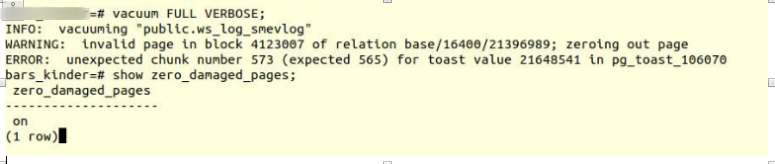
لسوء الحظ ، الفشل.
لقد واجهنا خطأً مماثلاً:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - آلية تخزين "البيانات الطويلة" في بوستجرس ، إذا لم تكن ملائمة على نفس الصفحة (8 كيلو بايت افتراضيًا).
محاولة 2: reindex
نصيحة google الأولى لم تساعد. بعد بضع دقائق من البحث ، وجدت نصيحة ثانية - لجعل
reindex طاولة تالفة. قابلت هذه النصيحة في العديد من الأماكن ، لكنها لم تلهم الثقة. اصنع ريندكس:
reindex table ws_log_smevlog
 reindex
reindex الانتهاء دون مشاكل.
ومع ذلك ، هذا لم يساعد ، تعطل
VACUUM FULL مع خطأ مماثل. منذ أن اعتدت على حالات الفشل ، بدأت أبحث عن المشورة على شبكة الإنترنت بشكل أكبر وصادفت
مقالًا مثيرًا للاهتمام إلى حد ما.
محاولة 3: حدد ، الحد ، OFFSET
اقترح المقال أعلاه النظر في جدول الجدول بسطر وحذف البيانات الإشكالية. للبدء ، كان من الضروري إلقاء نظرة على جميع الخطوط:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
في حالتي ، احتوى الجدول على
1628991 صفًا! بطريقة جيدة ، كان من الضروري الاهتمام
بتقسيم البيانات ، لكن هذا موضوع للمناقشة المنفصلة. كان يوم السبت ، ركضت هذا الأمر في tmux وذهبت للنوم:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
بحلول الصباح ، قررت أن أفحص كيف تسير الأمور. لدهشتي ، وجدت أنه خلال ساعتين تم فحص 2٪ فقط من البيانات! لم أكن أريد الانتظار لمدة 50 يومًا. فشل كامل آخر.
لكنني لم أستسلم. تساءلت لماذا استغرق المسح وقتًا طويلاً. من الوثائق (مرة أخرى على postgrespro) اكتشفت:
يشير OFFSET إلى تخطي عدد الخطوط المحدد قبل البدء في إنتاج الخطوط.
إذا تم تحديد كل من OFFSET و LIMIT ، يتخطى النظام أولاً خطوط OFFSET ثم يبدأ في حساب الخطوط للحد من LIMIT.
عند استخدام LIMIT ، من المهم أيضًا استخدام جملة ORDER BY بحيث يتم إرجاع خطوط النتيجة بترتيب معين. وإلا ، سيتم إرجاع مجموعات فرعية غير متوقعة من السلاسل.
من الواضح أن الأمر أعلاه كان خاطئًا: أولاً ، لم يكن هناك أي
أمر من جانب ، فالنتيجة قد تكون خاطئة. ثانياً ، كان على Postgres أولاً مسح خطوط OFFSET وتخطيها ، ومع زيادة
OFFSET ، سينخفض الأداء أكثر.
محاولة 4: إزالة تفريغ في شكل نص
علاوة على ذلك ، تتبادر إلى ذهني فكرة رائعة وهي إزالة ملف التفريغ في شكل نص وتحليل آخر سطر مسجل.
ولكن أولاً ،
دعنا ننظر إلى
بنية الجدول
ws_log_smevlog :

في حالتنا ، لدينا عمود
"معرف" ، والذي يحتوي على معرف فريد (عداد) للصف. كانت الخطة هي:
- نبدأ في إزالة التفريغ في شكل نص (في شكل أوامر sql)
- في وقت معين ، سيتم مقاطعة التفريغ نظرًا لحدوث خطأ ، ولكن لا يزال يتم حفظ الملف النصي على القرص
- نحن ننظر إلى نهاية الملف النصي ، وبالتالي نجد معرف (معرف) السطر الأخير الذي تم تصويره بنجاح
بدأت في إزالة ملف التفريغ في شكل نص:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
تمت مقاطعة تفريغ التفريغ ، كما هو متوقع ، بنفس الخطأ:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
علاوة على ذلك ، من خلال
الذيل ، نظرت إلى نهاية التفريغ (
الذيل -5 ./my_dump.dump ) ووجدت أن التفريغ قد انقطع على السطر ذو المعرف
186 525 . "لذا ، فإن المشكلة تتماشى مع المعرف 186 526 ، إنها مكسورة ، ويجب حذفها!" اعتقدت. ولكن عن طريق تقديم طلب إلى قاعدة البيانات:
"
حدد * من ws_log_smevlog حيث id = 186529 " اتضح أن كل شيء على ما يرام مع هذا السطر ... الخطوط ذات المؤشرات 186 530 - 186 540 عملت أيضًا دون مشاكل. فشل "فكرة رائعة" أخرى. في وقت لاحق ، فهمت سبب حدوث ذلك: عند حذف / تغيير البيانات من الجدول ، لا يتم حذفها فعليًا ، ولكن يتم تمييزها كـ "tuples ميتة" ، ثم يأتي
فراغ الفراغ التلقائي ويميز هذه الخطوط بأنها محذوفة ويسمح باستخدام هذه الخطوط مرة أخرى. لفهم أنه إذا تم تغيير البيانات الموجودة في الجدول وتم تشغيل ميزة التعبئة التلقائية ، فلن يتم تخزينها بالتتابع.
محاولة 5: حدد ، من ، حيث معرف =
الفشل يجعلنا أقوى. يجب ألا تستسلم أبدًا ، فأنت بحاجة إلى الوصول إلى النهاية والإيمان بنفسك وقدراتك. لذلك ، قررت تجربة خيار واحد آخر: فقط عرض جميع الإدخالات في قاعدة البيانات واحد في وقت واحد. مع العلم بهيكل طاولتي (انظر أعلاه) ، لدينا حقل معرف فريد (مفتاح أساسي). في الجدول ، لدينا 1،628،991 صفًا ورمزًا معرّفًا بالترتيب ، مما يعني أنه يمكننا ببساطة التكرار من خلالهم واحدًا تلو الآخر:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
إذا لم يفهم شخص ما ، يعمل الأمر كما يلي: يقوم بمسح جدول الجدول بسطر ويرسل stdout إلى
/ dev / null ، ولكن في حالة فشل الأمر SELECT ، يتم عرض نص الخطأ (يتم إرسال stderr إلى وحدة التحكم) ويتم إخراج سطر يحتوي على الخطأ (بفضل || ، والذي يعني أن الاختيار كان لديه مشاكل (كود إرجاع الأمر ليس 0)).
كنت محظوظًا ، وكان لدي فهارس تم إنشاؤها في حقل
المعرِّف :

هذا يعني أن العثور على السطر ذي المعرف المرغوب يجب ألا يستغرق الكثير من الوقت. من الناحية النظرية ، يجب أن تعمل. حسنًا ، قم بتشغيل الأمر في
tmux واذهب إلى النوم.
في الصباح ، وجدت أنه تم عرض حوالي 90،000 سجل ، وهو ما يزيد قليلاً عن 5٪. نتيجة ممتازة بالمقارنة مع الطريقة السابقة (2 ٪)! لكنني لا أريد الانتظار 20 يومًا ...
محاولة 6: SELECT ، FROM ، WHERE id> = و id <
تم تخصيص خادم ممتاز للعميل بموجب قاعدة البيانات: معالج ثنائي
Intel Intel Xeon E5-2697 v2 ، في موقعنا كان هناك ما يصل إلى 48 موضوع! كان تحميل الخادم متوسطًا ، وقد نأخذ حوالي 20 مؤشر ترابط دون أي مشاكل. كانت ذاكرة الوصول العشوائي كافية: 384 غيغابايت!
لذلك ، الأمر يحتاج إلى موازاة:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
كان من الممكن هنا كتابة نص برمجي جميل وأنيق ، لكنني اخترت أسرع طريقة للموازنة: قم يدويًا بتقسيم النطاق 0-1628991 إلى فواصل من 100000 سجل وتشغيل 16 أمر من النموذج بشكل منفصل:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
لكن هذا ليس كل شيء. من الناحية النظرية ، يستغرق الاتصال بقاعدة بيانات بعض الوقت وموارد النظام. الاتصال 1628199 لم يكن معقولاً جداً ، توافق. لذلك ، دعونا استخراج 1000 صف في اتصال واحد بدلاً من واحد. نتيجة لذلك ، تحول الفريق إلى هذا:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
افتح 16 نافذة في جلسة tmux وقم بتشغيل الأوامر:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
وبعد يوم ، حصلت على النتائج الأولى! وهي (القيمتان XXX و ZZZ لم يتم حفظهما):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
هذا يعني أن لدينا ثلاثة أسطر تحتوي على خطأ. يتراوح عدد سجلات id الأولى والثانية بين 829000 و 830،000 ، وكان الرقم الثالث بين 146000 و 147000. بعد ذلك ، كان علينا فقط العثور على قيمة المعرف الدقيقة لسجلات المشكلة. للقيام بذلك ، انظر إلى مجموعتنا التي تحتوي على سجلات للمشاكل في الخطوة 1 وحدد المعرف:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
نهاية سعيدة
وجدنا خطوط إشكالية. نذهب إلى قاعدة البيانات عبر psql ونحاول إزالتها:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
لدهشتي ، تم حذف الإدخالات دون أي مشاكل ، حتى من دون خيار
zero_damaged_pages .
ثم قمت بالاتصال بقاعدة البيانات ، وجعلت
VACUUM FULL (أعتقد أنه لم يكن من الضروري القيام بذلك) ، وأخيراً نجحت في إزالة النسخة الاحتياطية باستخدام
pg_dump . تفريغ دور البطولة دون أي أخطاء! تم حل المشكلة بطريقة غبية. لم يكن هناك حد للفرح ، بعد الكثير من الإخفاقات تمكنا من إيجاد حل!
شكر وتقدير
هذه هي تجربتي الأولى في استعادة قاعدة بيانات بوستجرس الحقيقية. سوف أتذكر هذه التجربة لفترة طويلة.
وأخيرًا ، أود أن أقول شكراً لـ PostgresPro على الوثائق المترجمة إلى اللغة الروسية وعلى
الدورات المجانية تمامًا عبر الإنترنت والتي ساعدت كثيرًا أثناء تحليل المشكلة.