في عملية العمل على مشروع كبير ، يوفر استعارة الوحدات الأخرى وحلول تسليم المفتاح كمية هائلة من وقت المطور وأموال المستثمر. واحدة من أكبر مستودعات مثل هذه الحلول هي إلى حد بعيد جيثب.
هناك خدعة صغيرة أسفل القطة التي أستخدمها عند البحث عن حلول جيثب واختيارها.
تخيل مهمة تطوير نظام
OSINT كبير ، دعنا نقول أننا بحاجة إلى النظر في جميع الحلول المتاحة على جيثب في هذا الاتجاه. نستخدم github العالمية القياسية للبحث عن الكلمة الأساسية osint. نحصل على 1124 مستودعًا ، والقدرة على التصفية حسب موقع البحث عن الكلمات الرئيسية (الكود ، التعهدات ، الإصدار ، إلخ) ، من خلال لغة التنفيذ. وفرزها حسب السمات المختلفة (مثل معظم / أقل عدد يبدأ ، شوك ، إلخ).
يتم اتخاذ القرار وفقًا لعدة معايير: الوظيفة ، عدد النجوم ، دعم المشروع ، لغة التطوير.
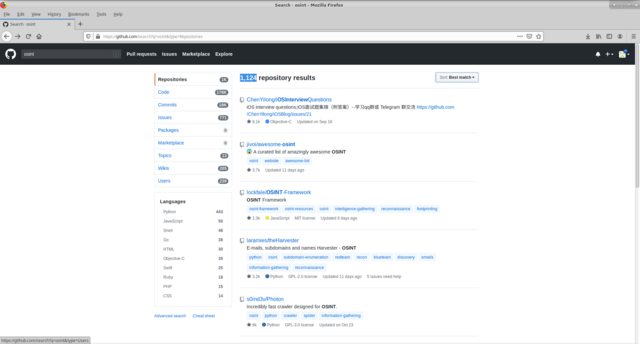
تم تلخيص القرارات التي تهمني في جدول تم فيه ملء الحقول المشار إليها أعلاه ، وتم تقديم الملاحظات المناسبة بناءً على نتائج اختبار معين.
عيب هذا الرأي ، كما يبدو لي ، هو عدم القدرة على الفرز والتصفية في وقت واحد عبر حقول متعددة.
باستخدام
api_github و
python3 ، نقوم بتحديد مخطط بسيط بسيط يشكل وثيقة
ملف بتنسيق csv مع الحقول التي تهمنا.
قم بتشغيل البرنامج النصي
python3 git_repo_search.py osint
نحن نحصل عليها
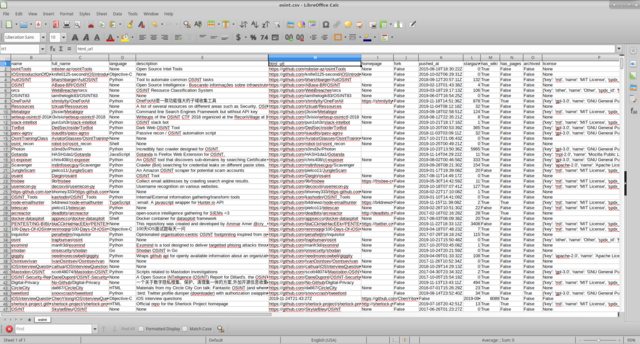
يبدو لي أن العمل بالمعلومات أكثر ملاءمة ، بعد إخفاء الأعمدة غير الضرورية.
كود
هناآمل أن يأتي شخص في متناول اليدين.