تحية!
يحدث أن تشاهد فيلمًا ، وفي رأسك هناك سؤال واحد فقط - "هل أحصل على clickbait مرة أخرى؟" سنحل هذه المشكلة وسنشاهد الأفلام المناسبة فقط. أقترح تجربة البيانات قليلاً وكتابة شبكة عصبية بسيطة لتقييم الفيلم.
تعتمد تجربتنا على تقنية تحليل المشاعر لتحديد مزاج الجمهور للمنتج. كبيانات نأخذ مجموعة بيانات من مراجعات المستخدم على أفلام IMDb. تسمح لك بيئة تطوير Google Colab بتدريب شبكتك العصبية بسرعة بفضل حرية الوصول إلى GPU (NVidia Tesla K80).
أستخدم مكتبة Keras ، التي سأساعدها في بناء نموذج عالمي لحل مشكلات مماثلة في تعلم الآلة. سأحتاج إلى الواجهة الخلفية TensorFlow ، الإصدار الافتراضي في Colab 1.15.0 ، لذلك فقط قم بالترقية إلى 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
بعد ذلك ، نقوم باستيراد جميع الوحدات اللازمة للمعالجة المسبقة للبيانات وبناء النماذج. في المقالات السابقة ، يتم التركيز على المكتبات ، ويمكنك البحث هناك.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
تحليل بيانات IMDb
تتكون مجموعة بيانات IMDb من 50000 فيلم مراجعات من المستخدمين الذين تم وضع علامة إيجابية عليهم (1) والسلبية (0).
- تتم معالجة المراجعات مسبقًا ، ويتم ترميز كل منها بسلسلة من مؤشرات الكلمات في شكل أعداد صحيحة
- تتم فهرسة الكلمات في المراجعات حسب إجمالي تواترها في مجموعة البيانات. على سبيل المثال ، يقوم العدد الصحيح "2" بترميز الكلمة الثانية الأكثر استخدامًا
- يتم تقسيم 50،000 مراجعة إلى مجموعتين: 25000 للتدريب و 25000 للاختبار.
قم بتنزيل مجموعة البيانات المضمنة في Keras. نظرًا لأن البيانات مقسمة إلى تدريب واختبار بنسبة 50-50 ، فسوف أقوم بدمجها بحيث يمكنني فيما بعد تقسيمها على 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
استكشاف البيانات
لنلقِ نظرة على ما نعمل عليه.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

يمكنك أن ترى أن جميع البيانات تنتمي إلى فئتين: 0 أو 1 ، وهو ما يمثل مزاج المراجعة. تحتوي مجموعة البيانات بأكملها على 9998 كلمة فريدة ، ومتوسط حجم المراجعة هو 234 كلمة بانحراف معياري قدره 173.
لنلقِ نظرة على المراجعة الأولى من مجموعة البيانات هذه ، والتي تم تمييزها على أنها إيجابية.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

إعداد البيانات
حان الوقت لإعداد البيانات. نحتاج إلى توجيه كل دراسة استقصائية وملء الأصفار بحيث يحتوي المتجه على 10000 رقم بالضبط. هذا يعني أن كل مراجعة أقصر من 10000 كلمة تمتلئ بالأصفار. أفعل ذلك لأن النظرة العامة الأكبر هي بنفس الحجم تقريبًا ، ويجب أن يكون لكل عنصر إدخال في شبكتنا العصبية نفس الحجم. تحتاج أيضًا إلى تحويل المتغيرات إلى نوع عائم.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
بعد ذلك ، أقسم مجموعة البيانات إلى بيانات تدريب واختبار كما هو متفق عليه 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
إنشاء وتدريب نموذج
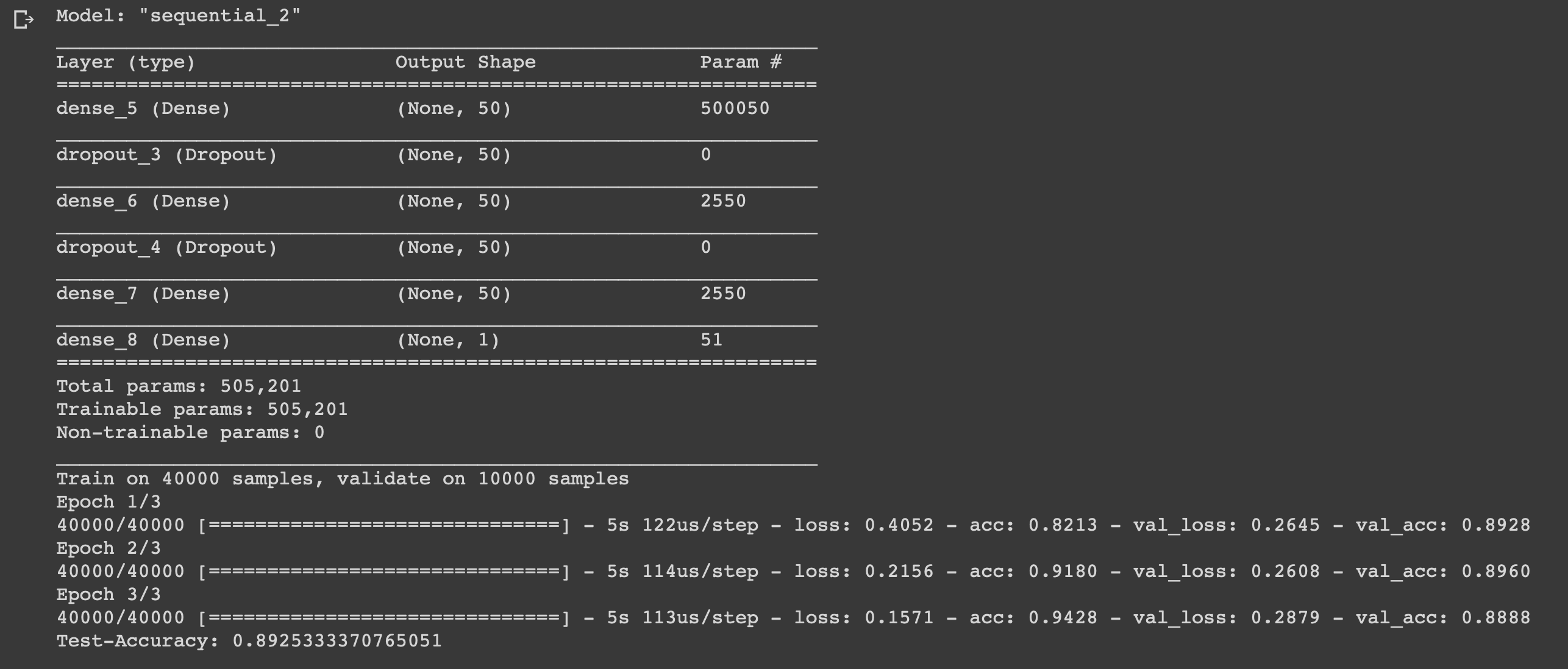
الشيء صغير ، يبقى فقط كتابة نموذج وتدريبه. ابدأ باختيار نوع. يتوفر نوعان من النماذج في Keras: متسلسل ومع واجهة برمجة تطبيقات وظيفية. ثم تحتاج إلى إضافة المدخلات ، والطبقات المخفية والإخراج.
لمنع إعادة التدريب ، سنستخدم "التسرب" بينهما ، وفي كل طبقة نستخدم الدالة "الكثيفة" لتوصيل الطبقات بعضها ببعض. في الطبقات المخفية ، سنستخدم وظيفة التنشيط "relu" ، وهذا يؤدي دائمًا إلى نتائج مرضية. في طبقة المخرجات ، نستخدم دالة السيني التي تعيد صياغة القيم في النطاق من 0 إلى 1.
أستخدم مُحسِّن adam ، سيغير الأوزان أثناء التدريب.
نستخدم الانتروبيا الثنائية كدالة للخسارة ، والدقة كمقياس للقياس.
الآن يمكنك تدريب نموذجنا. سنفعل ذلك بحجم دفعة 500 وثلاثة عصور فقط ، حيث تم الكشف عن أن النموذج يبدأ في إعادة التدريب إذا تم تدريبه لفترة أطول.
model = models.Sequential()
استنتاج
لقد أنشأنا شبكة عصبية بسيطة مكونة من ستة طبقات يمكنها حساب مزاج صانعي الأفلام بدقة 0.89. بالطبع ، لمشاهدة الأفلام الرائعة ، ليس من الضروري على الإطلاق كتابة شبكة عصبية ، ولكن هذا مجرد مثال آخر على كيفية استخدام البيانات ، والاستفادة منها ، لأنك في حاجة إليها. الشبكة العصبية عالمية بسبب بساطة بنيتها ، وتغيير بعض المعلمات ، ويمكنك تكييفها لمهام مختلفة تماما.
لا تتردد في كتابة أفكارك في التعليقات.