
تقوم الشركة التي أعمل من أجلها بكتابة نظام فلترة حركة المرور الخاصة بها وتحمي الشركة من هجمات DDoS والروبوتات والمحللات وغير ذلك الكثير. يعتمد المنتج على عملية مثل
البروكسي العكسي ، والتي
نساعدها في تحليل كميات كبيرة من حركة المرور في الوقت الحقيقي ، وفي النهاية ، لا نسمح إلا من خلال طلبات المستخدمين المشروعة ، بتصفية جميع الطلبات الضارة.
الميزة الرئيسية هي أن خدماتنا تعمل مع حركة مرور واردة غير محدودة ، لذلك من المهم للغاية استخدام جميع موارد محطات العمل بأكبر قدر ممكن من الكفاءة. تساعدنا خبرة كبيرة في تطوير C ++ الحديثة في هذا ، بما في ذلك أحدث المعايير ومجموعة من المكتبات تسمى Boost.
عكس الوكيل
دعنا نعود إلى الوراء عكس الوكلاء ونرى كيف يمكنك تنفيذه في C ++ و boost.asio. بادئ ذي بدء ، نحن بحاجة إلى كائنين يسمى جلسات الخادم والعميل. تنشئ جلسة الخادم اتصالًا مع المستعرض وتحافظ عليه ؛ وتقوم جلسة العميل بإنشاء اتصال بالخدمة والحفاظ عليه. ستحتاج أيضًا إلى مخزن مؤقت للتيار الذي يُغلف العمل بذاكرة داخلية ، تُقرأ فيه جلسة الخادم من المقبس وتكتب منه جلسة العميل إلى المقبس. يمكن العثور على أمثلة لجلسات الخادم والعميل في الوثائق الخاصة ب boost.asio. كيفية العمل مع المخزن المؤقت تيار يمكن العثور عليها هناك.
بعد أن نجمع نموذج الوكيل العكسي من الأمثلة ، سيتضح أن هذا التطبيق لن يخدم على الأرجح حركة مرور واردة غير محدودة. ثم سنبدأ في زيادة تعقيد الكود. دعونا نفكر في multithreading ، و wokers وحمامات لسياقات io ، وكذلك أكثر من ذلك بكثير. على وجه الخصوص ، حول تحسينات سابقة لأوانها تتعلق بنسخ الذاكرة بين جلسات الخادم والعميل.
أي نوع من نسخ الذاكرة نتحدث عنه؟ الحقيقة هي أنه عند التصفية ، لا تنتقل حركة المرور دائمًا دون تغيير. انظر إلى المثال أدناه: حيث نزيل رأسًا واحدًا ونضيف اثنين بدلاً منه. يزداد عدد استعلامات المستخدم التي يتم تنفيذ إجراءات مماثلة عليها مع تعقيد المنطق داخل الخدمة. في أي حال ، يمكنك نسخ البيانات في مثل هذه الحالات بلا هوادة! إذا تغير 1٪ فقط من إجمالي الطلب ، وظل 99٪ بدون تغيير ، فيجب عليك تخصيص ذاكرة جديدة لهذا 1٪ فقط. سيساعدك في هذا التعزيز :: asio :: const_buffer و boost :: asio :: mutable_buffer ، والتي يمكنك من خلالها تمثيل عدة كتل مستمرة من الذاكرة مع كيان واحد.
طلب المستخدم:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
المشكلة
نتيجةً لذلك ، حصلنا على تطبيق جاهز يمكن أن يتطور بشكل جيد ويتمتع بجميع أنواع التحسينات. من خلال إطلاقه في الإنتاج ، كنا سعداء للغاية بالوقت الذي عملت فيه بشكل جيد وثابت.
مع مرور الوقت ، بدأنا في الحصول على المزيد والمزيد من العملاء ، مع ظهور حركة المرور التي نمت أيضا. في مرحلة ما ، واجهنا مشكلة نقص الأداء أثناء صد الهجمات الكبيرة. بعد تحليل الخدمة باستخدام الأداة المساعدة
perf ، لاحظنا أن جميع العمليات مع كومة الذاكرة المؤقتة قيد التحميل في الأعلى. ثم أعدنا وضعًا مشابهًا على دارة الاختبار باستخدام
دبابات yandex وخراطيش تم إنشاؤها بناءً على حركة مرور حقيقية. تثبيت على خدمة من خلال
مكبر للصوت ، رأينا الصورة التالية ...
لقطة شاشة لمكبر الصوت (woslab):
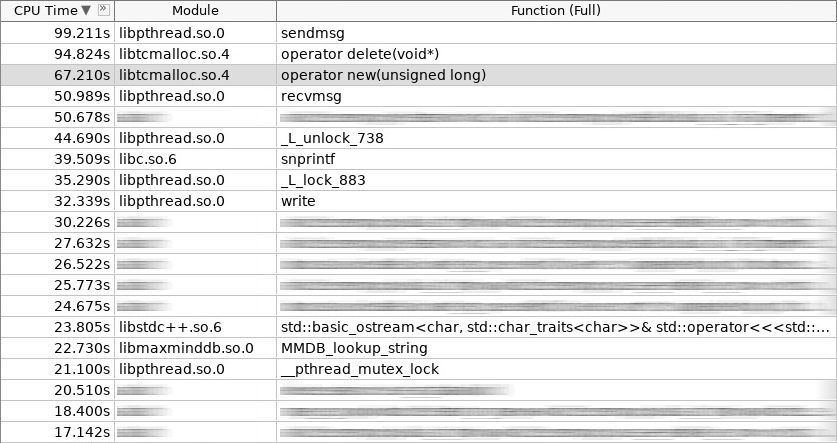
في لقطة الشاشة ، عمل المشغل الجديد لمدة 67 ثانية ، وحذف المشغل أكثر - 97 ثانية.
هذا الوضع أزعجنا. كيفية تقليل وقت البقاء التطبيق في المشغل الجديد وحذف المشغل؟ من المنطقي أن يتم ذلك عن طريق التخلي عن التخصيصات الثابتة للكائنات التي يتم إنشاؤها وحذفها بشكل متكرر على الكومة. استقرنا على ثلاثة نهج. اثنان منهم قياسي:
تجمع الكائنات وتخصيص المكدس . يتم وضع جلسات العميل التي يتم تنظيمها في تجمع في مرحلة بدء التطبيق في وضع جيد في النهج الأول. يتم استخدام الطريقة الثانية في كل مكان حيث تتم معالجة طلب المستخدم من البداية إلى النهاية في نفس الحزمة ، بمعنى آخر ، في معالج السياق io نفسه. لن نتناول هذا بمزيد من التفصيل. من الأفضل أن نتحدث عن الطريقة الثالثة ، باعتبارها الطريقة الأكثر تعقيدًا وإثارة للاهتمام. ويسمى
تخصيص بلاطة أو توزيع بلاطة.
فكرة توزيع الألواح ليست جديدة. تم اختراعه وتنفيذه في Solaris ، وتم ترحيله لاحقًا إلى kernel Linux ، وهو يتكون من حقيقة أن الكائنات المستخدمة في الغالب من نفس النوع تكون أسهل في التخزين في المجمع. نأخذ الكائن من التجمع عندما نحتاج إليه ، وعند الانتهاء من العمل ، نعيده مرة أخرى. لا توجد مكالمات لمشغل جديد ومشغل حذف! علاوة على ذلك ، الحد الأدنى من التهيئة. في لب الألواح ، يتم استخدام التوزيع للإشارات ، واصفات الملفات ، والعمليات ، والخيوط. في حالتنا ، وقع بشكل مثالي على جلسات الخادم والعميل ، وكذلك كل ما بداخلها.
الرسم البياني (توزيع بلاطة):

بالإضافة إلى حقيقة أن مخصصات البلاطات موجودة في النواة ، توجد تطبيقاتها أيضًا في مساحة المستخدم. هناك عدد قليل منهم ، وتلك التي تتطور بنشاط هي عموما قليلة.
استقرنا على مكتبة تسمى
libsmall ، والتي هي جزء من
tarantool . لديها كل ما تحتاجه.
- صغير :: مخصص
- صغير :: slab_cache (مؤشر ترابط محلي)
- الصغيرة :: بلاطة
- الصغيرة :: الساحة
- الصغيرة :: الحصة
بنية :: slab الصغيرة عبارة عن تجمع به نوع محدد من الكائنات. البنية الصغيرة :: slab_cache هي ذاكرة تخزين مؤقت تحتوي على قوائم متعددة من التجمعات بنوع محدد من الكائنات. الهيكل صغير :: مخصص هو رمز يحدد ذاكرة التخزين المؤقت الضرورية ، ويبحث عن تجمع مناسب فيه ، حيث يتم توزيع الكائن المطلوب. ما الأشياء الصغيرة :: الساحة والكائنات الصغيرة :: ستكون واضحة من الأمثلة أدناه.
اختام
مكتبة libsmall مكتوبة بلغة C ، وليس C ++ ، لذلك كان علينا تطوير عدة غلاف لتكامل شفاف في مكتبة C ++ القياسية.
- variti :: slab_allocator
- variti :: لوح
- variti :: thread_local_slab
- variti :: slab_allocate_shared
تطبق فئة variti :: slab_allocator الحد الأدنى من المتطلبات التي حددها المعيار عند كتابة مخصص خاص به. داخل الطبقات variti :: slab ، يتم تغليف كل العمل مع مكتبة libsmall. لماذا هناك حاجة إلى variti :: thread_local_slab؟ الحقيقة هي أن التخزين المؤقت لوح التوزيع هي كائنات مؤشر الترابط المحلية. هذا يعني أن كل مؤشر ترابط لديه مجموعة من ذاكرات التخزين المؤقت الخاصة به. يتم ذلك من أجل تقليل عدد العمليات المحظورة عند توزيع كائن جديد إلى صفر. لذلك ، في ذكرى كل موضوع ، نضع مثيلنا لفئة variti :: slab ، ويتم تنظيم الوصول إليه باستخدام برنامج variti :: thread_local_slab. سأخبرك عن وظيفة القالب variti :: slab_allocate_shared لاحقًا.
داخل فئة variti :: slab_allocator ، كل شيء بسيط للغاية. لديه القدرة على الترجيع من نوع إلى آخر ، على سبيل المثال ، من الفراغ إلى الحرف. ومن المثير للاهتمام ، يمكنك الانتباه إلى انتشار nullptr إلى الاستثناء std :: bad_alloc في حالة نفاد الذاكرة من لوحة التوزيع. يقوم الباقي بإعادة توجيه المكالمات داخل برنامج variti :: thread_local_slab.
مقتطف (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
دعونا نرى كيف يتم تطبيق المنشئ و destructor variti :: slab. في المنشئ ، نخصص ما لا يزيد عن 1 جيجا بايت من الذاكرة لجميع الكائنات. لا يتجاوز حجم كل مجموعة في حالتنا 1 ميجابايت. الحد الأدنى للكائن الذي يمكننا توزيعه هو 2 بايت في الحجم (في الواقع ، libsmall سيزيده إلى الحد الأدنى المطلوب - 8 بايت). الكائنات المتبقية المتاحة من خلال توزيع بلاطة لدينا ستكون مضاعفة لاثنين (تم ضبطها بواسطة ثابت 2.f). إجمالي ، يمكنك توزيع كائنات بحجم 8 ، 16 ، 32 ، إلخ. إذا كان حجم الكائن المطلوب 24 بايت ، فسيحدث مقدار حمل من الذاكرة. سيعيد التوزيع هذا الكائن إليك ، ولكن سيتم وضعه في تجمع يتوافق مع كائن بحجم 32 بايت. 8 بايت المتبقية ستكون خاملاً.
مقتطف (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
تنطبق كل هذه القيود على نسخة معينة من فئة variti :: slab. نظرًا لأن كل مؤشر ترابط خاص به (فكر في مؤشر ترابط محلي) ، فإن الحد الإجمالي لهذه العملية لن يكون 1 جيجا بايت ، ولكن سيكون متناسبًا بشكل مباشر مع عدد مؤشرات الترابط التي تستخدم توزيع بلاطة.
المخطط (std :: thread :: id):
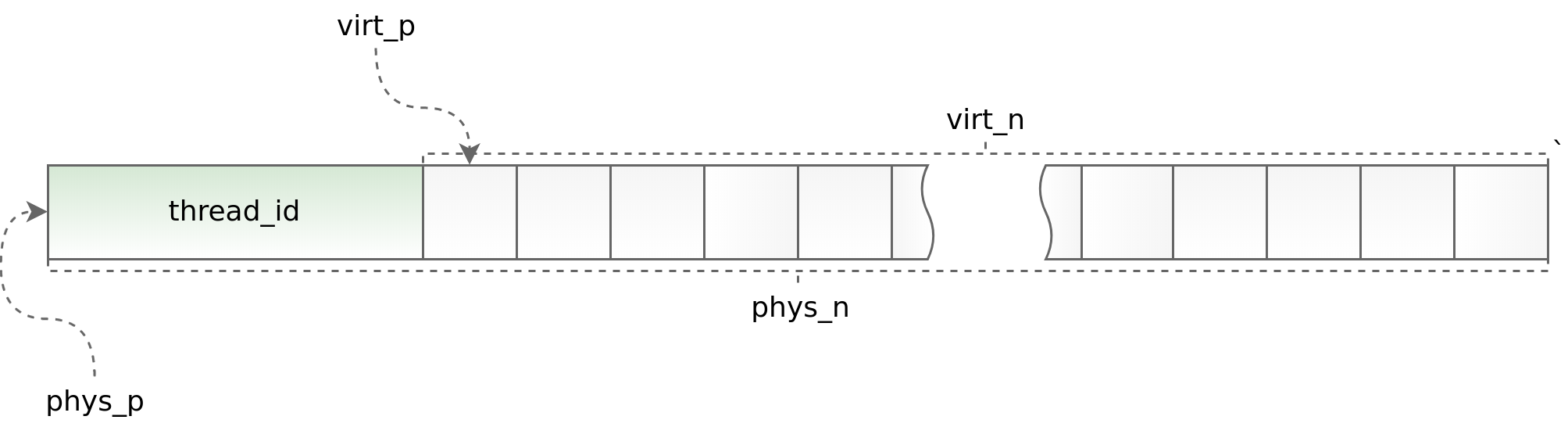
من ناحية ، يتيح لك استخدام مؤشر الترابط المحلي تسريع عمل توزيع الألواح في تطبيق متعدد الخيوط ، من ناحية أخرى ، فإنه يفرض قيودًا شديدة على بنية التطبيق غير المتزامن. يجب عليك طلب وإرجاع كائن في نفس الدفق. القيام بذلك كجزء من boost.asio هو في بعض الأحيان مشكلة للغاية. لتتبع المواقف الخاطئة بشكل واضح ، في بداية كل كائن ، نضع معرف الدفق الذي تسمى فيه طريقة التخصيص. يتم التحقق من هذا المعرف في طريقة إلغاء تخصيص البيانات. المساعدون phys_to_virt_p و virt_to_phys_p يساعدون في هذا.
مقتطف (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
مقتطف (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
عند فقدان التحكم في الدفق (عند نقل كائن بين سياقات io مختلفة) ، يسمح المؤشر الذكي بالإفراج الصحيح عن الكائن. كل ما يفعله هو توزيع الكائن ، وتذكر سياق io الخاص به ، ثم لفه في std :: shared_ptr بمقسم مخصص ، والذي لا يُرجع الكائن فورًا إلى التوزيع ، لكنه يفعله في سياق io الذي تم حفظه مسبقًا. هذا يعمل بشكل جيد عندما يعمل كل سياق io على موضوع واحد. خلاف ذلك ، لسوء الحظ ، هذا النهج غير قابل للتطبيق.
مقتطف (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
قرار
بعد اكتمال عمل التفاف libsmall ، قمنا أولاً بنقل مخصصات chun داخل المخزن المؤقت للتيار للبلاطة. كان هذا من السهل جدا القيام به. بعد أن تلقينا نتيجة إيجابية ، فقد تقدمنا وطبقنا أدوات تخصيص الألواح أولاً على المخزن المؤقت للتيار نفسه ، ثم على جميع الكائنات داخل جلسات عمل الخادم والعميل.
- variti :: القطعة
- variti :: streambuf
- variti :: server_session
- variti :: client_session
في الوقت نفسه ، كان من الضروري حل المشكلات الإضافية ، وهي: نقل الكائنات البسيطة والكائنات المركبة والمجموعات إلى موزعي بلاطات. وإذا لم تكن هناك صعوبات خطيرة في أول فئتين من الكائنات (يتم اختزال الكائنات المركبة إلى أشياء بسيطة) ، فعند ترجمة مجموعات ، واجهنا صعوبات خطيرة.
- الأمراض المنقولة جنسيا :: قائمة
- الأمراض المنقولة جنسيا :: deque
- الأمراض المنقولة جنسيا :: ناقلات
- الأمراض المنقولة جنسيا :: سلسلة
- الأمراض المنقولة جنسيا :: خريطة
- الأمراض المنقولة جنسيا :: unordered_map
أحد القيود الرئيسية عند العمل مع توزيع الألواح هو أن عدد الكائنات من الأنواع المختلفة لا ينبغي أن يكون كبيرًا جدًا (كلما كان أصغر ، كان أفضل). في هذا السياق ، قد تقع بعض المجموعات على مفهوم مخصصات البلاطات ، في حين أن بعضها قد لا يكون كذلك.
بالنسبة إلى std :: list slab ، يعمل المُخصصون بشكل رائع. يتم تنفيذ هذه المجموعة داخليًا باستخدام قائمة مرتبطة ، يكون لكل عنصر منها حجم ثابت. وبالتالي ، مع إضافة بيانات جديدة إلى قائمة الأمراض المنقولة جنسياً :: في توزيع الألواح ، لا تظهر أنواع جديدة من الكائنات. الشرط المشار إليه أعلاه مقتنع! الأمراض المنقولة جنسيا :: خريطة مرتبة بالمثل. الفرق الوحيد هو أنه في الداخل ليست قائمة مرتبطة ، ولكن شجرة.
في حالة الأمراض المنقولة جنسيا :: deque ، الأمور أكثر تعقيدا. يتم تطبيق هذه المجموعة من خلال كتلة متجاورة من الذاكرة تحتوي على مؤشرات إلى قطع. على الرغم من أن الأجزاء الدقيقة دقيقة جدًا ، إلا أن std :: deque تتصرف بنفس الطريقة التي تتبعها std :: list ، ولكن عند نهايتها ، يتم إعادة توزيع نفس كتلة الذاكرة هذه. من وجهة نظر مخصصات البلاطات ، فإن كل عملية إعادة توزيع للذاكرة هي كائن بنوع جديد. يعتمد عدد الكائنات المضافة إلى المجموعة بشكل مباشر على المستخدم ويمكن أن ينمو بشكل لا يمكن السيطرة عليه. هذا الموقف غير مقبول ، لذلك إما أننا قمنا أولاً بتحديد حجم std :: deque حيثما كان ذلك ممكنًا ، أو فضل std :: list.
إذا أخذنا std :: vector و std :: string ، فسيظلون أكثر تعقيدًا. يشبه تطبيق هذه المجموعات نوعًا ما std :: deque ، إلا أن كتلة الذاكرة المستمرة الخاصة بهم تنمو بشكل أسرع. استبدلنا std :: vector و std :: string بـ std :: deque ، وفي أسوأ الحالات مع std :: list. نعم ، فقدنا الأداء الوظيفي وفي مكان ما حتى في الأداء ، لكن هذا أثر على الصورة النهائية أقل بكثير من التحسينات التي تم تصميم كل شيء لها.
لقد فعلنا نفس الشيء تمامًا باستخدام std :: unordered_map ، مع التخلي عنه لصالح variti :: flat_map المكتوب ذاتيًا والذي تم تنفيذه من خلال std :: deque. في الوقت نفسه ، قمنا ببساطة بتخزين المفاتيح المستخدمة بشكل متكرر في متغيرات منفصلة ، على سبيل المثال ، كما هو الحال مع رؤوس طلبات http في nginx.
استنتاج
بعد الانتهاء من النقل الكامل لجلسات الخادم والعميل إلى موزعي بلاطات ، قللنا الوقت الذي تستغرقه مجموعة العمل بأكثر من مرة ونصف.
لقطة شاشة لمكبر الصوت (coldslab):
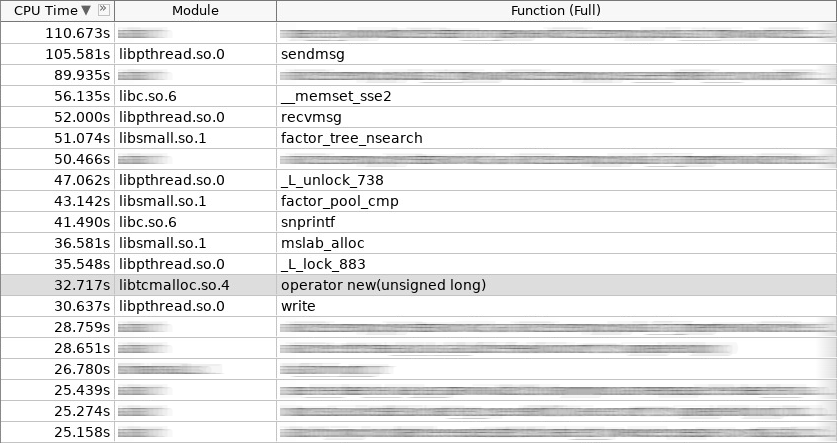
في لقطة الشاشة ، عمل المشغل الجديد 32 ثانية ، وحذف المشغل - 24 ثانية. بحلول هذا الوقت ، تمت إضافة وظائف أخرى للعمل مع الكومة: smalloc - 21 ثانية ، mslab_alloc - 37 ثانية ، smfree - 8 ثواني ، mslab_free - 21 ثانية. المجموع ، 143 ثانية مقابل 161 ثانية.
ولكن تم إجراء هذه القياسات فور بدء الخدمة دون تهيئة المخابئ في توزيع البلاطة. بعد إطلاق النار المتكرر من خزان ياندكس ، تحسنت الصورة العامة.
لقطة شاشة للمكبر (hotslab):
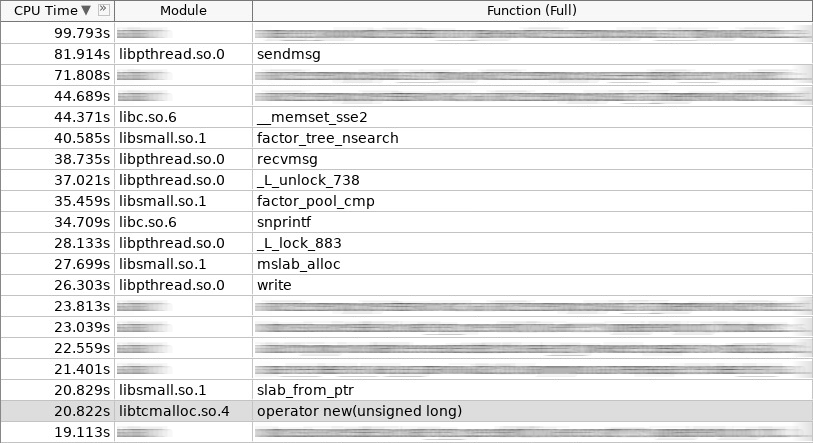
في لقطة الشاشة ، عمل المشغل الجديد 20 ثانية ، smalloc - 16 ثانية ، mslab_alloc - 27 ثانية ، حذف المشغل - 16 ثانية ، smfree - 7 ثواني ، mslab_free - 17 ثانية. مجموع 103 ثانية مقابل 161 ثانية.
جدول القياس:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
في الحياة الواقعية ، يجب أن تكون النتيجة أفضل ، حيث إن موزعي البلاطات لا يحلون مشكلة تخصيص الذاكرة الطويلة وتحريرها فحسب ، بل أيضًا تقليل التجزئة. بدون بلاطة ، بمرور الوقت ، يجب أن يتباطأ تشغيل المشغل الجديد وحذف المشغل. مع بلاطة - ستبقى دائما في نفس المستوى.
كما يمكننا أن نرى ، فإن مصممي الألواح يحلون بنجاح مشكلة تخصيص الذاكرة للكائنات المستخدمة بكثرة. انتبه لهم إذا كانت مسألة الإنشاء المتكرر وإزالة الأشياء مناسبة لك. لكن لا تنسى القيود التي يفرضونها على بنية التطبيق الخاص بك! لا يمكن ببساطة وضع كل الكائنات المعقدة في توزيع البلاطة. في بعض الأحيان عليك أن تتخلى عن الكثير! حسنًا ، كلما كانت بنية تطبيقك أكثر تعقيدًا ، كلما تعين عليك في كثير من الأحيان إعادة الكائن إلى ذاكرة التخزين المؤقت الصحيحة من حيث تعدد العمليات. قد يكون الأمر بسيطًا عندما تعمد على الفور إلى وضع بنية التطبيق ، مع مراعاة استخدام مُخصصات البلاطات ، ولكنه سيؤدي بالتأكيد إلى صعوبات عندما تقرر دمجها في مرحلة متأخرة.
تطبيق
تحقق من شفرة المصدر
هنا !