
قبل عامين ، نوقشت Kubernetes
بالفعل على مدونة جيثب الرسمية. منذ ذلك الحين ، أصبحت التكنولوجيا القياسية لنشر الخدمات. تدير Kubernetes الآن جزءًا كبيرًا من الخدمات الداخلية والعامة. مع نمو مجموعاتنا وأصبحت متطلبات الأداء أكثر صرامة ، بدأنا نلاحظ أن بعض الخدمات على Kubernetes تعرض بشكل متقطع التأخيرات التي لا يمكن تفسيرها من خلال تحميل التطبيق نفسه.
في الواقع ، في التطبيقات ، يحدث تأخير في شبكة عشوائية تصل إلى 100 مللي ثانية أو أكثر ، مما يؤدي إلى مهلات أو إعادة المحاولة. كان من المتوقع أن تكون الخدمات قادرة على الاستجابة للطلبات أسرع بكثير من 100 مللي ثانية. ولكن هذا غير ممكن إذا كان الاتصال نفسه يستغرق الكثير من الوقت. بشكل منفصل ، لاحظنا استعلامات MySQL سريعة جدًا ، والتي كان من المفترض أن تأخذ مللي ثانية ، وتمكنت MySQL من إدارة ميلي ثانية ، ولكن من وجهة نظر التطبيق الطالب ، استغرقت الاستجابة 100 مللي ثانية أو أكثر.
أصبح من الواضح على الفور أن المشكلة تحدث فقط عند الاتصال بمضيف Kubernetes ، حتى لو كانت المكالمة من خارج Kubernetes. تتمثل أسهل طريقة لإعادة إنتاج المشكلة في اختبار
Vegeta ، الذي يتم تشغيله من أي مضيف داخلي ، ويقوم باختبار خدمة Kubernetes على منفذ معين ، ويسجل بشكل متقطع تأخيرًا كبيرًا. في هذه المقالة ، سننظر في كيفية تمكننا من تعقب سبب هذه المشكلة.
تخلص من التعقيدات غير الضرورية في سلسلة الفشل
بعد إعادة إنتاج نفس المثال ، أردنا تضييق نطاق المشكلة وإزالة طبقات التعقيد الإضافية. في البداية ، كان هناك الكثير من العناصر في التيار بين Vegeta والقرون على Kubernetes. لتحديد مشكلة شبكة أعمق ، تحتاج إلى استبعاد بعضها.
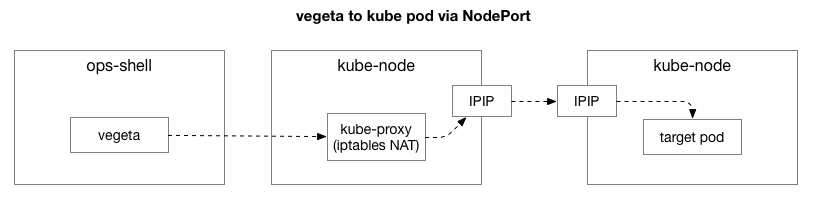
ينشئ العميل (Vegeta) اتصال TCP مع أي عقدة في الكتلة. تعمل Kubernetes كشبكة تراكب (عبر شبكة مركز البيانات الحالية) ، والتي تستخدم
IPIP ، أي ، تقوم بتغليف حزم IP لشبكة التراكب داخل حزم IP الخاصة بمركز البيانات. عند الاتصال بالعقدة الأولى ، يتم تنفيذ ترجمة عنوان شبكة ترجمة عنوان الشبكة (NAT) مع مراقبة الحالة لتحويل عنوان IP والمنفذ الخاص بمضيف Kubernetes إلى عنوان IP والمنفذ على شبكة التراكب (خاصة ، الحافظة مع التطبيق). للحزم المستلمة ، يتم تنفيذ التسلسل العكسي. هذا هو نظام معقد مع العديد من الدول والعديد من العناصر التي يتم تحديثها باستمرار وتغييرها مع نشر الخدمات ونقلها.
الأداة المساعدة
tcpdump في اختبار Vegeta يعطي تأخير أثناء مصافحة TCP (بين SYN و SYN-ACK). لإزالة هذا التعقيد غير الضروري ، يمكنك استخدام
hping3 "
hping3 " البسيطة مع حزم SYN. تحقق مما إذا كان هناك تأخير في حزمة الاستجابة ، ثم قم بإعادة تعيين الاتصال. يمكننا تصفية البيانات من خلال تضمين الحزم التي تزيد عن 100 مللي ثانية فقط ، والحصول على خيار أبسط لإعادة إنتاج المشكلة من اختبار مستوى الشبكة الكامل 7 في Vegeta. فيما يلي "الأصوات" لمضيف Kubernetes باستخدام TCP SYN / SYN-ACK على مضيف "المنفذ" للخدمة (30927) مع فاصل زمني قدره 10 مللي ثانية ، تتم تصفيته بواسطة أبطأ الاستجابات:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msيمكن أن تجعل على الفور أول ملاحظة. توضح الأرقام التسلسلية والتوقيتات أن هذه ليست احتقان لمرة واحدة. التأخير يتراكم في الغالب ، ويتم معالجته في النهاية.
بعد ذلك ، نريد أن نعرف المكونات التي قد تشارك في ظهور الازدحام. ربما هذه هي بعض المئات من قواعد iptables في NAT؟ أو بعض المشاكل مع نفق IPIP على الشبكة؟ إحدى طرق التحقق من ذلك هي التحقق من كل خطوة من خطوات النظام عن طريق استبعادها. ماذا يحدث إذا قمت بإزالة منطق NAT وجدار الحماية ، تاركة جزءًا فقط من IPIP:
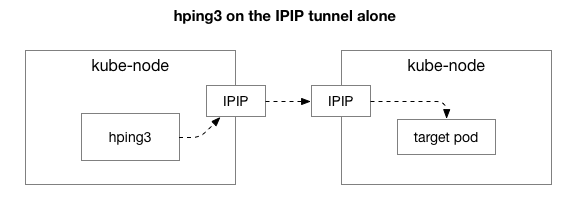
لحسن الحظ ، يسهل Linux الوصول مباشرة إلى طبقة تراكب IP إذا كان الجهاز على نفس الشبكة:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msاذا حكمنا من خلال النتائج ، لا تزال المشكلة قائمة! هذا يستبعد iptables و NAT. وبالتالي فإن المشكلة هي في TCP؟ دعونا نرى كيف يذهب بينغ ICMP العادية:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msأظهرت النتائج أن المشكلة لم تختف. ربما هذا هو نفق IPIP؟ دعونا تبسيط الاختبار:
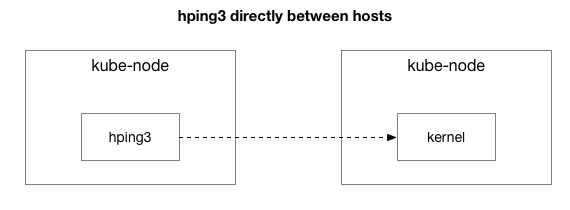
هل يتم إرسال جميع الحزم بين هذين المضيفين؟
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msلقد قمنا بتبسيط الموقف على مضيفين من Kubernetes بإرسال أي حزمة إلى بعضهما البعض ، حتى بين اختبار ICMP. ما زالوا يرون تأخيرًا إذا كان المضيف الهدف "سيئًا" (البعض أسوأ من الآخرين).
الآن السؤال الأخير: لماذا يحدث التأخير فقط على خوادم عقدة kube؟ وهل يحدث عندما تكون kube-node هي المرسل أو المستقبل؟ لحسن الحظ ، من السهل للغاية معرفة ذلك بإرسال حزمة من مضيف خارج Kubernetes ، ولكن مع نفس المستلم "السيئ المعروف". كما ترون ، لم تختف المشكلة:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msبعد ذلك ، نقوم بتنفيذ الطلبات نفسها من عقدة المصدر السابقة إلى المضيف الخارجي (الذي يستبعد المضيف الأصلي ، نظرًا لأن ping يشتمل على مكونات RX و TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msبعد فحص عمليات التقاط الحزمة المؤجلة ، حصلنا على بعض المعلومات الإضافية. على وجه الخصوص ، أن المرسل (أدناه) يرى هذه المهلة ، لكن المتلقي (أعلاه) لا يراها - راجع عمود دلتا (بالثواني):

بالإضافة إلى ذلك ، إذا نظرت إلى الفرق في ترتيب حزم TCP و ICMP (حسب أرقام التسلسل) على جانب المستلم ، فإن حزم ICMP تصل دائمًا بنفس التسلسل الذي تم إرسالها به ، لكن مع توقيت مختلف. في الوقت نفسه ، تتبدل حزم TCP أحيانًا ، ويتعطل بعضها. على وجه الخصوص ، إذا فحصنا منافذ حزم SYN ، فعندئذٍ من جانب المرسل يذهبون بالترتيب ، لكن من جانب المستلم لا يفعلون ذلك.
هناك اختلاف بسيط في كيفية معالجة
بطاقات الشبكة للخوادم الحديثة (كما في مركز البيانات الخاص بنا) الحزم التي تحتوي على TCP أو ICMP. عندما تصل الحزمة ، يقوم محول الشبكة "بتجزئةها عبر الاتصال" ، أي أنه يحاول قطع الاتصالات بالتناوب وإرسال كل قائمة انتظار إلى معالج معالج منفصل. بالنسبة إلى TCP ، تتضمن هذه التجزئة كل من عنوان IP للمصدر والوجهة والمنفذ. بمعنى آخر ، يتم تجزئة كل اتصال (يحتمل) بشكل مختلف. بالنسبة لـ ICMP ، يتم تجزئة عناوين IP فقط ، نظرًا لعدم وجود منافذ.
ملاحظة جديدة أخرى: خلال هذه الفترة نرى تأخير ICMP على جميع الاتصالات بين المضيفين ، ولكن TCP لا. هذا يخبرنا أن السبب ربما يرجع إلى تجزئة قوائم الانتظار RX: من شبه المؤكد أن الاحتقان يحدث في معالجة حزم RX ، بدلاً من إرسال الردود.
يستثني هذا إرسال الحزم من قائمة الأسباب المحتملة. نعلم الآن أن مشكلة معالجة الحزم هي في جانب المتلقي على بعض خوادم العقدة kube.
فهم معالجة الحزمة في Linux Kernel
لفهم سبب حدوث المشكلة مع المستلم على بعض خوادم kube-node ، دعونا نرى كيف تعالج kernel Linux الحزم.
بالرجوع إلى أبسط التنفيذ التقليدي ، تتلقى بطاقة الشبكة الحزمة وترسل
مقاطعة إلى kernel Linux ، وهي الحزمة التي تحتاج إلى معالجة. توقف kernel عملية أخرى ، وتقوم بتبديل السياق إلى معالج المقاطعة ، ومعالجة الحزمة ، ثم العودة إلى المهام الحالية.

رمز تبديل السياق هذا بطيء: قد لا يكون زمن الوصول ملحوظًا على بطاقات الشبكة ذات 10 ميجابايت في التسعينات ، ولكن على بطاقات 10G الحديثة بسرعات قصوى تصل إلى 15 مليون حزمة في الثانية ، يمكن مقاطعة كل نواة خادم صغير ذي ثمانية مراكز بملايين المرات في الثانية.
من أجل عدم التعامل مع المقاطعة بشكل مستمر ، أضاف Linux منذ عدة سنوات
NAPI : واجهة برمجة تطبيقات للشبكة تستخدمها جميع برامج التشغيل الحديثة لزيادة الأداء بسرعات عالية. عند السرعات المنخفضة ، لا يزال kernel يقبل المقاطعات من بطاقة الشبكة بالطريقة القديمة. بمجرد وصول عدد كافٍ من الحزم يتجاوز العتبة ، يقوم kernel بتعطيل المقاطعات وبدلاً من ذلك يبدأ استطلاع لمحول الشبكة وأخذ الحزم على دفعات. تتم المعالجة في softirq ، أي في
سياق مقاطعات
البرامج بعد مكالمات النظام ومقاطع الأجهزة عندما تكون النواة (على عكس مساحة المستخدم) قيد التشغيل بالفعل.
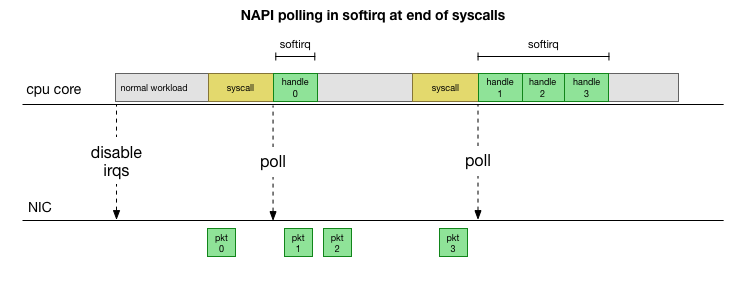
هذا أسرع بكثير ، لكنه يسبب مشكلة مختلفة. إذا كان هناك الكثير من الحزم ، فكل الوقت الذي تستغرقه معالجة الحزم من بطاقة الشبكة ، ولا تملك عمليات مساحة المستخدم الوقت لإفراغ قوائم الانتظار هذه فعليًا (القراءة من اتصالات TCP ، إلخ). في النهاية ، تملأ الطوابير ونبدأ في إسقاط الحزم. في محاولة للعثور على رصيد ، يحدد kernel ميزانية لأقصى عدد من الحزم التي تتم معالجتها في سياق softirq. بمجرد تجاوز هذه الميزانية ،
ksoftirqd مؤشر ترابط
ksoftirqd منفصل (سترى واحدًا منها في
ps لكل نواة) ، والذي يعالج هذه softirqs خارج مسار syscall / interrupt العادي. يتم تخطيط مؤشر الترابط هذا باستخدام جدولة عملية قياسية تحاول توزيع الموارد بشكل عادل.
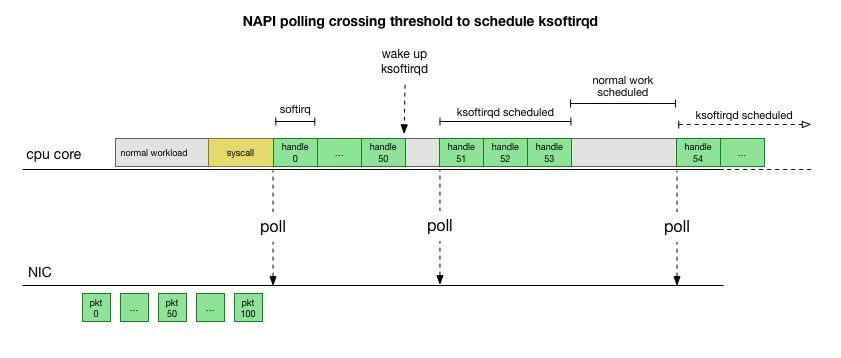
بعد فحص كيفية معالجة النواة للحزم ، يمكنك أن ترى أن هناك احتمالًا معينًا للازدحام. إذا تم تلقي مكالمات softirq بشكل متكرر أقل ، فستضطر الحزم إلى الانتظار بعض الوقت للمعالجة في قائمة انتظار RX على بطاقة الشبكة. ربما يكون هذا بسبب بعض المهام التي تمنع نواة المعالج ، أو أي شيء آخر يمنع النواة من بدء تشغيل softirq.
نقوم بتضييق نطاق المعالجة إلى النواة أو الطريقة
التأخير Softirq هي مجرد افتراض. لكن هذا منطقي ، ونعلم أننا نرى شيئًا مشابهًا للغاية. لذلك ، فإن الخطوة التالية هي تأكيد هذه النظرية. وإذا تم تأكيد ذلك ، فابحث عن سبب التأخير.
العودة إلى الحزم البطيئة لدينا:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msكما تمت مناقشته سابقًا ، يتم تجزئة حزم ICMP هذه إلى قائمة انتظار NIC RX واحدة ومعالجتها بواسطة وحدة معالجة مركزية واحدة. إذا كنا نريد أن نفهم كيف يعمل Linux ، فمن المفيد أن نعرف أين (على أي وحدة المعالجة المركزية الأساسية) وكيف (softirq ، ksoftirqd) تتم معالجة هذه الحزم لتتبع العملية.
حان الوقت الآن لاستخدام الأدوات التي تسمح بمراقبة نواة Linux في الوقت الفعلي. هنا استخدمنا
مخفية . تتيح لك مجموعة الأدوات هذه كتابة برامج C الصغيرة التي تعترض الوظائف التعسفية في أحداث kernel و buffer في برنامج Python الخاص بمساحة المستخدم والذي يمكنه معالجتها وإرجاع النتيجة. الخطافات للوظائف التعسفية في kernel معقدة ، ولكن الأداة المساعدة مصممة لتوفير أقصى درجات الأمان وتم تصميمها لتتبع مشكلات الإنتاج بدقة والتي ليس من السهل إعادة إنتاجها في بيئة اختبار أو تطوير.
الخطة هنا بسيطة: نحن نعلم أن kernel يعالج هذه الأصوات لـ ICMP ، لذلك نضع
ربطًا على وظيفة icmp_echo kernel ، التي تستقبل حزمة ICMP الواردة "طلب الارتداد" وتبدأ إرسال استجابة ICMP "استجابة الارتداد". يمكننا تحديد الحزمة عن طريق زيادة رقم icmp_seq ، والذي يظهر
hping3 أعلاه.
يبدو رمز
البرنامج النصي bcc معقدًا ، لكنه ليس مخيفًا كما يبدو. تقوم دالة
icmp_echo بتمرير
struct sk_buff *skb : هذه هي الحزمة مع طلب "طلب الارتداد". يمكننا تتبع ذلك ، وسحب تسلسل
echo.sequence (الذي يعين
icmp_seq من hping3
) ، وإرساله إلى مساحة المستخدم. كما أنه مناسب لالتقاط اسم / معرف العملية الحالي. فيما يلي النتائج التي نراها مباشرةً أثناء معالجة الحزم بواسطة kernel:
TGID PID PROCESS NAME ICMP_SEQ
0 0 swapper / 11،770
0 0 swapper / 11،771
0 0 swapper / 11 772
0 0 swapper / 11 773
0 0 swapper / 11،774
20041 20086 prometheus 775
0 0 swapper / 11،776
0 0 swapper / 11،777
0 0 swapper / 11 778
4512 4542 speaker-report-s 779
تجدر الإشارة هنا إلى أنه في سياق
softirq العمليات التي أجرت مكالمات النظام كـ "عمليات" ، على الرغم من أن هذا النواة في الحقيقة يعالج الحزم بأمان في سياق النواة.
باستخدام هذه الأداة ، يمكننا تأسيس اتصال عمليات محددة مع حزم محددة تظهر تأخيرًا في
hping3 . نصنع
grep بسيطًا في هذا الالتقاط لقيم
icmp_seq محددة. تم وضع علامة على الحزم المقابلة لقيم icmp_seq أعلاه بعلامة RTT الخاصة بها ، والتي لاحظناها أعلاه (بين قوسين هي قيم RTT المتوقعة للحزم التي قمنا بتصفيتها بسبب قيم RTT التي تقل عن 50 مللي ثانية):
TGID PID PROCESS NAME ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59ms
76 76 ksoftirqd / 11 1958 ** (49ms)
76 76 ksoftirqd / 11 1959 ** (39ms)
76 76 ksoftirqd / 11 1960 ** (29ms)
76 76 ksoftirqd / 11 1961 ** (19ms)
76 76 ksoftirqd / 11 1962 ** (9ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55ms
76 76 ksoftirqd / 11 2073 ** (45ms)
76 76 ksoftirqd / 11 2074 ** (35ms)
76 76 ksoftirqd / 11 2075 ** (25ms)
76 76 ksoftirqd / 11 2076 ** (15ms)
76 76 ksoftirqd / 11 2077 ** (5ms)
النتائج تخبرنا بعض الأشياء. أولاً ، يعالج سياق
ksoftirqd/11 كل هذه الحزم. هذا يعني أنه بالنسبة لهذا الزوج المعين من الآلات ، تم تجزئة حزم ICMP على النواة 11 في الطرف المتلقي. نرى أيضًا أنه في كل ازدحام مروري ، توجد حزم يتم معالجتها في سياق استدعاء نظام
cadvisor . ثم تأخذ
ksoftirqd المهمة وتلبي قائمة الانتظار المتراكمة: بالضبط عدد الحزم التي تراكمت بعد
cadvisor .
حقيقة أن
cadvisor يعمل دائما قبل هذا مباشرة يعني تورطه في المشكلة. ومن المفارقات أن الغرض من
cadvisor هو "تحليل استخدام الموارد وخصائص أداء حاويات التشغيل" ، بدلاً من التسبب في مشكلة الأداء هذه.
كما هو الحال مع الجوانب الأخرى لمناولة الحاويات ، فهذه كلها أدوات متطورة للغاية يمكن من خلالها توقع حدوث مشكلات في الأداء في بعض الظروف غير المتوقعة.
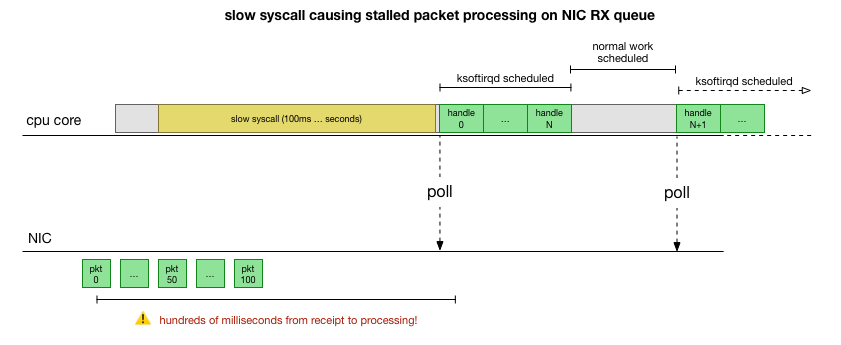
ماذا يفعل cadvisor أن يبطئ قائمة انتظار الحزمة؟
الآن لدينا فهم جيد لكيفية حدوث الفشل ، وأي عملية تتسبب فيه ، وعلى أي وحدة المعالجة المركزية. إننا نرى أنه نظرًا للحظر الصعب ، لا يوجد لدى Linux kernel الوقت لجدولة
ksoftirqd . ونحن نرى أن الحزم تتم معالجتها في سياق
cadvisor . من المنطقي افتراض أن
cadvisor يبدأ
cadvisor بطيئًا ، وبعد ذلك تتم معالجة جميع الحزم المتراكمة في هذا الوقت:
هذه هي النظرية ، ولكن كيف لاختبارها؟ ما يمكننا القيام به هو تتبع تشغيل وحدة المعالجة المركزية الأساسية خلال هذه العملية ، والعثور على النقطة التي يتم فيها تجاوز الميزانية من خلال عدد الحزم ويسمى ksoftirqd ، ثم تبدو قبل ذلك بقليل - ما الذي تم عمله بالضبط على وحدة المعالجة المركزية الأساسية قبل تلك اللحظة بالضبط. يشبه الأشعة السينية لوحدة المعالجة المركزية كل بضعة ميلي ثانية. سيبدو شيء مثل هذا:
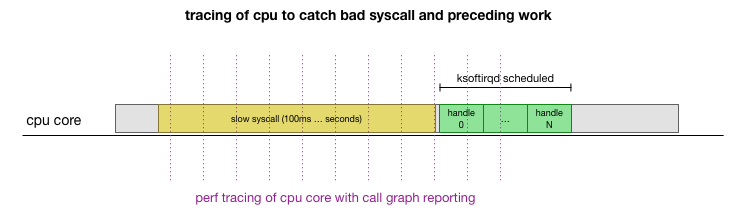
مريح ، كل هذا يمكن القيام به مع الأدوات الموجودة. على سبيل المثال ، يتحقق
سجل الأداء من وحدة المعالجة المركزية المحددة بالتردد المشار إليه ويمكنه إنشاء جدول للمكالمات إلى نظام يعمل ، بما في ذلك مساحة المستخدم ونواة Linux. يمكنك أخذ هذا السجل ومعالجته باستخدام شوكة صغيرة من برنامج
FlameGraph من Brendan Gregg ، والذي يحافظ على ترتيب تتبع المكدس. يمكننا حفظ آثار مكدس سطر واحد كل 1 مللي ثانية ، ثم تحديد وحفظ العينة لمدة 100 مللي ثانية قبل أن تحصل
ksoftirqd على التتبع:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100وهنا النتائج:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runهناك الكثير من الأشياء هنا ، ولكن الشيء الرئيسي هو أننا نجد قالب "cadvisor قبل ksoftirqd" الذي رأيناه سابقًا في تتبع ICMP. ماذا يعني هذا؟
كل سطر هو تتبع وحدة المعالجة المركزية في وقت معين من الزمن. يتم فصل كل استدعاء لأسفل المكدس في خط بفاصلة منقوطة. في منتصف السطور ، نرى syscall يسمى:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... . وبالتالي ، يقضي cadvisor الكثير من الوقت على مكالمة نظام
read() ، المتعلقة
mem_cgroup_* (أعلى مكدس المكالمة / نهاية السطر).
في تتبع المكالمات ، من غير
strace معرفة ما تتم قراءته بالضبط ، لذا قم بتشغيله
strace ما يفعله cadvisor ، وابحث عن مكالمات النظام التي تزيد عن 100 مللي ثانية:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>كما قد تتوقع ، نرى هنا مكالمات
read() بطيئة. من محتويات عمليات القراءة
mem_cgroup ، يمكن ملاحظة أن مكالمات
read() تشير إلى ملف
memory.stat ، الذي يوضح استخدام الذاكرة وقيود cgroup (تقنية عزل مورد Docker). تقوم أداة cadvisor باستقصاء هذا الملف للحصول على معلومات حول استخدام الموارد للحاويات. دعونا نتحقق مما إذا كان هذا الجهاز أو cadvisor يقوم بعمل غير متوقع:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $الآن يمكننا إعادة إنتاج الأخطاء وفهم أن نواة Linux تواجه علم الأمراض.
ما الذي يجعل القراءة بطيئة للغاية؟
في هذه المرحلة ، من الأسهل بكثير العثور على رسائل من مستخدمين آخرين حول مشكلات مماثلة. كما اتضح ، في تعقب cadvisor تم الإبلاغ عن هذا الخطأ
كمشكلة استخدام وحدة المعالجة المركزية المفرطة ، فقط لم يلاحظ أحد أن التأخير انعكس بشكل عشوائي أيضًا في مكدس الشبكة. في الواقع ، لوحظ أن cadvisor يستهلك وقتًا أطول من المتوقع للمعالج ، لكن هذا لم يعط أهمية كبيرة ، لأن خوادمنا لديها الكثير من موارد المعالج ، لذلك لم ندرس المشكلة بعناية.
المشكلة هي أن مجموعات التحكم (cgroups) تأخذ في الاعتبار استخدام الذاكرة داخل مساحة الاسم (الحاوية). عند انتهاء جميع العمليات في هذه المجموعة ، يحرر Docker مجموعة تحكم من الذاكرة. ومع ذلك ، فإن "الذاكرة" ليست مجرد ذاكرة عملية. على الرغم من أن ذاكرة العملية نفسها لم تعد مستخدمة ، فقد تبين أن النواة تقوم أيضًا بتعيين محتوى مؤقت ، مثل الأسنان و inode (الدليل وبيانات الملف الوصفية) ، والتي يتم تخزينها في ذاكرة التخزين المؤقت cgroup. من وصف المشكلة:
cgroups zombies: مجموعات التحكم التي لا توجد فيها عمليات ويتم حذفها ، لكن من أجلها لا تزال الذاكرة مخصصة (في حالتي ، من ذاكرة التخزين المؤقت لطب الأسنان ، ولكن يمكن تخصيصها أيضًا من ذاكرة التخزين المؤقت للصفحة أو tmpfs).
يمكن أن يكون التحقق من قبل النواة جميع الصفحات الموجودة في ذاكرة التخزين المؤقت عند تحرير cgroup بطيئًا للغاية ، لذلك يتم اختيار العملية البطيئة: انتظر حتى يتم طلب هذه الصفحات مرة أخرى ، وحتى عندما تكون هناك حاجة حقيقية للذاكرة ، قم بإلغاء تحديد cgroup أخيرًا. حتى الآن ، لا تزال cgroup تؤخذ في الاعتبار عند جمع الإحصاءات.
فيما يتعلق بالأداء ، فقد ضحوا بالذاكرة من أجل الأداء: تسريع عملية التنظيف الأولي نظرًا لحقيقة وجود القليل من الذاكرة المخزنة مؤقتًا. هذا طبيعي. عندما تستخدم kernel الجزء الأخير من الذاكرة المخبأة ، يتم مسح cgroup في النهاية ، لذلك لا يمكن تسميته "تسرب". لسوء الحظ ، يؤدي التنفيذ
memory.stat لآلية البحث
memory.stat في هذا الإصدار kernel (4.9) ، إلى جانب الكم الهائل من الذاكرة على خوادمنا ، إلى أن الأمر يتطلب وقتًا أطول بكثير لاستعادة أحدث البيانات المخزنة مؤقتًا ومسح زومبي cgroup.
اتضح أن هناك الكثير من الزومبي cgroup على بعض العقد لدينا أن القراءة والكمون تجاوزت الثانية.
يتمثل أحد حل المشكلة في cadvisor في مسح ذاكرة التخزين المؤقت على الفور dentries / inodes في جميع أنحاء النظام ، مما يحل على الفور كمون القراءة وكذلك زمن انتقال الشبكة على المضيف ، لأن حذف ذاكرة التخزين المؤقت يتضمن cgroup zombie الصفحات المخزنة مؤقتًا ، كما يتم تحريرها. هذا ليس حلاً ، لكنه يؤكد سبب المشكلة.
اتضح أن الإصدارات الأحدث من kernel (4.19+) حسّنت أداء مكالمة
memory.stat ، لذا فإن التبديل إلى هذا kernel حل المشكلة. في الوقت نفسه ، كان لدينا أدوات للكشف عن العقد المشكلة في مجموعات Kubernetes ، واستنزافها بأمان وإعادة التشغيل. تمشيطنا من خلال جميع المجموعات ، وجدنا العقد مع تأخير عالية بما فيه الكفاية وإعادة تشغيلها. هذا أعطانا الوقت لتحديث نظام التشغيل على بقية الخوادم.
لتلخيص
نظرًا لأن هذا الخطأ توقف عن معالجة قوائم انتظار NIC RX لمئات الميلي ثانية ، فقد تسبب في وقت واحد في تأخير كبير على الاتصالات القصيرة وتأخير في منتصف الاتصال ، على سبيل المثال ، بين استعلامات MySQL وحزم الاستجابة.
, Kubernetes, . Kubernetes .